Elasticsearch之Mapping详解
Mapping类似于数据库中的表定义,主要有以下几个作用:
Mapping设置会把JSON文档映射成Lucence所需要的扁平格式。
es7.0开始,一个索引只能有一个type,所以就可以说Mapping属于索引的type,每个文档都属于一个Type,每个Type都有一个Mapping。听起来好像很难理解,我们接着看。
简单类型
复杂类型:对象类型、嵌套类型
特殊类型:geo_point 、geo_shape、percolator等
什么是Dynamic Mapping? 它主要有以下几个作用:
| JSON类型 | ES类型 |
|---|---|
| 字符串 | 匹配日期,设置为Date。匹配数字,设置为float或者long(默认关闭)。会为字符串类型设置为Text,并增加keyword子字段。 |
| 布尔值 | boolean |
| 浮点数 | float |
| 整数 | long |
| 对象 | Object |
| 数组 | 有第一个非空数值的类型所决定 |
| 空 | 忽略 |
例子:我们新创建一个索引,不指定mapping,写入一个文档,查看ES为我们自动生成的mapping。
查看mapping:get index/_mapping
put index
put index/_doc/1
{
"firstName":"程",
"lastName":"大帅",
"date":"2021-12-01T00:00:00.000Z",
"age":18,
"isvid":true
}
-------------------------------------
{
"index" : {
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"date" : {
"type" : "date"
},
"firstName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"isvid" : {
"type" : "boolean"
},
"lastName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
可以看到时间格式的字段,es为我们转成了date类型,age转成了数字,字符串为我们设置了text字段和子类型keyword,布尔值自动映射为boolean类型。
上述示例我们可以看到,新建一个索引并插入文档后,ES会自动帮我们生成一个mapping,有时候自动生成的mapping字段格式并不是我们想要的,那么能否对mapping设置进行修改呢?
两种情况:
ES的搜索基于Lucene,倒排索引一旦生成之后,就不允许被修改如果希望改变已有数据的字段类型,必须重建索引 ReindexES之所以有上述规则,是因为如果字段的数据类型能够被随意更改,那么就会导致倒排索引的紊乱,影响到搜索,甚至无法被搜索。
但是如果时新增加的字段,相应的字段数据并不存在,则不会有这样的影响
我们可以在创建索引的时候指定Dynamic
PUT index
{
"mappings":{
"dynamic":"false"
}
}
也可以对索引mapping的dynamic属性进行修改
PUT index/_doc/_mapping?include_type_name=true
{
"dynamic":"false"
}
Dynamic有三个值可以设置:true、false、strict
设置为true时:文档可索引、字段可索引、mapping允许被更新。
设置为false时:文档可索引、字段不可索引、mapping不允许被更新。
设置为true时:文档不可索引、字段不可索引、mapping不允许被更新。
其实对于实际开发过程中,我们有一些小诀窍来减少创建mapping的工作量。
在我们设定一个mapping文件的时候,可以显示的指定某些字段不被可以被搜索。
比如我设置了firstname字段的index为false。
PUT index/_doc/_mapping?include_type_name=true
{
"dynamic":"false",
"properties":{
"age":{
"type":"long"
},
"date":{
"type":"date"
},
"firstName":{
"type":"text",
"index":false
},
"isvid":{
"type":"boolean"
},
"lastName":{
"type":"text"
}
}
}
---------------------------------------
get index/_search
{
"query":{
"match":{
"firstName":"程"
}
}
}
"status" : 400
failed to create query: Cannot search on field [firstName] since it is not indexed.
