图结构是算法学中最强大的框架之一。
图是各种关系的节点和边的集合,节点是与对象对应的顶点,边是对象之间的连接。
SciPy 提供了 scipy.sparse.csgraph 模块来处理图结构。
邻接矩阵(Adjacency Matrix)是表示顶点之间相邻关系的矩阵。
邻接矩阵逻辑结构分为两部分:V 和 E 集合,其中,V 是顶点,E 是边,边有时会有权重,表示节点之间的连接强度。
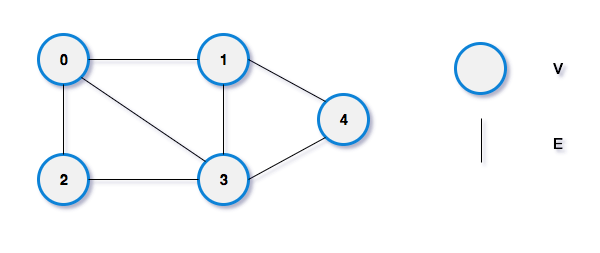
用一个一维数组存放图中所有顶点数据,用一个二维数组存放顶点间关系(边或弧)的数据,这个二维数组称为邻接矩阵。
看下下图实例:
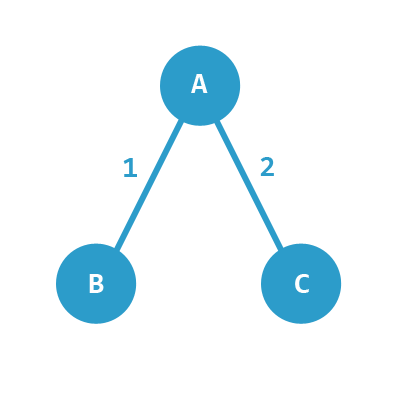
顶点有 A、B、C,边权重有 1 和 2。
A 与 B 是连接的,权重为 1。
A 与 C 是连接的,权重为 2。
C 与 B 是没有连接的。
这个邻接矩阵可以表示为以下二维数组:
A B C
A:[0 1 2]
B:[1 0 0]
C:[2 0 0]
邻接矩阵又分为有向图邻接矩阵和无向图邻接矩阵。
无向图是双向关系,边没有方向:
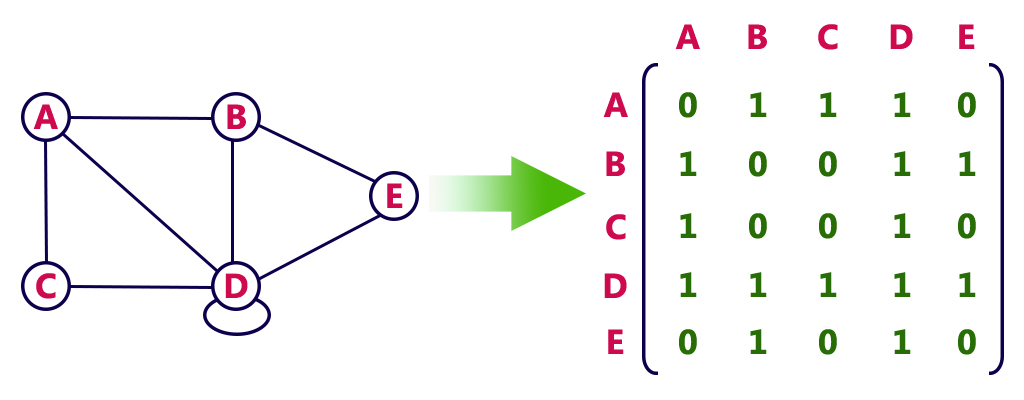
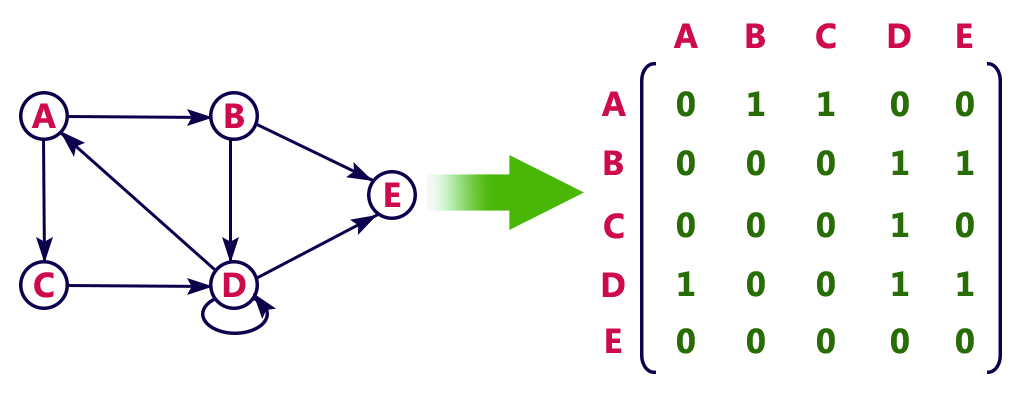
注:上面两个图中的 D 节点是自环,自环是指一条边的两端为同一个节点。
查看所有连接组件使用 connected_components() 方法。
以上代码输出结果为:
(1, array([0, 0, 0], dtype=int32))
Dijkstra(迪杰斯特拉)最短路径算法,用于计算一个节点到其他所有节点的最短路径。
Scipy 使用 dijkstra() 方法来计算一个元素到其他元素的最短路径。
dijkstra() 方法可以设置以下几个参数:查找元素 1 到 2 的最短路径:
以上代码输出结果为:
(array([ 0., 1., 2.]), array([-9999, 0, 0], dtype=int32))
弗洛伊德算法算法是解决任意两点间的最短路径的一种算法。
Scipy 使用 floyd_warshall() 方法来查找所有元素对之间的最短路径。
查找所有元素对之间的最短路径径:
以上代码输出结果为:
(array([[ 0., 1., 2.],
[ 1., 0., 3.],
[ 2., 3., 0.]]), array([[-9999, 0, 0],
[ 1, -9999, 0],
[ 2, 0, -9999]], dtype=int32))
贝尔曼-福特算法是解决任意两点间的最短路径的一种算法。
Scipy 使用 bellman_ford() 方法来查找所有元素对之间的最短路径,通常可以在任何图中使用,包括有向图、带负权边的图。
使用负权边的图查找从元素 1 到元素 2 的最短路径:
以上代码输出结果为:
(array([ 0., -1., 2.]), array([-9999, 0, 0], dtype=int32))
depth_first_order() 方法从一个节点返回深度优先遍历的顺序。
可以接收以下参数:
给定一个邻接矩阵,返回深度优先遍历的顺序:
以上代码输出结果为:
(array([1, 0, 3, 2], dtype=int32), array([ 1, -9999, 1, 0], dtype=int32))
breadth_first_order() 方法从一个节点返回广度优先遍历的顺序。
可以接收以下参数:
给定一个邻接矩阵,返回广度优先遍历的顺序:
以上代码输出结果为:
(array([1, 0, 2, 3], dtype=int32), array([ 1, -9999, 1, 1], dtype=int32))
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
您将如何构建一个简单的Sinatra应用程序?我正在制作,我希望该应用具有以下功能:“应用程序”更像是一个包含所有信息的管理仪表板。然后另一个应用程序将通过REST访问信息。我还没有创建仪表板,只是从数据库中获取东西session和身份验证(尚未实现)您可以上传图片,其他应用可以显示这些图片我已经使用RSpec创建了一个测试文件通过Prawn生成报告目前的设置是这样的:app.rbtest_app.rb因为我实际上只有应用程序和测试文件。到目前为止,我已经将Datamapper用于ORM,将SQLite用于数据库。这是我的第一个Ruby/Sinatra项目,所以欢迎任何和所有建议-我应
我想编写一个ruby脚本来递归复制目录结构,但排除某些文件类型。因此,给定以下目录结构:folder1folder2file1.txtfile2.txtfile3.csfile4.htmlfolder2folder3file4.dll我想复制这个结构,但不包含.txt和.cs文件。因此,生成的目录结构应如下所示:folder1folder2file4.htmlfolder2folder3file4.dll 最佳答案 您可以使用查找模块。这是一个代码片段:require"find"ignored_extensions=[".cs"
对于我正在编写的Rails3应用程序,我正在考虑从本地文件系统上的XML、YAML或JSON文件中读取一些配置数据。重点是:我应该把这些文件放在哪里?Rails应用程序中是否有用于存储此类内容的默认位置?附带说明一下,我的应用程序部署在Heroku上。 最佳答案 我经常做的是:如果文件是通用配置文件:我在目录/config中创建一个YAML文件,每个环境有一个上层key如果我为每个环境(大项目)创建一个文件:我为每个环境创建一个YAML并将它们存储在/config/environments/然后我在加载YAML的地方创建了一个初始化
在我的mac上安装几个东西时遇到这个问题,我认为这个问题来自将我的豹子升级到雪豹。我认为这个问题也与macports有关。/usr/local/lib/libz.1.dylib,filewasbuiltfori386whichisnotthearchitecturebeinglinked(x86_64)有什么想法吗?更新更具体地说,这发生在安装nokogirigem时日志看起来像:xslt_stylesheet.c:127:warning:passingargument1of‘Nokogiri_wrap_xml_document’withdifferentwidthduetoproto
我目前还在上学,正在上一门关于用C++实现数据结构的类(class)。在业余时间,我喜欢使用“高级”语言(主要是Ruby和一些c#)进行编程。既然这些高级语言为你管理内存,你会用数据结构做什么?我可以理解对队列和堆栈的需求,但是您需要在Ruby中使用二叉树吗?还是2-3-4树?为什么?谢谢。 最佳答案 Sosincethesehigherlevellanguagesmanagethememoryforyou,whatwouldyouusedatastructuresfor?使用数据结构的主要原因与垃圾收集无关。但它是以某种方式有效的
它们可以这样定义Struct.new(:x,:y)但是用它们能做什么?具体来说,如何创建这种结构的实例?这行不通Struct.new(:x=>1,:y=>1)(您收到TypeError:can'tconvertHashintoString)。我正在使用Ruby1.9.2。更新:目前为止很好的指点,谢谢。我想我问这个的原因是我有好几次发现自己想要这样做Struct.new(:x=>1,:y=>1)这样我就可以在可以编写obj.x的地方传递一个对象,而不是说,实例化一个散列并必须编写obj[:x].在这种情况下,我希望该结构真正是匿名的-我不想通过命名从Struct.new调用返回的内容来
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。要求我们推荐或查找工具、库或最喜欢的场外资源的问题对于StackOverflow来说是偏离主题的,因为它们往往会吸引自以为是的答案和垃圾邮件。相反,describetheproblem以及迄今为止为解决该问题所做的工作。关闭9年前。Improvethisquestion我很难找到在ruby中使用的树数据结构。我可以研究一些众所周知的吗?我的要求很简单。我想创建一棵树(或者可能是一个图)并找到一些节点之间的距离。例如,我可能有一个像下面这样的树/图A/\B-----C/\\DEF我希望能够找到根节点
SO上有几个关于在Ruby中解析结构化文本的问题,但没有一个适用于我的情况。我是RubyWhoislibrary的作者.该库包含多个解析器,用于解析WHOIS响应并从内容中提取属性。到目前为止,我使用了两种方法:基本解析器的正则表达式(例如whois.aero)StringScanner对于高级解析器(例如whois.nic.it)正则表达式效率不高,因为如果我需要提取15个属性,我需要至少扫描同一个响应15次。StringScanner是一个不错的库,但创建一个高效的扫描器并不是那么简单。我想知道您是否建议使用其他一些Ruby工具来实现WHOIS记录解析器。我正在阅读有关Treeto