数组使用一块连续的存储单元来存储数据,而链表是用一组任意地址的存储单元来存储数据,且链表的长度是不固定的,这一特点使其可以非常方便地实现节点的插入和删除操作。
链表的每个元素称为一个节点,每个节点都可以存储在内存中的不同的位置,为了表示每个元素与后继元素的逻辑关系,以便构成“一个节点链着一个节点”的链式存储结构。
除了存储元素本身的信息外,还要存储其直接后继信息。因此,每个节点都包含两个部分,第一部分称为链表的数据域,用于存储元素本身的数据信息,这里用 data 表示,它不局限于一个成员数据,也可是多个成员数据。第二部分是一个结构体指针,称为链表的指针域,用于存储其直接后继的节点信息,这里用next表示,next的值实际上就是下一个节点的地址。
struct foo_s {
int data;
struct foo_s *next;
};
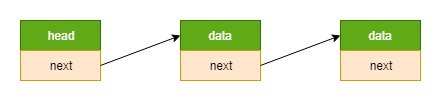
链表 = 节点1 --> 节点2 -->… (前一个节点的指针域指向下一个节点的数据结构首地址)
节点 = data + next (每个节点都是使用的相同的数据结构)
struct list_s {
struct list_s *next;
};
struct foo_s {
int data;
struct list_s link;
};
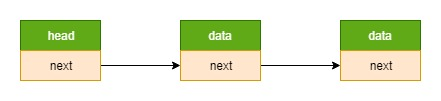
链表 = 节点1 --> 节点2 --> … (前一个节点的指针域指向下一个节点的指针域)
节点 = data + next (节点可以使用不同的数据结构,如 struct foo_s、struct foo_s2,只要在它们内部都包含 struct list_s就可以了)
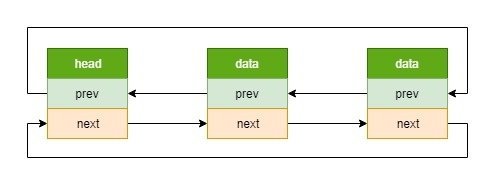
内核中使用的链表大多数都是侵入式链表,不过要比上面的例子稍微复杂点,是侵入式双向循环链表,如下图
其数据结构如下,这里以 led_classdev 为例
struct list_head {
struct list_head *next, *prev;
};
struct led_classdev {
const char *name;
enum led_brightness brightness;
enum led_brightness max_brightness;
int flags;
...
struct list_head node; /* LED Device list */
...
}
从上面结构体可以看出,链表(list_head)是嵌(侵)入在其它宿主数据结构(led_classdev)中的,这些宿主数据结构可以不相同。并且,这些宿主数据结构中可以包含多个链表。
如果我们有一种数据结构 foo,并且需要维持一个这种数据结构的双链队列,最简单的、也是最常用的办法就是在这个数据结构的类型定义中加入两个指针,例如:
typedef struct foo {
struct foo *prev;
struct foo *next;
....
} foo;
然后为这种数据结构写一套用于各种队列操作的子程序。由于用来维持队列的这两个指针的类型是固定的(都指向 foo 数据结构),这些子程序不能用于其它数据结构的队列。换言之,需要维持多少种数据结构的队列,就得有多少套的队列操作子程序。对于使用队列较少的应用程序或许不是个大问题,但对于使用大量队列的内核就成问题了。所以,Linux 内核中采用了一套通用的、一般的、可以用到各种不同数据结构的队列操作。为此,代码的作者们把指针 prev 和 next 从具体的“宿主”数据结构中抽象出来成为一种数据结构 list_head,这种数据结构既可以“寄宿”在具体的宿主数据结构内部,成为该数据结构的一个“连接件”;也可以独立存在而成为一个队列的头。这个数据结构的定义在 include/linux/list.h 中
我们以用于内存页面管理的 page 数据结构为例:
typedef struct page {
struct list_head list;
...
struct list_head lru;
...
} mem_map_t;
可见,在 page 数据结构中寄宿了两个 list_head 结构,或者说有两个队列操作的连接件,所以 page 结构可以同时存在于两个双链队列中。
有些小伙伴可能发问了:队列操作都是通过 list_head 进行的,但是那不过是个连接件,如果我们手上有宿主结构,那当然知道它的某个 list_head 在哪里,从而以此为参数调用 list_add() 或 list_del();可是,反过来,当我们顺着一个队列取得其中一项的 list_head 结构时,又怎样找到其宿主结构呢?在 list_head 结构中并没有指向宿主结构的指针啊。毕竟,我们真正关心的是宿主结构,而不是连接件。
这就要提到内核中 offsetof、container_of 这两个神奇的宏了,使用这两个宏,在给定链表结构地址时,我们能够获取其宿主结构的地址。这样就能开心地操作宿主结构了。这里我们只给出它们的定义,后面再专门写文章介绍他们。
include/linux/kernel.h
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member) * __mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member)); })
在Ruby(1.8.X)中为什么Object既继承了内核又包含了内核?仅仅继承还不够吗?irb(main):006:0>Object.ancestors=>[Object,Kernel]irb(main):005:0>Object.included_modules=>[Kernel]irb(main):011:0>Object.superclass=>nil请注意,在Ruby1.9中情况类似(但更简洁):irb(main):001:0>Object.ancestors=>[Object,Kernel,BasicObject]irb(main):002:0>Object.included
在Ruby中的面向对象设计一书中,SandiMetz说模块的主要用途是用它们实现鸭子类型,并将它们包含在每个需要的类中。为什么RubyKernel是包含在Object中的模块?据我所知,它没有在其他任何地方使用。使用模块有什么意义? 最佳答案 理想情况下,Methodsinspirit(适用于任何对象),即使用接收器的方法,应在Object上定义上课,而Procedures(全局提供),即忽略接收者的方法,应该收集在Kernel中模块。Kernel#puts,例如不对其接收者做任何事情;它不调用它的私有(private)方法,它不访
在笔者前面有一篇文章《驱动开发:断链隐藏驱动程序自身》通过摘除驱动的链表实现了断链隐藏自身的目的,但此方法恢复时会触发PG会蓝屏,偶然间在网上找到了一个作者介绍的一种方法,觉得有必要详细分析一下他是如何实现的进程隐藏的,总体来说作者的思路是最终寻找到MiProcessLoaderEntry的入口地址,该函数的作用是将驱动信息加入链表和移除链表,运用这个函数即可动态处理驱动的添加和移除问题。MiProcessLoaderEntry(pDriverObject->DriverSection,1)添加MiProcessLoaderEntry(pDriverObject->DriverSection,
在Ruby中,方法puts是Kernel的单例方法模块。通常,当一个模块是included或extend由另一个模块编辑,该模块(但不是它的单例类)被添加到继承树中。这有效地使模块的实例方法可用于模块或其单例类(分别用于include和extend)......但混合模块的单例方法仍然无法访问,因为单例类从未将模块添加到继承树中。那么为什么我可以使用puts(和其他内核单例方法)?Kernel.singleton_methods(false)#=>[:caller_locations,:local_variables,:require,:require_relative,:autolo
前文,我们实现了认识了链表这一结构,并实现了无头单向非循环链表,接下来我们实现另一种常用的链表结构,带头双向循环链表。如有仍不了解单向链表的,请看这一篇文章(7条消息)【数据结构和算法】认识线性表中的链表,并实现单向链表_小王学代码的博客-CSDN博客目录前言一、带头双向循环链表是什么?二、实现带头双向循环链表1.结构体和要实现函数2.初始化和打印链表3.头插和尾插4.头删和尾删5.查找和返回结点个数6.在pos位置之前插入结点7.删除指定pos结点8.摧毁链表三、完整代码1.DSLinkList.h2.DSLinkList.c3.test.c总结前言带头双向循环链表,是链表中最为复杂的一种结
我是Sidekiq的新手,将它与AmazonEC2实例上的Ruby结合使用,以使用ImageMagick处理图像来完成一些工作。在运行它时,我意识到每个工作人员都在同一个核心上运行。我使用EC2c3.2xlarge机器,它们有8个内核。它显示CPU使用率为15%,但一个内核使用了100%,而其他内核使用了0%。Sidekiq可以为不同的worker使用不同的CPU内核吗?如果可以,这种低效率是由ImageMagic造成的吗?我怎样才能让它使用其他内核? 最佳答案 如果您想使用MRI使用多个内核,则需要启动多个Sidekiq进程;为您
原文链接,欢迎关注:你为什么学习Linux内核?-CodeAllen的回答-知乎https://www.zhihu.com/question/31369673/answer/2894981254主要是工作需要,其实对于我自己的工作来说,在Linux开发的具体业务和算法才是重要的,内核的知识并没有那么重要,对于很多应用开发来说也差不多,最多也是先看看用户态即可。但是出于对技术的追求还是在通过看书和阅读源码学习。书的话主要是看了下边本,其他乱七八糟的还有一些不列举了:深入Linux内核架构这本可能不是那么经典,看这本的原因是网上找到了高清的PDF书籍,于是就画时间看了,结论是非常不错,我很多内核的
我正在尝试向Kernel添加一个方法模块,而不是重新打开Kernel并直接定义一个实例方法,我正在编写一个模块,我想要Kernel至extend/include那个模块。moduleTalkdefhelloputs"hellothere"endendmoduleKernelextendTalkend当我在IRB中运行它时:$helloNameError:undefinedlocalvariableormethod`hello'formain:Objectfrom(irb):12from/Users/JackC/.rvm/rubies/ruby-1.9.2-p290/bin/irb:16
在编写Rspec测试时,我经常对should_receive感到沮丧。我想知道是否有侵入性较小的替代方案。例如:describe"makingacake"doit"shouldusesomeothermethods"do@baker.should_receive(:make_batter)@baker.make_cakeendend对should_receive的调用是一个很好的描述,但它破坏了我的代码,因为should_receive通过屏蔽原始方法来工作,而make_cake除非make_batter实际上返回一些面糊,否则无法继续。所以我把它改成这样:@baker.should_
我在网上查了几个Ruby教程,他们似乎什么都用数组。那么如何在Ruby中实现以下数据结构呢?堆栈队列链表map组 最佳答案 (从评论中移出)好吧,通过限制堆栈或队列方法(push、pop、shift、unshift),数组可以是堆栈或队列。使用push/pop提供LIFO(后进先出)行为(堆栈),而使用push/shift或unshift/pop提供FIFO行为(队列)。map是hashes,和一个Set类已经存在。您可以使用类实现链表,但数组将使用标准数组方法提供类似于链表的行为。 关