kafka依赖zookeeper,所以搭建kafka需要先配置zookeeper
zookeeper:127.0.0.1:2181
kafka1: 127.0.0.1:9092
kafka2: 127.0.0.1:9093
kafka3: 127.0.0.1:9094
1.安装 docker-compose
curl -L http://mirror.azure.cn/docker-toolbox/linux/compose/1.25.4/docker-compose-Linux-x86_64 -o /usr/local/bin/docker-compose chmod +x /usr/local/bin/docker-compose
2、创建 docker-compose.yml 文件
version: '3.3'
services:
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
ports:
- 2181:2181
volumes:
- /data/zookeeper/data:/data
- /data/zookeeper/datalog:/datalog
- /data/zookeeper/logs:/logs
restart: always
kafka1:
image: wurstmeister/kafka
depends_on:
- zookeeper
container_name: kafka1
ports:
- 9092:9092
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 192.168.10.219:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.10.219:9092
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_LOG_DIRS: /data/kafka-data
KAFKA_LOG_RETENTION_HOURS: 24
volumes:
- /data/kafka1/data:/data/kafka-data
restart: unless-stopped
kafka2:
image: wurstmeister/kafka
depends_on:
- zookeeper
container_name: kafka2
ports:
- 9093:9093
environment:
KAFKA_BROKER_ID: 2
KAFKA_ZOOKEEPER_CONNECT: 192.168.10.219:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.10.219:9093
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9093
KAFKA_LOG_DIRS: /data/kafka-data
KAFKA_LOG_RETENTION_HOURS: 24
volumes:
- /data/kafka2/data:/data/kafka-data
restart: unless-stopped
kafka3:
image: wurstmeister/kafka
depends_on:
- zookeeper
container_name: kafka3
ports:
- 9094:9094
environment:
KAFKA_BROKER_ID: 3
KAFKA_ZOOKEEPER_CONNECT: 192.168.10.219:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.10.219:9094
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9094
KAFKA_LOG_DIRS: /data/kafka-data
KAFKA_LOG_RETENTION_HOURS: 24
volumes:
- /data/kafka3/data:/data/kafka-data
restart: unless-stopped
参数说明:
3、启动
docker-compose up -d

测试
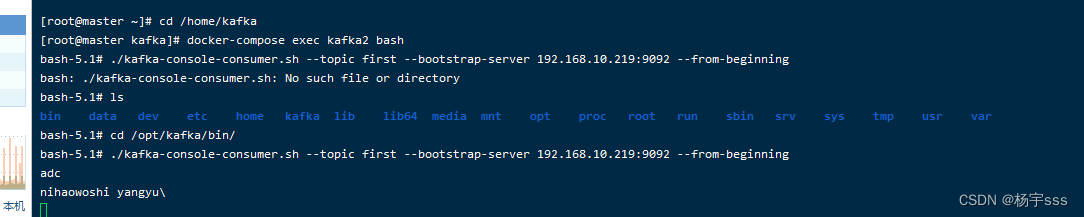
1、登录到 kafka1 容器
docker-compose exec kafka1 bash
切到 /opt/kakfa/bin 目录下
cd /opt/kafka/bin/
创建一个 topic:名称为first,3个分区,2个副本
./kafka-topics.sh --create --topic first --zookeeper 192.168.10.219:2181 --partitions 3 --replication-factor 2

zookeeper在kafka中的作用https://www.jianshu.com/p/a036405f989c![]() https://www.jianshu.com/p/a036405f989c
https://www.jianshu.com/p/a036405f989c
注意:副本数不能超过brokers数(分区是可以超过的),否则会创建失败。
2.查看 topic 列表
./kafka-topics.sh --list --zookeeper 192.168.10.219:2181
 3.查看 topic 为 first 的详情
3.查看 topic 为 first 的详情
./kafka-topics.sh --describe --topic first --zookeeper 192.168.10.219:2181
4.在宿主机上,切到 /data/kafka1/data下,可以看到topic的数据

说明:
5.创建一个生产者,向 topic 中发送消息

6.登录到 kafka2 或者 kafka3 容器内(参考第1步),然后创建一个消费者,接收 topic 中的消息
 其它命令
其它命令
1、删除topic
./kafka-topics.sh --delete --topic first --zookeeper 192.168.10.219:2181

删除topic,不会立马删除,而是会先给该topic打一个标记。在/data/kafka1/data下可以看到:

2、查看某个topic对应的消息数量
./kafka-run-class.sh kafka.tools.GetOffsetShell --topic second --time -1 --broker-list 192.168.10.219:9092
3、查看所有消费者组
./kafka-consumer-groups.sh --bootstrap-server 192.168.56.101:9092 --list
4、查看日志文件内容(消息内容)
./kafka-dump-log.sh --files /data/kafka-data/my-topic-0/00000000000000000000.log --print-data-log
查看topic=my-topic的消息,日志文件为00000.log,--print-data-log表示查看消息内容(不加不会显示消息内容)

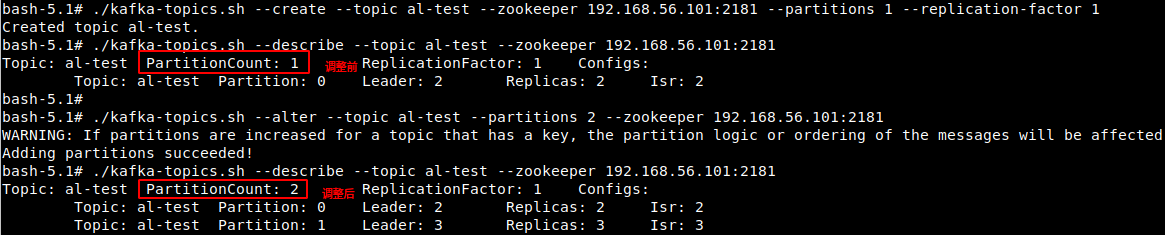
5、修改kafka对应topic分区数(只能增加,不能减少)
./kafka-topics.sh --alter --topic al-test --partitions 2 --zookeeper 192.168.10.219:2181
6、修改kafka对应topic数据的保存时长(可以查看server.properties文件中log.retention.hours配置,默认168小时)
./kafka-topics.sh --alter --zookeeper 192.168.56.101:2181 --topic al-test --config retention.ms=86400000
这里是改为24小时=24*3600*1000

总结
The broker is trying to join the wrong cluster. Configured zookeeper.connect may be wrong.
参考地址:docker-compose 搭建 kafka 集群 - 仅此而已-远方 - 博客园
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里
我正在尝试使用docker运行一个Rails应用程序。通过github的sshurl安装的gem很少,如下所示:Gemfilegem'swagger-docs',:git=>'git@github.com:xyz/swagger-docs.git',:branch=>'my_branch'我在docker中添加了keys,它能够克隆所需的repo并从git安装gem。DockerfileRUNmkdir-p/root/.sshCOPY./id_rsa/root/.ssh/id_rsaRUNchmod700/root/.ssh/id_rsaRUNssh-keygen-f/root/.ss
我在Heroku上构建了一个必须在Docker容器内运行的RoR应用程序。为此,我使用officialDockerfile.因为它在Heroku中很常见,所以我需要一些附加组件才能使这个应用程序完全运行。在生产中,变量DATABASE_URL在我的应用程序中可用。但是,如果我尝试其他一些使用环境变量(在我的例子中是Mailtrap)的加载项,变量不会在运行时复制到实例中。所以我的问题很简单:如何让docker实例在Heroku上执行时知道环境变量?您可能会问,我已经知道我们可以在docker-compose.yml中指定一个environment指令。我想避免这种情况,以便能够通过项目
我在开发和生产中都使用docker,真正困扰我的一件事是docker缓存的简单性。我的ruby应用程序需要bundleinstall来安装依赖项,因此我从以下Dockerfile开始:添加GemfileGemfile添加Gemfile.lockGemfile.lock运行bundleinstall--path/root/bundle所有依赖项都被缓存,并且在我添加新gem之前效果很好。即使我添加的gem只有0.5MB,从头开始安装所有应用程序gem仍然需要10-15分钟。由于依赖项文件夹的大小(大约300MB),然后再花10分钟来部署它。我在node_modules和npm上遇到了
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
测试环境对于任何一个软件公司来讲,都是核心基础组件之一。转转的测试环境伴随着转转的发展也从单一的几套环境发展成现在的任意的docker动态环境+docker稳定环境环境体系。期间环境系统不断的演进,去适应转转集群扩张、新业务的扩展,走了一些弯路,但最终我们将系统升级到了我们认为的终极方案。下面我们介绍一下转转环境的演进和最终的解决方案。1测试环境演进1.1单体环境 转转在2017年成立之初,5台64G内存的机器,搭建5个完整的测试环境。就满足了转转的日常所需。一台分给开发,几台分给测试。通过沟通协调就能解决多分支并行开发下冲突问题。1.2动态环境+稳定环境 随着微服务化的进
文章目录查看ES信息查看节点信息查看分片信息实际场景下ES分片及副本数量应该怎么分关于ES的灵活使用查看ES信息查看版本kibana:GET/查看节点信息GET/_cat/nodes?v解释:ip:集群中节点的ip地址;heap.percent:堆内存的占用百分比;ram.percent:总内存的占用百分比,其实这个不是很准确,因为buff/cache和available也被当作使用内存;cpu:cpu占用百分比;load_1m:1分钟内cpu负载;load_5m:5分钟内cpu负载;load_15m:15分钟内cpu负载;node.role:上图的dilmrt代表全部权限master:*代表
elasticsearch查看当前集群中的master节点是哪个需要使用_cat监控命令,具体如下。查看方法es主节点确定命令,以kibana上查看示例如下:GET_cat/nodesv返回结果示例如下:ipheap.percentram.percentcpuload_1mload_5mload_15mnode.rolemastername172.16.16.188529952.591.701.45mdi-elastic3172.16.16.187329950.990.991.19mdi-elastic2172.16.16.231699940.871.001.03mdi-elastic4172
一、解决痛点使用spring-kafka客户端,每次新增topic主题,都需要硬编码客户端并重新发布服务,操作麻烦耗时长。kafkaListener虽可以支持通配符消费topic,缺点是并发数需要手动改并且重启服务。对于业务逻辑相似场景,创建新主题动态监听可以用kafka-batch-starter组件二、组件能力1、新增topic名称为:auto.topic1(由于配置spring.kafka.consumer.prefix为auto,因此只有auto前缀的topic,才会被组件动态监听。)2、应用输出日志,监听到新增auto.topic1,并初始化客户端(主题刷新间隔为10s)3、发新的消
(二十二)-框架主入口main.py设计&log日志调用和生成1测试目的2测试需求3需求分析4详细设计4.1新建存放日志目录log4.1.1配置config.py中写入log的目录4.2`baseInfo.py`中加入日志4.3`test_gedit.py`中加入日志4.4主函数入口main.py中调用日志5调用日志主函数main.py源码6`baseInfo.py`源码7`test_gedit.py`源码8运行效果9目前框架结构1测试目的组织运行所有的测试用例,并调用日志模块,便于问题定位。