✨ redis基本数据类型
📃个人主页:不断前进的皮卡丘
🌞博客描述:梦想也许遥不可及,但重要的是追梦的过程,用博客记录自己的成长,记录自己一步一步向上攀登的印记
🔥个人专栏:微服务专栏
✔️redis常见的操作命令:http://www.redis.cn/commands.html
| 命令 | 功能 |
|---|---|
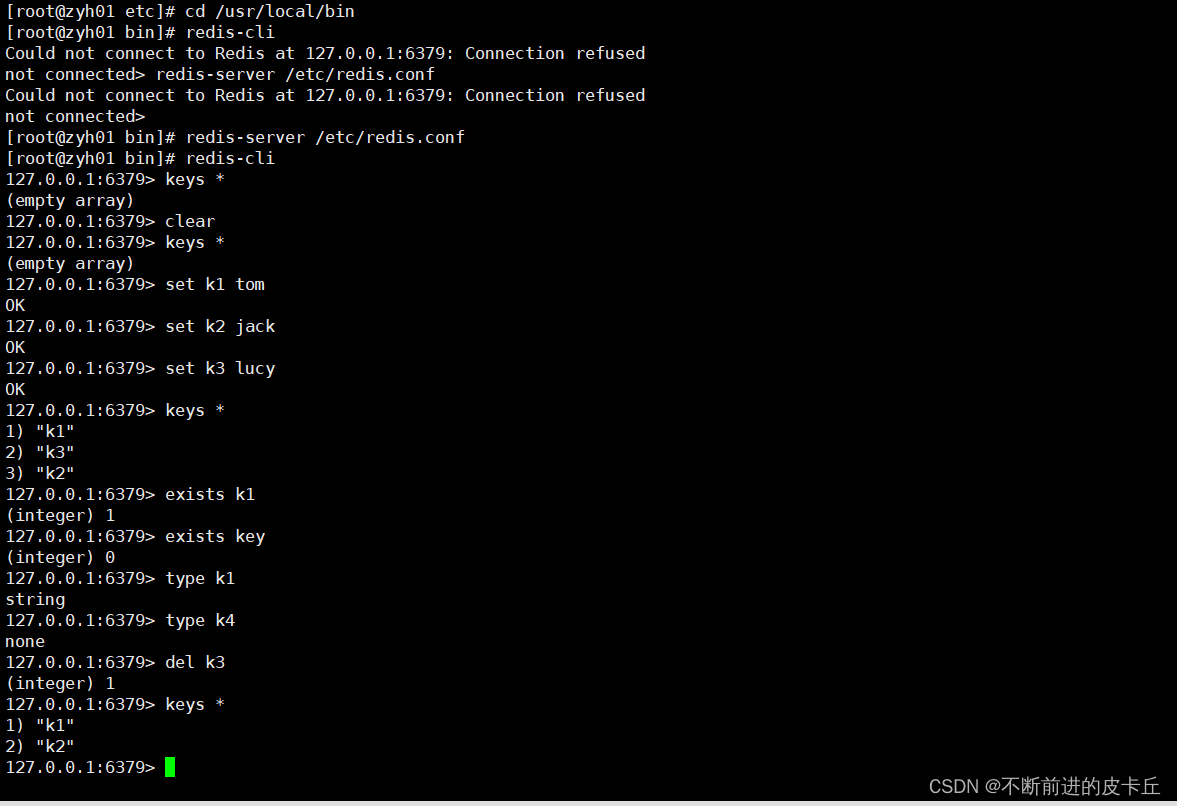
| keys * | 查看当前库的所有key |
| exists key | 判断某个key是否存在 |
| type key | 查看某个key的数据类型 |
| del key | 删除指定key |
| unlink key | 根据value选择非阻塞删除,仅仅把key从keyspace元数据中删除,真正的删除会在后续异步操作,也就是把删除操作放到其他线程中进行 |
| expire key 10 | 为key设置过期时间为10秒钟 |
| ttl key | 查看key还有多少秒过期,-1表示永远不过期,-2表示已经过期 |
| select | 切换数据库 |
| dbsize | 查看当前数据库的key的数量 |
| flushdb | 清空当前数据库数据 |
| flushall | 清除所有数据库数据 |

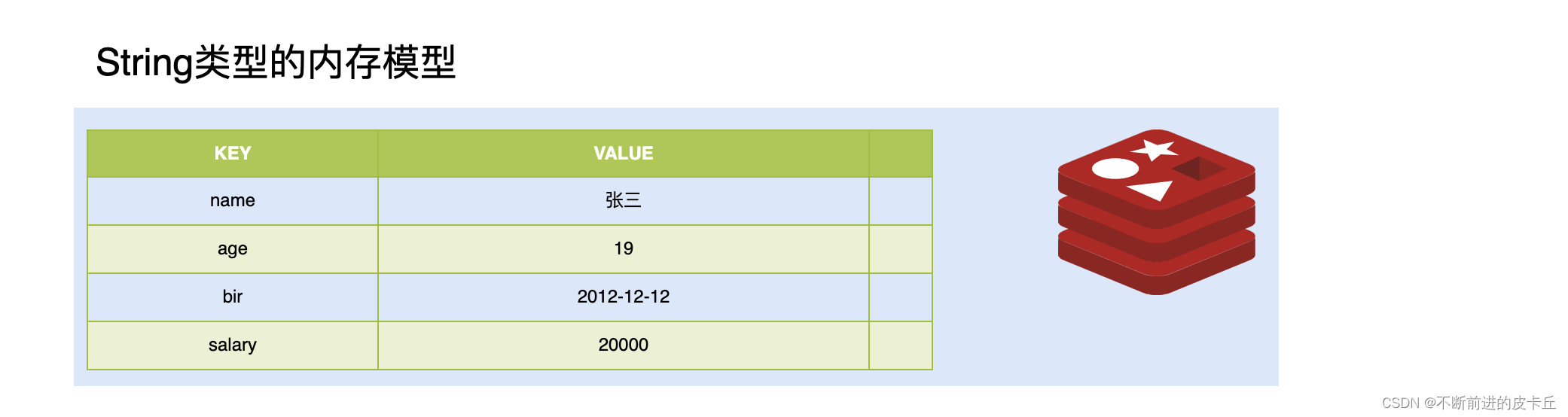
String是Redis最基本的类型,一个key对应一个value。
