我使用的云服务器centos7,2核+4G内存,跑起来内存使用率50%左右
建议使用最低配置和我一样,1+2的配置kibana应该跑不起来,安装过程使用了尚硅谷的springcloud的课程资料,也!!!!!!!!可以不用,自己pull,我附了pull的方法
资料包:链接:https://pan.baidu.com/s/1GW1qUUwya6mUAacFokpZUw?pwd=eses
提取码:eses
参考资料:https://blog.csdn.net/liurui_wuhan/article/details/115480511
使用的版本都是7.12.1
使用的安装方式是docker
创建kibana和es可以在docker中互联的网络
docker network create es-net
将资料包中的es.tar上传到服务器
# 导入数据2
docker load -i es.tar
ps:也可以自己pull ,只要最后的docker里有镜像就好了
#pull的方法
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.12.1
docker pull kibana:7.12.1
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "http.host=0.0.0.0"\
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
命令解释:
--name es :给启动的容器别名,查看的时候可以直接使用es代替所有需要填写容器名称的地方,比如docker logs -f es
-e "cluster.name=es-docker-cluster":设置集群名称
-e "http.host=0.0.0.0":监听的地址,可以外网访问
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小
-e "discovery.type=single-node":非集群模式
-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录
-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录
-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录
--privileged:授予逻辑卷访问权
--network es-net :加入一个名为es-net的网络中
-p 9200:9200:端口映射配置
在浏览器中输入:http://服务器地址:9200 即可看到elasticsearch的响应结果:
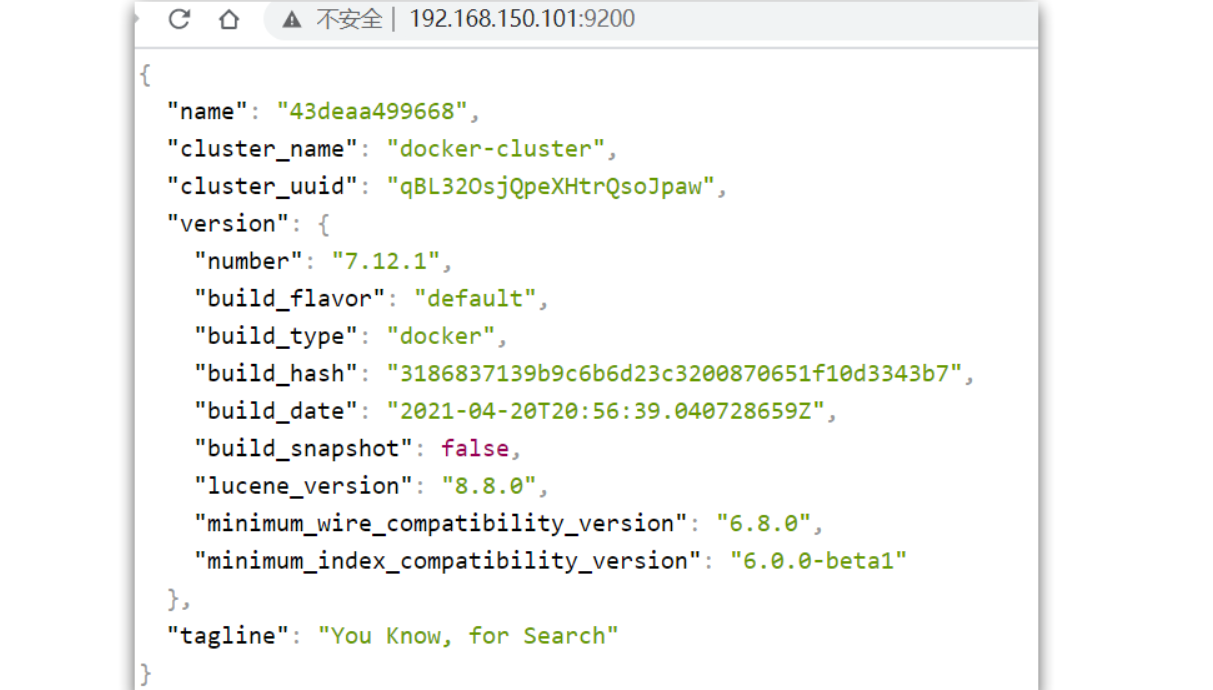
kibana提供了可视化的界面
跟es一样,上传到服务器,再加载
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
--network es-net :加入一个名为es-net的网络中,与elasticsearch在同一个网络中-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch-p 5601:5601:端口映射配置kibana启动一般比较慢,需要多等待一会,可以通过命令:
docker logs -f kibana
查看运行日志,当查看到下面的日志,说明成功:
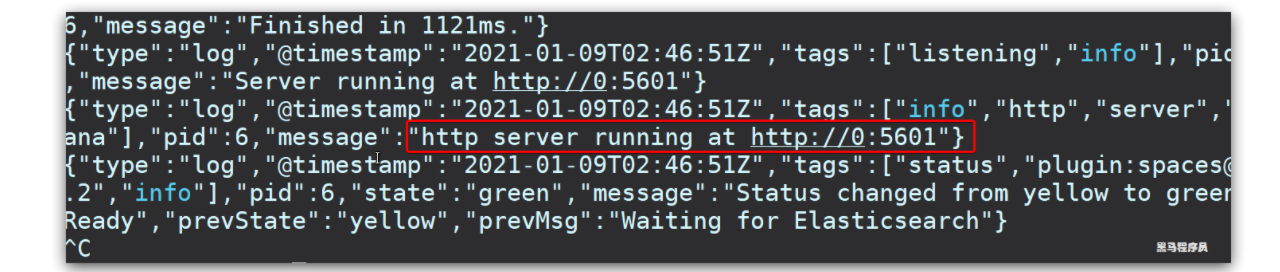
此时,在浏览器输入地址访问:http://服务器地址:5601,即可看到结果
filebeat要安装在你需要采集数据的计算机上,不一定要和es安装在一台机器上
比如我的项目是在本地跑,filebeat就要安在我的本机也就是windows下
https://www.elastic.co/cn/downloads/past-releases/filebeat-7-12-1
# ============================== Filebeat inputs ===============================
filebeat.inputs:
- type: log
enabled: true
encoding: UTF-8
paths:
#你需要采集数据的地址,比如这个是我的项目生成log文件的地址
- D:\socialManeger\test1\logs\oper\*.log
# ---------------------------- Elasticsearch Output ----------------------------
output.elasticsearch:
# es 地址
hosts: ["1.14.120.65:9200"]
ps:这是最简单的yml,如果要实现过滤或者其他的功能,可以去看看他的配置文件详解
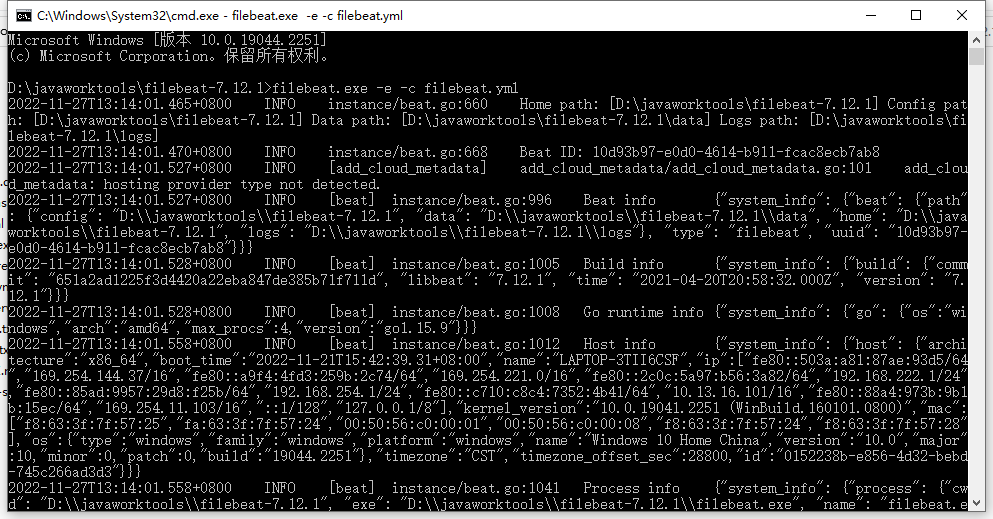
进入filebeat的安装目录
filebeat.exe -e -c filebeat.yml
1.pom.xml 新增logstash-logback-encoder依赖,logstash-logback-encoder可以将日志以json的方式输出,也不用我们单独处理多行记录问题
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>5.3</version>
</dependency>
2.配置logback-spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration >
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<contextName>logback</contextName>
<property name="log.path" value="logs/" />
<!--输出到控制台-->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>debug</level>
</filter>
<encoder>
<Pattern>${CONSOLE_LOG_PATTERN}</Pattern>
<!-- 设置字符集 -->
<charset>UTF-8</charset>
</encoder>
</appender>
<!--输出到文件-->
<appender name="INFO_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}/oper/oper.log</file>
<encoder>
<pattern>%msg%n</pattern>
