摘要:目前TopSQL功能被用户广泛使用,是性能定位、劣化分析、审计回溯等重要的基石,为用户提供覆盖内存、耗时、IO、网络、空间等多方面的监控能力。
本文分享自华为云社区《GaussDB(DWS)监控工具指南(一)作业级监控TopSQL》,作者:幕后小黑爪 。
监控系统是智能化管理和自动化运维的基石,可以为资源规划,故障排查,性能优化提供至关重要的数据支持。GaussDB(DWS)作为企业级数仓,为用户提供了一整套覆盖实例级、用户级、作业级的资源监控能力,其中,作业级监控(下文统称为TopSQL)主要是对运行作业的监控,包括了实时运行作业的相关信息,历史运行作业的相关信息等。它收集的数据来源于数据库内部,为用户提供了实时监控数据库的能力。
目前TopSQL功能被用户广泛使用,是性能定位、劣化分析、审计回溯等重要的基石,为用户提供覆盖内存、耗时、IO、网络、空间等多方面的监控能力。
本文以数仓813版本作为基线,对TopSQL进行介绍。
对于用户而言,数据库是个黑盒,输入SQL语句,输出预期结果。在此过程中,用户关心两点:
关于第一个问题,用户需要关注下SQL语句写的是否合理。而对于第二个问题,普通用户可以通过explain等手段分析作业的执行计划,然而企业用户的SQL作业耗时久,影响较大,重跑代价较高,无法额外通过explain performance等手段进行分析,此时TopSQL可以帮助用户打开数据库黑盒,查看作业执行的实时情况和历史情况,便于用户分析数据库的情况。
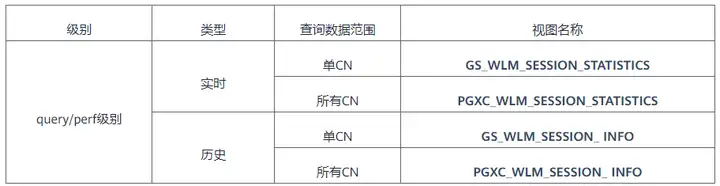
TopSQL功能主要通过视图进行承载,如下表所示,本文以query级别的视图为例进行说明。
使用TopSQL功能需要sysadmin权限。此外,用户需先检查下TopSQL功能是否开启,涉及TopSQL的数据库GUC参数包括:
是否开启监控功能,实时TopSQL的总开关,关闭之后实时TopSQL将不再进行记录,更不会在历史TopSQL中出现。
设置对当前会话的语句进行资源监控的最小执行代价。
设置当前会话的资源监控的等级,默认为query级别。
设置实时TopSQL中记录的语句执行结束后进行历史信息转存的最小执行时间。当执行完成的作业,其执行时间不小于此参数值时,作业信息会从实时视图(以STATISTICS为后缀的视图)转存到相应的历史视图
设置是否开启资源监控记录归档功能。开启时,对于执行结束的记录,会分别被归档到相应的INFO视图,CN和DN都需要设置上。
设置历史TopSQL中GS_WLM_SESSION_INFO和GS_WLM_OPERATOR_INFO表中数据的保存时间,单位为天。
参数正确设置后,TopSQL会记录用户的SQL语句执行过程中的相关信息,用户可以使用TopSQL的视图筛选出执行时间较长的作业,专注于慢SQL的分析。
TopSQL功能分为实时TopSQL和历史TopSQL,以query级别为例,当需要查看正在运行的作业时,用户可查看实时TopSQL视图GS_WLM_SESSION_STATISTICS和PGXC_WLM_SESSION_STATISTICS,若需要对已经执行完成的作业进行分析,可查询历史TopSQL视图GS_WLM_SESSION_ HISTORY和PGXC_WLM_SESSION_ HISTORY。其中GS_开头的可以查询当前CN节点上正在执行的作业信息,PGXC_开头的可查询所有CN节点上正在执行的作业信息。
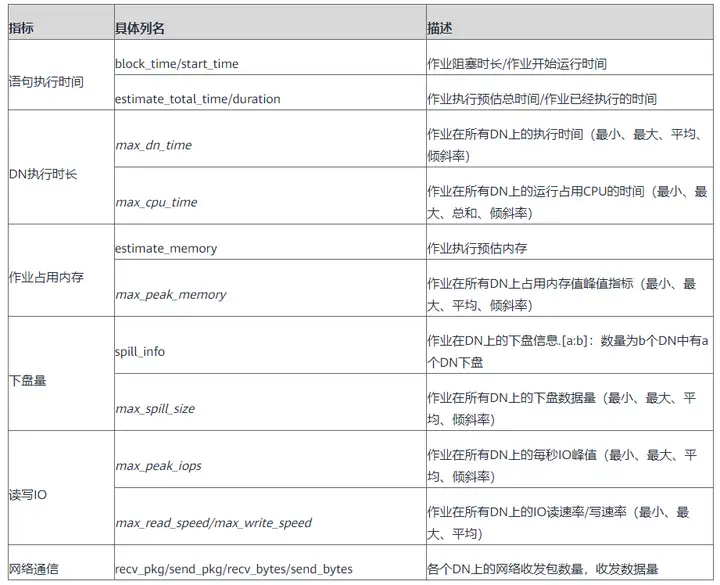
实时TopSQL视图为用户记录了作业运行时的相关信息,比如作业下发来源、阻塞时间、执行时长、开始时间、内存消耗、作业下盘量、作业IO、网络、语句类型、语句的执行计划等信息。用户可先通过resource_pool、nodename、username、query等信息定位到自己需要分析的语句,再通过作业运行信息定位问题。又或者用户可通过对查询进行筛选,筛选出当前占用资源较多的作业。
历史TopSQL视图记录了作业运行结束时的资源使用情况(包括内存、下盘、CPU时间等)和运行状态信息(包括报错、终止、异常等)以及性能告警信息。用户可通过对历史语句运行数据的分析,筛选出执行时长较大的语句,看语句执行计划是否有优化的空间,是否需要对表做一些analyze或者vacuum之类的操作。又比如对于内存报错的情况,可分析内存占用高的语句是否合理,从执行计划上分析是否有优化空间。
文末附TopSQL实践:常见问题现象及对应原因。
TopSQL的数据来源于数据库内核,当语句执行时,TopSQL会实时记录语句执行的相关信息。实时TopSQL数据会保存在内存的临时表中,当语句执行结束后,数据会转存到对应实体表GS_WLM_SESSION_INFO中,在实际使用中,由于下发作业繁多,历史TopSQL记录的作业数也不断增长,这样会导致INFO表中的数据量逐渐庞大,为了确保数仓整体性能不受影响,支持通过TOPSQL_RETENTION_TIME来设置INFO表中数据的保存时间(单位为天)。当数据存留时长超过这个时限,会对实体表GS_WLM_SESSION_INFO进行数据老化删除处理。

图 3-1 TopSQL数据流通图
如图3-1所示,各项GUC参数决定了TopSQL生成的记录信息,具体的参数说明详见第2节使用TopSQL前的检验。
对于企业用户而言,性能问题是Top级问题,对于TopSQL功能,我们进行了性能压测,在4TB的场景下,进行TPCC基准性能测试,进行了2000的并发压测,TPMC下降了约有2%,属于可接受的范围。
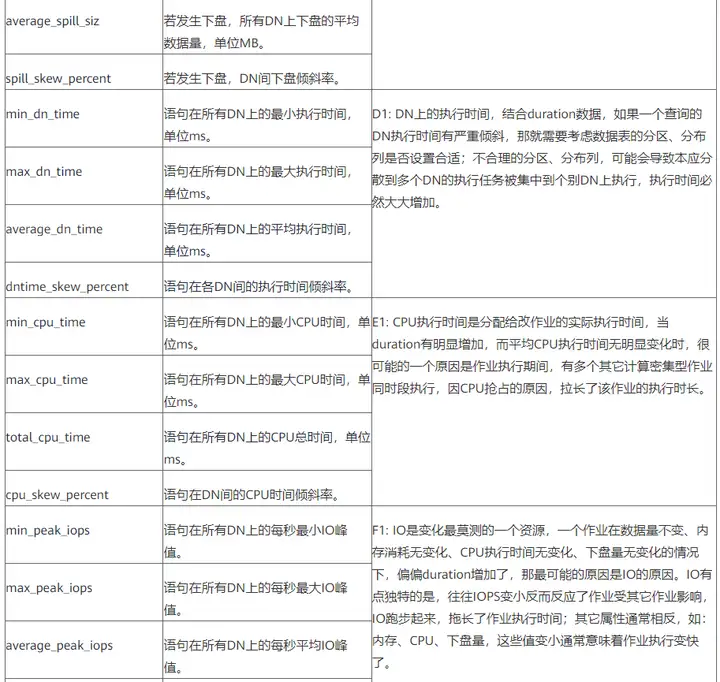
语句属性列说明:
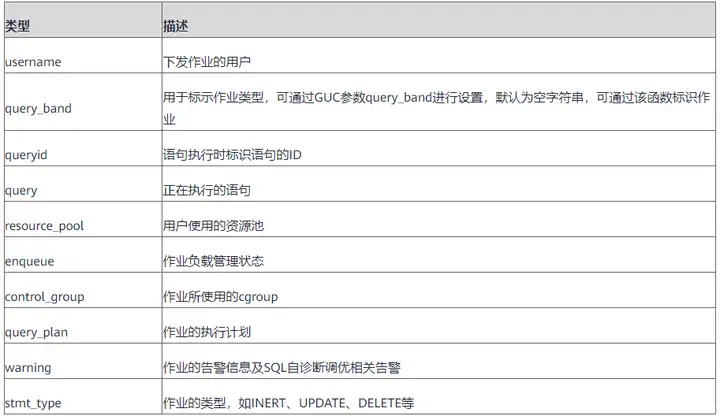
语句的执行信息属性列,斜体代表可更换前缀/后缀式的指标,类似前缀后缀有(min_,max_,total_,average_,_skew_percent)
TopSQL由于自身限制,存在一些记录异常的情况,此处对8.1.3版本的TopSQL语句记录情况进行说明:
TopSQL功能是GaussDB(DWS)支持性能问题定位、语句劣化分析、审计回溯等重要功能的基石。在此基础上,内核也拓展出了异常规则等一些高阶用法,在日常使用中,用户也对TopSQL提出了更高的要求,比如记录子语句、记录语句类型、提升算子级别语句监控准确性等诸多建议。为此,GaussDB(DWS)团队会在此基础上继续演进,更好的服务用户,提升用户满意度。
