转载请标明来源:https://www.cnblogs.com/huim/
本身需要对外有良好的服务能力,对内流程透明,有日志、问题排查简便。
这里的服务能力指的是系统层面的服务,将扫描器封装成提供给业务的业务服务能力不在该篇讲述范围内
高端的漏洞往往用最朴实的扫描方法
最简单的扫描需求,只需要从数据库中读取数据,定期跑一遍所有规则就好了。

一个脚本更新资产,一个脚本定时读取数据、结合规则进行扫描、并把结果打到数据库里,一个脚本定时读取结果发邮件,这样就已经满足SRC自动化挖漏洞的需求了,而且效果还不错。
随着扫描的资产变多,单个机器的龟速扫描令人着急,所以运行规则这一步加上分布式,即任务打到队列(redis/MQ/kafka等),再由多个节点运行扫描规则、输出漏洞结果

这样很方便的可以扫描主机漏洞
再往后,不想只单单的扫描主机漏洞了,也想扫描注入/XSS/SSRF/XXE等基于url的漏洞,有了url类型数据。
甚至发现有的漏洞应该是针对域名的(单纯的IP+端口请求到达不了负载均衡),又有了domain类型的数据。

这时候生产模块还能应付得过来,即读取各类型数据、绑定各类型插件。
但是有时候新增了规则,想单纯的扫描对着所有数据扫描这条规则,需要另外起脚本加一个临时的生产者。
有时候新增了一批资产,想单独对着这批资产扫描所有的规则,又需要临时写个生产者脚本。
由此代码变得冗杂,操作变得繁琐,于是有了任务的概念。
任务用于绑定数据与规则,一个任务就是一个生产扫描子任务的单位。
这样增量规则扫描全量数据,新增一个任务绑定这个规则和对应的数据;增量资产扫描全量规则,新增一个任务绑定这批资产和对应的规则。
而从数据库上操作任务与规则变得不太方便,于是加上了可视化平台,可在web端发布扫描任务、新增修改规则。
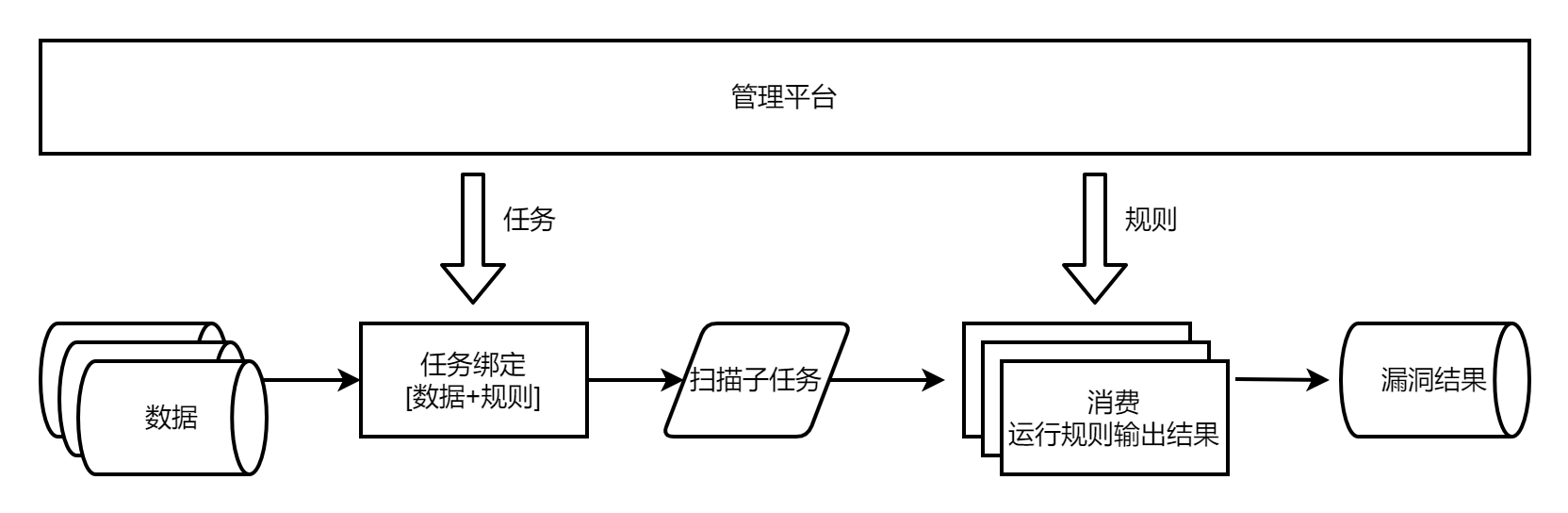
而在甲方内部,随着接入的数据源越来越多,url数据有镜像流量、爬虫流量、代理流量、nginx流量等等,host数据有hids agent流量、黑盒资产探测流量、cmdb/IT等流量,domain有域名爆破流量、内部运维系统获取的流量等。
每多一个数据源,都得加一段代码逻辑 : "当数据源是a的时候,从哪哪哪获取流量数据"。
当数据源数量超过十种,任务模块的数据源获取代码变得很冗杂,且并硬编码横行(从哪哪哪获取数据)、逻辑写死不通用(a的数据要从接口分页遍历、b的数据需要从redis读、c的数据是kafka、d的数据从数据库获取)。
某些数据不走中间的某段过滤匹配逻辑,于是又要加一个字段 is_xxx 标识 ,再在引擎里 if is_xxx=True,代码通用性低、高度耦合,遇到bug时排查成本极高,比如遇到这个流量怎么会有这样的输出结果、怎么会报错这类问题时,往往花半天一天追踪流量。
故而需要对数据源进行改造,统一数据源输入格式,数据源分几种类型,url/host/domain,每种类型都有固定的格式,由外部按照这种格式进行输入。
在数据源过多时,外部的输入代码太多了,可额外抽象出来形成数据输入模块。
比如定义redis类型数据从哪里获取、接口怎么分页获取数据、数据库怎么迭代读取等,再一一配置数据格式转换方式。这样再遇到需要新增的流量类型,需要新增的代码就是可复用的某类数据获取方式。
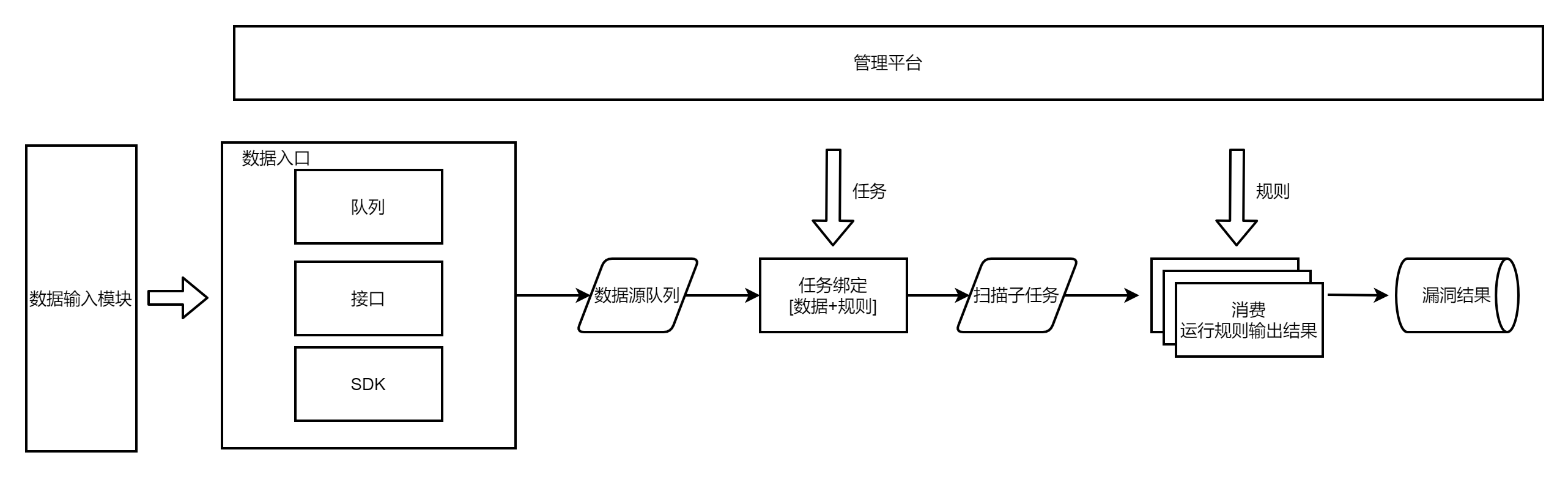
但是又遇到一个问题,遇到跨部门或者跨项目需要调用扫描能力时,很不方便,输入上需要自己配置数据来源,还需要扫描开发人员添加这类数据,扫描结果还需要去数据库获取,有的没结果不知道到底是没扫描还是没漏洞。
对于业务方,需求增改、服务调用不方便。
所以需要提高服务提供的能力,对于调用方来说,扫描是一个黑箱子,只管传入数据、启动任务、获取结果,提供给调用方的是扫描服务能力。
对于扫描引擎开发方,对外进行引擎能力封装,服务与上下游拆分开,也实现低耦合、高可维护、可扩展易扩展,不会因需求增改而频繁改动引擎代码、从而导致代码冗余、开发维护成本上升。
实现方式:
数据接入时,调用方在管理平台注册数据标签,并在传入数据时标明数据标签(抽象数据配置步骤);
结果输出时,调用方注册回调接口(数据打往回调接口),扫描结果分有漏洞/无漏洞/没扫描这一类,回调接口选择接收的结果类型;或注册处置结果标签,扫描结果打给消息总线。
回调方式不知道对方接口设置的状态,可能接口报错了消息没有正确打过去,可能接口返回200的 status: false但无法判断是失败了,简单来讲就是无法保证数据一致性,扫描结果里有但接口因为报错没有这个结果。所以还是尽量使用消息总线的方式,由消费方对消费失败的数据进行记录、排查并作再消费,保证接收结果的接口不会丢数据。
再由注册方操作任务,绑定待扫描的流量的标签,需要扫描的规则,处置的方式即结果是打给某个回调或者是打上某个结果标签。
实现效果:
这样将引擎封装起来,基本可以保证引擎中不会因为过多的数据源,而东一块西一块,有很多的针对不同数据源读取的代码。
引擎本身只保证数据读取、按照规定的任务选择扫描规则、将扫描的结果打到结果队列或者打回给调用方。
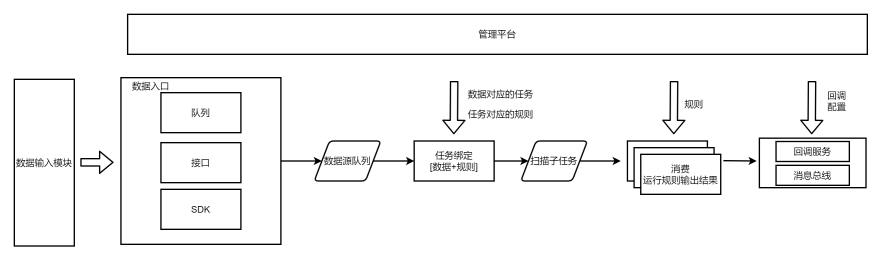
但还有另外一个问题,排查问题成本比较大。
扫描器引擎逻辑相比部分产品会比较复杂,主要涉及到其中的存活检测、集群判断、白名单限制、QPS控制、任务调度等功能,有时候丢流量或者因为某个字段不对导致漏报、在插件运行前请求的内容有问题导致判断为不存活的流量从而漏报。
这些情况在以redis为队列的引擎中,排查起来比较麻烦。
所以需要全流程的日志:最好能知道几个关键步骤的中间结果是什么样的,遇到问题时排查方便。扫描器在去重后扫描中间过程数据量不如IDS大 (日百亿处理结果),大概也就上千万,可以全部记录下来,资源紧张可以只记录一段时间。
关于日志种类:我们溯源排查时一般需要的中间结果有数据源、扫描子任务、扫描结果。
关于日志实现:redis pop后数据就没了,引擎读后做双写比较麻烦。
所以选择可订阅的消息队列,比如kafka,引擎使用一个group进行消息消费,再起一个服务用另外的group对这批topic的数据进行存储,熟悉的ELK结构。
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
我想在一个没有Sass引擎的类中使用Sass颜色函数。我已经在项目中使用了sassgem,所以我认为搭载会像以下一样简单:classRectangleincludeSass::Script::FunctionsdefcolorSass::Script::Color.new([0x82,0x39,0x06])enddefrender#hamlengineexecutedwithcontextofself#sothatwithintemlateicouldcall#%stop{offset:'0%',stop:{color:lighten(color)}}endend更新:参见上面的#re
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除
我想为我的Rails网络应用程序提供推荐功能。特别是,我想向新注册的用户推荐他可能想要关注的其他用户。Rails中是否有用于此目的的引擎/gem?如果没有,我应该从哪里开始构建它?谢谢。 最佳答案 有Coletivogemhttps://github.com/diogenes/coletivo我试了一下。在MySQL上运行。Neo4jhttp://neo4j.org真的很容易实现一个“跟随谁”。事实上,大多数展示其能力的样本都涉及“跟随谁”。快速提示-只有在JRuby上运行时,Neo4j.rb才会很酷。如果不是-使用Neograph
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