文章目录
黑马程序员Spark全套视频教程,4天spark3.2快速入门到精通,基于Python语言的spark教程





学习目标:
1.[了解]Spark诞生背景
2.[了解]Saprk的应用场景
3.[掌握]Spark环境的搭建
4.[掌握]Spark的入门案例
5.[了解]Spark的基本原理
第一章:Spark框架概述
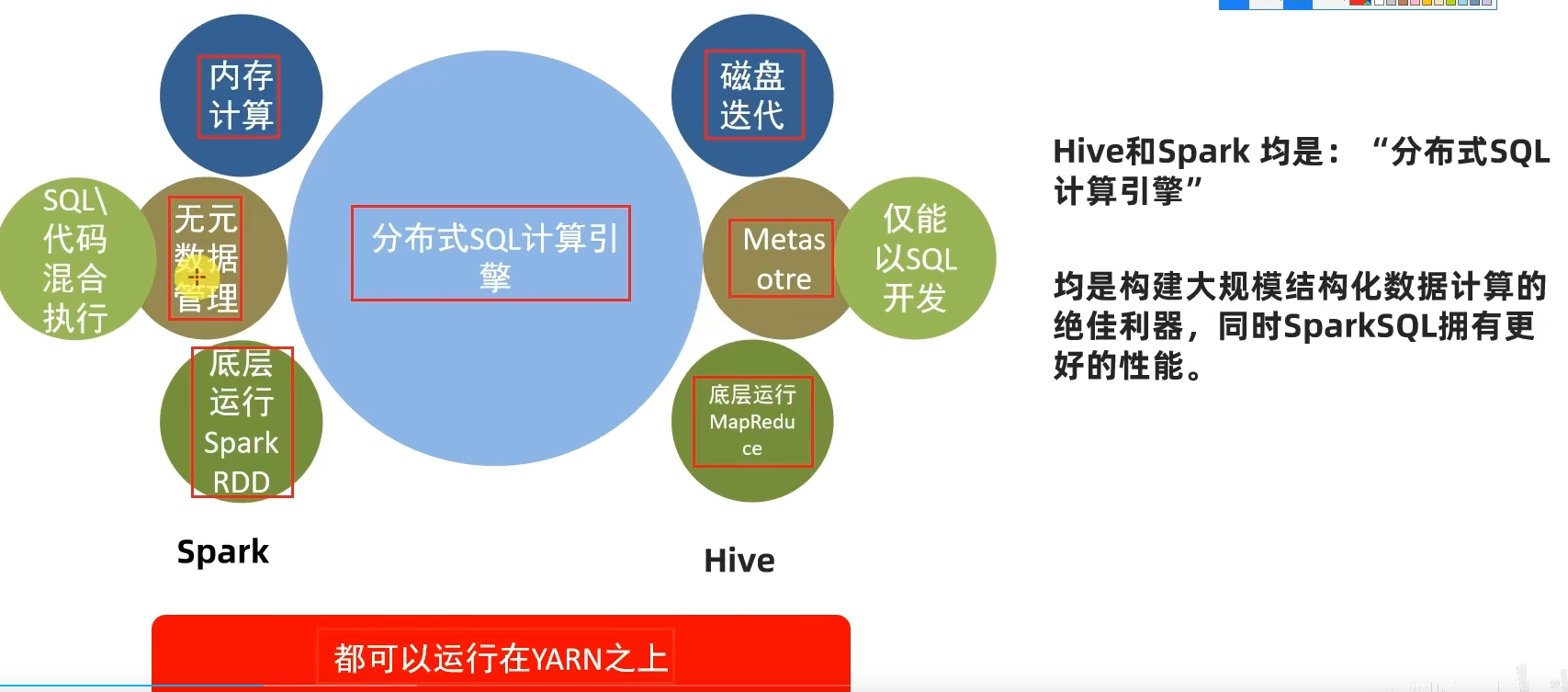
1.1 Spark是什么
定义:Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。
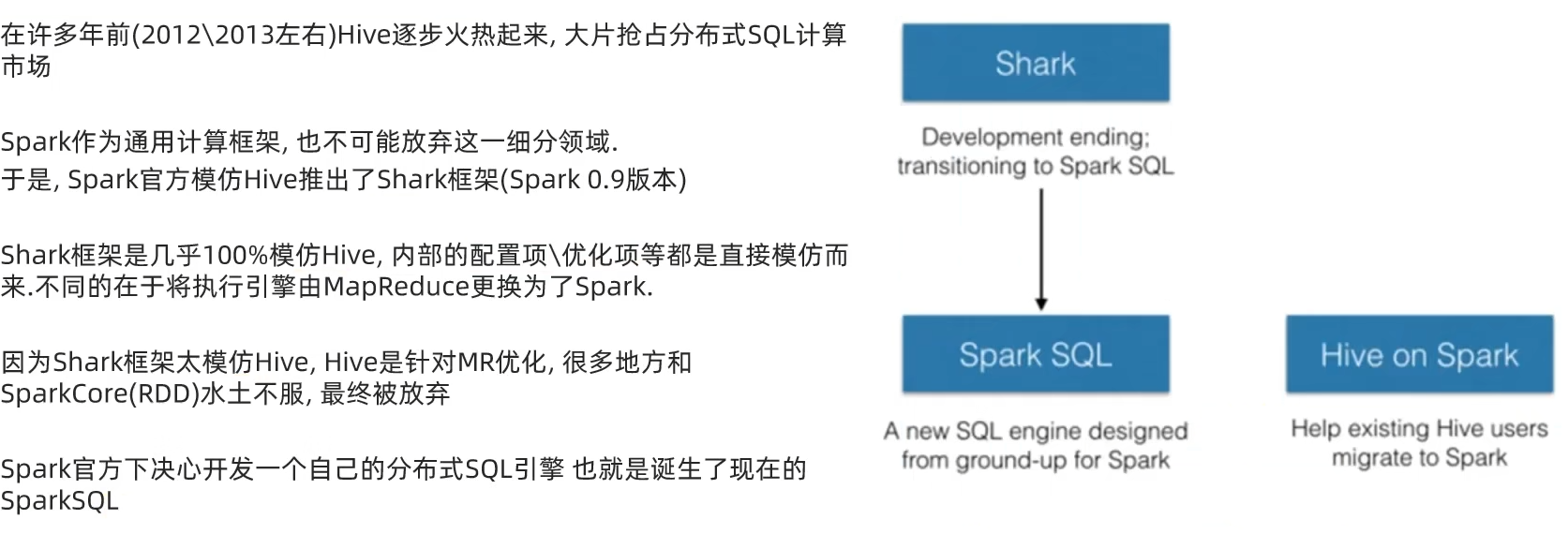
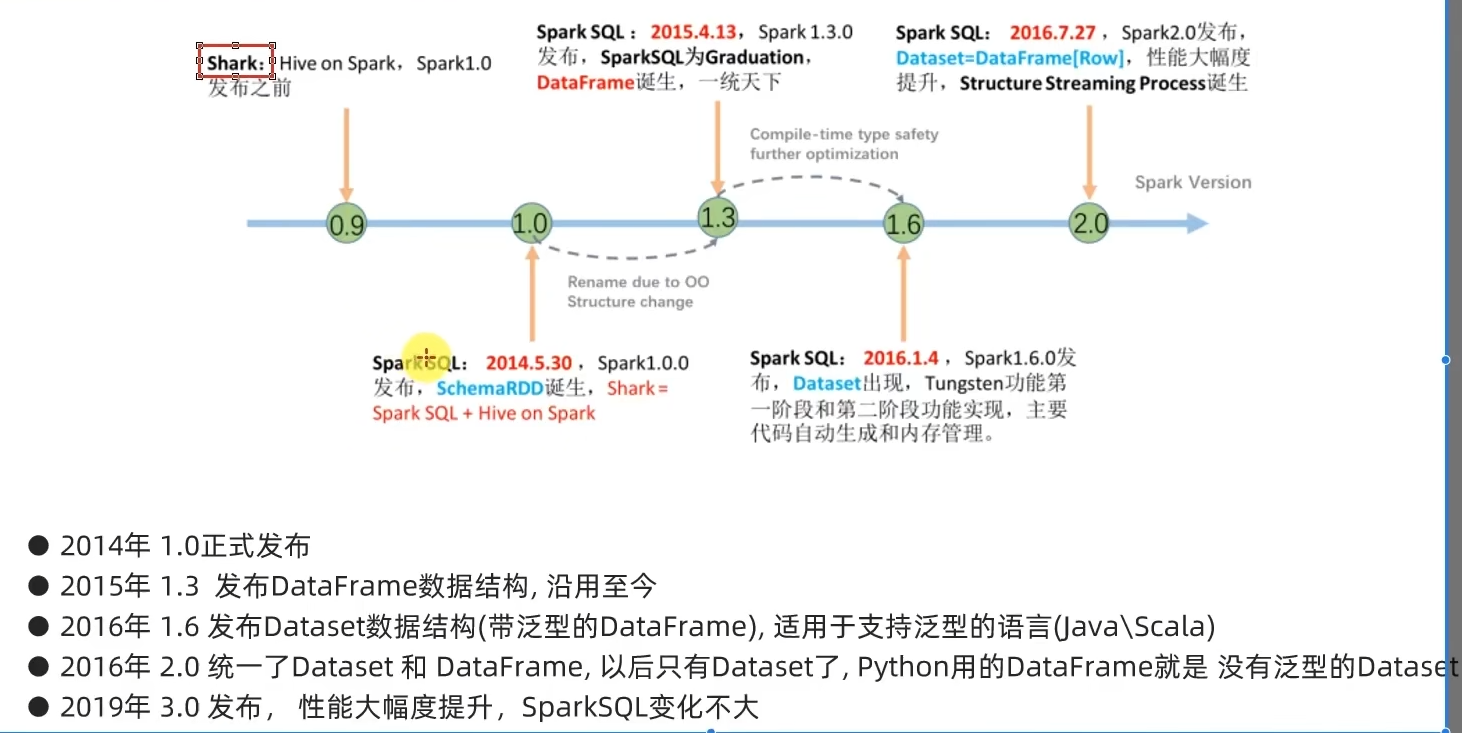
1.2 Spark风雨十年
1.3 扩展阅读:Spark VS Hadoop
1.4 Spark四大特点
1.5 Spark框架模型-了解
1.6 Spark运行模式
1.7 Spark架构角色
Spark解决什么问题?
Spark有哪些模块?
Spark特点有哪些?
Spark的运行模式?
本地模式(Local模式,在一个
集群模式(StandAlone、YARN、K8S)
云模式
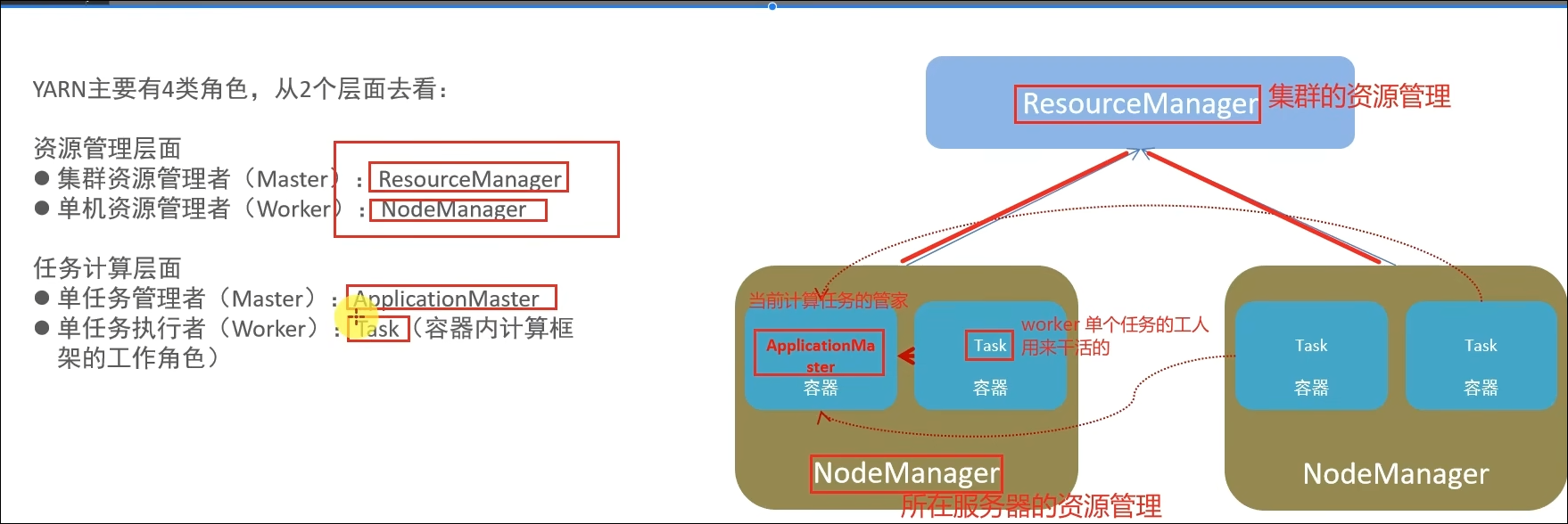
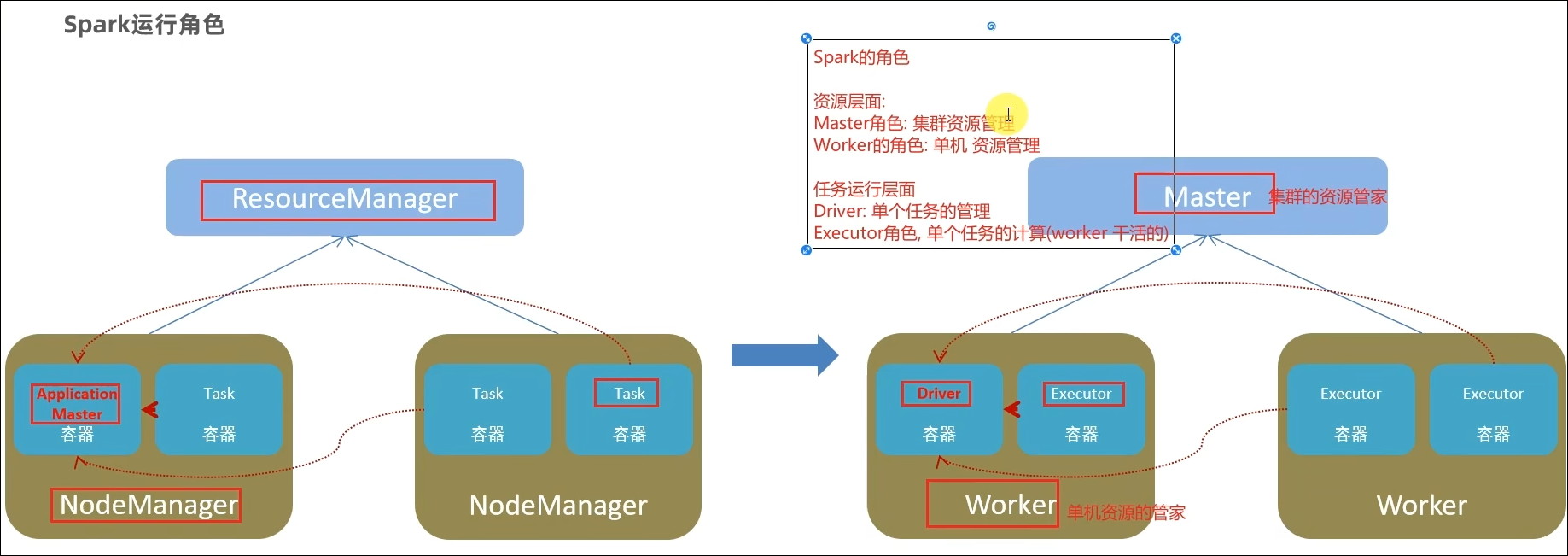
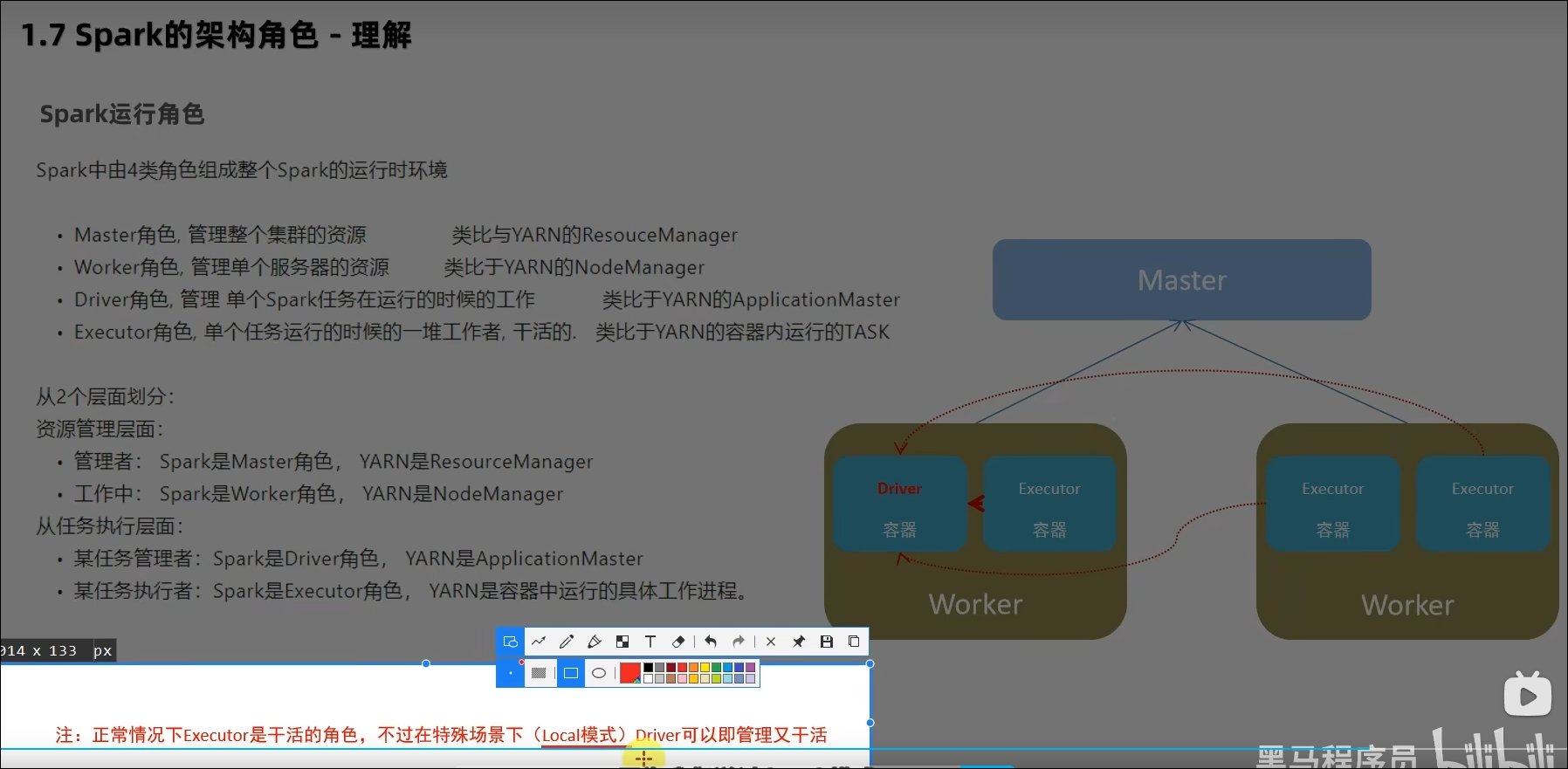
Spark的运行角色(对比YARN)?
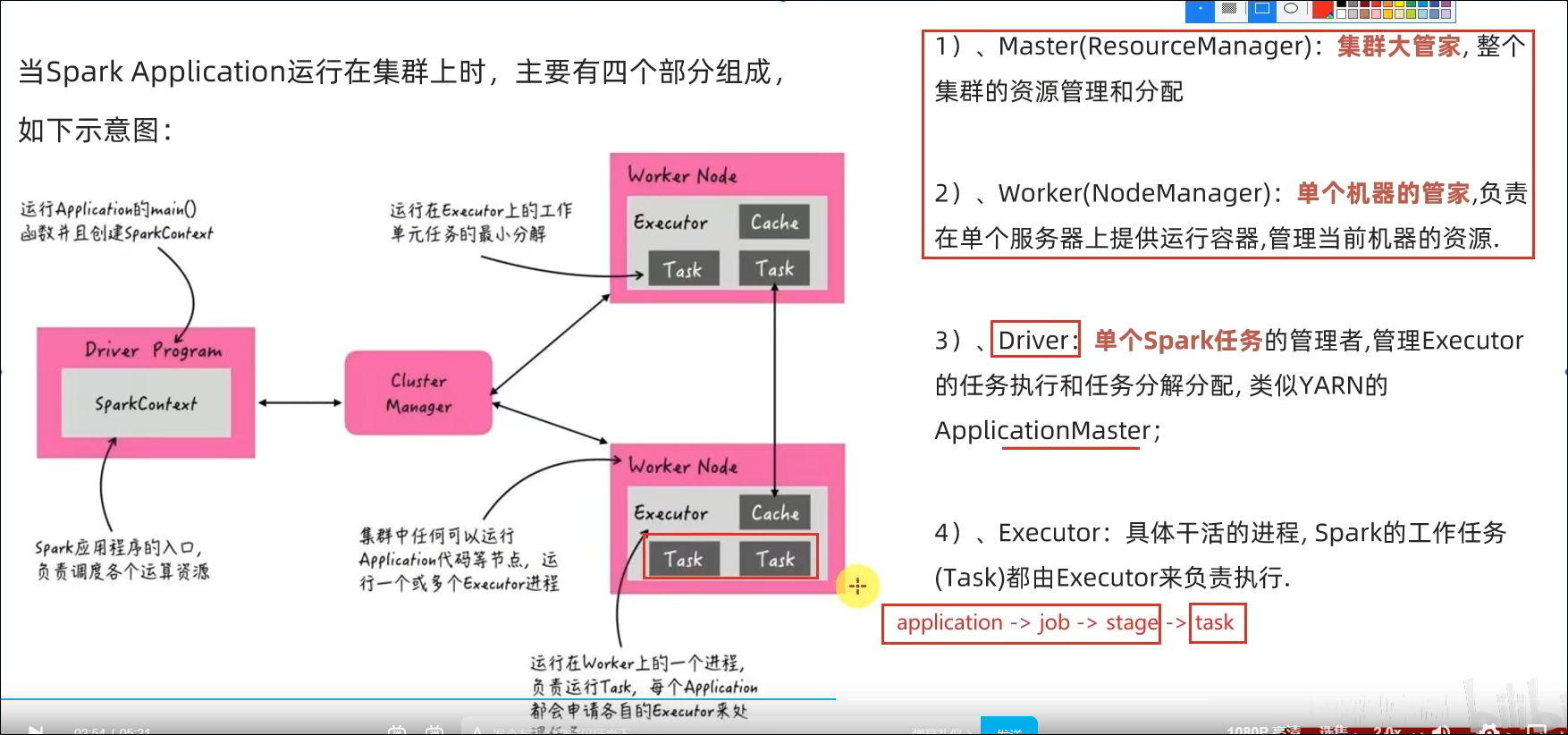
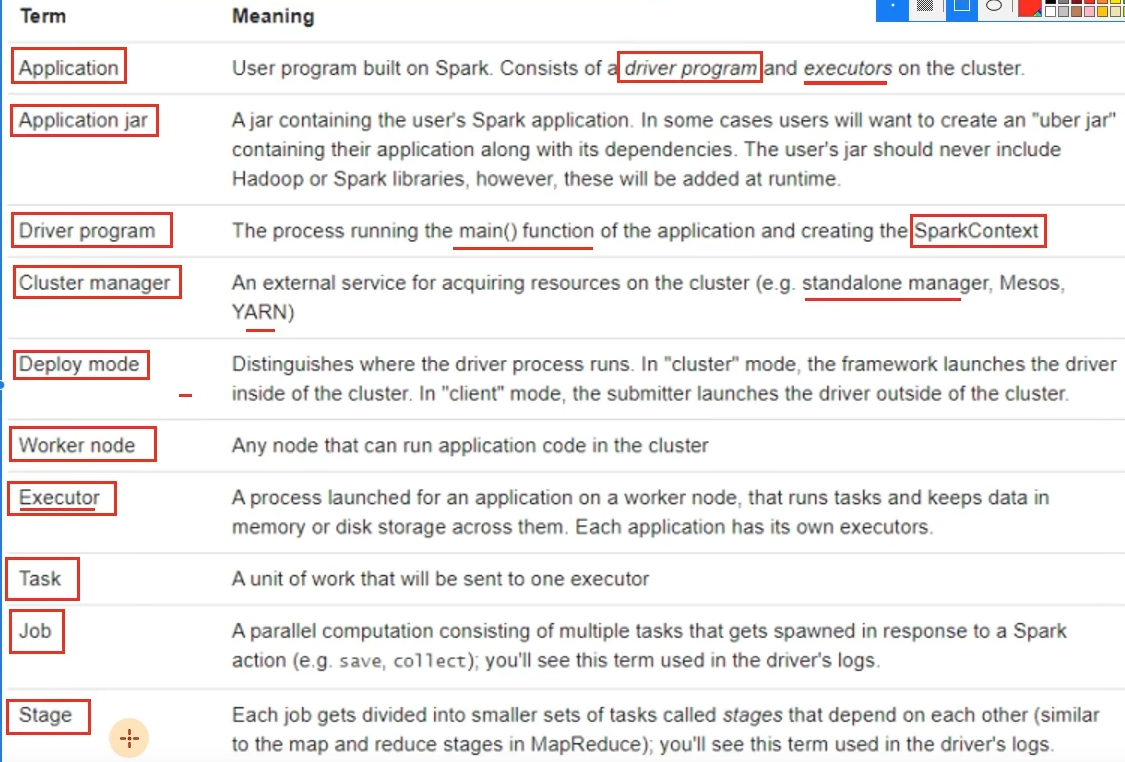
Master:集群资源管理(类同ResourceManager)
Worker:单机资源管理(类同NodeManager)
Driver:单任务管理者(类同ApplicationMaster)
Executor:单任务执行者(类同YARN容器内的Task)


PS:软连接与硬链接,参考资料:https://www.bilibili.com/video/BV1CZ4y1v7SR/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=c1627e67b359df87544f502955497bf7
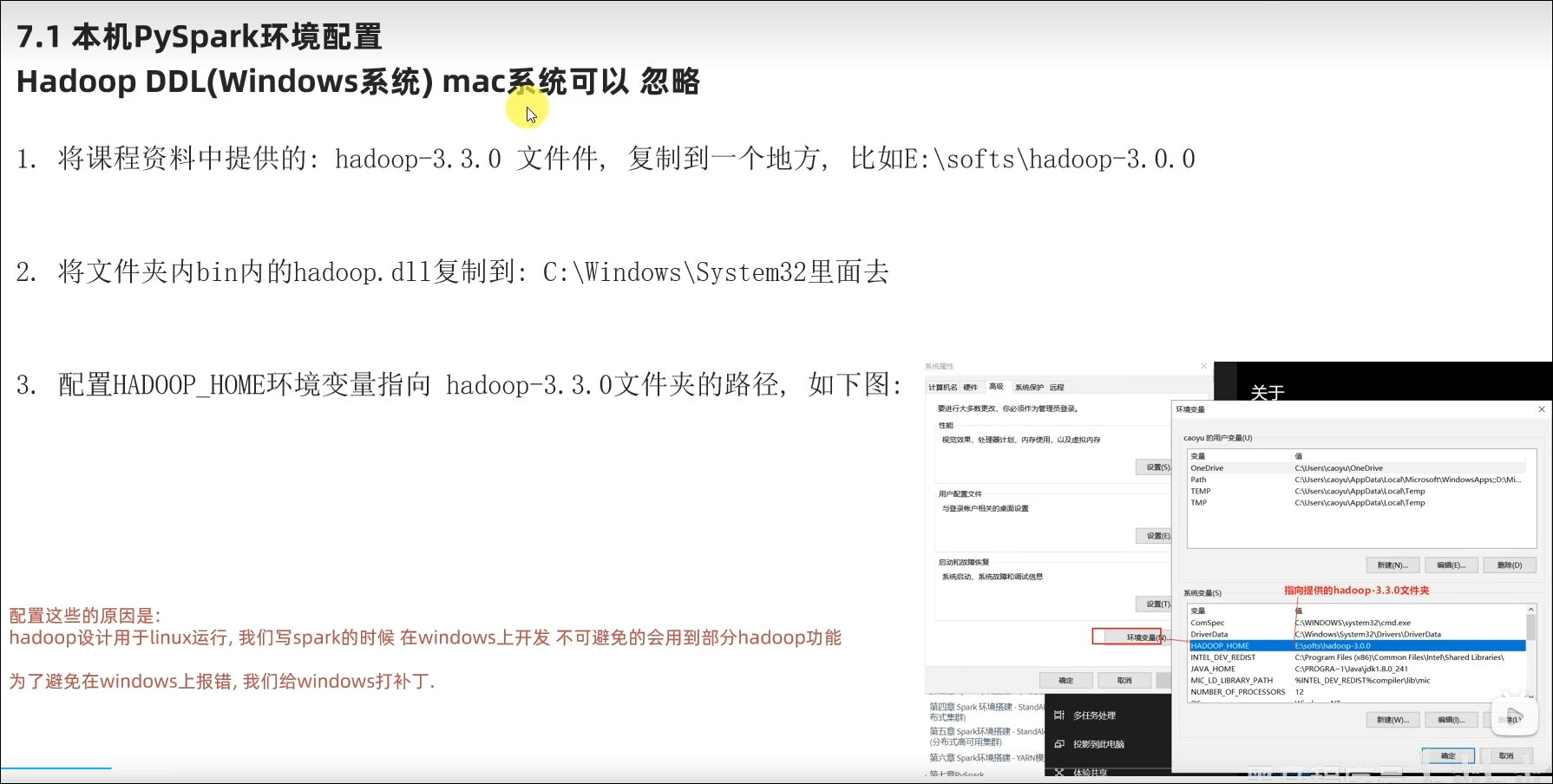
配置环境变量:

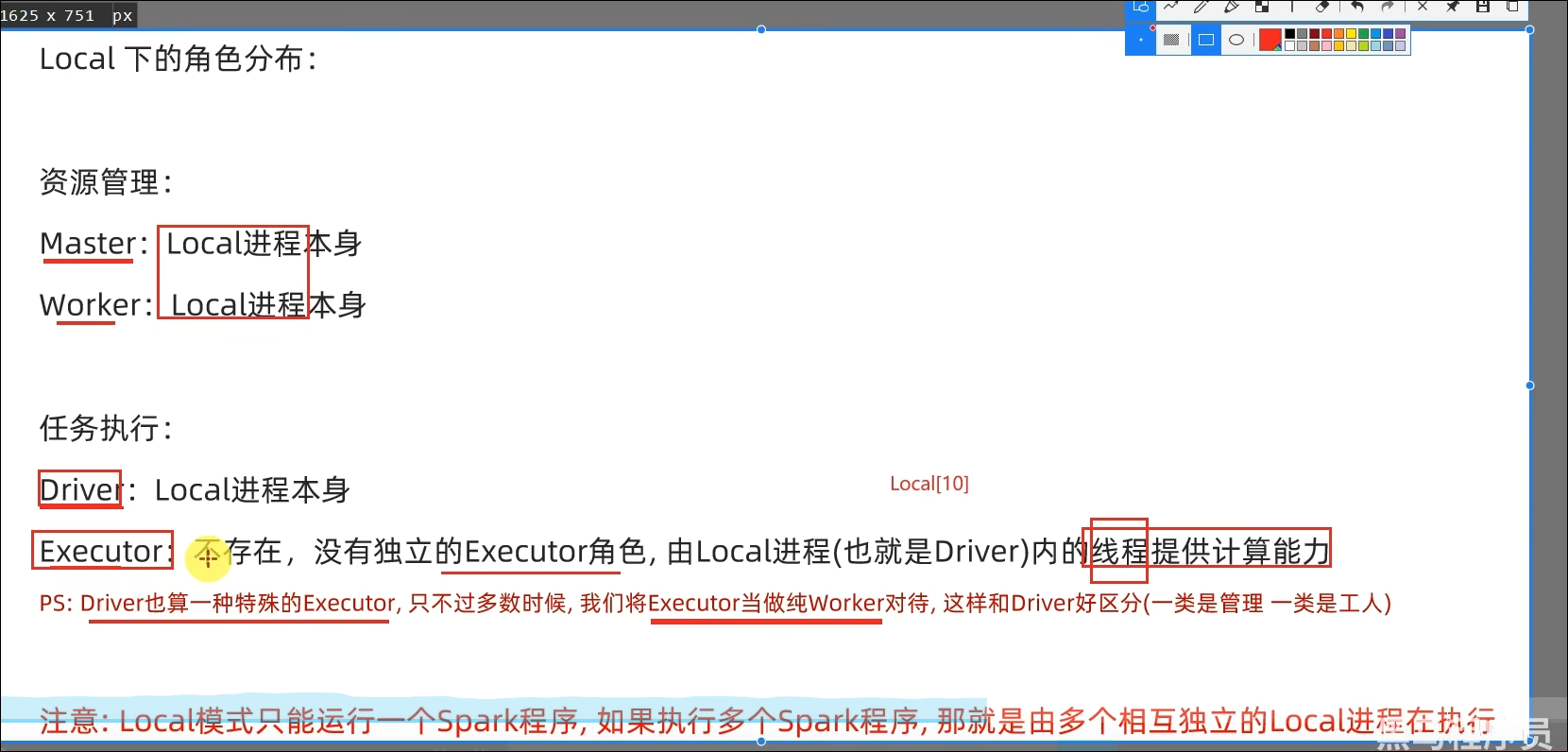
Local模式就是以一个独立进程配合其内部线程来提供完成Spark运行时环境。Local模式可以通过spark-shell/pyspark/spark-submit等来开启。
是一个交互式的解释器执行环境,环境启动后就得到了一个Local Spark环境,可以运行Python代码去进行Spark计算,类似Python自带解释器。
Spark的任务在运行后,会在Driver所在机器绑定到4040端口,提供当前任务的监控页面供查看。
PS:如果有多个Local模式下的Spark任务在一台机器上执行,则绑定的端口会依次顺延。
详看视频



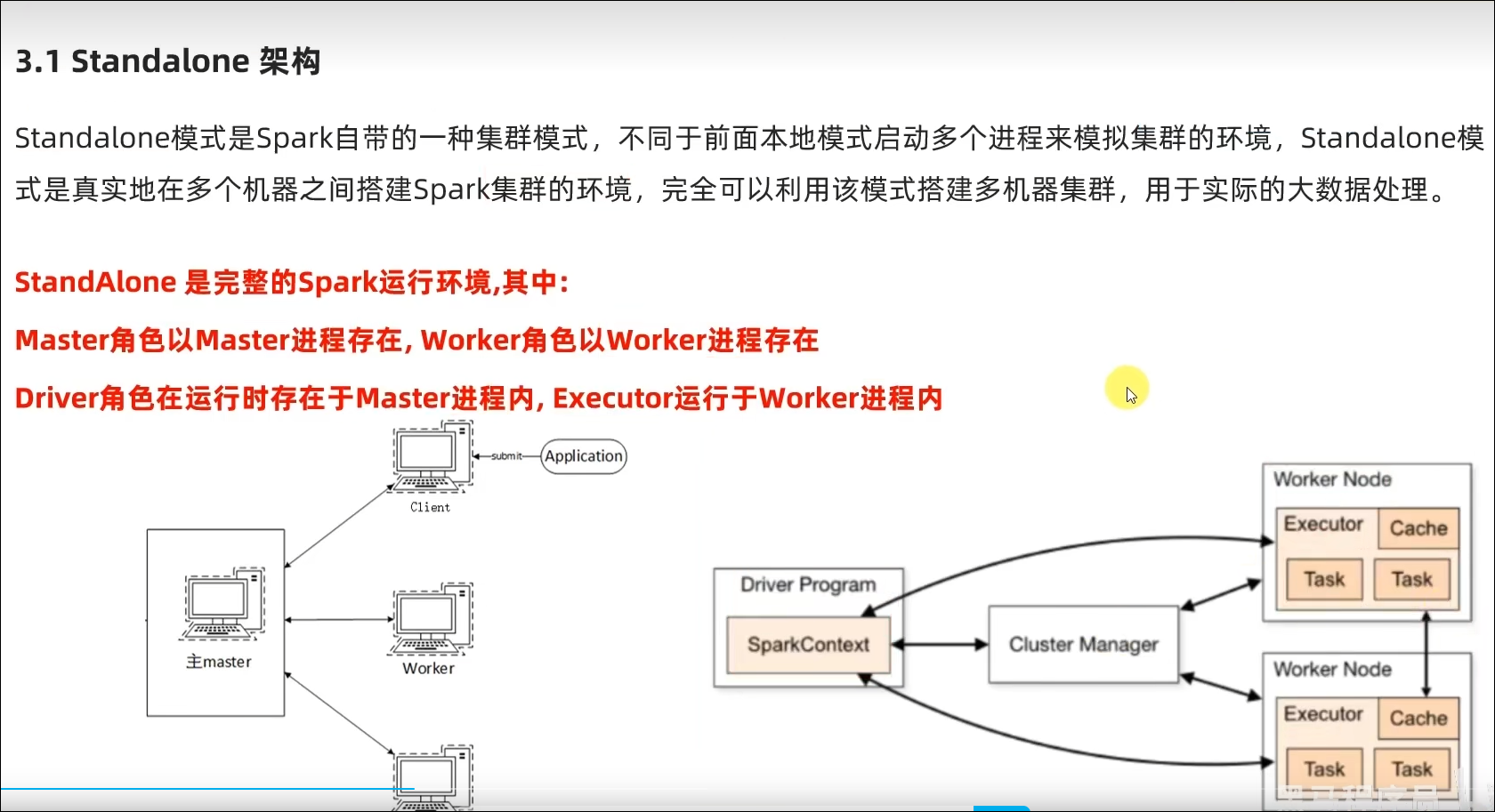
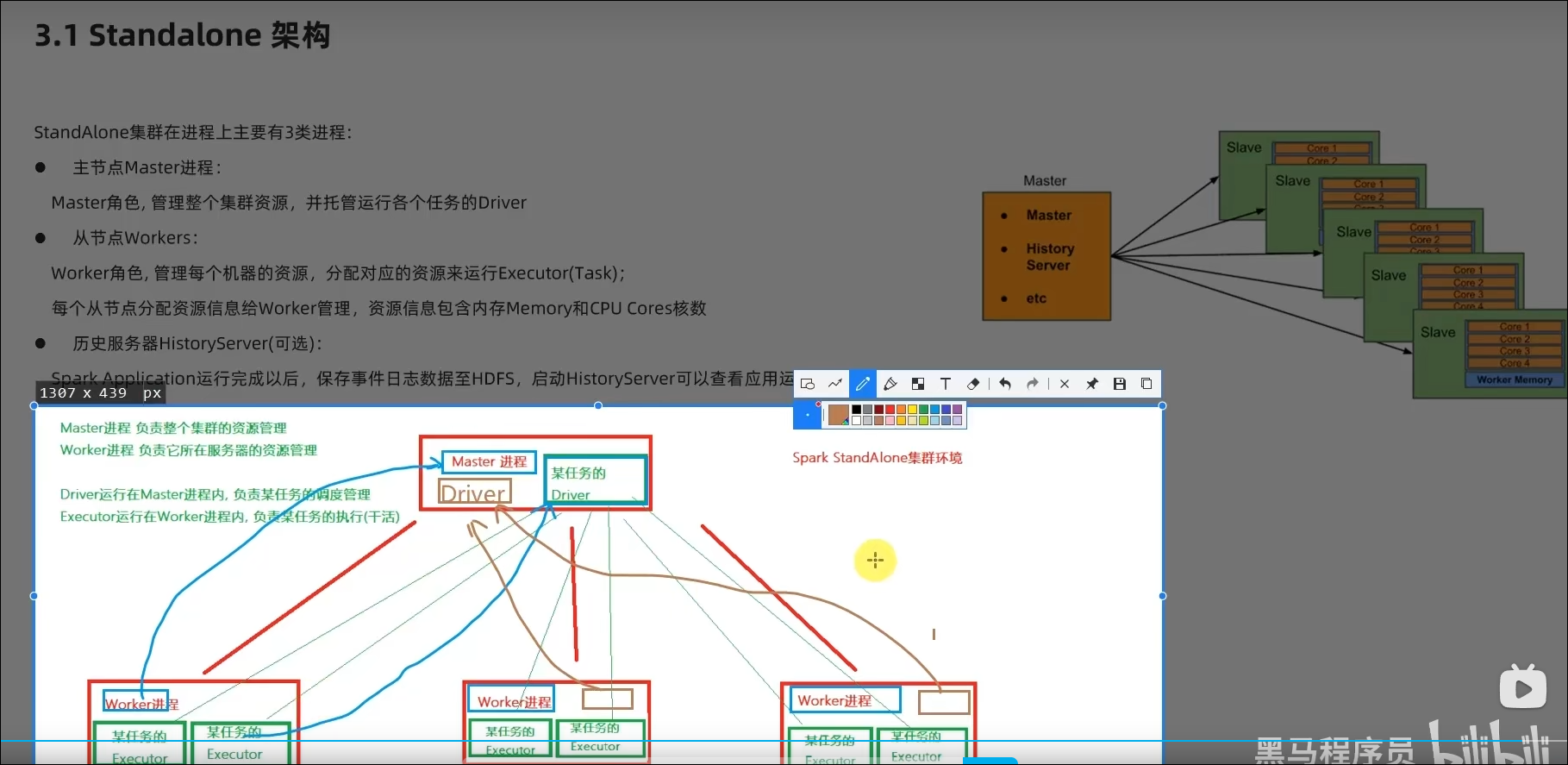
Master和Worker角色以独立进程的形式存在,并组成Spark运行时环境(集群)
Master角色:Master进程
Worker角色:Worker进程
Driver角色:以线程运行在Master中
Executor角色:以线程运行在Worker中
bin/spark-submit --master spark://server:7077
4040是单个程序运行的时候绑定的端口可供查看本任务运行情况(4040和Driver绑定,也和Spark的应用程序绑定)。
8080是Master运行的时候默认的WebUI端口(Master进程是守护进程)。
18080是Spark历史服务器的端口,可供我们查看历史运行程序的运行状态。
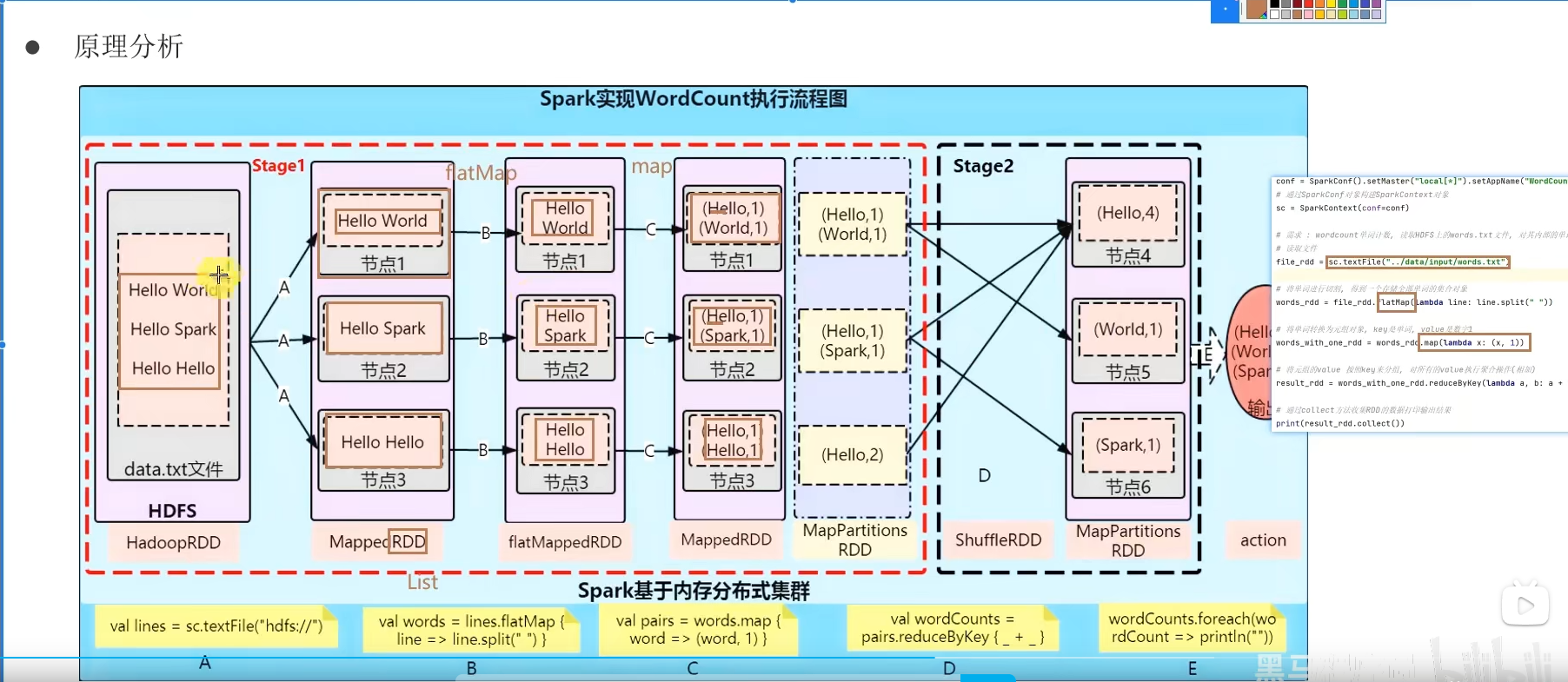
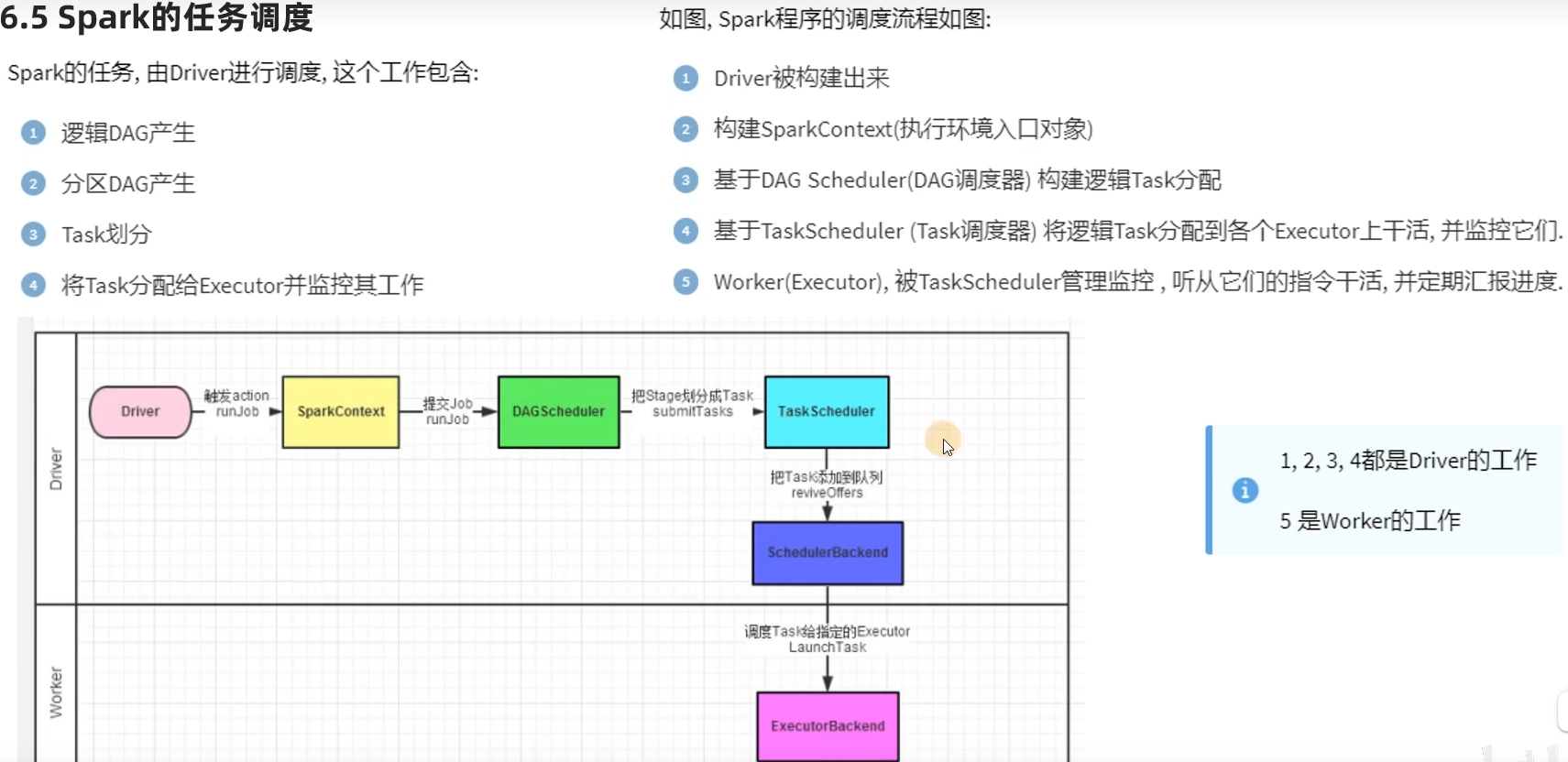
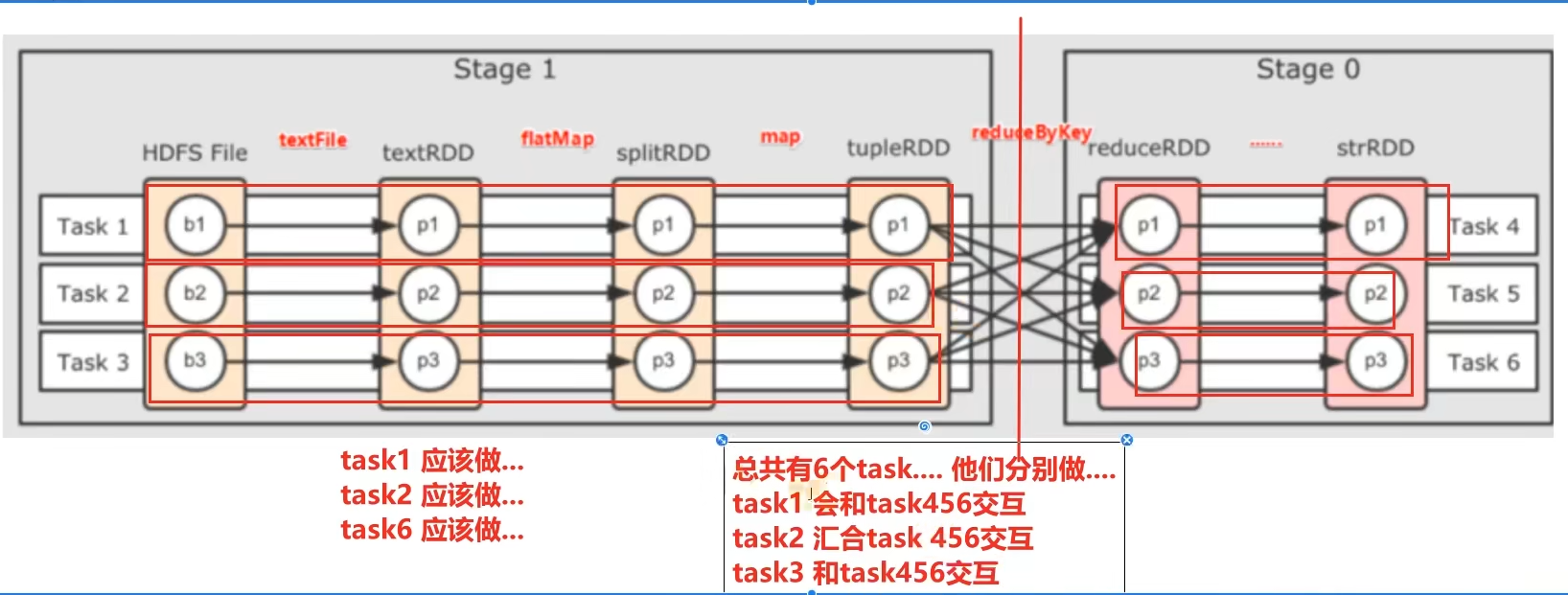
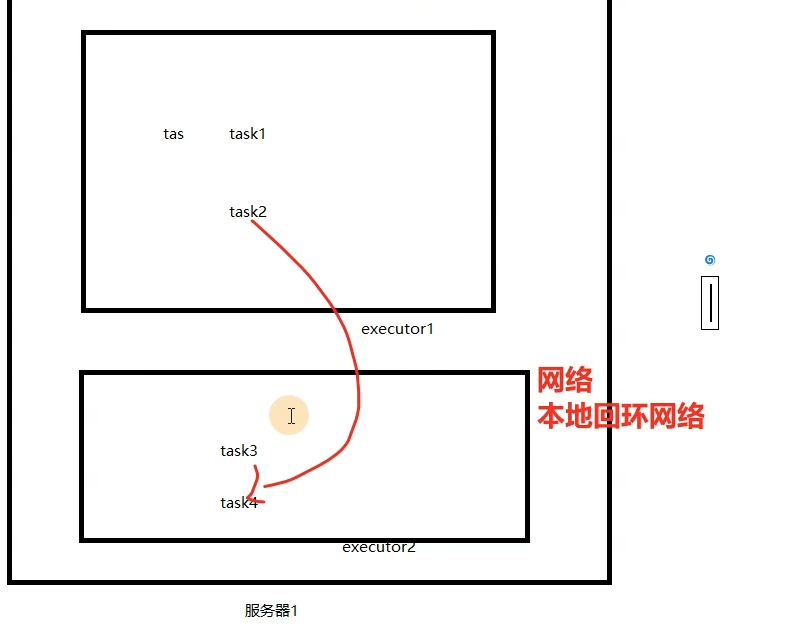
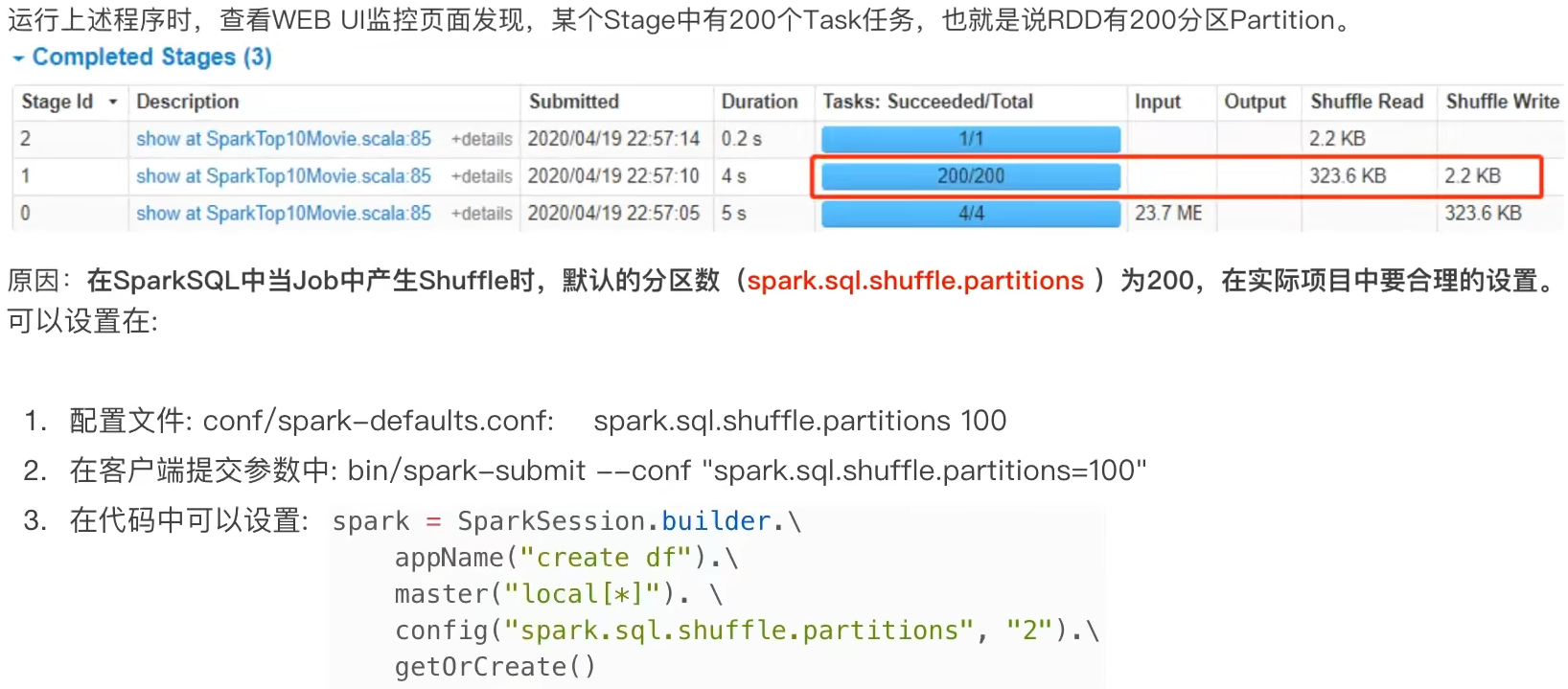
一个Spark应用程序会被分成多个子任务(Job)运行,每一个Job会分成多个Stage(阶段)来运行,每一个Stage内会分出来多个Task(线程)来执行具体任务。
Spark Standalone集群存在Master单点故障(SPOF)的问题。
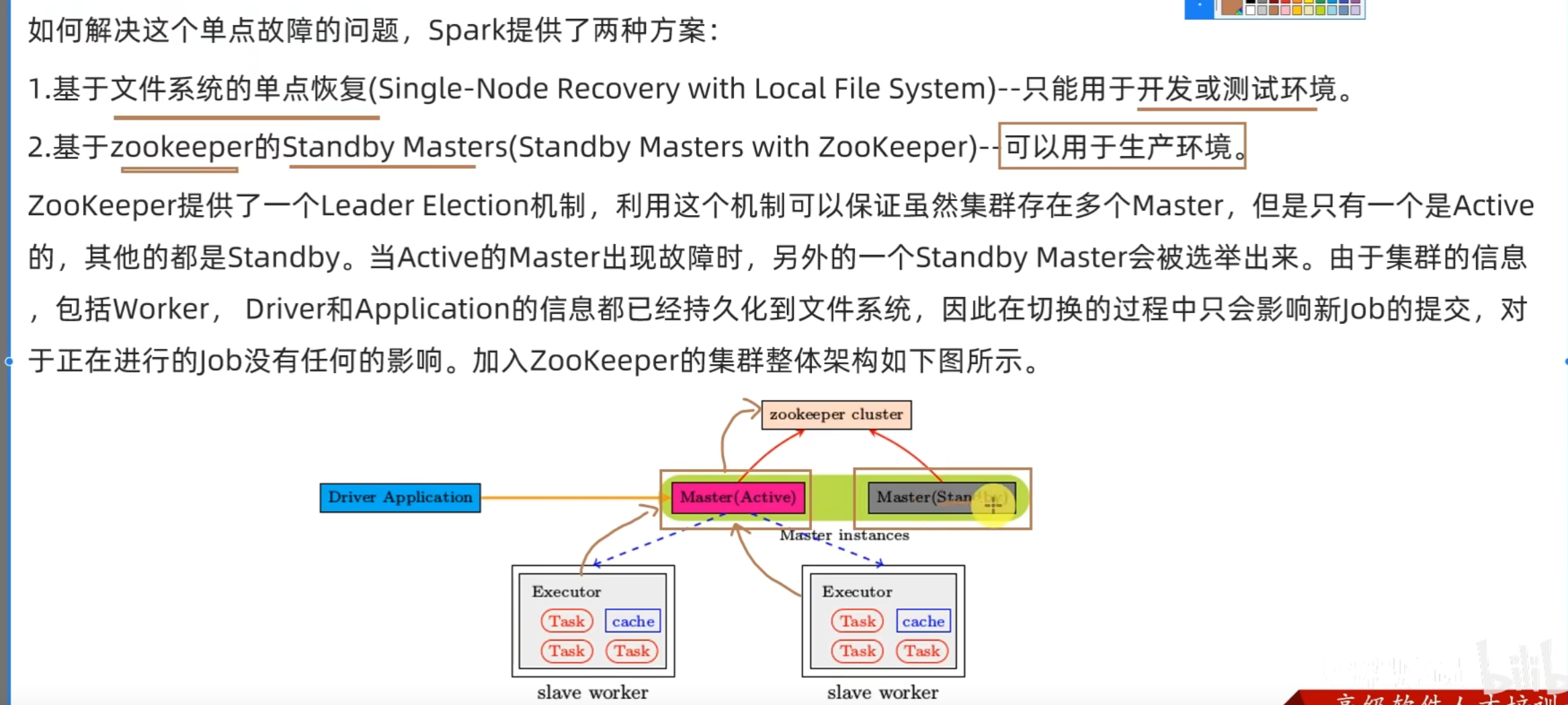
基于Zookeeper做状态的维护,开启多个Master进程,一个作为活跃,其他的作为备份,当活跃进程宕机,备份的Master进行接管。


详见视频
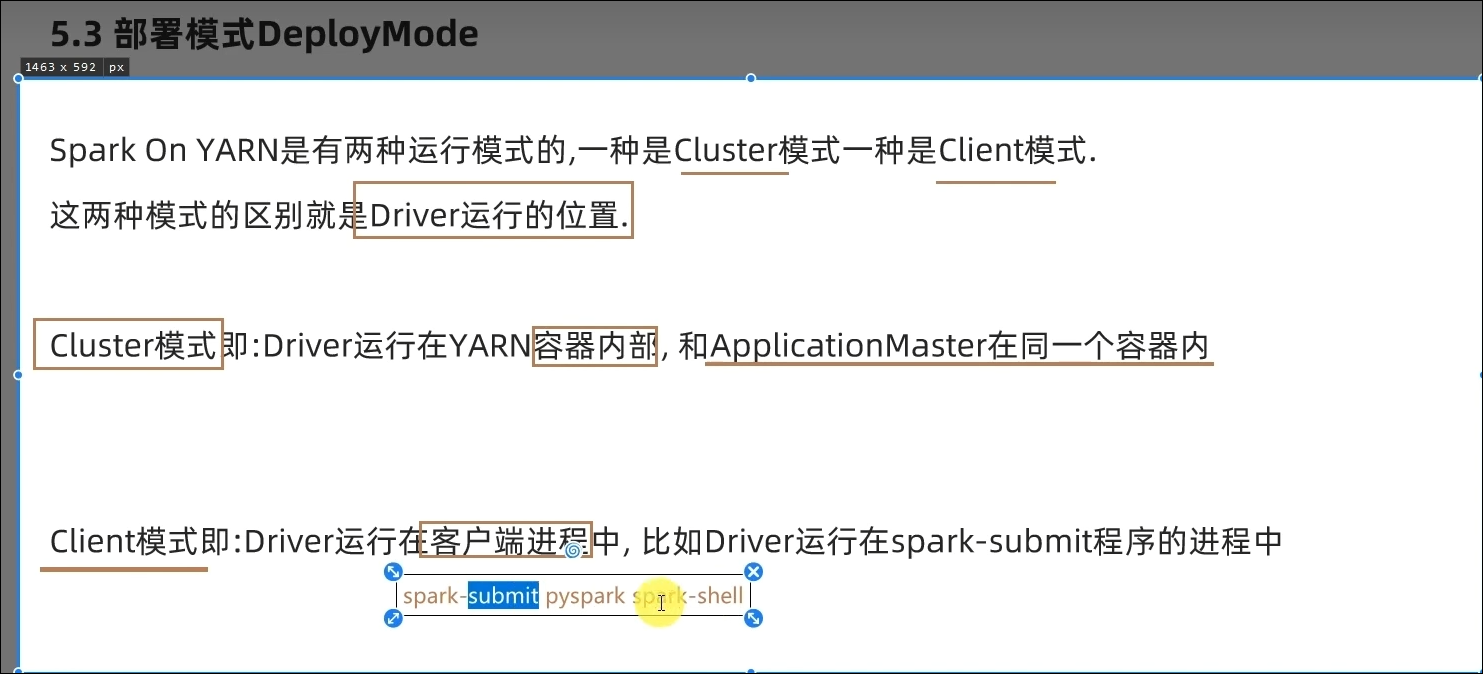
Cluster模式
bin/spark-submit --master yarn --deploy-mode cluster --driver-memory 512m --executor-memory 512m --num-executors 3 --total-executor-cores 3 /export/server/spark/examples/src/main/python/pi.py 100
需要通过下面命令打开Yarn的历史服务器(JobHistoryServer)
mapred --daemon start historyserver
Client模式
bin/spark-submit --master yarn --deploy-mode client --driver-memory 512m --executor-memory 512m --num-executors 3 --total-executor-cores 3 /export/server/spark/examples/src/main/python/pi.py 100

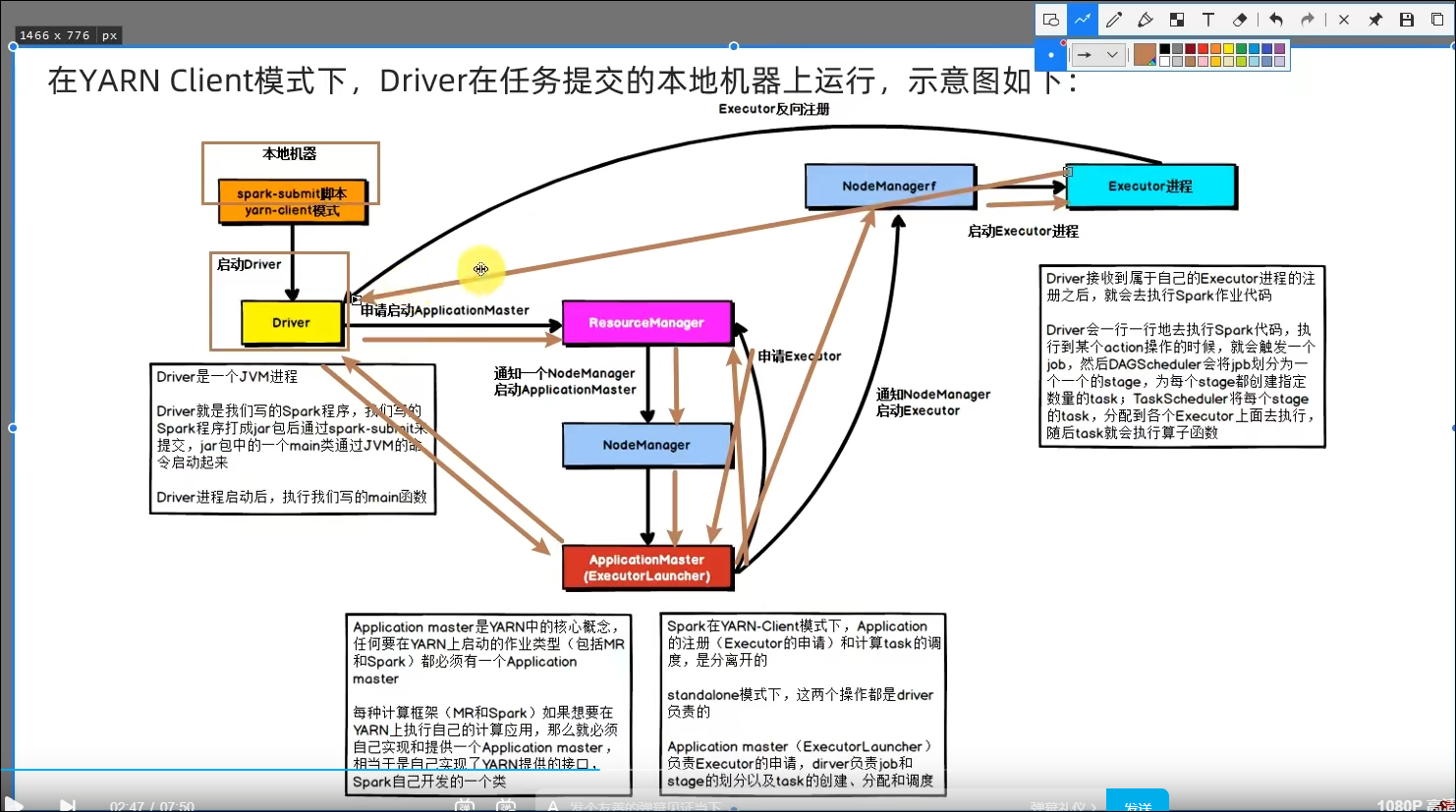
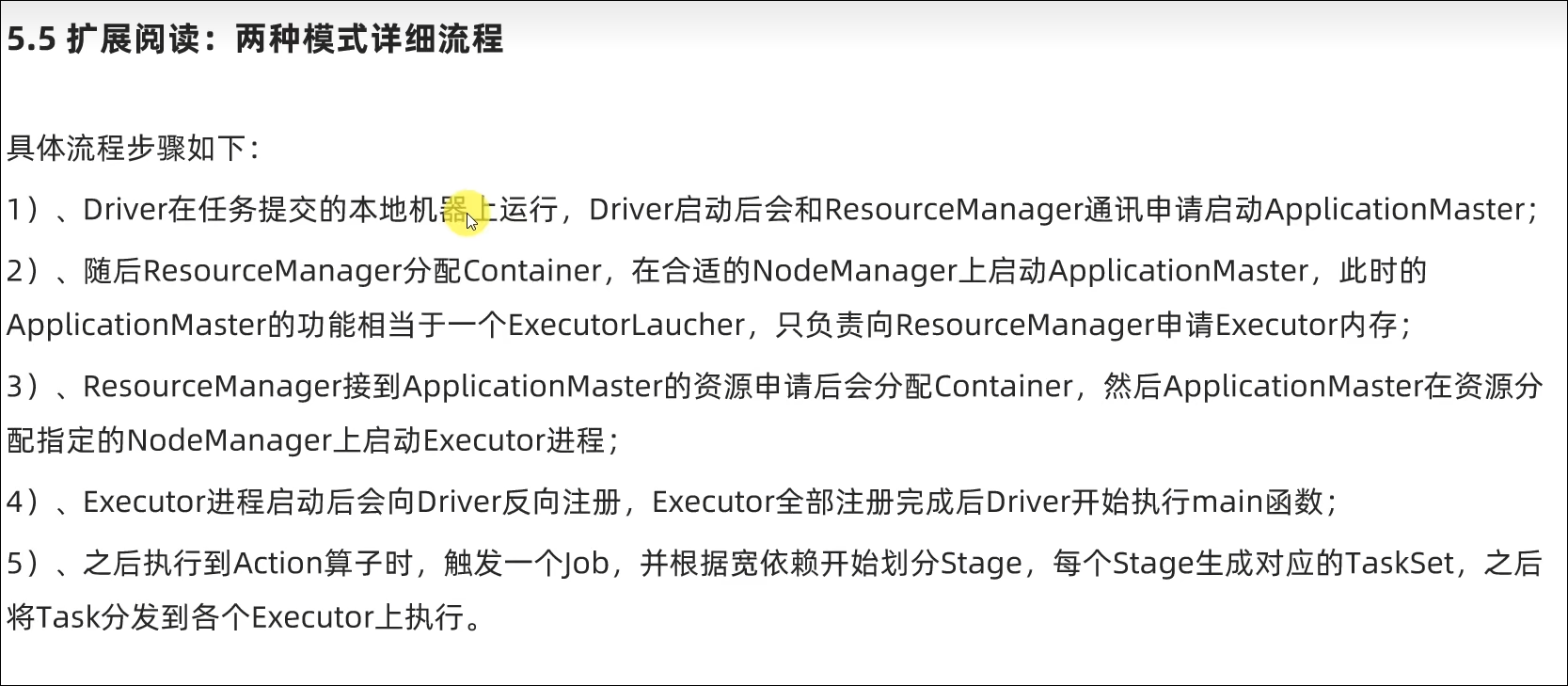
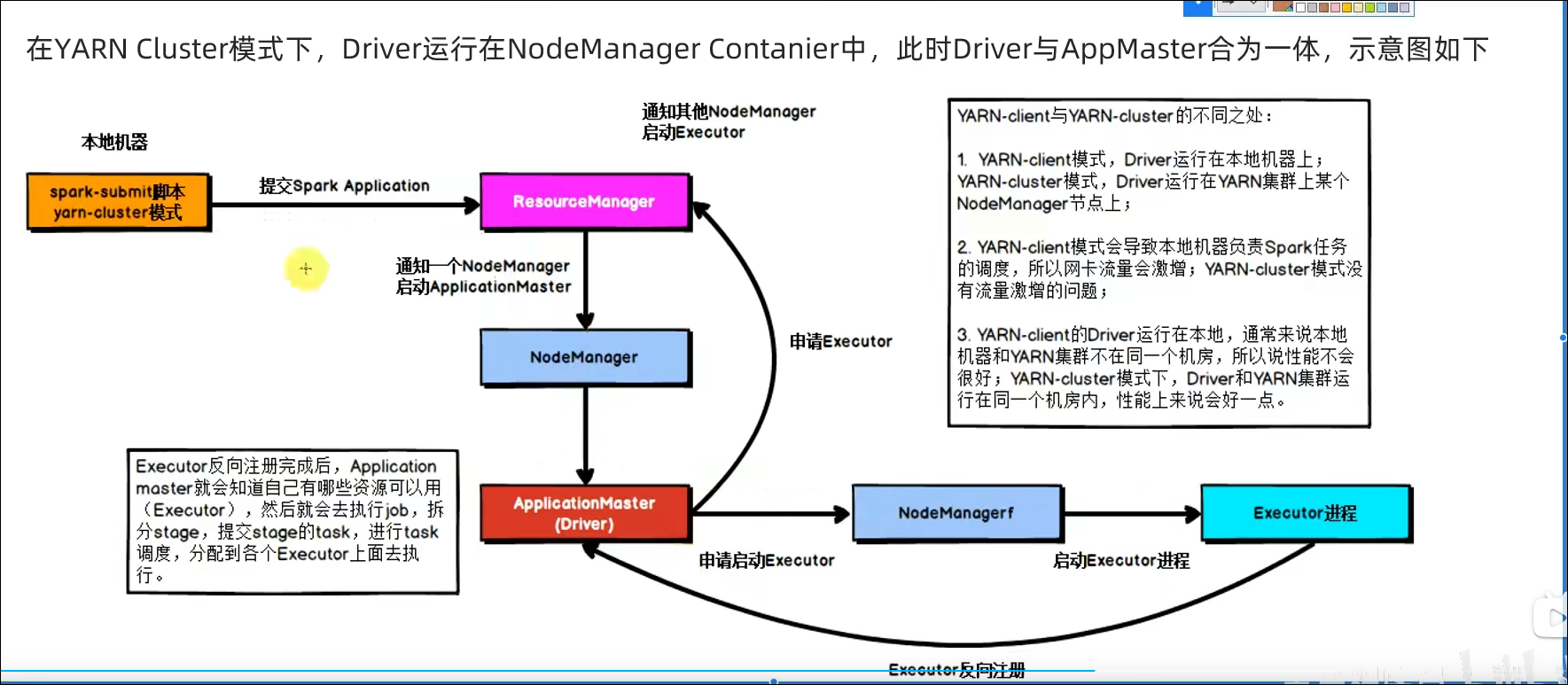
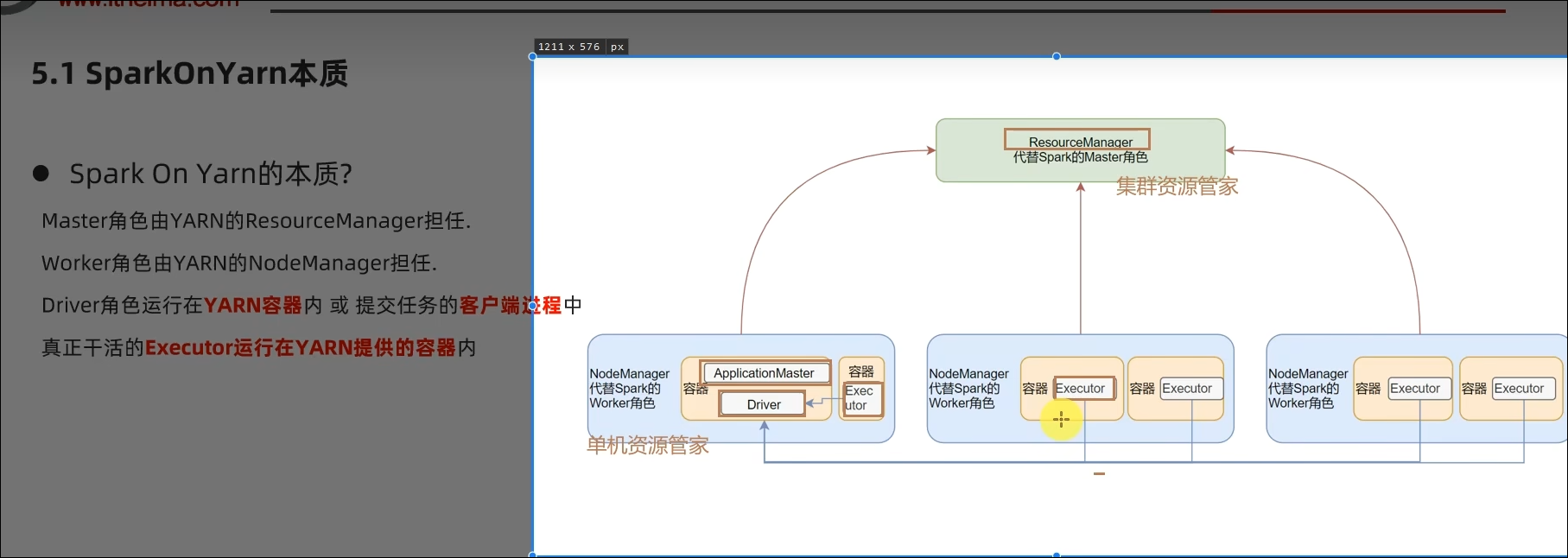
Master由ResourceManager代替
Worker由NodeManager代替
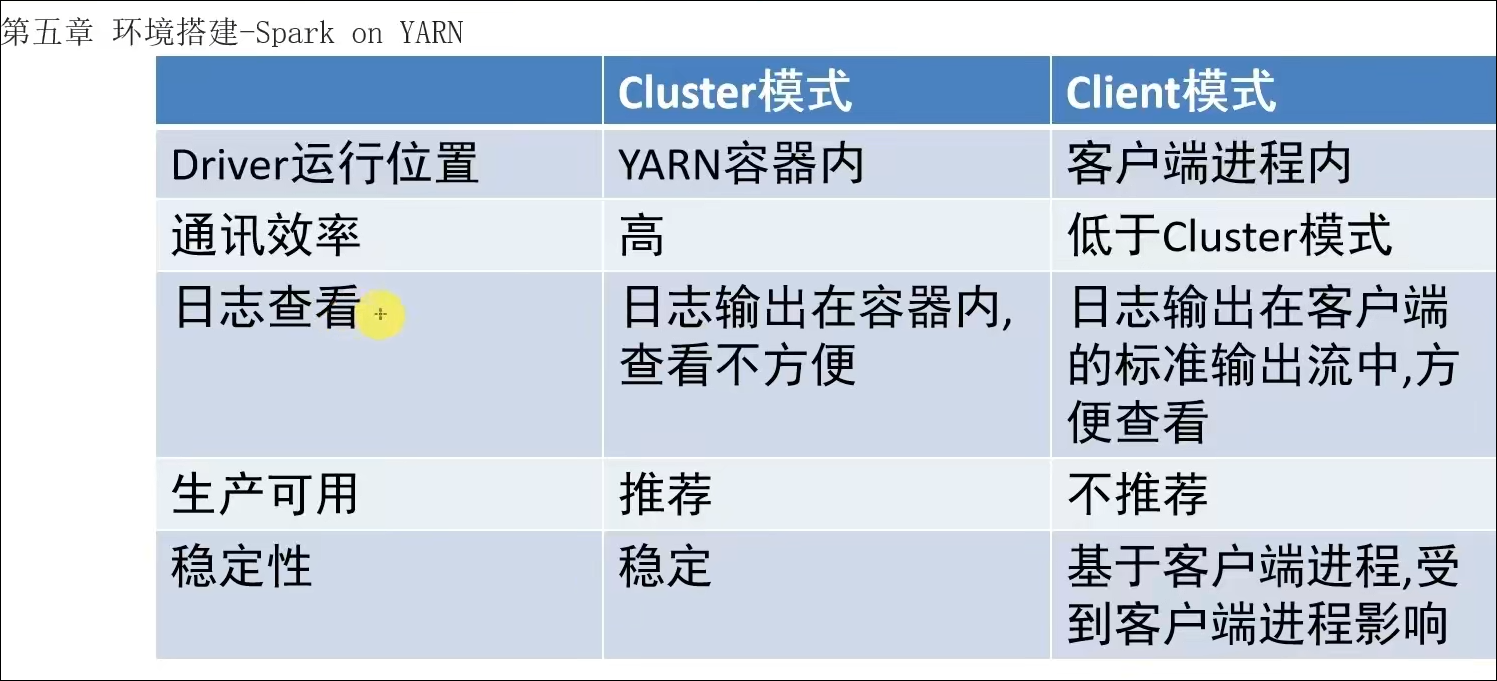
Driver可以运行在容器内(Cluster模式)或客户端进程中(Client模式)
Executor全部运行在YARN提供的容器内
提供资源利用率,在已有YARN的场景下让Spark收到YARN的调度可以更好的管控资源提高利用率并方便管理。

详见视频
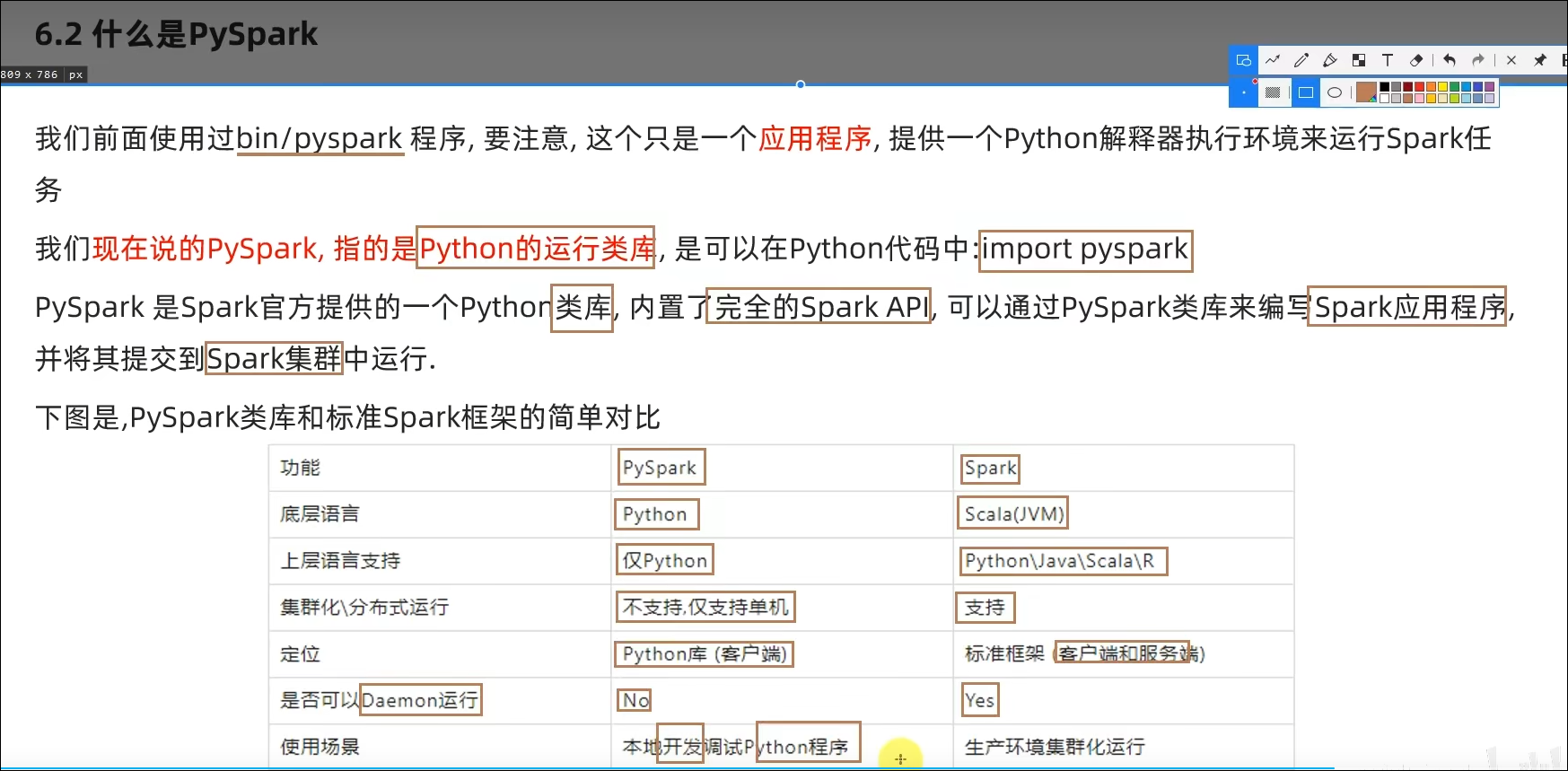
PySpark是一个Python的类库,提供Spark的操作API
bin/pyspark是一个交互式的程序,可以提供交互式编程并执行Spark计算
由Anaconda提供,并使用虚拟环境,环境名称叫做:pyspark
详见视频
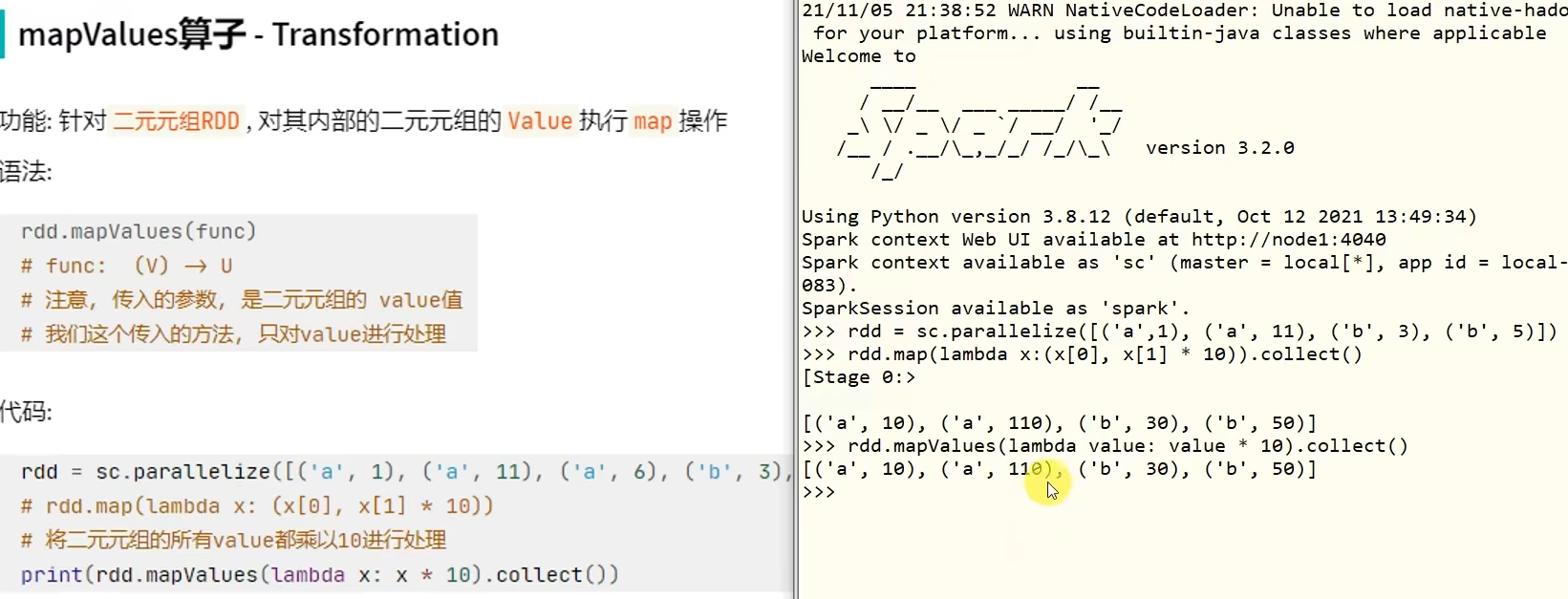
PS:解决WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform…警告

找了好几个都不行。
PS:解决

参考资料https://blog.csdn.net/weixin_51951625/article/details/117452855
https://blog.csdn.net/OWBY_Phantomhive/article/details/123088763
https://blog.csdn.net/qq_20540901/article/details/123499540

需要配置环境变量
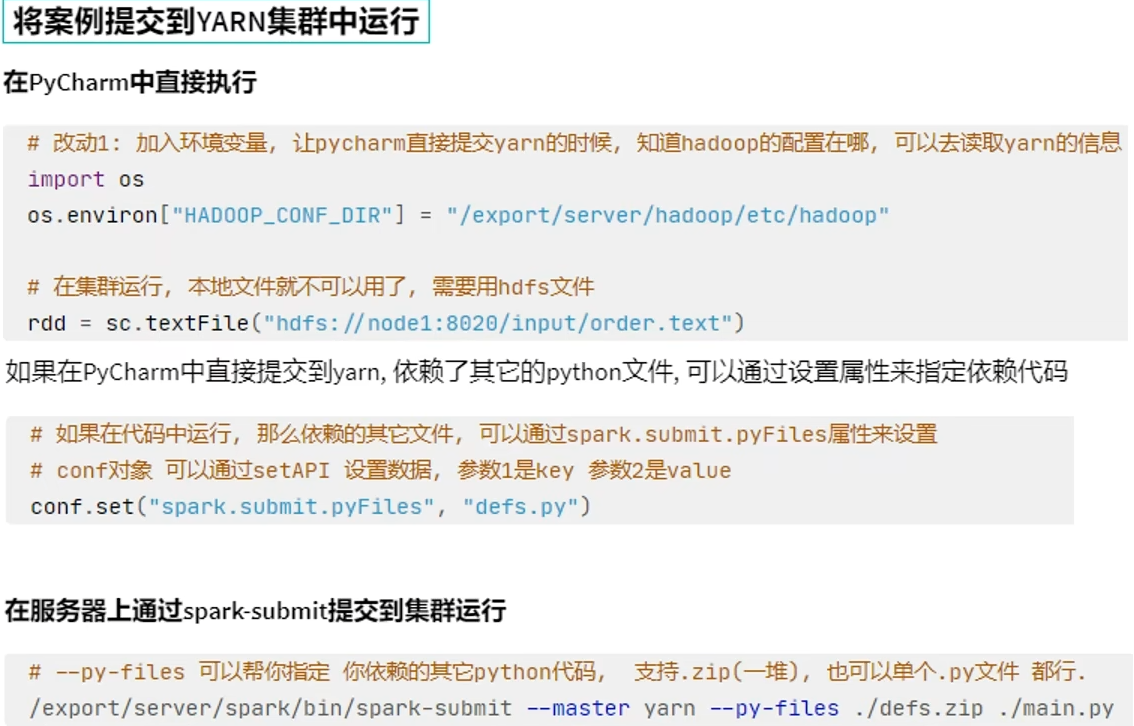
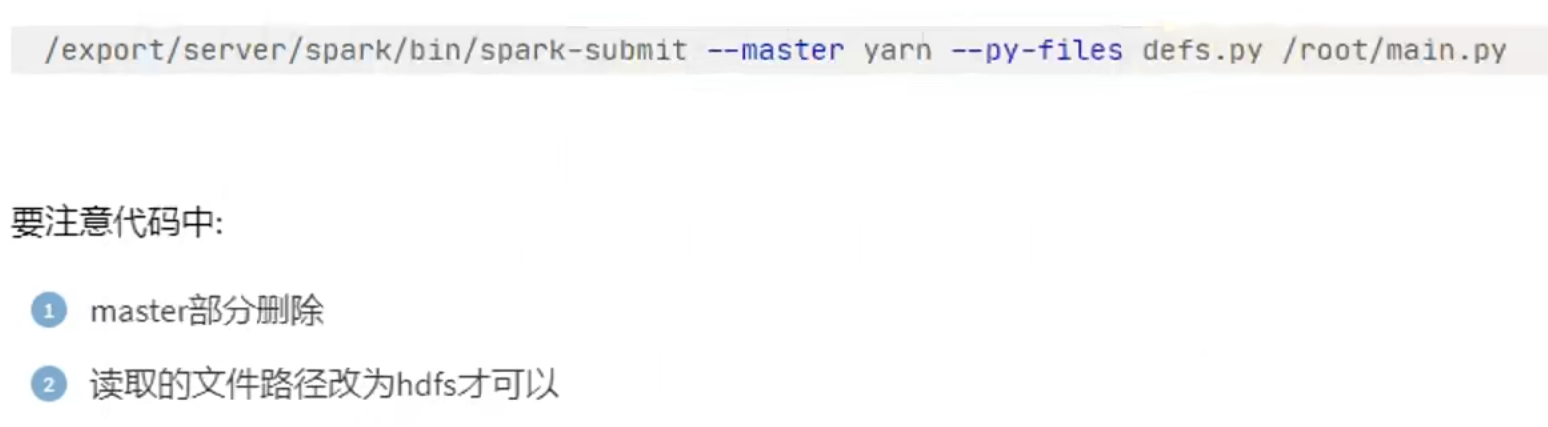
通过spark-submit yarn提交到集群的py文件中的地址,集群会默认去hdfs里面找。


在yarn模式或者standalone这样的集群下,访问的文件路径,要么是网络地址,要么是hdfs,这样每台机器都能访问到。
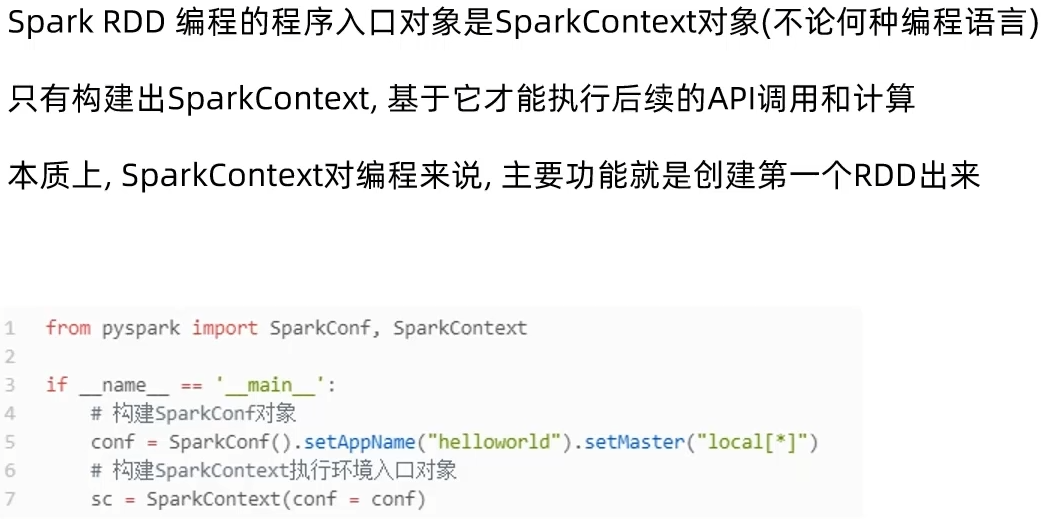
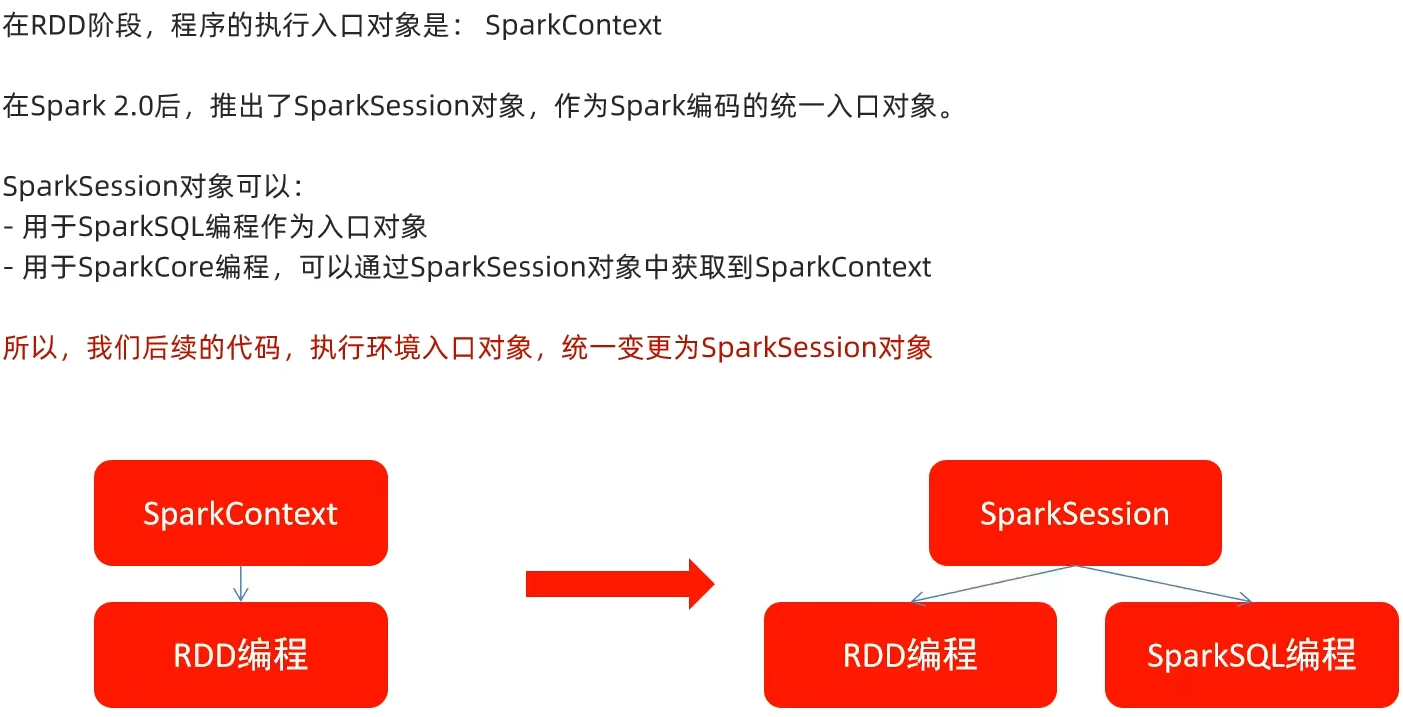
主要是获取SparkContext对象,基于SparkContext对象作为执行环境入口。
将程序代码上传到服务器上,通过spark-submit客户端工具进行提交。
1.在代码中不要设置master,如果设置了,会以代码为准,spark-submit工具的设置就无效了。
2.提交程序到集群中的时候,读取的文件一定是各个机器都能访问到的地址。比如HDFS。
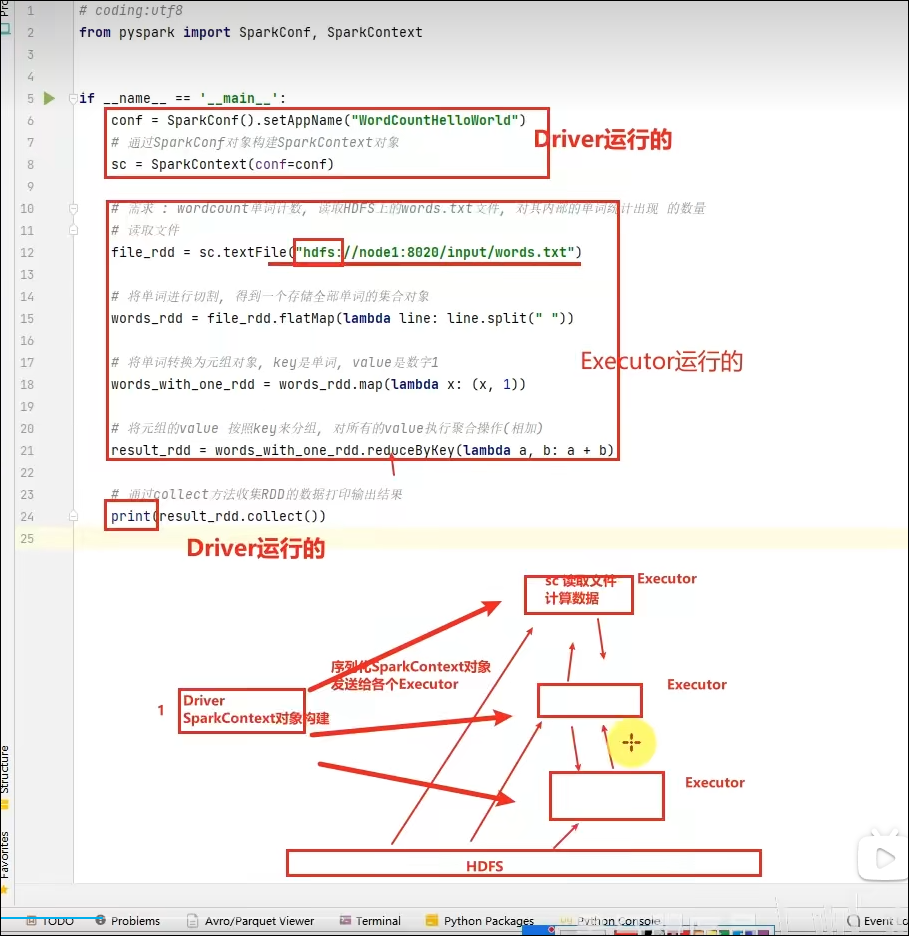

代码在集群上运行,是被分布式运行的。
在Spark中, 非任务处理部分,由Driver执行(非RDD代码)。
任务处理部分由Executor执行(RDD代码)。
Executor的数量很多,所以任务的计算是分布式在运行的。
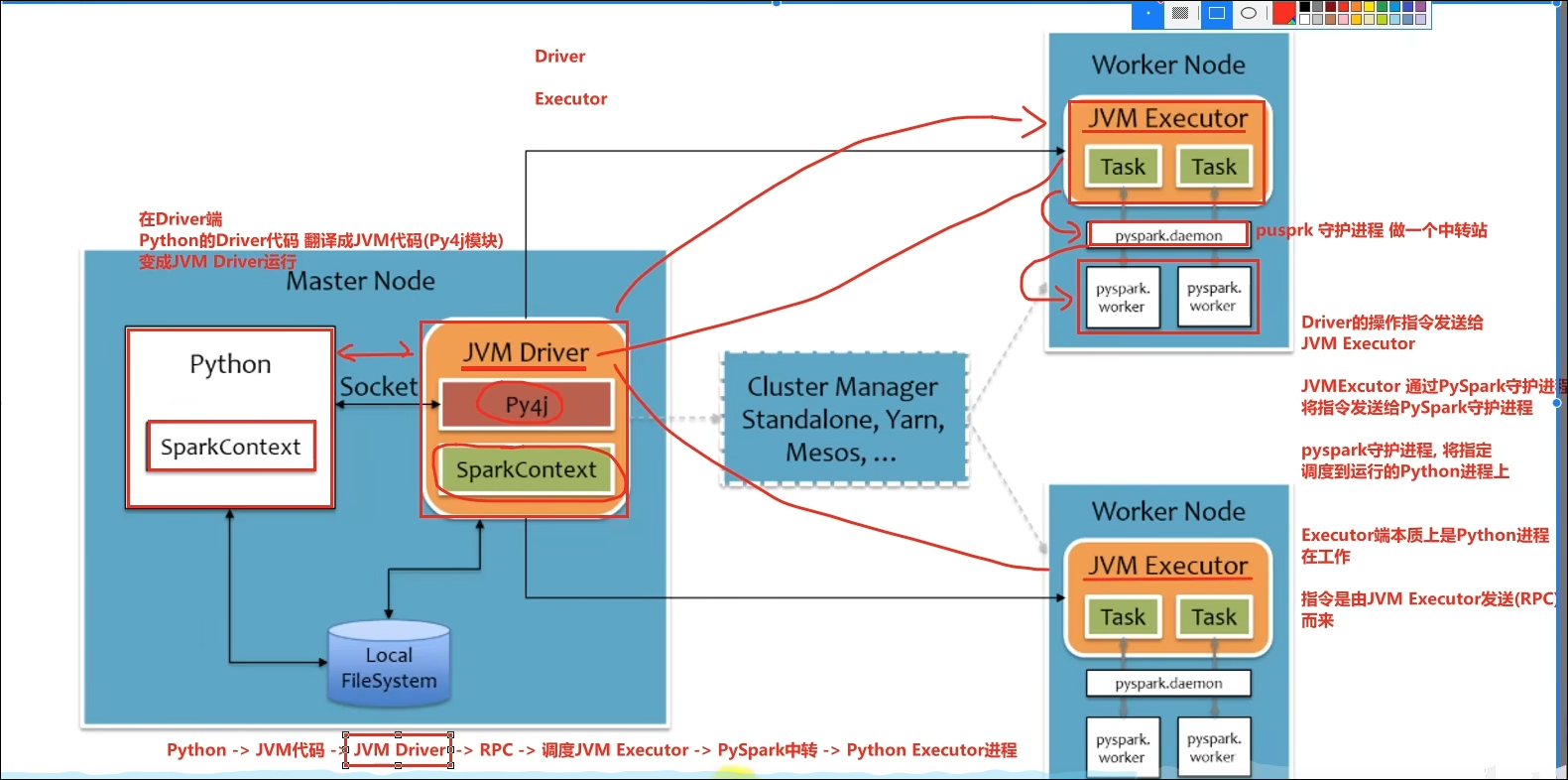
Python On Spark:Driver端由JVM执行,Executor端由JVM做命令转发,底层由Python解释器进行工作。
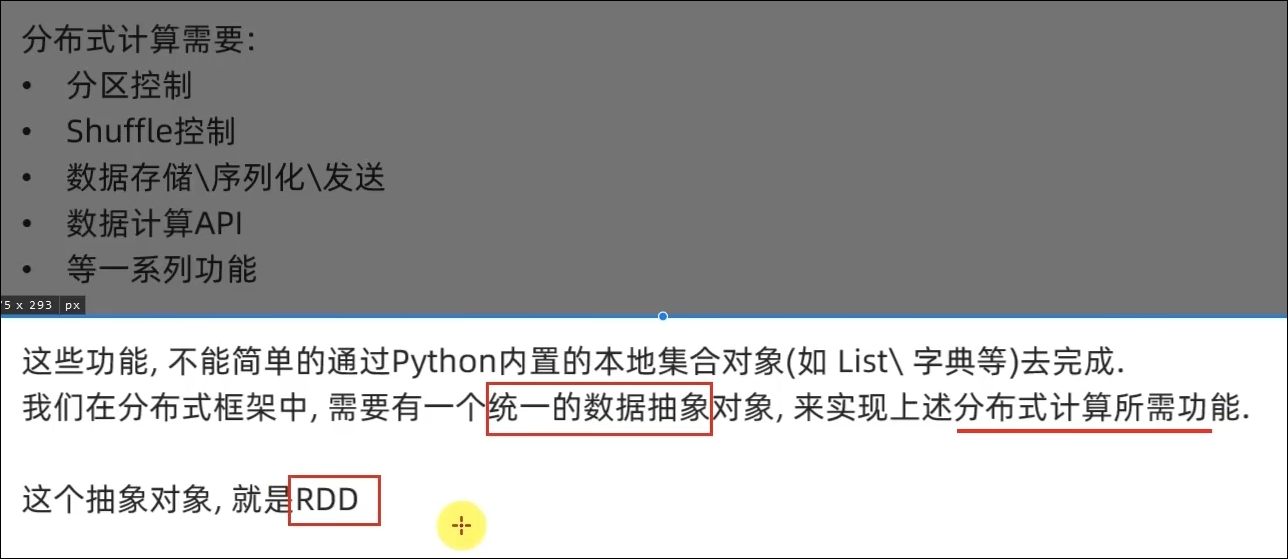

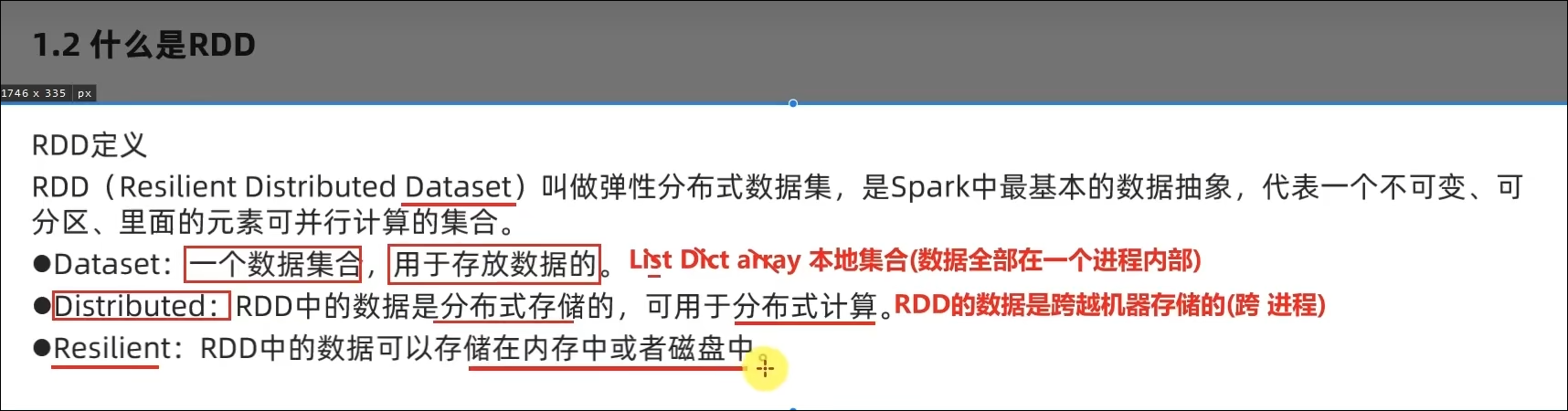
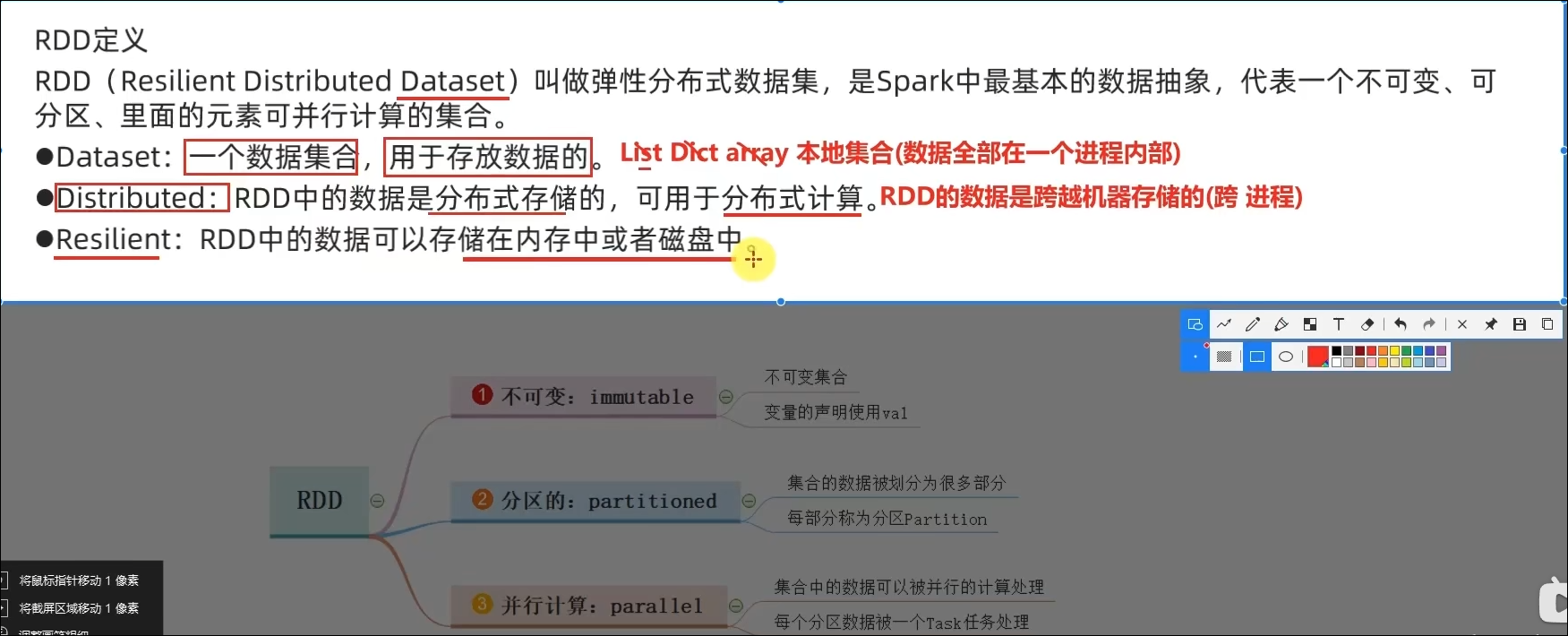

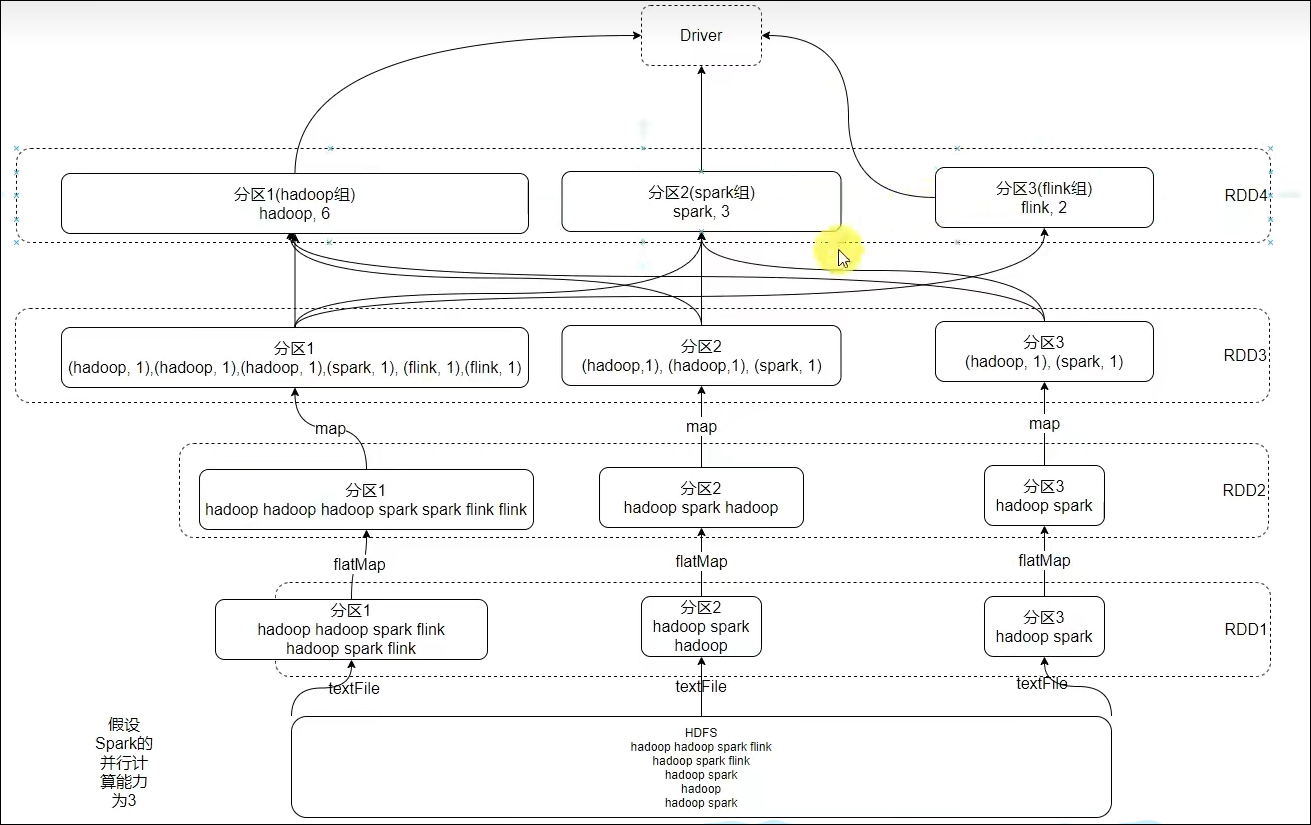
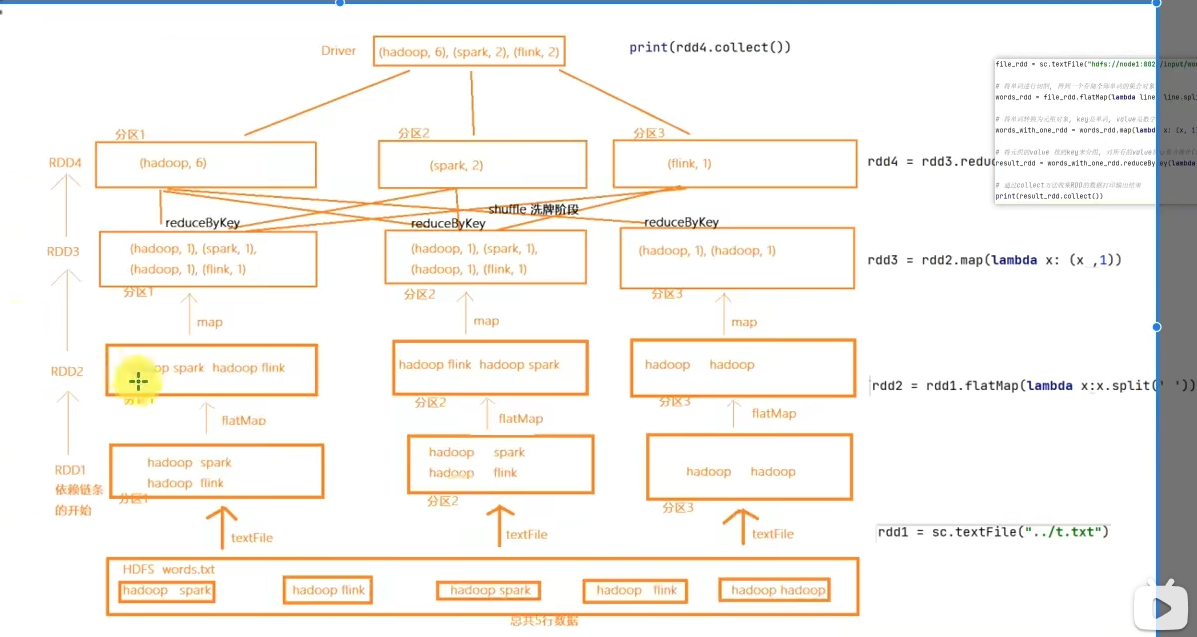
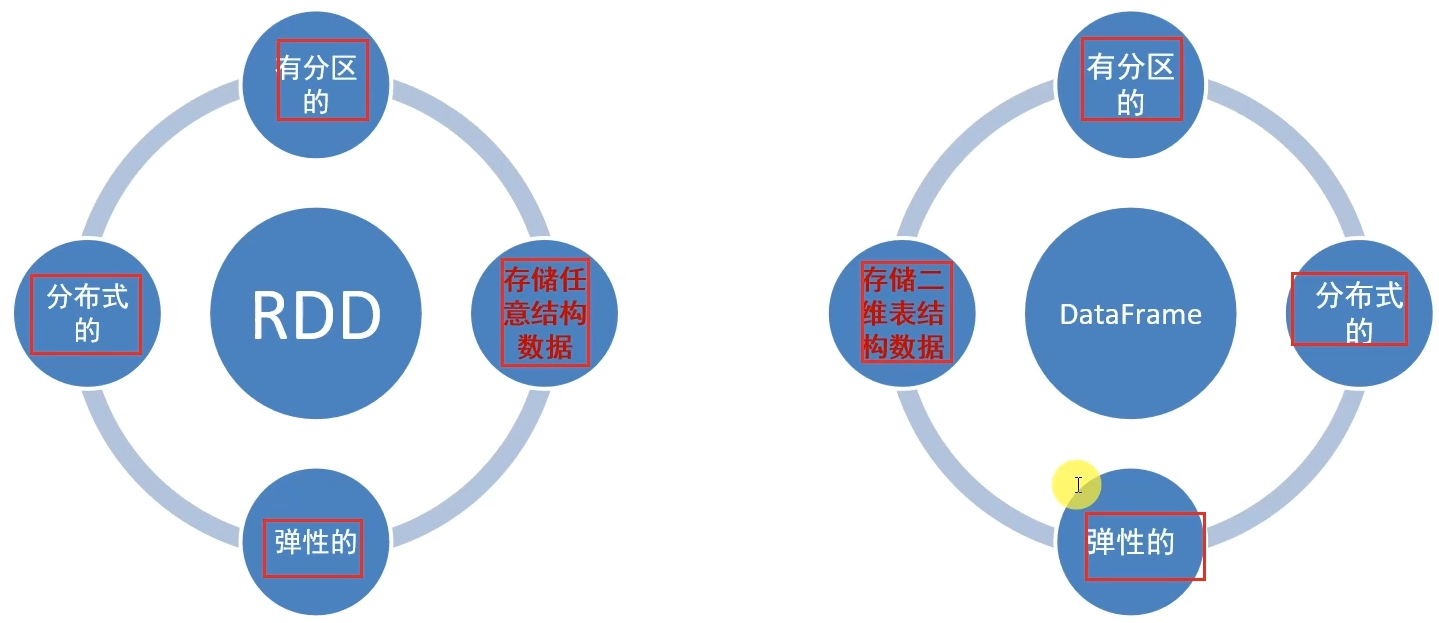
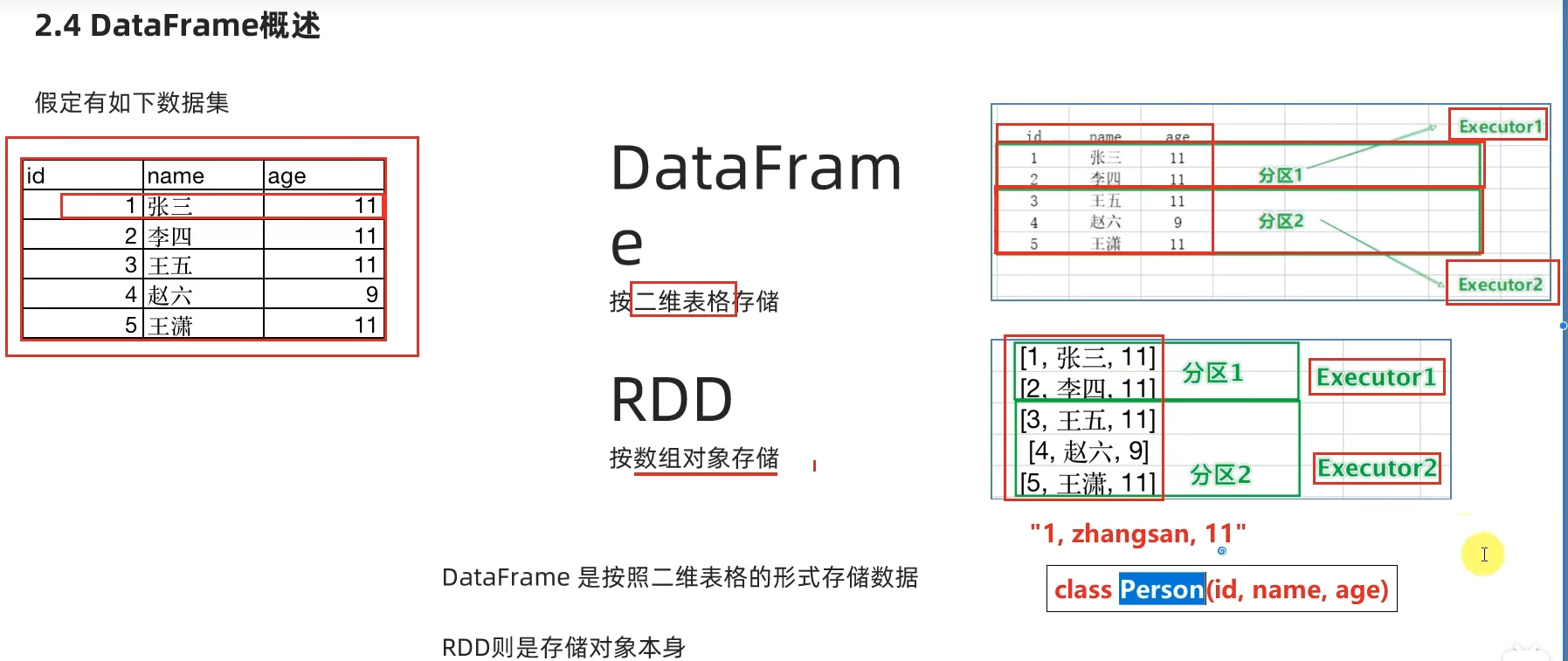
不可变、可分区、并行计算的弹性分布式数据集,分布式计算的实现载体(数据抽象)
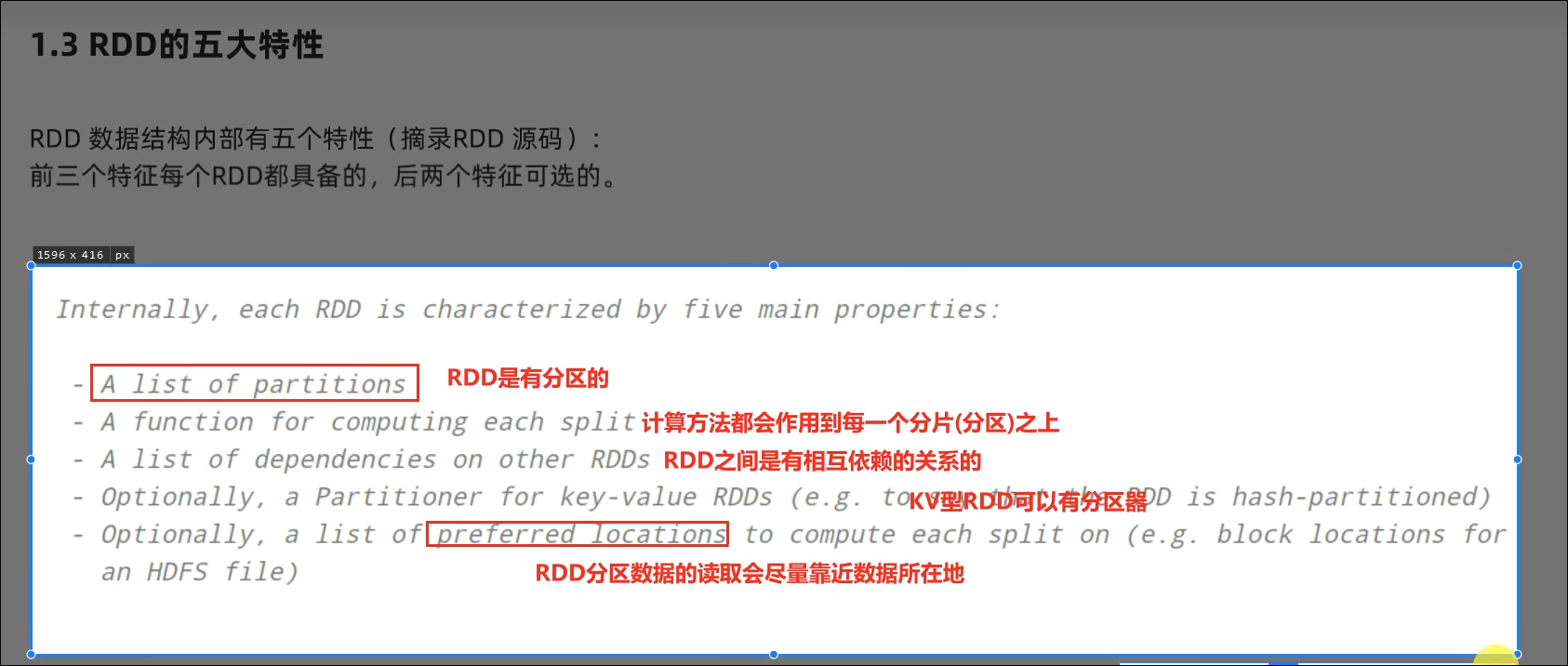
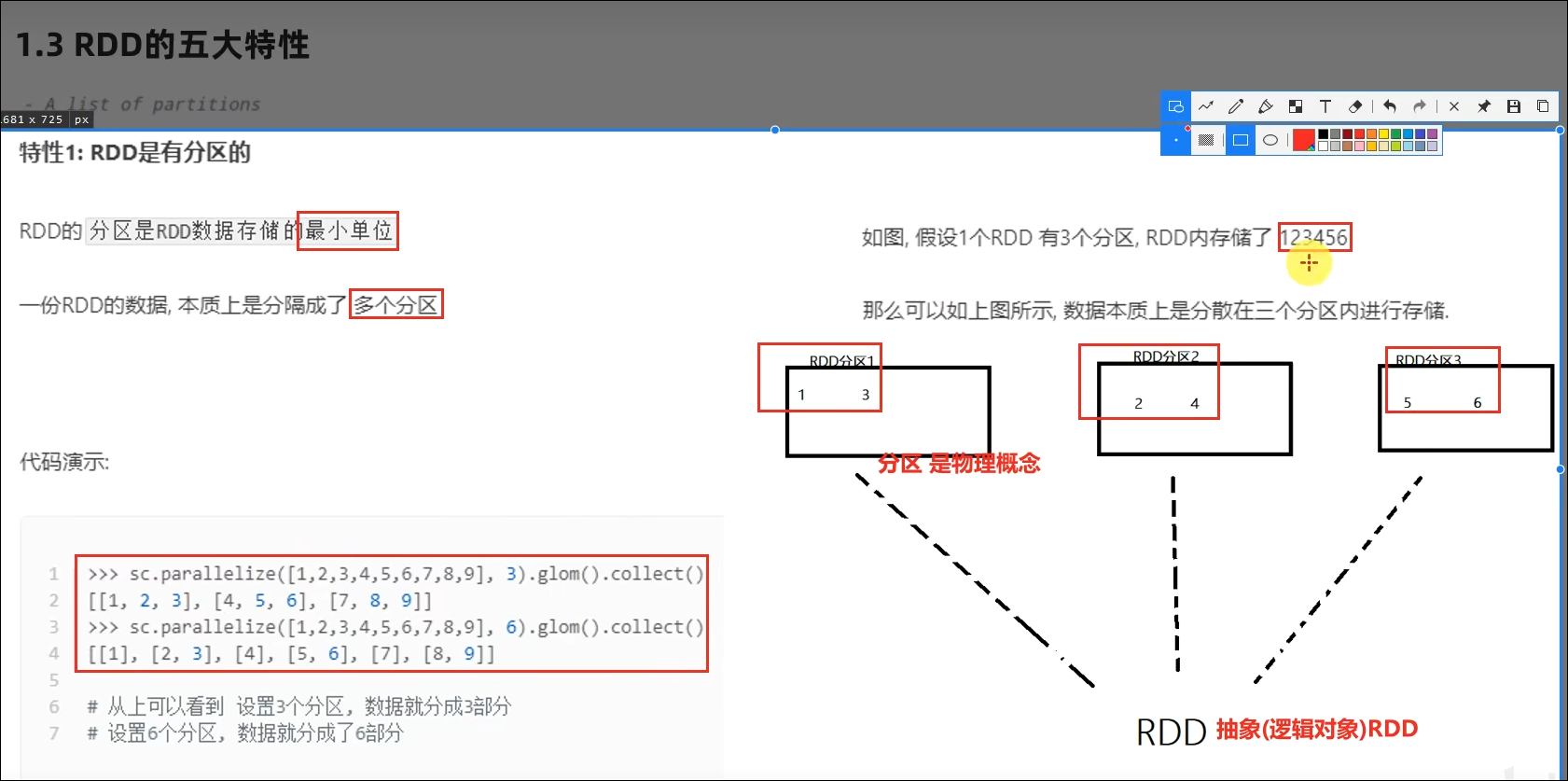
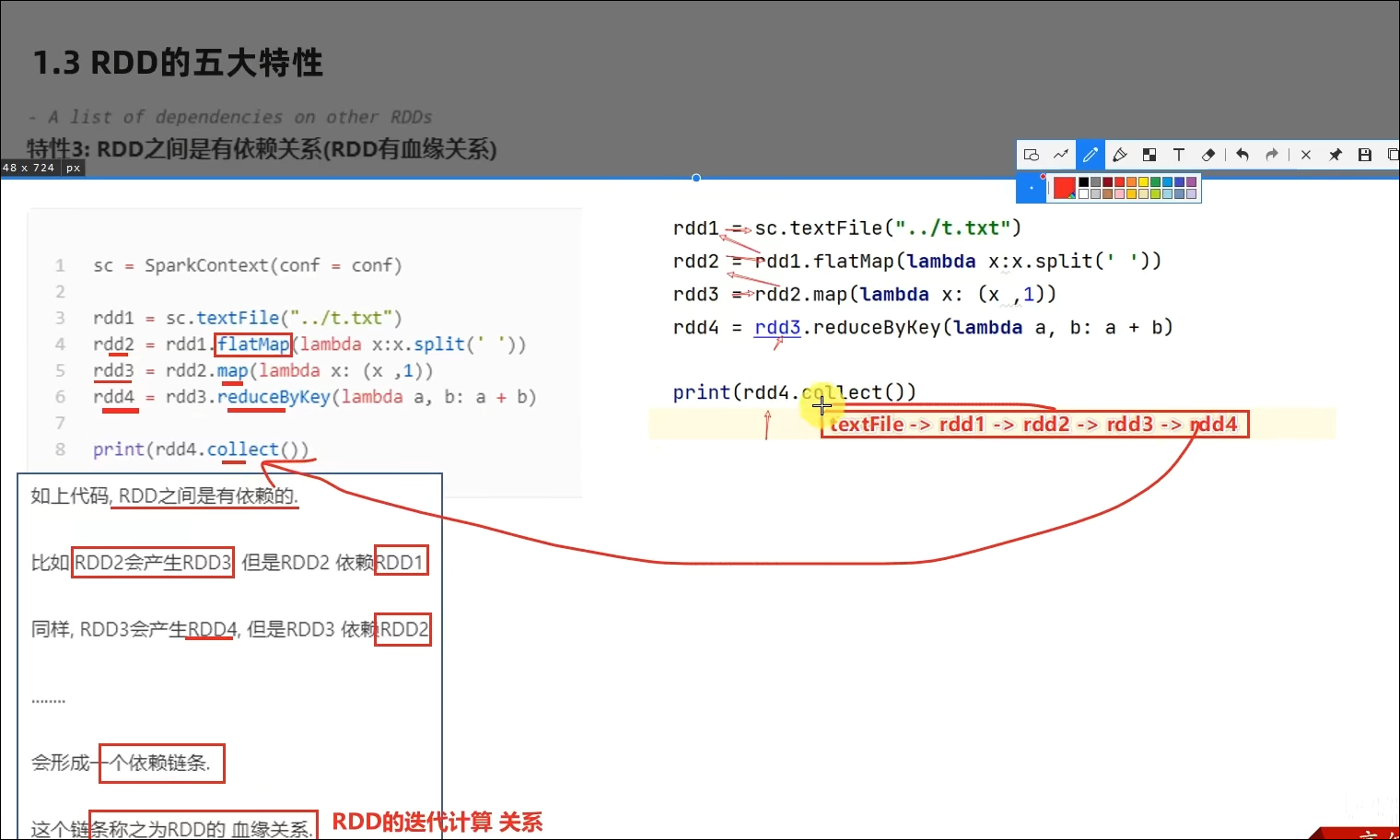
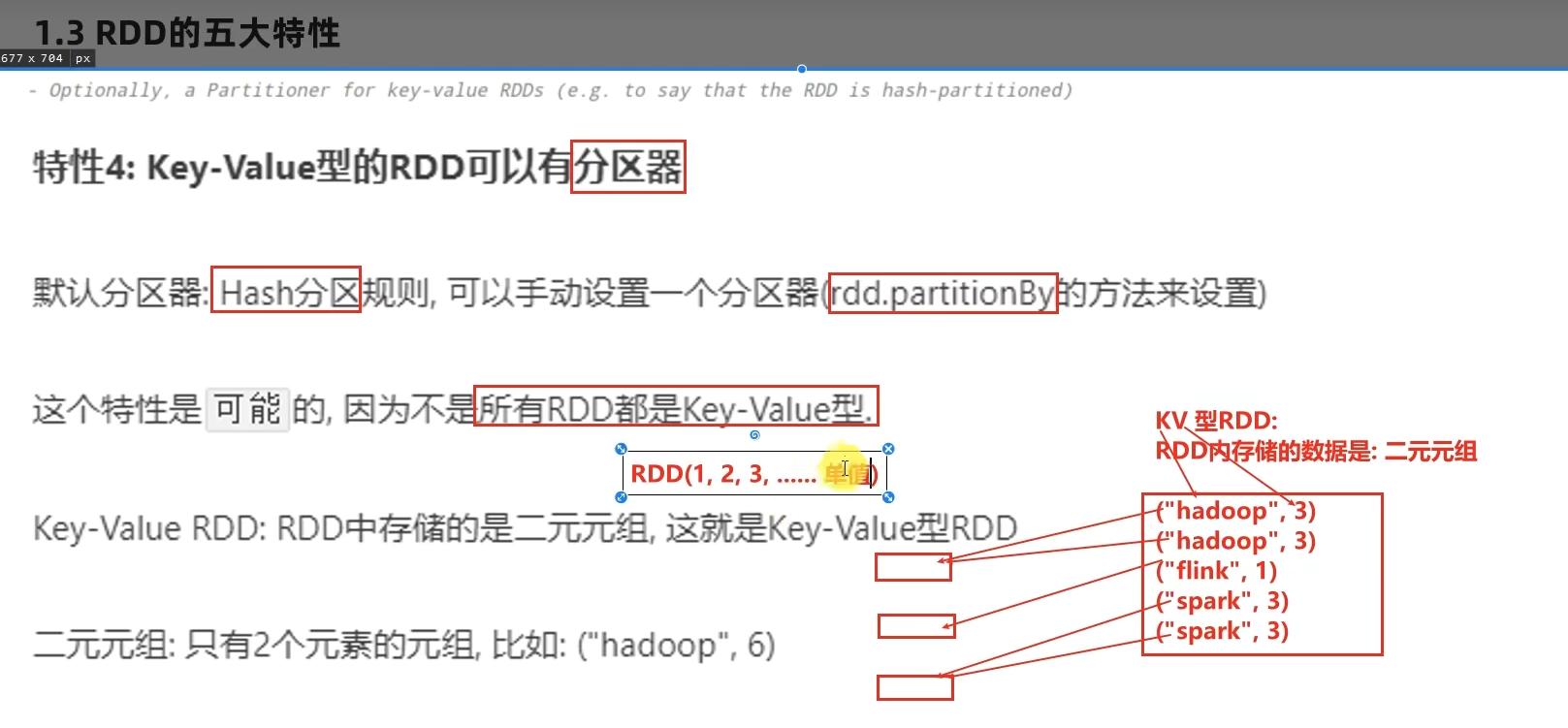
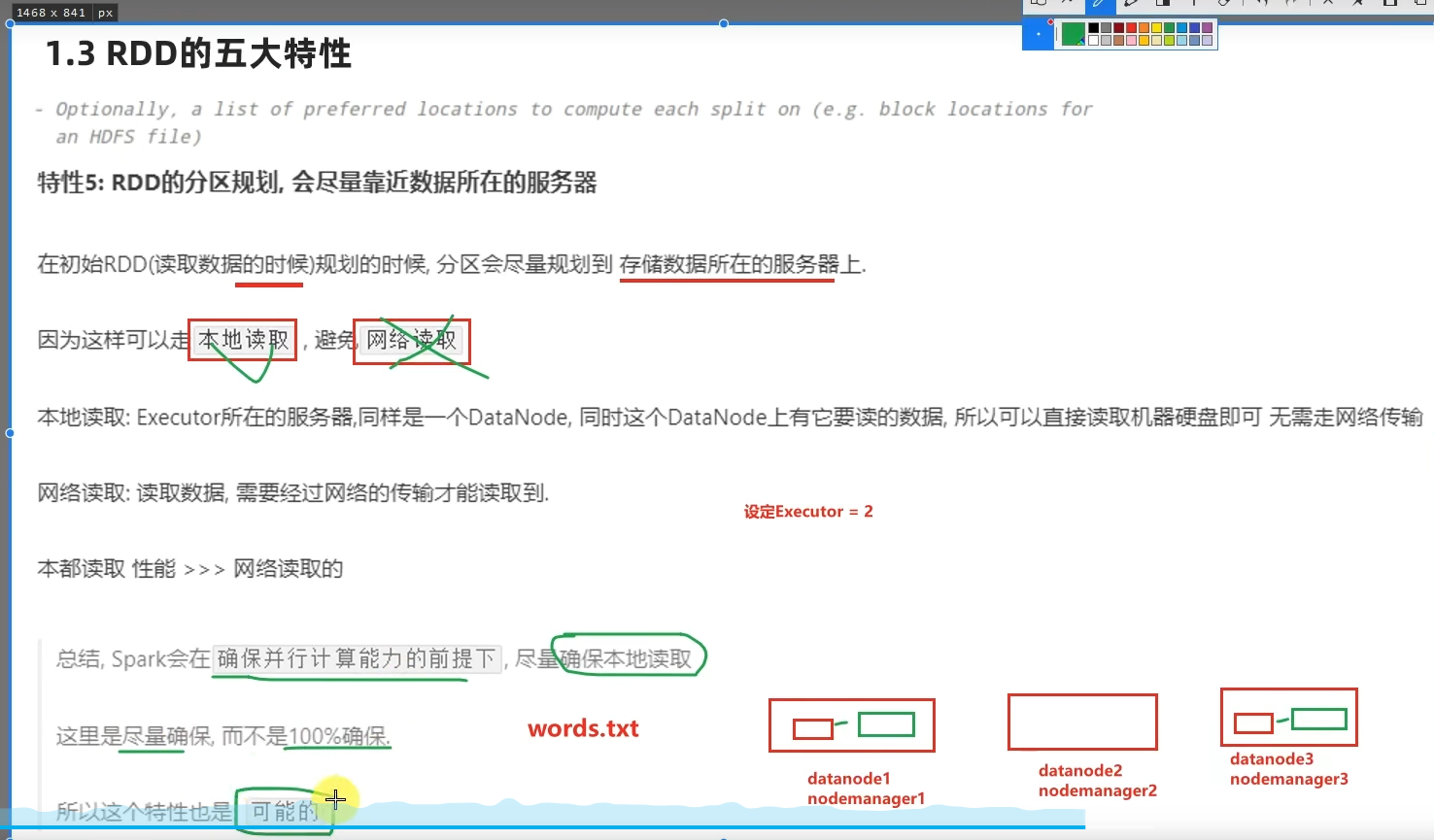
RDD有分区;RDD的方法会作用在所有分区上;RDD之间有依赖关系;KV型的RDD是有分区器的;RDD的分区规划,会尽量靠近数据所在服务器。
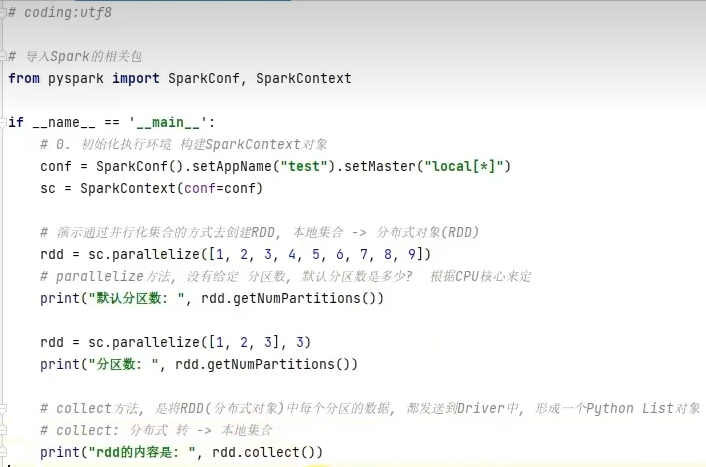
在local[*]方法下,parallelize方法,没有给定分区数的情况下,默认分区数是根据CPU核心数来定。




PS:报错:UserWarning: Please install psutil to have better support with spilling
参考资料:https://blog.csdn.net/sqlserverdiscovery/article/details/102936203

PS:未正确退出conda环境,会报错
参考资料:https://blog.csdn.net/weixin_44211968/article/details/122483304
conda deactivate
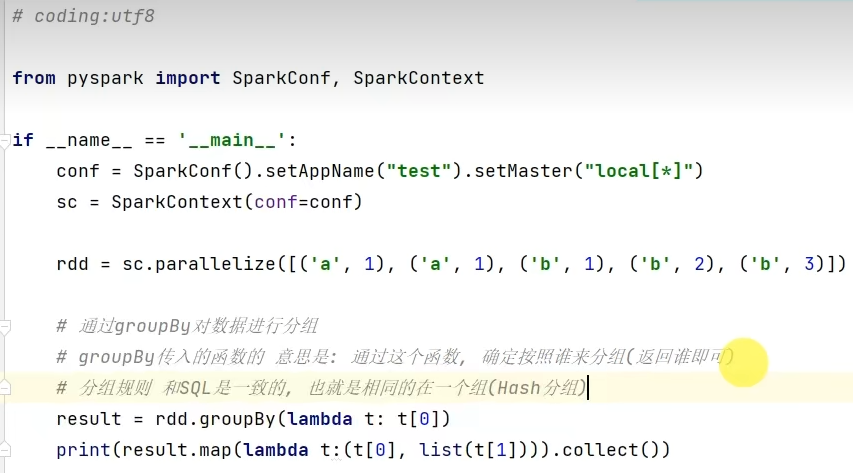

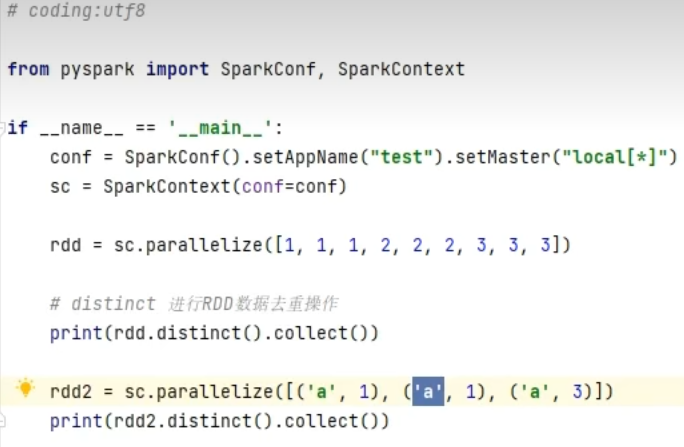

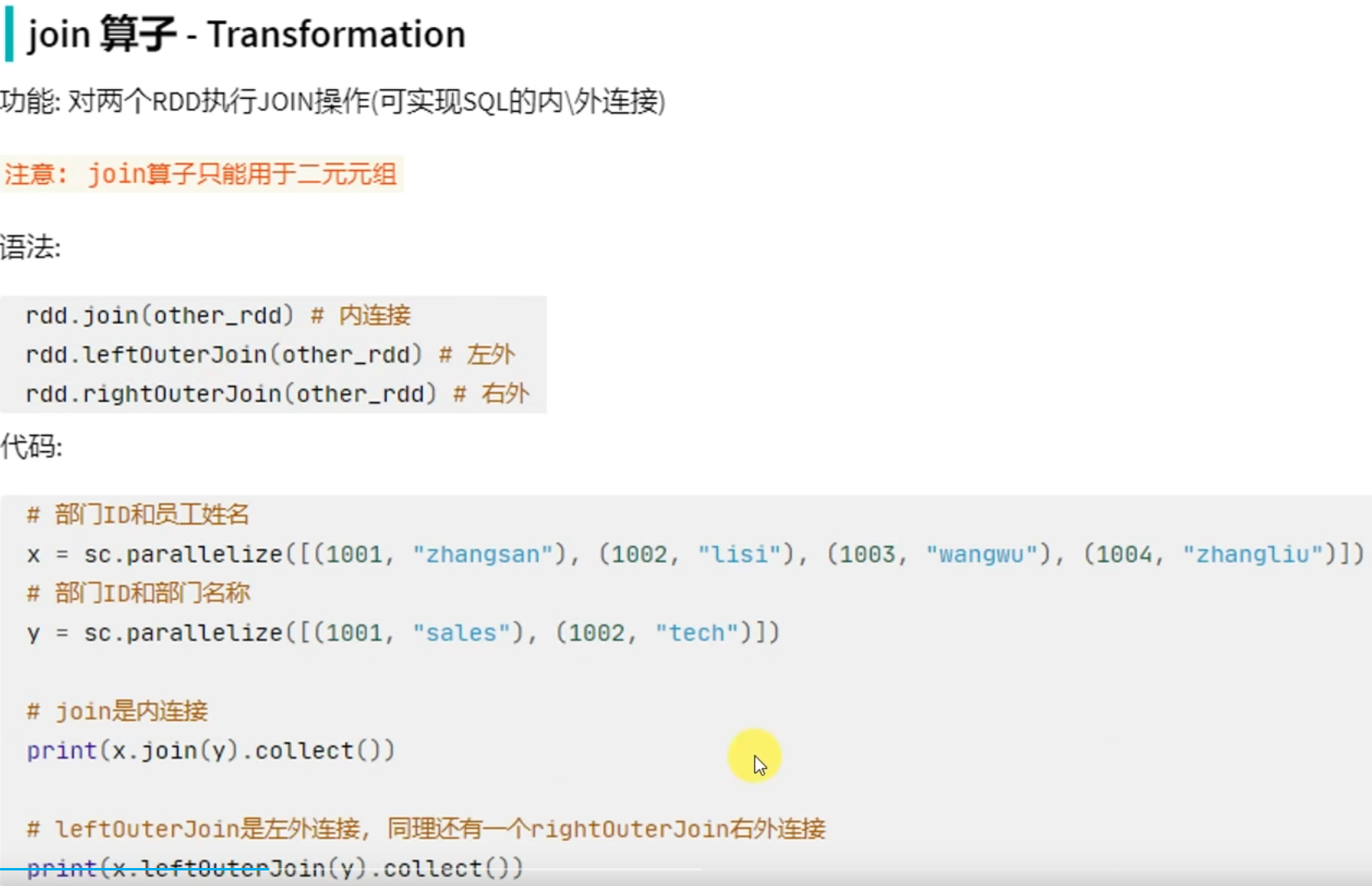
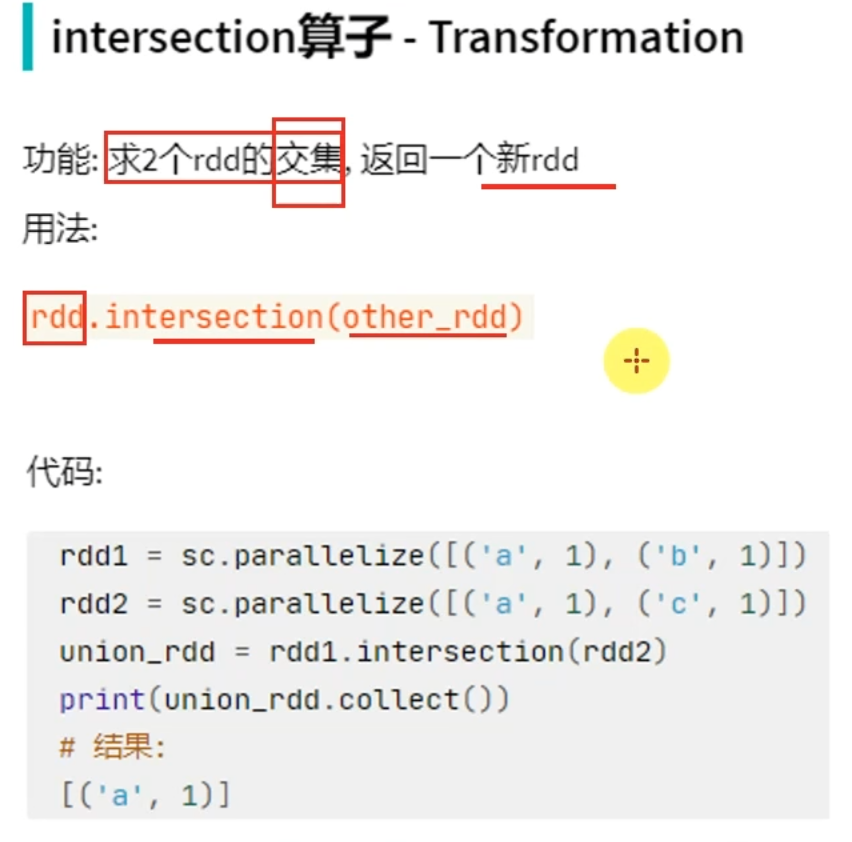
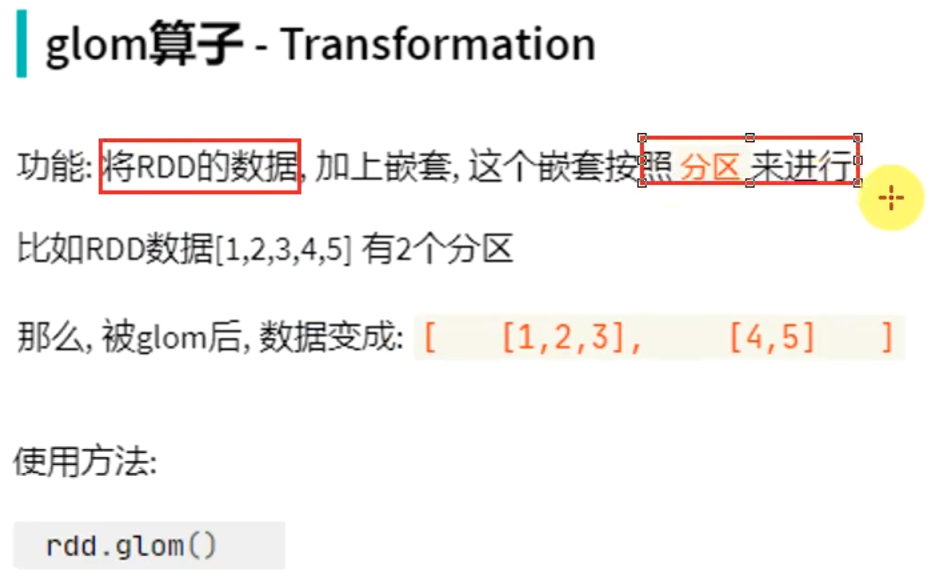

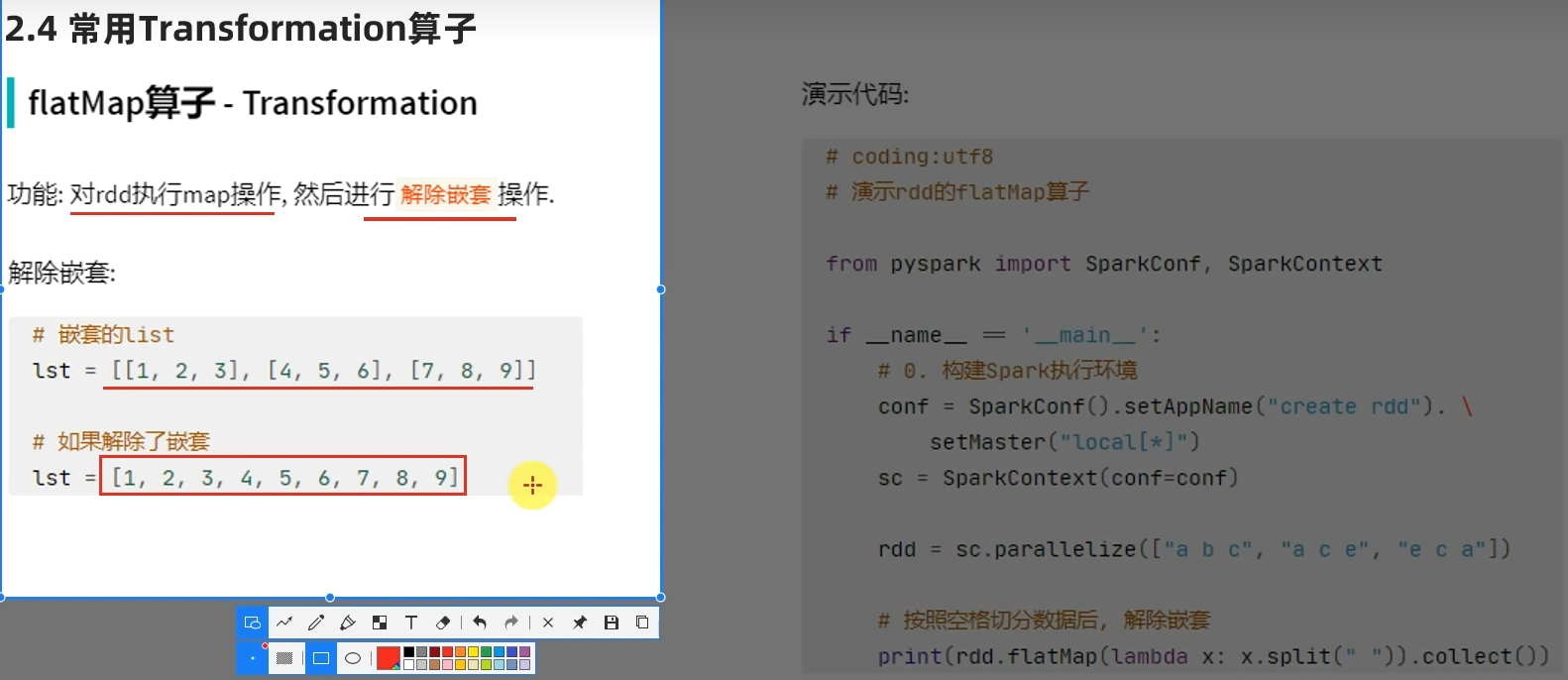
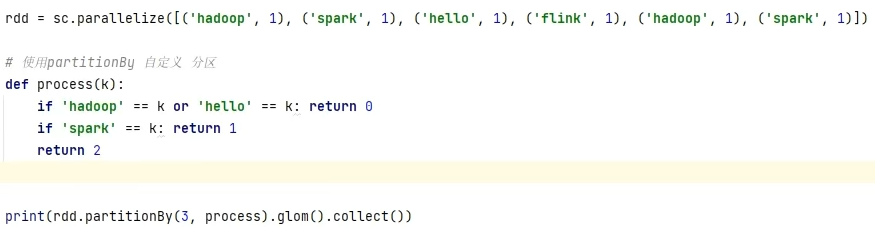
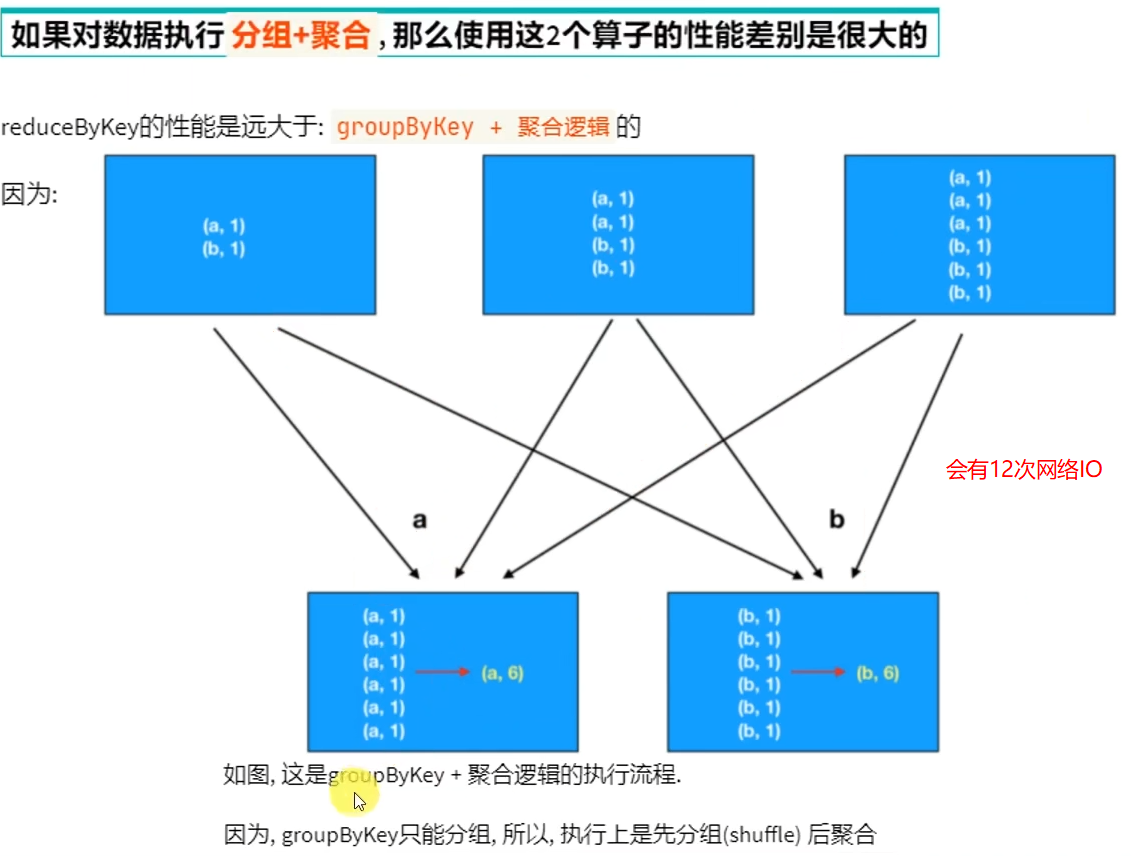
groupByKey只保留同组的值,而groupBy还保留key。
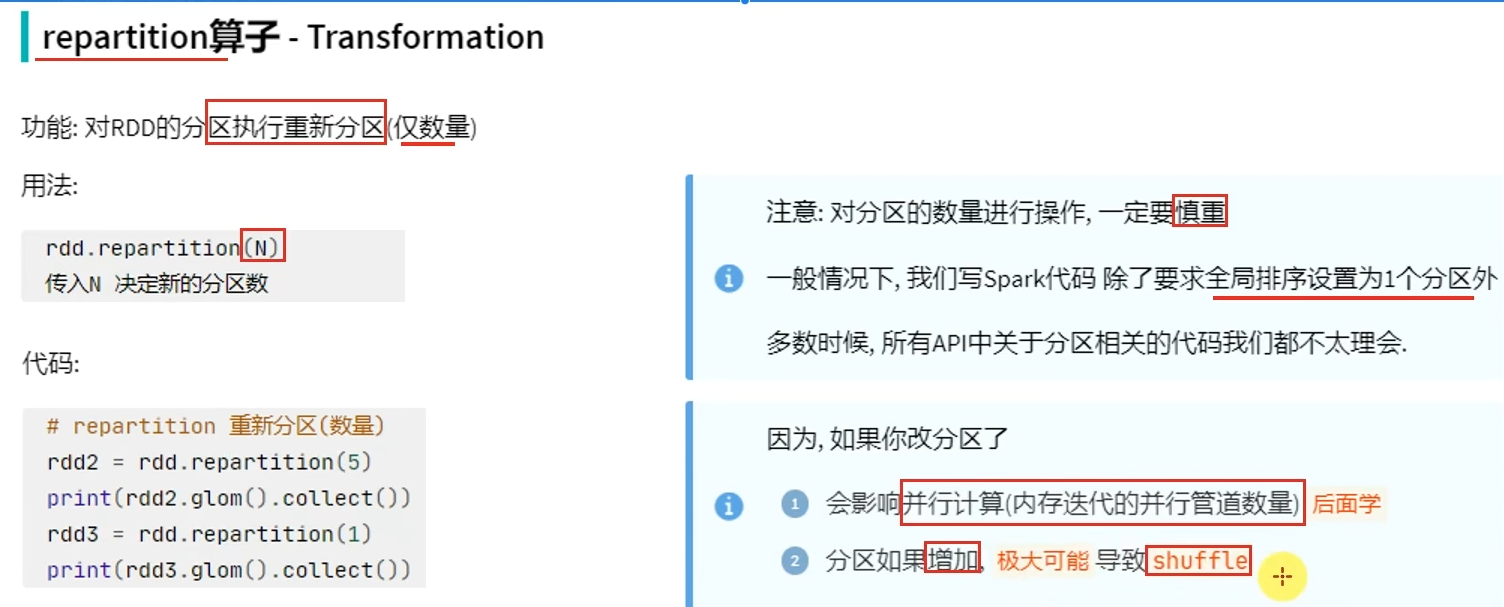
注意:如果选择多个分区来进行排序,那么就意味着有多个excutor,每个excutor只能保证局部有序。所以如果要全局有序,排序分区的并行任务数请设置为1






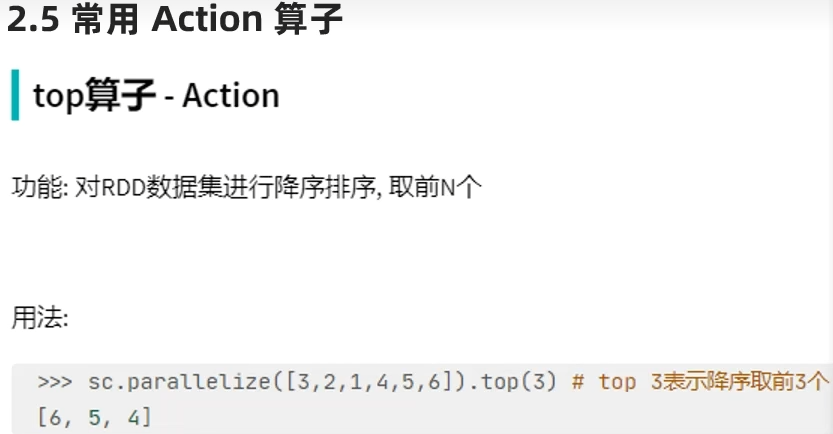

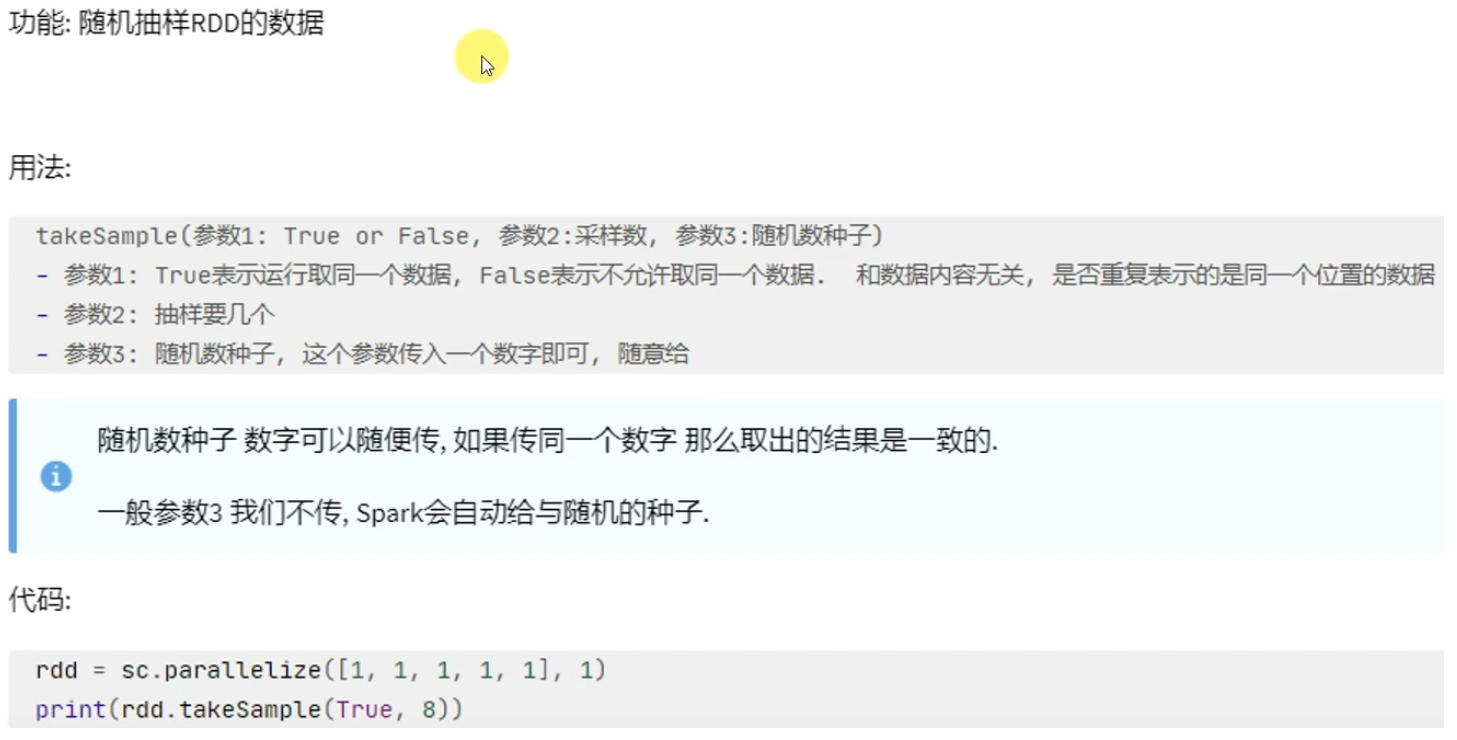

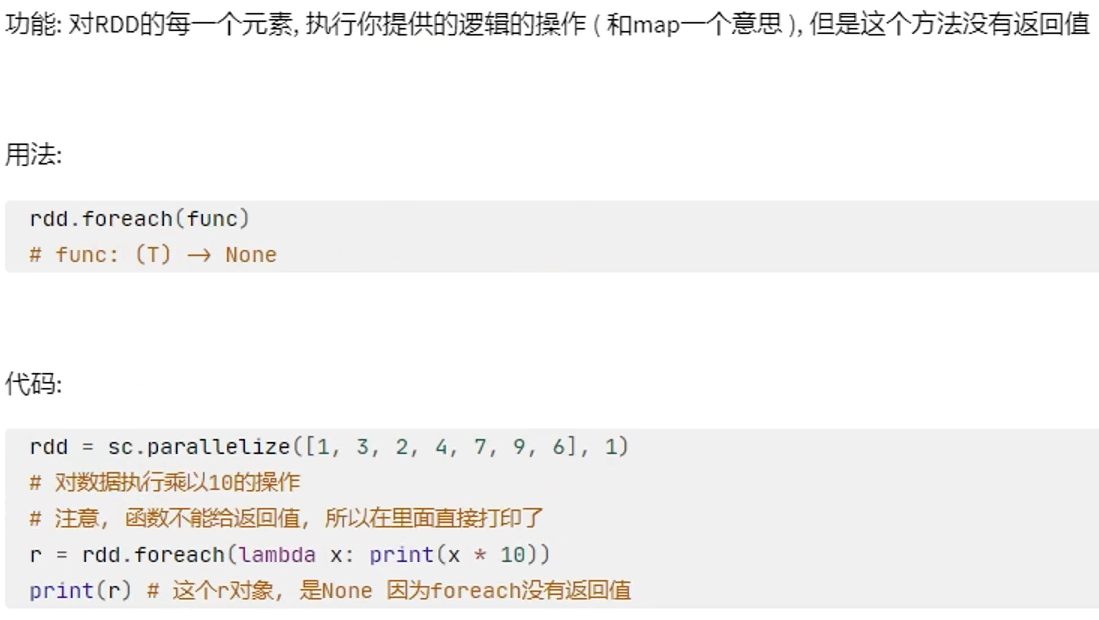
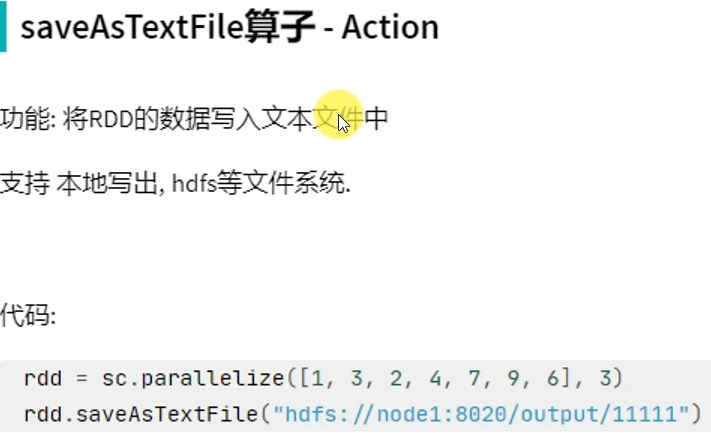
rdd有几个分区,写出的数据就有几个"part-xxxx"文件

