在中心云,Kubernetes容器平台已经成为容器编排和调度的事实标准,但是在边缘计算领域,涉及范围较大且场景复杂,缺乏统一的标准;当前Kubernetes开源社区的主线版本,并没适配边缘场景的计划。
目前国内各个公有云厂商,都开源了各自基于Kubernetes的边缘计算云原生项目,主要有华为的KubeEdge,阿里的OpenYurt,腾讯的SuperEdge,百度的Baetyl等,碎片化严重,短时间很难有大一统的开源产品。
长远来看,建议通过标准的Kubernetes API来集成,这种兼容所有边缘容器的中庸方案。如果非要择其一,建议是OpenYurt,非侵入式设计,整体技术架构及实现更加优雅。本篇主要是通过OpenYurt架构与原理分析,深入浅出的了解边缘容器的技术详情。
OpenYurt以上游开源项目Kubernetes为基础,针对边缘场景适配的发行版。是业界首个依托云原生技术体系、“零”侵入实现的智能边缘计算平台。具备全方位的“云、边、端一体化”能力,能够快速实现海量边缘计算业务和异构算力的高效交付、运维及管理。
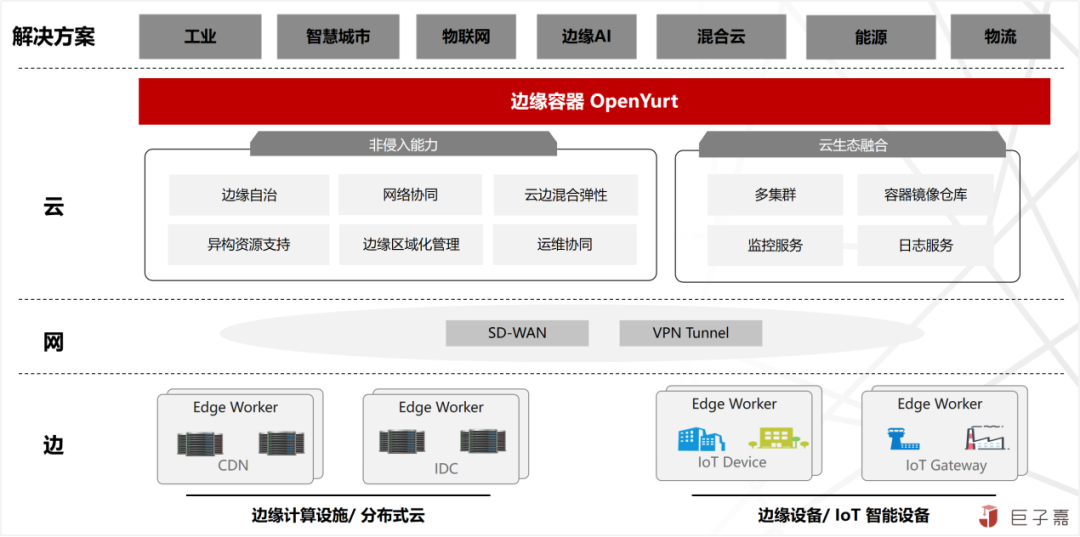
OpenYurt采用当前业界主流的“中心管控、边缘运行”的云边分布式协同技术架构,始终贯彻“Extending your native Kubernetes to Edge”产品理念,同时遵守以下设计原则:
“云边一体化”原则:保证与中心云一致的用户体验及产品能力的基础上,通过云边管控通道将云原生能力下沉至边缘,实现海量的智能边缘节点及业务应用,基础架构提升至业界领的云原生架构的重大突破。
“零侵入”原则:确保面向用户开放的API与原生Kubernetes完全一致。通过节点网络流量代理方式(proxy node network traffic),对Worker工作节点应用生命周期管理新增一层封装抽象,实现分散式工作节点资源及应用统一管理及调度。同时遵循“UpStream First”开源法则;
“低负载”原则:在保障平台功能特性及可靠性的基础上,兼顾平台的通用性,严格限制所有组件的资源,遵循最小化,最简化的设计理念,以此实现最大化覆盖边缘设备及场景。
“一栈式”原则:OpenYurt不仅实现了边缘运行及管理的增强功能,还提供了配套的运维管理工具,实现将原生Kubernetes与支持边缘计算能力的Kubernetes集群的相互一键高效转换;
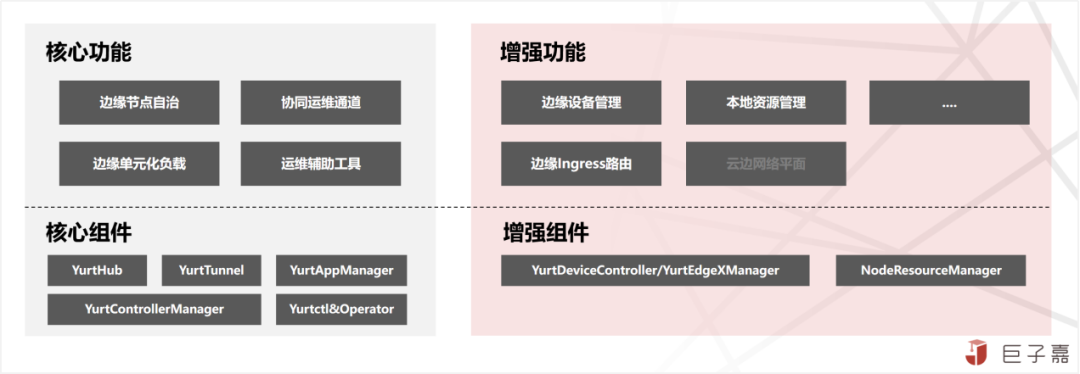
借助Kubernetes强大的容器编排、调度能力,针对边缘资源有限,网络受限不稳定等情况适配增强;将中心云原生能力拓展至分散式边缘节点,实现面向边缘业务就近低延迟服务;同时打通反向安全控制运维链路,提供便捷高效的,云端集中式边缘设备及应用的统一运维管理能力。其核心功能特性如下:
1.边缘节点自治:在边缘计算场景,云边管控网络无法保证持续稳定,通过增强适配解决原生Worker工作节点无状态数据,强依赖Master管控节点数据且状态强一致机制,这些在边缘场景不适配的问题。从而实现在云边网络不畅的情况下,边缘工作负载不被驱逐,业务持续正常服务;即使断网时边缘节点重启,业务依然能恢复正常;即边缘节点临时自治能力。
2.协同运维通道:在边缘计算场景,云边网络不在同一网络平面,边缘节点也不会暴露在公网之上,中心管控无法与边缘节点建立有效的网络链路通道,导致所有原生的Kubernetes运维APIs(logs/exec/metrics)失效。适配增强Kubernetes能力,在边缘点初始化时,在中心管控与边缘节点之间建立反向通道,承接原生的Kubernetes运维APIs(logs/exec/metrics)流量,实现中心化统一运维;
3.边缘单元化负载:在边缘计算场景,面向业务一般都是“集中式管控,分散式运行”这种云边协同分布式架构;对于管理端,需要将相同的业务同时部署到不同地域节点;对于边缘端,Worker工作节是一般是分散在广域空间,并且具有较强的地域性,跨地域的节点之间网络不互通、资源不共享、资源异构等明显的隔离属性。适配增强Kubernetes能力,基于资源,应用及流量三层实现对边缘负载进行单元化管理调度。
通过OpenYurt开源社区,引入更多的参与方,通过联合研发方式提供更多的可选的专业功能,丰富OpenYurt特性,扩大产品覆盖能力:
1.边缘设备管理:在边缘计算场景,端侧设备才是平台真正的服务对象;基于云原生理念,抽象非侵入、可扩展的设备管理标准模型,无缝融合Kubernetes工作负载模型与IoT设备管理模型,实现平台赋能业务的最后一公里。目前,通过标准模型完成EdgeX Foundry开源项目的集成,极大的提升了边缘设备的管理效率。
2.本地资源管理:在边缘计算场景,将边缘节点上已有的块设备或者持久化内存设备,初始化成云原生便捷使用的容器存储,支持两种本地存储设备:(一)基于块设备或者是持久化内存设备创建的LVM;(二)基于块设备或者是持久化内存设备创建的 QuotaPath
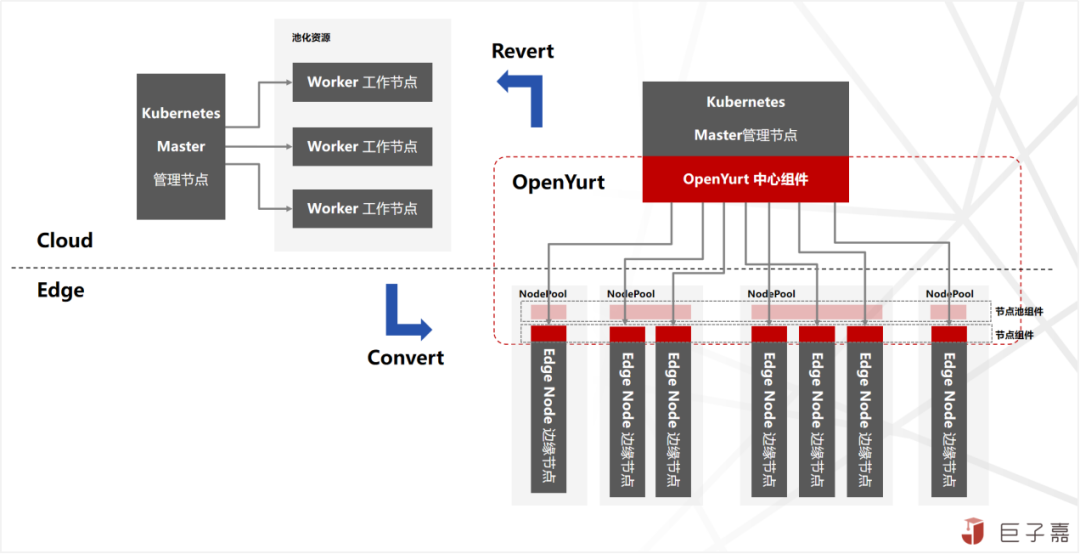
原生Kubernetes是一个中心式的分布式架构,Master控制节点负责管理调度及控制集群运行状态;Worker工作节点负责运行容器(Container)及监控/上报运行状态;
