整个数据获取的信息是通过房源平台获取的,通过下载网页元素并进行数据提取分析完成整个过程。
导入相关的网页下载、数据解析、数据处理库
from fake_useragent import UserAgent # 身份信息生成库
from bs4 import BeautifulSoup # 网页元素解析库
import numpy as np # 科学计算库
import requests # 网页下载库
from requests.exceptions import RequestException # 网络请求异常库
import pandas as pd # 数据处理库
然后,在开始之前初始化一个身份信息生成的对象,用于后面随机生成网页下载时的身份信息。
user_agent = UserAgent()
编写一个网页下载函数get_html_txt,从相应的url地址下载网页的html文本。
def get_html_txt(url, page_index):
'''
获取网页html文本信息
:param url: 爬取地址
:param page_index:当前页数
:return:
'''
try:
headers = {
'user-agent': user_agent.random
}
response = requests.request("GET", url, headers=headers, timeout=10)
html_txt = response.text
return html_txt
except RequestException as e:
print('获取第{0}页网页元素失败!'.format(page_index))
return ''
编写网页元素处理函数catch_html_data,用于解析网页元素,并将解析后的数据元素保存到csv文件中。
def catch_html_data(url, page_index):
'''
处理网页元素数据
:param url: 爬虫地址
:param page_index:
:return:
'''
# 下载网页元素
html_txt = str(get_html_txt(url, page_index))
if html_txt.strip() != '':
# 初始化网页元素对象
beautifulSoup = BeautifulSoup(html_txt, 'lxml')
# 解析房源列表
h_list = beautifulSoup.select('.resblock-list-wrapper li')
# 遍历当前房源的详细信息
for n in range(len(h_list)):
h_detail = h_list[n]
# 提取房源名称
h_detail_name = h_detail.select('.resblock-name a.name')
h_detail_name = [m.get_text() for m in h_detail_name]
h_detail_name = ' '.join(map(str, h_detail_name))
# 提取房源类型
h_detail_type = h_detail.select('.resblock-name span.resblock-type')
h_detail_type = [m.get_text() for m in h_detail_type]
h_detail_type = ' '.join(map(str, h_detail_type))
# 提取房源销售状态
h_detail_status = h_detail.select('.resblock-name span.sale-status')
h_detail_status = [m.get_text() for m in h_detail_status]
h_detail_status = ' '.join(map(str, h_detail_status))
# 提取房源单价信息
h_detail_price = h_detail.select('.resblock-price .main-price .number')
h_detail_price = [m.get_text() for m in h_detail_price]
h_detail_price = ' '.join(map(str, h_detail_price))
# 提取房源总价信息
h_detail_total_price = h_detail.select('.resblock-price .second')
h_detail_total_price = [m.get_text() for m in h_detail_total_price]
h_detail_total_price = ' '.join(map(str, h_detail_total_price))
h_info = [h_detail_name, h_detail_type, h_detail_status, h_detail_price, h_detail_total_price]
h_info = np.array(h_info)
h_info = h_info.reshape(-1, 5)
h_info = pd.DataFrame(h_info, columns=['房源名称', '房源类型', '房源状态', '房源均价', '房源总价'])
h_info.to_csv('北京房源信息.csv', mode='a+', index=False, header=False)
print('第{0}页房源信息数据存储成功!'.format(page_index))
else:
print('网页元素解析失败!')
编写多线程处理函数,初始化网络网页下载地址,并使用多线程启动调用业务处理函数catch_html_data,启动线程完成整个业务流程。
import threading # 导入线程处理模块
def thread_catch():
'''
线程处理函数
:return:
'''
for num in range(1, 50, 3):
url_pre = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num))
url_cur = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num + 1))
url_aft = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num + 2))
thread_pre = threading.Thread(target=catch_html_data, args=(url_pre, num))
thread_cur = threading.Thread(target=catch_html_data, args=(url_cur, num + 1))
thread_aft = threading.Thread(target=catch_html_data, args=(url_aft, num + 2))
thread_pre.start()
thread_cur.start()
thread_aft.start()
thread_catch()
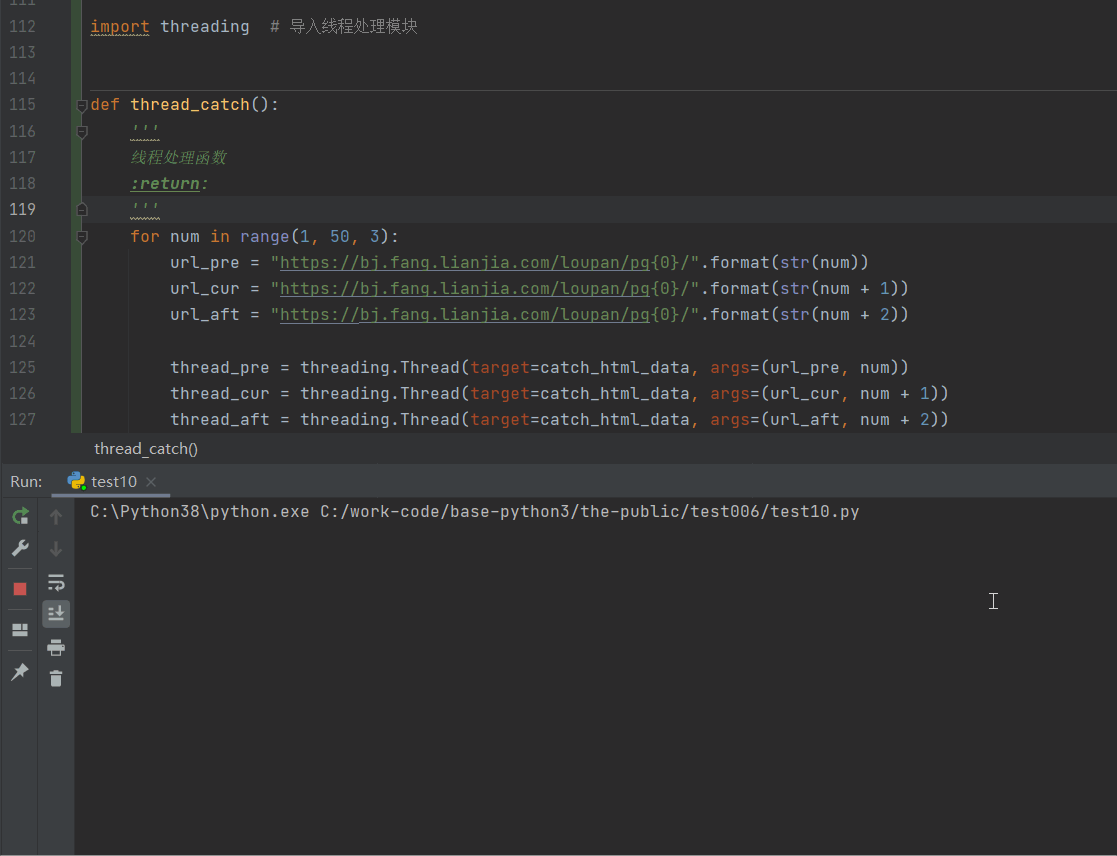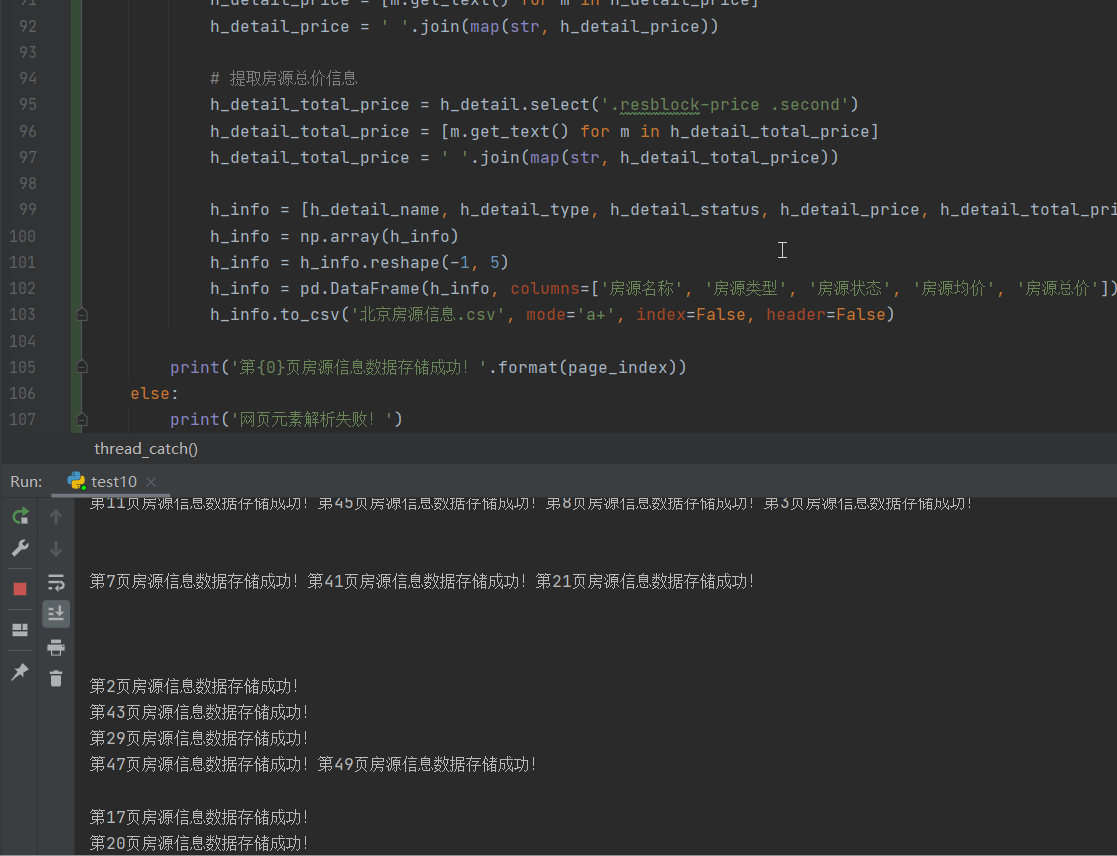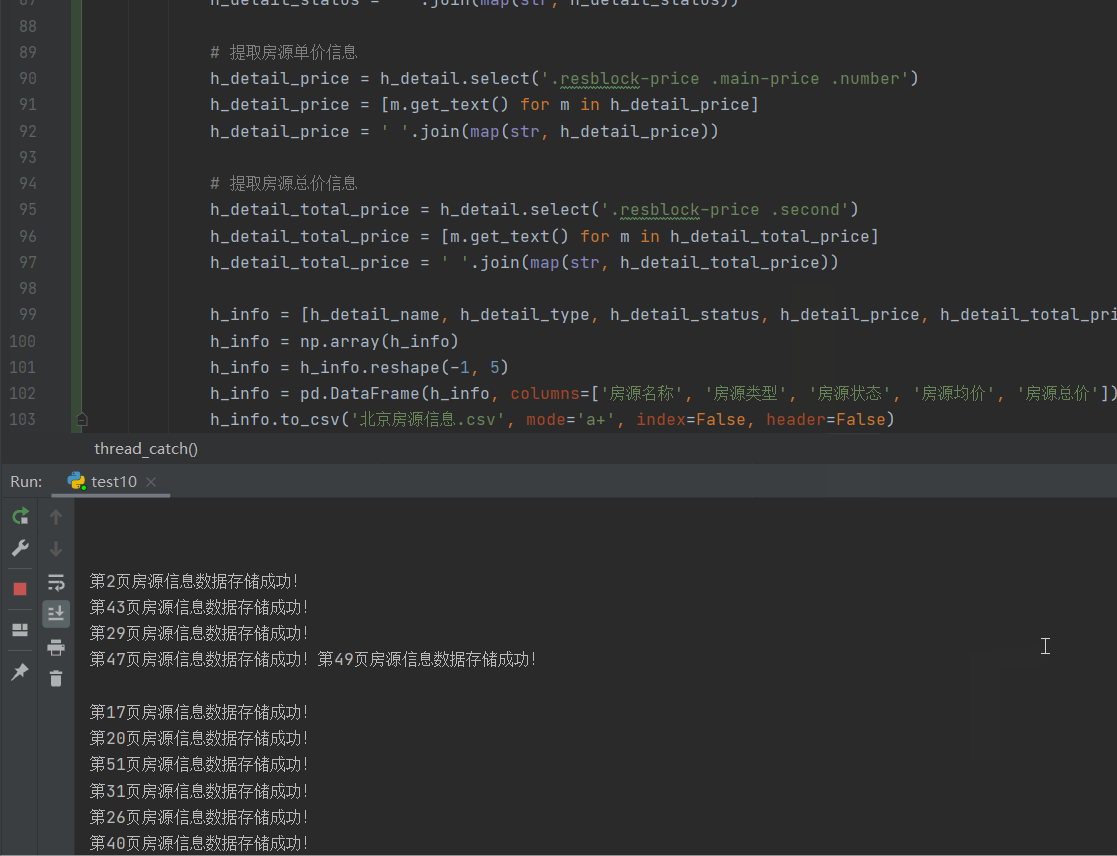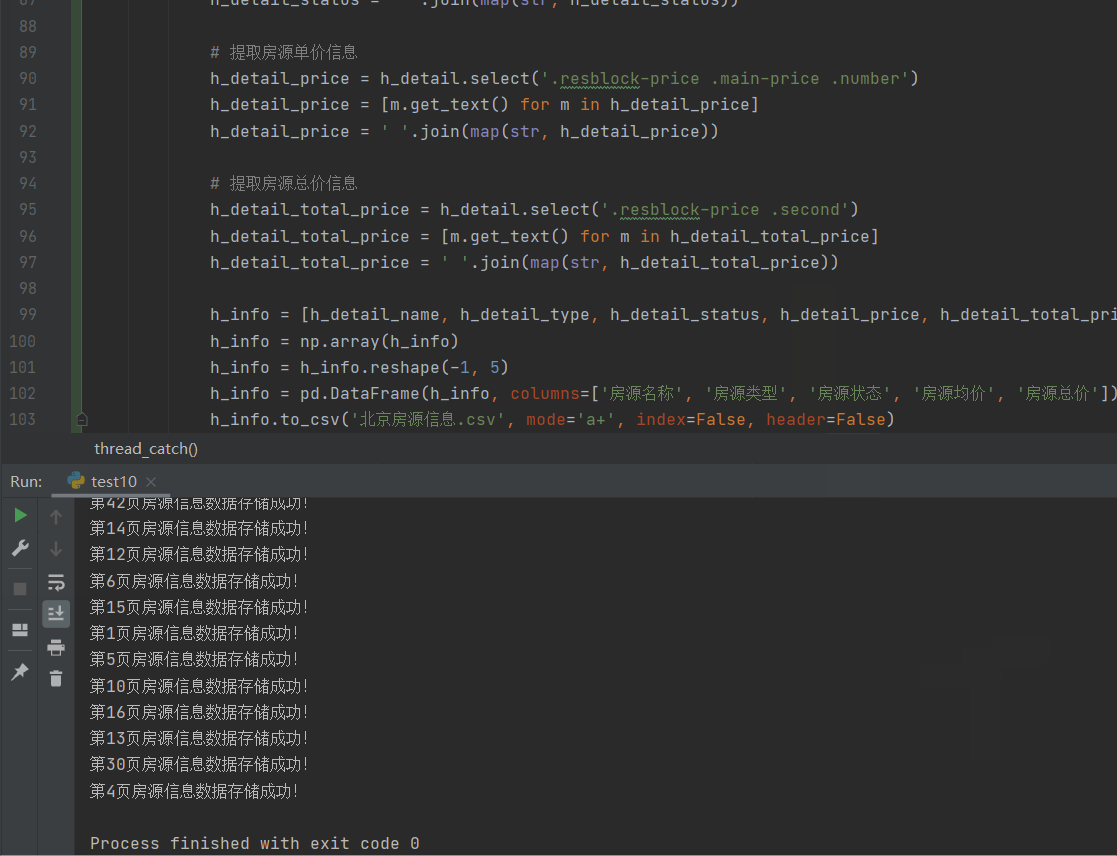
数据存储结果展示效果
【往期精彩】

办公自动化:Image图片转换成PDF文档存储...
python做一个微型美颜图片处理器,十行代码即可完成...
用python做一个文本翻译器,自动将中文翻译成英文,超方便的!
小王,给这2000个客户发一下节日祝福的邮件...
python 一行命令开启网络间的文件共享...
PyQt5 批量删除 Excel 重复数据,多个文件、自定义重复项一键删除...
再见XShell,这款国人开源的终端命令行工具更nice!
python 表情包下载器,轻松下载上万个表情包、斗图不用愁...
Python 自动清理电脑垃圾文件,一键启动即可...
有了jmespath,处理python中的json数据就变成了一种享受...
解锁一个新技能,如何在Python代码中使用表情包...
万能的list列表,python中的堆栈、队列实现全靠它!
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
我有一个存储主机名的Ruby数组server_names。如果我打印出来,它看起来像这样:["hostname.abc.com","hostname2.abc.com","hostname3.abc.com"]相当标准。我想要做的是获取这些服务器的IP(可能将它们存储在另一个变量中)。看起来IPSocket类可以做到这一点,但我不确定如何使用IPSocket类遍历它。如果它只是尝试像这样打印出IP:server_names.eachdo|name|IPSocket::getaddress(name)pnameend它提示我没有提供服务器名称。这是语法问题还是我没有正确使用类?输出:ge
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
我安装了ruby版本管理器,并将RVM安装的ruby实现设置为默认值,这样'哪个ruby'显示'~/.rvm/ruby-1.8.6-p383/bin/ruby'但是当我在emacs中打开inf-ruby缓冲区时,它使用安装在/usr/bin中的ruby。有没有办法让emacs像shell一样尊重ruby的路径?谢谢! 最佳答案 我创建了一个emacs扩展来将rvm集成到emacs中。如果您有兴趣,可以在这里获取:http://github.com/senny/rvm.el
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。