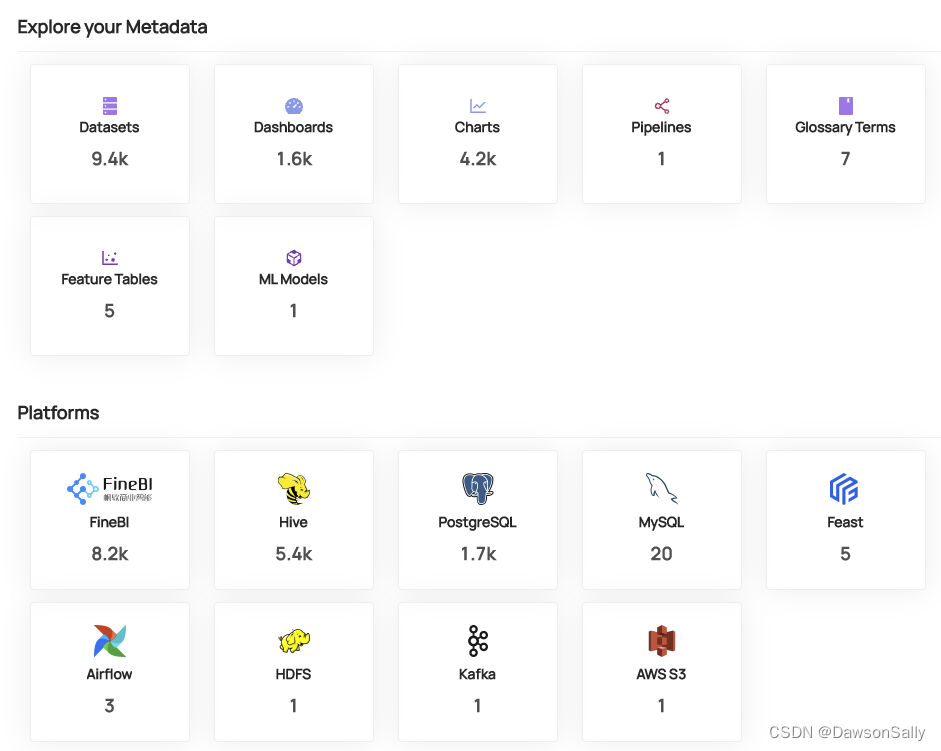
当前数仓架构流程图如下图所示,不支持端到端数据血缘,数据异常排查及影响分析比较被动,需要端到端数据血缘及元数据管理。
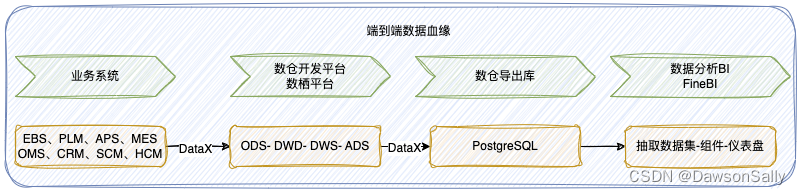
业务系统:各种制造业业务系统(高速迭代、重构、新建中)
数仓开发平台:数栖平台,支持数仓内各层级的DAG调度血缘图
数仓导出库:PG
BI可视化系统:FineBI,支持内部数据集、图表的血缘
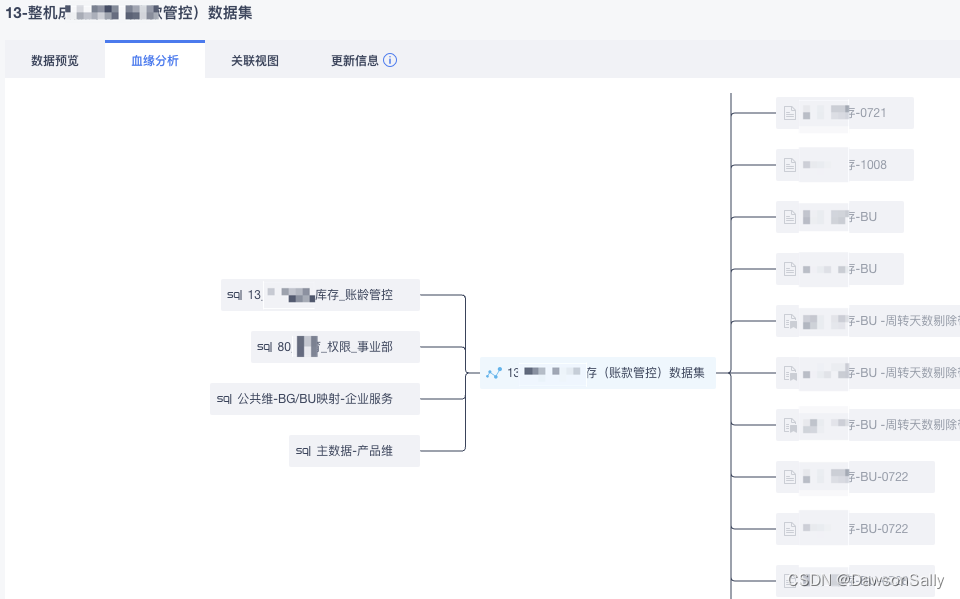
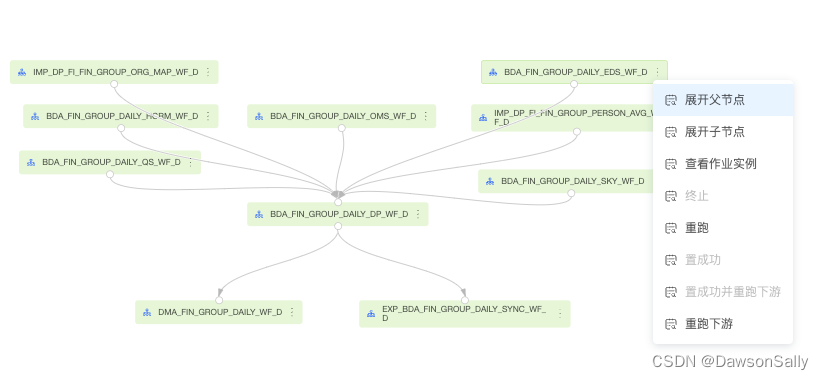
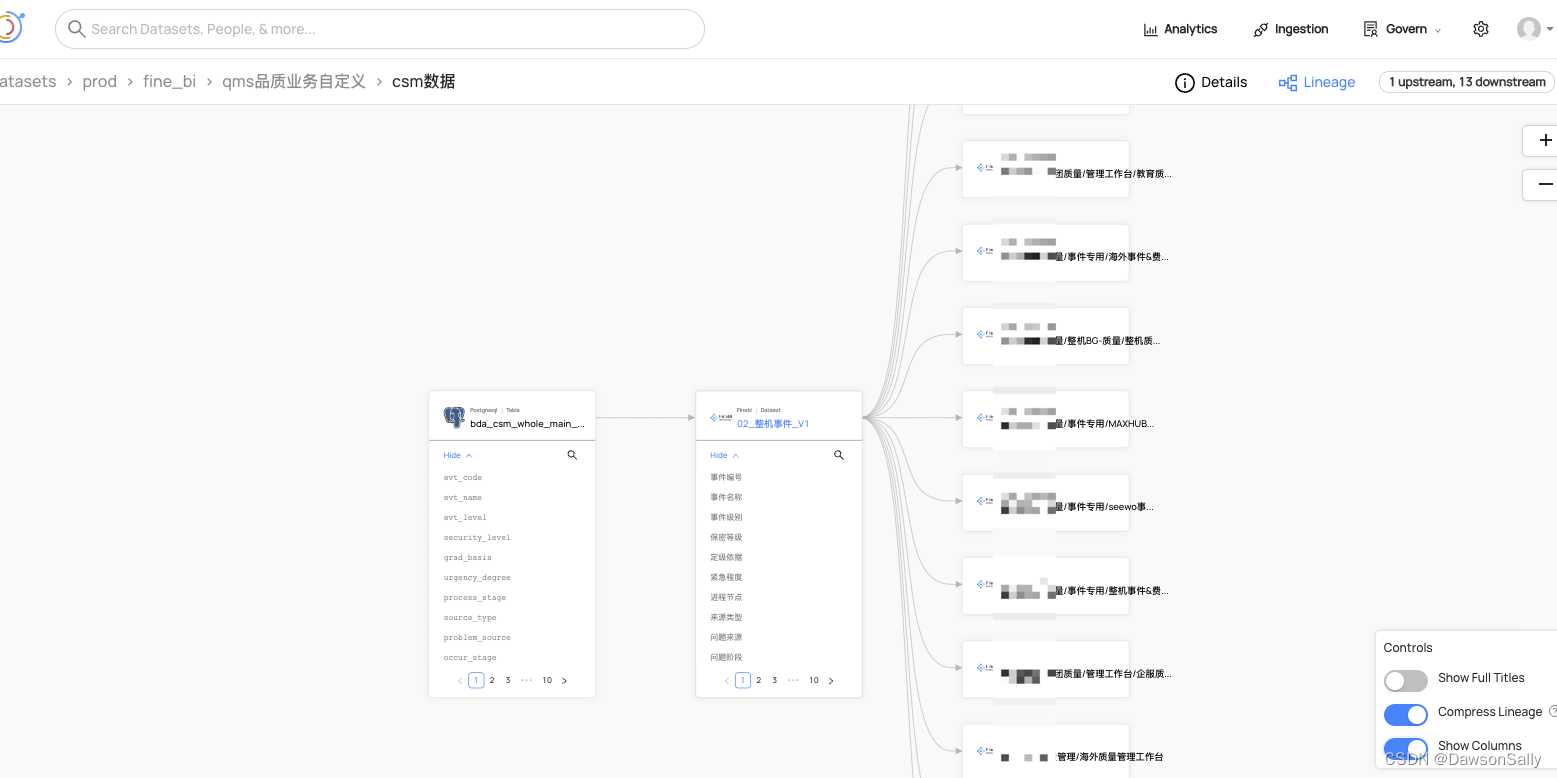
通过调研分析,引入datahub做元数据管理平台,实现效果如下图展示。
实现如下端到端血缘图:
BI报表/仪表盘(dashboard)->BI组件(chart)->BI数据集->数仓导出库(PG)->数仓数据资产(数栖平台)->上游业务系统
工作内容:
本文介绍:
官方文档:
[cloud@dp-web-uic1 datahub_ingest]$ datahub put platform --name fine_bi --display_name "FineBI" --logo "https://www.finebi.com/images/logo-FineBI.png"
✅ Successfully wrote data platform metadata for urn:li:dataPlatform:fine_bi to DataHub (DataHubRestEmitter: configured to talk to http://localhost:8080)
[cloud@dp-web-uic1 ~]$ datahub put platform --name yuan_xiang --display_name "源象" --logo "https://www.dtwave.com/images/index/product/shuqi.svg"
✅ Successfully wrote data platform metadata for urn:li:dataPlatform:yuan_xiang to DataHub (DataHubRestEmitter: configured to talk to http://localhost:8080)
[cloud@dp-web-uic1 ~]$ datahub put platform --name dolphinscheduler --display_name "海豚调度" --logo "https://dolphinscheduler.apache.org/img/hlogo_white.svg"
✅ Successfully wrote data platform metadata for urn:li:dataPlatform:dolphinscheduler to DataHub (DataHubRestEmitter: configured to talk to http://localhost:8080)
[cloud@dp-web-uic1 datahub_ingest]$ datahub put platform --name statrocks --display_name "StarRocks" --logo "https://docs.starrocks.io/static/b660bcde69091ea56bd94cac0a907018/95f17/starrocks-logo_en-us.png"
✅ Successfully wrote data platform metadata for urn:li:dataPlatform:statrocks to DataHub (DataHubRestEmitter: configured to talk to http://localhost:8080)
from sqllineage.runner import LineageRunner
def test_create_as():
sql="""
-- mes数据中获取每个批次第一次上线扫码时间
drop table if exists sda${db_para}.tmp_sda_delivety_complete_sr_sum_00;
create table if not exists sda${db_para}.tmp_sda_delivety_complete_sr_sum_00
as
select
min(produce_date) min_produce_DATE,
mo_lot_no,
organization_id
from bda${db_para}.BDA_MES_PRODUCT_SUMMARY
where factory_no ='CY-SR'
and step_name in ('OC上线组装','整机组装1')
group by mo_lot_no,
organization_id
;
-- 订单承诺
drop table if exists sda${db_para}.tmp_sda_delivety_complete_sr_sum_01_1;
create table if not exists sda${db_para}.tmp_sda_delivety_complete_sr_sum_01_1
as
select t1.version_id
, t1.promise_id
, t1.organization_id
, t1.order_id
, t1.order_no
, t1.order_stage
, t1.order_type
, t1.so_type
, t1.order_status
, t1.order_priority
, t1.promise_status
, t1.product_id
, t1.product_no
, t1.product_model
, t1.order_qty
, t1.bu_name
, t1.rcv_client_name
, t1.prepared_client_name
, t1.order_source
, t1.om_user_name
, t1.term_cust
, t1.to_pur_time
, t1.factory_no
, t1.mo_lot_no
, t1.completed_qty
, t1.mo_audit_status
, t1.req_arrival_time
, t1.mtr_ready_time
, t1.plan_promise_time
, t1.promise_date_change_reason
, t1.schedule_start_time
, t1.schedule_end_time
, t1.pps_type
, t1.pps_exception_info
, t1.promise_diff_day
, t1.promise_delivery_cycle
, t1.change_reason
, t1.client_abbr
, t1.item_type_product
, t1.match_forecast
, t1.software_flag
, t1.risk_level
, t1.risk_reason
, t1.ckd_type
, t1.crt_user
, t1.crt_time
, t1.upd_user
, t1.upd_time
, t1.crt_user_name
, t1.upd_user_name
from bda${db_para}.bda_whole_pto_order t1
left join bda${db_para}.bda_promise_history_record t2 on t1.promise_id = t2.promise_id and coalesce(t2.afterchangereason,'') = 'AGAIN_PLAN'
where t1.version_id like '%最新版本%'
and t2.promise_id is null
union all
select t1.version_id
, t1.promise_id
, t1.organization_id
, t1.order_id
, t1.order_no
, t1.order_stage
, t1.order_type
, t1.so_type
, t1.order_status
, t1.order_priority
, t1.promise_status
, t1.product_id
, t1.product_no
, t1.product_model
, t1.order_qty
, t1.bu_name
, t1.rcv_client_name
, t1.prepared_client_name
, t1.order_source
, t1.om_user_name
, t1.term_cust
, t1.to_pur_time
, t1.factory_no
, t1.mo_lot_no
, t1.completed_qty
, t1.mo_audit_status
, t1.req_arrival_time
, t1.mtr_ready_time
, t1.plan_promise_time
, t1.promise_date_change_reason
, t1.schedule_start_time
, t1.schedule_end_time
, t1.pps_type
, t1.pps_exception_info
, t1.promise_diff_day
, t1.promise_delivery_cycle
, t1.change_reason
, t1.client_abbr
, t1.item_type_product
, t1.match_forecast
, t1.software_flag
, t1.risk_level
, t1.risk_reason
, t1.ckd_type
, t1.crt_user
, t1.crt_time
, t1.upd_user
, t1.upd_time
, t1.crt_user_name
, t1.upd_user_name
from (
select t1.version_id
, t1.promise_id
, t1.organization_id
, t1.order_id
, t1.order_no
, t1.order_stage
, t1.order_type
, t1.so_type
, t1.order_status
, t1.order_priority
, t1.promise_status
, t1.product_id
, t1.product_no
, t1.product_model
, t1.order_qty
, t1.bu_name
, t1.rcv_client_name
, t1.prepared_client_name
, t1.order_source
, t1.om_user_name
, t1.term_cust
, t1.to_pur_time
