🤔极狐GitLab 的 Securtiy Code Reviewer 是如何工作的?
近日,在极狐 TechTalk 直播上,极狐(GitLab) 资深后端工程师曹宝栋结合他的工作经验回答了这个问题,并通过极狐GitLab 历史上的一些 Bug 和漏洞修复经验,诠释了 Security Code Review 的作用和意义。
以下内容整理自本次分享,你也可以点击这里观看视频回放。enjoy~
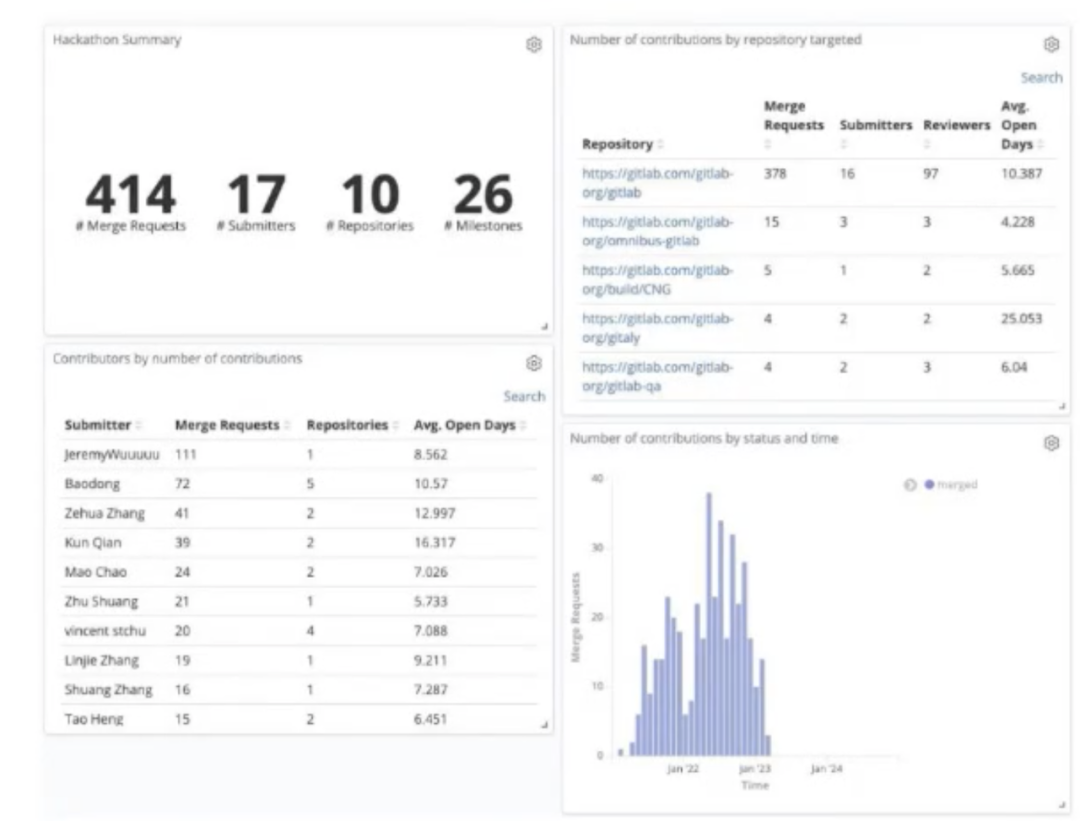
大家好!首先分享一下我在极狐GitLab 的一些工作成果数据:
在极狐GitLab repo 下,贡献 MR 90+ 个;
参与 Code Review MR 200 + 个。
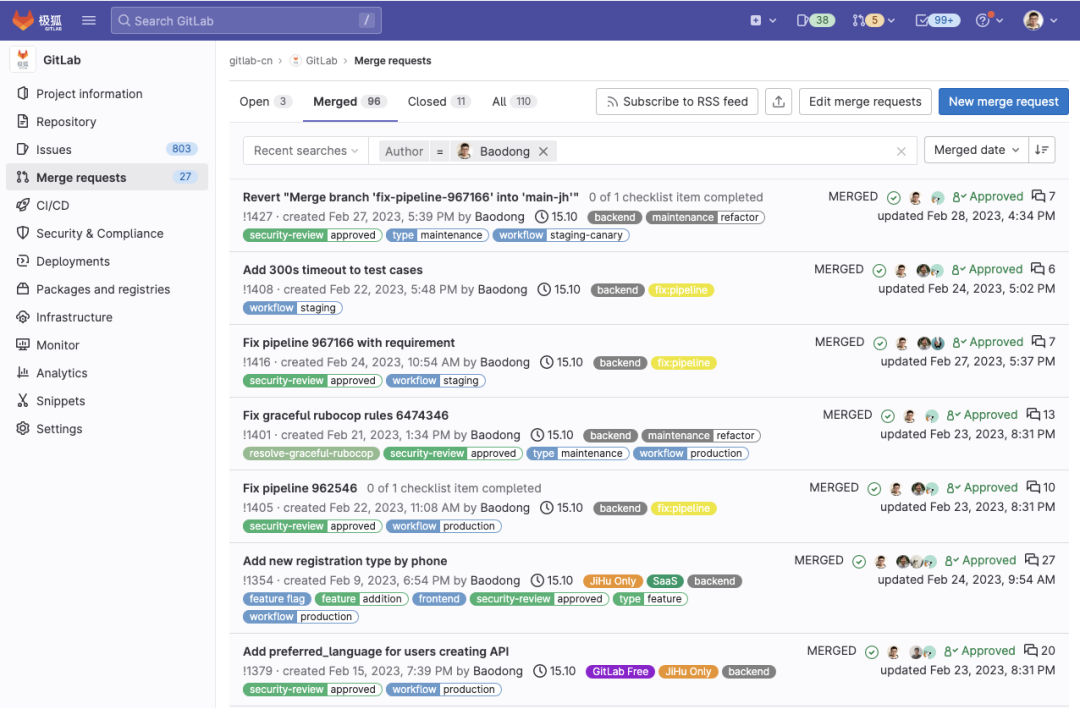
下图展示的是极狐GitLab 成立至今,为 GitLab Inc. 所贡献的 MR 的数量:极狐GitLab 团队所贡献的 MR 数量目前居全球第二,仅次于 GitLab Inc. 团队;其中我个人贡献数量是 72 个,涉及 5 个不同 repo,核心 repo 是 GitLab。
今天分享的内容也是从这些实际开发工作出发,向大家介绍作为极狐GitLab 的 Securtiy Code Reviewer,我是如何工作的,并结合极狐GitLab 历史上的一些 Bug 和漏洞修复,来看一下 Securtiy Code Review 关注重点是哪些。
毋庸置疑,安全是很重要的话题,与研发相关的任何一个环节都有可能暴露安全风险。产品功能越丰富,相对应的安全风险面越大。
并且,随着越来越多的企业和团队都采用敏捷研发风格,习惯小步快跑,可能一天就发布好几次,每次迭代所对应的更新,都有可能引入 Bug 或者安全漏洞。
因此 Securtiy Code Review 的重要性不言而喻。极狐GitLab 作为一体化安全 DevOps 平台,将「安全」提到了高优先级,帮助用户安全、高效地交付软件。从极狐GitLab 的功能矩阵上也可以看出来,「安全」这一栏占据着非常重要的位置。
但是安全这个话题实在是太大了,今天我们先侧重分享如何在开发过程中,提高安全意识,尽量减少开发功能所暴露的安全隐患。
在极狐GitLab 工作流中,提交的每个 MR 都需要经过 Code Review,进行代码风格或功能实现方面的评审。
当一个 Code Reviewer 提交了 Approve 之后:
1. 机器人会提醒 Security Code Reviewer 进行安全审查;
2. Security Code Reviewer 安全审查通过之后,才会交给 Maintainer 进行 Merge 评审;
3. Maintainer 完成最后的 Merge 评审,才进行合并。
也就是说一个 MR 经过至少三道评审才会合并,确保了代码质量与代码安全。
下面我们通过一些实例回顾,看一下从这些安全事故身上,我们能总结出什么经验教训。
说到研发安全事故,不得不提密码泄露,数据库数据被泄露已经是非常严重的事故了,如果数据库中存储的用户明文密码被泄露,可能导致用户在其他平台上的账号也蒙受风险,会给企业和用户造成很大的伤害和损失。
这里有一个背景,即使产品平台有密码复杂度的门槛,但还是有很多用户习惯使用简单的、容易被猜到的密码组合,甚至在不同的平台上使用相同的密码。
作为开发者,我们很难改变这样的现实,我们能做的是最大程度降低一旦发生数据泄露所导致的损失。
首先,我们来看看,验证密码的原理。
用户登录系统时,其实开发者不需要知道用户设置的原始密码的明文是什么,只需要知道在登录过程中,输入的密码与设置的密码是否一致。很自然的,我们就想到了使用摘要算法,摘要算法特点是不可逆的,即只能从数据计算到摘要,不能从摘要反推回数据本身。

用户输入密码后,把密码摘要哈希值存到数据库,下次认证时,使用相同的算法再算一次,比较两次哈希值是否一致,就能判断输入的密码是否正确了。
最常见的比如 MD5 这样的算法,对于相同的字符串它总是能得到相同的摘要值,它的优点是很稳定,性能很好,算得很快。但对于存储密码这样的具体场景来说,反而成了一个致命缺点,因为黑客可以用很小的成本,提前准备好字符串到摘要的映射。
除了 MD5 ,实际生产中还可能会用到其他算法,黑客需要先探测一下系统使用的是哪一种算法。常用的其实也不过几种,做一下取样就可以轻易探测出所使用的算法,或者说已经能读到代码源码了,那么黑客就可以直接去代码里查看所使用的算法。下一步黑客就可以根据已经知道的算法,准备相应的明文到哈希值的映射关系,这也就是我们俗称的彩虹表。
为了应对预先准备好的彩虹表,我们需要给密码做一些处理,比如在用户输入的密码的基础上做一些拼接,再去做摘要算法,这也就是「密码加盐」,加盐的值一般是硬编码或者保存在环境变量里,如果这个值也被泄露了,黑客也很容易根据盐的值重新再生成一份彩虹表。