<charset>UTF-8</charset>
</encoder>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>${log.path}/oper/oper -%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxFileSize>100MB</maxFileSize>
<maxHistory>30</maxHistory>
<totalSizeCap>1GB</totalSizeCap>
</rollingPolicy>
<encoder class="net.logstash.logback.encoder.LogstashEncoder" >
<providers>
<timestamp>
<timeZone>Asia/Shanghai</timeZone>
</timestamp>
<pattern>
<pattern>{"message": "%message"}</pattern>
</pattern>
</providers>
</encoder>
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>info</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<!-- 时间滚动输出 level为 ERROR 日志 -->
<appender name="ERROR_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${log.path}/error/error.log</file>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
<charset>UTF-8</charset> <!-- 此处设置字符集 -->
</encoder>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>${log.path}/error/error-%d{yyyy-MM-dd}.%i.log</fileNamePattern>
<maxFileSize>100MB</maxFileSize>
<maxHistory>30</maxHistory>
<totalSizeCap>1GB</totalSizeCap>
</rollingPolicy>
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERROR</level>
<onMatch>ACCEPT</onMatch>
<onMismatch>DENY</onMismatch>
</filter>
</appender>
<root level="INFO">
<appender-ref ref="STDOUT" />
<appender-ref ref="INFO_FILE" />
<appender-ref ref="ERROR_FILE" />
</root>
<!--name:用来指定受此loger约束的某一个包或者具体的某一个类。-->
<!--addtivity:是否向上级loger传递打印信息。默认是true。-->
<logger name="com.netflix" level="ERROR" />
<logger name="net.sf.json" level="ERROR" />