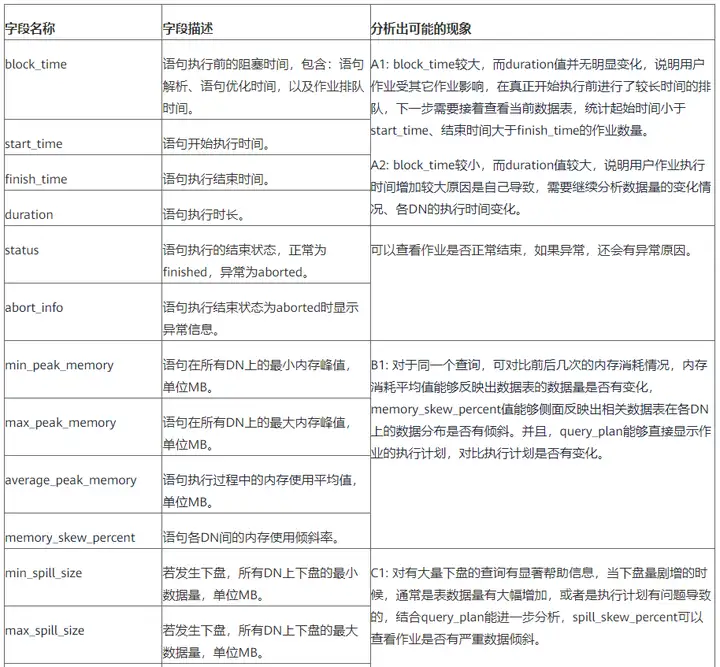

总结一下:
值得注意的是,发生资源争抢时,可能会出现并发症,即CPU、IO抢占,作业排队现象都会发生,针对并发症问题,可以逐步分析解决,比如:
第一步,调整作业执行顺序,减少并发作业数量,减少阻塞时间;
第二步,定位出同时段执行的典型计算密集型、存储密集型作业,先移动到其它时间段执行,减少对本作业的影响;
第三步,在无其他作业明显干预的情况下,做进一步分析,
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
是否可以在所有delayed_job任务之前运行一个方法?基本上,我们试图确保每个运行delayed_job的服务器都有我们代码的最新实例,所以我们想运行一个方法来在每个作业运行之前检查它。(我们已经有了“check”方法并在别处使用它。问题只是关于如何从delayed_job中调用它。) 最佳答案 现在有一种官方方法可以通过插件来做到这一点。这篇博文通过示例清楚地描述了如何执行此操作http://www.salsify.com/blog/delayed-jobs-callbacks-and-hooks-in-rails(本文中描述
我有一个bash脚本,它运行一个ruby脚本来获取我的Twitter提要。##/home/username/twittercron#!/bin/bashcd/home/username/twitterrubytwitter.rbfriends命令行运行成功/home/username/twittercron但是当我尝试将它作为cronjob运行时,它运行了但无法获取提要。##crontab-e*/15*****/home/username/twittercron脚本已经chmod+x。不知道为什么会这样。有什么想法吗? 最佳答案
我正在尝试在RVM环境中运行10.5的旧PPC机器上运行一个简单的ruby脚本。在SO上搜索,我遵循了这个post中选择的答案.这是cron中的结果行:SHELL=/bin/bash00****BASH_ENV=~/.bash_profile&&/bin/bash-c'~/deggy/onlineGW.rb'此命令在用户sam的根目录下的Bash中运行良好。这是我脚本的重要部分:#!/usr/bin/envrubyrequire'open-uri'require'nokogiri'...这是cron的错误输出:X-Cron-Env:X-Cron-Env:X-Cron-Env:X-C
我实在是无计可施了。我不明白为什么它不起作用。我创建了一个类,我使用rake命令对其进行调用和排队。当我使用“rakejobs:work”运行worker并调用命令“rakeget_updates”时,它执行得很好。但是,当我将worker作为守护进程运行时(RAILS_ENV=productionbin/delayed_jobstart)并调用命令“rakeget_updates”时,它会产生错误。app/workers/get_updates.rbclassGetUpdatesdefperformbeginning=Time.nowincludeSoapHelperrequire'
