
目录
三言两语,不如细心探索。
希望读完此文,能帮助读者对AWS S3 有一个初步的了解
文章标记颜色说明:
- 黄色:重要标题
- 红色:用来标记结论
- 绿色:用来标记一级论点
- 蓝色:用来标记二级论点
Amazon Simple Storage Service (Amazon S3) 是一种对象存储服务
特点:
- 行业领先
- 可扩展性
- 数据可用性
- 安全性
- 性能高
其具有高成本效益的存储类和易于使用的管理功能
可以优化成本、组织数据并配置精细调整过的访问控制,从而满足特定的业务、组织和合规性要求。

Amazon S3 是一种数据元存储服务,可将数据以对象形式存储在存储桶中。对象指的是一个文件和描述该文件的任何元数据。存储桶是对象的容器。
要将数据存储在 Amazon S3 中,
- 需要先创建存储桶,
- 指定存储桶名称和 AWS 区域。
- 将数据作为 Amazon S3 中的数据元上传到该存储桶。
每个对象都带有密钥(或键名称),它是存储桶中对象的唯一标识符。
S3除了用于对象存储,还可以做一下场景:
- 数据湖
- 网站
- 移动应用程序
- 备份和恢复
- 归档
- 企业应用程序
- IoT 设备和大数据分析
运行大数据分析、人工智能 (AI)、机器学习 (ML) 和高性能计算 (HPC) 应用程序来获得数据见解。
数据湖基础:Amazon S3、AWS Lake Formation、Amazon Athena、Amazon EMR 和 AWS Glue
使用在 Amazon S3 上构建的数据湖,可以使用原生 AWS 服务运行大数据分析、人工智能(AI)、机器学习、高性能计算(HPC)和媒体数据处理应用程序,以便从非结构化数据集中获得洞察信息。
与 AWS Lake Formation 和 AWS Glue 结合使用时,可以通过端到端数据集成和集中的、类似数据库的权限和治理来轻松简化数据湖的创建和管理。Glue、Amazon EMR 和 Amazon Athena 等 AWS 分析解决方案可让您轻松直接查询数据湖。
通过 S3 强大的复制功能达到恢复时间目标 (RTO)、恢复点目标 (RPO) 以及符合合规要求。
优势:
- 数据持久性
- 灵活性和可扩展性
- 成本效益
- 适合所有数据类型的备份
- 安全性与合规性
- 数据传输方法
将数据存档移动到 Amazon S3 Glacier 存储类以降低成本、消除运营复杂性并获得新见解。
优势:
- 检索速度快至毫秒
- 无与伦比的持久性和可扩展性
- 最全面的安全与合规性功能
- 最低成本
- 在整个数据生命周期中保持一致
构建快速、功能强大的移动和基于 Web 的云原生应用程序,可在高度可用的配置中自动扩展。
云原生应用程序实现功能的速度更快,因为微服务在准备就绪时提供其功能,而无需等待单片应用程序完成。Amazon S3为IT团队交付的内部员工应用程序和产品团队交付的外部客户应用程序提供即时、弹性的容量。
功能分为以下几个模块
存储类
Amazon S3 提供一系列适合不同使用案例的存储类。
使用方法:
频繁访问存储在:
- S3 Standard
不经常访问,存储在:
- S3 Standard-IA
- S3 One Zone-IA
成本归档,存储在:
- S3 Glacier Instant Retrieval
- S3 Glacier Flexible Retrieval
- S3 Glacier Deep Archive
不断变化或未知访问模式的数据:
- S3 Intelligent-Tiering
这四个访问层包括两个低延迟访问层(针对频繁和不频繁访问进行了优化),以及两个为异步访问很少访问的数据而设计的 opt-in archive 访问层。
Amazon S3 具有存储管理功能,可以使用这些功能来管理成本、满足法规要求、减少延迟并保存数据的多个不同副本以满足合规性要求。
生命周期: 配置生命周期策略以管理对象,并在其整个生命周期内经济高效地存储。您可以将对象转换为其他 S3 存储类,也可以使其生命周期结束的对象过期。
对象锁定:可以在固定的时间段内或无限期地阻止删除或覆盖 Amazon S3 对象。可以使用对象锁定来满足需要一次写入多次读取 (WORM) 存储的法规要求,或只是添加另一个保护层来防止对象被更改和删除。
复制: 将对象及其各自的元数据和对象标签复制到同一或不同的 AWS 区域 目标存储桶中的一个或多个目标存储桶,以减少延迟、合规性、安全性和其他使用案例。
分批操作:通过单个 S3 API 请求或在 Amazon S3 控制台中单击几次,大规模管理数十亿个对象。可以使用分批操作来执行诸如复制、调用 AWS Lambda 函数, 和恢复数百万或数十亿对象。
Amazon S3 提供了用于审核和管理对存储桶和数据元的访问的功能。默认情况下,S3 存储桶和对象都是私有的。
用户只能访问自己创建的 S3 资源。
如果需要授予支持特定使用案例的细粒度资源权限或审核 Amazon S3 资源的权限,可以使用以下功能。
阻止共有访问:阻止对 S3 存储桶和对象的公有访问。默认情况下,在账户和存储桶级别打开 “阻止公共访问” 设置。
AWS Identity and Access Management (IAM):为 AWS 账户 管理对 Amazon S3 资源的访问。例如,可以将 IAM 用于 Amazon S3,控制用户或用户组对您的 AWS 账户 所拥有 S3 存储桶的访问类型。
存储桶策略:使用基于 IAM 的策略语言为 S3 存储桶及其中的对象配置基于资源的权限。
Amazon S3 访问点:使用专用访问策略配置命名网络终端节点,以便大规模管理对 Amazon S3 中共享数据集的访问。
访问控制列表 (ACL) :向授权用户授予单个存储桶和对象的读写权限。作为一般规则,建议使用基于 S3 资源的策略(存储桶策略和访问点策略)或 IAM 策略进行访问控制,而不是 ACL。ACL 是一种访问控制机制,早于基于资源的策略和 IAM。
(S3 对象所有权): 禁用 ACL 并获取存储桶中每个对象的所有权,从而简化了对存储在 Amazon S3 中的数据的访问管理。作为存储桶所有者,会自动拥有并完全控制桶中的每个对象,并且数据的访问控制是基于策略而进行。
S3 访问分析器:评估和监控S3 存储桶访问策略,确保这些策略仅提供对 S3 资源的预期访问。
先找到S3
进入S3控制台,点击创建存储桶

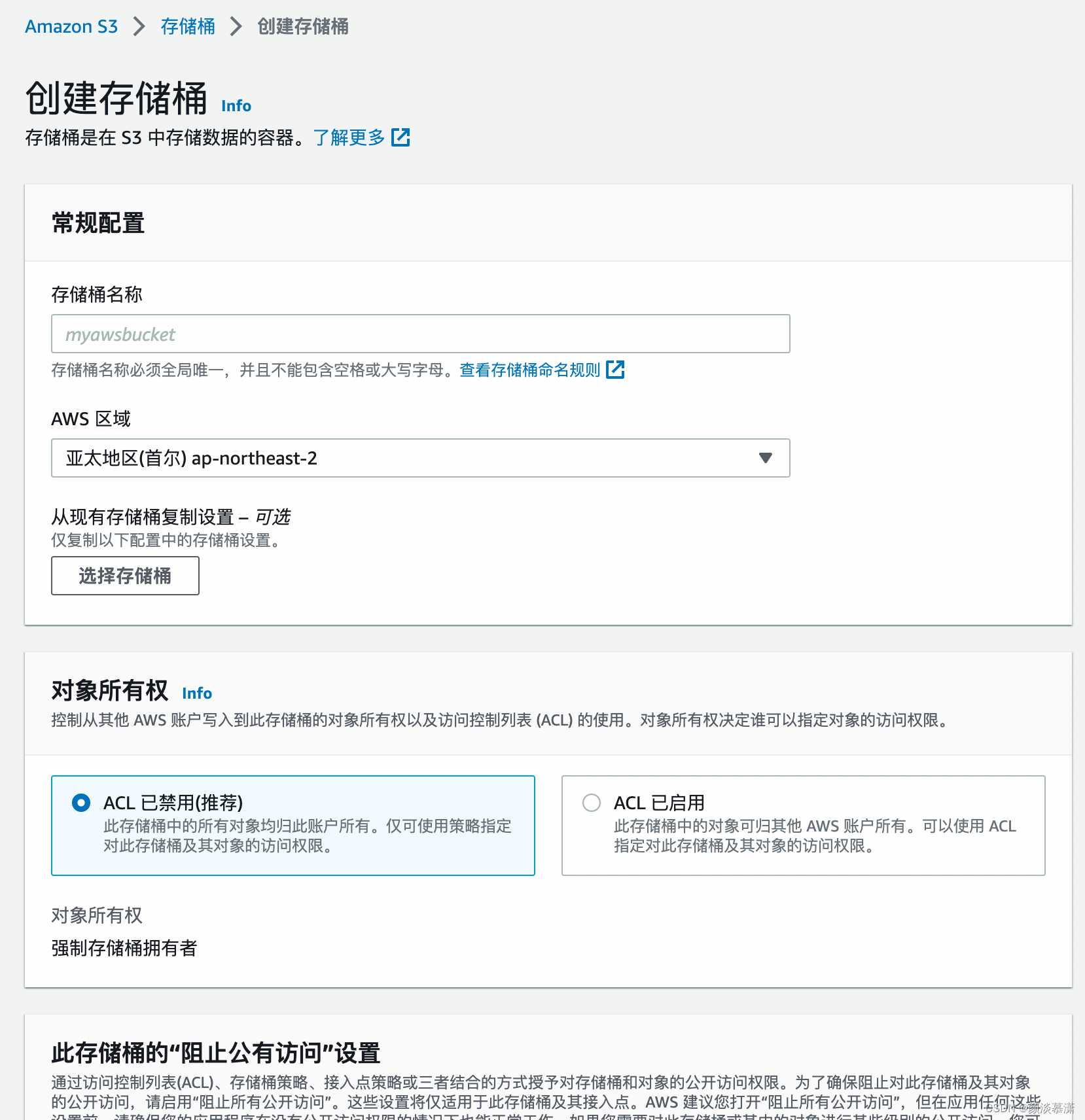
根据业务,设置不同的参数 然后点击创建,即可创建一个简单的存储桶
 2.2 配置 CORS 规则
2.2 配置 CORS 规则以下代码示例显示如何向 S3 桶添加跨源资源共享 (CORS) 规则。示例为Java
其他的学习。可以查阅github
public static void deleteBucketCorsInformation(S3Client s3, String bucketName, String accountId) {
try {
DeleteBucketCorsRequest bucketCorsRequest = DeleteBucketCorsRequest.builder()
.bucket(bucketName)
.expectedBucketOwner(accountId)
.build();
s3.deleteBucketCors(bucketCorsRequest) ;
} catch (S3Exception e) {
System.err.println(e.awsErrorDetails().errorMessage());
System.exit(1);
}
}
public static void getBucketCorsInformation(S3Client s3, String bucketName, String accountId) {
try {
GetBucketCorsRequest bucketCorsRequest = GetBucketCorsRequest.builder()
.bucket(bucketName)
.expectedBucketOwner(accountId)
.build();
GetBucketCorsResponse corsResponse = s3.getBucketCors(bucketCorsRequest);
List<CORSRule> corsRules = corsResponse.corsRules();
for (CORSRule rule: corsRules) {
System.out.println("allowOrigins: "+rule.allowedOrigins());
System.out.println("AllowedMethod: "+rule.allowedMethods());
}
} catch (S3Exception e) {
System.err.println(e.awsErrorDetails().errorMessage());
