个人简介
👀个人主页: 前端杂货铺
🙋♂️学习方向: 主攻前端方向,也会涉及到服务端
📃个人状态: 在校大学生一枚,已拿多个前端 offer(秋招)
🚀未来打算: 为中国的工业软件事业效力n年
🥇推荐学习:🍍前端面试宝典 🍉Vue2 🍋Vue3 🍓Vue2&Vue3项目实战 🥝Node.js🍒Three.js
🌕个人推广:每篇文章最下方都有加入方式,旨在交流学习&资源分享,快加入进来吧
| 内容 | 参考链接 |
|---|---|
| Node.js(一) | 初识 Node.js |
| Node.js(二) | Node.js——开发博客项目之接口 |
| Node.js(三) | Node.js——一文带你开发博客项目(使用假数据处理) |
| Node.js(四) | Node.js——开发博客项目之MySQL基础 |
| Node.js(五) | Node.js——开发博客项目之API对接MySQL |
| Node.js(六) | Node.js——开发博客项目之登录(前置知识) |
| Node.js(七) | Node.js——开发博客项目之登录(对接完毕) |
| Node.js(八) | Node.js——开发开发博客项目之联调 |
文章目录
开发日志对整个项目可以起到备忘、记录、总结等作用。以帮助开发或者运维人员快速定位错误位置,提出解决方案。
所以,日志的存在还是非常非常有必要的!
日志要放在文件中,可读可写~
接下来,我们先学习如何进行文件的读取…
创建 file-test 文件夹,文件夹下创建 test1.txt 文件 和 data.txt 文件
test1.txt
进行文件读取操作,读取 data.txt 文本的内容,并进行输出
const fs = require('fs')
const path = require('path')
// 获取文件目录 __dirname 表示当前文件所在目录
const fileName = path.resolve(__dirname, 'data.txt')
// 读取文件内容(异步的)
fs.readFile(fileName, (err, data) => {
if (err) {
console.error(err)
return
}
// data 是二进制类型,需要转成字符串类型
console.log(data.toString())
})
data.txt
这是我们在文本中存储的一些信息
Hello
这里是前端杂货铺
感谢你的观看
Thanks

接下来,我们进行文件的写入操作(分为两种:追加写入和覆盖写入)
test1.js
const fs = require('fs')
const path = require('path')
// 获取文件目录 __dirname 表示当前文件所在目录
const fileName = path.resolve(__dirname, 'data.txt')
// 写入文件
const content = '哇咔咔,这是新写入的内容\n'
// 写入的方式(追加'a'/覆盖'w')
const opt = {
flag: 'a' // 追加写入用'a',覆盖用 'w'
}
// 写入文件(文件名,内容,方式,错误的回调)
fs.writeFile(fileName, content, opt, err => {
if (err) {
console.error(err)
}
})
终端运行 node test1.js
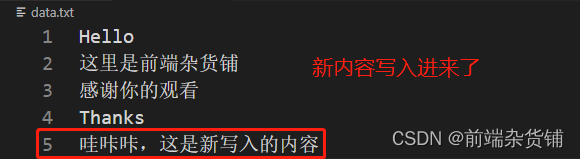
接下来,我们来进行判断文件是否存在的操作
test1.js
const fs = require('fs')
const path = require('path')
// 获取文件目录 __dirname 表示当前文件所在目录
const fileName = path.resolve(__dirname, 'data.txt')
// 判断文件是否存在
fs.exists(fileName, (exist) => {
console.log('exist', exist)
})

那么我们就要使用 stream 流(不是一下子全给,而是通过“小管子”一点点给…)
在 stream-test 文件夹下创建 test1.js 文件
test1.js
// 标准输入输出
process.stdin.pipe(process.stdout)

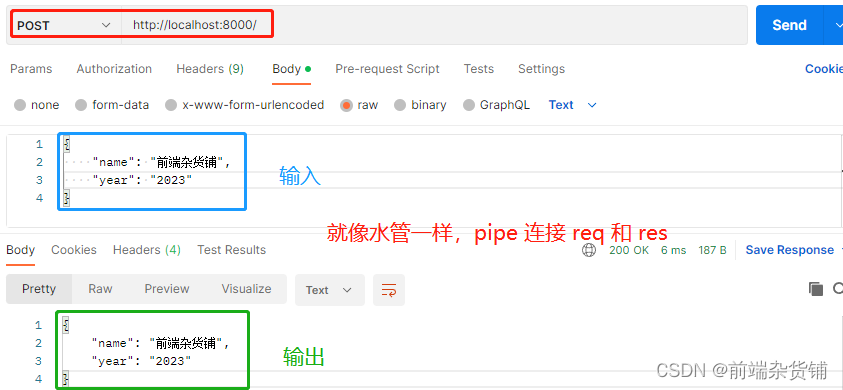
下面我们监听端口,通过 postman 进行简单测试
test1.js
const http = require('http')
const server = http.createServer((req, res) => {
if (req.method === 'POST') {
// 管道连接请求和响应
req.pipe(res)
}
})
// 监听的端口 8000
server.listen(8000)
终端 node test1.js 启动它,之后去 postman 进行测试
我们先创建 stream-test 文件,之后创建文本(原文本和复制的目标文本,之后在 test1.js 中添加一些代码),此时 data.txt 文本有内容,data-bak.txt 文本为空。

data.txt
这里是前端杂货铺
当前目标如下:
把 data.txt 文本里的内容拷贝到 data-bak.txt 中
test1.js
// 复制文件
const fs = require('fs')
const path = require('path')
const fileName1 = path.resolve(__dirname, 'data.txt')
const fileName2 = path.resolve(__dirname, 'data-bak.txt')
// 读取流
const readStream = fs.createReadStream(fileName1)
// 写入流
const writeStream = fs.createWriteStream(fileName2)
// 管道连接
readStream.pipe(writeStream)
// 监听每一次读取的内容
readStream.on('data', chunk => {
console.log(chunk.toString())
})
// 监听拷贝完成
readStream.on('end', () => {
console.log('copy done')
})


发送一个 GET 请求,读取文本的内容
test.js
const http = require('http')
const fs = require('fs')
const path = require('path')
const fileName1 = path.resolve(__dirname, 'data.txt')
const server = http.createServer((req, res) => {
if (req.method === 'GET') {
const readStream = fs.createReadStream(fileName1)
// 将 res 作为 stream 的 dest
readStream.pipe(res)
}
})
// 监听的端口 8000
server.listen(8000)
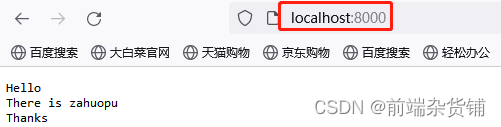
终端 node test1.js 运行,之后打开 8000 端口
我们首先改变一下我们的目录结构(新增如下文件)
logs 里面的文件用来存放写入的日志(创建空文件就好),utils 里面的 log.js 文件用来编写一些写入日志的逻辑
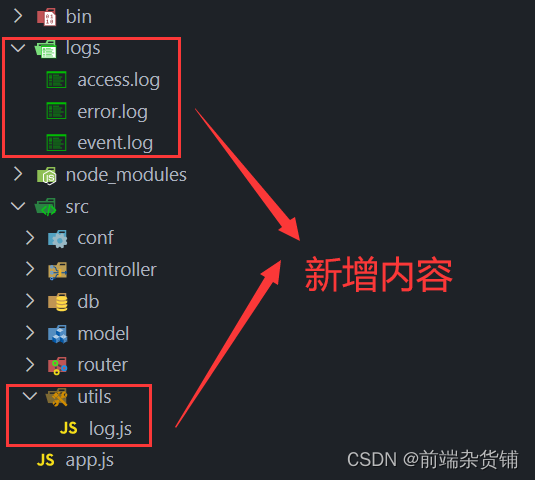
log.js
首先我们引入所需模块,封装写入流函数,访问我们所需的日志,进行换行写入
// 引入 fs 和 path 模块
const fs = require('fs')
const path = require('path')
// 写日志
function writeLog(writeStream, log) {
// 关键代码(每写入一行日志换行一次)
writeStream.write(log + '\n')
}
// 生成 write Stream(第二个水桶)
function createWriteStream(fileName) {
// 找到文件名
const fullFileName = path.join(__dirname, '../', '../', 'logs', fileName)
// 创建写入流(追加的方式)
const writeStream = fs.createWriteStream(fullFileName, {
flags: 'a'
})
// 返回写入的内容
return writeStream
}
// 写访问日志
const accessWriteStream = createWriteStream('access.log')
// 参数 log 为 app.js 中传入的内容
function access(log) {
writeLog(accessWriteStream, log)
}
module.exports = {
access
}
之后更改 app.js 文件,调用 access 函数
app.js
我们先导入 access 进来,之后进行调用,传进所需的参数,用来记录 access log
const { access } = require('./src/utils/log')
...
const serverHandle = (req, res) => {
// 记录 access log
access(`${req.method} -- ${req.url} -- ${req.headers['user-agent']} -- ${Date.now()}`)
......
}
之后,我们打开 http://localhost:8000/api/blog/list 端口,进行三次刷新,查看 access.log 文件中日志的写入

至此,我们明白了 如何进行文件读写,了解了 stream流 的原理及其基本使用,以及如何写日志。 继续跟进学习吧!
后续会对该项目进行多次重构【多种框架(express,koa)和数据库(mysql,sequelize,mongodb)】
如果你需要该项目的 源码,请通过本篇文章最下面的方式 加入 进来~~

如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
这里有一个很好的答案解释了如何在Ruby中下载文件而不将其加载到内存中:https://stackoverflow.com/a/29743394/4852737require'open-uri'download=open('http://example.com/image.png')IO.copy_stream(download,'~/image.png')我如何验证下载文件的IO.copy_stream调用是否真的成功——这意味着下载的文件与我打算下载的文件完全相同,而不是下载一半的损坏文件?documentation说IO.copy_stream返回它复制的字节数,但是当我还没有下
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit