不知不觉这已经是我的第四篇文章了,如果有机会下次应该是分享关于分割的一些知识;无论你是仅仅想跑通代码还是其他原因,我觉得都应该了解其相关的知识再去搞一搞代码。
yolov5+deepsort
在这里简单概述一下目标跟踪算法:主要分为传统的目标跟踪算法,基于深度学习的目标跟踪算法、也可以分为基于检测的目标跟踪算法(目标检测网络+跟踪部分yolov3/yolov5+deepsort/sort),基于孪生网络的跟踪算法(Sima系列),基于相关滤波的跟踪算法(MOSSE、KCF、CSK、DSST),也可以分为单目标跟踪(SOT)、多目标跟踪(MOT),大家可以自行百度一下他们。
现在很多跟踪算法都是基于单目标的目标跟踪,因为单目标跟踪是基于区域的搜索策略,会在一定的范围内去跟踪而不是全局的进行搜索去跟踪也可以称为局部跟踪;单目标跟踪通过输入第一帧的目标特征进行跟踪。基于检测的多目标跟踪:无论你第一帧是否存在目标都可以在全局进行搜索跟踪这就是基于检测的好处。
下面简单介绍一下yolov5+deepsort(基于检测的目标跟踪(全局跟踪))原理:
整体的原理流程如下:

大体的可以从图上看出:通过检测当前帧的图片和经过卡尔曼滤波预测的图片首先进行级联匹配得到三个状态(匹配成功、未匹配的预测、未匹配的检测)我觉得最不重要的应该是预测结果,让后对未匹配的结果在进行IOU匹配得到三个状态(匹配成功、未匹配的预测、未匹配的检测),没有匹配的检测结果作为新的跟踪目标,如果是没有匹配的预测(这里MAX_AGE跟踪轮数,假如我运行了70次你还是没有被匹配上你就直接被删除),这里面有一个确定态和非确定态我没有太看懂怎么区分的(有大佬可以教我一下感激不尽),所有的结果输入到卡尔曼滤波中进行一个滤波器的参数更新,因为每一帧跟踪完后为了跟踪效果更好肯定要更新跟踪参数。
大家可能会问什么是卡尔曼滤波、级联(Cascade)匹配、iou匹配?
卡尔曼滤波可以看一下视频点击一下,主要了解数据融合、卡尔曼增益、协方差矩阵、状态空间方程等(自我感觉还是有点难度)
级联匹配:主要包括外观特征、马氏距离构成的代价函数。
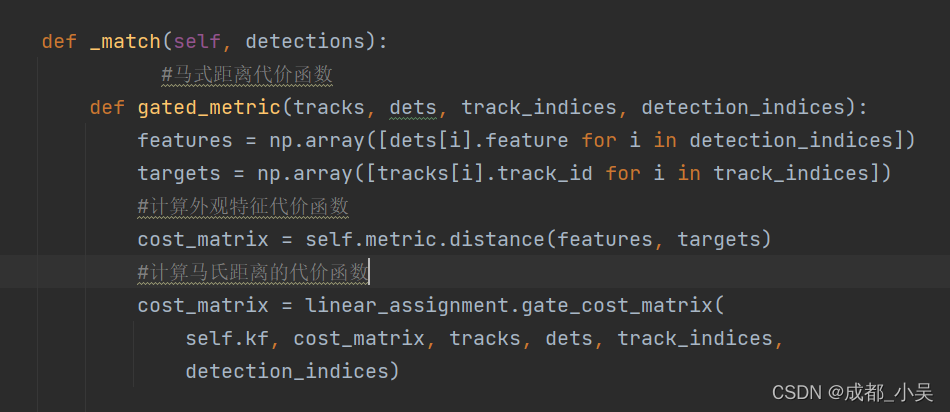
这里的外观特征是通过我们下载的行人重识别网络权重CKpt.T7这个进行提取特征,如果大家是对人的跟踪我觉得是没有必要进行重新训练跟踪的模型,通过提取检测和预测框的特征来计算代价函数。
马氏距离通俗的也可以理解为两个框的欧氏距离来判定关联程度,(欧氏距离就是比作距离嘛这么理解比较方便)
如果你是其他的跟踪模型可以参考这篇博客![]() https://blog.csdn.net/weixin_50008473/article/details/122347582?ops_request_misc=%7B
https://blog.csdn.net/weixin_50008473/article/details/122347582?ops_request_misc=%7B
我们得到cosine 代价函数进而计算马氏距离的代价函数,通过级联匹配得到三个状态量:
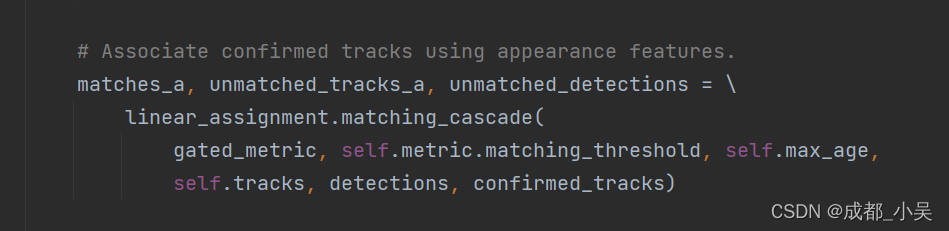
接下来就是IOU匹配:
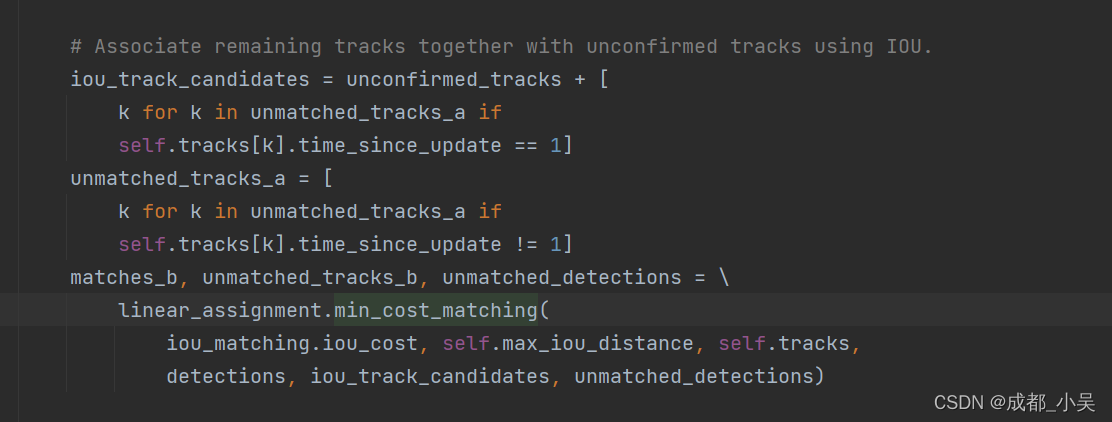
后续还有一些对未匹配到的预测结果处理部分这里不介绍了,有一些我也不是理解,核心的就这些;
deepsort 是在sort (只有IOU匹配)的基础 上加入了级联匹配(也就是这里的Cascade),
大概原理介绍完了我们来看一下我自己加的界面代码吧(这个代码是在我的第一篇文章上面进行改进添加的点击这里),我继续延用YOLOV5 4.0版本的代码,大家可以去官网下载也可以去我的第一篇博客下载权重添加至自己的YOLOV5文件夹下面。行人重识别权重我放在CSDN你们可以下载,下载完以后将其放在如下:

我还不会导入github上所以我没法上传我的源码,大家可以先下载官网源码
下载完源代码大家可以尝试运行一下track.py,在准确无误之后就可以搭建自己的界面了
第一部分模块导入:如果没有对应模块按要求下载。
import sys
from random import random
import numpy as np
sys.path.insert(0, './yolov5')
import threading
from yolov5.utils.google_utils import attempt_download
from yolov5.models.experimental import attempt_load
from yolov5.utils.datasets import LoadImages, LoadStreams
from yolov5.utils.general import check_img_size, non_max_suppression, scale_coords, \
check_imshow
from yolov5.utils.torch_utils import select_device, time_synchronized