String类型是二进制安全的。意味着Redis的string可以包含任何数据。比如jpg图片或者序列化的对象。
String类型是Redis最基本的数据类型,一个Redis中字符串value最多可以是512M

| 命令 | 说明 |
|---|---|
| set | 设置一个key/value |
| get | 根据key获得对应的value |
| mset | 一次设置多个key value |
| mget | 一次获得多个key的value |
| getset | 获得原始key的值,同时设置新值 |
| strlen | 获得对应key存储value的长度 |
| append | 为对应key的value追加内容 |
| getrange 索引0开始 | 截取value的内容 |
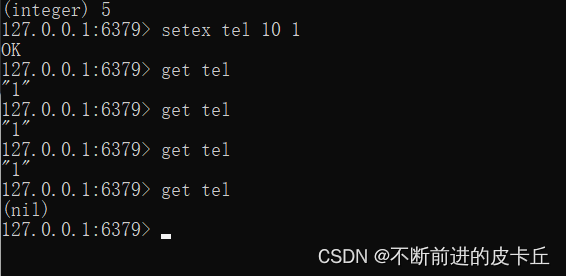
| setex | 设置一个key存活的有效期(秒) |
| psetex | 设置一个key存活的有效期(毫秒) |
| setnx | 存在不做任何操作,不存在添加 |
| msetnx原子操作(只要有一个存在不做任何操作) | 可以同时设置多个key,只有有一个存在都不保存 |
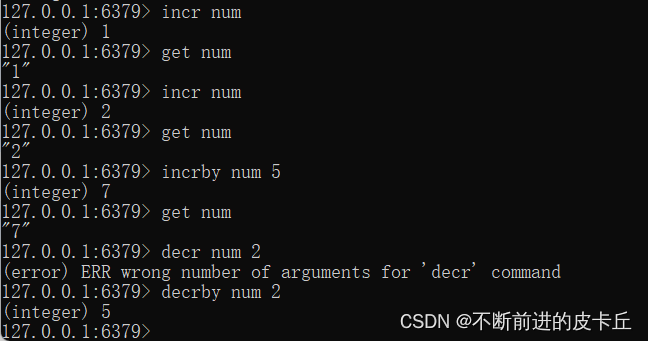
| decr | 进行数值类型的-1操作 |
| decrby | 根据提供的数据进行减法操作 |
| Incr | 进行数值类型的+1操作 |
| incrby | 根据提供的数据进行加法操作 |