于是,我们就想是不是应该给每一个用户分配不一样的盐值,这样就会大大提高黑客的破解成本,因为他需要给每个用户都重新生成一份新的彩虹表,这是非常耗费时间和存储空间的。
前文说到了 MD5,或者类似的摘要算法都有很高的效率,这是一个算法本身的优点,但是我们并不希望黑客在破解的过程中也算这么快,如果能提高每次计算的计算成本,那么就会让黑客破解的总成本变得非常大。
综合以上所述,Bcrypt 就是一个非常合适的算法。

它由这 4 个部分构成:
1. 算法,它有很多备选的算法可以选,对于每一个密码来说,有可能算法取样都是不一样的,黑客进行破解的时候,要对每一个密码进行算法探测;
2. 计算成本,如图中 “12” 这个值对应的是计算成本,值越大,对于单个哈希计算的成本也就越大;
3. 盐,每个用户的盐都是不一样的;
4. 所对应的哈希值。
对于 Security Code Reviewer 来说,一定要做好算法选择,以及登录或者注册逻辑上的把关。除此之外,还需要一系列辅助功能的配合,比如:
1. 两步验证;
2. reCAPTCHA;
3. 对用户或 IP 的频率限制,包括如果发现账号在新的 IP 尝试登录,也会发出邮件告警等。
这些功能在极狐GitLab 都是支持的。
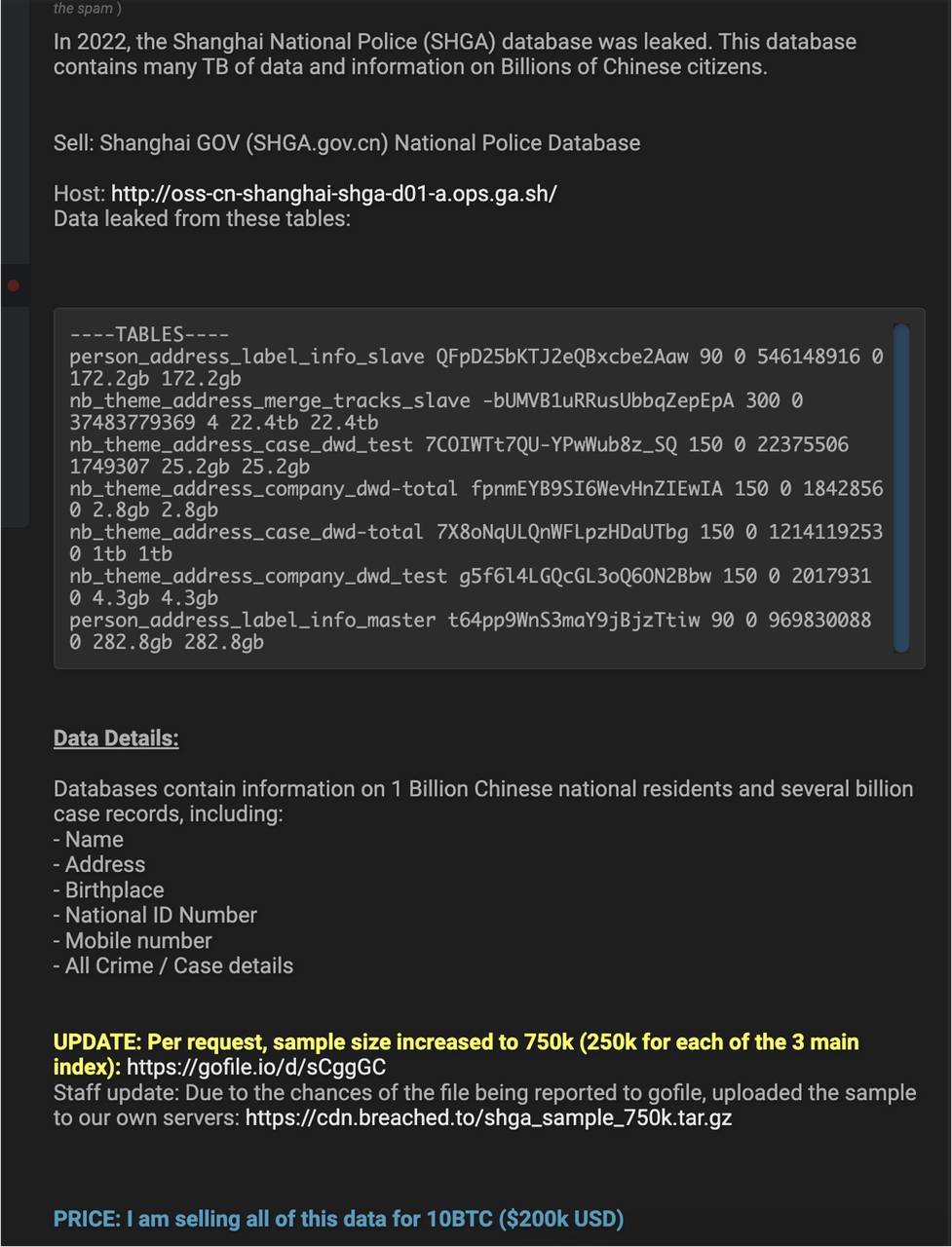
上图是一个黑客发的帖,号称要卖一个 billion 的数据,据说这个数据的来源是由于一位程序员在某平台上分享了自己的一个代码片段,这个代码片段包含了连接数据库所使用的 token,因此造成泄露。具体导致泄露的根本原因已无从考证,但是这个行为本身确实是非常危险的,而且确实有很多案例是因为 token 提交到了 Git 仓库中进而造成了巨大的损失。
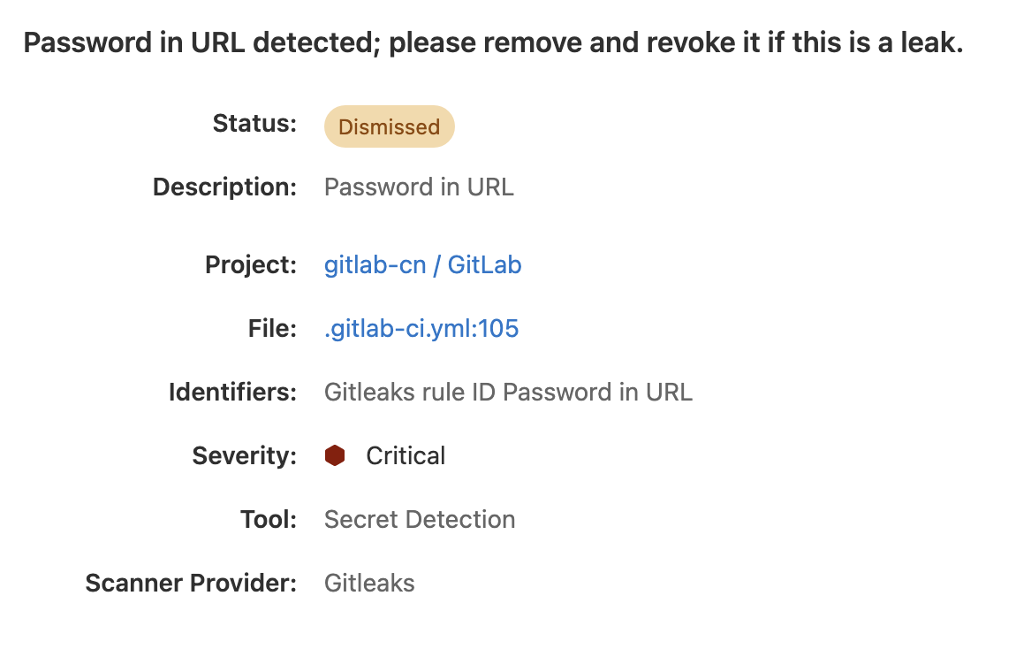
因此,Code Review 时需要特别注意这样的问题,但其实这是一个非常好识别的现象,而且极狐GitLab 支持对 Git 仓库进行扫描,一旦发现有泄露的风险,就会给出提示,下图就是具体例子:提示到在 yml 中, Elasticsearch 的 URL 可能会暴露出风险。
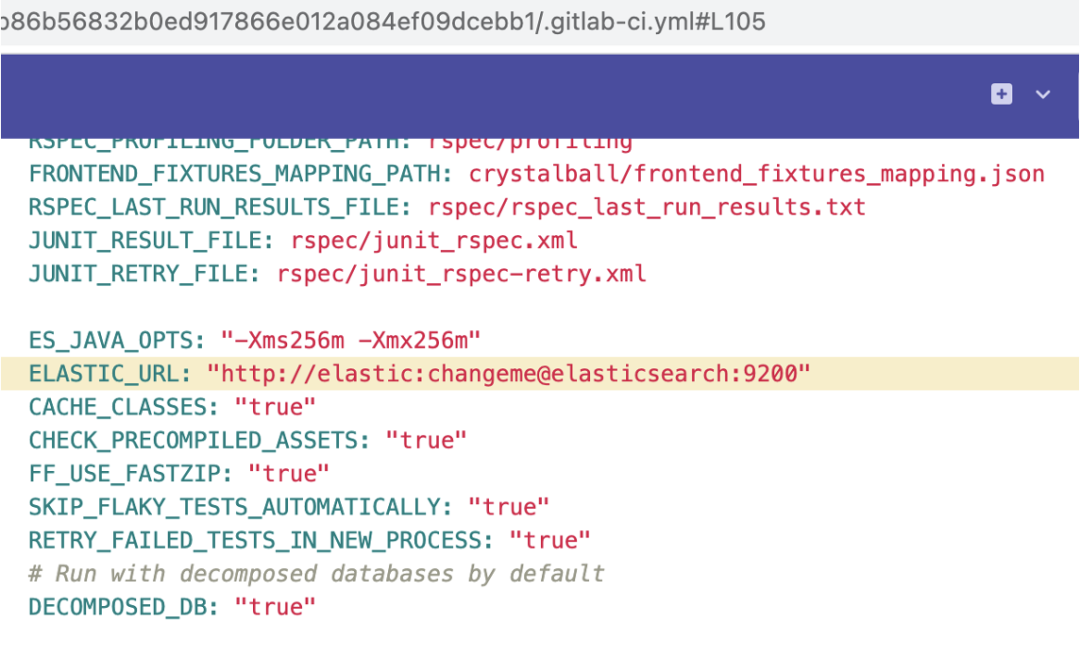
这样的提示对我们来说非常具有警示作用。如果我们能明确知道它不具有安全风险,可以在这个页面中把它取消,那么下一次就不会再次报警。
这背后的实现原理是通过 Gitleaks 这样的工具进行 SAST 扫描,扫描 Git 仓库里有安全风险的部分,比如 Passwords、API keys、或者 Tokens 等。它的使用方法非常简单:在极狐GitLab CI 的 yml 里面,include 该模板,后续的流水线就可以自动使用这个功能。

SQL 注入是 Reviewer 要特别关注的点,也是非常容易发生风险的点。

上图是一个简单例子,比如 ID 是10,如果我们去查询 ID 为 10 的 user,并且是自己手写的查询条件,会得到这样的 SQL,并得到相应的用户,这是理想情况。
但是如果我们真的这样写查询的话,黑客就很容易把 ID 部分进行扩展,然后提前关闭判断,这样就会造成 SQL 注入问题。本来只想查一个用户,但是通过这样的组装,可以查出一系列的用户,更可怕的是在检验权限的地方,如果黑客这样破坏了,就可以绕过你的权限判断,这是非常危险的。

上图中,比较危险的写法是在 where 里面,自己拼 condition 条件,或者直接使用 execute 方法执行裸 SQL 查询,或者 find_by_sql 这样的裸查询都非常危险。
正确的做法是尽量使用 Prepared SQL Statement,并且在复杂数据的时候进行数据校验。
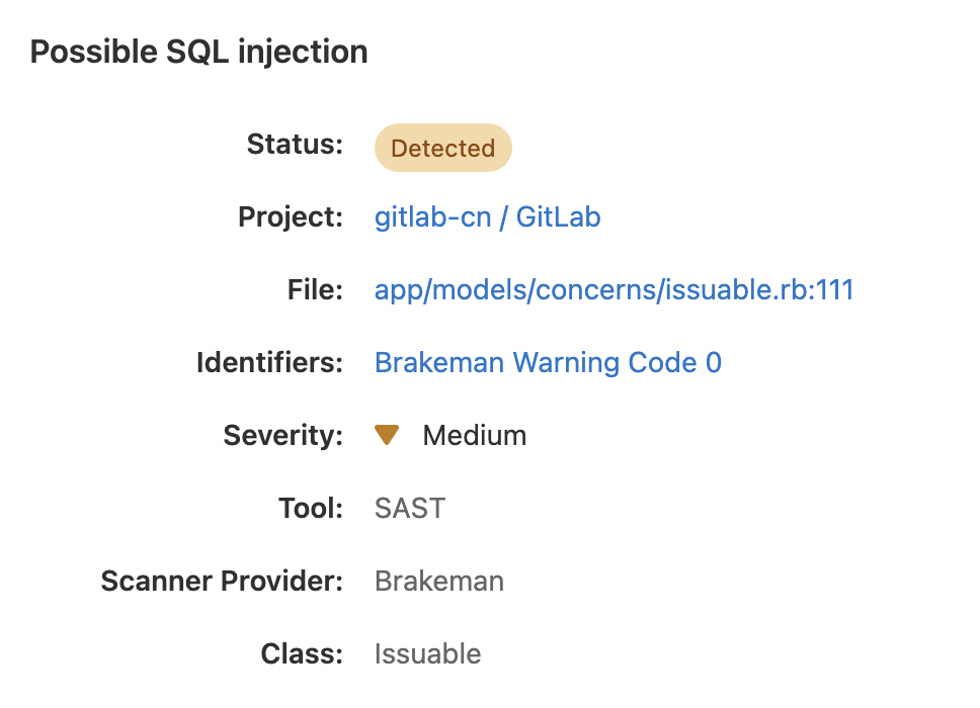
当然,极狐GitLab 也是有相应的工具支持—— SAST 工具,会报出相应的风险警告,比如下图,对于特殊的场景来说,确实需要手写一些 SQL 拼进去,组装成一个特殊的查询条件。这样虽然会被报警出来,但如果你能明确知道它是安全的,可以手动把它处理掉。
关于 SAST 分析工具, 极狐GitLab 有一系列支持,并且还在不断添加中,基本支持主流语言和框架。
还是以 Ruby 代码为例,如果我们的 Message 是一个字符串,我们想把这个字符串打印一下,如下图,它是一个正常的 Warning 输出,看起来好像没什么问题。

如果黑客想把报警信息掩盖掉,并且输出一个 Success 信息,他可以像下面这样自己手动拼接一个换行符进去,那么在 log 中就会多一行 Success信息,这对一般 log 来说可能没什么太大影响,但是对于需要对账的系统来说,就有可能导致对账出问题。

下面我们来看一个更危险的 CRLF 注入。这是一段 HTTP 协议。重点看一下空行,它分隔了 Header 和 Content,这里大家可以结合前面的例子,猜一下,黑客有什么办法来篡改?