, t1.factory_no
, t1.mo_lot_no
, t1.completed_qty
, t1.mo_audit_status
, t1.req_arrival_time
, t1.mtr_ready_time
, t1.plan_promise_time
, t1.promise_date_change_reason
, t1.schedule_start_time
, t1.schedule_end_time
, t1.pps_type
, t1.pps_exception_info
, t1.promise_diff_day
, t1.promise_delivery_cycle
, t1.change_reason
, t1.client_abbr
, t1.item_type_product
, t1.match_forecast
, t1.software_flag
, t1.risk_level
, t1.risk_reason
, t1.ckd_type
, t1.crt_user
, t1.crt_time
, t1.upd_user
, t1.upd_time
, t1.crt_user_name
, t1.upd_user_name
, row_number() over (partition by t1.promise_id order by t1.version_id desc) rn
from bda${db_para}.bda_whole_pto_order t1
where version_id not like '%最新版本%'
and not exists (select 1 from bda${db_para}.bda_whole_pto_order t2 where version_id like '%最新版本%' and t1.promise_id = t2.promise_id )
) t1
left join bda${db_para}.bda_promise_history_record t2 on t1.promise_id = t2.promise_id and coalesce(t2.afterchangereason,'') = 'AGAIN_PLAN'
where t2.promise_id is null
and t1.rn = 1
;
-- CRM订单与工单关联
drop table if exists sda${db_para}.tmp_sda_delivety_complete_sr_sum_01;
create table if not exists sda${db_para}.tmp_sda_delivety_complete_sr_sum_01
as
select bu.dept_name bu_name
,t2.organization_id -- 20220701 wyr
-- ,'514' Organization_Id
,t1.item_code item_code
,cus.cus_name -- 收货客户
,t1.so_header_id
,t1.so_line_id so_line_id
,t1.so_code so_header_code
,t1.line_no so_line_code
,t2.wip_entity_name -- 工单号
,t2.lot_number -- 批次
,t2.Project_Name
,t1.om_user_name Om_User_Name -- 销管
,t1.sale_name sales_user -- 销售
,case when bsse.is_source_forecast = '1' and mio.planning_make_buy_code = '制造'
and mig.min_class like '%PC模块%' then date_add(t1.pur_start_time, 20)
when bsse.is_source_forecast = '1' and mio.planning_make_buy_code = '制造'
and mig.min_class not like '%PC模块%' then date_add(t1.pur_start_time, 35)
when bsse.is_source_forecast = '0' and mio.planning_make_buy_code = '制造'
and mig.min_class like'%PC模块%' then date_add(t1.pur_start_time, 25)
when bsse.is_source_forecast = '0' and mio.planning_make_buy_code = '制造'
and mig.min_class not like '%PC模块%' then date_add(t1.pur_start_time, 45)
when bsse.is_source_forecast is null and mio.planning_make_buy_code = '制造'
and mig.min_class like '%PC模块%' then date_add(t1.pur_start_time, 20)
when bsse.is_source_forecast is null and mio.planning_make_buy_code = '制造'
and mig.min_class not like '%PC模块%' then date_add(t1.pur_start_time, 30)
else t1.pur_start_time
