应用场景:姓名 地址 爱好
name = 'kevin'
addr = '浦东新区'
hobby = '学习'
定义字符串的四种方式
# 方式1:
name = 'kevin'
# 方式2:
name = "kevin"
# 方式3:
name = '''kevin'''
# 方式4:
name = """kevin"""
为什么定义字符串需要有多种方式
information = '洋哥说':'趁年轻,学技能,养活自己''
information = '洋哥说:“趁年轻,学技能,养活自己”'
information = "洋哥说:'趁年轻,学技能,养活自己'"
# 存放多个数据值
name_list = ['tony', 'kevin', 'oscar', 'jerry']
# 放入任意数据类型
l1 = [11, 11.11, 'kevin',[11, 22]]
infor_dict = {'name': 'kevin', 'age': '19', 'hobby': 'read'}
文字描述:大括号括起来,内部可以存放多个数据,数据的组织形式是k:v键值对。键值对与键值对之间逗号隔开
K:是对V的描述性信息(一般情况是字符串)
V:真正的数据,其实相当于数据值,也是任意的数据类型
字典不能通过索引取值,因为字典是无序的,所以只能按k取值
print(infor_dict['name'])
# 判断是否正确
'''只有两种情况'''
True 对 正确的 可行的
False 错误 不可行的
# python中所以的数据都自带布尔值
布尔值为False的数据有:0 None '' [] {}
布尔值为True的数据有:除了上面的都是True
# 布尔值的变量命名规范:以is开头
is_right
is_delete
'''结果可能是布尔值的情况,我们都采用is开头命名'''
t1 = (11, 22, 'kevin')
建议:以后在使用可以存放多个数据值的数据类型时 如果里面暂时只有一个数据值 那么也建议你加上逗号
列表和元组的区别
集合只能用于去重和关系运算,集合是无序的,也是不可变类型
s1 = {11,22,33,44}
'''集合中得直接不能直接取出'''
input函数
当我们运行input函数时,pycharm的运行窗口中会有光标闪烁,等待我们输入信息。(input输入的数据值会变成字符串类型)
username = input('请输入您的用户名>>>:')
print函数
可以把想要打印的数据值、函数名等信息打印出来,括号内部可以用逗号隔开,一次性打印多个数据
print('name', 11)
python中\n和\r、\r\n都是换行符,但是\n用的比较多,我们使用print()打印文本时可以在文本对应位置输入换行符,达到换行的效果print打印的时会自动换行,这是因为print函数中自带换行符,我们也可以更改print的end=''参数来达到不换行输入的目的。(默认情况下end='\n')print('使用print打印时会自动换行',end='')
print('使用print打印时会自动换行')
# 这两行代码会打印在同一行
print('使用print打印时\n会自动换行')
# 会分两行输出
比如:'亲爱的xxx你好!你xxx月的话费是xxx,余额是xxx‘,我们需要做的就是将xxx替换为具体的内容。
res = '亲爱的%s你好!你%s月的话费是%s,余额是%s,我们需要做的就是将xxx替换为具体的内容。'