from deep_sort_pytorch.utils.parser import get_config
from deep_sort_pytorch.deep_sort import DeepSort
import argparse
from yolov5.utils.datasets import letterbox
import os
import platform
import shutil
import time
from pathlib import Path
import cv2
import torch
import torch.backends.cudnn as cudnn
from PyQt5 import QtWidgets,QtCore,QtGui
from PyQt5.QtCore import *
from PyQt5.QtGui import *
from PyQt5.QtWidgets import *
from PyQt5.QtWidgets import QMainWindow
from untitled import Ui_MainWindow
第二部分类的创建以及参数的设置:包括界面无边框移动事件
class ui_main(QMainWindow):
def __init__(self):
super(ui_main, self).__init__()
self.timer_video = QtCore.QTimer() # 创建定时器
self.ui = Ui_MainWindow()
self.ui.setupUi(self)
self.init_slots()
self.palette = (2 ** 11 - 1, 2 ** 15 - 1, 2 ** 20 - 1)
self.setWindowFlags(Qt.FramelessWindowHint)
def mouseMoveEvent(self, e: QMouseEvent): # 重写移动事件
if self._tracking:
self._endPos = e.pos() - self._startPos
self.move(self.pos() + self._endPos)
def mousePressEvent(self, e: QMouseEvent):
if e.button() == Qt.LeftButton:
self._startPos = QPoint(e.x(), e.y())
self._tracking = True
def mouseReleaseEvent(self, e: QMouseEvent):
if e.button() == Qt.LeftButton:
self._tracking = False
self._startPos = None
self._endPos = None
def paintEvent(self, event):
painter = QPainter(self)
pixmap = QPixmap('./kehuan.jpg')
painter.drawPixmap(self.rect(), pixmap)第三部分函数绑定:
def init_slots(self):
# self.ui.pushButton_img.clicked.connect(self.button_image_open)
# self.ui.pushButton_video.clicked.connect(self.button_video_open)
#模型初始化
self.ui.pushButton_2.clicked.connect(self.model_init)
#打开视频
# self.ui.pushButton_4.clicked.connect(self.open_model)
# 打开摄像头
self.ui.pushButton_3.clicked.connect(self.button_camera_open)
#关闭程序
self.ui.pushButton.clicked.connect(self.finish_detect)
# 定时器超时,将槽绑定至show_video_frame第四部分是源码边框绘制函数:
def xyxy_to_xywh(self,*xyxy):
"""" Calculates the relative bounding box from absolute pixel values. """
bbox_left = min([xyxy[0].item(), xyxy[2].item()])
bbox_top = min([xyxy[1].item(), xyxy[3].item()])
bbox_w = abs(xyxy[0].item() - xyxy[2].item())
bbox_h = abs(xyxy[1].item() - xyxy[3].item())
x_c = (bbox_left + bbox_w / 2)
y_c = (bbox_top + bbox_h / 2)
w = bbox_w
h = bbox_h
return x_c, y_c, w, h
def xyxy_to_tlwh(self,bbox_xyxy):
tlwh_bboxs = []
for i, box in enumerate(bbox_xyxy):
x1, y1, x2, y2 = [int(i) for i in box]
top = x1
left = y1
w = int(x2 - x1)
h = int(y2 - y1)
tlwh_obj = [top, left, w, h]
tlwh_bboxs.append(tlwh_obj)
return tlwh_bboxs
def compute_color_for_labels(self,label):
"""
Simple function that adds fixed color depending on the class
"""
color = [int((p * (label ** 2 - label + 1)) % 255) for p in self.palette]
return tuple(color)
@pyqtSlot()
def finish_detect(self):
self.close()
def draw_boxes(self,img, bbox, identities=None, offset=(0, 0)):
for i, box in enumerate(bbox):
x1, y1, x2, y2 = [int(i) for i in box]
x1 += offset[0]
x2 += offset[0]
y1 += offset[1]
y2 += offset[1]
# box text and bar
id = int(identities[i]) if identities is not None else 0
color = self.compute_color_for_labels(id)
label = '{}{:d}'.format("", id)
t_size = cv2.getTextSize(label, cv2.FONT_HERSHEY_PLAIN, 2, 2)[0]
cv2.rectangle(img, (x1, y1), (x2, y2), color, 3)
cv2.rectangle(
img, (x1, y1), (x1 + t_size[0] + 3, y1 + t_size[1] + 4), color, -1)
cv2.putText(img, label, (x1, y1 +
t_size[1] + 4), cv2.FONT_HERSHEY_PLAIN, 2, [255, 255, 255], 2)
return img第五部分模型初始化:
def model_init(self):
print("模型初始化")
parser = argparse.ArgumentParser()
parser.add_argument('--yolo_weights', type=str, default='yolov5/weights/yolov5s.pt', help='model.pt path')
parser.add_argument('--deep_sort_weights', type=str, default='deep_sort_pytorch/deep_sort/deep/checkpoint/ckpt.t7', help='ckpt.t7 path')
# file/folder, 0 for webcam
parser.add_argument('--source', type=str, default='0', help='source')
parser.add_argument('--output', type=str, default='inference/output', help='output folder') # output folder
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.4, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.5, help='IOU threshold for NMS')
parser.add_argument('--fourcc', type=str, default='mp4v', help='output video codec (verify ffmpeg support)')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--show-vid', action='store_true', help='display tracking video results')
parser.add_argument('--save-vid', action='store_true', help='save video tracking results')
parser.add_argument('--save-txt', action='store_true', help='save MOT compliant results to *.txt')
# class 0 is person, 1 is bycicle, 2 is car... 79 is oven
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 16 17')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--evaluate', action='store_true', help='augmented inference')
parser.add_argument("--config_deepsort", type=str, default="deep_sort_pytorch/configs/deep_sort.yaml")
self.args = parser.parse_args()
# self.args.img_size = check_img_size(self.args.img_size)
out, source, yolo_weights, deep_sort_weights, imgsz = self.args.output, self.args.source, self.args.yolo_weights, self.args.deep_sort_weights ,self.args.img_size
# initialize deepsort加载deepsort的各种参数设置和模型
cfg = get_config()
print(1)
cfg.merge_from_file(self.args.config_deepsort)
print(2)
self.depp_wights = attempt_download(deep_sort_weights, repo='mikel-brostrom/Yolov5_DeepSort_Pytorch')
print(3)
self.deepsort = DeepSort(cfg.DEEPSORT.REID_CKPT,
max_dist=cfg.DEEPSORT.MAX_DIST, min_confidence=cfg.DEEPSORT.MIN_CONFIDENCE,
nms_max_overlap=cfg.DEEPSORT.NMS_MAX_OVERLAP, max_iou_distance=cfg.DEEPSORT.MAX_IOU_DISTANCE,
max_age=cfg.DEEPSORT.MAX_AGE, n_init=cfg.DEEPSORT.N_INIT, nn_budget=cfg.DEEPSORT.NN_BUDGET,
use_cuda=True)
# Initialize
print(1)
self.device = select_device(self.args.device)
self.half = self.device.type != 'cpu' # half precision only supported on CUDA
cudnn.benchmark = True
# Load model
self.model = attempt_load(yolo_weights, map_location=self.device) # load FP32 model
stride = int(self.model.stride.max()) # model stride
self.imgsz = check_img_size(imgsz, s=stride) # check img_size
if self.half:
self.model.half() # to FP16
# if webcam:
# set True to speed up constant image size inference
# dataset = LoadStreams(source, img_size=imgsz, stride=stride)
# else:
# dataset = LoadImages(source, img_size=imgsz)
# Get names and colors
self.names = self.model.module.names if hasattr(self.model, 'module') else self.model.names
self.colors = [[random.randint(0, 255) for _ in range(3)] for _ in self.names]
# Run inference
print("model initial done")
QtWidgets.QMessageBox.information(self, u"Notice", u"模型加载完成", buttons=QtWidgets.QMessageBox.Ok,
defaultButton=QtWidgets.QMessageBox.Ok)
# if self.device.type != 'cpu':
# self.model(torch.zeros(1, 3, imgsz, imgsz).to(self.device).type_as(next(self.model.parameters()))) # run once
# t0 = time.time()
# save_path = str(Path(out))
# # extract what is in between the last '/' and last '.'
# txt_file_name = source.split('/')[-1].split('.')[0]
# txt_path = str(Path(out)) + '/' + txt_file_name + '.txt'第六部分检测函数:
def detect(self,name_list,img):
showing = img
with torch.no_grad():
img = letterbox(img, new_shape=self.opt.img_size)[0]
# for frame_idx, (path, img, im0s, vid_cap) in enumerate(dataset):
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(self.device)
img = img.half() if self.half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Inference
t1 = time_synchronized()
pred = self.model(img, augment=self.args.augment)[0]
# Apply NMS
pred = non_max_suppression(
pred, self.args.conf_thres, self.args.iou_thres, classes=self.args.classes, agnostic=self.args.agnostic_nms)
t2 = time_synchronized()
# Process detections
for i, det in enumerate(pred): # detections per image
# if webcam: # batch_size >= 1
# p, s, im0 = path[i], '%g: ' % i, im0s[i].copy()
# else:
# p, s, im0 = path, '', im0s
#
# s += '%gx%g ' % img.shape[2:] # print string
# save_path = str(Path(out) / Path(p).name)
if det is not None and len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(
img.shape[2:], det[:, :4], showing.shape).round()
# Print results
# for c in det[:, -1].unique():
# n = (det[:, -1] == c).sum() # detections per class
# s += '%g %ss, ' % (n, self.names[int(c)]) # add to string
xywh_bboxs = []
confs = []
# Adapt detections to deep sort input format
for *xyxy, conf, cls in det:
# to deep sort format
x_c, y_c, bbox_w, bbox_h = self.xyxy_to_xywh(*xyxy)
xywh_obj = [x_c, y_c, bbox_w, bbox_h]
xywh_bboxs.append(xywh_obj)
confs.append([conf.item()])
xywhs = torch.Tensor(xywh_bboxs)
confss = torch.Tensor(confs)
# pass detections to deepsort
outputs = self.deepsort.update(xywhs, confss, img)
# draw boxes for visualization
if len(outputs) > 0:
bbox_xyxy = outputs[:, :4]
identities = outputs[:, -1]
single_info = self.draw_boxes(img, bbox_xyxy, identities)
info_show = info_show+single_info+"\n"
# to MOT format
tlwh_bboxs = self.xyxy_to_tlwh(bbox_xyxy)
# Write MOT compliant results to file
# if save_txt:
# for j, (tlwh_bbox, output) in enumerate(zip(tlwh_bboxs, outputs)):
# bbox_top = tlwh_bbox[0]
# bbox_left = tlwh_bbox[1]
# bbox_w = tlwh_bbox[2]
# bbox_h = tlwh_bbox[3]
# identity = output[-1]
# with open(txt_path, 'a') as f:
# f.write(('%g ' * 10 + '\n') % (frame_idx, identity, bbox_top,
# bbox_left, bbox_w, bbox_h, -1, -1, -1, -1)) # label format
else:
self.deepsort.increment_ages()第七部分是大家一直都想找的如何解决界面调用摄像头检测卡顿问题的代码,我在这里分享给大家禁止转发,谢谢大家!(如果有大佬可以纠正一下我的错误因为我只能这样写才能缓解当下的速度延迟问题)
def button_camera_open(self):
print("Open camera to detect")
# 设置使用的摄像头序号,系统自带为0
# camera_num ='rtsp://192.168.42.22'
# 'rtsp://admin:htkt12345@192.168.1.64:554/' 'rtsp://192.168.42.22/202202261154CHN1.264'
# camera_num = 0
# 打开摄像头
self.cap = cv2.VideoCapture(0)
# 判断摄像头是否处于打开状态
bool_open = self.cap.isOpened()
# now3 = time.time()
# print(now3)
if not bool_open:
QtWidgets.QMessageBox.warning(self, u"Warning", u"打开摄像头失败", buttons=QtWidgets.QMessageBox.Ok,
defaultButton=QtWidgets.QMessageBox.Ok)
else:
fps, w, h, save_path = self.set_video_name_and_path()
# fps = 30 # 控制摄像头检测下的fps,Note:保存的视频,播放速度有点快,我只是粗暴的调整了FPS
# self.vid_writer = cv2.VideoWriter(save_path,
# cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))#视频保存
self.timer_video.timeout.connect(self.show_video_frame)
self.timer_video.start(1)
self.ui.pushButton_3.setDisabled(True)
# t = threading.Thread(target=self.show_video_frame)
# t.start()
def show_video_frame(self):
self.n += 1
flag, img = self.cap.read()
# 获取视频帧读取
if self.n % 4 == 0:
# print(self.n)
if img is not None:
# 开启子线程进行检测
p = threading.Thread(target=self.detection, args=(img,))
p.start()
# # 暂停与继续检测
def detection(self, img):
name_list = []
# print(x)
info_show = self.detect(name_list, img) # 检rif测结果写入到原始img上
show = cv2.resize(img, (640, 640)) # 直接将原始img上的检测结果进行显示
self.result = cv2.cvtColor(show, cv2.COLOR_BGR2RGB)
showImage = QtGui.QImage(self.result.data, self.result.shape[1], self.result.shape[0],
QtGui.QImage.Format_RGB888)
self.ui.label_2.setFixedSize(758, 424)
self.ui.label_2.setPixmap(QtGui.QPixmap.fromImage(showImage))
self.ui.label_2.setScaledContents(True)
if __name__ == '__main__':
app = QtWidgets.QApplication(sys.argv)
ui = ui_main()
qssStyle = '''
QLabel {
border:1px solid white
}
QPushButton{
background:transparent;
font: bold 16px;
border:1px solid white
}
'''
ui.setStyleSheet(qssStyle)
ui.show()
sys.exit(app.exec_())
这么快就结束了,如果有什么建议可以进群交流学习:471550878
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
参考文章搭建文章gitte源码在线体验可以注册两个号来测试演示图:一.整体介绍 介绍SignalR一种通讯模型Hub(中心模型,或者叫集线器模型),调用这个模型写好的方法,去发送消息。 内容有: ①:Hub模型的方法介绍 ②:服务器端代码介绍 ③:前端vue3安装并调用后端方法 ④:聊天室样例整体流程:1、进入网站->调用连接SignalR的方法2、与好友发送消息->调用SignalR的自定义方法 前端通过,signalR内置方法.invoke() 去请求接口3、监听接受方法(渲染消息)通过new signalR.HubConnectionBuilder().on
在Rails3.x应用程序中,我正在使用net::ssh并向远程pc运行一些命令。我想向用户的浏览器显示实时日志。比如,如果两个命令在net中运行::ssh执行即echo"Hello",echo"Bye"被传递然后"Hello"应该在执行后立即显示在浏览器中。这是代码我在rubyonrails应用程序中使用ssh连接和运行命令Net::SSH.start(@servers['local'],@machine_name,:password=>@machine_pwd,:timeout=>30)do|ssh|ssh.open_channeldo|channel|channel.requ
文章目录🔥Linux系统目录结构🔥Linux用户和用户组🔥Linux用户管理🔥Linux系统目录结构文件系统组织结构⭐ /lib系统开机所需要最基本的动态链接共享库,其作用类似于Windows里的DLL文件。几乎所有的应用程序都需要用到这些共享库。⭐ /lost+found一般情况下是空的,当系统非法关机后,这里就存放了一些文件。⭐ /etc所有系统管理所需要的配置文件和子目录my.conf⭐ /usr用户的很多应用程序和文件都放在这个目录下。⭐ /bin是Binary的缩写,这个目录存放着经常使用的命令⭐ /sbin(usr/sbin、/usr/local/sbin)sbin就是peruse
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
我想使用Rails3创建一个公共(public)实时聊天应用程序。我在rails2上找到了一些例子。任何人都可以告诉你一个很好的例子/教程来使用rails3开发一个实时聊天应用程序。 最佳答案 当我试图在我的Rails3应用程序中实现一个公共(public)和私有(private)聊天系统时,我遇到了几个障碍。我查看了faye、juggernaut、node.js等。最终在尝试了几种方法之后,我能够实现一个运行良好的系统:1)我开始关注Railscast260中的faye消息传递视频指南。正如DevinM所提到的,我能够快速设置一个
第一章Selenium+WebDriver环境搭建第二章Selenium定位方式第三章元素常用属性第四章自动化中的三种等待第五章自动化浏览器设置及句柄、窗口切换操作第六章鼠标、键盘操作第七章javascript在自动化中的应用第八章unittest&断言第九章ddt数据驱动第十章测试框架搭建过程Python+Selenium+BeautifulReport文章目录一、鼠标操作二、键盘操作一、鼠标操作1、在web测试中,鼠标的操作包含在ActionChains类中,经常用到的有单击、双击、右击、拖动等操作。2、在使用鼠标操作前需要先导入ActionChains类包:fromselenium.we
Anaconda+PyCharm+PyTorch(GPU)+虚拟环境声明一、安装Anaconda二、安装PyCharm三、创建虚拟环境并安装PyTorch四、关联虚拟环境五、致谢声明感谢姜小敏同学对我的支持、鼓励和鞭策!默认你的电脑上已经装有GPU,如果没有GPU,可以正常的进行各种下载安装操作,但是最终结果会有所不同。一、安装Anaconda首先,进入Anaconda官网,单击Download按钮,稍微等待即可下载安装包。下载好之后,双击打开安装包,进行一系列安装操作。建议安装路径全英文,并且一定要记住安装地址。此处不勾选第二项,因此之后需要人为配置环境变量。没啥用,不用勾选,就是跳出两个打
高科技摄像头特别是海康萤石摄像头,已经不再只局限于简单的视频功能,特别是智能AI的普及,摄像头也华丽变身成了一个个独立的智能个体,可以实现人脸抓拍,人形检测,客流统计等店铺值守场景,也可以实现安全帽识别,车辆识别,非法入侵识别等智慧工地场景。但用户也许会问,摄像头又不会说话,他得知的这些信息怎么告诉我们,还是说需要配一个主机去处理,这成本又有点太高了。这点正是萤石云要为大家解决的,下面来介绍下如何让设备更简便智能的说话。API(应用程序编程接口)提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力。形象一点API可以理解为一个管道,通过该管道,可以传入约定好的命令,来获得摄像头的反馈,
一、下载源代码打开终端,输入命令克隆仓库gitclonehttps://github.com/raulmur/DXSLAM.gitDXSLAM二、配置环境WehavetestedthelibraryinUbuntu16.04andUbuntu18.04,butitshouldbeeasytocompileinotherplatforms.C++11orC++0xCompilerPangolinOpenCVEigen3Dbow、Fbowandg2o(IncludedinThirdpartyfolder)tensorflow(1.12)作者提供了一个脚本build.sh来编译Thirdparty目