是的,黑客可以借助 cookie 字段,提早让 Header 部分结束,再自己伪造一些新的 body 内容。
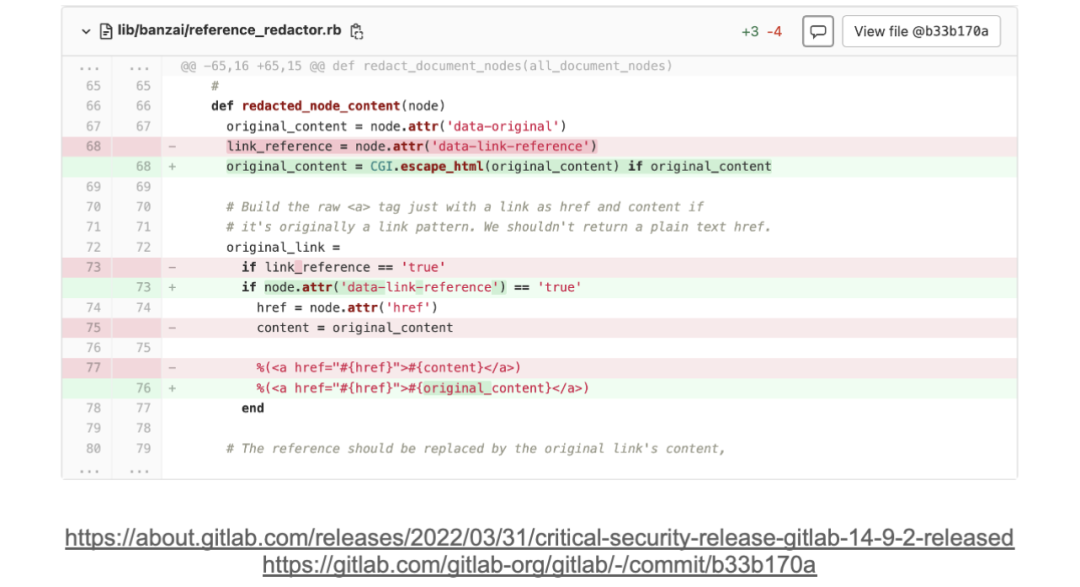
解决这个问题的办法其实很简单,如上图标绿位置,只需要把特殊情况处理一下就好了,极狐GitLab 需要做的就是升级到 PUMA 新版本。
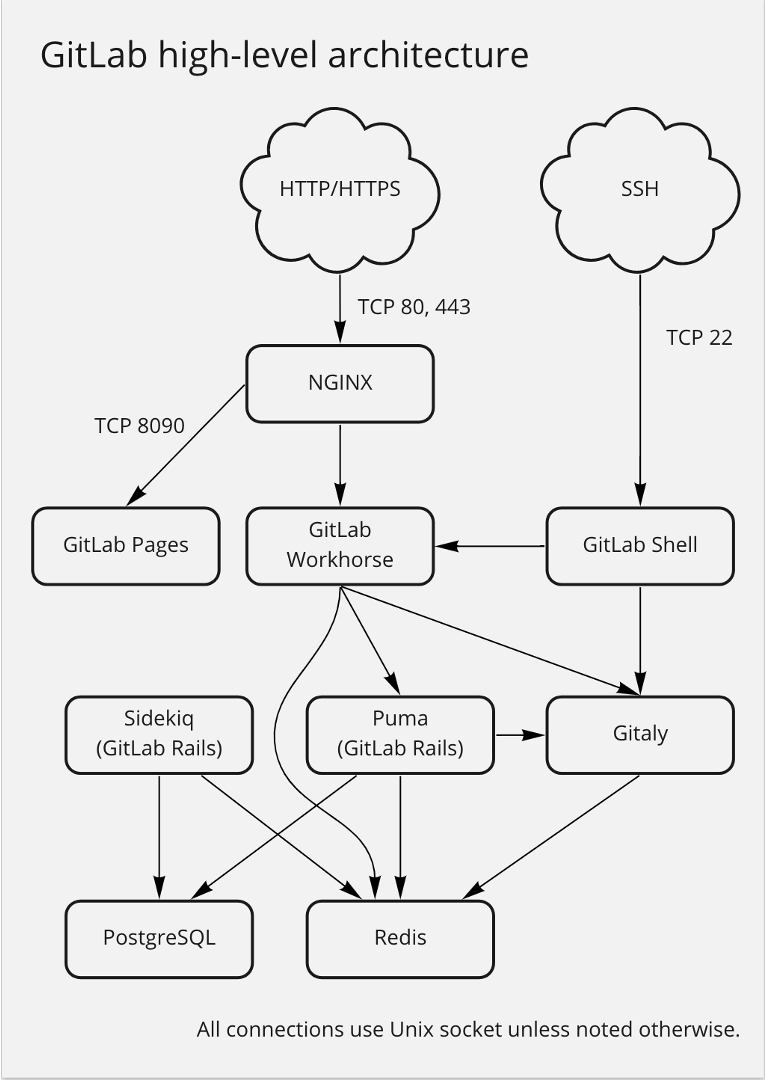
下图是一个简化的极狐GitLab 架构图。从下往上依次是:
底层:存储,包括数据库,Redis;
中间层:从左到右是Sidekiq,它是一个处理异步任务的工具;中间 PUMA 是 Web Server ;右边 Gitaly 是由 Golang 编写的处理 Git 请求的中间件;
上层:GitLab Pages,是一项独立服务用来处理处理 Pages 页面服务的;GitLab Workhorse 是漏洞的关键点,它是一个反向代理,或者说智能代理,它所做的事情就是进行分流,把大型请求比如文件处理、Git 请求等自己来处理,把动态请求交给 Rails 来处理,也就是中间层中的 PUMA 来处理。
那么,如果上传大文件会对极狐GitLab Workhorse 造成什么影响?
在 GitLab 的某一个老版本中会出现这样的现象:如果上传一个特别大的单个文件,它会让 Workhorse 的内存爆掉,导致整个 Workhorse 节点无法工作,这样,用户的所有 HTTP 请求都会被拒绝访问,造成整个节点不可用。
解决办法也是非常简单,就是识别出这样的异常文件,然后忽略它,并且给用户相应提示,如下图,从 CVE 的描述中,我们可以看到更多的细节,感兴趣的同学也可以点击 查看链接详情 。
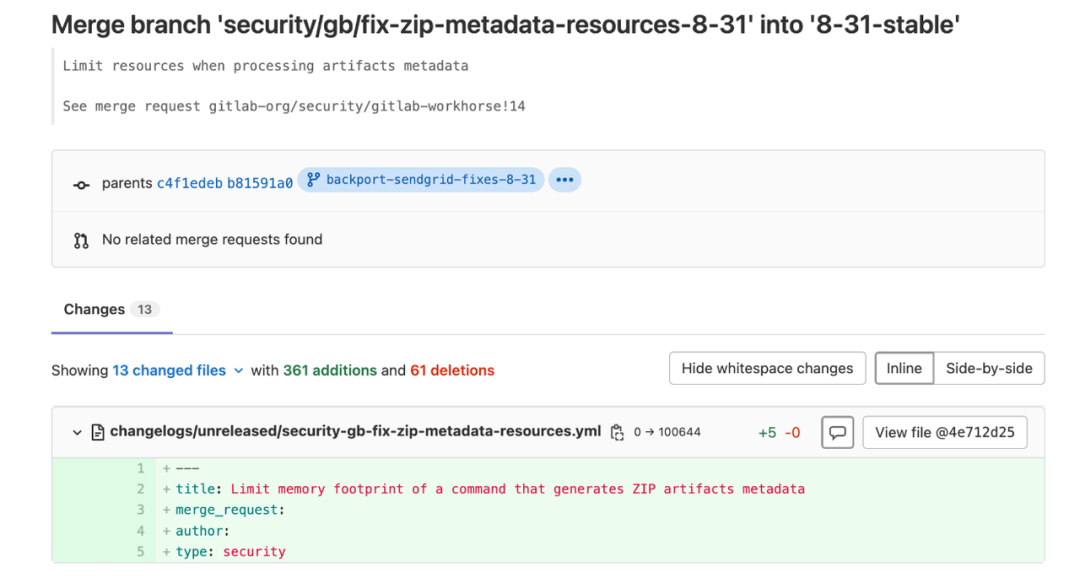
另外一个与 workhorse 相关的问题,是一个 RCE 问题,全称是远程代码执行 (Remote Code Execution)。

这个问题非常有意思,首先先介绍一下背景,有一个工具 ExifTool,它是开源的,用来处理多媒体文件的 meta 信息,它支持的文件非常多,包括主流的图片、视频、音频,PDF 等。其中还有一种比较少见的文件格式叫 DjVu,这是用来做复杂文本排版的一种文件格式。

上面左侧是一个 DjVu 的 meta 信息,右侧是黑客构建出来的一种特殊的 DjVu 的 meta 信息。即使你不知道他到底是怎么解析 meta 信息的,看起来也非常危险,好像是能执行起来,实际上确实是这样。
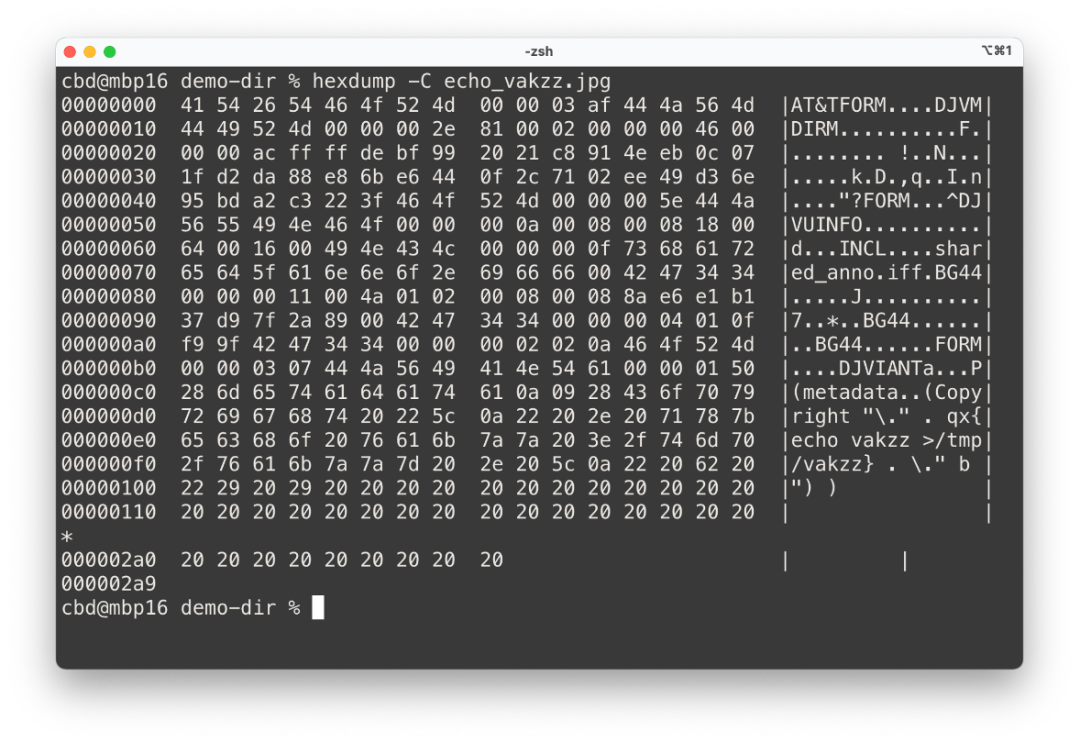
在上传图片时,Workhouse 会把所有图片都先做一次安全过滤,如果文件的 tag 不在白名单里,它就会把 tag 给移除掉,这个过程是通过 ExifTool 工具实现。
在 ExifTool 处理过程中,会忽略掉文件本身 .jpg/.png 这样的后缀,因为这个值用户可以随意修改,所以 ExifTool 不看这个,它是通过文件本身的真实内容去识别文件类型,从而再进行下一步处理。
在这个过程中,ExifTool 会把所有支持的文件格式全都做一次识别,包括上文介绍的 DjVu 格式。如果黑客构造出这样有问题的格式,可以达到一个非常危险的目的,就是把他所想要执行的命令埋在一个文件里,让这个文件去到 Server 机器上创建出一个文件,再执行起来。
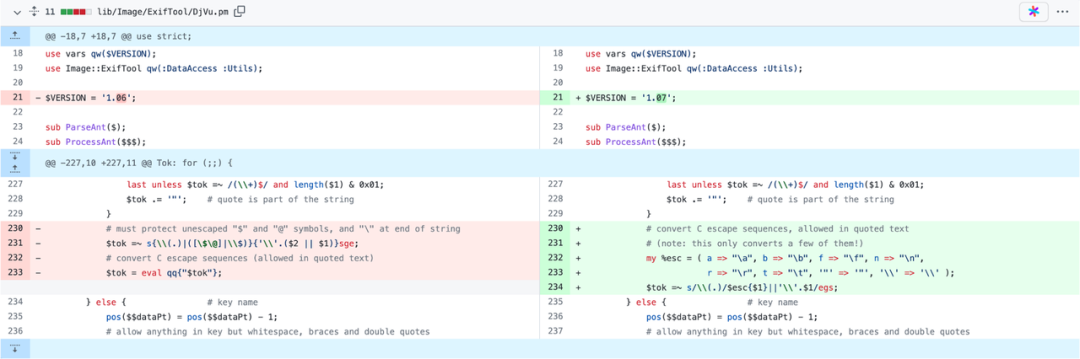
上图展示的是 ExifTool 这个工具如何修改 Bug。
极狐GitLab 做法是在处理有问题的格式之前,先做一次文件格式的检查,如果检查出有风险,就把它过滤掉。更多的细节我们可以 通过这个链接去查看。
XSS 漏洞是一种更广泛的漏洞。下图展示的是通过对 Milestone title 特殊构建,构建出来保存之后,如果新的用户也过来查看页面,就会产生 XSS 攻击。
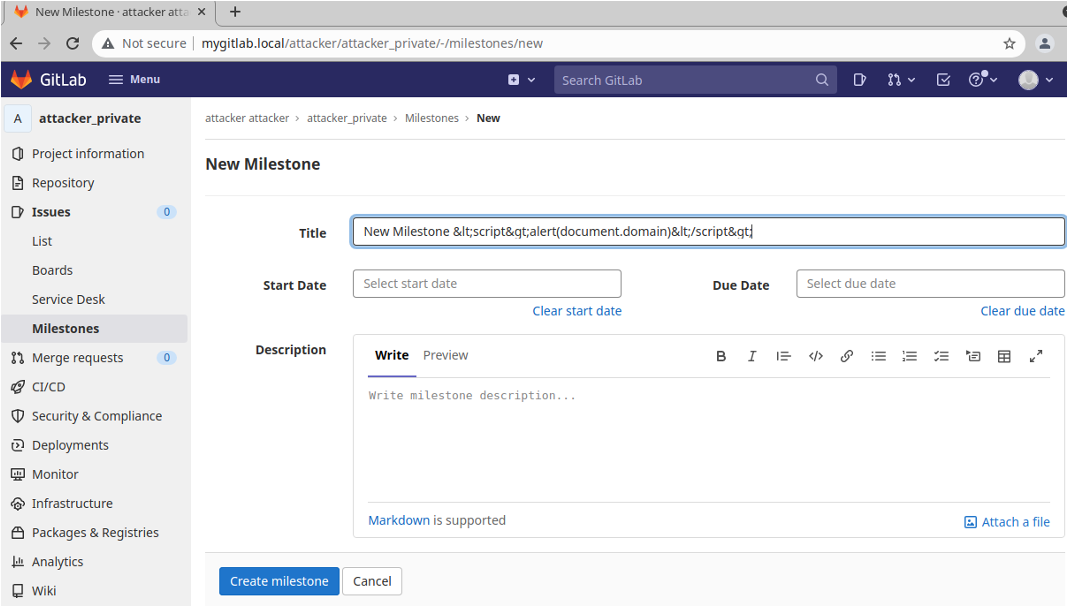
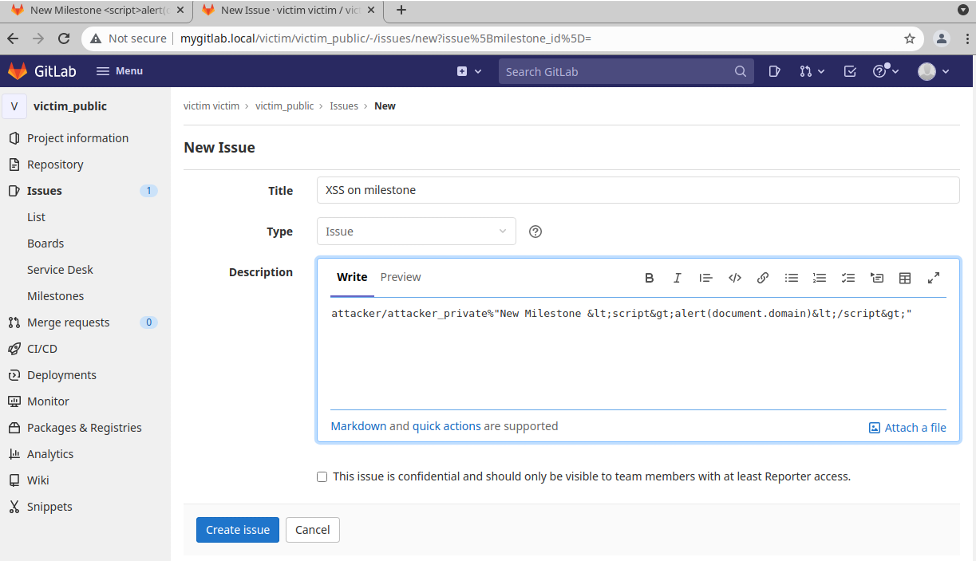
具体的攻击细节,可以在 相应的文档和 Issue 里看到完整复现。
针对 XSS 攻击,这可能是最常见的攻击方式,所以也是需要 Security Code Reviewer 重点关注。每个框架的应对方式可能有所区别,但思路是一致的:过滤有风险的组合。
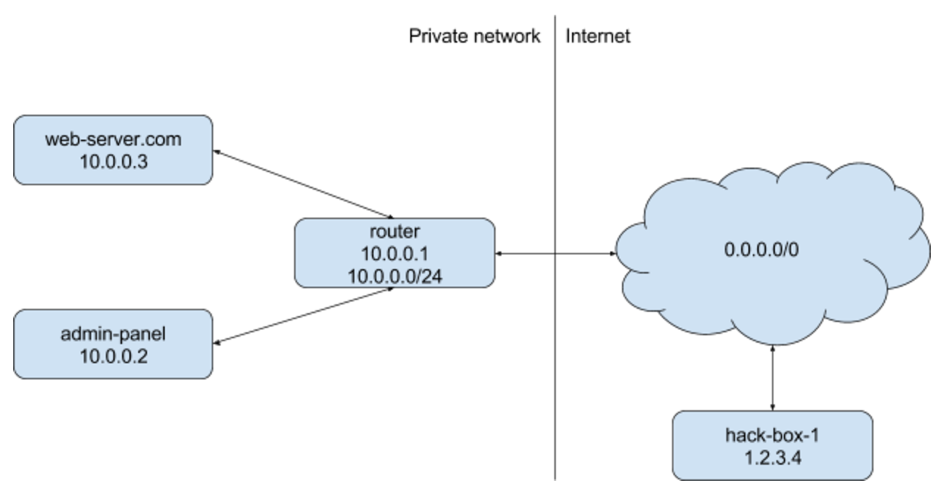
还有一种情况是服务器端的请求伪造,我们可以通过下图这个例子来看,图例左边是内网,右边是公网。
假设我们在内网中有多种不同的服务,一般会假设内网的服务之间相互请求都是比较安全的,如果用户访问的请求就是构造一个假的内网的请求的话,这样的保护机制很容易被骗过,让一台 Web Server 作为跳板来访问 Admin 的一些请求,这样就会造成相应的权限管理漏洞。

这也就是为什么极狐GitLab 默认的配置下是不允许访问 Localhost 的,可能大家也会在配置中遇到这样的情况,这是一种保护措施。
需要注意的就是在构建 HTTP 请求的时候,也是使用极狐GitLab 已经录制好的类库,GitLab::HTTP 或者 Gitlab::UrlBlocker,这里面包装了很多很多现成的方法可以方便使用。
Security Code Reviewer 需要经常模拟黑客攻击,想一下黑客常用的攻击手段是什么?我们是不是已经考虑到了这些主流的方式?
总的来说,就是不要把代码和数据混在一起,这虽然是一种灵活编程策略,但是对于我们业务的开发而言,是非常危险的。特别是如果允许用户输入数据的话,会向黑客暴露更宽泛的攻击面,提升维护的成本。
另外,不要信任任何外来数据,对于外来数据都要做有罪假定,假设所接收的所有外部数据都可能包含安全隐患。尽量提供最小的攻击面,才能尽可能减少风险。
还有,良好的测试覆盖可以帮助提高代码质量。对于有风险的 Case,要有意识的写测试来覆盖,避免重复的回归。
以上我们通过回顾极狐GitLab 的漏洞分析,用 6 个真实案例给大家诠释了 Security Code Review 的作用和意义,希望对大家有帮助。
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
当我使用Bundler时,是否需要在我的Gemfile中将其列为依赖项?毕竟,我的代码中有些地方需要它。例如,当我进行Bundler设置时:require"bundler/setup" 最佳答案 没有。您可以尝试,但首先您必须用鞋带将自己抬离地面。 关于ruby-我需要将Bundler本身添加到Gemfile中吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/4758609/
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
为什么4.1%2返回0.0999999999999996?但是4.2%2==0.2。 最佳答案 参见此处:WhatEveryProgrammerShouldKnowAboutFloating-PointArithmetic实数是无限的。计算机使用的位数有限(今天是32位、64位)。因此计算机进行的浮点运算不能代表所有的实数。0.1是这些数字之一。请注意,这不是与Ruby相关的问题,而是与所有编程语言相关的问题,因为它来自计算机表示实数的方式。 关于ruby-为什么4.1%2使用Ruby返
我正在查看instance_variable_set的文档并看到给出的示例代码是这样做的:obj.instance_variable_set(:@instnc_var,"valuefortheinstancevariable")然后允许您在类的任何实例方法中以@instnc_var的形式访问该变量。我想知道为什么在@instnc_var之前需要一个冒号:。冒号有什么作用? 最佳答案 我的第一直觉是告诉你不要使用instance_variable_set除非你真的知道你用它做什么。它本质上是一种元编程工具或绕过实例变量可见性的黑客攻击
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只