OpenYurt以原生Kubernetes为基础,针对边缘场景,将中心式分布式架构(Cloud Master,Cloud Worker),解耦适配为中心化管控分散式边缘运行(Cloud Master,Edge Worker),形成一个中心式大脑,多个分散式小脑的章鱼式云边协同分布式架构;其主要核心点是:
(一)将元数据集中式且强一致的状态存储,分散至边缘节点,并且调整原生Kubernetes调度机制,实现自治节点状态异常不触发重新调度,以此实现边缘节点临时自治能力;
(二)保证Kubernetes能力完整一致,同时兼容现有的云原生生态体系的同时,尽最大肯能将云原生体系下沉至边缘;
(三)将中心大规模资源池化,多应用委托调度共享资源的模式,适配为面向地域小规模甚至单节点资源,实现边缘场景下,更精细化的单元化工作负载编排管理;
(四)面向边缘实际业务场景需求,通过开放式社区,无缝集成设备管理,边缘AI,流式数据等,面向边缘实际业务场景的开箱的通用平台能力,赋能更多的边缘应用场景。
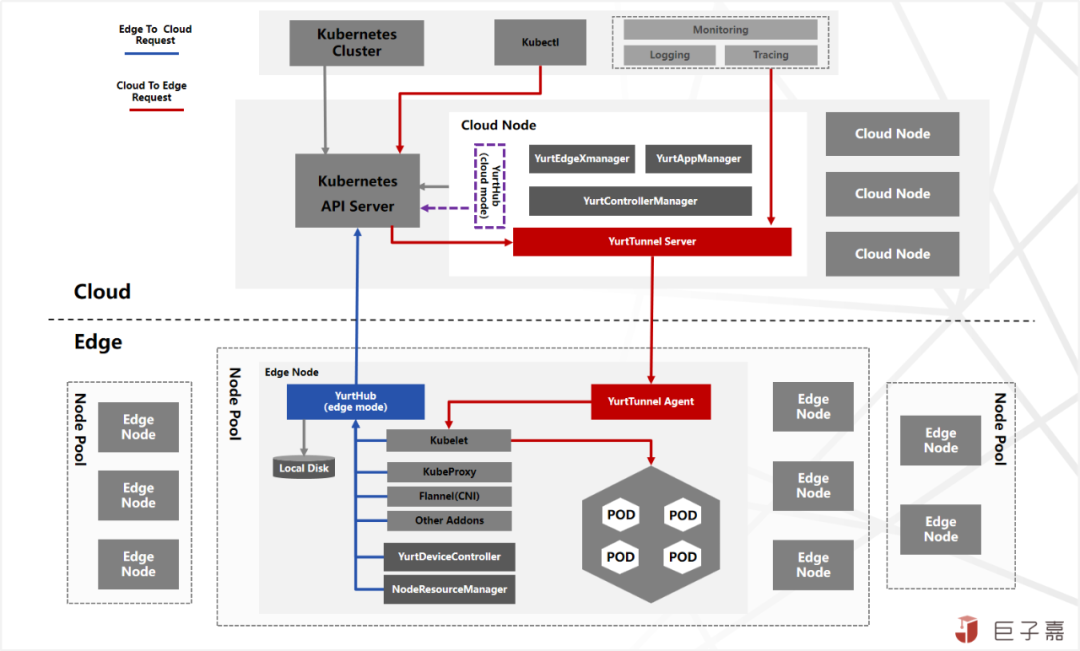
OpenYurt践行云原生架构理念,深刻理解Kubernetes实现机制,创新性的采用非侵入式架构设计,面向边缘计算场景实现云边协同分布式架构及中心管控边缘运行的能力:
针对边缘节点自治能力,一方面,通过新增YurtHub组件实现边缘向中心管控请求(Edge To Cloud Request)代理,并缓存机制将最新的元数据持久化在边缘节点;另一方面新增YurtControllerManager组件接管原生Kubernetes调度,实现边缘自治节点状态异常不触发重新调度;
针对Kubernetes能力完整及生态兼容,通过新增YurtTunnel组件,构建云边(Cloud To Edge Request)反向通道,保证Kubectl,Promethus等中心运维管控产品一致能力及用户体验;同时将中心其他能力下沉至边缘,包含各不同的工作负载及Ingress路由等。
针对边缘单元化管理能力,通过新增YurtAppManager组件,同时搭配NodePool,YurtAppSet(原UnitedDeployment),YurtAppDaemon,ServiceTopology等实现边缘资源,工作负载及流量三层单元化管理;
针对赋能边缘实际业务平台能力,通过新增NodeResourceManager实现边缘存储便捷使用,通过引入YurtEdgeXManager/YurtDeviceController实现通过云原生模式管理边缘设备。
