本文主要为了记录在学习armv8的过程中的一些感悟。由于原文部分章节晦涩难懂,作者参考了网上很多优秀博主的部分章节(可能是直接摘录)并结合自己的理解重新整理了当前这个版本。文中不免有部分章节讲解很浅,后续有新的理解会再来修改补充。更新于2020.02.28
Armv8提供了以下互斥的内存类型:
| 类型 | 说明 |
|---|---|
| Normal | 这通常用于大容量内存操作,包括读/写和只读操作。系统中大部分内存都是这种类型 |
| Device | 对该种类型的内存进行读写可能具有连带效应(side-effects,指对一个内存位置的读写操作会影响其它内存位置)或者从该种内存中的一个位置装载的值可能随着装载的次数而变化。通常内存映射外设(指使用访问内存的方法来访问的外设)会采用这种内存类型 |
这里重点说明一下device memory:
The Device memory type attributes define memory locations where an access to the location can cause side-effects, or where the value returned for a load can vary depending on the number of loads performed. Typically, the Device memory attributes are used for memory-mapped peripherals and similar locations.
Device memory属性有三种,分别是Gathering,Reordering,Early Write Acknowledgement
1. Gathering
(1)G 表明内存具有Gathering属性;
(2)nG 表明内存具有non-Gathering属性;
Gathering属性表明是否有如下权限:
(1)对同种类型,同块内存进行读或写操作可以合并成一个single transaction。例如:代码中有2次对同样的一个地址的读访问,那么处理器必须严格进行两次read transaction;
(2)对同种类型,不同内存进行读或写操作可以合并成一个single transaction。如两个byte write merge为一个halfword write;
对于Gathering属性的内存,只要遵循ordering和coherency这两个规则,如上两个行为是被允许的。
2. Reordering
(1)R 表示内存具有reordering属性。
(2)nR 表示内存不具有reordering属性。
Reordering表示允许处理器对内存访问指令进行(优化)重排。
3. Early Write Acknowledgement
(1)E 表示内存具有Early Write Acknowledgement属性
(2)nE 表示内存不具有Early Write Acknowledgement属性
对于内存系统来说,PE写操作的最终结束标志是得到应答。对于No Early Write Acknowledgement属性的内存需要保证:
(1)写操作必须获取最终目的的应答;
(2)不允许其他节点提前提供应答;
PE访问memory是有问有答的(更专业的术语叫做transaction),对于write而言,PE需要write ack操作以便确定完成一个write transaction。为了加快写的速度,系统的中间环节可能会设定一些write buffer。nE表示写操作的ack必须来自最终的目的地而不是中间的write buffer。
Device memory支持如下类型
| 类型 | 说明 |
|---|---|
| Device-nGnRnE | Device non-Gathering, non-Reordering, No Early write acknowledgement. Equivalent to the Strongly-ordered memory type in earlier versions of the architecture |
| Device-nGnRE | Device non-Gathering, non-Reordering, Early Write Acknowledgement. Equivalent to the Device memory type in earlier versions of the architecture. |
| Device-nGRE | Device non-Gathering, Reordering, Early Write Acknowledgement. Armv8 adds this memory type to the translation table formats found in earlier versions of the architecture. The use of barriers is required to order accesses to Device-nGRE memory |
| Device-GRE | Device Gathering, Reordering, Early Write Acknowledgement. Armv8 adds this memory type to the translation table formats found in earlier versions ofthe architecture. Device-GRE memory has the fewest constraints. It behaves similar toNormal memory, with the restriction that Speculative accesses to Device-GRE memory is forbidden. |
本节主要解析ARMv8手册中的Atomicity这个概念。首先给出为何定义这样的概念,定义这个概念的作用为何?然后介绍Atomicity相关的概念,很多时候我们引用了手册的原文,但是由于这些原文可读性比较差,因此,我们使用程序员可理解的一些语言来描述这些概念。
