计算机网络基础,考验一个程序员的基本功,也能更快的筛选出更优秀的人才。
假设发送端为客户端,接收端为服务端。开始时客户端和服务端的状态都是CLOSED。
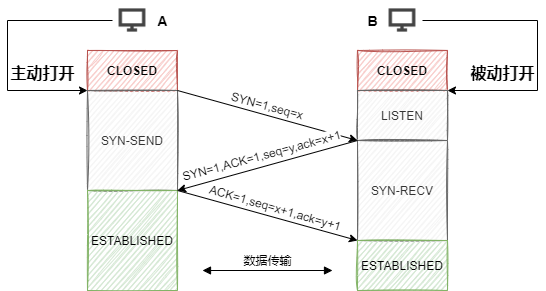
SYN=1,序列号seq=x。第一次握手前客户端的状态为CLOSE,第一次握手后客户端的状态为SYN-SENT。此时服务端的状态为LISTEN。SYN=1,ACK=1,序列号seq=y,确认号ack=x+1。第二次握手前服务端的状态为LISTEN,第二次握手后服务端的状态为SYN-RCVD,此时客户端的状态为SYN-SENT。(其中SYN=1表示要和客户端建立一个连接,ACK=1表示确认序号有效)ACK=1,序列号seq=x+1,确认号ack=y+1。第三次握手前客户端的状态为SYN-SENT,第三次握手后客户端和服务端的状态都为ESTABLISHED。此时连接建立完成。之所以需要第三次握手,主要为了防止已失效的连接请求报文段突然又传输到了服务端,导致产生问题。
本文已经收录到Github仓库,该仓库包含计算机基础、Java基础、多线程、JVM、数据库、Redis、Spring、Mybatis、SpringMVC、SpringBoot、分布式、微服务、设计模式、架构、校招社招分享等核心知识点,欢迎star~
如果访问不了Github,可以访问gitee地址。
IP 层是「不可靠」的,它不保证网络包的交付、不保证网络包的按序交付、也不保证网络包中的数据的完整性。
因为 TCP 是一个工作在传输层的可靠数据传输的服务,它能确保接收端接收的网络包是无损坏、无间隔、非冗余和按序的。
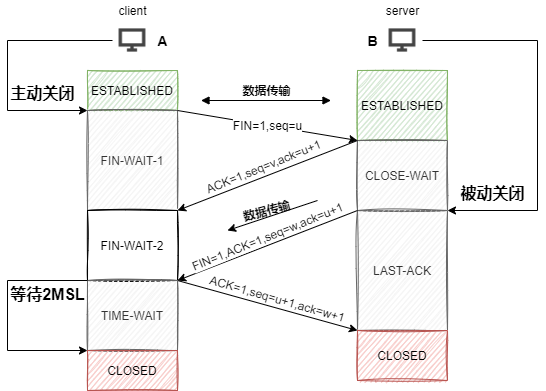
FIN=1,seq=u),并停止再发送数据,主动关闭TCP连接,进入FIN-WAIT-1(终止等待1)状态,等待B的确认。ACK=1,ack=u+1,seq=v),B进入CLOSE-WAIT(关闭等待)状态,此时的TCP处于半关闭状态,A到B的连接释放。FIN-WAIT-2(终止等待2)状态,等待B发出的连接释放报文段。FIN=1,ACK=1,seq=w,ack=u+1),B进入LAST-ACK(最后确认)状态,等待A的确认。ACK=1,seq=u+1,ack=w+1),A进入TIME-WAIT(时间等待)状态。此时TCP未释放掉,需要经过时间等待计时器设置的时间2MSL(最大报文段生存时间)后,A才进入CLOSED状态。B收到A发出的确认报文段后关闭连接,若没收到A发出的确认报文段,B就会重传连接释放报文段。ACK报文段有可能丢失,B收不到这个确认报文,就会超时重传连接释放报文段,然后A可以在2MSL时间内收到这个重传的连接释放报文段,接着A重传一次确认,重新启动2MSL计时器,最后A和B都进入到CLOSED状态,若A在TIME-WAIT状态不等待一段时间,而是发送完ACK报文段后立即释放连接,则无法收到B重传的连接释放报文段,所以不会再发送一次确认报文段,B就无法正常进入到CLOSED状态。ACK报文段后,再经过2MSL,就可以使这个连接所产生的所有报文段都从网络中消失,使下一个新的连接中不会出现旧的连接请求报文段。因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。但是在关闭连接时,当Server端收到Client端发出的连接释放报文时,很可能并不会立即关闭SOCKET,所以Server端先回复一个ACK报文,告诉Client端我收到你的连接释放报文了。只有等到Server端所有的报文都发送完了,这时Server端才能发送连接释放报文,之后两边才会真正的断开连接。故需要四次挥手。

基于TCP的应用层协议有:HTTP、FTP、SMTP、TELNET、SSH
基于UDP的应用层协议:DNS、TFTP、SNMP
TCP是面向流,没有界限的一串数据。TCP底层并不了解上层业务数据的具体含义,它会根据TCP缓冲区的实际情况进行包的划分,所以在业务上认为,一个完整的包可能会被TCP拆分成多个包进行发送,也有可能把多个小的包封装成一个大的数据包发送,这就是所谓的TCP粘包和拆包问题。
为什么会产生粘包和拆包呢?
解决方案:
TCP 利用滑动窗口实现流量控制。流量控制是为了控制发送方发送速率,保证接收方来得及接收。 TCP会话的双方都各自维护一个发送窗口和一个接收窗口。接收窗口大小取决于应用、系统、硬件的限制。发送窗口则取决于对端通告的接收窗口。接收方发送的确认报文中的window字段可以用来控制发送方窗口大小,从而影响发送方的发送速率。将接收方的确认报文window字段设置为 0,则发送方不能发送数据。
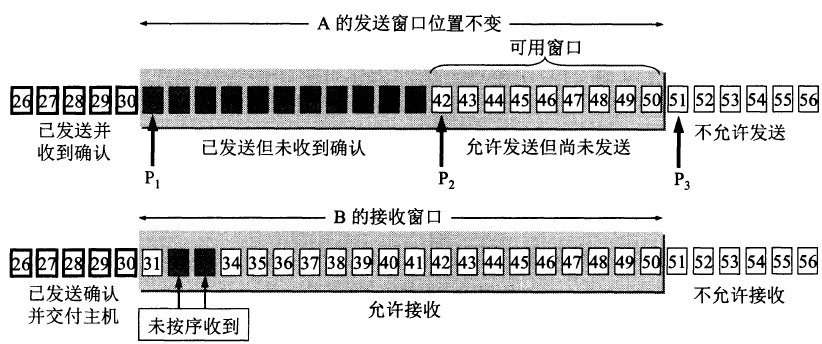
TCP头包含window字段,16bit位,它代表的是窗口的字节容量,最大为65535。这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。接收窗口的大小是约等于发送窗口的大小。
防止过多的数据注入到网络中。 几种拥塞控制方法:慢开始( slow-start )、拥塞避免( congestion avoidance )、快重传( fast retransmit )和快恢复( fast recovery )。
慢开始
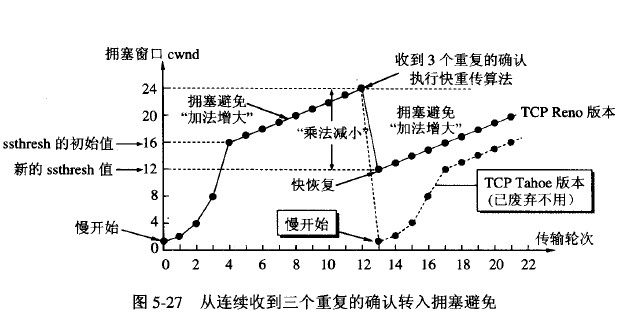
把拥塞窗口 cwnd 设置为一个最大报文段MSS的数值。而在每收到一个对新的报文段的确认后,把拥塞窗口增加至多一个MSS的数值。每经过一个传输轮次,拥塞窗口 cwnd 就加倍。 为了防止拥塞窗口cwnd增长过大引起网络拥塞,还需要设置一个慢开始门限ssthresh状态变量。
当 cwnd < ssthresh 时,使用慢开始算法。
当 cwnd > ssthresh 时,停止使用慢开始算法而改用拥塞避免算法。
当 cwnd = ssthresh 时,既可使用慢开始算法,也可使用拥塞控制避免算法。
拥塞避免
让拥塞窗口cwnd缓慢地增大,每经过一个往返时间RTT就把发送方的拥塞窗口cwnd加1,而不是加倍。这样拥塞窗口cwnd按线性规律缓慢增长。
无论在慢开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞(其根据就是没有收到确认),就要把慢开始门限ssthresh设置为出现拥塞时的发送 方窗口值的一半(但不能小于2)。然后把拥塞窗口cwnd重新设置为1,执行慢开始算法。这样做的目的就是要迅速减少主机发送到网络中的分组数,使得发生 拥塞的路由器有足够时间把队列中积压的分组处理完毕。
快重传
有时个别报文段会在网络中丢失,但实际上网络并未发生拥塞。如果发送方迟迟收不到确认,就会产生超时,就会误认为网络发生了拥塞。这就导致发送方错误地启动慢开始,把拥塞窗口cwnd又设置为1,因而降低了传输效率。
快重传算法可以避免这个问题。快重传算法首先要求接收方每收到一个失序的报文段后就立即发出重复确认,使发送方及早知道有报文段没有到达对方。
发送方只要一连收到三个重复确认就应当立即重传对方尚未收到的报文段,而不必继续等待重传计时器到期。由于发送方尽早重传未被确认的报文段,因此采用快重传后可以使整个网络吞吐量提高约20%。
快恢复
当发送方连续收到三个重复确认,就会把慢开始门限ssthresh减半,接着把cwnd值设置为慢开始门限ssthresh减半后的数值,然后开始执行拥塞避免算法,使拥塞窗口缓慢地线性增大。
在采用快恢复算法时,慢开始算法只是在TCP连接建立时和网络出现超时时才使用。 采用这样的拥塞控制方法使得TCP的性能有明显的改进。
我们都知道 TCP 连接建立是需要三次握手,假设攻击者短时间伪造不同 IP 地址的 SYN 报文,服务端每接收到 一个 SYN 报文,就进入 SYN_RCVD 状态,但服务端发送出去的 ACK + SYN 报文,无法得到未知 IP 主机的ACK 应答,久而久之就会占满服务端的 SYN 接收队列(未连接队列),使得服务器不能为正常用户服务。
TCP 四元组可以唯一的确定一个连接,四元组包括如下: 源地址 源端口 目的地址 目的端口。
源地址和目的地址的字段(32位)是在 IP 头部中,作用是通过 IP 协议发送报文给对方主机。
源端口和目的端口的字段(16位)是在 TCP 头部中,作用是告诉 TCP 协议应该把报文发给哪个进程。
最后给大家分享一个Github仓库,上面有大彬整理的300多本经典的计算机书籍PDF,包括C语言、C++、Java、Python、前端、数据库、操作系统、计算机网络、数据结构和算法、机器学习、编程人生等,可以star一下,下次找书直接在上面搜索,仓库持续更新中~


我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
我已经有很多两个值数组,例如下面的例子ary=[[1,2],[2,3],[1,3],[4,5],[5,6],[4,7],[7,8],[4,8]]我想把它们分组到[1,2,3],[4,5],[5,6],[4,7,8]因为意思是1和2有关系,2和3有关系,1和3有关系,所以1,2,3都有关系我如何通过ruby库或任何算法来做到这一点? 最佳答案 这是基本Bron–Kerboschalgorithm的Ruby实现:classGraphdefinitialize(edges)@edges=edgesenddeffind_maximum_
我正在阅读“Rails3Way”,在第39页,它显示了匹配:to=>重定向方法的代码示例。在该方法中存在以下代码。虽然我知道模对数字有什么作用,但我不确定下面的%是做什么的,因为路径和参数显然都不是数字。如果有人能帮助我理解%在这种情况下的用法,我将不胜感激。proc{|params|path%params} 最佳答案 这可能是String#%与其他语言中的sprintf非常相似的方法:'%05d'%10#=>"00010"它可以接受单个参数或数组:'%.3f%s'%[10.341412,'samples']#=>"10.341sa
我遇到了ruby正则表达式的问题。我需要找到所有(可能重叠的)匹配项。这是问题的简化:#Simpleexample"Hey".scan(/../)=>["He"]#Actualresults#Withoverlappingmatchestheresultshouldbe=>["He"],["ey"]我尝试执行并获得所有结果的正则表达式如下所示:"aaaaaa".scan(/^(..+)\1+$/)#Thislooksformultiplesof(here)"a"biggerthanonethat"fills"theentirestring."aa"*3=>true,"aaa"*2=
西安华为OD面试体验开始投简历技术面试进展工作进展开始投简历去年一整年一直在考研和工作之间纠结,感觉自己的状态好像当时的疫情一样差劲。之前刚毕业的时候投了个大厂的简历,结果一面写算法的时候太拉跨了,虽然知道时dfs但是代码熟练度不够,放在平时给足时间自己可以调试通过,但是熟练度不够那面试当时就写不出来被刷了。说真的算法学到后期我感觉最重要的是熟练度和背板子(对于我这种普通玩家来说),面试题如果一上来短时间内想不出思路就完蛋了。然后由于当时找的工作不是很理想就又想考研了。但是考研是有风险的,我自我感觉自己可能冲不上那个学校,而找工作一个没成可以继续找嘛。本着抱着试试看的态度在boss上投了简历,
在我们的项目中,我们有一些“被遗忘的”类存在了很长一段时间。那些类已被其他类替代,但我们忘记删除它们。是否有一些自动化的方法/工具可以发现Ruby{onRails}应用程序中没有使用哪些类?谢谢! 最佳答案 这个问题已经被提出了很多次,但是最好的答案都在这里:FindunusedcodeinaRailsapp我个人喜欢日志解析:https://stackoverflow.com/a/14161807但在任何情况下,您都可以创建自己的记录器,扩展ActiveRecord::Base以创建一个观察器,该观察器将最常用的模块存储在数据库中
我正在研究Ruby解释器是如何实现的,并且出现了一个问题,但我还没有得到答案。这就是标题中的那个:因为Class(r_cClass)将super设置为自身(忽略元类,因为实际上super是r_cClass的元类),如果我向Class对象发送一个方法,这将在Class的方法表中查找'类(class)。但是Class的类是Class,所以我不应该最终寻找Class的实例方法吗?但事实并非如此,因为在文档中Class类方法和Class实例方法是分开的。在Ruby的eval.c中的search_method中,我没有发现对Class类有什么特别的检查。任何人都可以阐明这一点吗?
我知道我能做到:classParentdefinitialize(args)args.eachdo|k,v|instance_variable_set("@#{k}",v)endendendclassA但我想使用关键字参数来更清楚地说明可以接受哪个散列键方法(并进行验证表明不支持此键)。所以我可以写:classAdefinitialize(param1:3,param2:4)@param1=param1@param2=param2endend但是有没有可能写一些更短的东西而不是@x=x;@y=y;...从传递的关键字参数初始化实例变量?是否可以访问作为哈希传递的关键字参数?