我正在使用DelayedJob,我想更新我的Rails4.2应用程序以使用ActiveJob。问题是我有一堆看起来像这样的自定义作业:AssetDeleteJob=Struct.new(:user_id,:params)dodefperform#codeend#moremethodsn'stuffend然后在某处的Controller中,作业使用以下语法排队:@asset_delete_job=AssetDeleteJob.new(current_admin_user.id,params)Delayed::Job.enqueue@asset_delete_job我想找到ActiveJo
我尝试每天在我的Rails应用程序中自动记录一些数据。我想知道是否有人知道一个好的解决方案?我找到了https://github.com/javan/whenever,但我想确保在选择之前了解所有选项。谢谢!艾略特 最佳答案 我真的很喜欢whenever-这是一个很棒的Gem,我已经在生产中使用了它。关于它还有一个很好的Railscasts插曲:http://railscasts.com/episodes/164-cron-in-ruby 关于ruby-on-rails-rails3中c
我知道我们可以做到:sidekiq_optionsqueue:"Foo"但在这种情况下,Worker只分配给一个队列:“Foo”。我需要在特定队列中分配作业(而不是worker)。使用Resque很容易:Resque.enqueue_to(queue_name,my_job)另外,为了并发问题,我需要限制每个队列的Worker数量为1。我该怎么做? 最佳答案 您可能会使用https://github.com/brainopia/sidekiq-limit_fetch然后:Sidekiq::Client.push({'class'=>
🎉精彩专栏推荐💭文末获取联系✍️作者简介:一个热爱把逻辑思维转变为代码的技术博主💂作者主页:【主页——🚀获取更多优质源码】🎓web前端期末大作业:【📚毕设项目精品实战案例(1000套)】🧡程序员有趣的告白方式:【💌HTML七夕情人节表白网页制作(110套)】🌎超炫酷的Echarts大屏可视化源码:【🔰Echarts大屏展示大数据平台可视化(150套)】🔖HTML+CSS+JS实例代码:【🗂️5000套HTML+CSS+JS实例代码(炫酷代码)继续更新中…】🎁免费且实用的WEB前端学习指南:【📂web前端零基础到高级学习视频教程120G干货分享】🥇关于作者:💬历任研发工程师,技术组长,教学总监;
是否可以在我的服务器上运行任何工具来监控多个Rails应用程序?我需要监控每个应用程序收到的请求数、每个应用程序使用了多少内存、使用了多少CPU以及其他类似的统计信息。我需要查看每个单独的Rails应用程序的统计信息。 最佳答案 我建议你试试NewRelicRPM.免费版:RPMLiteisthemostwidelyusedsolutionforbasicwebapplicationmonitoring.RPMLiteprovidesapplicationmonitoringforunlimitedJava,RubyorJRubya