| Incrbyfloat | 根据提供的数据加入浮点数 |


| 命令 | 说明 |
|---|---|
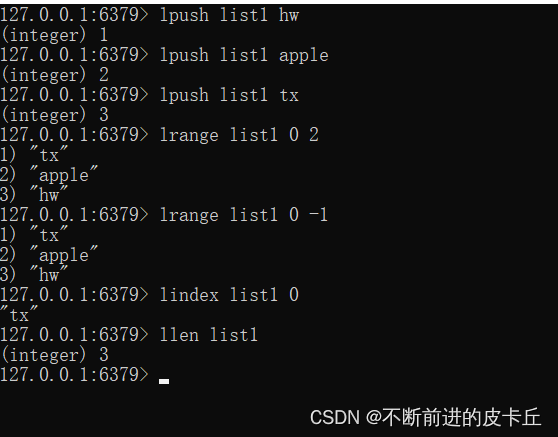
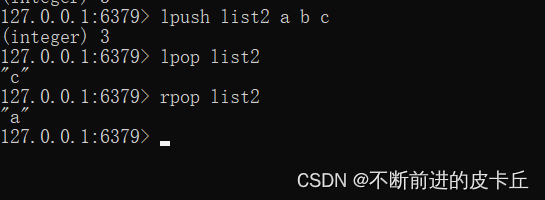
| lpush | 将某个值加入到一个key列表头部 |
| lpushx | 同lpush,但是必须要保证这个key存在 |
| rpush | 将某个值加入到一个key列表末尾 |
| rpushx | 同rpush,但是必须要保证这个key存在 |
| lpop | 返回和移除列表左边的第一个元素 |
| rpop | 返回和移除列表右边的第一个元素 |
| lrange | 获取某一个下标区间内的元素 |
| llen | 获取列表元素个数 |
| lset | 设置某一个指定索引的值(索引必须存在) |
| lindex | 获取某一个指定索引位置的元素 |
| lrem | 删除重复元素 |
| ltrim | 保留列表中特定区间内的元素 |
| linsert | 在某一个元素之前,之后插入新元素 |
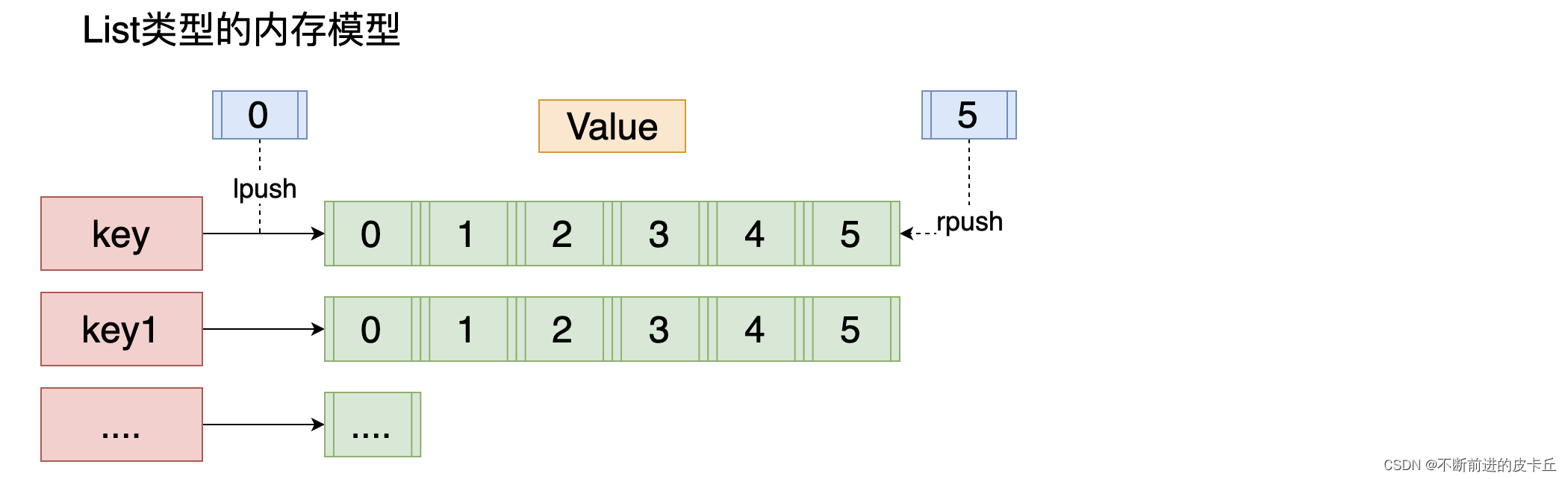
List的数据结构为快速链表quickList。
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表。
它将所有的元素紧挨着一起存储,分配的是一块连续的内存。
当数据量比较多的时候才会改成quicklist。