# print(res % ('kevin', 99, 2, 99999999))
# print(res % ('kevin1', 991, 2, 100))
# print(res % ('kevin2', 992, 2, 1199999))
# print(res % ('kevin3', 993, 2, 22999999))
# print(res % ('kevin4', 994, 2, 933999999))
# res1 = 'my name is %s'
# print(res1 % 'tony')
# %d占位符(了解)只能给数字类型占位
# print("my name is %d" % 'kevin')
print("金额:%08d" % 111)
print("金额:%08d" % 666666)
print("金额:%08d" % 99999999999)
加:+、减:-、乘:*、除:/、赋值符号:=、乘方:** 、取余数:%、整除://
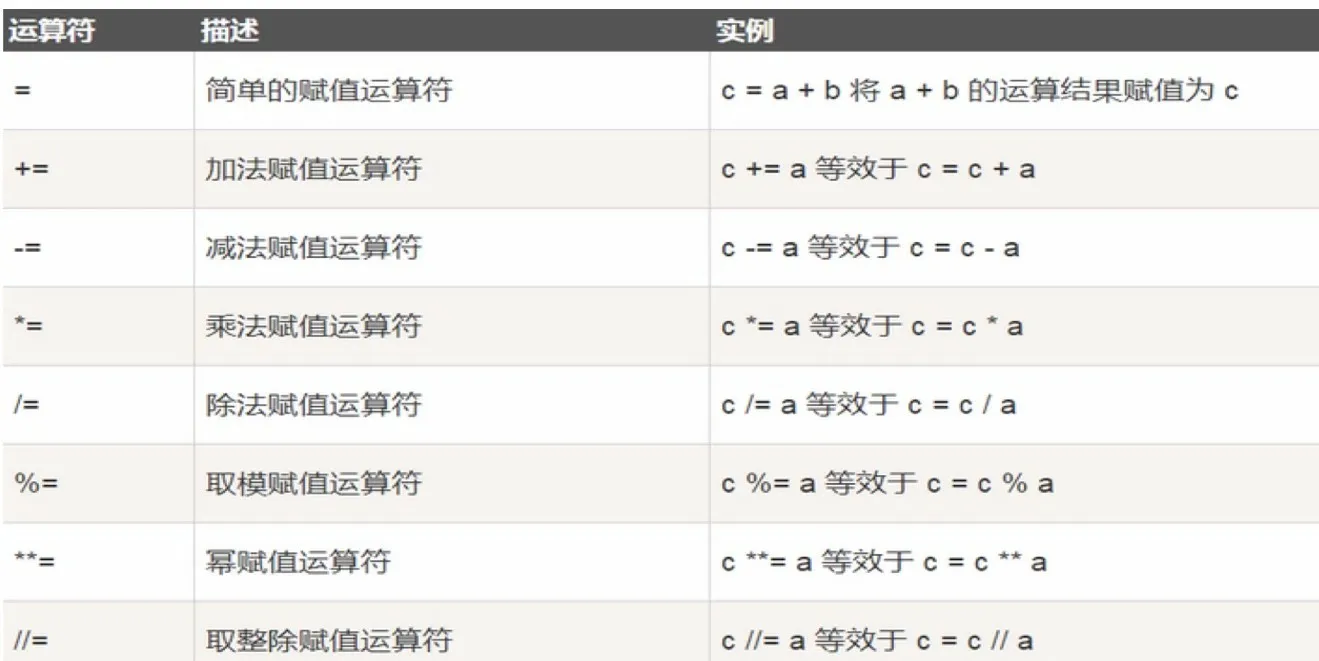
python中拼接字符串使用 +
s1 = 'hello'
s2 = 'world'
print(s1 + s2)
print(s1 * 10)
大于:>、小于:<、大于等于:>=、小于等于:<=、等于号:==、不等于:!=
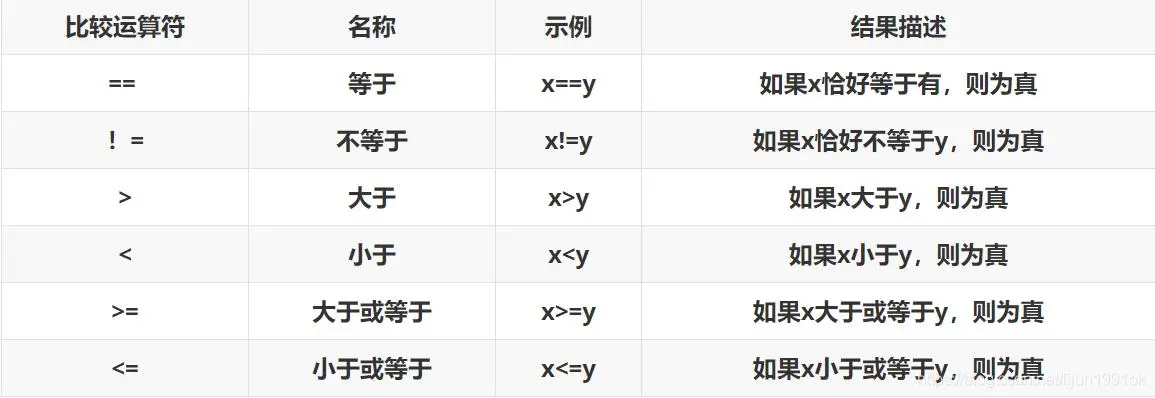
n = 666
n += 4
n -= 3
n *= 2
n /= 2
m = 10
n = 20
方式1:
y = m
m = n
n = y
方式2:
m,n = n,m
names_list = ['kevin', 'tony', 'tank', 'tom']
l1 = names_list[0]
l2 = names_list[1]
l3 = names_list[2]
l4 = names_list[3]
'''左右两边的个数必须一致'''
# ll1, ll2, ll3, ll4 = names_list
# ll1, ll2, ll3, ll4 = ['kevin', 'tony', 'tank', 'tom']
# 了解
ll1, *a, ll3, ll4 = ['kevin', 'tony', 'tank','a','b', 'tom']
# 星号的作用是用来接收多余数据给后面变量
# print(l1, l2, l3, l4)
print(ll1, a, ll4)
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
在我的Rails(2.3,Ruby1.8.7)应用程序中,我需要将字符串截断到一定长度。该字符串是unicode,在控制台中运行测试时,例如'א'.length,我意识到返回了双倍长度。我想要一个与编码无关的长度,以便对unicode字符串或latin1编码字符串进行相同的截断。我已经了解了Ruby的大部分unicode资料,但仍然有些一头雾水。应该如何解决这个问题? 最佳答案 Rails有一个返回多字节字符的mb_chars方法。试试unicode_string.mb_chars.slice(0,50)
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar