申明:本次只是说一下实现思路,官方的接口以及如何实现方式,本文没有提及,这次只是一个思路,若想代替人工完成质量还差的很远,请审核大大放行

今天再次优化了代码,修复了一些bug,考虑到不完善且文章质量不是很高的情况(连个图文都没有),打算将代码分离开来,一起使用可能会对后面维护开发产生不必要的麻烦,欢迎大佬的关注,我会自动回关!,等到真正实现自动化,会打包成exe分享
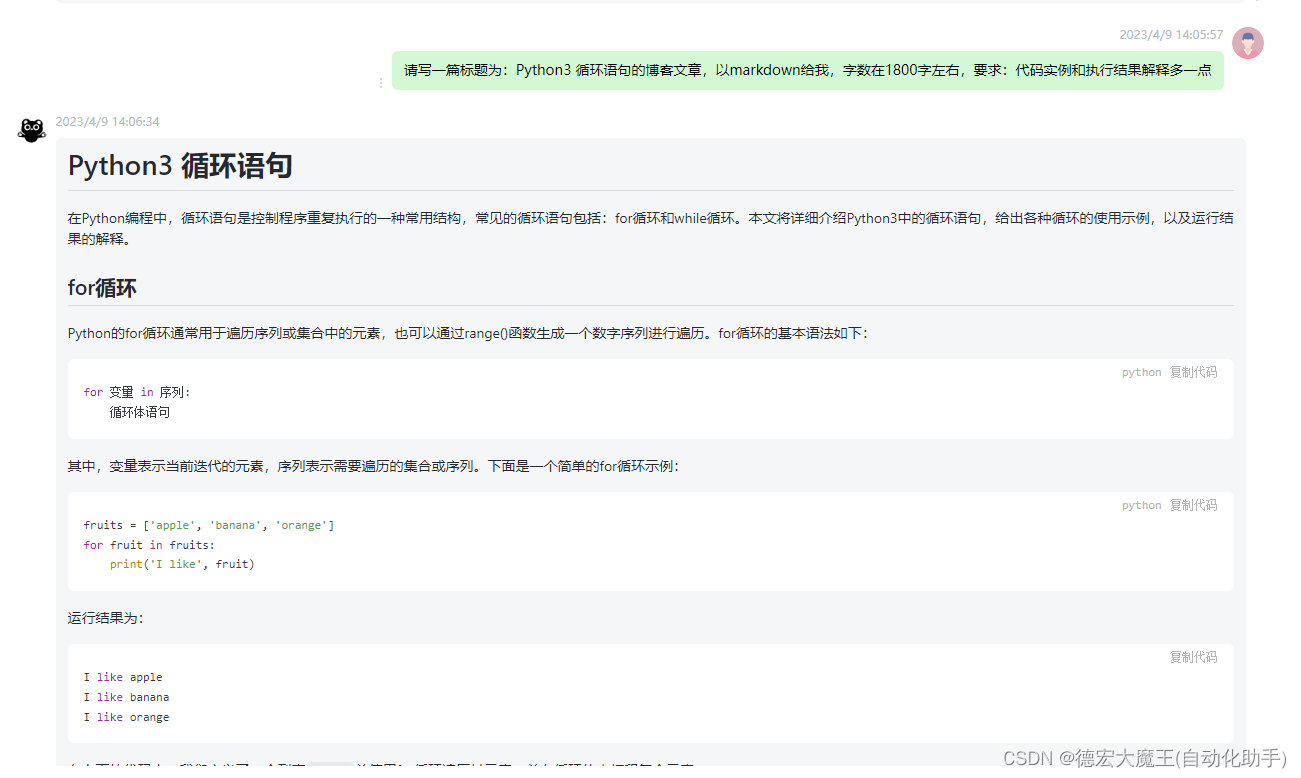
实现效果看我的博客:Python3 循环语句

