目录
简单的来说,指针就是地址。我们口头上说的指针其实指的是指针变量。指针变量就是一个存放地址的变量。
指针在32位机器下是4个字节,在64位机器下是8个字节。注:(指针的大小与类型无关)
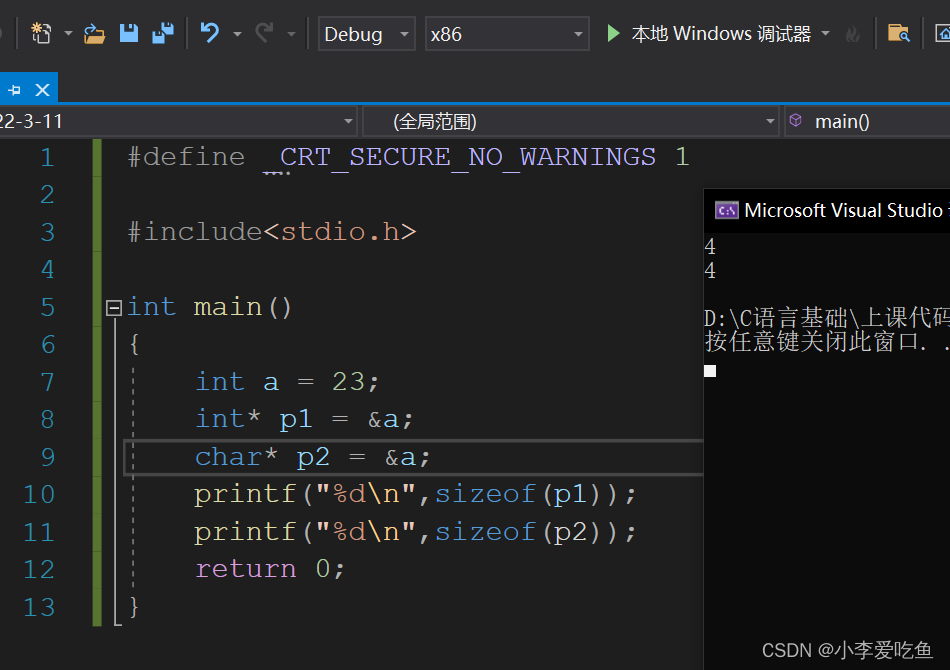
 1.3指针类型的作用
1.3指针类型的作用上面涉及到指针的大小与指针类型无关,那么指针类型的作用是什么呢?
指针解引用访问,使用的访问权限是多少 话不多说,上图!
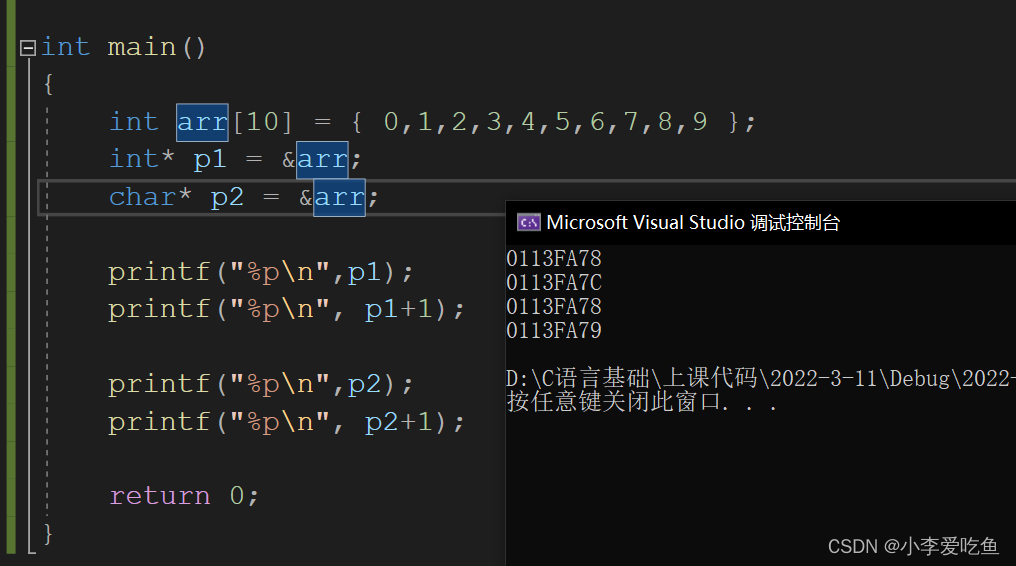
当一个int* 的指针+1,跳过4个字节;当一个char* 的指针+1,跳过1个字节。
同理,对于(指针+-整数)类的题也是如上的原理。
野指针顾名思义,指针指向的位置不可知,就像没有主人的流浪狗。
指针未被初始化
指针越界访问
指针指向的空间释放
对于前两点比较好理解,下面对第三点进行解释:
int* test( )
{
int a = 5;
return &a;
}
int main()
{
int* p = test();
*p = 10;
return 0;
}变量a的地址只在test()函数内有效,当把a的地址传给指针p时,因为出了test函数,变量a的空间地址释放,导致p变成了野指针。
- 小心越界
- 及时把指针赋成空指针
- 避免返回局部变量的地址
- 使用指针前检查有效性
此部分内容跟指针类型那部分一致
指针-指针的绝对值指的是两个指针之间元素的个数。
前提:两个指针必须指向同一空间
例如:&arr[9]-&arr[0]
下面举个例子实现my_strlen函数
int my_strlen(char str[])
{
char* p = str;
int count = 0;
while (*p != '\0')
{
p++;
count++;
}
return count;
}
int main()
{
char arr[] = "abcdef";
printf("%d\n",my_strlen(arr));
return 0;
}此部分内容很简单,指针与指针之间比较大小就是指针的关系运算。
例如:定义int* p1,数组int arr[5],p1>&arr[5]。
但是要遵循一个标准:允许指针指向数组元素和指针指向数组最后一个元素后面的位置进行比较,不允许指针指向数组元素与指针指向数组第一个位置的前面进行比较。
二级指针就是存放指针地址的指针变量。就像有三个抽屉第一个抽屉的钥匙放在第二个抽屉,第二个抽屉的钥匙放在第三个抽屉。
例如:int a=10;int* p1=&a;int** p2=&p1;
对int* * 做解释:第一个*号代表指针指向的类型是int*的,第二个*代表这个是指针。
数组名大家都很熟悉,但要区分以下几种情况:
- sizeof(arr):表示的是整个数组的大小。
- &arr: 表示整个数组,取出的是整个数组的大小。
其他情况数组名都表示数组首元素地址。
定义:存放指针的数组(int* arr[])。我们知道有整型类型的数组int arr[],还有字符类型的数组char arr[],指针数组就是指针类型的数组。
以下举个例:
int main()
{
int a = 0;
int b = 1;
int* p1 = &a;
int* p2 = &b;
int* arr[] = { p1,p2 };//指针数组
int* arr[] = { &a,&b };//指针数组
return 0;
}
- 定义: 指向数组的指针int (*)[]。
- 应用:遍历整个二维数组
void my_print(int(*p)[5], int x, int y)
{
int i = 0;
for (i = 0; i < x; i++)
{
int j = 0;
for (j = 0; j < y; j++)
{
printf("%d ", *(*(p + i) + j));
//printf("%d ", p[i][j]);相似的写法
}
printf("\n");
}
}
int main()
{
int arr1[3][5] = { {1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7} };
my_print(arr1, 3, 5);
return 0;
}
- int arr[5] //名为arr的数组,数组里有5个元素,每个元素是int
- int* p1[5] //指针数组,数组里有5个元素,每个元素是int*
- int (*p2)[5] //数组指针,一个指向数组(里面有五个元素,每个元素是int)的指 针
- int (*p3[5])[5] //p3[5]是一个有5个元素的数组,数组里每个元素是int(*)[5]
- 一维数组传参: int arr[10](形参部分数组大小可以不写)、int* arr
- 二维数组传参: int arr[3][5]、int arr[][5](行可以省略,列不能)、int (*arr)[5] 不能直接传数组名,二维数组的首地址是第一行元素的首地址
- 一级指针传参:int* p
- 二级指针传参:int** p
- 定义:指向函数的指针int (*pf) (int,int),pf函数返回的类型是int (*)(int,int)
- 对于函数来说如:Add和&Add,意义和值都一样。这一定要区别于数组。
- 特别的,当要调用函数时,定义一个pf的函数指针指向函数。那么int ret=(*pf)(2,3)和int ret=pf (2,3)等价。
**对下面代码的理解:
(*(void(*)())0)() // 将0处强制类型转换为函数指针类型,再对0地址 进行调用
void(*signal(int,void(*)(int)))(int) //这是函数的声明,singal是一个函数,传进去两个 参数的类型是int和void(*)(int),signal函数的返回值 类型是void(*)(int)。
- 定义:存放函数指针类型元素的数组
- 应用:实现计算器
#include<stdio.h>
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
void menu()
{
printf("****************\n");
printf("* 1.Add 2.Sub *\n");
printf("* 3.Mul 4.Div *\n");
printf("*** 0.exit ***\n");
printf("****************\n");
}
int main()
{
menu();
int input = 0;
printf("请选择:");
scanf("%d",&input);
int ret = 0;
//转移表
int(*pfarr[])(int, int) = { 0,Add,Sub,Mul,Div };
do
{
if (input == 0)
{
printf("退出\n");
break;
}
else if (input >= 1 && input <= 4)
{
int x = 0;
int y = 0;
printf("请输入两个操作数:");
scanf("%d%d",&x,&y);
ret = pfarr[input](x,y);
printf("结果是%d\n",ret);
break;
}
else
{
printf("选择错误!");
}
} while (input);
return 0;
}1.定义:int (*(*parr)[4])(int int)=&parr
- qsort()函数: 是一个库函数,基于快速排序算法实现的一个排序的函数。优点是,任意类型的数据都能排序。
- qsort()函数的形参定义:
void qsort(void* base(起始地址),size_t num(元素个数),size_t width(一个元素的字节长度),int (*cmp)(const void* e1,const void* e2)(自定义比较函数))
- qsort()函数应用:模拟计算器,排序结构体
//模拟计算器,对上面的代码进行优化
#include<stdio.h>
void print(int* str, int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", str[i]);
}
printf("\n");
}
void swap(char* e1, char* e2, int width)
{
int temp = 0;
int i = 0;
for (i = 0; i < width; i++)
{
temp = *e1;
*e1 = *e2;
*e2 = temp;
e1++;
e2++;
}
}
int cmp(const void* e1, const void* e2)
{
return (*(int*)e1 - *(int*)e2);//e1>e2-> >0;e1=e2-> 0;e1<e2-> <0
}
int bubble_sort(void* base, int num, int width, int(*cmp)(const int* e1, const int* e2))
{
int i = 0;
int j = 0;
for (i = 0; i < num - 1; i++)
{
for (j = 0; j < num - 1 - i; j++)
{
if (cmp((char*)base + j * width, (char*)base + (j + 1) * width)>0)
{
swap((char*)base + j * width, (char*)base + (j + 1) * width, width);
}
}
}
}
int main()
{
int arr[] = { 9,8,7,3,5,4,2,1,6,0 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr, sz, sizeof(arr[0]), cmp);
print(arr, sz);
return 0;
}//排序结构体
#include<stdio.h>
struct Student
{
char name[20];
int age;
double score;
};
int cmp_name(const void* e1, const void* e2)
{
return strcmp(((struct Student*)e1)->name, ((struct Student*)e2)->name);
}
int main()
{
struct Student arr[] = { {"zhang",17,80.6},{"wang",20,85.2},{"li",19,92.0} };
int sz = sizeof (arr) / sizeof (arr[0]);
qsort(arr,sz,sizeof (arr[0]),cmp_name);
return 0;
}
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我希望将Favorite模型添加到我的User和Link模型。业务逻辑用户可以有多个链接(即可以添加多个链接)用户可以收藏多个链接(他们自己的或其他用户的)一个链接可以被多个用户收藏,但只有一个所有者我对如何为这种关联建模以及在模型就位后如何创建用户收藏夹感到困惑?classUser 最佳答案 下面的数据模型怎么样:classUser:destroyhas_many:favorite_links,:through=>:favorites,:source=>:linkendclassLink:destroyhas_many:favor
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
>>a=5=>5>>b=a=>5>>b=4=>4>>a=>5如何将“b”设置为实际的“a”,以便在示例中,变量a也将变为4。谢谢。 最佳答案 classRefdefinitializeval@val=valendattr_accessor:valdefto_s@val.to_sendenda=Ref.new(4)b=aputsa#=>4putsb#=>4a.val=5putsa#=>5putsb#=>5当您执行b=a时,b指向与a相同的对象(它们具有相同的object_id).当你执行a=some_other_thing时,a将指向
关闭。这个问题是off-topic.它目前不接受答案。想改进这个问题吗?Updatethequestion所以它是on-topic用于堆栈溢出。关闭11年前。Improvethisquestion我不经常使用ruby-通常它加起来相当于每两个月或更长时间编写一次脚本。我的大部分编程都是使用C++进行的,这与ruby有很大不同。由于我与ruby之间的差距如此之大,我总是忘记语言的基本方面(比如解析文本文件和其他简单的东西)。我想每天练习一些基本的东西,我想知道是否有一些我可以订阅的网站,并且会向我发送当天的Ruby问题或类似的东西。有人知道这样的站点/Internet服务吗?
如果特定语言环境中缺少翻译,如何配置i18n以使用en语言环境翻译?当前已插入翻译缺失消息。我正在使用RoR3.1。 最佳答案 找到相似的question这里是答案:#application.rb#railswillfallbacktoconfig.i18n.default_localetranslationconfig.i18n.fallbacks=true#railswillfallbacktoen,nomatterwhatissetasconfig.i18n.default_localeconfig.i18n.fallback
在我的双语Rails4应用程序中,我有一个像这样的LocalesController:classLocalesController用户可以通过此表单更改其语言环境:deflocale_switcherform_tagurl_for(:controller=>'locales',:action=>'change_locale'),:method=>'get',:id=>'locale_switcher'doselect_tag'set_locale',options_for_select(LANGUAGES,I18n.locale.to_s)end这有效。但是,目前用户无法通过URL更改
我使用Ruby编程已经有一段时间了,现在只使用Ruby的标准MRI实现,但我一直对我经常听到的其他实现感到好奇。前几天我在读有关Rubinius的文章,这是一个用Ruby编写的Ruby解释器。我试着在不同的地方查找它,但我很难弄清楚这样的东西到底是如何工作的。我在编译器或语言编写方面从来没有太多经验,但我真的很想弄明白。一门语言究竟如何才能被自己解释?编译中是否有一个我不明白这有意义的基本步骤?有人可以像我是个白痴一样向我解释这个吗(因为无论如何这都不会太离谱) 最佳答案 它比你想象的要简单。Rubinius并非100%用Ruby编