<logger name="org.springframework" level="ERROR" />
<logger name="springfox" level="ERROR" />
</configuration>
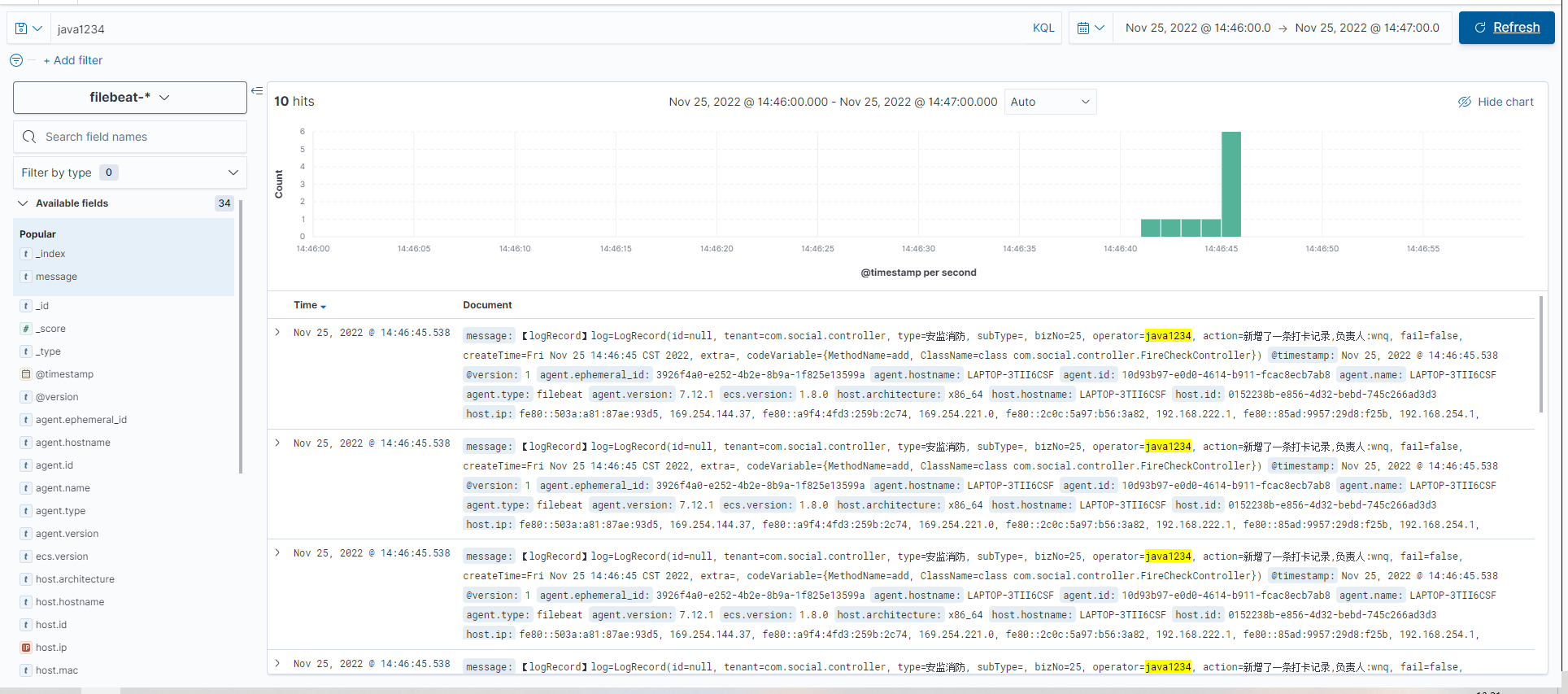
启动springboot服务,生成的日志会自动被filebeat采集并推送到es,可以查询
如果想定制fielbeat.yml和logback.xml,可以去找参考资料
logback.xml详解:
logback中文文档:https://www.docs4dev.com/docs/zh/logback/1.3.0-alpha4/reference/architecture.html
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
我正在构建一个小部件来显示奥运会的奖牌数。我有一个“国家”对象的集合,其中每个对象都有一个“名称”属性,以及奖牌计数的“金”、“银”、“铜”。列表应该排序:1.首先是奖牌总数2.如果奖牌相同,按类型分割(金>银>铜,即2金>1金+1银)3.如果奖牌和类型相同,则按字母顺序子排序我正在用ruby做这件事,但我想语言并不重要。我确实找到了一个解决方案,但如果感觉必须有更优雅的方法来实现它。这是我做的:使用加权奖牌总数创建一个虚拟属性。因此,如果他们有2个金牌和1个银牌,加权总数将为“3.020100”。1金1银1铜为“3.010101”由于我们希望将奖牌数排序为最高的,因此列表按降序排
如何在出现异常时指定全局救援,如果您将Sinatra用于API或应用程序,您将如何处理日志记录? 最佳答案 404可以在not_found方法的帮助下处理,例如:not_founddo'Sitedoesnotexist.'end500s可以通过调用带有block的错误方法来处理,例如:errordo"Applicationerror.Plstrylater."end错误的详细信息可以通过request.env中的sinatra.error访问,如下所示:errordo'Anerroroccured:'+request.env['si
我正在使用ruby标准记录器,我想要每天轮换一次,所以在我的代码中我有:Logger.new("#{$ROOT_PATH}/log/errors.log",'daily')它运行完美,但它创建了两个文件errors.log.20130217和errors.log.20130217.1。如何强制它每天只创建一个文件? 最佳答案 您的代码对于长时间运行的应用程序是正确的。发生的事情是您在给定的一天多次运行代码。第一次运行时,Ruby会创建一个日志文件“errors.log”。当日期改变时,Ruby将文件重命名为“errors.log
在运行Cucumber测试时,我得到(除了测试结果)大量调试/日志相关的输出形式:D,[2013-03-06T12:21:38.911829#49031]DEBUG--:SOAPrequest:D,[2013-03-06T12:21:38.911919#49031]DEBUG--:Pragma:no-cache,SOAPAction:"",Content-Type:text/xml;charset=UTF-8,Content-Length:1592W,[2013-03-06T12:21:38.912360#49031]WARN--:HTTPIexecutesHTTPPOSTusingt
