大家好,我是百思不得小赵。
创作时间:2022 年 7 月 5 日
博客主页: 🔍点此进入博客主页
—— 新时代的农民工 🙊
—— 换一种思维逻辑去看待这个世界 👀
今天是加入CSDN的第1221天。觉得有帮助麻烦👏点赞、🍀评论、❤️收藏
文章目录
Scala中的集合与Java中的集合相类似,但是又有很多的改变,接下来我们开启Scala集合篇的学习历程吧!
在Java中的集合分为三大类:List集合、Set集合、Map集合。其中List集合、Set集合继承自Collection。它们都是接口。
Scala 的集合有三大类:序列 Seq、集 Set、映射 Map,所有的集合都扩展自 Iterable特质。
对于几乎所有的集合类,Scala 都同时提供了可变和不可变的版本,分别位于以下两个包:不可变集合:scala.collection.immutable、可变集合: scala.collection.mutable
不可变集合,就是指该集合对象不可修改,每次修改就会返回一个新对象,而
不会对原对象进行修改。类似于 java 中的 String 对象。
可变集合,就是这个集合可以直接对原对象进行修改,而不会返回新的对象。类似
于 java 中 StringBuilder 对象
Scala中的集合都是引用类型,并不关心指向的对象中的内容,只关心当前指向的对象。
建议:在操作集合的时候,不可变用符号,可变用方法。
不可变集合
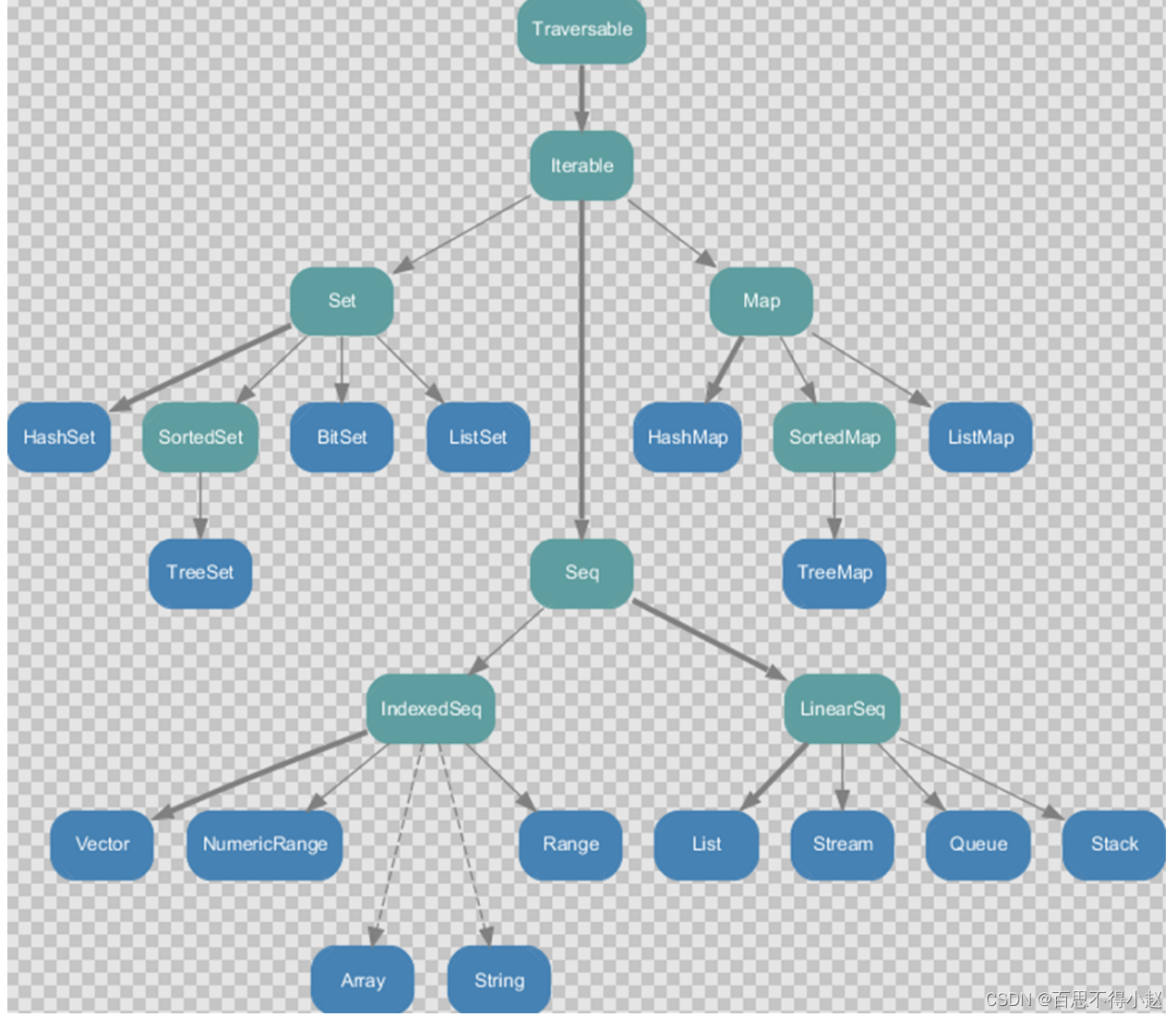
IndexedSeq和LinearSeq两个特质。String就是java.lang.String,和集合无直接关系,所以是虚箭头,是通过Perdef中的低优先级隐式转换来做到的。经过隐式转换为一个包装类型后就可以当做集合了。IndexedSeq 是通过索引来查找和定位,因此速度快,比如 String 就是一个索引集合,通过索引即可定位LinearSeq 是线型的,即有头尾的概念,这种数据结构一般是通过遍历来查找.可变集合
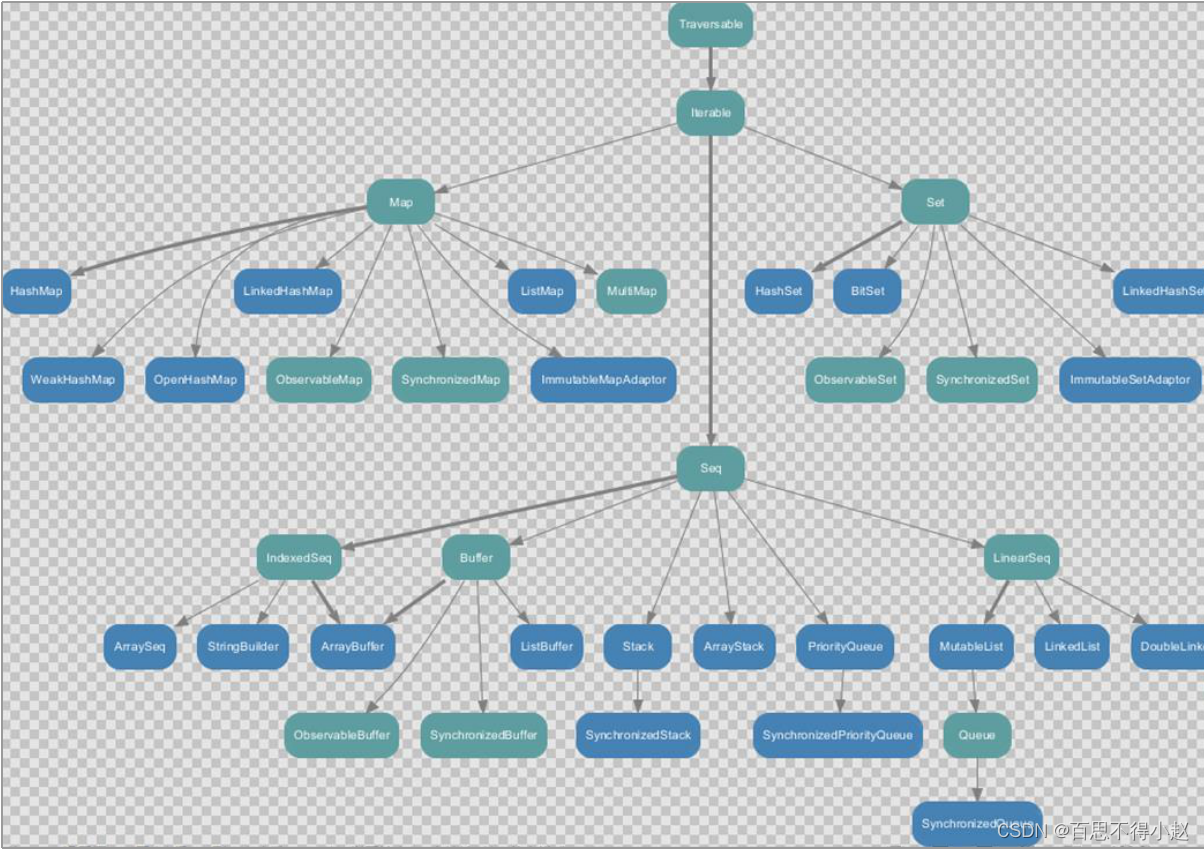
不可变和可变:
如何定义?
val array = new Array[Int](10)
[Type],不同于java的<Type>。[Int]是指定可以存放的数据类型,如果希望存放任意数据类型,则指定 Any(10),表示数组的大小,确定后就不可以变化代码如下:
object Test01_ImmutableArray {
def main(args: Array[String]): Unit = {
// 创建数组
val array = new Array[Int](10)
// 另一种方式
val array2 = Array(10, 21, 65, 33, 78)
// 访问数组中的元素
println(array(0))
println(array(1))
println(array(2))
println(array(3))
// 修改值
array(0) = 12
array(2) = 23
println(array(0))
println(array(1))
println(array(2))
println("===============================")
// 数组遍历
// 1.普通for循环
for (i <- 0 until array.length) {
println(array(i))
}
for (i <- array.indices) println(array(i))
// 2.增强for循环
for (elem <- array2) println(elem)
// 3.迭代器
val iterator = array2.iterator
while (iterator.hasNext) println(iterator.next())
// 4.调用foreach方法
array2.foreach((elem: Int) => println(elem))
array.foreach(println)
// 5.转换为String
println(array2.mkString("--"))
println("=============================")
// 添加元素
// 加到数组后面
val newArray = array2.:+(90)
println(array2.mkString("--"))
println(newArray.mkString("--"))
// 加到数组前面
val newArray2 = newArray.+:(30)
println(newArray2.mkString("--"))
val newArray3 = newArray2 :+ 18
val newArray4 = 19+: 28 +: newArray3 :+ 87 :+ 98
println(newArray4.mkString("--"))
}
}
apply 方法创建数组对象:在前,对象在前,:在后,对象在后。pply/update方法实现,源码中的实现只是抛出错误作为存根方法(stab method),具体逻辑由编译器填充。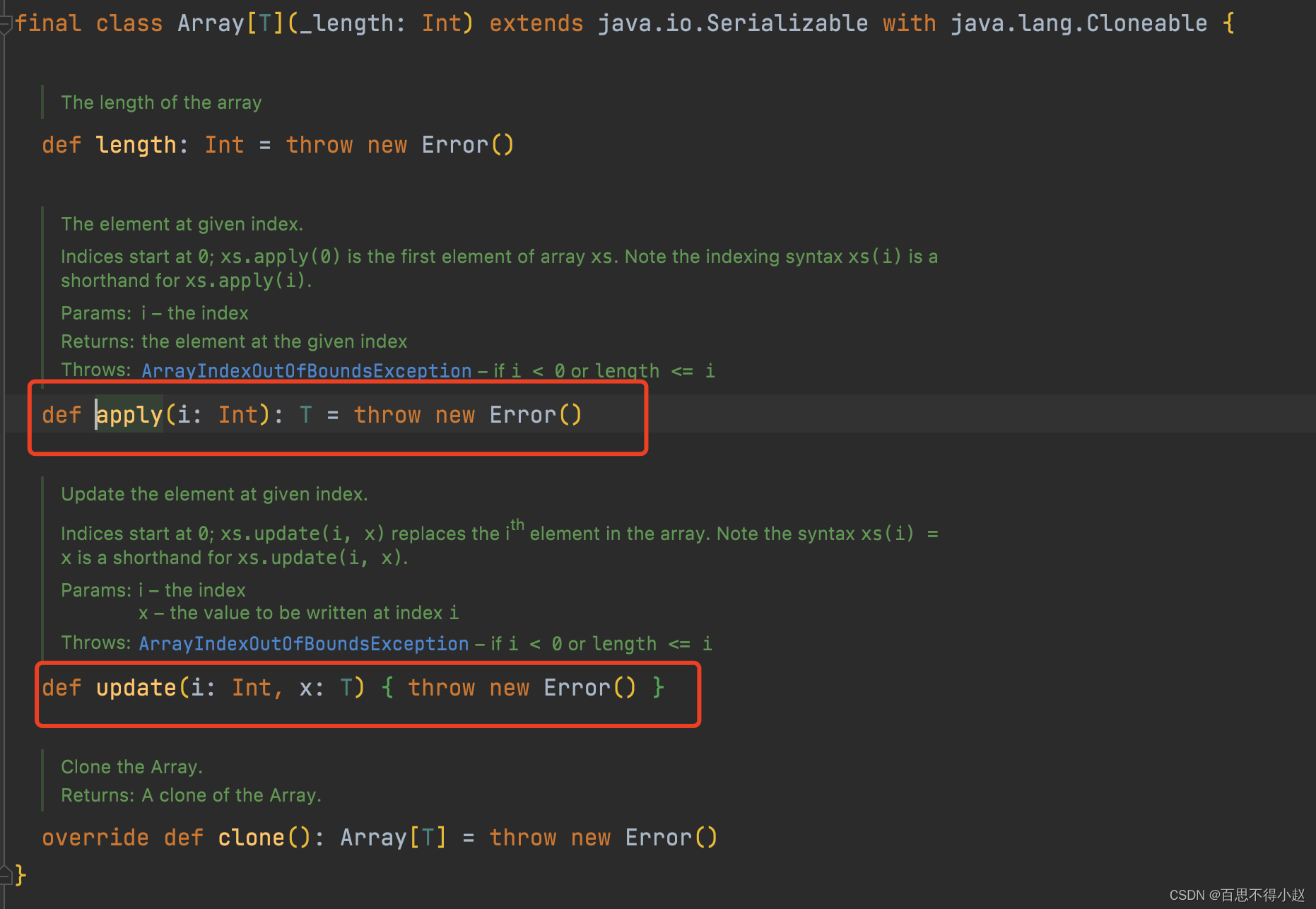
如何定义?
val arr = new ArrayBuffer[Int]()
[Int]表示存放整型的数据()初始化的数据,整型默认为0ArrayBuffer 需要引入 scala.collection.mutable.ArrayBuffer代码实操:
//1。 创建可变数组
val arr = new ArrayBuffer[Int]()
// 另一种方式
val arr2 = ArrayBuffer(10, 21, 17, 9, 28)
println(arr.mkString("-"))
println(arr2)
// 2.访问元素
println(arr2(0))
// 修改元素
arr2(0) = 12
println(arr2(0))
// 3。向数组添加元素
// :+ 主要针对不可变数组来添加元素使用的,添加完元素后必须要将其赋给一个新的数组
val newArray1 = arr :+ 15
println(arr)
println(newArray1)
println(arr == newArray1) // false
// 可变数组添加元素调用 += 方法,添加完后无需赋给新的数组对象
// += 向后追加 +=: 向前追加
arr += 19
27 +=: arr
// 推荐使用append() 方法
// 向后追加
arr.append(36)
// 向前添加
arr.prepend(11, 90, 56)
// 在指定位置添加 arr.insert(索引位置,可变参数)
arr.insert(1, 23, 56)
//直接添加数组
arr.insertAll(2, arr2)
// arr.appendAll()
// arr.prefixLength()
// 4.删除元素
// 删除某个位置的元素
arr.remove(3)
// 从索引位置开始,删除xx个数
// arr.remove(0,10)
arr -= 36
可变与不可变集合转换
arr1.toBuffer 返回结果才是一个可变数组,arr1 本身没有变化arr2.toArray 返回结果才是一个不可变数组,arr2 本身没有变化举个栗子:
// 可变数组转为不可变数组
val array = ArrayBuffer(10, 21, 90)
val newArray = array.toArray
println(newArray.mkString("-"))
println(array)
// 不可变数组转为可变数组
val buffer = newArray.toBuffer
println(buffer)
println(newArray)
多维数组
定义:
val array = Array.ofDim[Int](2, 3)
举个栗子:
// 创建二维数组
val array = Array.ofDim[Int](2, 3)
// 访问元素
array(0)(2) = 19
array(1)(0) = 26
// 遍历
for (i <- 0 until array.length; j <- 0 until array(i).length) {
println(array(i)(j))
}
for (i <- array.indices; j <- array(i).indices) {
print(array(i)(j) + "\t")
if (j == array(i).length - 1) println()
}
array.foreach(line => line.foreach(println))
array.foreach(_.foreach(println))
如何定义?
val list: List[Int] = List(1,2,3,4,3)
List 默认为不可变集合,数据有序且可重复sealed修饰的一个抽象的密封类。提供了一个约束,打包密封在当前文件内,当前类的子类不能定义在文件之外。new对象的方式,使用半生对象的apply方法进行创建 list.foreach(println)
println(list(1))
+: :+首尾添加元素,Nil空列表,::添加元素到表头 val list2 = list.+:(10)
val list3 = list :+ 20
val list4 = list2.::(23)
Nil.::(元素)创建新的列表,29 :: 99 :: 80 :: 43 :: Nil相当于给列表头部一直添加元素,定义一个新列表。list1 :: list2将list1整个列表合并到list2。list1 ::: list2 或者list1 ++ list2 将list1的各个元素合并到list2。++底层也是调用:::如何定义?
import scala.collection.mutable
val listBuffer = new ListBuffer[Int]()
val buffer = mutable.ListBuffer(1,2,3,4)
new对象的方式,也可使用伴生对象的apply方法创建append prepend insert 添加元素到头或尾:+=: +=list1 ++ list2 或者 list1 ++= list2 前者得到新的列表,后者将元素合并到list1list(index) = value 底层调用update方法remove 或者 -=默认情况下,Scala 使用的是不可变集合,如果你想使用可变集合,需要引用scala.collection.mutable.Set 包
如何创建?
val set1 = Set(12,78,90,56,78,12,34,23)
set + 元素set1 ++ set2得到新的Set集合set - 元素代码实操:
// 1.创建Set
val set1 = Set(12,78,90,56,78,12,34,23)
println(set1)
// 2。添加元素
val set2 = set1 + 80
println(set2)
// 3。合并set
val set3 = Set(14,25,46,57,68,91)
val set4 = set2 ++ set3
println(set2)
println(set3)
println(set4)
// 4.删除元素
val set5 = set3 - 14
println(set3)
println(set5)
如何创建?
val set1 = mutable.Set(12,78,90,56,78,12,34,23)
set += 元素 调用add()set -= 元素 调用remove()set1 ++= set2代码实操:
// 1.创建Set
val set1 = mutable.Set(12,78,90,56,78,12,34,23)
println(set1)
/// 2.添加元素
val set2 = set1 + 32
set1 += 88
set1.add(30)
// 3.删除元素
set1 -= 12
set1.remove(23)
// 4.合并两个集合
val set3 = mutable.Set(75,90,56,39,54,51)
val set4 = set1 ++ set3
println(set4)
set1 ++= set3
println(set1)
如何创建?
val map1: Map[String, Int] = Map("a" -> 13, "b" -> 21, "hello" -> 80)
key -> value 键值对儿,为二元组类型。代码实操:
// 1.创建Map key -> value 键值对儿
val map1: Map[String, Int] = Map("a" -> 13, "b" -> 21, "hello" -> 80)
println(map1)
println(map1.getClass)
// 2.遍历元素
for (elem <- map1) {
println(elem+"")
}
map1.foreach(println)
// 元组类型 (String, Int)
map1.foreach((kv: (String, Int)) => println(kv))
// 3.取Map中所有对Key
for (key <- map1.keys) {
println(s"${key} ----> ${map1.get(key)}")
}
// 4.访问某一个Key的value
// 不安全的,报空指针异常
println(map1.get("a").get)
println(map1.get("v"))
// 推荐使用
println(map1.getOrElse("f", 0))
println(map1("a"))
类似于不可变的Map,直接上代码实操。
// 1。创建Map
val map1: mutable.Map[String, Int] = mutable.Map("a" -> 13, "b" -> 21, "hello" -> 80)
println(map1)
println(map1.getClass)
// 2.添加元素
map1.put("c",10)
map1.put("d",21)
println(map1)
map1 += (("e",90))
println(map1)
// 3.删除元素
println(map1.remove("e"))
println(map1.getOrElse("e", 0))
map1 -= "d"
println(map1)
// 4.修改元素
map1.update("a",21)
println(map1)
// 5.合并集合
val map2: Map[String, Int] = Map("o" -> 9, "y" -> 28, "hello" -> 80)
// 可变加不可变
map1 ++= map2
println(map1)
println(map2)
// 不可变加可变
val map3 = map2 ++ map1
println(map3)
元组也是可以理解为一个容器,可以存储相同或者不同类型的数据,换句话说就是将多个无关的数据封装为一个整体。
(元素 1,元素 2,元素 3,......)Tuple1定义到了Tuple22。_顺序号tuple.productElement(index)for (elem <- tuple.productIterator)举个栗子:
object Test_Tuple {
def main(args: Array[String]): Unit = {
// 1。创建元祖
val tuple = ("hello", 0, false,'a')
println(tuple)
// 2.访问元祖数据
println(tuple._1)
println(tuple._2)
println(tuple._3)
println(tuple._4)
println(tuple.productElement(0))
// 3.遍历元祖
for (elem <- tuple.productIterator){
println(elem)
}
// 4.嵌套元组
val mulTuple = (112,32,"aa",("scala",90))
println(mulTuple._4._2)
}
}
本次Scala集合内容汇总的上篇到这里就结束了,内容篇幅较长,干货满满,希望对大家学习Scala语言有所帮助!!!

我需要读入一个包含数字列表的文件。此代码读取文件并将其放入二维数组中。现在我需要获取数组中所有数字的平均值,但我需要将数组的内容更改为int。有什么想法可以将to_i方法放在哪里吗?ClassTerraindefinitializefile_name@input=IO.readlines(file_name)#readinfile@size=@input[0].to_i@land=[@size]x=1whilex 最佳答案 只需将数组映射为整数:@land边注如果你想得到一条线的平均值,你可以这样做:values=@input[x]
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在尝试提取方括号内的内容。到目前为止,我一直在使用它,它有效,但我想知道我是否可以直接在正则表达式中使用某些东西,而不是使用这个删除功能。a="Thisissuchagreatday[coolawesome]"a[/\[.*?\]/].delete('[]')#=>"coolawesome" 最佳答案 差不多。a="Thisissuchagreatday[coolawesome]"a[/\[(.*?)\]/,1]#=>"coolawesome"a[/(?"coolawesome"第一个依赖于提取组而不是完全匹配;第二个利用前瞻和
我正在构建一个小部件来显示奥运会的奖牌数。我有一个“国家”对象的集合,其中每个对象都有一个“名称”属性,以及奖牌计数的“金”、“银”、“铜”。列表应该排序:1.首先是奖牌总数2.如果奖牌相同,按类型分割(金>银>铜,即2金>1金+1银)3.如果奖牌和类型相同,则按字母顺序子排序我正在用ruby做这件事,但我想语言并不重要。我确实找到了一个解决方案,但如果感觉必须有更优雅的方法来实现它。这是我做的:使用加权奖牌总数创建一个虚拟属性。因此,如果他们有2个金牌和1个银牌,加权总数将为“3.020100”。1金1银1铜为“3.010101”由于我们希望将奖牌数排序为最高的,因此列表按降序排
使用Ruby1.8.6/Rails2.3.2我注意到在我的任何ActiveRecord模型类上调用的任何方法都返回nil而不是NoMethodError。除了烦人之外,这还破坏了动态查找器(find_by_name、find_by_id等),因为即使存在记录,它们也总是返回nil。不从ActiveRecord::Base派生的标准类不受影响。有没有办法追踪在ActiveRecord::Base之前拦截method_missing的是什么?更新:切换到1.8.7后,我发现(感谢@MichaelKohl)will_paginate插件首先处理method_missing。但是will_pa
在学习Python之后,我现在正在尝试学习Ruby,但我在将这段代码转换为Ruby时遇到了问题:defcompose1(f,g):"""Returnafunctionh,suchthath(x)=f(g(x))."""defh(x):returnf(g(x))returnh我必须使用block来翻译吗?或者Ruby中是否有类似的语法? 最佳答案 您可以使用Ruby中的lambda执行此操作(我在这里使用的是1.9stabby-lambda):compose=->(f,g){->(x){f.(g.(x))}}所以compose是一个返