因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。

Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
| 命令 | 说明 |
|---|---|
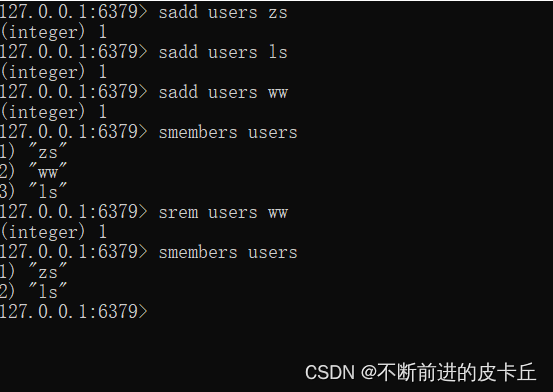
| sadd | 为集合添加元素 |
| smembers | 显示集合中所有元素 无序 |
| scard | 返回集合中元素的个数 |
| spop | 随机返回一个元素 并将元素在集合中删除 |
| smove | 从一个集合中向另一个集合移动元素 必须是同一种类型 |
| srem | 从集合中删除一个元素 |
| sismember | 判断一个集合中是否含有这个元素 |
| srandmember | 随机返回元素 |
| sdiff | 去掉第一个集合中其它集合含有的相同元素 |
| sinter | 求交集 |
| sunion | 求和集 |
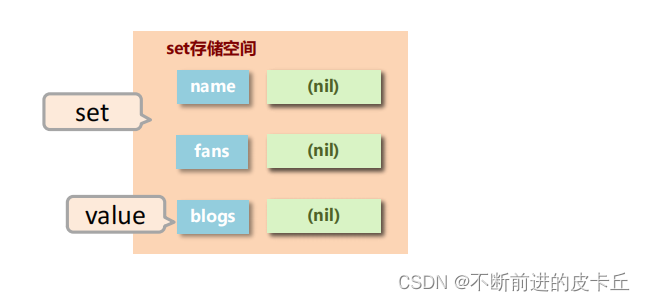
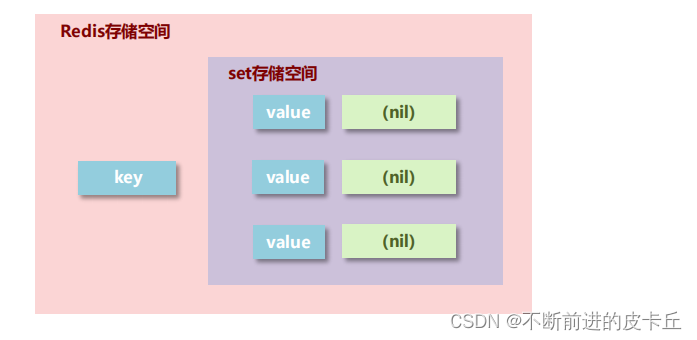
Set数据结构是dict字典,字典是用哈希表实现的。
Java中HashSet的内部实现使用的是HashMap,只不过所有的value都指向同一个对象。Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