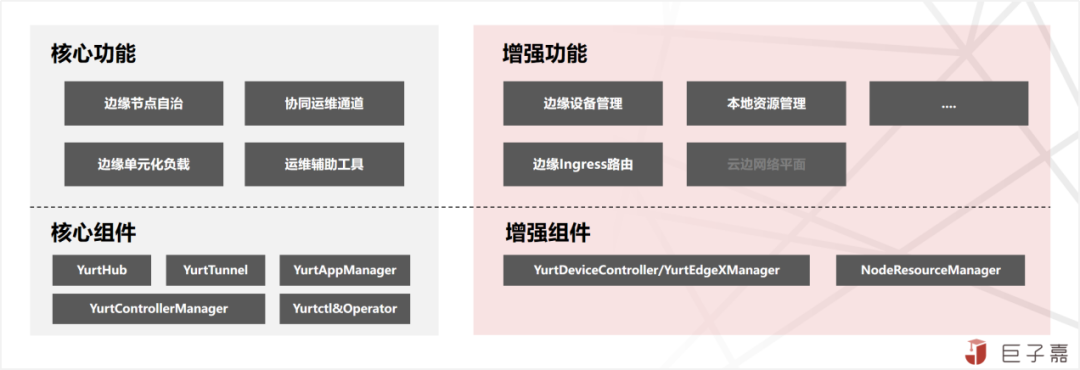
OpenYurt所有新增功能及组件,均是通过Addon与Controller方式来实现其核心必选与可选组件如下:
1.YurtHub(必选):有边缘(edge)和云中心(cloud)两种运行模式;以Static Pod形态运行在云边所有节点上,作为节点流量的SideCar,代理节点上组件和kube-apiserver的访问流量,其中边缘YurtHub会缓存的数据,实现临时边缘节点自治能力。
2.YurtTunnel(必选):由Server服务端与Agent客户端组成,构建双向认证加密的云边反向隧道,转发云中心(cloud)到边缘(edge)原生的Kubernetes运维APIs(logs/exec/metrics)请求流量。其中Server以Deployment工作负载部署在云中心,Agent以DaemonSet工作负载部署在边缘节点。
3.YurtControllerManager(必选):云中心控制器,接管原生Kubernetes的NodeLifeCycle Controller,实现在云边网络异常时,不驱逐自治边缘节点的Pod应用;还有YurtCSRController,用以审批边缘节点的证书申请。
4.YurtAppManager(必选):实现对边缘负载进行单元化管理调度,包括NodePool:节点池管理;YurtAppSet:原UnitedDeployment,节点池维度的业务负载;YurtAppDaemon:节点池维度的Daemonset工作负载。以Deploymen工作负载部署在云中心。
5.NodeResourceManager(可选):边缘节点本地存储资源的管理组件,通过修改ConfigMap来动态配置宿主机本地资源。以DaemonSet工作负载部署在边缘节点。
6.YurtEdgeXManager/YurtDeviceController(可选):通过云原生模式管控边缘设备,当前支持EdgeX Foundry的集成。YurtEdgeXManager以Deployment工作负载署在云中心,YurtDeviceController以YurtAppSet工作负载署部署在边缘节点,并且以节点池NodePool为单位部署一套YurtDeviceController即可。
7.运维管理组件(可选):为了标准化集群管理,OpenYurt社区推出YurtCluster Operator组件,提供云原生声名式Cluster API及配置,基于标准Kubernetes自动化部署及配置OpenYurt相关组件,实现OpenYurt集群的全生命周期。旧Yurtctl工具建议只在测试环境使用。
除了核心功能及可选的专业功能外,OpenYurt持续贯彻云边一体化理念,将云原生丰富的生态能力最大程度推向边缘,已经实现了边缘容器存储,边缘守护工作负载 DaemonSet,边缘网络接入Ingress Controller等,还有规划中的有Service Mesh,Kubeflow,Serverless等功能,拭目以待。
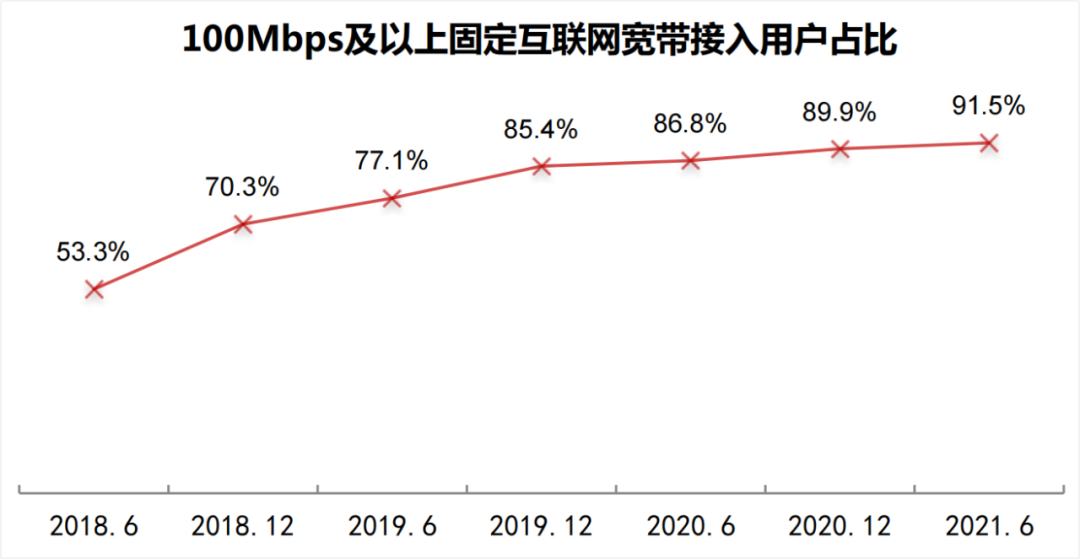
对于云边网络差的认知误区,在边缘计算场景中,被提到最多的就是云边网络差且不稳定;其实国内基础网络在2015年开始全面升级;尤其是在“雪亮工程”全面完成之后,基础网络有一个很大的提升;上图摘自《第 48 次中国互联网络发展状况》报告,固网100Mbps接入占比已达91.5%;无线网络接入已经都是4G,5G的优质网络。
真的挑战在云边网络组网,对于使用公有云的场景:公有云屏蔽数据中心网络,只提供了互联网出口带宽,通过互联网打通云边,通常只需要解决数据安全传输即可,接入不复杂。对于私有自建的IDC场景:打通云边网络并不容易,主要是运营商网络没有完全产品化,同时私有IDC层层防火墙等其他复杂产品,需要专业的网络人员才能完成实施工作。
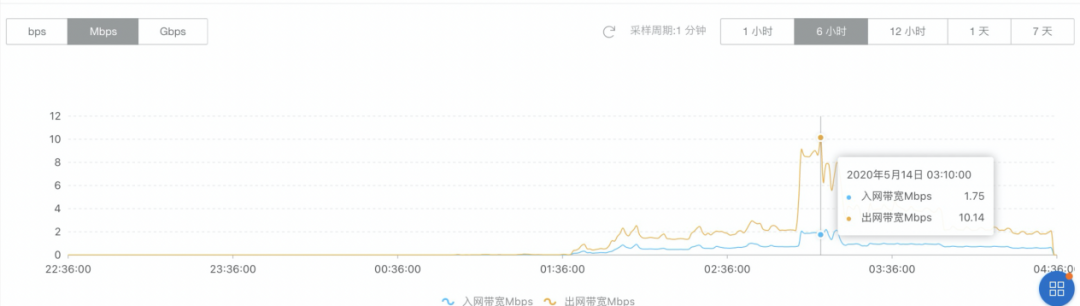
对于list-watch机制,云边流量大的认知误区,List-Watch机制是Kubernetes的设计精华,通过主动监听机制获取相关的事件及数据,从而保证所有组件松耦合相互独立,逻辑上又浑然一体。List请求返回是全量的数据,一旦Watch失败,就需要重新Relist。但是Kubernetes有考虑管理数据同步优化,节点的kubelet只监听本节点数据,kube-proxy会监听所有的Service数据,数据量相对可控;同时采用gRPC协议,文本报文数据相比业务数据非常小。上图是在节点1200节点的集群规模,做的压测数据监控图表。
真的挑战在基础镜像及应用镜像下发,当前的基础镜像及业务镜像,即使在中心云,依然在探索各种技术来优化镜像快速分发的瓶颈;尤其是边缘的AI应用,一般都是由推送应用+模型库构成,推算应用的镜像相对较小,模型库的体积就非常,同时模型库随着自学习还需要频繁的更新,如果更高效的更新模型库,需要更多技术及方案来应对。
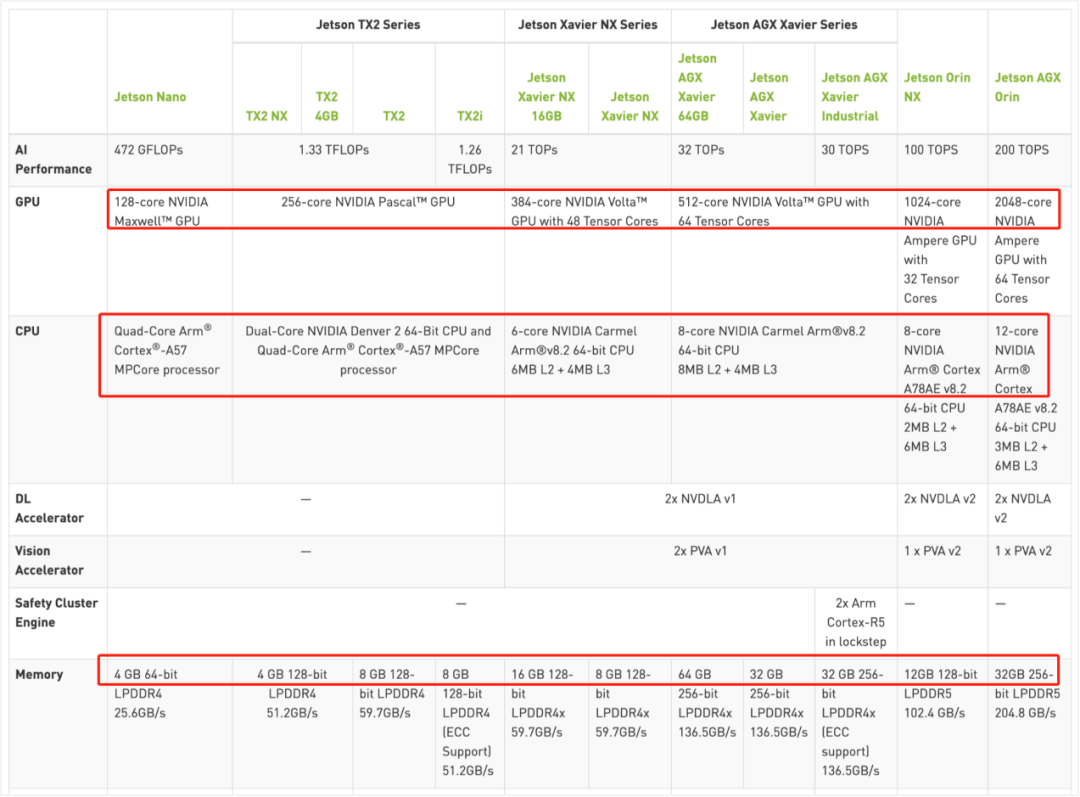
