目录
modbus是OSI模型第七层上的应用层报文传输协议。
modbus是一个请求/应答协议。并规定了相关的功能码。
modbus功能码是modbus请求应答PDU的元素。(PDU:协议数据单元)
modbus通信栈:

·
modbus网络体系结构示例 :
MODBUS 协议允许在各种网络体系结构内进行简单通信。
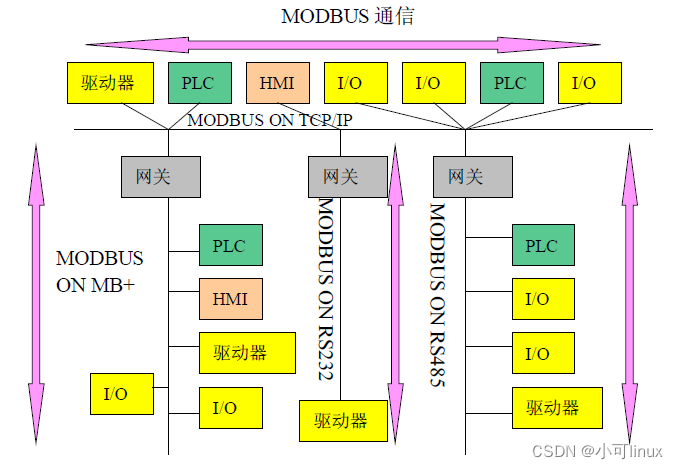
每种设备(PLC、HMI、控制面板、驱动程序、动作控制、输入/输出设备)都能使用MODBUS协议来启动远程操作。
在基于串行链路和以太TCP/IP 网络的MODBUS上可以进行相同通信。
modbus帧:

主/从站通信时序图:

有两种串行传输模式被定义: RTU 模式和 ASCII 模式。
所有设备必须必须实现RTU 模式。
当设备使用RTU (Remote Terminal Unit) 模式在Modbus 串行链路通信, 报文中每个8位字节含
有两个4 位十六进制字符。这种模式的主要优点是较高的数据密度,在相同的波特率下比ASCII 模
式有更高的吞吐率。每个报文必须以连续的字符流传送。
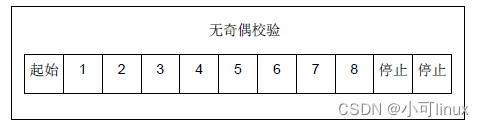
RTU 模式每个字节( 11 位 ) 的格式为 :
编码系统: 8–位二进制
报文中每个8 位字节含有两个4 位十六进制字符(0–9, A–F)
Bits per Byte: 1 起始位
8 数据位, 首先发送最低有效位
1 位作为奇偶校验
1 停止位
默认校验位模式必须位偶校验
RTU模式位序列:

RTU模式位序列(无校验的特殊情况):
RTU帧描述:

CRC(循环冗余校验)
modbus RTU帧最大256个字节。
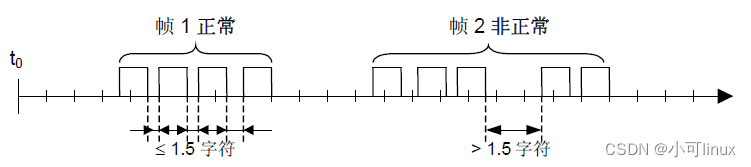
由发送设备将Modbus 报文构造为带有已知起始和结束标记的帧。这使设备可以在报文的开始接收新帧,并且知道何时报文结束。不完整的报文必须能够被检测到而错误标志必须作为结果被设置。在 RTU 模式,报文帧由时长至少为3.5 个字符时间的空闲间隔区分。在后续的部分,这个时间区间被称作t3.5。


整个报文帧必须以连续的字符流发送。
如果两个字符之间的空闲间隔大于1.5 个字符时间,则报文帧被认为不完整应该被接收节点丢弃。
RTU传输状态图:

上面状态图的一些解释:
§ 从 "初始" 态到 “空闲” 态转换需要t3.5 定时超时: 这保证帧间延迟
§ “空闲” 态是没有发送和接收报文要处理的正常状态。
§ 在RTU 模式, 当没有活动的传输的时间间隔达3.5 个字符长时,通信链路被认为在“空闲”
态。
§ 当链路空闲时, 在链路上检测到的任何传输的字符被识别为帧起始。链路变为 "活动" 状态。
然后, 当链路上没有字符传输的时间间个达到t3.5 后,被识别为帧结束。
§ 检测到帧结束后,完成CRC 计算和检验。然后,分析地址域以确定帧是否发往此设备,如果不
是,则丢弃此帧。为了减少接收处理时间,地址域可以在一接到就分析,而不需要等到整个帧
结束。这样,CRC 计算只需要在帧寻址到该节点(包括广播帧) 时进行。
在RTU 模式包含一个对全部报文内容执行的,基于循环冗余校验 (CRC - Cyclical RedundancyChecking) 算法的错误检验域。CRC 域检验整个报文的内容。不管报文有无奇偶校验,均执行此检验。
CRC 包含由两个8 位字节组成的一个16 位值。
CRC 域作为报文的最后的域附加在报文之后。计算后,首先附加低字节,然后是高字节。CRC高字节为报文发送的最后一个子节。
附加在报文后面的CRC 的值由发送设备计算。接收设备在接收报文时重新计算CRC 的值,
并将计算结果于实际接收到的CRC 值相比较。如果两个值不相等,则为错误。
CRC 的计算, 开始对一个16 位寄存器预装全1。然后将报文中的连续的8 位子节对其进行后
续的计算。只有字符中的8个数据位参与生成CRC 的运算,起始位,停止位和校验位不参与CRC
计算。
CRC 的生成过程中, 每个 8–位字符与寄存器中的值异或。然后结果向最低有效位(LSB)方向
移动(Shift) 1位,而最高有效位(MSB)位置充零。然后提取并检查LSB:如果LSB 为1, 则寄存
器中的值与一个固定的预置值异或;如果LSB 为 0, 则不进行异或操作。
这个过程将重复直到执行完8 次移位。完成最后一次(第8 次)移位及相关操作后,下一个8
位字节与寄存器的当前值异或,然后又同上面描述过的一样重复8 次。当所有报文中子节都运算之
后得到的寄存器忠的最终值,就是CRC。
帧结构 = 地址(设备ID) + 功能码 + 数据 + 校验
地址:占1个字节,范围0~255,有效范围1~247,其他特殊用途 如255为广播地址。
功能码:占1个字节。功能码是modbus协议定的。是modbus编程两个重要的概念之一(另一个是字符间隔1.5T—判断帧是否完整,字符间隔大于3.5T视为帧结束。),不同的功能码,后面数据格式也不同,从机返回的帧格式也不同。
数据:见后面示例。
校验:CRC校验值。
备注:读线圈返回数据时,1个字节表示8个线圈状态。
比如线圈地址0001-0008这一部分的状态ON-ON-ON-OFF-ON-ON-OFF-OFF,等价11101100。二进制表示为00110111,16进制为0x37.
Modbus常用功能码:
| 代码 | 名称 | 寄存器PLC地址 | 位/字操作 | 操作数量 |
| 01 | 读线圈状态 | 00001~09999 | 位操作 | 单个或多个 |
| 02 | 读离散输入状态 | 10001~19999 | 位操作 | 单个或多个 |
| 03 | 读保持寄存器 | 40001~49999 | 字操作 | 单个或多个 |
| 04 | 读输入寄存器 | 30001~39999 | 字操作 | 单个或多个 |
| 05 | 写单个线圈 | 00001~09999 | 位操作 | 单个 |
| 06 | 写单个保持寄存器 | 40001~49999 | 字操作 | 单个 |
| 15 | 写多个线圈 | 00001~09999 | 位操作 | 多个 |
| 16 | 写多个保持寄存器 | 40001~49999 | 字操作 | 多个 |
线圈寄存器:实际上就可以类比为开关量(继电器状态),每一个bit对应一个信号的开关状态。所以一个byte就可以同时控制8路的信号。比如控制外部8路io的高低。 线圈寄存器支持读也支持写,写在功能码里面又分为写单个线圈寄存器和写多个线圈寄存器。对应上面的功能码也就是:0x01 0x05 0x0f
离散输入寄存器:如果线圈寄存器理解了这个自然也明白了。离散输入寄存器就相当于线圈寄存器的只读模式,他也是每个bit表示一个开关量,而他的开关量只能读取输入的开关信号,是不能够写的。比如我读取外部按键的按下还是松开。所以功能码也简单就一个读的 0x02
保持寄存器:这个寄存器的单位不再是bit而是两个byte,也就是可以存放具体的数据量的,并且是可读写的。一般对应参数设置,比如我我设置时间年月日,不但可以写也可以读出来现在的时间。写也分为单个写和多个写,所以功能码有对应的三个:0x03 0x06 0x10
输入寄存器:这个和保持寄存器类似,但是也是只支持读而不能写,一般是读取各种实时数据。一个寄存器也是占据两个byte的空间。类比我我通过读取输入寄存器获取现在的AD采集值。对应的功能码也就一个 0x04。
(名词解释来源:https://blog.csdn.net/lingshi75/article/details/105991450/)
主机发送:01 01 00 01 00 08 6C 0C
从机回复: 01 01 01 2F 10 54
主机解析:01 地址(设备ID);
01 功能码;
00 01 代表查询的起始线圈地址,即从0001线圈开始查询。
00 08 查询线圈数量。
6C 0C 循环冗余校验。
从机解析:01 地址(设备ID);
01 功能码;
01 代表后面数据的字节数。
2F 读取以0001线圈开始的8个线圈的状态。0x2F二进制为00101111,对应状态为1111 0100
10 54 循环冗余校验。
功能:读离散输入寄存器,位操作,可读单个或多个,类似功能码0X01
主机发送:01 03 00 01 00 01 D5 CA
从机回复: 01 03 02 00 01 79 84
主机解析:01 地址(设备ID);
03 功能码;
00 01 代表查询的起始寄存器地址,即从0001寄存器开始查询。
00 01 查询寄存器数量。
D5 CA 循环冗余校验。
从机解析:01 地址(设备ID);
03 功能码;
02 代表后面数据的字节数。
00 01 查询0001寄存器的值。
79 84 循环冗余校验。
功能:读输入寄存器,字节操作,可读单个或多个,类似功能码0X03
功能:对单个线圈进行写操作,位操作,只能写一个。写入0xFF00表示将线圈置为ON,写入0x0000表示将线圈置为OFF,其它值无效;
主机发送数据:从站地址+功能码+寄存器起始地址+数据值+校验码
从站应答数据:从站地址+功能码+寄存器地址+写入值+校验码
主机发送:01 06 00 02 00 01 E9 CA
从机回复: 01 06 00 02 00 01 E9 CA
主机解析:01 地址(设备ID);
06 功能码;
00 02 代表待写入的起始寄存器地址,即从0002寄存器开始写数据。
00 01 写入的寄存器的值。即给0002寄存器写入0001
E9 CA 循环冗余校验。
从机解析:01 地址(设备ID);
06 功能码;
02 代表后面数据的字节数。
00 01 查询0001寄存器的值。
E9 CA 循环冗余校验。
主机发送:01 0F 00 01 00 07 01 6B B2 B9
从机回复: 01 0F 00 01 00 07 45 C9
主机解析:01 地址(设备ID);
0F 功能码;
00 01 代表待写入的起始线圈地址,即从0001线圈开始写数据。
00 07 待写入的线圈的数量。
01 后面写入数据的字节数。
6B写入寄存器的值,即11010110。二进制01101011
B2 B9 循环冗余校验。
从机解析:01 地址(设备ID);
0F 功能码;
00 01 代表待写入的起始线圈地址,即从0001线圈开始写数据。
00 07 待写入的线圈的数量。
45 C9 循环冗余校验。
主机发送:01 10 00 04 00 03 06 00 01 00 00 00 01 5B 55
从机回复: 01 10 00 04 00 03 C1 C9
主机解析:01 地址(设备ID);
10 功能码;
00 04 代表待写入的起始寄存器地址,即从0004寄存器开始写数据。
00 03 待写入的寄存器的数量。
06 后面写入数据的字节数。
0001,0000,0001写入寄存器的值。即给0004,0005,0006寄存器分别写入0001,0000,0001
5B 55 循环冗余校验。
从机解析:01 地址(设备ID);
10 功能码;
00 04 代表待写入的起始寄存器地址,即从0004寄存器开始写数据。
00 03 待写入的的寄存器的值。即给0004,0005,0006寄存器分别写入0001,0000,0001
C1 C9 循环冗余校验。
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
我正在使用ruby2.1.0我有一个json文件。例如:test.json{"item":[{"apple":1},{"banana":2}]}用YAML.load加载这个文件安全吗?YAML.load(File.read('test.json'))我正在尝试加载一个json或yaml格式的文件。 最佳答案 YAML可以加载JSONYAML.load('{"something":"test","other":4}')=>{"something"=>"test","other"=>4}JSON将无法加载YAML。JSON.load("
我想用Nokogiri解析HTML页面。页面的一部分有一个表,它没有使用任何特定的ID。是否可以提取如下内容:Today,3,455,34Today,1,1300,3664Today,10,100000,3444,Yesterday,3454,5656,3Yesterday,3545,1000,10Yesterday,3411,36223,15来自这个HTML:TodayYesterdayQntySizeLengthLengthSizeQnty345534345456563113003664354510001010100000344434113622315
我使用的第一个解析器生成器是Parse::RecDescent,它的指南/教程很棒,但它最有用的功能是它的调试工具,特别是tracing功能(通过将$RD_TRACE设置为1来激活)。我正在寻找可以帮助您调试其规则的解析器生成器。问题是,它必须用python或ruby编写,并且具有详细模式/跟踪模式或非常有用的调试技术。有人知道这样的解析器生成器吗?编辑:当我说调试时,我并不是指调试python或ruby。我指的是调试解析器生成器,查看它在每一步都在做什么,查看它正在读取的每个字符,它试图匹配的规则。希望你明白这一点。赏金编辑:要赢得赏金,请展示一个解析器生成器框架,并说明它的
在Rails自动生成的功能测试(test/functional/products_controller_test.rb)中,我看到以下代码:classProductsControllerTest我的问题是:方法调用products()在哪里/如何定义?products(:one)到底是什么意思?看代码,大概意思是“创建一个产品”,但是它是如何工作的呢?注意我是Ruby/Rails的新手,如果这些是微不足道的问题,我深表歉意。 最佳答案 如果您查看test/fixtures文件夹,您会看到一个products.yml文件。这是在您创建