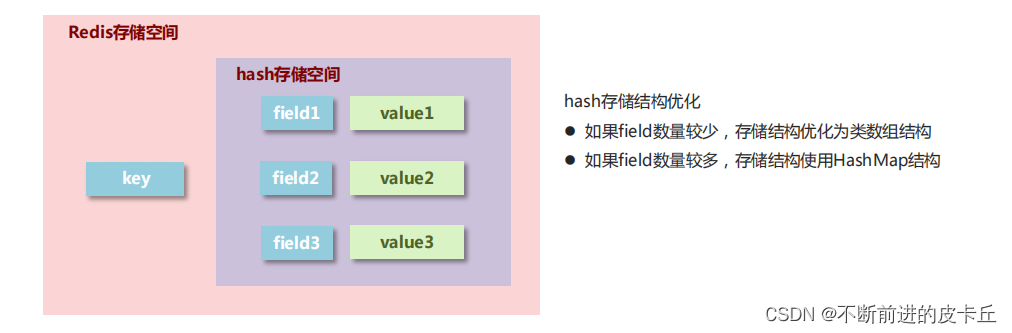
Redis hash 是一个键值对集合。
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
类似Java里面的Map<String,Object>
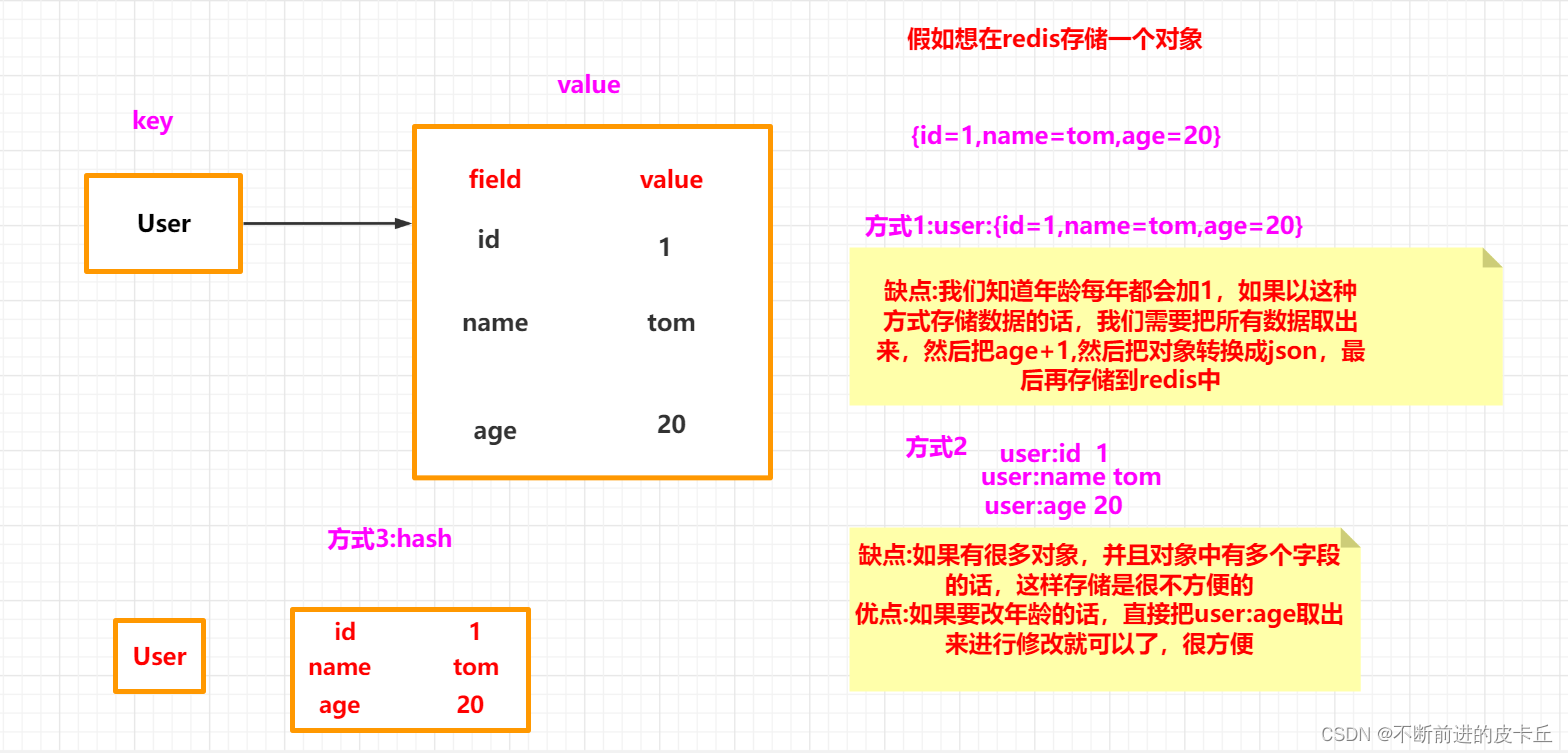
| 命令 | 说明 |
|---|---|
| hset key field1 value1 field2 value2 | 添加/修改数据 |
| hget key field1 field2 | 获得多个数据 |
| hgetall key | 获得所有的数据 |
| hdel key field1 field2 | 删除数据 |
| hexists key field | 获取哈希表中是否存在的字段 |
| hlen key | 获取哈希表中字段的数量 |
| hkeys key | 获得所有的key |
| hvals key | 获得所有的value |
| hmset key field1 value1 field2 value2 | 添加/修改多个数据 |
| hmget key field1 field2 | 获得多个数据 |
| hsetnx key field value | 设置一个不存在的key的值 |
| hincrby key field increment | 为value进行加法运算 |