缺点:
gpt3.5没有图文并茂"复制代码"转换过程中处理成了文字20230405
20230406优化
20230408

这里接口有需要的伙伴,私聊领取哈,免费的
构造完成整理为发送gpt的模块中
title="Python3 循环语句"
yaoqiu="要求:代码实例和执行结果解释多一点"
text_val = "请写一篇标题为:"+title+"的博客文章,以markdown给我,字数在1800字左右"+yaoqiu
content=chatgpt(title)
文章保存参数:
| 参数名 | 值 | 说明 |
|---|---|---|
| title | Python3 循环语句 | 标题 |
| description | 摘要 | 摘要可为空 |
| content | 内容 | 需要使用markdown转换,不转换就是一行 |
| tags | 文章标签 | 例如:机器学习 |
| categories | 空 | 暂不清楚,猜测分类 |
| type | original | 暂不清楚 |
| status | 2 | 暂不清楚 |
| read_type | public | 是否公开 |
| reason | 暂不清楚 | |
| cover_images | imgurl | 头图支持多个 |
| is_new | 1 | 新文 |
| 等等… |
知道请求参数,关键在于标题、内容、标签、图片,于是接下来着手获取
输入标题,完成构造对话发送等待返回文章,通过markdown处理请求
def convert_markdown_to_html(markdown_text):
html = markdown.markdown(markdown_text)
return html
处理后获得title标题、content内容
C站标签和头图属于一个接口,通过请求
result=get_recommend_tags(title,content_mark)
获取到标签和头图,这里由于比较忙我就不整理参数了
以下为接口返回数据(请求标题与numpy相关):
{
"code": 200,
"message": "success",
"traceId": "xxxxxx",
"data": {
"common": ["bug", "php", "开发语言", "thinkphp5", "微信小程序"],
"list": {
"推荐": ["numpy", "python", "机器学习", "开发语言", "人工智能"],
"Python": ["python", "django", "pygame", "virtualenv", "tornado", "flask", "scikit-learn", "plotly", "dash", "fastapi", "pyqt", "scrapy", "beautifulsoup", "numpy", "scipy", "pandas", "matplotlib", "httpx", "web3.py", "pytest", "pillow", "gunicorn", "pip", "conda", "ipython"],"images": ["https://xxxxxx/img_convert/7bc0b398d41f4dbc81d31b9dedc4e172.png", "https://xxxxxx/img_convert/77fcfea2a41749d7867f62f0e98b01ca.png", "https://xxxxxx/img_convert/fad536e972e14ce4b37803185dc3b00c.png", "https://xxxxxx/img_convert/5bbc102f2243430991aedee1be20b4f3.png", "https://xxxxxx/img_convert/cf52fbe57e404f30babcdda6f1ef2c08.png"]
}
}
标签是[‘推荐’]字段,使用python转换
tags = result['data']['list']['推荐']
tag_str = ', '.join(str(tag) for tag in tags)
print(tag_str)
打印结果为:numpy, python, 机器学习, 开发语言, 人工智能
以上已经获取到了标签和头图以及markdown格式的内容,接下来结合起来像C站文章保存接口请求一次
saveArticle(tag_str,imgurl,title,content_mark)
部分请求成功构造:
json_data = {
# 'article_id': 130040595,
'title': title,
'description': '',
'content': content,
'tags': tag_str,
'categories': '',
'type': 'original',
'status': 2,
'read_type': 'public',
'reason': '',
'resource_url': '',
'original_link': '',
'authorized_status': False,
'check_original': False,
'source': 'pc_postedit',
'not_auto_saved': 1,
'creator_activity_id': '',
'cover_images': [
imgurl,
],
'cover_type': 1,
'vote_id': 0,
'scheduled_time': 0,
'is_new': 1,
}
response = requests.post(
'xxxxx',
cookies=cookies,
headers=headers,
json=json_data,
)
print(response.text)
请求成功,刷新我的文章查看
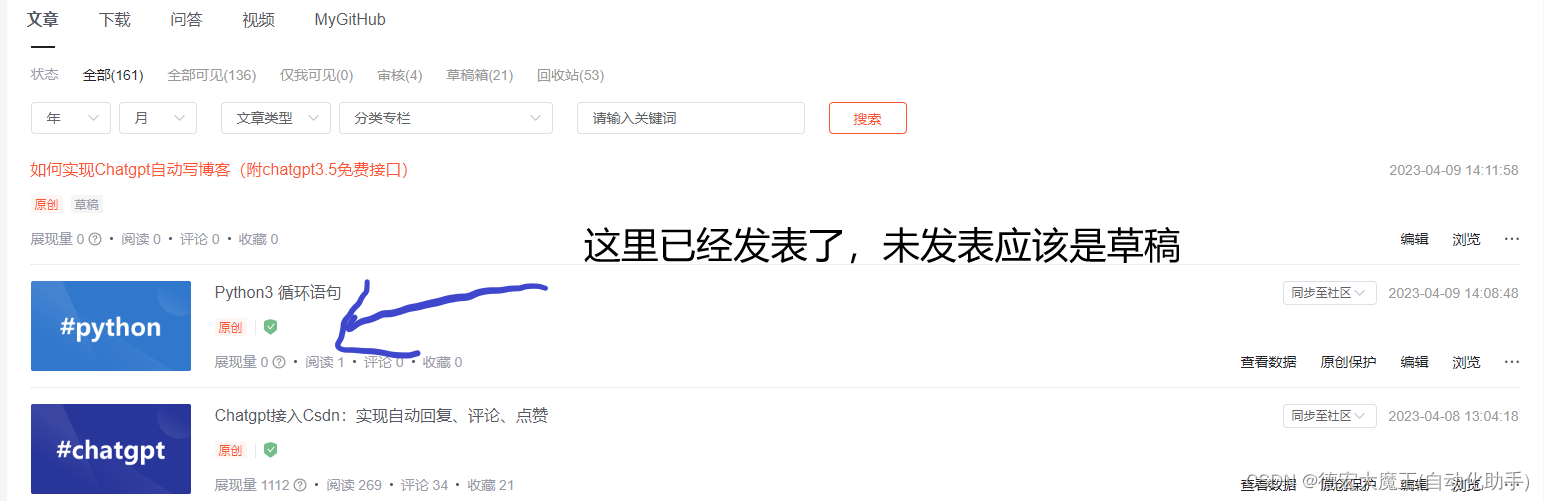
由于这里还在对文章内容排版优化,所以就不直接发表,需要核查一遍,等后面对接了文心一言考虑自动发表!
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
我有一大串格式化数据(例如JSON),我想使用Psychinruby同时保留格式转储到YAML。基本上,我希望JSON使用literalstyle出现在YAML中:---json:|{"page":1,"results":["item","another"],"total_pages":0}但是,当我使用YAML.dump时,它不使用文字样式。我得到这样的东西:---json:!"{\n\"page\":1,\n\"results\":[\n\"item\",\"another\"\n],\n\"total_pages\":0\n}\n"我如何告诉Psych以想要的样式转储标量?解