当我们对设置了"index":false的字段进行搜索的时候,直接报错400。
索引配置(Index Options):可以控制倒排索引记录的内容。记录的内容越多,所占用的存储空间就越大。不同的索引配置也可以达到性能优化的目的。
记录doc id记录doc id +(term出现频率)term frequencies记录 doc id +(term出现频率)term frequencies + (term所在语句位置)term position记录 doc id +(term出现频率)term frequencies + (term所在语句位置)term position + (词条所在的偏移量)character offsets示例:
PUT index/_doc/_mapping?include_type_name=true
{
"dynamic":"false",
"properties":{
"age":{
"type":"long"
},
"date":{
"type":"date"
},
"firstName":{
"type":"text",
"index":false
},
"isvid":{
"type":"boolean"
},
"lastName":{
"type":"text"
"index_options":"offsets"
}
}
}
有时候我们插入的文档,某些字段是null,但是需求需要对其进行搜索,那么我们就可以给字段指定"null_value:"xxx"",搜索时让字段匹配xxx即可搜索到null值。
注意:只有keyword类型支持null_value
PUT index2
{
"mappings":{
"properties":{
"date":{
"type":"date"
},
"firstName":{
"type":"keyword",
"null_value":"N"
},
"lastName":{
"type":"text"
}
}
}
}
--------------------
GET index2/_search
{
"query":{
"match":{
"firstName":"N"
}
}
}
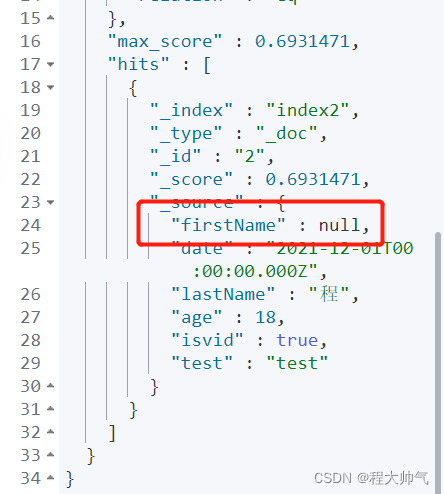
copy to可以满足一些特定的搜索需求,它的作用是:将多个字段的数据拷贝到目标字段中,目标字段可以用于搜索,拷贝字段不在_source中保存。
PUT index
{
"mappings":{
"properties":{
"firstName":{
"type":"text",
"copy_to":"fullName"
},
"lastName":{
"type":"text",
"copy_to":"fullName"
}
}
}
}
---------------------------
put index/_doc/1
{
"firstName":"程",
"lastName":"大帅"
}
----我们就可以使用fullName进行搜索----
get index/_search
{
"query":{
"match":{
"fullName":"程"
}
}
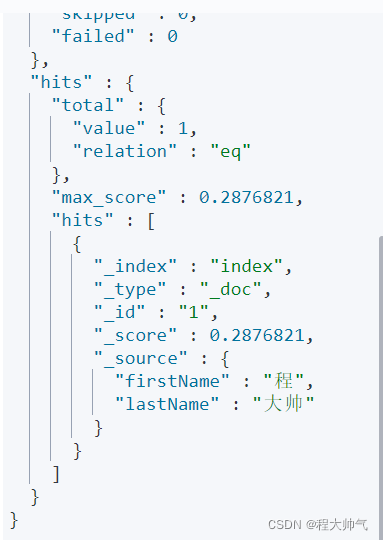
我们get index/_mapping看一下,可以看到fullName被放进mapping内,但是搜索结果的_source中是没有这个字段的
{
"index" : {
"mappings" : {
"properties" : {
"firstName" : {
"type" : "text",
"copy_to" : [
"fullName"
]
},
"fullName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"lastName" : {
"type" : "text",
"copy_to" : [
"fullName"
]
}
}
}
}
}
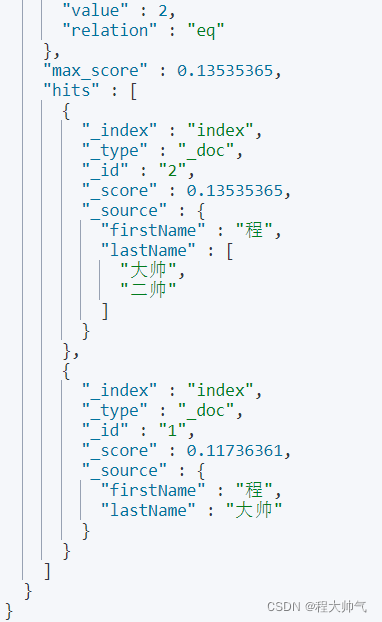
ES中不提供专门的数组类型。任何字段都可以包含多个相同字段的数据。
比如还是上面创建的索引,我现在将 程二帅 也想保存到ES中,就可以这样写。
put index/_doc/2
{
"firstName":"程",
"lastName":["大帅","二帅"]
}
----------------------------
get index/_search
{
"query":{
"match":{
"fullName":"帅"
}
}
}
