继承 Thread 类创建线程的步骤为:
1)创建一个类继承Thread类,重写run()方法,将所要完成的任务代码写进run()方法中;
2)创建Thread类的子类的对象;
3)调用该对象的start()方法,该start()方法表示先开启线程,然后调用run()方法;
@Slf4j
public class ExtendsThread {
static class T extends Thread {
@Override
public void run() {
log.debug("hello");
}
}
public static void main(String[] args) {
T t = new T();
t.setName("t1");
t.start();
}
}
也可以直接使用Thread 类创建线程:
public static void main(String[] args) {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
log.debug("hello");
}
}, "t1");
}
看看 Thread 类的构造器,Thread 类有多个构造器来创建需要的线程对象:
// Thread.java
public Thread() {}
public Thread(Runnable target) {}
public Thread(String name) {}
public Thread(Runnable target, String name) {}
// 还有几个使用线程组创建线程的构造器,就不列举了
实现 Runnable 接口创建线程的步骤为:
1)创建一个类并实现 Runnable 接口;
2)重写 run() 方法,将所要完成的任务代码写进 run() 方法中;
3)创建实现 Runnable 接口的类的对象,将该对象当做 Thread 类的构造方法中的参数传进去;
4)使用 Thread 类的构造方法创建一个对象,并调用 start() 方法即可运行该线程;
@Slf4j
public class ImplRunnable {
static class T implements Runnable {
@Override
public void run() {
log.debug("hello");
}
}
public static void main(String[] args) {
Thread t1 = new Thread(new T(), "t1");
t1.start();
}
}
也可以写成这样:
public static void main(String[] args) {
Runnable task = new Runnable() {
@Override
public void run() {
log.debug("hello");
}
};
Thread t2 = new Thread(task, "t2");
t2.start();
}
Java 8 以后可以使用 lambda 精简代码(IDEA会有提示可将匿名内部类换成 Lambda 表达式):
public static void main(String[] args) {
Runnable task = () -> log.debug("hello");
Thread t2 = new Thread(task, "t2");
t2.start();
}
查看一下 Runnable 接口的源码,可以看到 Runnable 接口中只有一个抽象方法 run(),这种只有一个抽象方法的接口会加上一个注解:@FunctionalInterface,那只要带有这个注解的接口就可以被Lambda表达式来简化。
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
分析一下源码:
public static void main(String[] args) {
Runnable task = () -> log.debug("hello");
Thread t2 = new Thread(task, "t2");
t2.start();
}
?;
public Thread(Runnable target, String name) { // 调用Thread的指定构造器
init(null, target, name, 0);
}
?;
private void init(ThreadGroup g, Runnable target, String name, long stackSize) {
init(g, target, name, stackSize, null, true);
}
?;
private void init(ThreadGroup g, Runnable target, String name, long stackSize, AccessControlContext acc,
boolean inheritThreadLocals) {
if (name == null) {
throw new NullPointerException("name cannot be null");
}
this.name = name;
....
this.target = target; // target是Thread类中的成员变量,private Runnable target
....
}
?;
@Override
public void run() {
if (target != null) {
target.run();
}
}
Thread类是实现了Runnable接口的,那Thread类中重写了Runnable接口的run()方法,在创建Thread类的对象时,如果传进来的形参target不为空,那他就会去执行target的run(),也就是我们创建实现Runnable的实现类时重写的run()方法。
这种通过实现 Callable 接口来实现的,步骤为:
1)创建一个类并实现 Callable 接口;
2)重写call()方法,将所要完成的任务的代码写进call()方法中,需要注意的是call()方法有返回值,并且可以抛出异常;
3)如果想要获取运行该线程后的返回值,需要创建 Future 接口的实现类的对象,即 FutureTask 类的对象,调用该对象的 get() 方法可获取call() 方法的返回值;
4)使用 Thread 类的有参构造器创建对象,将 FutureTask 类的对象当做参数传进去,然后调用 start() 方法开启并运行该线程;
@Slf4j
public class ImplCallable {
static class MT implements Callable<String> {
@Override
public String call() throws Exception {
return Thread.currentThread().getName() + " finished!";
}
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 创建 FutureTask 的对象
FutureTask<String> task = new FutureTask<>(new MT());
// 创建 Thread 类的对象
Thread t1 = new Thread(task, "t1");
t1.start();
// 获取 call() 方法的返回值
String ret = task.get();
log.debug(ret);
}
}
// --------------运行结果:
00:33:29.628 [main] DEBUG cn.peng.create.ImplCallable - t1 finished!
FutureTask 能够接收 Callable 类型的参数,用来处理线程执行结束,有返回结果的情况
上面代码同样可以使用 Lambda 表达式简写:
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 匿名内部类方式
/*
FutureTask<Integer> task = new FutureTask<>(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
log.debug("call() running....");
return 5 + 3;
}
});
*/
// Lambda 简写
FutureTask<Integer> task = new FutureTask<>(() -> {
log.debug("call() running....");
return 5 + 3;
});
new Thread(task, "t2").start();
Integer ret = task.get();
log.debug("ret: {}", ret);
}
// -------运行结果
00:41:45.300 [main] DEBUG cn.peng.create.ImplCallable - ret: 8
看下源码,Callable 接口中也只有一个抽象方法 call(),并且call()方法支持返回值,含有注解:@FunctionalInterface,可以被Lambda表达式简化。
@FunctionalInterface
public interface Callable<V> {
V call() throws Exception;
}
FutureTask 类实现了 RunnableFuture接口,而 RunnableFuture接口又同时多继承了 Runnable, Future<V>接口,因此可以作为Thread 类的target。
public class FutureTask<V> implements RunnableFuture<V> {...}
public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
}
采用实现Runnable、Callable接口的方式创建线程时,
Thread.currentThread()方法;而使用继承 Thread 类的方式创建多线程时,
Thread.currentThread()方法,直接使用this即可获得当前线程;查看下ThreadPoolExecutor类中参数最全的构造方法,共有七大参数;
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {...}
corePoolSize 核心线程数目 (最多保留的线程数)
maximumPoolSize 最大线程数目
keepAliveTime 生存时间 - 针对救急线程
unit 时间单位 - 针对救急线程
workQueue 阻塞队列
threadFactory 线程工厂 - 可以为线程创建时起个好名字
handler 拒绝策略
根据这个构造方法,JDK Executors 类中提供了众多工厂方法来创建各种用途的线程池。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
// 这种通过 ThreadFactory 指定线程名称
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
创建一个固定大小的线程池,通过
Executors.newFixedThreadPool(线程个数)即可创建。线程池特点:
- 核心线程数 == 最大线程数(没有救急线程被创建),因此也无需超时时间,时间被设置成了0;
- 阻塞队列
LinkedBlockingQueue是无界的,可以放任意数量的任务;适用场景:
这种线程池适用于任务量已知,相对耗时的任务;
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
// 这种通过 ThreadFactory 指定线程名称
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}
创建一个带缓冲功能的线程池,通过
Executors.newCachedThreadPool(线程个数)即可创建。线程池特点:
- 核心线程为0,救急线程为 int 最大值,该线程池创建出的线程全是救急线程;
- 每个救急线程空闲存活时间 60s;
- 队列采用了
SynchronousQueue,实现特点是,它没有容量,没有线程来取是放不进去的(一手交钱、一手交货);适用场景:
线程池表现为线程数会根据任务量不断增长,没有上限;当任务执行完毕,空闲 1分钟后释放线程。适合任务数比较密集,但每个任务执行时间较短的情况。
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}
创建一个单线程的线程池,通过
Executors.newSingleThreadExecutor()即可创建。线程池特点:
- 只有1个核心线程,没有救急线程,所以救急线程空闲存活时间为0;
- 阻塞队列
LinkedBlockingQueue是无界的,可以放任意数量的任务;- 任务执行完毕,这唯一的线程也不会被释放。
适用场景:
希望多个任务排队串行执行。(线程数固定为 1,任务数多于 1 时,会放入无界队列排队)
Q:单线程的线程池和自己创建一个线程执行任务上的区别?
A:自己创建一个单线程(如实现Runnable接口)串行执行任务,如果任务执行失败导致线程终止,那么没有任何补救措施;而单线程的线程池
newSingleThreadExecutor出现了这种情况时,还会新建一个线程,保证线程池的正常工作。
举个例子:
@Slf4j
public class TestExecutors {
public static void main(String[] args) {
test();
}
private static void test() {
ExecutorService pool = Executors.newSingleThreadExecutor();
// 任务1
pool.execute(() -> {
log.debug("1");
int i = 1 / 0; // 手动写异常
});
// 任务2
pool.execute(() -> {
log.debug("2");
});
// 任务3
pool.execute(() -> {
log.debug("3");
});
}
}
//-----运行结果:任务1中出现异常,但任务2和任务3都执行完了,任务执行完毕,这唯一的线程也不会被释放。
13:47:26.448 [pool-1-thread-1] DEBUG cn.peng.threadpool.TestExecutors - 1
13:47:26.453 [pool-1-thread-2] DEBUG cn.peng.threadpool.TestExecutors - 2
13:47:26.453 [pool-1-thread-2] DEBUG cn.peng.threadpool.TestExecutors - 3
Exception in thread "pool-1-thread-1" java.lang.ArithmeticException: / by zero
at cn.peng.threadpool.TestExecutors.lambda$test$0(TestExecutors.java:25)
Q:单线程的线程池
newSingleThreadExecutor和创建固定数量为1的线程池newFixedThreadPool(1)有什么区别?A:看两者的构造方法,
newFixedThreadPool返回的是 ThreadPoolExecutor 对象,可以强转后调用 setCorePoolSize 等方法进行修改线程池的配置;- 而
newSingleThreadExecutor在 ThreadPoolExecutor 的外层做了一个包装,FinalizableDelegatedExecutorService应用的是装饰器模式,只对外暴露了 ExecutorService 接口,因此不能调用 ThreadPoolExecutor 中特有的方法,即不能修改线程池的配置。
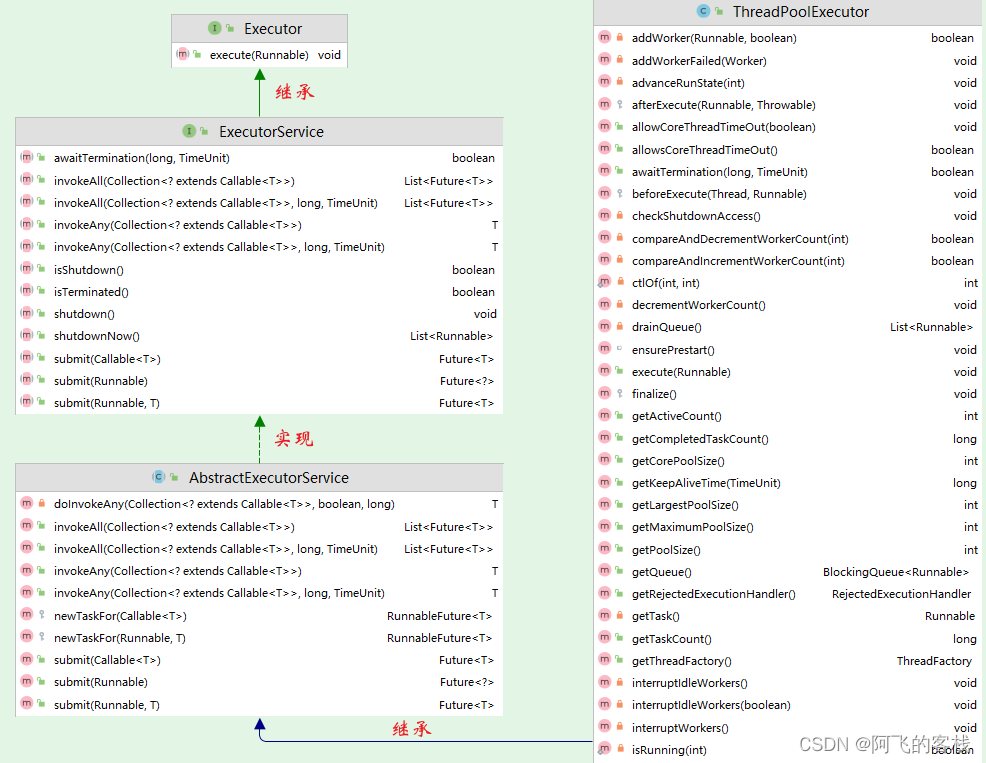
来看看 Executor、Executors、ExecutorService、ThreadPoolExecutor这几个有什么联系。
Executor是一个接口,内部只有一个抽象方法 execute();
void execute(Runnable command);
ExecutorService也是一个接口,继承自Executor,定义了一些操作线程池的抽象方法:
void shutdown(); // 执行任务
List<Runnable> shutdownNow();
boolean isShutdown();
boolean isTerminated();
<T> Future<T> submit(Callable<T> task);
......
Executors是一个工具类,内部提供了众多工厂方法来创建各种用途的线程池;
ThreadPoolExecutor是一个类,对于不同的业务可以自定义不同的线程池。上面三个官方自带的线程池都是利用ThreadPoolExecutor来实现所需要的功能池。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public static ScheduledExecutorService newScheduledThreadPool(
int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}
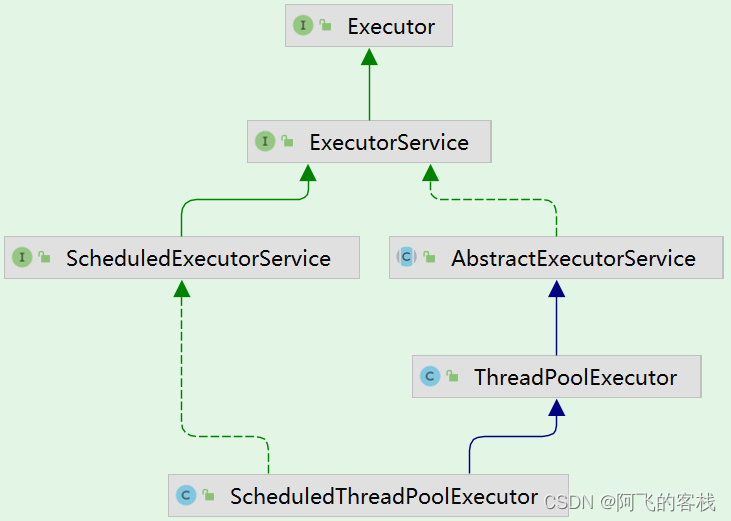
创建带有任务调度功能的线程池,线程池支持定时以及周期性执行任务。ScheduledThreadPoolExecutor继承了ThreadPoolExecutor,间接实现了 ExecutorService接口,在ExecutorService的基础上新增了一些方法,如 schedule()、scheduleAtFixedRate() 等。
public class ScheduledThreadPoolExecutor extends ThreadPoolExecutor
implements ScheduledExecutorService {
// 构造方法
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
public ScheduledFuture<?> schedule(Runnable command,
long delay,
TimeUnit unit) {}
public <V> ScheduledFuture<V> schedule(Callable<V> callable,
long delay,
TimeUnit unit) {}
// scheduleAtFixedRate(任务对象,延时时间,执行间隔,时间单位)
// 表示线程第一次执行时,过了延时时间后再去处理参数一中的任务
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit) {}
通过
Executors.newScheduledThreadPool(核心线程数)来创建任务调度线程池;适用场景:
- 整个线程池表现为:线程数固定,任务数多于线程数时,会放入无界队列排队;
任务执行完毕,线程池中的线程也不会被释放,用来执行延迟或反复执行的任务。(只有核心线程、没有救急线程)
前三种方法创建关闭频繁会消耗系统资源影响性能,而使用线程池可以不用线程的时候放回线程池,用的时候再从线程池取,项目开发中主要使用线程池。
前三种一般推荐采用实现接口的方式来创建线程。
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我对最新版本的Rails有疑问。我创建了一个新应用程序(railsnewMyProject),但我没有脚本/生成,只有脚本/rails,当我输入ruby./script/railsgeneratepluginmy_plugin"Couldnotfindgeneratorplugin.".你知道如何生成插件模板吗?没有这个命令可以创建插件吗?PS:我正在使用Rails3.2.1和ruby1.8.7[universal-darwin11.0] 最佳答案 随着Rails3.2.0的发布,插件生成器已经被移除。查看变更日志here.现在
如何使用RSpec::Core::RakeTask初始化RSpecRake任务?require'rspec/core/rake_task'RSpec::Core::RakeTask.newdo|t|#whatdoIputinhere?endInitialize函数记录在http://rubydoc.info/github/rspec/rspec-core/RSpec/Core/RakeTask#initialize-instance_method没有很好的记录;它只是说:-(RakeTask)initialize(*args,&task_block)AnewinstanceofRake
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我正在阅读SandiMetz的POODR,并且遇到了一个我不太了解的编码原则。这是代码:classBicycleattr_reader:size,:chain,:tire_sizedefinitialize(args={})@size=args[:size]||1@chain=args[:chain]||2@tire_size=args[:tire_size]||3post_initialize(args)endendclassMountainBike此代码将为其各自的属性输出1,2,3,4,5。我不明白的是查找方法。当一辆山地自行车被实例化时,因为它没有自己的initialize方法