对于边缘资源少的认知误区,边缘的资源情况是需要再细分场景,针对运营商网络边缘,面向消费者的边缘计算,资源相对比较充足,最大的挑战是资源共享及隔离;针对实体产业的边缘,都会有不小的IDC支持,边缘资源非常充足,足以将整个云原生体系下沉。针对智能设备边缘,资源相对比较稀缺,但是一般都都会通过一个智能边缘盒子,一端连接设备,一端连接中心管控服务,从上图的AI边缘盒子来看,整体配置提升速度较快,长期来看,边缘的算力快速增强以此来满足更复杂更智能化的场景需求。
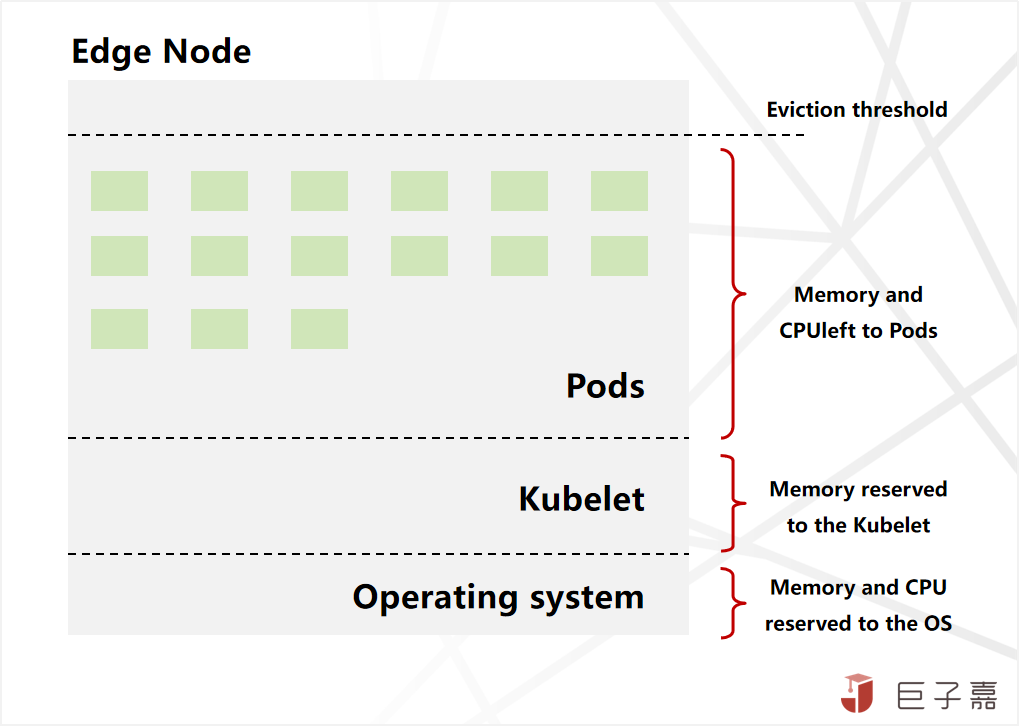
对于Kubelet比较重,运行占用资源多的认知误区,是需要深入的了解节点资源分配及使用情况,通常节点的资源自下而上分为四层:
1.运行操作系统和系统守护进程(如 SSH、systemd等)所需的资源。
2.运行Kubernetes代理所需的资源,如 Kubelet、容器运行时、节点问题检测器等。
3.Pod可用的资源。
4.保留到驱逐阈值的资源。
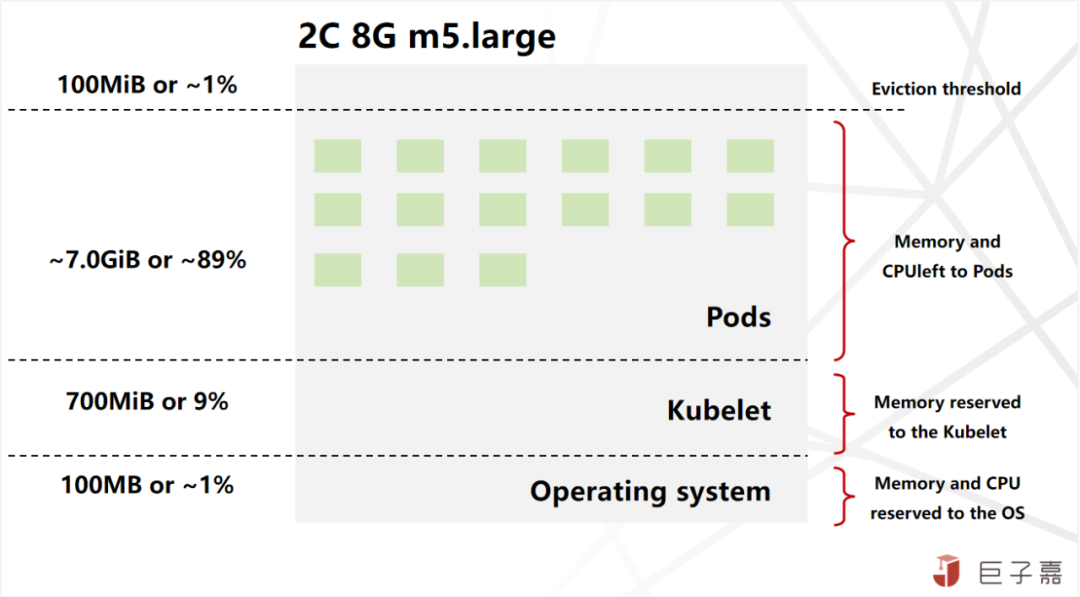
对于各层的资源分配设置的没有标准,需要根据集群的情况来权衡配置,Amazon Kubernetes对Kubelet资源配置算法是Reserved memory = 255MiB + 11MiB * MAX_POD_PER_INSTANCE;假设运行32 Pods,高达90%的内存都可以分配给业务使用,相对来说Kubelet资源占用并不高。
同时也要结合业务对高可用的要求,做响应的调整。针对边缘场景,一般不建议在一个节点上运行大量的Pods,稳定为大。
边缘计算平台的建设,以Kubernetes为核心的云原生技术体系,无疑是当前最佳的选择与建设路径;但是云原生体系庞大,组件复杂,将体系下沉至边缘,不仅存在很大的挑战与困难,同时充满巨大的机遇及想象空间;
当前边缘容器产品碎片化严重,短时间很难有大一统的开源产品;其中阿里开源的OpenYurt边缘容器产品,采用非侵入式设计,整体技术架构及实现更加优雅实用;虽然还有一些不足,大部分的边缘场景都能覆盖;简约至上,实用为大;

关注“巨子嘉”,巨子出品,必属精品
参考资料:
1.第 48 次中国互联网络发展状况
2.Allocatable memory and CPU in Kubernetes Nodes
3.OpenYurt官方文档
4.nvidia开发者官网
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
我需要尝试一些AES片段。我有一些密文c和一个keyk。密文已使用AES-CBC加密,并在前面加上IV。不存在填充,纯文本的长度是16的倍数。所以我这样做:aes=OpenSSL::Cipher::Cipher.new("AES-128-CCB")aes.decryptaes.key=kaes.iv=c[0..15]aes.update(c[16..63])+aes.final它工作得很好。现在我需要手动执行CBC模式,所以我需要单个block的“普通”AES解密。我正在尝试这个:aes=OpenSSL::Cipher::Cipher.new("AES-128-ECB")aes.dec
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我是一名决定学习Ruby和RubyonRails的ASP.NETMVC开发人员。我已经有所了解并在RoR上创建了一个网站。在ASP.NETMVC上开发,我一直使用三层架构:数据层、业务层和UI(或表示)层。尝试在RubyonRails应用程序中使用这种方法,我发现没有关于它的信息(或者也许我只是找不到它?)。也许有人可以建议我如何在RubyonRails上创建或使用三层架构?附言我使用ruby1.9.3和RubyonRails3.2.3。 最佳答案 我建议在制作RoR应用程序时遵循RubyonRails(RoR)风格。Rails
我正在尝试对某些帖子的评论使用简单的身份验证。用户使用即时ID和密码输入评论我使用“bcrypt”gem将密码存储在数据库中。在comments_controller.rb中像这样@comment=Comment.new(comment_params)bcrypted_pwd=BCrypt::Password.create(@comment.user_pwd)@comment.user_pwd=bcrypted_pwd当用户想要删除他们的评论时,我使用data-confirm-modalgem来确认数据在这部分,我必须解密用户输入的密码以与数据库中的加密密码进行比较我怎样才能解密密码,
深度学习12.CNN经典网络VGG16一、简介1.VGG来源2.VGG分类3.不同模型的参数数量4.3x3卷积核的好处5.关于学习率调度6.批归一化二、VGG16层分析1.层划分2.参数展开过程图解3.参数传递示例4.VGG16各层参数数量三、代码分析1.VGG16模型定义2.训练3.测试一、简介1.VGG来源VGG(VisualGeometryGroup)是一个视觉几何组在2014年提出的深度卷积神经网络架构。VGG在2014年ImageNet图像分类竞赛亚军,定位竞赛冠军;VGG网络采用连续的小卷积核(3x3)和池化层构建深度神经网络,网络深度可以达到16层或19层,其中VGG16和VGG
我尝试用Ruby设计一个基于Web的应用程序。我开发了一个简单的核心应用程序,在没有框架和数据库的情况下在六边形架构中实现DCI范例。核心六边形中有小六边形和网络,数据库,日志等适配器。每个六边形都在没有数据库和框架的情况下自行运行。在这种方法中,我如何提供与数据库模型和实体类的关系作为独立于数据库的关系。我想在将来将框架从Rails更改为Sinatra或数据库。事实上,我如何在这个核心Hexagon中实现完全隔离的rails和mongodb的数据库适配器或框架适配器。有什么想法吗? 最佳答案 ROM呢?(Ruby对象映射器)。还有
进行这种深度检查的最佳方法是什么:{:a=>1,:b=>{:c=>2,:f=>3,:d=>4}}.include?({:b=>{:c=>2,:f=>3}})#=>true谢谢 最佳答案 我想我从那个例子中明白了你的意思(不知何故)。我们检查子哈希中的每个键是否在超哈希中,然后检查这些键的对应值是否以某种方式匹配:如果值是哈希,则执行另一次深度检查,否则,检查值是否相等:classHashdefdeep_include?(sub_hash)sub_hash.keys.all?do|key|self.has_key?(key)&&ifs
我有一个Rails应用程序,它从WorldWeatherOnlineAPI获取响应。我正在使用rest-clientgem,响应采用JSON格式。我使用以下方法解析响应:parsed_response=JSON.parse(response)parsed_response显然是一个散列。我需要的数据是哈希内的字符串,数组内的哈希,另一个数组内的哈希,另一个哈希内的另一个哈希内的字符串。最内层的嵌套散列在["hourly"]中,这是一个由8个散列组成的数组,每个散列有20个键,拥有各种天气参数的字符串值。数组中的每个哈希值都是一天中的不同时间(预测是每三小时一次,3*8=24小时)。因此
有点边缘情况,但知道为什么&&=会这样吗?我正在使用1.9.2。obj=Object.newobj.instance_eval{@bar&&=@bar}#=>nil,expectedobj.instance_variables#=>[],soobjhasno@barinstancevariableobj.instance_eval{@bar=@bar&&@bar}#ostensiblythesameas@bar&&=@barobj.instance_variables#=>[:@bar]#whywouldthisversioninitialize@bar?为了比较,||=将实例变量初始