联邦学习(fate)从主机安装到实现联邦学习
单机版提供3种部署方式,这里选择在主机中安装FATE(官方建议使用Docker镜像,但不熟悉Docker的人容易找不到FATE路径)
使用虚拟机VMware进行实验,实验过程中随时拍摄快照,节约重装时间。
| 项目 | Value |
|---|---|
| 虚拟机配置 | 内存4G + 硬盘150G |
| 操作系统 | centos 7 |
检查端口8080、9360、9380是否被占用
netstat -apln|grep 8080
netstat -apln|grep 9360
netstat -apln|grep 9380
sudo wget https://webank-ai-1251170195.cos.ap-guangzhou.myqcloud.com/fate/1.8.0/release/standalone_fate_install_1.8.0_release.tar.gz --no-check-certificate
tar -xzvf standalone_fate_install_1.8.0_release.tar.gz
cd standalone_fate_install_1.8.0_release
bash init.sh init
bash init.sh status
bash init.sh start
加载环境变量
source bin/init_env.sh
部署成功后,通过网页访问 localhost:8080 可以进入FATE Board页面,账号密码默认为:admin
返回终端,开始测试
flow test toy -gid 10000 -hid 10000
如果成功,屏幕显示类似下方的语句:
success to calculate secure_sum, it is 2000.0(我的显示的为1999.999999999)
之后进入FATE Broad,点击右上角JOBS,看到任务栏出现两项任务,并且状态为success则说明成功。
fate_test unittest federatedml --yes
如果成功,屏幕显示类似下方的语句:
there are 0 failed test
python -m pip install fate-client
python -m pip install fate-test
flow init --ip 127.0.0.1 --port 9380
上边如果安装anaconda的则只需要执行下方第二步
pip install notebook fate-client
启动 Juypter Notebook 服务并监听 20000 端口,待服务启动完毕后则可以通过的方式 “IP:Port” 的方式访问 Notebook
jupyter notebook --ip=0.0.0.0 --port=20000 --allow-root --debug --no-browser --NotebookApp.token= ''--NotebookApp.password= ''
在开始本章之前,请确保已经安装Python和FATE单机版
from sklearn.datasets import load_breast_cancer
import pandas as pd
breast_dataset = load_breast_cancer()
breast = pd.DataFrame(breast_dataset.data, columns=breast_dataset.feature_names)
breast['y'] = breast_dataset.target
breast.head()
为了模拟横向联邦建模的场景,我们首先在本地将乳腺癌数据集切分为特征相同的横向联邦形式,当前的breast数据集有569条样本,我们将前面的469条作为训练样本,后面的100条作为评估测试样本。
from sklearn.datasets import load_breast_cancer
import pandas as pd
breast_dataset = load_breast_cancer()
breast = pd.DataFrame(breast_dataset.data, columns=breast_dataset.feature_names)
breast = (breast-breast.mean())/(breast.std())
col_names = breast.columns.values.tolist()
columns = {}
for idx, n in enumerate(col_names):
columns[n] = "x%d"%idx
breast = breast.rename(columns=columns)
breast['y'] = breast_dataset.target
breast['idx'] = range(breast.shape[0])
idx = breast['idx']
breast.drop(labels=['idx'], axis=1, inplace = True)
breast.insert(0, 'idx', idx)
breast = breast.sample(frac=1)
train = breast.iloc[:469]
eval = breast.iloc[469:]
breast_1_train = train.iloc[:200]
breast_1_train.to_csv('breast_1_train.csv', index=False, header=True)
breast_2_train = train.iloc[200:]
breast_2_train.to_csv('breast_2_train.csv', index=False, header=True)
eval.to_csv('breast_eval.csv', index=False, header=True)
运行完此程序之后会得到三个新的scv格式的数据集
在数据处理完之后,我们需要进行对数据进行上传。我们采用json格式进行上传。在FATE项目中有写好的上传json文件,在examples/dsl/v2/upload文件夹中,upload_conf.json此文件。在我的实验中,我将此文件复制到了我在FATE目录下新建的工作目录下,并对其进行了修改。
{
"file": "examples/data/breast_1_train.csv",#指定数据文件
"head":1,
"partition": 10,
"work_mode": 0,
"table_name": "homo_breast_1_train",#指定DTable表名
"namespace": "breast_1_train.csv" #指定DTable表名的命名空间
}
“file”:需要改为自己的csv路径
“work_model”:0 表示为单机部署模式
“table_name”:需要改为自己的table名
为了方便后面的叙述统一,我们假设读者安装的FATE单机版本目录为:
fate_dir=/data/projects/fate-1.8.0-experiment/standalone-fate-master-1.8.0/
做完上述准备之后,我们需要进行以下操作
cd /data/projects/fate-1.8.0-experiment/standalone-fate-master-1.8.0
source bin/init_env.sh
python /opt/standalone_fate_install_1.8.0/fateflow/python/fate_flow/fate_flow_client.py -f upload -c /opt/standalone_fate_install_1.8.0/fate/upload_data/upload_train1.json
或者
flow data upload -c /opt/standalone_fate_install_1.8.0/fate/upload_data/upload_train1.json
出现如下界面说明成功:
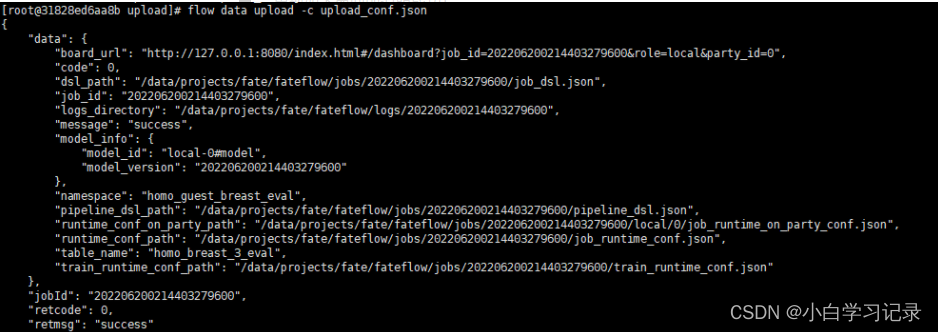
在数据完成上传之后,下面需要对训练任务进行配置,在FATE项目中已经给出了很多写好的配置,我们可以在此基础上进行修改就能直接用了。
书中的版本与v1.8.0完全发生了改变,我们需要重新配置dsl和conf文件,且书中是使用训练集建模,训练集评估,与建模流程不符,我们改变书中流程,使用训练集建模,训练集与测试集分开进行评估。
在这里我使用的是homo_lr_train_conf.json和homo_lr_train_dsl.json,这两个文件在examples/dsl/v2/homo_logistic_regression目录中能够找到。接下来我们需要对其进行修改
{
"role": {
"host": {
"0": {
"reader_0": {
"table": {
"name": "mnist_host_train", #注意此处换成对应的表名,在复制此代码时需要删除此注释
"namespace": "experiment"
}
},
"evaluation_0": {
"need_run": false
}
}
},
"guest": {
"0": {
"reader_0": {
"table": {
"name": "mnist_guest_train",#注意此处换成对应的表名,在复制此代码时需要删除此注释
"namespace": "experiment"
}
}
}
}
}
}
}
"component_parameters": {
"common": {
"data_transform_0": {
"with_label": true,
"output_format": "dense"
},
"homo_lr_0": {
"penalty": "L2",
"tol": 1e-05,
"alpha": 0.01,
"optimizer": "sgd",
"batch_size": -1,
"learning_rate": 0.15,
"init_param": {
"init_method": "zeros"
},
"max_iter": 30,
"early_stop": "diff",
"encrypt_param": {
"method": null
},
"cv_param": {
"n_splits": 4,
"shuffle": true,
"random_seed": 33,
"need_cv": false
},
"decay": 1,
"decay_sqrt": true
},
"evaluation_0": {
"eval_type": "binary"
}
}
python /opt/standalone_fate_install_1.8.0/fateflow/python/fate_flow/fate_flow_client.py -f submit_job -d /opt/standalone_fate_install_1.8.0/fate/dsl_conf/homo_lr_train_dsl.json -c /opt/standalone_fate_install_1.8.0/fate/dsl_conf/homo_lr_train_conf.json
或者
flow job submit -d /opt/standalone_fate_install_1.8.0/fate/dsl_conf/homo_lr_train_dsl.json -c /opt/standalone_fate_install_1.8.0/fate/dsl_conf/homo_lr_train_conf.json
成功后显示如图
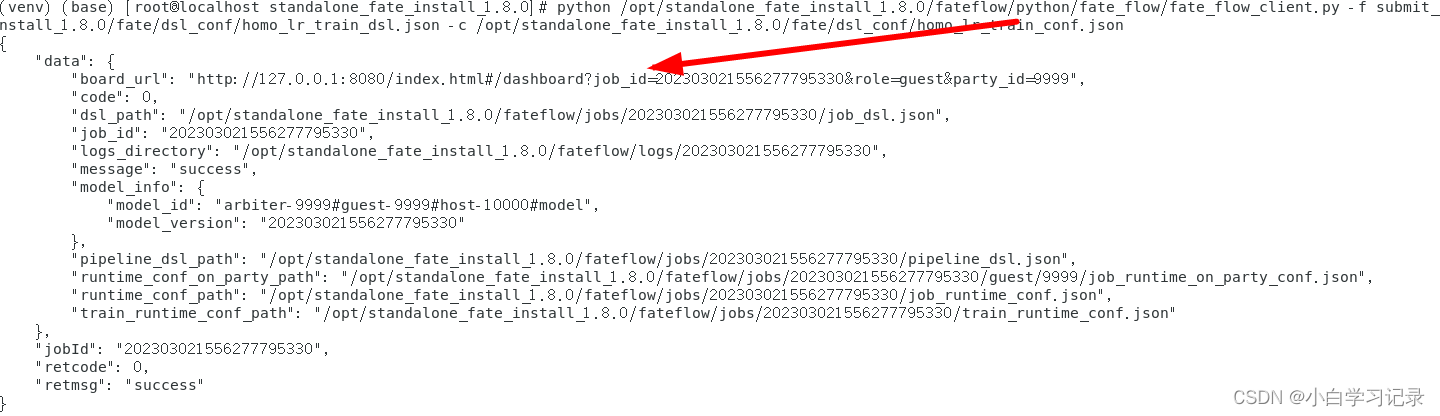
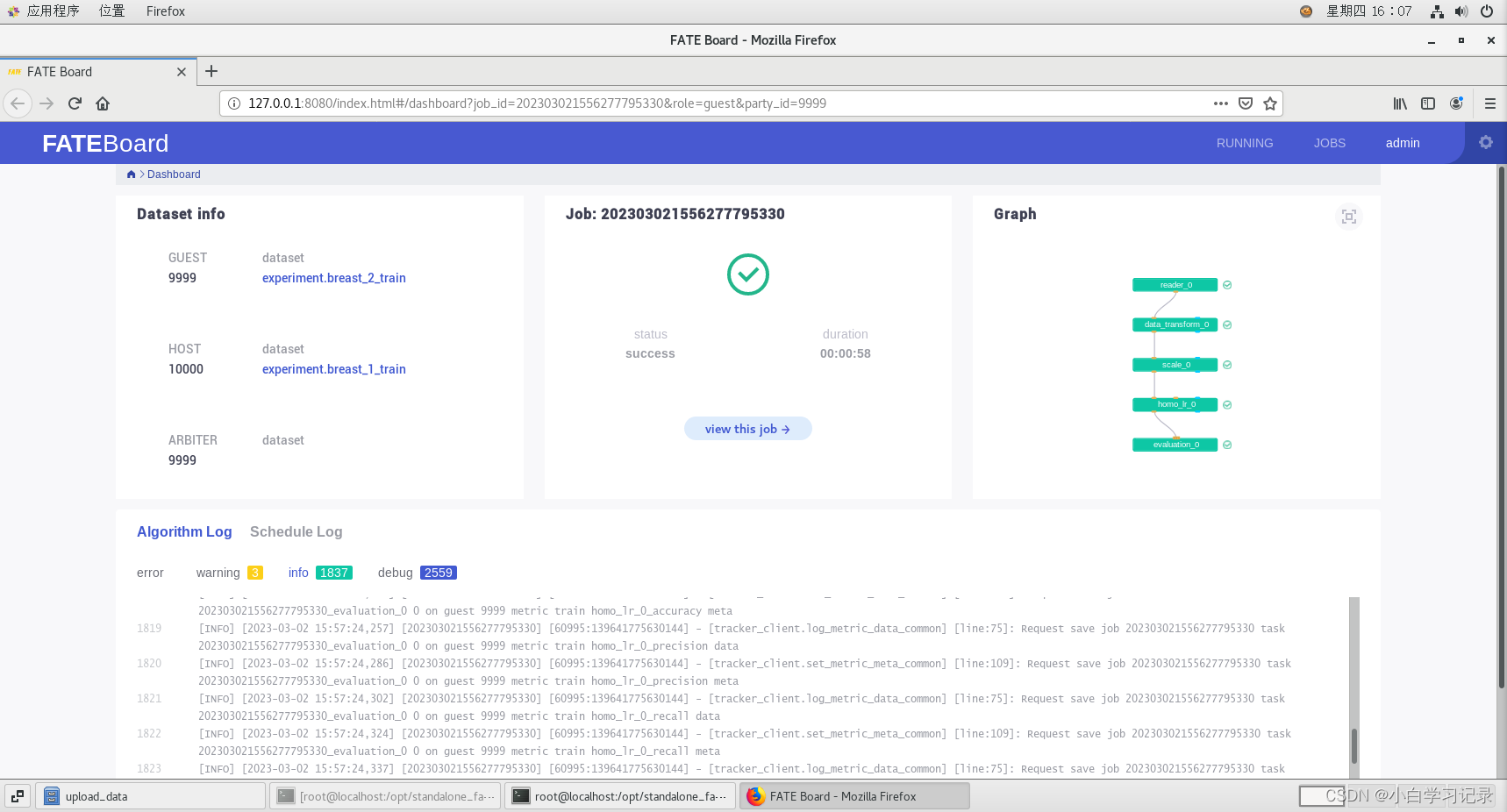
通过箭头所指地址我们可以在浏览器中查看任务进度和信息
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
我有一个奇怪的问题:我在rvm上安装了rubyonrails。一切正常,我可以创建项目。但是在我输入“railsnew”时重新启动后,我有“程序'rails'当前未安装。”。SystemUbuntu12.04ruby-v"1.9.3p194"gemlistactionmailer(3.2.5)actionpack(3.2.5)activemodel(3.2.5)activerecord(3.2.5)activeresource(3.2.5)activesupport(3.2.5)arel(3.0.2)builder(3.0.0)bundler(1.1.4)coffee-rails(
我刚刚为fedora安装了emacs。我想用emacs编写ruby。为ruby提供代码提示、代码完成类型功能所需的工具、扩展是什么? 最佳答案 ruby-mode已经包含在Emacs23之后的版本中。不过,它也可以通过ELPA获得。您可能感兴趣的其他一些事情是集成RVM、feature-mode(Cucumber)、rspec-mode、ruby-electric、inf-ruby、rinari(用于Rails)等。这是我当前用于Ruby开发的Emacs配置:https://github.com/citizen428/emacs
我正在尝试在我的centos服务器上安装therubyracer,但遇到了麻烦。$geminstalltherubyracerBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtherubyracer:ERROR:Failedtobuildgemnativeextension./usr/local/rvm/rubies/ruby-1.9.3-p125/bin/rubyextconf.rbcheckingformain()in-lpthread...yescheckingforv8.h...no***e
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
我实际上是在尝试使用RVM在我的OSX10.7.5上更新ruby,并在输入以下命令后:rvminstallruby我得到了以下回复:Searchingforbinaryrubies,thismighttakesometime.Checkingrequirementsforosx.Installingrequirementsforosx.Updatingsystem.......Errorrunning'requirements_osx_brew_update_systemruby-2.0.0-p247',pleaseread/Users/username/.rvm/log/138121
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r