前言:大家好,我是小威,24届毕业生,在一家满意的公司实习。本篇文章参考网上的课程,介绍Elasticsearch搜索引擎之自动补全功能的介绍与使用,这块内容不作为面试中的重点。
如果文章有什么需要改进的地方还请大佬不吝赐教👏👏。
小威在此先感谢各位大佬啦~~🤞🤞

🏠个人主页:小威要向诸佬学习呀
🧑个人简介:大家好,我是小威,一个想要与大家共同进步的男人😉😉
目前状况🎉:24届毕业生,在一家满意的公司实习👏👏💕欢迎大家:这里是CSDN,我总结知识的地方,欢迎来到我的博客,我亲爱的大佬😘

以下正文开始

当我们再很多网站输入拼音,关键字时,会出现商品,词语,与之有关联的的自动补全功能,可以帮助用户搜索到自己想要的结果。
Elasticsearch恰好能帮助我们完成这一业务。想要使用拼音来搜索商品,就需要使用拼音分词,根据字母做补全功能,就需要对文档按照拼音来分词。
首先我们需要安装拼音分词插件,将拼音分词插件下载到挂载的es-plugins目录下。下载完成后,我们可以测试一下是否可以,DSL代码如下:
POST /_analyze
{
"text": ["小威要向诸佬学习呀"],
"analyzer": "pinyin"
}
发送请求可以看到确实是按照拼音分词得到的结果,在创建索引库的时候可以以拼音分词的形式来创建:

上面我们演示了使用拼音来做分词,但是上面是根据单个和组合的拼音来做分词的。在生产环境中,我们往往需要以拼音和汉字词语一起作为分词,这就需要我们来自定义分词器了。
elasticsearch中分词器(analyzer)的组成包含三部分:
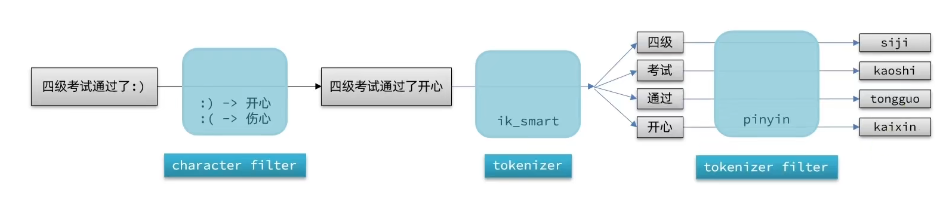 我们可以在创建索引库时,通过settings来配置自定义的分词器(analyzer):
我们可以在创建索引库时,通过settings来配置自定义的分词器(analyzer):
// 自定义拼音分词器
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": { //自定义tokenizer filter
"py": { //过滤器名称
"type": "pinyin", //过滤器类型为pinyin
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text"
"analyzer": "my_analyzer"//分词使用自定义分词器
, "search_analyzer": "ik_smart"//搜索使用ik分词器
}
}
}
}
在上面创建的索引库中放入两条文档:
{
"id": 1,
"name": "狮子"
}
POST /test/_doc/2
{
"id": 2,
"name": "虱子"
}
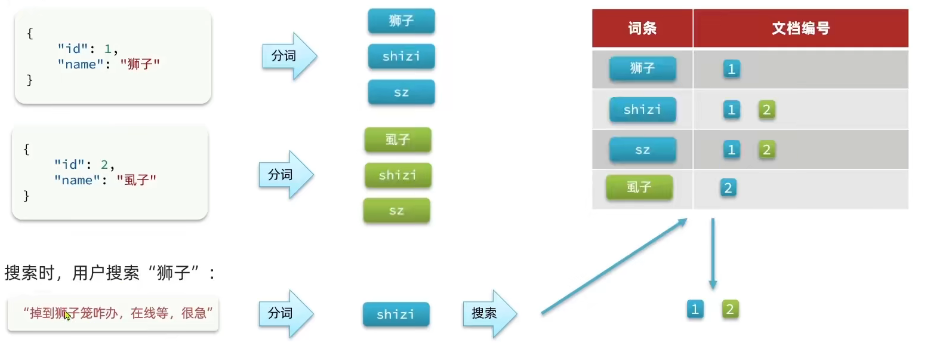
由于搜索时设置的根据ik_smart分词器进行分词,所以搜索结果只有狮子一条:

为了避免搜索到同音字,在创建索引库是时使用拼音分词器,在搜索时尽量不用。

es提供了completion suggester查询来实现自动补全功能,这个查询的概念就是匹配用户输入内容开头的词条并返回,对于文档中字段的类型,要遵循:参与补全查询的字段必须是completion类型;并且字段值是多个词条形成的数组。
举个栗子:
第一步,创建自动补全的索引库
# 创建自动补全的索引库
PUT test2
{
"mappings": {
"properties": {
"title":{
"type": "completion"
}
}
}
}
第二步,在创建的索引库中插入几条补全数据:
# 示例数据
POST test2/_doc
{
"title": ["Sony", "WH-1000XM3"]
}
POST test2/_doc
{
"title": ["SK-II", "PITERA"]
}
POST test2/_doc
{
"title": ["Nintendo", "switch"]
}
第三步,编写DSL语句,实现自动补全功能:
# 自动补全查询
POST /test/_search
{
"suggest": {
"title_suggest": {
"text": "s", // 搜索关键字s开头的数据
"completion": {
"field": "title", // 补全字段
"skip_duplicates": true, // 跳过重复的
"size": 10 // 获取前10条结果
}
}
}
}
执行上述的DSL语句,得到如下查询结果:

本期推荐阅读书籍,鳄鱼书:《 健壮的Python》
《 健壮的Python》,英文原书名为《Robust Python》,顾名思义,就是教我们如何写出更加“健壮”的代码,不易出错,且能长时间的进行修改和维护。Python 本身的语法和概念非常简单,很多人甚至都觉得这是一门不需要刻意学习的语言(相比 Rust,Scala 等)。但看了这本书才发现原来写出高质量的工程代码有这么多的讲究!

在这本实用的书中,作者Patrick Viafore将告诉你如何大限度地使用 Python的类型系统。你将看到用户定义的类型(如类和枚举),以及Python的类型提示系统。你还将学习如何使Python代码具有可扩展性,以及如何基于一个全面的测试策略构建安全网。利用这些知识和技术,你将编写更清晰、更易于维护的代码。
阅读收获
通过学习本书,你将:
本书结构
本书涵盖了非常广泛的知识,主要分为四个部分:
我们将从 Python 中的类型开始。类型是语言的基础,但开发人员往往没有对其进行详细检查。开发人员选择的类型很重要,因为它们传达了非常具体的意图。我们将介绍类型注解以及要与开发人员沟通的具体注解。我们还将介绍类型检查器以及它们是如何帮助开发人员在早期捕获 bug 的。
在介绍了如何考虑Python 的类型之后,我们将重点关注如何创建自己的类型。我们将深人讨论枚举、数据类和类,并探讨在设计类型时特定的选择会如何增加或减少代码的健壮性。
在学习了如何更好地表达你的意图之后,我们将重点关注如何使开发人员能够轻松地更改你的代码,并在你的基础上充满信心地构建代码。我们将讨论可扩展性、依赖关系和架构模式方面的问题,这些方面使你可以在最小的影响下修改系统。
最后,我们特探讨如何构建一个安全网,这样你說可以在未来的合作者失误时招助他们。他们的信心会因此而增强,因为他们会知道自己有一个强大的、健壮的系统,可以无所畏俱地用于他们的用例。最后,我们将介绍各种静志分析和测试工具,它们将帮助你捕获惡意的行为。
读者得以从四个不同的角度了解各种Python技巧,并借助其中的例子加强“编写良好代码”(不只是Python)的意识。每一章基本上都是独立的,你既可以按照顺片从头到尾问读,也可以根据自己的需求阅读相应的章节。各部分中的章节相互关联,但各个部分之间的关联较少。所有代码示例都是用 Python 3.9.0 运行。
希望阅读此书的读者都能有所收获,并能够将其中一些做法或者思想应用到自己的职业生涯或者编码工作中。
京东购买链接:点击了解
评论区任意留言可参与活动抽奖(评论最多三条,抽取四名欧皇)
好了,本篇文章就先分享到这里了,后续会继续分享其他方面的知识,感谢大佬认真读完支持咯~

文章到这里就结束了,如果有什么疑问的地方请指出,诸佬们一起讨论😁
希望能和诸佬们一起努力,今后我们顶峰相见🍻
再次感谢各位小伙伴儿们的支持🤞

我使用Nokogiri(Rubygem)css搜索寻找某些在我的html里面。看起来Nokogiri的css搜索不喜欢正则表达式。我想切换到Nokogiri的xpath搜索,因为这似乎支持搜索字符串中的正则表达式。如何在xpath搜索中实现下面提到的(伪)css搜索?require'rubygems'require'nokogiri'value=Nokogiri::HTML.parse(ABBlaCD3"HTML_END#my_blockisgivenmy_bl="1"#my_eqcorrespondstothisregexmy_eq="\/[0-9]+\/"#FIXMEThefoll
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
寻找有用的ruby的好网站是什么? 最佳答案 AgileWebDevelopment列出插件(虽然不是rubygems,我不确定为什么),并允许人们对它们进行评级。RubyToolbox按类别列出gem并比较它们的受欢迎程度。Rubygems有一个搜索框。StackOverflow对最有用的rails插件和rubygems有疑问。 关于ruby-如何搜索有用的ruby,我们在StackOverflow上找到一个类似的问题: https://stacko
我有很多这样的文档:foo_1foo_2foo_3bar_1foo_4...我想通过获取foo_[X]的所有实例并将它们中的每一个替换为foo_[X+1]来转换它们。在这个例子中:foo_2foo_3foo_4bar_1foo_5...我可以用gsub和一个block来做到这一点吗?如果不是,最干净的方法是什么?我真的在寻找一个优雅的解决方案,因为我总是可以暴力破解它,但我觉得有一些正则表达式技巧值得学习。 最佳答案 我(完全)不懂Ruby,但类似这样的东西应该可以工作:"foo_1foo_2".gsub(/(foo_)(\d+)/
我正在尝试用ruby编写一个简单的网络抓取代码。它一直工作到第29个url,然后我收到此错误消息:C:/Ruby193/lib/ruby/1.9.1/open-uri.rb:346:in`open_http':500InternalServerError(OpenURI::HTTPError)fromC:/Ruby193/lib/ruby/1.9.1/open-uri.rb:775:in`buffer_open'fromC:/Ruby193/lib/ruby/1.9.1/open-uri.rb:203:in`blockinopen_loop'fromC:/Ruby193/lib/r
我读了"BingSearchAPI-QuickStart"但我不知道如何在Ruby中发出这个http请求(Weary)如何在Ruby中翻译“Stream_context_create()”?这是什么意思?"BingSearchAPI-QuickStart"我想使用RubySDK,但我发现那些已被弃用前(Rbing)https://github.com/mikedemers/rbing您知道Bing搜索API的最新包装器(仅限Web的结果)吗? 最佳答案 好吧,经过一个小时的挫折,我想出了一个办法来做到这一点。这段代码很糟糕,因为它是
在Rails自动生成的功能测试(test/functional/products_controller_test.rb)中,我看到以下代码:classProductsControllerTest我的问题是:方法调用products()在哪里/如何定义?products(:one)到底是什么意思?看代码,大概意思是“创建一个产品”,但是它是如何工作的呢?注意我是Ruby/Rails的新手,如果这些是微不足道的问题,我深表歉意。 最佳答案 如果您查看test/fixtures文件夹,您会看到一个products.yml文件。这是在您创建
给定一个元素和一个数组,Ruby#index方法返回元素在数组中的位置。我使用二进制搜索实现了我自己的索引方法,期望我的方法会优于内置方法。令我惊讶的是,内置的在实验中的运行速度大约是我的三倍。有Rubyist知道原因吗? 最佳答案 内置#indexisnotabinarysearch,这只是一个简单的迭代搜索。但是,它是用C而不是Ruby实现的,因此自然可以快几个数量级。 关于Ruby#index方法VS二进制搜索,我们在StackOverflow上找到一个类似的问题:
在我的一些Controller中,我有一个before_filter检查用户是否登录?用于CRUD操作。application.rbdeflogged_in?unlesscurrent_userredirect_toroot_pathendendprivatedefcurrent_user_sessionreturn@current_user_sessionifdefined?(@current_user_session)@current_user_session=UserSession.findenddefcurrent_userreturn@current_userifdefine
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a