Atomicity是用来描述系统中的memory access的特性的一个术语。在 单核系统上,我们用Single-copy atomicity这个术语来描述,也就是说该内存访问操作是否是原子的,是否是可以被打断的。在多核系统中,用Single-copy atomicity来描述一次内存访问的原子性是不够的,因为即便是在执行该内存访问指令的CPU CORE上是Single-copy atomicity的,也只不过说明该指令不会被本CPU CORE的异常或者中断之类的异步事件打断,它并不能阻止其他CPU core上的内存访问操作对同一地址上的memory location进行操作,这时候,我们使用Multi-copy atomicity来描述 多个CPU CORE发起对同一个地址进行写入的时候,这些内存访问表现出来的特性是怎样的。
主要是为了软件和硬件能够和谐工作在一起。对于软件工程师而言,我们必须了解硬件和软件的“接口”,即那些是HW完成,那些是需要软件完成的,只有这样,软件和CPU的硬件才能愉快的一起玩耍。对于硬件,其architecture reference maual需要定义这些接口。对于ARM处理器而言(并非SOC,主要指CPU core),接口分成两个大类,第一类是指CPU定义的各种通用寄存器、状态寄存器、各种协处理器寄存器,CPU支持的指令集等,这些是属于比较好理解的那一部分,另外一类是关于行为或者说是操作的定义,这部分的接口不是那么明显,但是也是非常重要的。Atomicity即属于第二类接口定义。
英文原文描述如下:
Data accesses from a set of observers to a byte in memory are coherent if accesses to that byte in memory by the members of that set of observers are consistent with there being a single total order of all writes to that byte in memory by all members of the set of observers. This single total order of all to writes to that memory location is the coherence order for that byte in memory.
从英文原文描述,可以得出以下结论:
Single-copy atomicity英文原文定义如下:
A read or write operation is single-copy atomic only if it meets the following conditions:
1. For a single-copy atomic store, if the store overlaps another single-copy atomic store, then all of the writes from one of the stores are inserted into the Coherence order of each overlapping byte before any of the writes of the other store are inserted into the Coherence orders of the overlapping bytes.
2. If a single-copy atomic load overlaps a single-copy atomic store and for any of the overlapping bytes the load returns the data written by the write inserted into the Coherence order of that byte by the single-copy atomic store then the load must return data from a point in the Coherence order no earlier than the writes inserted into the Coherence order by the single-copy atomic store of all of the overlapping bytes.
基本上来说,工程师可以知道上面这段话的每一个单词的含义,但是组合起来就是不知道这段话表达什么意思,为了方便理解,我们首先对几个单词进行解析:
理解了上面的几个英文单词之后,我们来看看整段的英文表述。整段表述分成两个部分:
对于store overlap store而言,每一个store操作的bits都是不可分割的整体,而这个store连同其操作的所有bits做为一个原子的、不可被打断的操作,插入到Coherence order操作序列中。当然,插入时机也很重要,不能随便插入,不能在其他store中的中间过程中插入。如果操作的bits有交叠,例如有8个bit在A B两个store操作中都有涉及,那么这8个比特要么是A store的结果,要么是B store的结果,不能是一个综合A B store操作的结果。
理解了store overlap store之后,load overlap store就很容易了。它主要是从其他观察者的角度看:如果load和store操作的memory区域有交叠,那么那些交叠区域的返回值(对load操作而言)要么是全部bit被store写入,要么没有任何写入,不会是一个中间结果。
Multi-copy atomicity英文原文定义如下:
In a multiprocessing system, writes to a memory location are multi-copy atomic if the following conditions are both true:
1、All writes to the same location are serialized, meaning they are observed in the same order by all observers, although some observers might not observe all of the writes.
2、A read of a location does not return the value of a write until all observers observe that write.
single-copy atomicity描述的是内存访问指令操作的原子性,而Multi-copy atomicity定义的是multiprocessing 环境下,多个store操作的顺序问题以及多个observer之间的交互问题,因此Single-copy atomicity和Multi-copy atomicity定义的内容是不一样的,或者说Multi-copy atomicity并不是站在Single-copy atomicity的对立面,它们就是不同的东西而已。那么,你可能会问:到底Multi-copy atomicity中的Multi-copy是什么意思呢?我理解是这样的:系统中有多个CPU core,每一个core都可以对内存系统中的某个特定的地址发起写入操作,系统中有n个CORE,那么就有可能有n个寄存器到memory的copy动作。
对Multi-copy atomicity的定义解释倒是比较简单:
显然,根据定义,Multi-copy atomicity要求比较严格,对cpu performance伤害很大。
1. AArch64 - Single-copy atomicity
对于从异常级别生成的显式内存访问(通过load或者store指令进行的内存访问),以下规则适用:
| 类型 | 说明 |
|---|---|
| load单个通用寄存器并与指令中所读寄存器的大小对齐的装入指令生成的读 | Single-copy atomicity |
| store单个通用寄存器并与指令中写操作大小对齐的store指令生成的写操作 | Single-copy atomicity |
| load两个通用寄存器并与每个寄存器的加载大小对齐的Load Pair指令生成的读取 | 两个Single-copy atomicity读取 |
| store两个通用寄存器并与每个寄存器的存储大小对齐的 Store pair指令生成的写操作 | 两个Single-copy atomicity写操作 |
| Load-Exclusive Pair(加载2个32-bit)指令和Store-Exclusive Pair(写入2个32-bit数据)指令 | Single-copy atomicity |
| 两个64位的Load Exclusive/Store Exclusive Pair指令的Store Exclusive执行成功时 | 会对整个内存位置进行Single-copy atomicity更新 |
| 对转化表遍历生成的对转换表项的读取 | Single-copy atomicity |
| 指令获取的原子性 | 请参阅B2-120页的指令并发修改和执行 |
| 对SIMD和单个64位或更小数(与所加载数量的大小对齐)的浮点寄存器的读取 | Single-copy atomicity |
| 对64位或更小的元素的SIMD和浮点寄存器的元素或结构读取(每个元素与要加载的元素的大小对齐) | 每个元素视为Single-copy atomicity存储 |
| 对SIMD和64位或更小的元素的浮点寄存器进行的元素或结构写操作(每个元素与要存储的元素的大小对齐) | 每个元素视为Single-copy atomicity存储 |
| 对64位或更小元素的SIMD和浮点寄存器写入的元素或结构(其中每个元素与存储的元素大小对齐) | 每个元素视为Single-copy atomicity存储 |
| 对内存中64位对齐的128位值的SIMD和浮点寄存器的读取 | 视为一对Single-copy atomicity64位读取 |
| 对内存中64位对齐的128位值的SIMD和浮点寄存器的写入 | 视为一对Single-copy atomicity64位写入 |
| 对于未对齐的内存访问 | 参考 page B2-148 数据访问对齐 |
| 由CASP指令访问的 two words or double-words的读写 | Single-copy atomicity |
所有其他内存访问都被视为字节访问流,不同字节访问之间不存在原子性。对任何字节的所有访问都是单拷贝原子的。
2. AArch64 - Multi-copy atomicity
显式内存访问(通过load或者store指令进行的内存访问) 的规则如下:
| 类型 | 说明 |
|---|---|
| 对于normal memory | 写入操作不需要具备Multi-copy atomicity的特性 |
| 如果是Device类型的memory,并且具备non-Gathering的属性 | 所有符合Single-copy atomicity要求的write操作指令也都是Multi-copy atomicity的 |
| 如果是Device类型的memory,并且具备Gathering的属性 | 写入操作不需要具备Multi-copy atomicity的特性 |
3. AArch32 - Single-copy atomicity
对于从异常级别生成的显式内存访问(通过load或者store指令进行的内存访问),以下规则适用:
| 类型 | 说明 |
|---|---|
| 所有byte访问 | Single-copy atomicity |
| 所有halfword 访问halfword-aligned的位置 | Single-copy atomicity |
| 所有word 访问 word-aligned的位置 | Single-copy atomicity |
| 由LDREXD和STREXD指令导致的内存访问到doubleword-aligned的位置 | Single-copy atomicity |
| LDM、LDC、LDRD、STM、STC、STRD、PUSH、POP、RFE、SRS、VLDM、VLDR、VSTM和VSTR指令作为一个word-aligned的word访问序列执行时 | 每个32位word访问保证是Single-copy atomicity的。该体系结构不要求序列中两个或多个word访问的子序列为Single-copy atomicity序列 |
| LDRD和STRD对64位对齐位置的访问 | 64位 Single-copy atomicity |
| 高级SIMD元素和结构load/store作为访问元素或结构大小的序列执行 | 该体系结构要求元素访问是Single-copy atomicity访问,当且仅当 :(1)元素大小为32位或更小;(2)元素是自然对齐的 |
| 对32位对齐的64位元素或结构的访问作为32位访问序列执行 | 每个32位访问都是Single-copy atomicity访问。该体系结构不要求序列中两个或多个32位访问的子序列为Single-copy atomicity |
更多的规则可以参考ARMV8手册,这里不再描述。
为了支持数据一致性协议 ,需要增加硬件很多开销,会降低系统的性能,同时也会增加系统的功耗。但是,很多时候并不需要系统中的所有模块之间都保持数据一致性,而只需要在系统中的某些模块之间保证数据一致性就行了。因此,需要对系统中的所有模块,根据数据一致性的要求,做出更细粒度的划分。ARMv8架构将这种划分称作为域(Domain)
共享域一共划分成了四类:
| 共享域类型 | 说明 |
|---|---|
| 非共享域(Non-shareable) | 处于这个域中的内存只由当前CPU核访问,所以,如果一个内存区域是非共享的,系统中没有任何硬件会保证其缓存一致性。如果一不小心共享出去了,别的CPU核可以访问了,那必须由软件自己来保证其一致性。 |
| 内部共享域(Inner Shareable) | (1) 处于这个域中的内存可以由系统中的多个模块同时访问,并且系统硬件保证对于这段内存,对于处于同一个内部共享域中的所有模块,保证缓存一致性。 (2) 一个系统中可以同时存在多个内部共享域,对一个内部共享域做出的操作不会影响另外一个内部共享域。 |
| 外部共享域(Outer Shareable) | (1) 处于这个域中的内存也可以由系统中的多个模块同时访问,并且系统硬件保证对于这段内存,对于处于同一个外部共享域中的所有模块,保证缓存一致性。外部共享域可以包含一个或多个内部共享域,但是一个内部共享域只能属于一个外部共享域,不能被多个外部共享域共享。 (2) 对一个外部共享域做出的操作会影响到其包含的所有的内部共享域。 |
| 全系统共享域(Full System) | 表示对内存的修改可以被系统中的所有模块都感知到 |
在一个具体的系统中,不同域的划分是由硬件平台设计者决定的,不由软件控制。并且,Arm的文档中也没有提及具体要怎么划分。但有一些指导原则,一般在一个操作系统中可以看到的所有CPU核要分配在一个内部域里面,如下图所示:
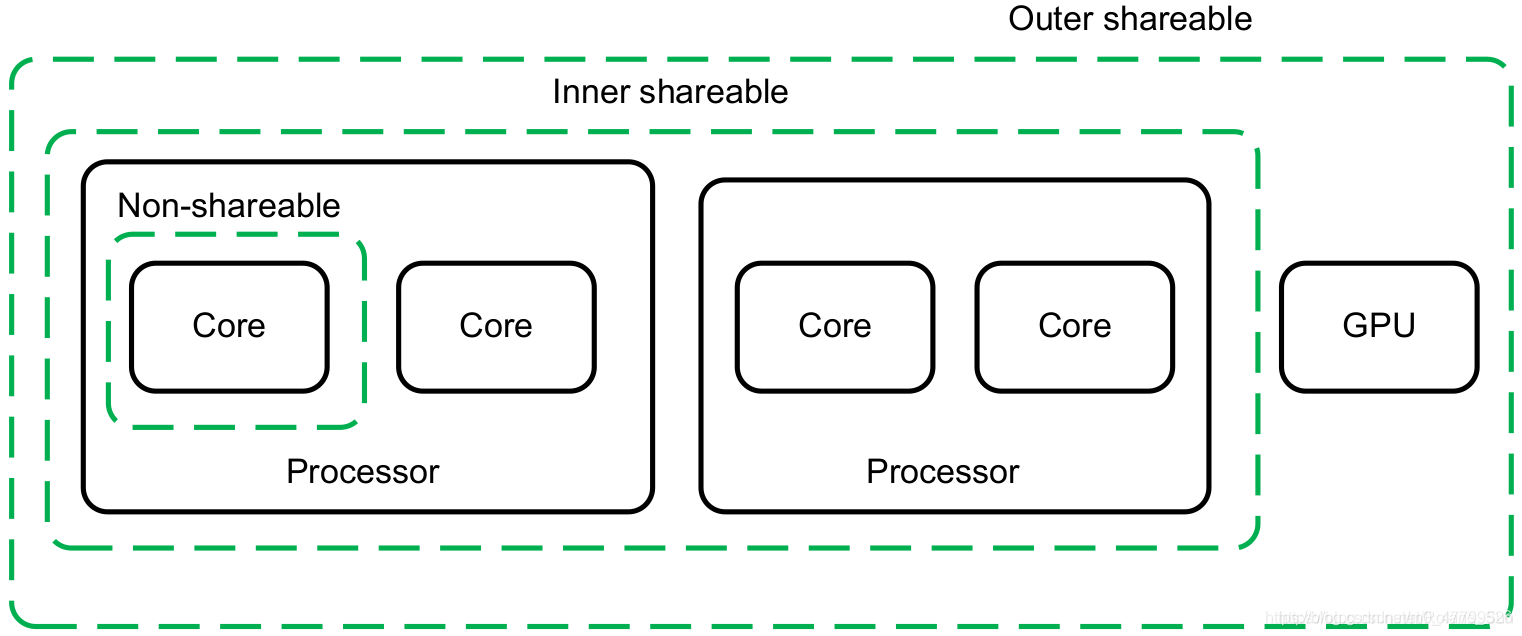
这些域的划分只是为了更细粒度的管理内存的缓存一致性,理论上所有内存都可以放到全系统共享域中,从功能上说也可以,但会影响性能。
可缓存性和共享性一定是对普通内存才有的概念。设备内存一定是不支持缓存的,且是外部共享的。
1. 缓存
高速缓存是一个高速内存块,包含许多条目,每个条目包括:
缓存的存在主要是为了提高内存访问的平均速度。缓存考虑了两个本地原则
| 原则 | 说明 |
|---|---|
| 空间局部性 | 访问一个位置之后可能会访问相邻的位置。这一原则的例子有:顺序指令执行时和访问数据结构时 |
| 时间局部性 | 被引用过一次的存储器位置在未来会被多次引用(通常在循环中) |
2. 内存分级体系
通常,靠近PE的内存具有非常低的延迟,但在大小上受到限制,并且实现成本昂贵。除了PE之外,通常实现更大的内存块,但这会增加延迟。为了优化整体性能,Armv8内存系统可以在层次化内存系统中包含多个缓存级别,从而利用大小和延迟之间的权衡。下图体现了一个典型的ARMv8架构处理器的多级存储系统:
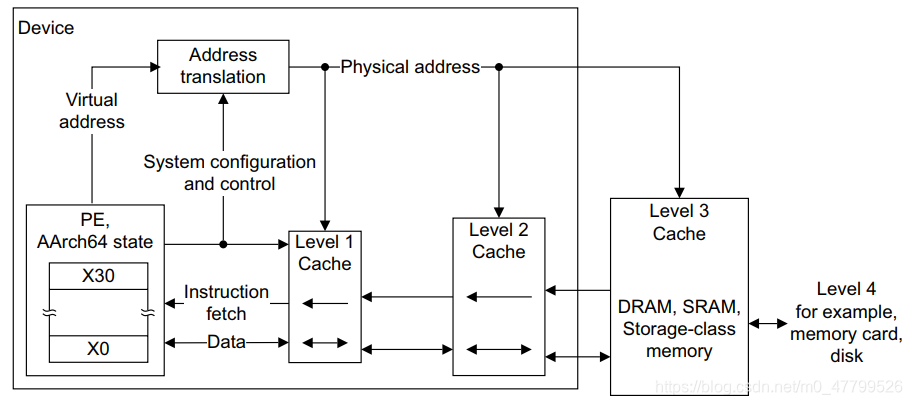
流程如下:
内存屏障是应用于一条指令或指令序列的通用术语,该指令或指令序列可强制PE退出同步的加载/存储指令。 Armv8架构定义的内存屏障提供了一系列功能,包括:
• 对加载/存储指令进行排序;
• 完成加载/存储指令; • 上下文的同步。
Arm系统有两种类型的缓存,一种是指令缓存(I-Cache),还有一种是数据缓存(D-Cache)。因此,内存屏障指令还要区分是对指令的还是针对普通数据的。
| 屏障类型 | 中英文全称 | 功能描述 | 严格程度 |
|---|---|---|---|
| DMB | 数据内存屏障 Data Memory Barrier | 数据内存屏障保证仅当所有在它前面的存储器访问操作都执行完毕后,才提交(commit)在它后面的存储器访问操作。 | 低 |
| DSB | 数据同步屏障 Data Synchronization Barrier | 数据同步屏障在保证和前面的数据内存屏障相同的存储器访问操作顺序的同时,还会保证在这条指令之后的所有指令(不仅仅是存储器操作指令)一定会在这条指令之后才会执行。因此,数据同步屏障比数据内存屏障更加严格 | 中 |
| ISB | 指令同步屏障 Instruction Synchronization Barrier | 指令同步屏障会清洗当前CPU核的流水线和指令预取缓冲,以保证所有这条指令前面的指令都执行完毕之后,才执行这条指令后面的指令 | 高 |
ISB 指令可确保在ISB指令完成后,在高速缓存或内存中的所有指令按照程序顺序依次全部完成执行。 使用ISB 确保在ISB 指令之后获取的指令可以看到在ISB 之前执行的上下文更改操作的效果。
需要插入ISB指令的场景如下:
按程序顺序出现的任何上下文的改变操作都只在ISB已经被执行之后生效。
ISB操作的伪代码函数是 InstructionSynchronizationBarrier()。
数据内存屏障保证,站在系统中其它同属一个域的模块来看,在这条指令之前的存储器访问操作(包括加载或存储)一定比在这条指令之后的存储器访问操作先被感知到。也就是说,数据内存屏障指令阻止在这条指令之前的所有存储器访问操作被重排序到这条指令之后,同时也会阻止这条指令之后的所有存储器访问指令被重排序到这条指令之前。
DMB 指令只影响内存访问和数据缓存的操作以及统一缓存维护指令。它对处理器上执行的任何其他指令的顺序没有影响。用于确保缓存维护指令完成的 DMB 指令必须同时具有加载和存储的访问类型。
SB 指令可以防止指令的推测性执行,直到屏障完成后,才能通过旁路观察到这些指令。
原文翻译,作者水平有限,可能存在部分偏差
CSDB 指令用来控制推测性执行和数据值的预测。包括
原文翻译,作者水平有限,可能存在部分偏差
SSBB指令在某些情况下,防止推测性的从旁路加载先前存储到同一虚拟地址的值。
当在SSBB指令之后,加载某个位置时,则加载不会从满足以下所有条件的任何存储位置中,以一致性顺序推测性地读取比最后一次存储生成的条目更早的条目:
当在SSBB指令之前,加载某个位置时,则加载不会从满足以下所有条件的任何存储位置中推测性地读取数据:
原文翻译,作者水平有限,可能存在部分偏差PSB CSYNC指令用来确保当前处理器的所有现有分析数据都已格式化,并且分析缓冲区地址已经转换,以便所有对分析缓冲区的写入都已启动。对分析缓冲区的写入完成后,以下DSB指令将完成。
如果未实现统计分析扩展,则此指令将作为NOP执行。
原文翻译,作者水平有限,可能存在部分偏差在某些情况下,防止推测性的从旁路加载先前存储到同一物理地址的值。
物理推测性存储旁路屏障的语义是:
当在PSSBB指令之后,加载某个位置时,则加载不会从满足以下所有条件的任何存储位置中,以一致性顺序推测性地读取比最后一次存储生成的条目更早的条目:
当加载到某个位置时,在PSSBB指令之前以程序顺序出现,则加载不会从满足以下所有条件的任何存储中推测性地读取数据:
注意:这种屏障的效果适用于对同一位置的访问,即使它们是用不同的虚拟地址和不同的异常级别访问的。
原文翻译,作者水平有限,可能存在部分偏差TSB CSYNC 指令保留由于跟踪操作和对同一寄存器的其他内存访问而对系统寄存器进行内存访问的相对顺序。
跟踪操作是处理器跟踪单元在实现和启用FEAT_TRF时为指令生成跟踪的操作。
相对于其他指令,TSB CSYNC指令不需要按程序顺序执行。这包括相对于其他跟踪指令重新排序。需要一个或多个上下文同步事件,以确保TSB CSYNC指令按必要的顺序执行。
如果在上下文同步事件和TSB CSYNC操作之间生成跟踪,则这些跟踪操作可能会相对于TSB CSYNC操作重新排序,因此可能不会同步。
数据同步屏障在保证和前面的数据内存屏障相同的存储器访问操作顺序的同时,还会保证在这条指令之后的所有指令(不光是存储器操作指令)一定会在这条指令之后才会执行。因此,数据同步屏障比数据内存屏障更加严格。
需要执行DSB指令的场景有:
DMB和DSB指令都需要带一个参数,这个参数指明了数据屏障指令的作用范围和针对的共享域。
1. 共享域前面说过了,一共有四种,分别是:
2. 作用范围表示数据屏障指令具体对哪些存储器访问操作起作用,ARMv8共定义了三种,分别是:
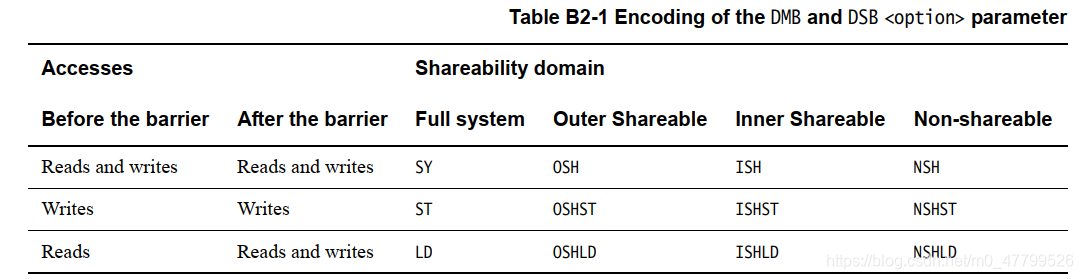
3. Linux内核中对内存屏障的定义
Linux将不同类型的内存屏障和ARMv8提供的屏障指令都做了映射(代码位于arch/arm64/include/asm/barrier.h中):
#define isb() asm volatile("isb" : : : "memory")
#define dmb(opt) asm volatile("dmb " #opt : : : "memory")
#define dsb(opt) asm volatile("dsb " #opt : : : "memory")
......
#define spec_bar() asm volatile(ALTERNATIVE("dsb nsh\nisb\n", \
SB_BARRIER_INSN"nop\n", \
ARM64_HAS_SB))
#define mb() dsb(sy)
#define rmb() dsb(ld)
#define wmb() dsb(st)
#define dma_rmb() dmb(oshld)
#define dma_wmb() dmb(oshst)
......
#define __smp_mb() dmb(ish)
#define __smp_rmb() dmb(ishld)
#define __smp_wmb() dmb(ishst)
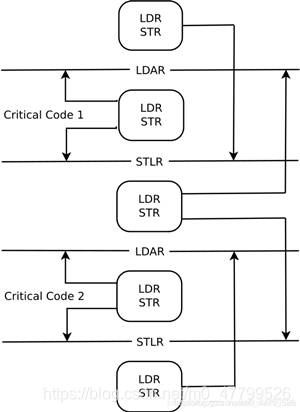
前面的所有屏障指令对于ARMv8之前所有的架构都有效,在ARMv8架构下,还加入了一类单向屏障指令,也就是所谓的Load-Acquire(LDAR指令)和Store-Release(STLR指令)。
普通的内存屏障一般是双向的,也就是可以控制内存屏障之前的某些存储操作要在内存屏障之前完成,并且内存屏障之后的某些存储操作要在内存屏障之后才能开始。但是Load-Acquire和Store-Release却只限定了单个方向的:
Load-Acquire:这条指令之后的所有加载和存储操作一定不会被重排序到这条指令之前,但是没有要求这条指令之前的所有加载和存储操作一定不能被重排序到这条指令之后。所以,可以看出来,这条指令是个单向屏障,只挡住了后面出现的所有内存操作指令,但是没有挡住这条指令之前的所有内存操作指令。
Store-Release:这条指令之前的所有加载和存储才做一定不会被重排序到这条指令之后,但是没有要求这条指令之后的所有加载和存储操作一定不能被重排序到这条指令之前。所以,这条指令也是一个单向屏障,只挡住了前面出现的所有内存操作指令,但是没有挡住这条指令之后的所有内存操作指令。
LDAR和STLR指令也有作用的共享域,只不过没有明确在指令中表示出来。这两条指令的共享域就是它们操作的内存的共享域。比如,如果LDAR指令读取内存的地址是属于内部共享域的,那么这条指令锁提供的屏障也只是作用于这个内部共享域。
还有一点,如果LDAR指令出现在STLR指令之后,处理器也会保证LDAR指令一定不会被重排序到STLR指令之前。
单向屏障的作用范围可以总结为下面这张图:
参考:
(1)共享域的概念和单向屏障参考:Arm64内存屏障
(2)内存屏障的分类:谈乱序执行和内存屏障
(3) Arm架构中的原子性参考:ARMv8之Atomicity
(4)《ARM Architecture Reference Manual, for ARMv8-A architecture profile》--- B2.7.2 Device memory
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我需要在客户计算机上运行Ruby应用程序。通常需要几天才能完成(复制大备份文件)。问题是如果启用sleep,它会中断应用程序。否则,计算机将持续运行数周,直到我下次访问为止。有什么方法可以防止执行期间休眠并让Windows在执行后休眠吗?欢迎任何疯狂的想法;-) 最佳答案 Here建议使用SetThreadExecutionStateWinAPI函数,使应用程序能够通知系统它正在使用中,从而防止系统在应用程序运行时进入休眠状态或关闭显示。像这样的东西:require'Win32API'ES_AWAYMODE_REQUIRED=0x0
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此