System.exit(1);
}
}
public static void setCorsInformation(S3Client s3, String bucketName, String accountId) {
List<String> allowMethods = new ArrayList<>();
allowMethods.add("PUT");
allowMethods.add("POST");
allowMethods.add("DELETE");
List<String> allowOrigins = new ArrayList<>();
allowOrigins.add("http://example.com");
try {
// Define CORS rules.
CORSRule corsRule = CORSRule.builder()
.allowedMethods(allowMethods)
.allowedOrigins(allowOrigins)
.build();
List<CORSRule> corsRules = new ArrayList<>();
corsRules.add(corsRule);
CORSConfiguration configuration = CORSConfiguration.builder()
.corsRules(corsRules)
.build();
PutBucketCorsRequest putBucketCorsRequest = PutBucketCorsRequest.builder()
.bucket(bucketName)
.corsConfiguration(configuration)
.expectedBucketOwner(accountId)
.build();
s3.putBucketCors(putBucketCorsRequest);
} catch (S3Exception e) {
System.err.println(e.awsErrorDetails().errorMessage());
System.exit(1);
}
}
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
从给定URL下载文件并立即将其上传到AmazonS3的更直接的方法是什么(+将有关文件的一些信息保存到数据库中,例如名称、大小等)?现在,我既不使用Paperclip,也不使用Carrierwave。谢谢 最佳答案 简单明了:require'open-uri'require's3'amazon=S3::Service.new(access_key_id:'KEY',secret_access_key:'KEY')bucket=amazon.buckets.find('image_storage')url='http://www.ex
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我正在尝试编写一个将文件上传到AWS并公开该文件的Ruby脚本。我做了以下事情:s3=Aws::S3::Resource.new(credentials:Aws::Credentials.new(KEY,SECRET),region:'us-west-2')obj=s3.bucket('stg-db').object('key')obj.upload_file(filename)这似乎工作正常,除了该文件不是公开可用的,而且我无法获得它的公共(public)URL。但是当我登录到S3时,我可以正常查看我的文件。为了使其公开可用,我将最后一行更改为obj.upload_file(file
我有一个应用程序可以读取文件的内容并为其编制索引。我将它们存储在磁盘本身中,但现在我使用的是AmazonS3,因此以下方法不再适用。事情是这样的:defperform(docId)@document=Document.find(docId)if@document.file?#Youshould'tcreateanewversion@document.versionlessdo|doc|@document.file_content=Cloudoc::Extractor.new.extract(@document.file.file)@document.saveendendend@docu
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于