我最近将我的http客户端切换到faraday,一切都按预期工作。我有以下代码来创建连接:@connection=Faraday.new(:url=>base_url)do|faraday|faraday.useCustim::Middlewarefaraday.request:url_encoded#form-encodePOSTparamsfaraday.request:jsonfaraday.response:json,:content_type=>/\bjson$/faraday.response:loggerfaraday.adapterFaraday.default_ada
网站的日志分析,是seo优化不可忽视的一门功课,但网站越大,每天产生的日志就越大,大站一天都可以产生几个G的网站日志,如果光靠肉眼去分析,那可能看到猴年马月都看不完,因此借助网站日志分析工具去分析网站日志,那将会使网站日志分析工作变得更简单。下面推荐两款网站日志分析软件。第一款:逆火网站日志分析器逆火网站日志分析器是一款功能全面的网站服务器日志分析软件。通过分析网站的日志文件,不仅能够精准的知道网站的访问量、网站的访问来源,网站的广告点击,访客的地区统计,搜索引擎关键字查询等,还能够一次性分析多个网站的日志文件,让你轻松管理网站。逆火网站日志分析器下载地址:https://pan.baidu.
我正在使用此代码在我的Sinatra应用程序中启用日志记录:log_file=File.new('my_log_file.log',"a")$stdout.reopen(log_file)$stderr.reopen(log_file)$stdout.sync=true$stderr.sync=true实际的日志记录是使用:logger.debug("Startingcall.Params=#{params.inspect}")事实证明,只有INFO或更高级别的日志消息被记录,而DEBUG消息没有被记录。我正在寻找一种将日志级别设置为DEBUG的方法。 最佳
我有这段代码来跟踪远程日志文件:defdo_tail(session,file)session.open_channeldo|channel|channel.on_datado|ch,data|puts"[#{file}]->#{data}"endchannel.exec"tail-f#{file}"endNet::SSH.start("host","user",:password=>"passwd")do|session|do_tailsession,"/path_to_log/file.log"session.loop我只想在file.log中检索带有ERROR字符串的行,我正在尝
当我为Daemons(1.1.0)gem设置日志记录参数时,我将如何实现与此行类似的行为?logger=Logger.new('foo.log',10,1024000)守护进程选项:options={:ARGV=>['start'],:dir_mode=>:normal,:dir=>log_dir,:multiple=>false,:ontop=>false:mode=>:exec,:backtrace=>true,:log_output=>true} 最佳答案 不幸的是,Daemonsgem不使用Logger。它将STDOUT和S