前言
作者:小蜗牛向前冲
如果觉的博主的文章还不错的话,还请
点赞,收藏,关注👀支持博主。如果发现有问题的地方欢迎❀大家在评论区指正。
目录
本期学习目标:谈谈对文件的认识,认识操纵系统的文件接口。
在平常我们对于文件的认识都是在window操纵系统下认识,我们建立的目录是文件,文本文档是文件,图片是文件。

在Linux中有这么一句话:Linux下一切皆文件。
为什么这么说的呢?
Linux中所有的内容都是以文件的形式保存的,我们认为普通文件是文件,一个目录我们也称为文件,甚至认为硬件设备(键盘,硬盘,打印机等)是文件。
Linux有一个根目录,其他的所以的文件都放在根目录中。
普通文件

直接就可以使用的我们就称为普通文件,如上面的makefile就是一个普通文件
目录文件

这个目录中包含各个文件的文件名和文件及其指向这些文件的指针,只要有权限就可以访问目录中的任何文件,上面的myshell就是一个目录文件,一个目录不仅仅有目录名,还有一些权限设置、文件大小等。
其他的一些文件类型:字符设备文件和块设文件、套接字文件(socket)、符号链接文件(symbolic link)、管道文件(pipe)。
- 空文件,也要在磁盘中占据空间。
- 文件 = 内容 +属性。
- 文件操纵 = 对内容 + 对属性.
- 如果没有指明对应的文件的路径,和默认当前路径。
- 当我们通过fopen,fclose,fwrite,fread对文件进行操纵的时候,编译代码,形成可执行的程序,但是不运行,对于的文件操纵执行了吗?没有(对文件的操纵,本质上是进程对文件的操纵)。
- 一个文件没有被打开,可以直接进行文件的访问吗?不能
通过上面的共识我们可以得出,对文件的操纵的本质 :是进程和打开文件的关系。
我们在C语言和C++都有对文件的操纵函数,我们都知道文件是存放在磁盘上的,而要想访问文件就必须将磁盘上的文件导入到内存中,在进行相应的操作,其实本质上是操作系统在对这些文件进行管理,而C语言和C++中对文件的操作的接口,他底层也是操作系统对文件操作的接口,只是通过了封装了而已。
文件打开open

头文件:<sys/types.h>、 <sys/stat.h>、<fcntl.h>
访问形式:
1、int open(const char *pathname, int flags);
2、int open(const char *pathname, int flags, mode_t mode);
当我们要调用open接口就必须包含相应的头文件,但这里要注意的是这里接口为我们提供了二个调用的方式,方式1是文件已经存在我们调用,方式2是文件不存在时要调用的接口。
接口参数:
const char *pathname:这里就指我们要打开的文件名
int flags:指的是标记位,传过来的比特位,不同的比特位就调用不同选项,从对文件进行一些初始化。
mode_t mode:这里是设置相应的权限(如操作系统默认的普通文件的权限是0x666)
这里我们要重点了解open接口的第二个参数,上面我们说他是一个标记位 ,我们知道一个int是有32个比特位了,这里我们用每个比特位表示不同的选项。
下面我们看一段代码理解一下:
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <assert.h>
// 每一个宏,对应的数值,只有一个比特位是1,彼此位置不重叠
#define ONE (1<<0)
#define TWO (1<<1)
#define THREE (1<<2)
#define FOUR (1<<3)
void show(int flags)
{
if(flags & ONE) printf("one\n");
if(flags & TWO) printf("two\n");
if(flags & THREE) printf("three\n");
if(flags & FOUR) printf("four\n");
}
int main()
{
show(ONE);
printf("-----------------------\n");
show(TWO);
printf("-----------------------\n");
show(ONE | TWO);
printf("-----------------------\n");
show(ONE | TWO | THREE);
printf("-----------------------\n");
show(ONE | TWO | THREE | FOUR);
printf("-----------------------\n");
return 0;
} 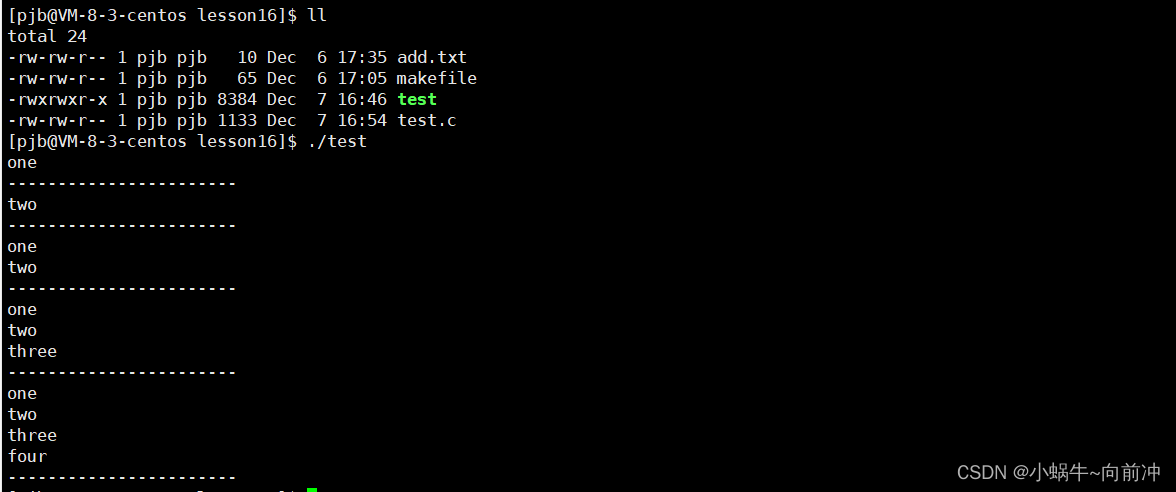
当我们运行代码,就会发现我们通过不同的比特位就调用了不同的参数选项,展现出现不同的效果。
flags多个选项:
- O_RDONLY: 只读打开
- O_WRONLY: 只写打开
- O_RDWR : 读,写打开
- 这三个常量,必须指定一个且只能指定一个
- O_CREAT : 若文件不存在,则创建它。需要使用mode选项,来指明新文件的访问权
- O_APPEND: 追加写
- O_TRUNC:如果文件已经存在,且成功打开,则删除文件中原来的全部数据
对于这些选项我们还可以进行功能的多选,选项间用 “ | ” 分割
O_RDONY | O_CREAT//这里的文件用只读的方式创建,如果没有这个文件会自动创建返回值
- 成功:新打开的文件描述符(fd)
- 失败:-1
文件关闭 close

文件关闭接口用起来非常简单,只要给他传打开文件的文件描述符就可以了。
read读文件

函数原型:
ssize_t read(int fd, void *buf, size_t count);
参数
- fd:是文描述符
- buf:接收读取数据的缓存区
- count:读取的字节数
- 返回值:读取成功则返回读取的字节数,读取到文件尾则返回0,读取失败则返回-1,同时设置全局变量errno的值来表示错误原因;
write写文件

函数原型:
ssize_t write(int fd, const void *buf, size_t count);
参数:
- fd:是文描述符
- buf:存放写入数据的缓存区
- count:写入的的字节数
- 返回值:写入成功则返回实际写入的字节数,写入失败则返回-1,同时设置全局变量errno的值来表示错误原因;
下面为了更好的理解文件操作,为了大家演示了文件的打开,写入和读取数据,最后在关闭。
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
//定义文件名
char filename[] = "pjb.txt";
//定义写入的数据
char write_data[] = "hellow Linux!";
//读取的数据
char read_buf[64] = { 0 };
//测试写入数据
int fd = open(filename, O_RDWR | O_CREAT, O664);
if (fd < 0)
{
perror("open");
return -1;
}
//写入内容
int ret = write(fd, write_data, sizeof(write_data));
if (ret < 0)
{
perror("write");
return -1;
}
else
{
printf("write: %s\n", write_data);
}
//关闭文件
close(fd);
//测试写入文件
fd = open(filename, O_RDONLY);;
if (fd < 0)
{
perror("open");
return -1;
}
//写入
ret = read(fd, read_buf, sizeof(read_buf));
if (ret < 0)
{
perror("read");
return -1;
}
else
{
printf("read: %s\n", read_buf);
}
close(fd);
return 0;
}
这里观察到我们成功向文件中写入和向文件中读取数据。
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A