end stat_date -- 统计日期 提交下采购日期 + 对应日期
,substr(t1.expected_delivery_date, 1, 10) delivety_time -- 计划发运日期
,substr(t1.crt_time, 1, 10) crm_create_time -- 销售订单创建时间
,substr(t1.pur_start_time, 1, 10) purchase_date -- 提交下采购时间
,substr(t1.produce_start_time, 1, 10) produce_date -- 下生产时间
,substr(t2.Xwh_Creation_Date, 1, 10) wip_create_date -- 委外工单创建日期
,substr(t2.Scheduled_Start_Date, 1, 10) Scheduled_Start_Date -- 工单齐套日期
,substr(t2.Mc_Creation_Date, 1, 10) Mc_Creation_Date -- 生管确认时间
,substr(t2.first_trx_date, 1, 10) first_finish_date -- 首次完工入库日期
,substr(t2.last_trx_date, 1, 10) last_finish_date -- 完全完工入库日期
,t1.so_type_name order_type -- 订单类型
,t2.wip_job_status -- 工单状态
,t2.Job_Type -- 工单类型
,t2.Class_Code -- 工单分类
,t2.Quantity_Completed -- 工单已完工数量
,t1.qty -- 订单数量
,case when t6.order_no is not null then t6.match_forecast else bsse.is_source_forecast end as is_source_forecast -- 订单有无预测
,mio.planning_make_buy_code -- 整机加工模式 制造/采购
,case when mig.min_class like '%PC模块%' then 'PC模块' else '其他' end prod_type
,datediff(t2.last_trx_date, t1.pur_start_time) supply_cycle -- 供应链周期 (取多个工单中最早的完工入库时间,计算供应链周期)
,case when t1.so_type_name <> '备品订单' and t2.first_trx_date is not null then 'Y' else 'N' end supply_cycle_flag -- 供应链周期标识
,case when t1.so_type_name = '客户订单' and t2.Job_Type = '标准'
and (
(bsse.is_source_forecast = '1' and mio.planning_make_buy_code = '制造'
and mig.min_class like '%PC模块%' and datediff(t2.first_trx_date, t1.pur_start_time) <= 20)
or
(bsse.is_source_forecast = '1' and mio.planning_make_buy_code = '制造'
and mig.min_class not like '%PC模块%' and datediff(t2.first_trx_date, t1.pur_start_time) <= 35)
or
(bsse.is_source_forecast = '0' and mio.planning_make_buy_code = '制造'
and mig.min_class like '%PC模块%' and datediff(t2.first_trx_date, t1.pur_start_time) <= 25)
or
(bsse.is_source_forecast = '0' and mio.planning_make_buy_code = '制造'
and mig.min_class not like '%PC模块%' and datediff(t2.first_trx_date, t1.pur_start_time) <= 45)
or
(bsse.is_source_forecast is null and mio.planning_make_buy_code = '制造'
and mig.min_class like '%PC模块%' and datediff(t2.first_trx_date, t1.pur_start_time) <= 20)
or
(bsse.is_source_forecast is null and mio.planning_make_buy_code = '制造'
and mig.min_class not like '%PC模块%' and datediff(t2.first_trx_date, t1.pur_start_time) <= 35)
) and t2.first_trx_date is not null then 'Y'
else 'N' end delivety_complete_flag -- 交付达成标识
,case when t1.so_type_name in ('客户订单','销售订单') and t2.Job_Type = '标准' then 'Y' else 'N' end is_delivety_complete_flag -- 交付达成标识
,t1.expected_delivery_date overseas_stat_date -- 海外订单交付达成归集时间
,case when t1.so_type_name in ('客户订单','销售订单') -- and bsse.is_source_forecast is not null
and datediff(t2.last_trx_date, t1.expected_delivery_date) <= 0 and t2.last_trx_date is not null then 'Y'
else 'N' end overseas_is_delivety_complete_flag -- 海外订单交付达成标识
,case when t1.so_type_name in ('客户订单','销售订单') -- and bsse.is_source_forecast is not null
and (datediff('${bizDate}', t1.expected_delivery_date) >= 0
or (datediff('${bizDate}', t1.expected_delivery_date) < 0 and datediff(t2.last_trx_date, t1.expected_delivery_date) <= 0)
) then 'Y'
else 'N' end overseas_delivety_complete_flag -- 海外订单交付达成数据范围
,row_number() over(partition by t2.Lot_Number order by t1.pur_start_time) rn
,t2.Start_Quantity wip_qty
,t2.fisrt_picking_date -- 首次领料时间
,t3.first_ship_date
,t3.last_ship_date
,-1*trx33.shipped_qty shipped_qty -- 已出货数量
,t2.Quantity_Completed + trx33.shipped_qty as difference_qty -- 差异
,dmpm.screen_size -- 尺寸
,t2.Created_By as pm_user -- 生管负责人
,substr(t3.min_scheduled_date, 1, 10) as min_scheduled_date -- 实际齐套日期
,substr(t5.min_produce_DATE, 1, 10) min_produce_date
,t1.bt_name -- add by tjl 2022.07.21
,bsse.so_line_group_id --
,substr(t3.online_date, 1, 10) as online_date
,datediff(substr(t1.expected_delivery_date, 1, 10),substr(t1.pur_start_time, 1, 10)) as cus_expect_cycle -- 客户期望周期
,case when t6.order_no is not null and t6.plan_promise_time is not null then datediff(substr(t6.plan_promise_time,1,10),substr(t1.pur_start_time, 1, 10)) -- 如有承诺日期 预计供应链=承诺日期-下采购日期
when t6.order_no is not null and t6.plan_promise_time is null and t2.wip_entity_name is null then datediff(date_add(substr(t6.mtr_ready_time, 1, 10),6),substr(t1.pur_start_time, 1, 10)) -- 无承诺日期 未开工单,= 齐套日期+6
when t2.wip_entity_name is not null and t3.online_date is not null then datediff(date_add(substr(t3.online_date, 1, 10),4),substr(t1.pur_start_time, 1, 10)) -- 已开工单,已有上线日期,=上线日期+4
when t2.wip_entity_name is not null and t3.online_date is null then datediff(date_add(substr(t2.Scheduled_Start_Date, 1, 10),6),substr(t1.pur_start_time, 1, 10)) -- 已开工单,暂无上线日期,=齐套日期+6
end as estimate_supply_cycle -- 预计供应链周期
,t8.cus_level
-- from bda${db_para}.bda_oms_so_lines t1
FROM bda${db_para}.bda_sd_so t1
left join bda${db_para}.bda_sd_so_ext bsse
on t1.so_line_id = bsse.so_line_id
and bsse.part_dt IN ('crm_so', 'oms_so')
join bda${db_para}.bda_job_inv_trx_zj_dtl t2