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我在使用omniauth/openid时遇到了一些麻烦。在尝试进行身份验证时,我在日志中发现了这一点:OpenID::FetchingError:Errorfetchinghttps://www.google.com/accounts/o8/.well-known/host-meta?hd=profiles.google.com%2Fmy_username:undefinedmethod`io'fornil:NilClass重要的是undefinedmethodio'fornil:NilClass来自openid/fetchers.rb,在下面的代码片段中:moduleNetclass
我正在查看instance_variable_set的文档并看到给出的示例代码是这样做的:obj.instance_variable_set(:@instnc_var,"valuefortheinstancevariable")然后允许您在类的任何实例方法中以@instnc_var的形式访问该变量。我想知道为什么在@instnc_var之前需要一个冒号:。冒号有什么作用? 最佳答案 我的第一直觉是告诉你不要使用instance_variable_set除非你真的知道你用它做什么。它本质上是一种元编程工具或绕过实例变量可见性的黑客攻击
我想设置一个默认日期,例如实际日期,我该如何设置?还有如何在组合框中设置默认值顺便问一下,date_field_tag和date_field之间有什么区别? 最佳答案 试试这个:将默认日期作为第二个参数传递。youcorrectlysetthedefaultvalueofcomboboxasshowninyourquestion. 关于ruby-on-rails-date_field_tag,如何设置默认日期?[rails上的ruby],我们在StackOverflow上找到一个类似的问
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
我在Rails应用程序中使用CarrierWave/Fog将视频上传到AmazonS3。有没有办法判断上传的进度,让我可以显示上传进度如何? 最佳答案 CarrierWave和Fog本身没有这种功能;你需要一个前端uploader来显示进度。当我不得不解决这个问题时,我使用了jQueryfileupload因为我的堆栈中已经有jQuery。甚至还有apostonCarrierWaveintegration因此您只需按照那里的说明操作即可获得适用于您的应用的进度条。 关于ruby-on-r
我正在尝试为我的iOS应用程序设置cocoapods但是当我执行命令时:sudogemupdate--system我收到错误消息:当前已安装最新版本。中止。当我进入cocoapods的下一步时:sudogeminstallcocoapods我在MacOS10.8.5上遇到错误:ERROR:Errorinstallingcocoapods:cocoapods-trunkrequiresRubyversion>=2.0.0.我在MacOS10.9.4上尝试了同样的操作,但出现错误:ERROR:Couldnotfindavalidgem'cocoapods'(>=0),hereiswhy:U
我正在构建一个应用程序,想知道是否将未使用的对象设置为nil是生产级编码中的常见做法。我知道这只是垃圾收集器的提示,并不总是处理对象。 最佳答案 根据这个thread如果您使用完一个成员对象,将其设置为nil将引发被引用对象被垃圾回收。如果它是局部变量,方法exit将做同样的事情。也就是说,如果您要求将成员显式设置为nil,我会质疑您的设计。 关于ruby-将对象设置为nil是否很常见?,我们在StackOverflow上找到一个类似的问题: https://
我正在关注Hartl的railstutorial.org并已到达11.4.4:Imageuploadinproduction.我做了什么:注册亚马逊网络服务在AmazonIdentityandAccessManagement中,我创建了一个用户。用户创建成功。在AmazonS3中,我创建了一个新存储桶。设置新存储桶的权限:权限:本教程指示“授予上一步创建的用户读写权限”。但是,在存储桶的“权限”下,未提及新用户名。我只能在每个人、经过身份验证的用户、日志传送、我和亚马逊似乎根据我的名字+数字创建的用户名之间进行选择。我已经通过选择经过身份验证的用户并选中了上传/删除和查看权限的框(而不
使用Paperclip,我想从这样的URL抓取图像:require'open-uri'user.photo=open(url)问题是我最后得到一个像“open-uri20110915-4852-1o7k5uw”这样的文件名。有什么方法可以更改user.photo上的文件名?作为一个额外的变化,Paperclip将我的文件存储在S3上,所以如果我可以在初始分配中设置我想要的文件名就更好了,这样图像就会上传到正确的S3key。像这样:user.photo=open(url),:filename=>URI.parse(url).path 最佳答案