👨🎓👨🎓博主:发量不足
个人简介:耐心,自信来源于你强大的思想和知识基础!!
📑📑本期更新内容:虚拟机Hadoop集群交换 SSH 密钥与验证SSh无密码登录🔥🔥
📑📑下篇文章预告:安装Hadoop、配置Hadoop 配置文件🔥🔥🔥
目录
(1) 将 Master 节点的公钥 id_rsa.pub 复制到每个 Slave 点
(2) 在每个 Slave 节点把 Master 节点复制的公钥复制到 authorized_keys 文 件
(3) 在每个 Slave 节点删除 id_rsa.pub 文件
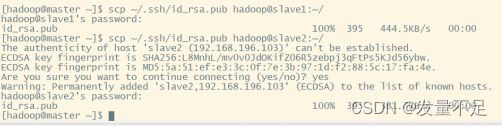
(5) slave2: scp ~/.ssh/id_rsa.pub hadoop@master:~/
(1)在master上验证ssh无密码登录ssh slave1
master:scp ~/.ssh/id_rsa.pub hadoop@slave1:~/
scp ~/.ssh/id_rsa.pub hadoop@slave2:~/
slave1: cat ~/id_rsa.pub >>~/.ssh/authorized_keys
slave2: cat ~/id_rsa.pub >>~/.ssh/authorized_keys
slave1: rm -f ~/id_rsa.pub
slave2: rm -f ~/id_rsa.pub
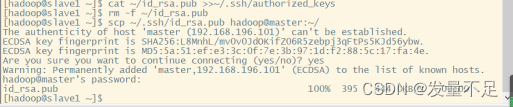
slave1: scp ~/.ssh/id_rsa.pub hadoop@master:~/
master: cat ~/id_rsa.pub >>~/.ssh/authorized_keys
master: rm -f ~/id_rsa.pub
master: cat ~/id_rsa.pub >>~/.ssh/authorized_keys
master: rm -f ~/id_rsa.pub

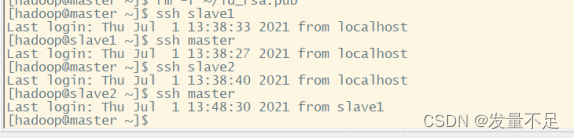
master切换到slave1、slave2不需要密码
slave1切换到master不需要密码
slave2 切换到master不需要密码
ssh master
ssh slave2
ssh master
我尝试使用不同的ssh_options在同一阶段运行capistranov.3任务。我的production.rb说:set:stage,:productionset:user,'deploy'set:ssh_options,{user:'deploy'}通过此配置,capistrano与用户deploy连接,这对于其余的任务是正确的。但是我需要将它连接到服务器中配置良好的an_other_user以完成一项特定任务。然后我的食谱说:...taskswithoriginaluser...task:my_task_with_an_other_userdoset:user,'an_othe
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
Ocra无法处理需要“tk”的应用程序require'tk'puts'nope'用奥克拉http://github.com/larsch/ocra不起作用(如链接中的一个问题所述)问题:https://github.com/larsch/ocra/issues/29(Ocra是1.9的"new"rubyscript2exe,本质上它用于将rb脚本部署为可执行文件)唯一的问题似乎是缺少tcl的DLL文件我不认为这是一个问题据我所知,问题是缺少tk的DLL文件如果它们是已知的,则可以在执行ocra时将它们包括在内有没有办法知道tk工作所需的DLL依赖项? 最佳答