| hincrbyfloat key field increment | 为value加入浮点值 |
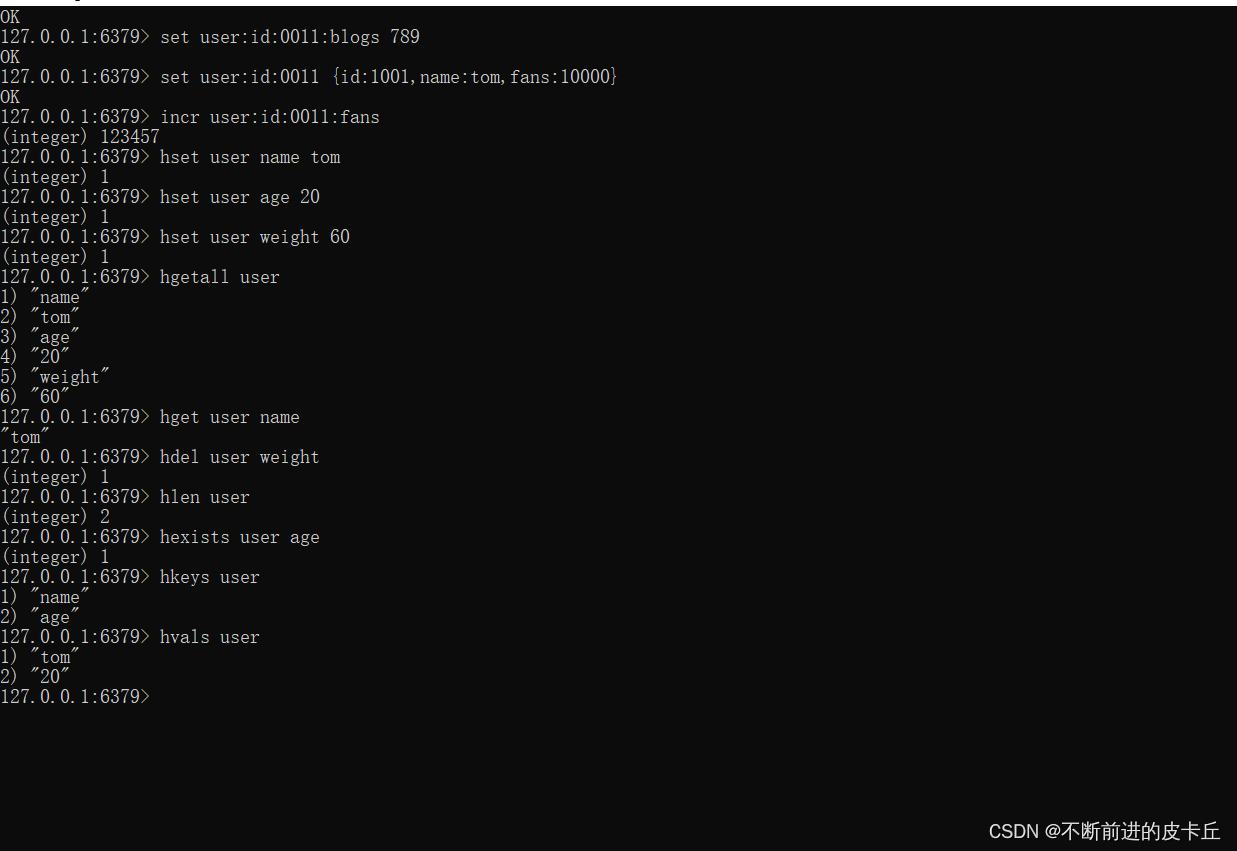
hash类型下的value只能存储字符串,不允许存储其他数据类型,不存在嵌套现象。如果数据未获取到,对应的值为(nil)
每个 hash 可以存储 2^32 - 1 个键值对
hash类型十分贴近对象的数据存储形式,并且可以灵活添加删除对象属性。但hash设计初衷不是为了存储大量对象而设计的,切记不可滥用,更不可以将hash作为对象列表使用
hgetall 操作可以获取全部属性,如果内部field过多,遍历整体数据效率就很会低,有可能成为数据访问瓶颈
Hash类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable。
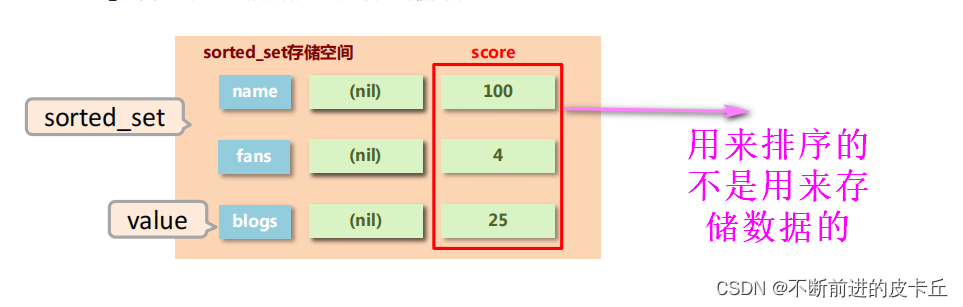
| 功能 | 命令 |
|---|---|
| 添加数据 | zadd key score1 member1 [score2 member2] |
| 获取全部数据 | zrange key start stop[withscores] |
| 获取全部数据 | zrevrange key start sto[withscores] |
| 删除数据 | zrem key member [member…] |
| 按照条件获取数据 | zrangebyscore key min max[withscores][limit] limt用来分页 |
| 按照条件获取数据 | zrevrangebyscore key max min[withscores] |
| 按照条件删除数据 | zremrangebyrank key start stop |
| 按照条件删除数据 | zremrangebyscore key min max |
| 获取集合数据总量 | zcard key |
| 获取集合数据总量 | zcount key min max |
| 集合交操作 | zinterstore destination numkeys key[key…] |
| 集合并操作 | zunionstore destination numkeys key[key…] |
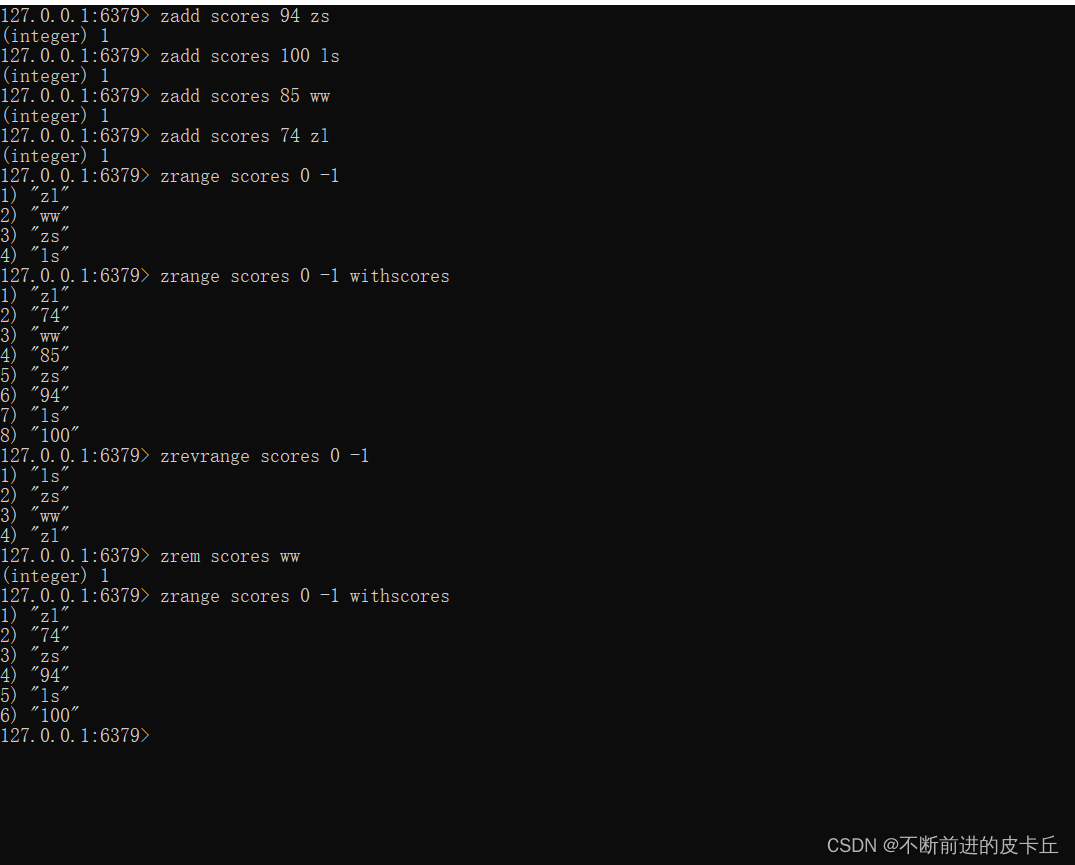
在生活中,其实排序是很常见的,比如好友亲密度,投票之类的都需要进行排序,我们需要为所有参加排名的资源来建立排序依据
| 功能 | 命令 |
|---|---|
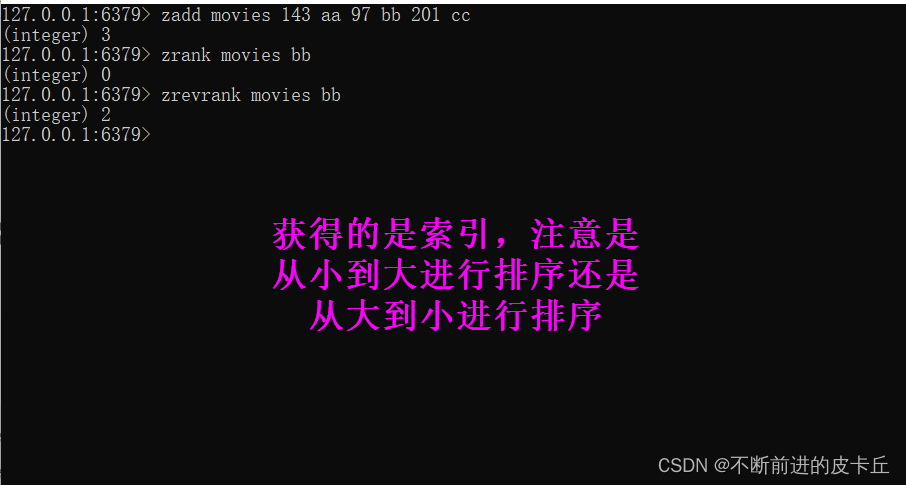
| 获取数据对应的索引(排名) | zrank key member |
| 获取数据对应的索引(排名) | zrevrank key member |
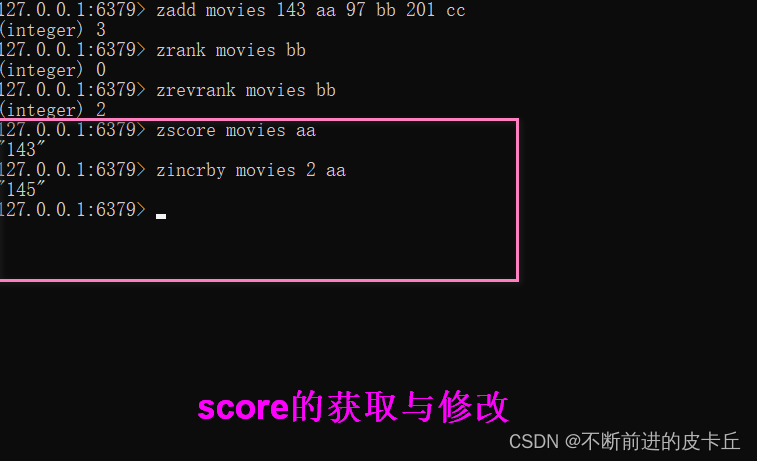
| score值获取 | zscore key member |
| score值修改 | zincrby key increment member |
SortedSet(zset)是Redis提供的一个非常特别的数据结构,一方面它等价于Java的数据结构Map<String, Double>,可以给每一个元素value赋予一个权重score,另一方面它又类似于TreeSet,内部的元素会按照权重score进行排序,可以得到每个元素的名次,还可以通过score的范围来获取元素的列表。
zset底层使用了两个数据结构
(1)hash,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。
(2)跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我可以得到Infinity和NaNn=9.0/0#=>Infinityn.class#=>Floatm=0/0.0#=>NaNm.class#=>Float但是当我想直接访问Infinity或NaN时:Infinity#=>uninitializedconstantInfinity(NameError)NaN#=>uninitializedconstantNaN(NameError)什么是Infinity和NaN?它们是对象、关键字还是其他东西? 最佳答案 您看到打印为Infinity和NaN的只是Float类的两个特殊实例的字符串
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit