
大型语言模型在上下文学习中表现出了惊人的能力,这些模型可以通过几个输入输出示例构建的上下文进行学习,无需微调优化直接应用于许多下游任务。然而,先前的研究表明,由于训练样本 (training examples)、示例顺序 (example order) 和提示格式 (prompt formats) 的变化,上下文学习可能会表现出高度的不稳定性。因此,构建适当的 prompt 对于提高上下文学习的表现至关重要。
以前的研究通常从两个方向研究这个问题:(1)编码空间中的提示调整 (prompt tuning),(2)在原始空间中进行搜索 (prompt searching)。
Prompt tuning 的关键思想是将任务特定的 embedding 注入隐藏层,然后使用基于梯度的优化来调整这些 embeddings。然而,这些方法需要修改模型的原始推理过程并且获得模型梯度,这在像 GPT-3 和 ChatGPT 这样的黑盒 LLM 服务中是不切实际的。此外,提示调整会引入额外的计算和存储成本,这对于 LLM 通常是昂贵的。
更可行且高效的方法是通过在原始文本空间中搜索近似的演示样本和顺序来优化提示。一些工作从 “Global view” 或 “Local view” 构建提示。基于 Global view 的方法通常将提示的不同元素作为整体进行优化,以达到更优异的性能。例如,Diversity-guided [1] 的方法利用演示的整体多样性的搜索,或者试图优化整个示例组合顺序 [2],以实现更好的性能。与 Global view 相反,基于 Local view 的方法通过设计不同的启发式选择标准,例如 KATE [3]。
但这些方法都有各自的局限性:(1)目前的大多数研究主要集中在沿着单个因素搜索提示,例如示例选择或顺序。然而各个因素对性能的总体影响尚不清楚。(2)这些方法通常基于启发式标准,需要一个统一的视角来解释这些方法是如何工作的。(3)更重要的是,现有的方法会全局或局部地优化提示,这可能会导致性能不理想。
本文从 “预测偏差” 的角度重新审视了 NLP 领域中的 prompt 优化问题,发现了一个关键现象:一个给定的 prompt 的质量取决于它的内在偏差。基于这个现象,文章提出了一个基于预测偏差的替代标准来评估 prompt 的质量,该度量方法能够在不需要额外开发集 (development set) 的情况下通过单个前向过程来评估 prompt。
具体来说,通过在一个给定的 prompt 下输入一个 “无内容” 的测试,期望模型输出一个均匀的预测分布(一个 “无内容” 的输入不包含任何有用的信息)。因此,文中利用预测分布的均匀性来表示给定 prompt 的预测偏差。这与先前的后校准方法 [4] 用的指标类似,但与后校准在固定的 prompt 情况下使用这个 metric 进行概率后校准不同的是,文中进一步探索了其在自动搜索近似 prompt 中的应用。并通过大量实验证实了一个给定 prompt 的内在偏差和它在给定测试集上的平均任务表现之间的相关性。
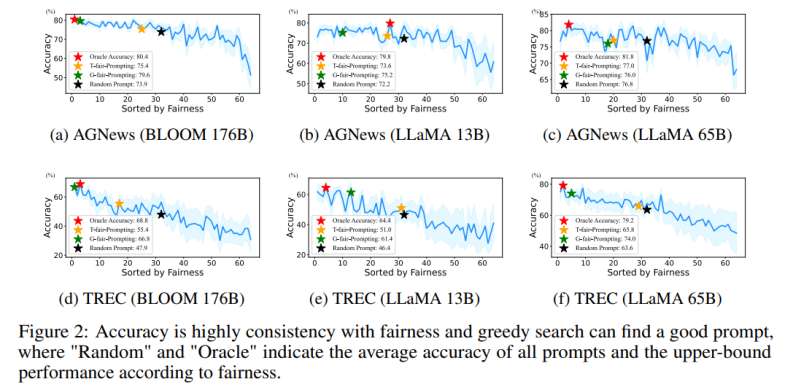
此外,这种基于偏差的度量使该方法能够以 “局部到全局” 的方式搜索合适的 prompt。然而,一个现实的问题是无法通过遍历所有组合的方式搜索最优解,因为它的复杂度将超过 O (N!)。
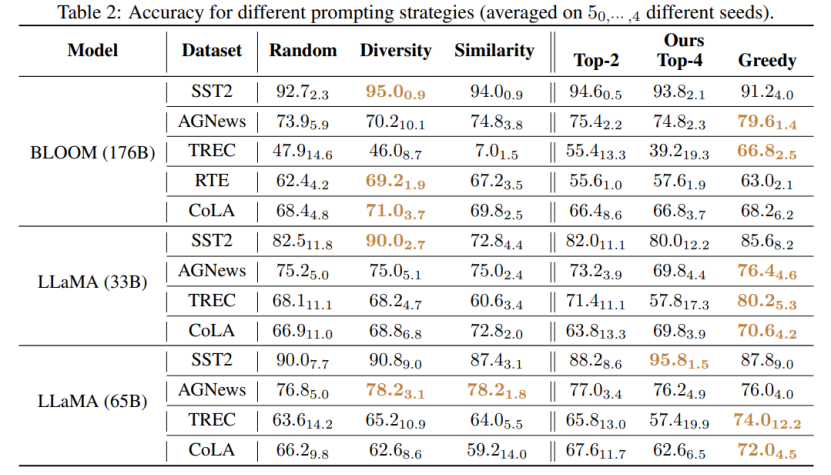
该工作提出了两种新颖的策略以高效的方式搜索高质量的 prompt:(1) T-fair-Prompting (2) G-fair-Prompting。T-fair-Prompting 使用一种直观的方式,首先计算每个示例单独组成 prompt 的偏差,然后选择 Top-k 个最公平示例组合成最终 prompt。这个策略相当高效,复杂度为 O (N)。但需要注意的是,T-fair-Prompting 基于这样的假设:最优的 prompt 通常是由偏差最小的示例构建的。然而,这在实际情况下可能并不成立,并且往往会导致局部最优解。因此,文章中进一步介绍了 G-fair-Prompting 来改善搜索质量。G-fair-Prompting 遵循贪心搜索的常规过程,通过在每个步骤上进行局部最优选择来找到最优解。在算法的每一步,所选择的示例都能使更新的 prompt 获得最佳的公平性,最坏情况时间复杂度为 O (N^2),搜索质量显著提高。G-fair-Prompting 从局部到全局的角度进行工作,其中在早期阶段考虑单个样本的偏差,而在后期阶段则侧重于减少全局预测偏差。
该研究提出了一种有效和可解释的方法来提高语言模型的上下文学习性能,这种方法可以应用于各种下游任务。文章验证了这两种策略在各种 LLMs(包括 GPT 系列模型和最近发布的 LMaMA 系列)上的有效性,G-fair-Prompting 与 SOTA 方法相比,在不同的下游任务上获得了超过 10%的相对改进。
与该研究最相近的是 Calibration-before-use [4] 方法,两者都使用 “无内容” 的输入提高模型的表现。但是,Calibration-before-use 方法旨在使用该标准来校准输出,而该输出仍然容易受到所使用示例的质量的影响。与之相比,本文旨在搜索原始空间找到近似最优的 prompt,以提高模型的性能,而不需要对模型输出进行任何后处理。此外,该文首次通过大量实验验证了预测偏差与最终任务性能之间的联系,这在 Calibration-before-use 方法中尚未研究。
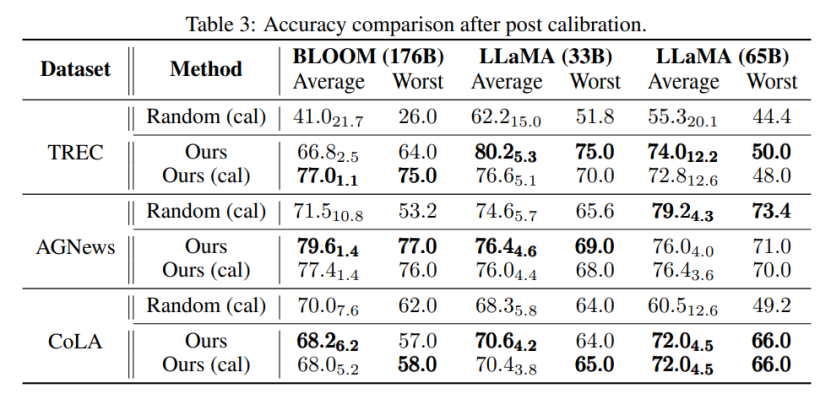
通过实验还能发现,即使不进行校准,该文章所提方法选择的 prompt 也可以优于经过校准的随机选择的 prompt。这表明该方法可以在实际应用中具有实用性和有效性,可以为未来的自然语言处理研究提供启示。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我正在使用active_admin,我在Rails3应用程序的应用程序中有一个目录管理,其中包含模型和页面的声明。时不时地我也有一个类,当那个类有一个常量时,就像这样:classFooBAR="bar"end然后,我在每个必须在我的Rails应用程序中重新加载一些代码的请求中收到此警告:/Users/pupeno/helloworld/app/admin/billing.rb:12:warning:alreadyinitializedconstantBAR知道发生了什么以及如何避免这些警告吗? 最佳答案 在纯Ruby中:classA
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案