on bsse.so_line_group_id = t2.source_line_id
-- and t1.so_header_id = t2.source_header_id
left join dim${db_para}.dim_hcm_orgunit bu
on t1.bill_bu_id = bu.dept_oid
left join bda${db_para}.comm_market_cus cus
on t1.rec_cus_code = cus.id
-- join (select item_value, fullname
-- from o_crm${db_para}.comm_dictionary_detail
-- where parentcode = '$CRM_DELIVERY_SO_TYPE') cdd
-- on cdd.item_value = t1.so_type
left join dim${db_para}.md_item_group mig
on t2.item_code = mig.item_code
left join dim${db_para}.md_item_org mio
on t1.item_code = mio.item_code
and mio.Organization_Id = '514'
left join dim${db_para}.dim_md_prod_model dmpm
on mig.product_model = dmpm.prod_model
left join bda${db_para}.bda_job_dtl t3
on t2.wip_entity_name = t3.wip_entity_name
left join o_md${db_para}.md_prod_model t4
on mig.product_model = t4.product_model
left join (select sum(trx_so.trx_qty) shipped_qty
,trx_so.bch_nbr
from bda${db_para}.bda_inv_item_trx_bach_dtl trx_so
where trx_so.trx_type_id = 33
group by trx_so.bch_nbr) trx33
on trx33.bch_nbr = t2.lot_number
left join sda${db_para}.tmp_sda_delivety_complete_sr_sum_00 t5 on t5.mo_lot_no = t2.lot_number
left join sda${db_para}.tmp_sda_delivety_complete_sr_sum_01_1 t6
on t1.line_code = t6.order_no
left join bda${db_para}.bda_wip_mo_header t7 on t3.wip_entity_name = t7.ebs_mo_code
left join (select t.cus_code
, t2.hcm_dept_oid as dept_oid
, max(t.cus_level) as cus_level_id
, max(t1.fullname) as cus_level
, t2.hcm_dept_name as dept_name
from o_crm${db_para}.cus_bu_ext_info t
left join o_crm${db_para}.comm_dictionary_detail t1
on t.cus_level = t1.item_value
and t1.parentcode = '$CRM_CUS_LEVEL'
inner join dim${db_para}.dim_hcm_crm_org_map t2
on t.bu_code = t2.dept_code
where t2.dept_name not like '%失效%'
and t.is_deleted = '0'
and t2.hcm_dept_oid is not null
group by t.cus_code,t2.hcm_dept_oid,t2.hcm_dept_name) t8
on t1.rec_cus_code = t8.cus_code
and bu.dept_oid = t8.dept_oid
where t1.pur_start_time is not null
and t1.is_onhand_out in ('0','否')
and t4.finished_or_semi_finished_prod = '成品'
AND t1.part_dt IN ('crm_so', 'oms_so')
and t3.wip_job_status<>'已取消' and (t3.wip_job_status<>'已关闭' or t3.quantity_completed >0)
and coalesce(t7.source_demand_max,'')<>'相关需求'
;
insert overwrite table sda${db_para}.sda_delivety_complete_sr_sum
select t.bu_name
,t.Organization_Id
,t.item_code
,t.cus_name -- 收货客户
,t.so_header_code
,t.so_line_code
,t.wip_entity_name
,t.lot_number
,t.Project_Name
,t.Om_User_Name -- 销管
,t.sales_user -- 销售
,t.delivety_time -- 计划发运日期
,t.crm_create_time -- 销售订单创建时间
,t.purchase_date -- 提交下采购时间
,t.produce_date -- 下生产时间
,t.stat_date -- 统计日期 提交下采购日期 + 对应日期
,t.wip_create_date -- 委外工单创建日期
,t.Scheduled_Start_Date -- 工单齐套日期
,t.Mc_Creation_Date -- 生管确认时间
,t.first_finish_date -- 首次完工入库日期
,t.last_finish_date -- 完全完工入库日期
,t.order_type -- 订单类型
,t.job_type
,t.supply_cycle -- 供应链周期
,t.supply_cycle_flag -- 供应链周期标识
,t.delivety_complete_flag -- 交付达成标识
,t.is_delivety_complete_flag
,t.overseas_stat_date
,t.overseas_is_delivety_complete_flag
,t.overseas_delivety_complete_flag
,t.is_source_forecast is_source_forecast
,t.wip_qty
,t.fisrt_picking_date
,t.first_ship_date
,t.last_ship_date
,'MTO' order_mode
,current_timestamp()
,'${bizDate}'
,t.shipped_qty -- 已出货数量
,t.difference_qty -- 差异
,t.screen_size -- 尺寸
,t.pm_user -- 生管负责人
,t.min_scheduled_date
,t.min_produce_date
,t.bt_name -- add by tjl 2022.07.21
,t.so_line_group_id
,t.Class_Code -- add by wyr 2022.09.23
,t.cus_level as cus_level -- tjl 2022.11.02
,t.cus_expect_cycle as cus_expect_cycle -- 客户期望周期 -- add by tjl 2022.11.02
,t.estimate_supply_cycle as estimate_supply_cycle -- 预计供应链周期 -- add by tjl 2022.11.02
from sda${db_para}.tmp_sda_delivety_complete_sr_sum_01 t
where t.rn = 1
;
"""
result = LineageRunner(sql.replace("${db_para}",''))
print(result.source_tables)
print(result.target_tables)
if __name__ == "__main__":
test_create_as()
#!/usr/bin/python3
# coding=utf8
# -----------------------------------------------------------------------------------
# 日 期:2022.08.30
# 作 者:zds
# 用 途: 数仓Hive血缘
# 1. 通过Trino查询数据库,获取数栖平台调度DAG血缘关系
# 2. 注意:直接操作数据库修改权限,BI有大概几分钟的缓存时间,需要等待数据更新。
# 3. 注意:fine_pack_filter中create_type=3,是用户角色。使用的rowid = fine_user中的id,在最终用户权限上配置的。
# . 4. "且" = 34;"或"=35
# 5. 依赖数仓中manual开头的表,这些表通过爬虫采集,数据延迟一天
# -----------------------------------------------------------------------------------
import json
import time
import datetime
import base64
import re
import pandas as pd
from simple_ddl_parser import DDLParser
from sqlalchemy import create_engine
from sqllineage.runner import LineageRunner
import datahub.emitter.mce_builder as builder
from datahub.emitter.rest_emitter import DatahubRestEmitter
class DWHiveLineage:
def __init__(self):
self.shuxi_db = create_engine("mysql+pymysql://xxxx@p-dbsec-mysql.gz.cvte.cn:10006/uic")
def get_task_sql(self):
# tasktype_id in (4,8,11,12,16) 全部有源码的任务
sql = """
select cata_id,flow_id,task_id,task_name,task_type_name,source, parameter from (
select rtc.task_id ,rtc.source,rtc.parameter,bt.task_name,bt.tasktype_id,btt.task_type_name,bc.cata_id,bc.flow_id
from dipper.rel_task_config rtc
left join (
select task_name,tasktype_id,task_id,flow_id from dipper.bas_task where tasktype_id in (12,16) and tasktype_id is not null
and ws_id = 11 and invalid = 0
)bt on rtc.task_id = bt.task_id
left join dipper.bas_tasktype btt on btt.tasktype_id = bt.tasktype_id
left join (select * from dipper.bas_cata where invalid = 0 and ws_id = 11) bc on bc.flow_id = bt.flow_id
)t where t.source is not null and t.task_name is not null
order by flow_id
"""
df = pd.read_sql(sql=sql, con=self.shuxi_db)
return df
def list_lineages(self):
df = self.get_task_sql()
dataset_lineages = {}
idx = 0
for row in df.to_dict(orient="records"):
try:
sql = base64.b64decode(row['source']).decode('utf-8')
print("============" + row['task_name'] + "========")
result = LineageRunner(sql.replace("${db_para}", ''))
# 一个文件中有多个SQL语句,需要拆分处理
if len(result.target_tables) > 2:
print("目标表有多个,需要拆分SQL再计算血缘:【{}】".format(result.target_tables))
else:
dataset_lineages[str(result.target_tables[0])] = [str(t) for t in self.source_tables]
idx += 1
except Exception as e:
print("解析任务【{}】SQL失败。".format(row['task_name']))
print(e)
break
if idx > 10:
break
return dataset_lineages
def generate_lineages(self):
result_tables = self.list_lineages()
for target_table in result_tables.keys():
input_tables_urn = []
for source_table in result_tables[target_table]:
input_tables_urn.append(builder.make_dataset_urn("hive", source_table))
# Construct a lineage object.
lineage_mce = builder.make_lineage_mce(
input_tables_urn,
builder.make_dataset_urn("hive", target_table),
)
# Create an emitter to the GMS REST API.
emitter = DatahubRestEmitter("http://xx.xx.xx.xx:8080")
# Emit metadata!
emitter.emit_mce(lineage_mce)
try:
emitter.emit_mce(lineage_mce)
print("添加数仓表 【{}】血缘成功".format(target_table))
except Exception as e:
print("添加数仓表 【{}】血缘失败".format(target_table))
print(e)
break
if __name__ == "__main__":
dw = DWHiveLineage()
dw.generate_lineages()
有疑问,欢迎留言讨论
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我是Rails的新手,所以请原谅简单的问题。我正在为一家公司创建一个网站。那家公司想在网站上展示它的客户。我想让客户自己管理这个。我正在为“客户”生成一个表格,我想要的三列是:公司名称、公司描述和Logo。对于名称,我使用的是name:string但不确定如何在脚本/生成脚手架终端命令中最好地创建描述列(因为我打算将其设置为文本区域)和图片。我怀疑描述(我想成为一个文本区域)应该仍然是描述:字符串,然后以实际形式进行调整。不确定如何处理图片字段。那么……说来话长:我在脚手架命令中输入什么来生成描述和图片列? 最佳答案 对于“文本”数
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些