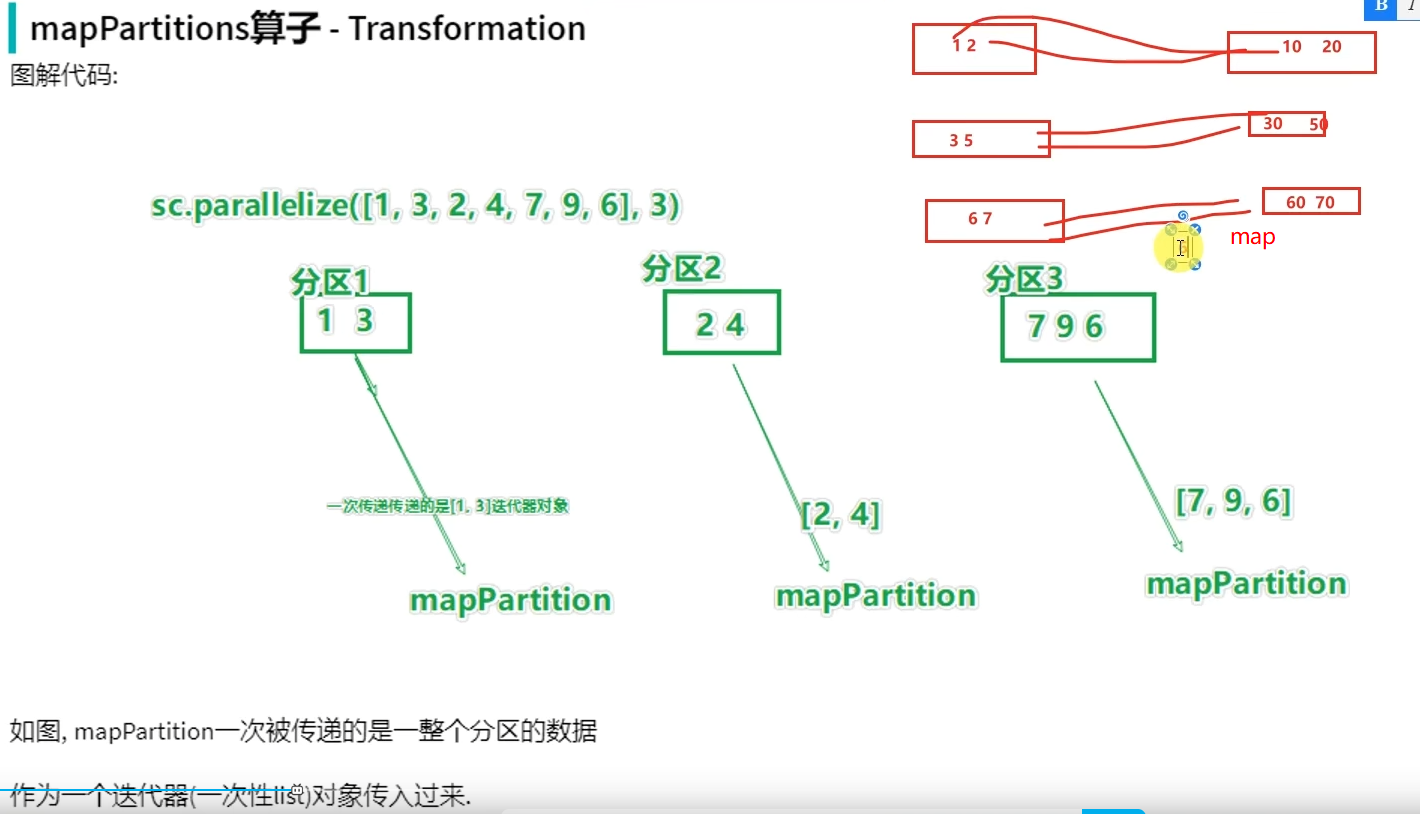
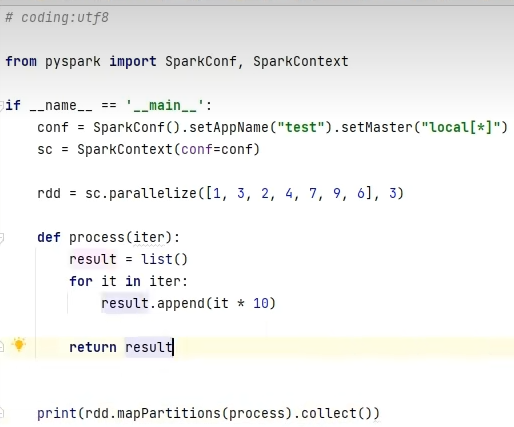
mapPartitions并没有节省CPU执行层面的东西,但节省了网络管道IO开销,所以他的性能比map好。


shuffle是有状态计算,有状态计算涉及到状态的获取,就会导致性能下降。而没有shuffle,大部分都是无状态计算,可以并行执行,效果很快。

coalesce有安全机制,当增加分区但没有设置shuffle参数为True时,分区并不会增加
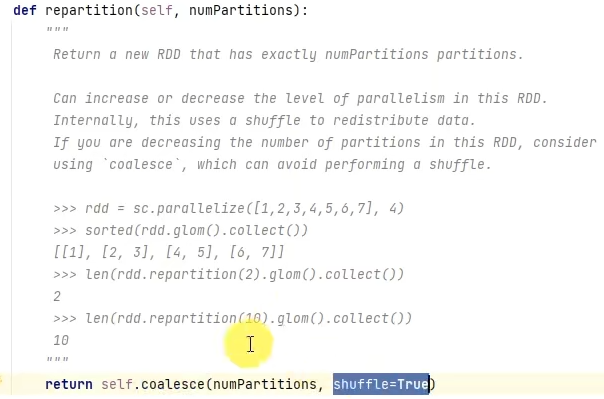
repartition底层调用的是coalesce,只是参数shuffle默认设置为True

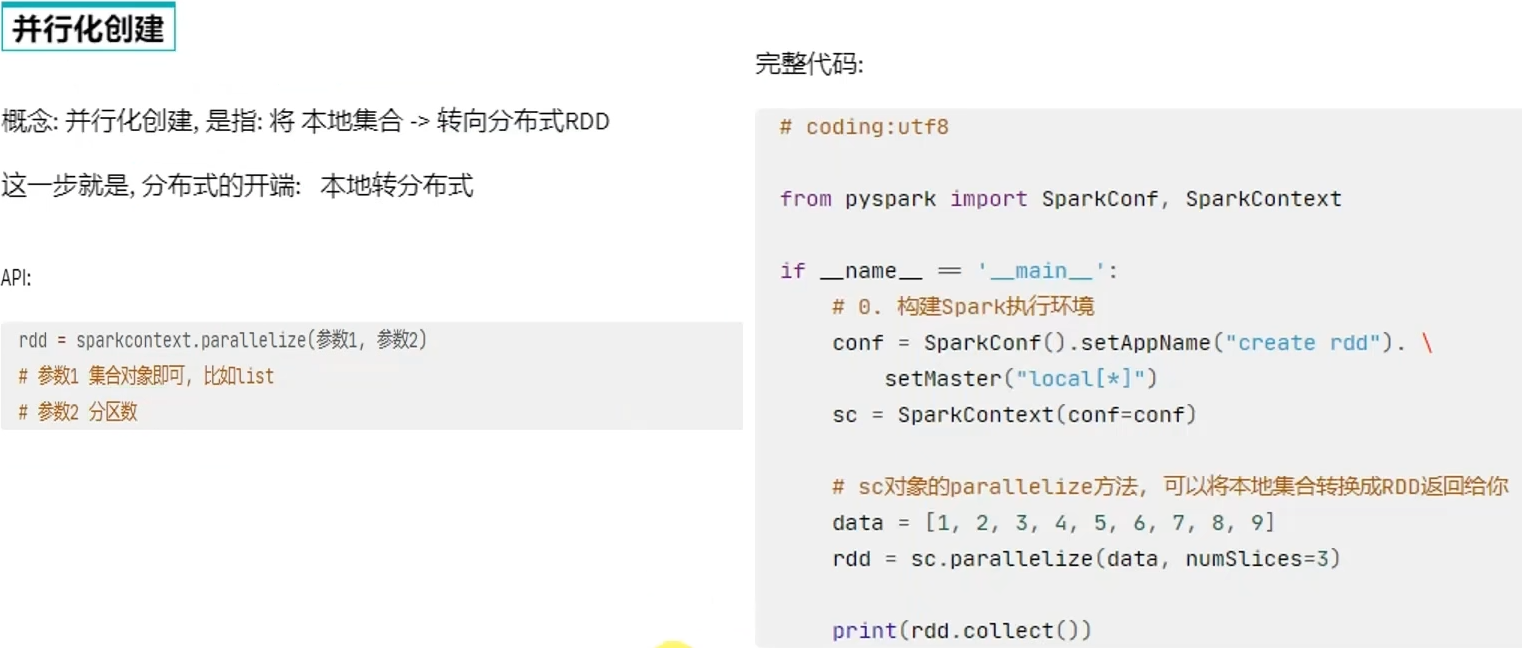
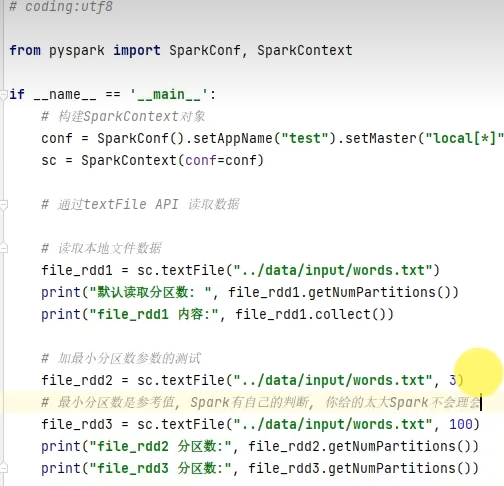
通过并行化集合的方式(本地集合转分布式集合)
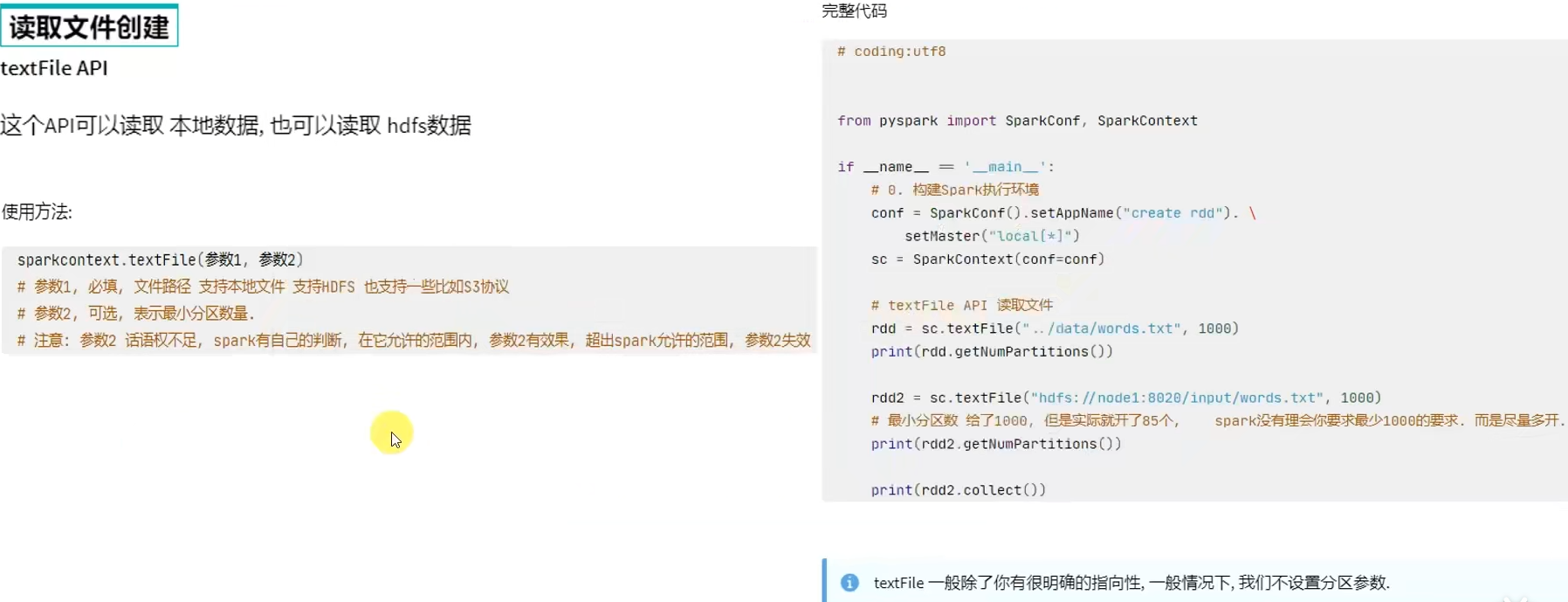
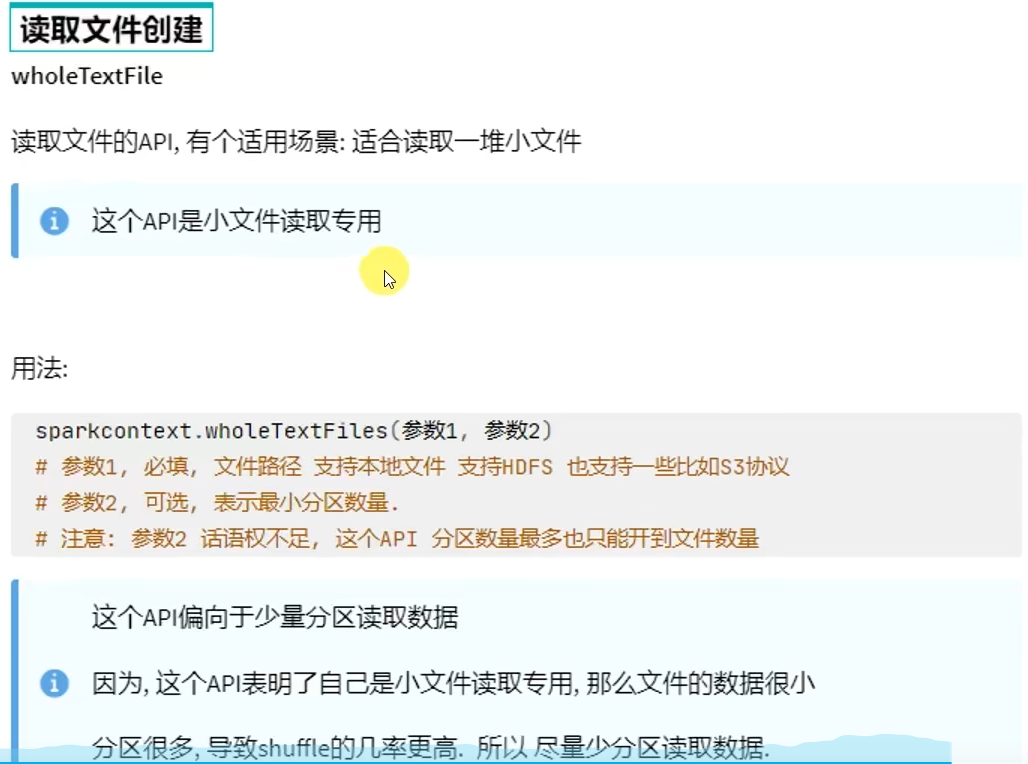
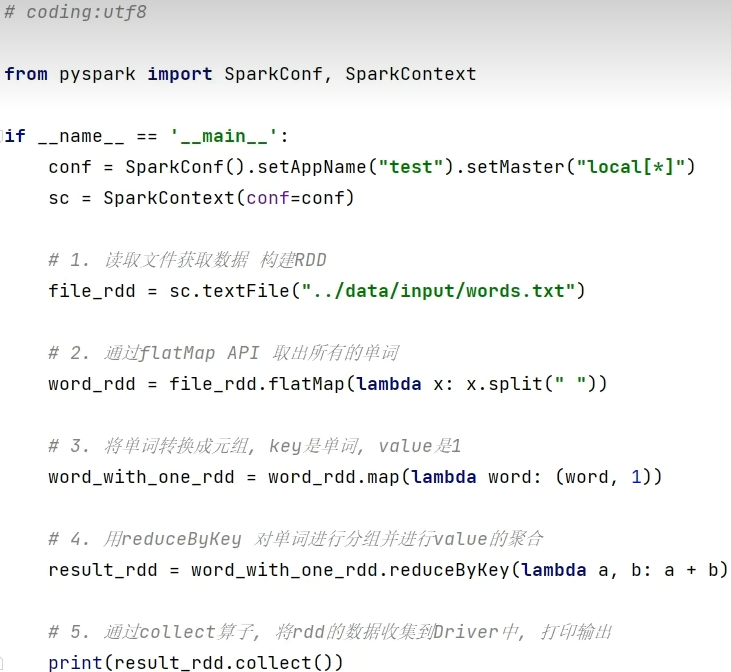
或者读取数据的方式创建(TextFile\WholeTextFile)
通过getNumPartitions API查看,返回Int
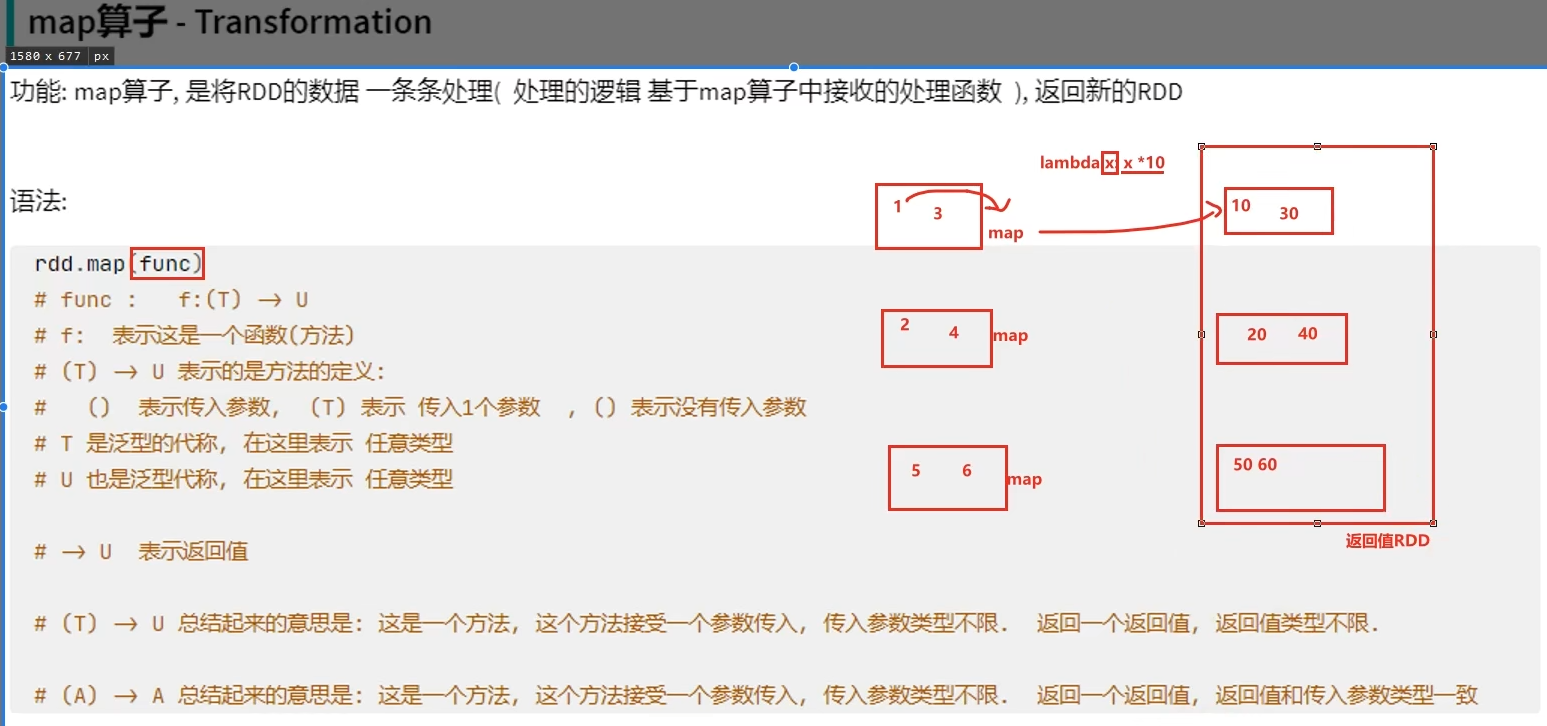
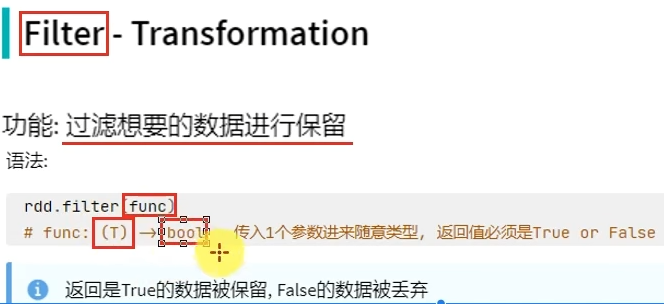
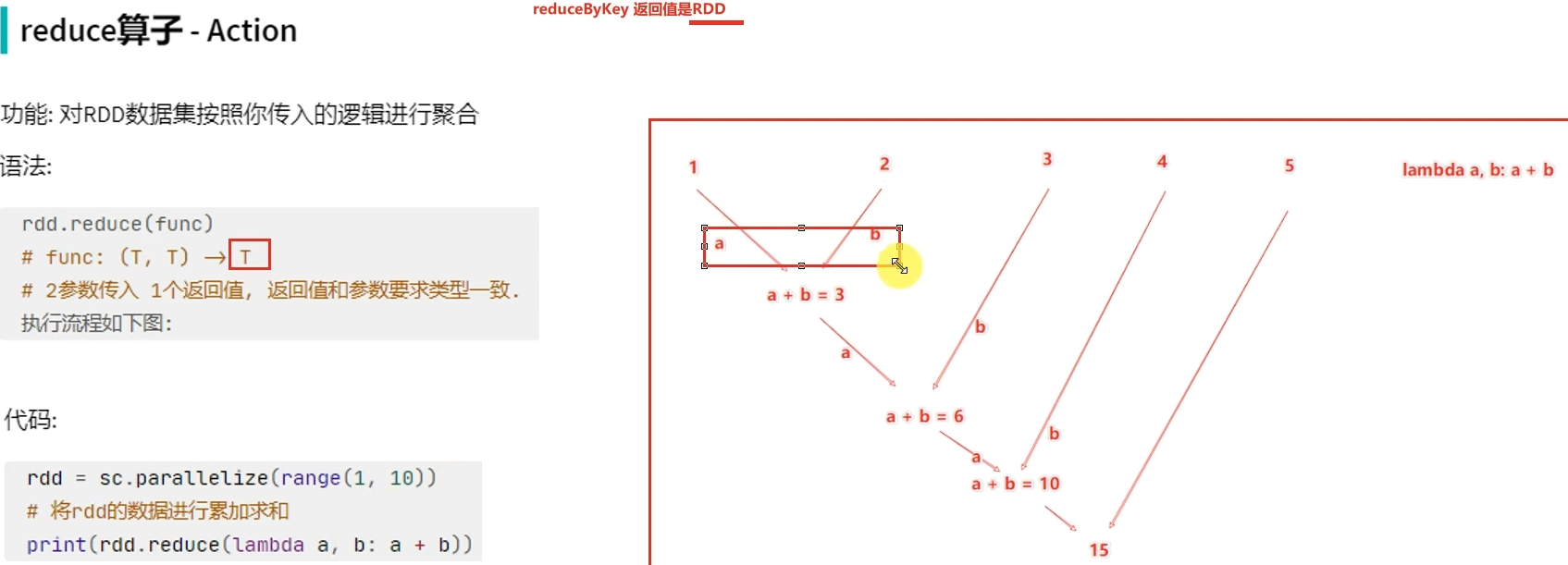
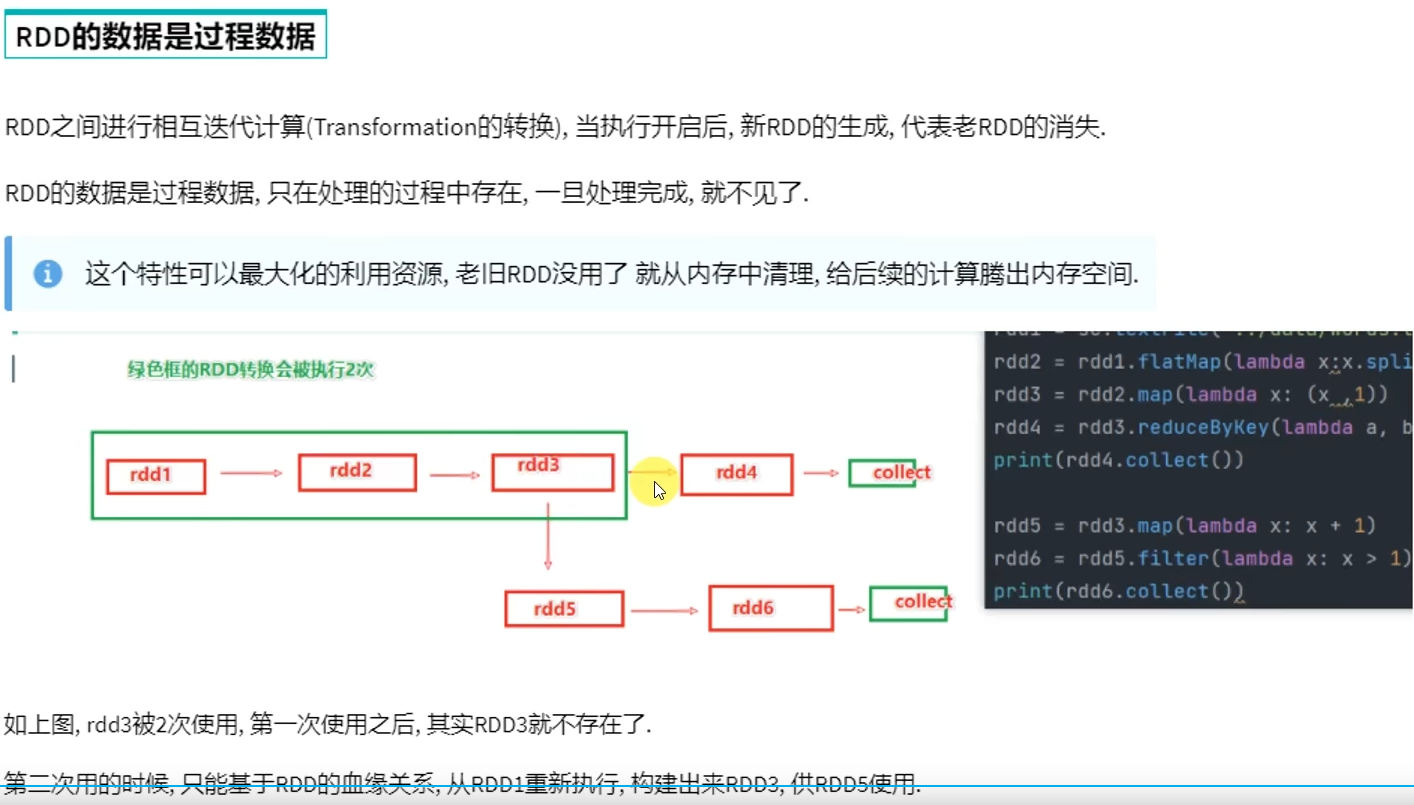
转换算子的返回值100%是RDD,而Action算子的返回值100%不是RDD。
转换算子是懒加载的,只有遇到Action才会执行。Action就是转换算子处理链条的开关。
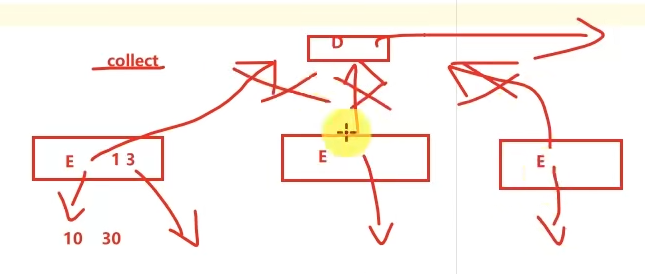
foreach和saveAsTextFile直接由Executor执行后输出,不会将结果发送到Driver上去(foreachPartition也是)
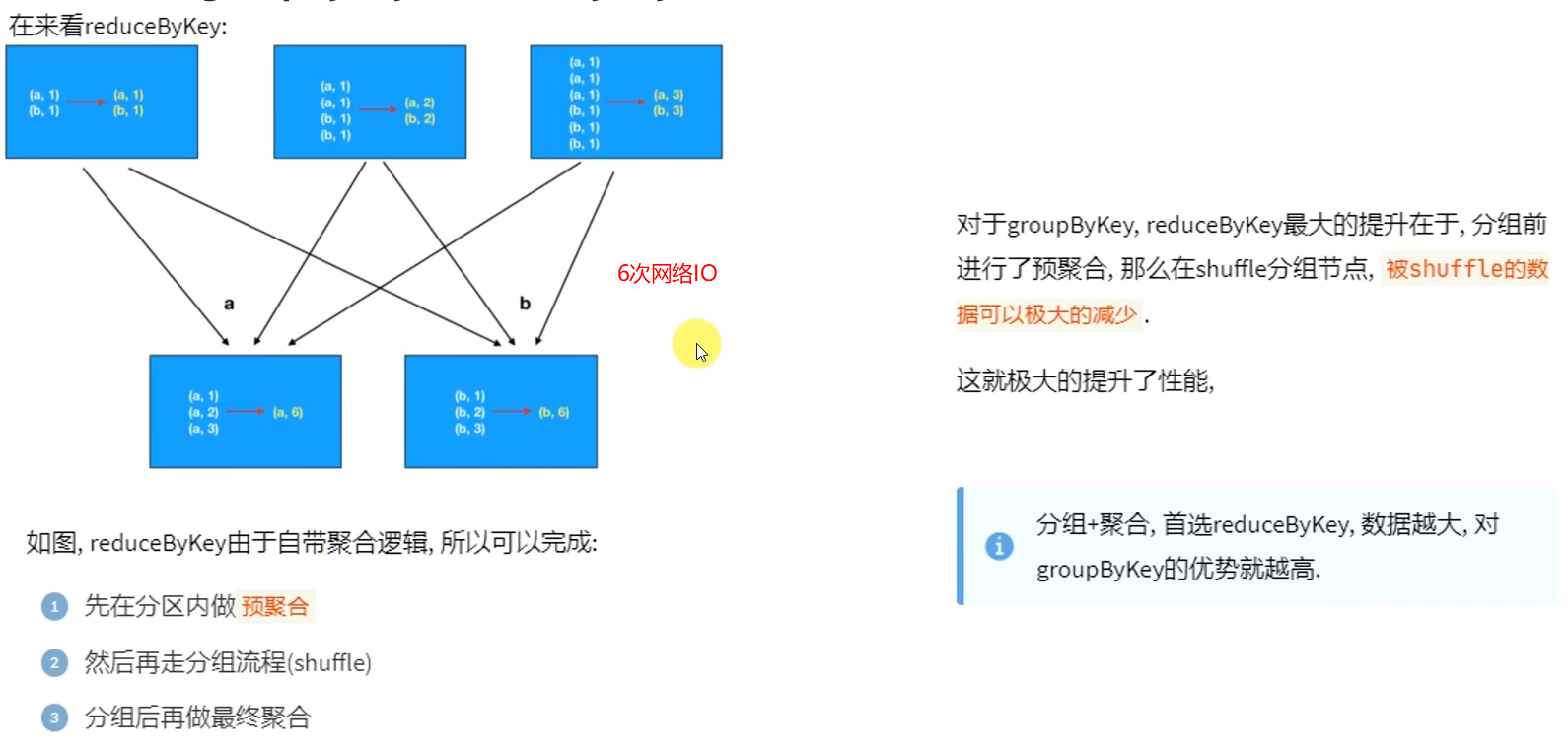
reduceByKey自带聚合逻辑,groupByKey不带
如果做数据聚合reduceByKey的效果更好,因为可以先聚合后shuffle再最终聚合,传输的IO小
mapPartitions带有返回值,是个转换算子;foreachPartition不带返回值,是个Action算子
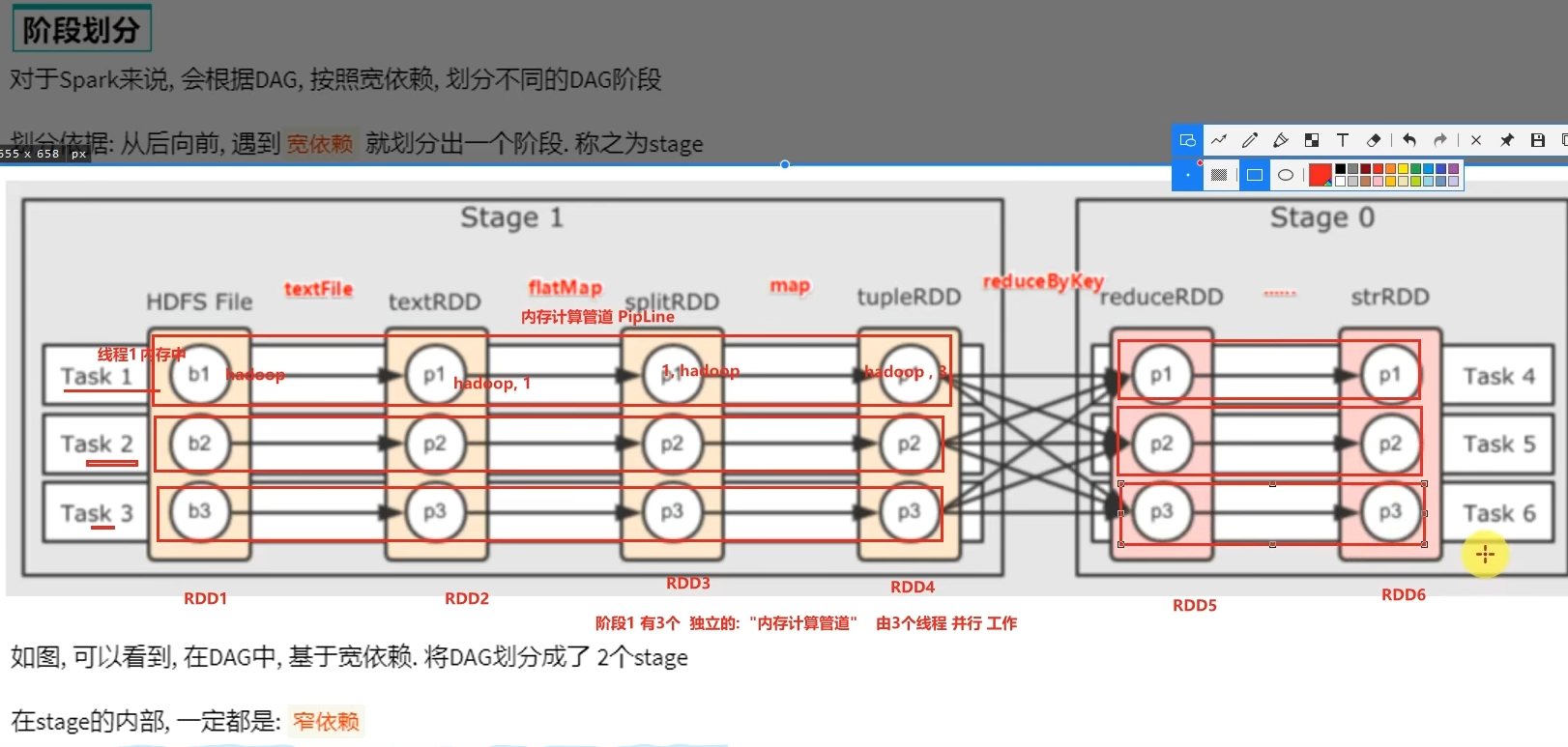
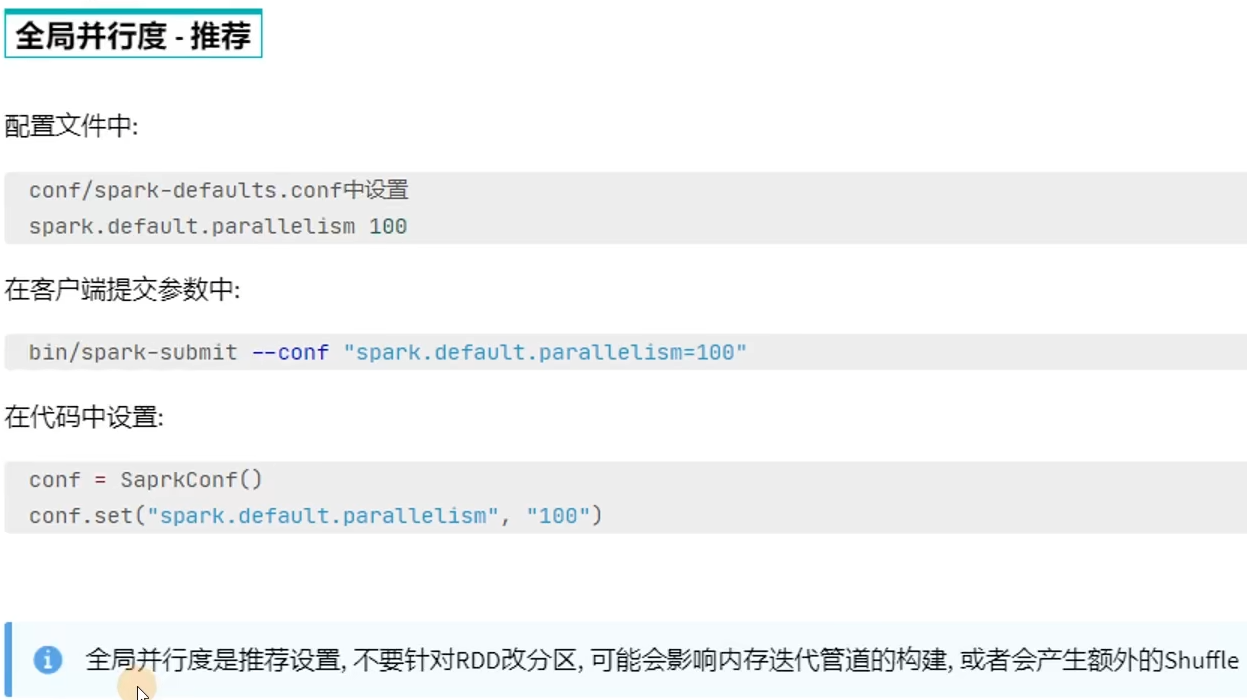
尽量不要增加分区,可能破坏内存迭代的计算管道

PS:linux下kill -9不能强制杀死spark-submit进程
参考资料:https://blog.csdn.net/intersting/article/details/84492999(原因分析)
https://blog.csdn.net/qq_41870111/article/details/126068306
https://blog.csdn.net/agonysome/article/details/125722926(如何清理僵尸进程)
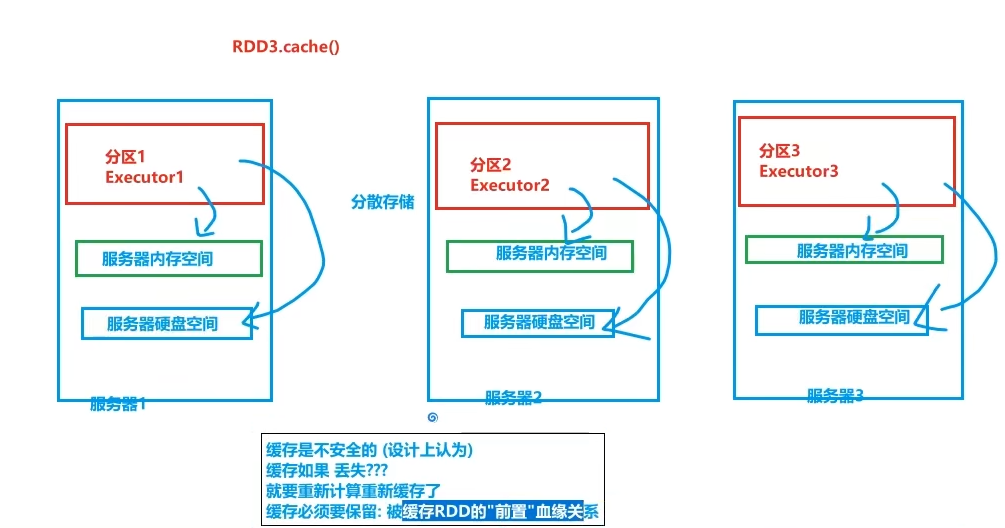


Cache是轻量化保存RDD数据,可存储在内存和硬盘,是分散存储,设计上数据是不安全的(保留RDD血缘关系)
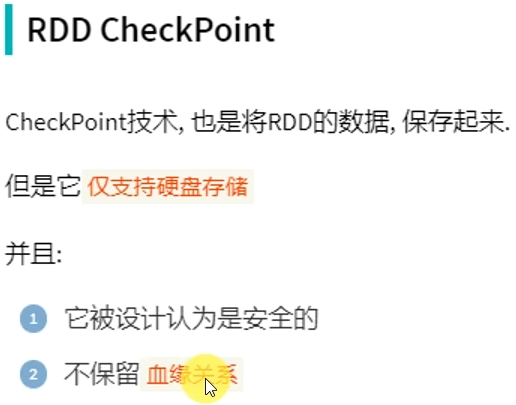
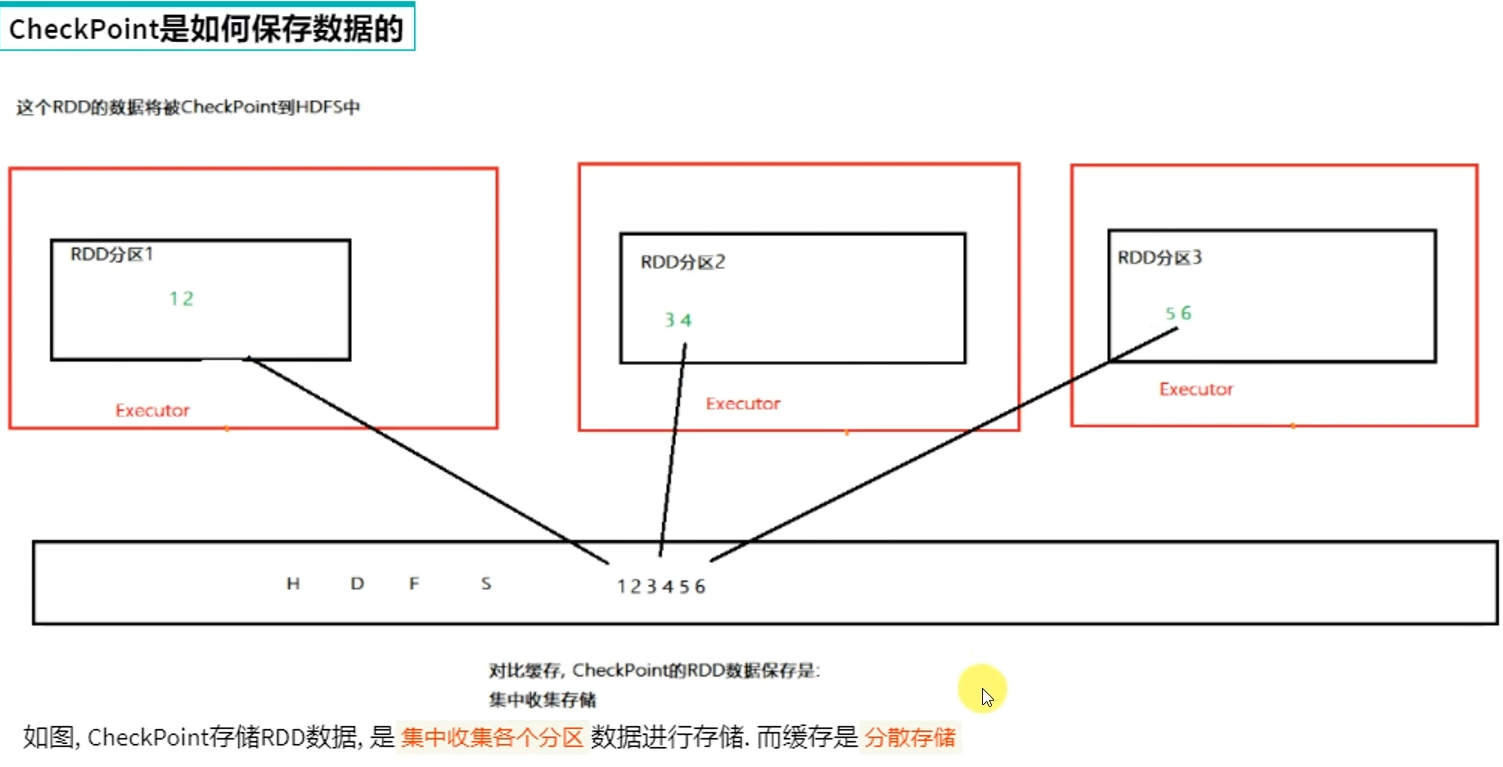
CheckPoint是重量级保存RDD数据,是集中存储,只能存储在硬盘(HDFS)上,设计上是安全的(不保留RDD血缘关系)
Cache性能更好,因为是分散存储,各个Executor并行,效率高,可以保存到内存中(占内存),更快
CheckPoint比较慢,因为是集中存储,涉及到网络IO,但是存储在HDFS上更加安全(多副本)

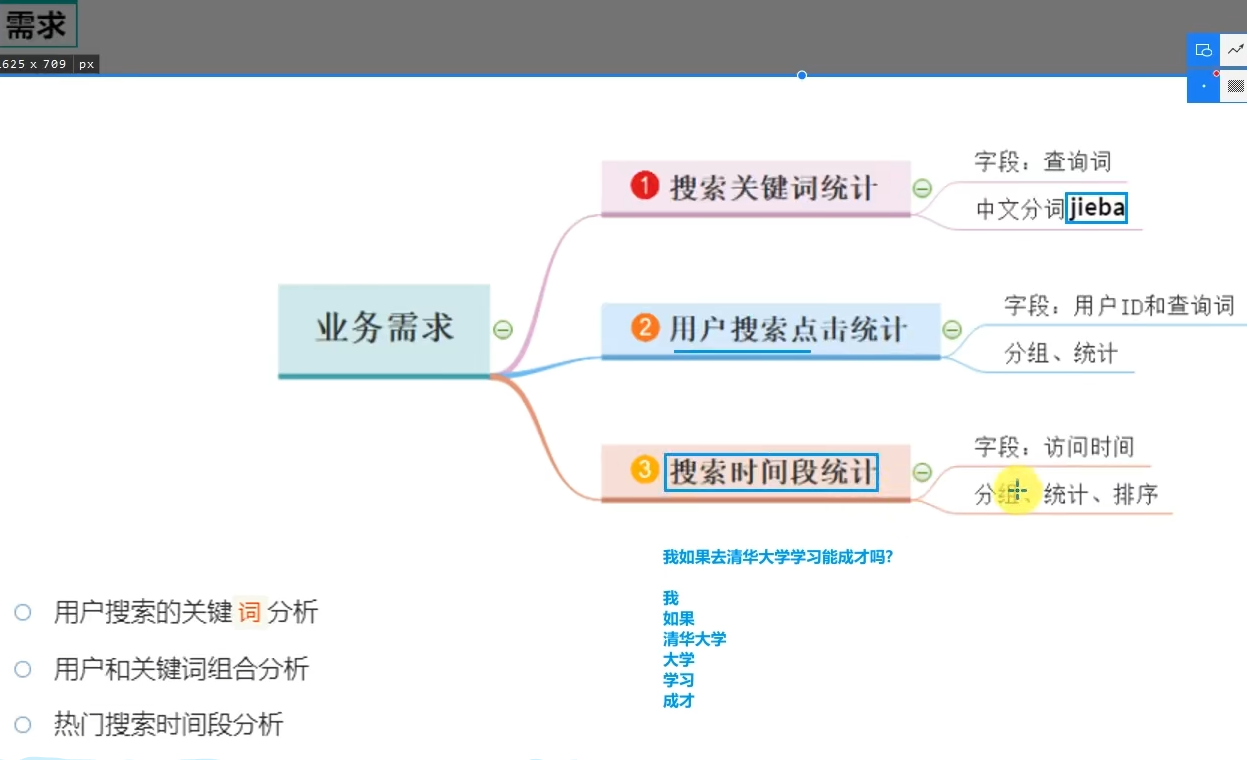
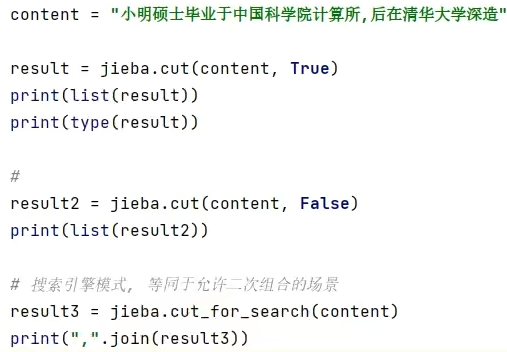

jieba库
因为YARN是集群运行,Executor可以在所有服务器上执行,所以每个服务器都需要有jieba库提供支撑
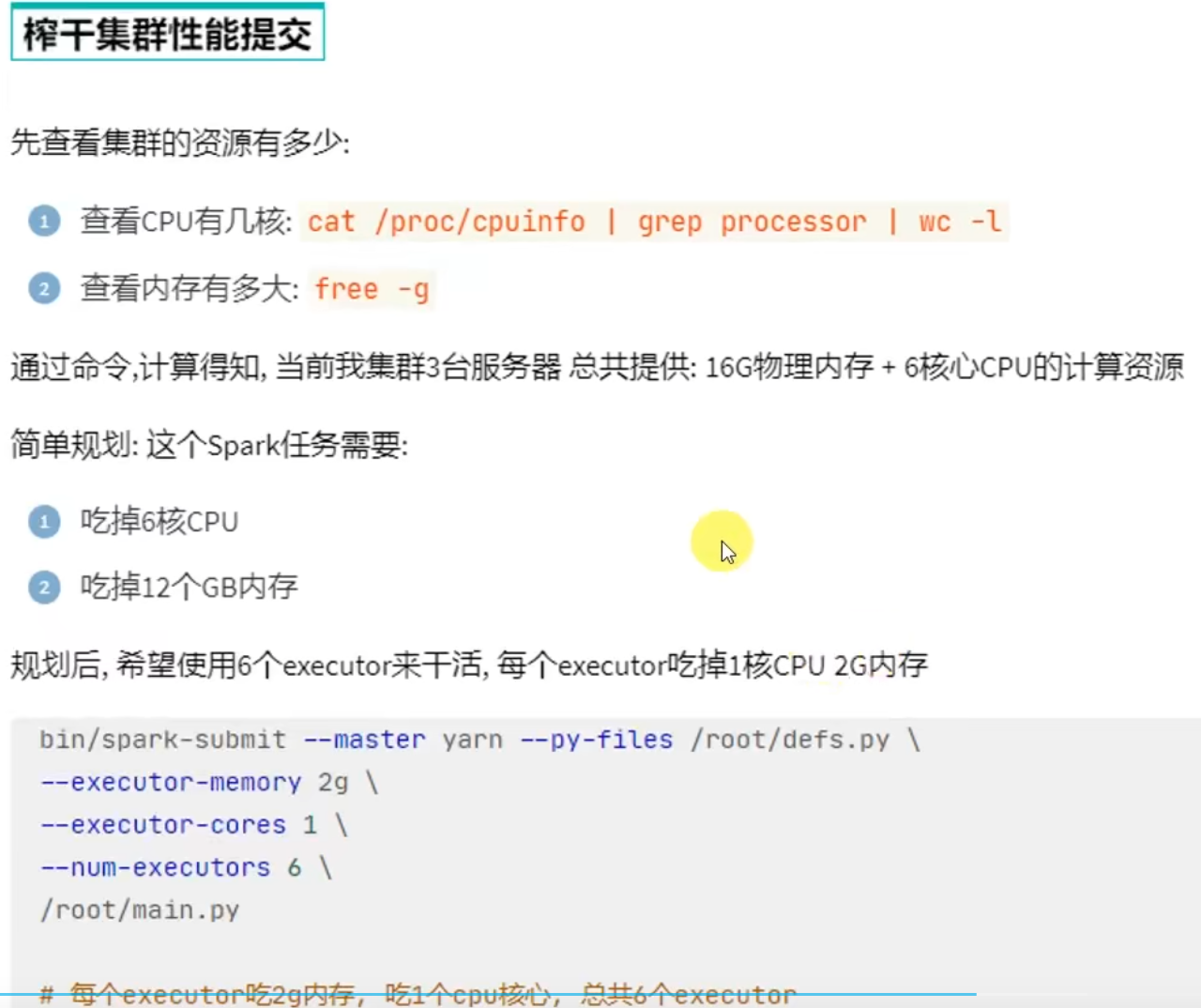
计算CPU核心和内存量,通过–executor-memory指定executor内存,通过–executor-cores指定executor的核心数
通过–num-executors指定总executor数量
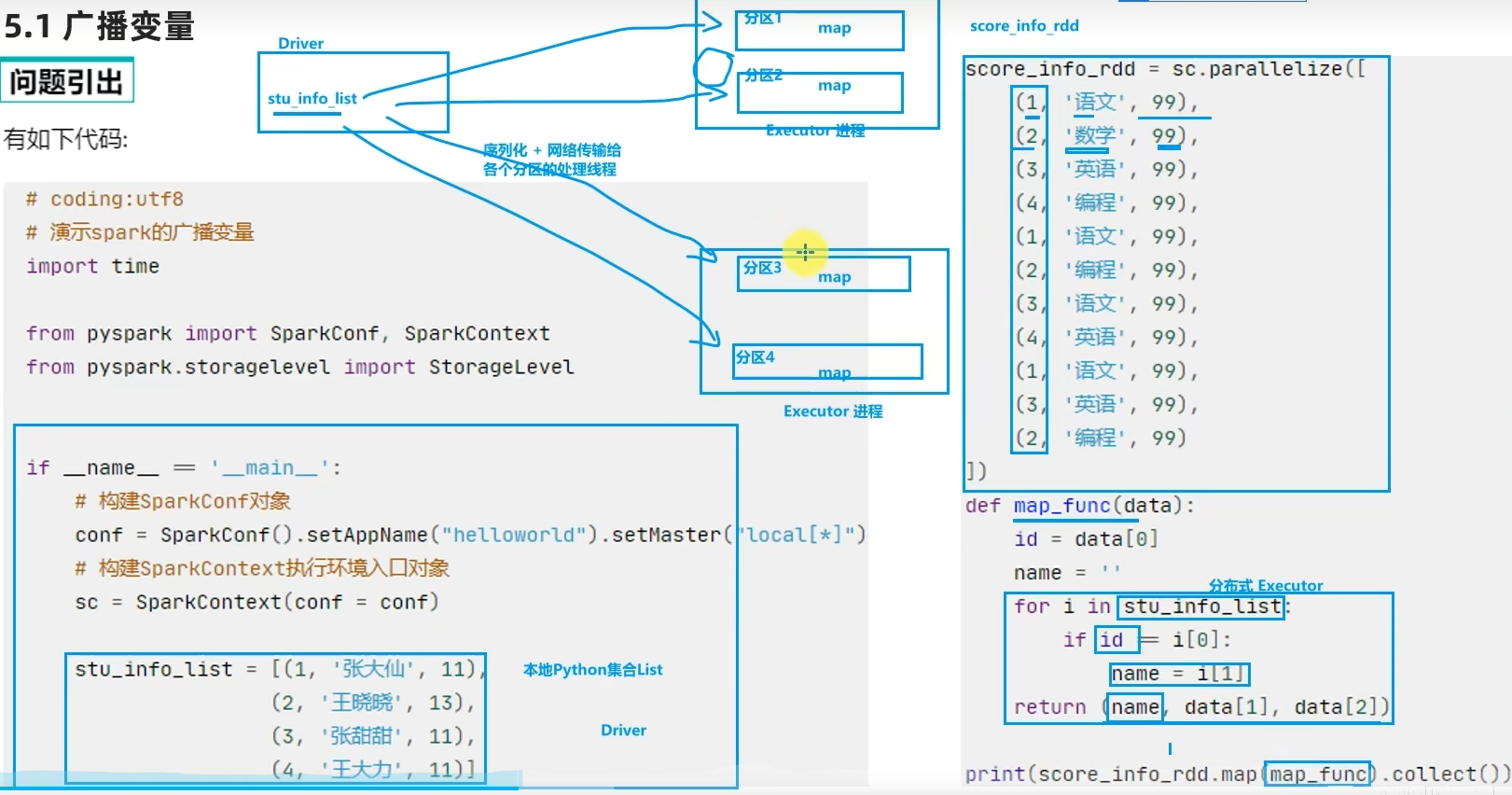
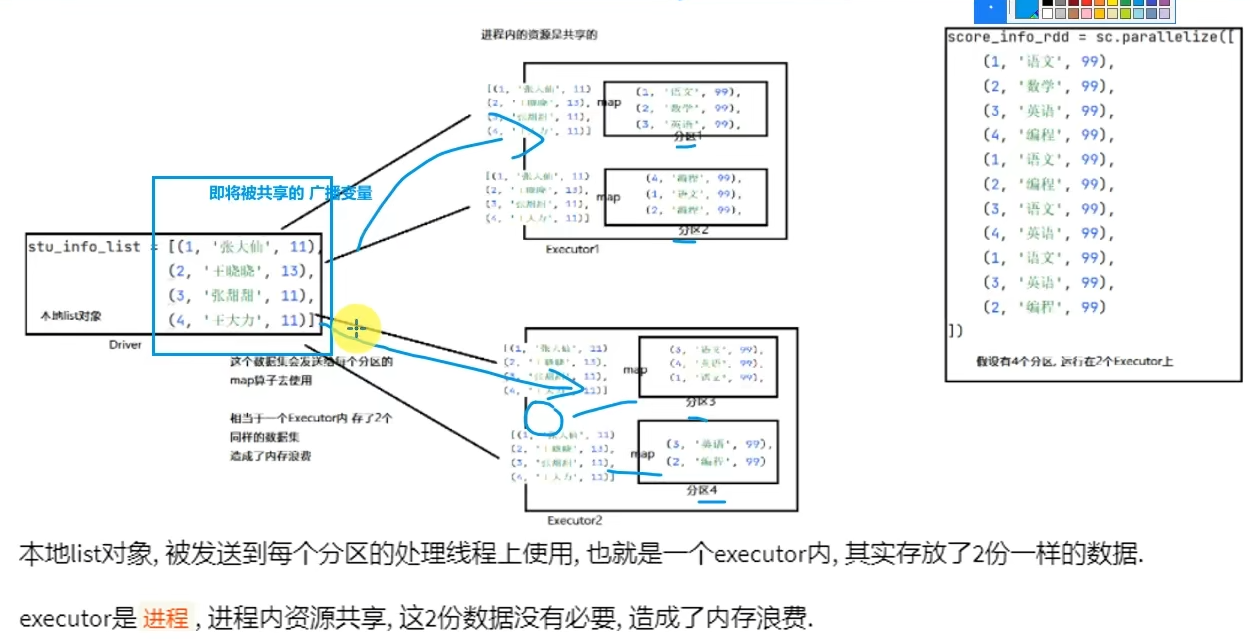



分布式集合RDD和本地集合进行关联使用的时候,降低内存占用以及减少网络IO传输,提高性能。
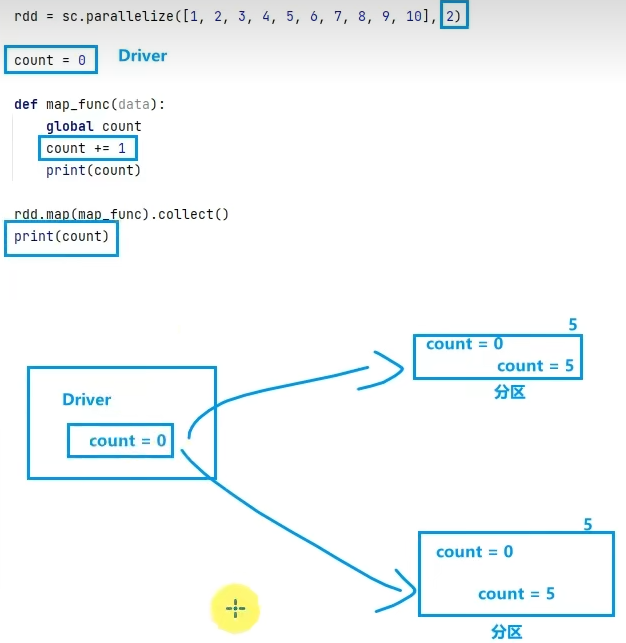
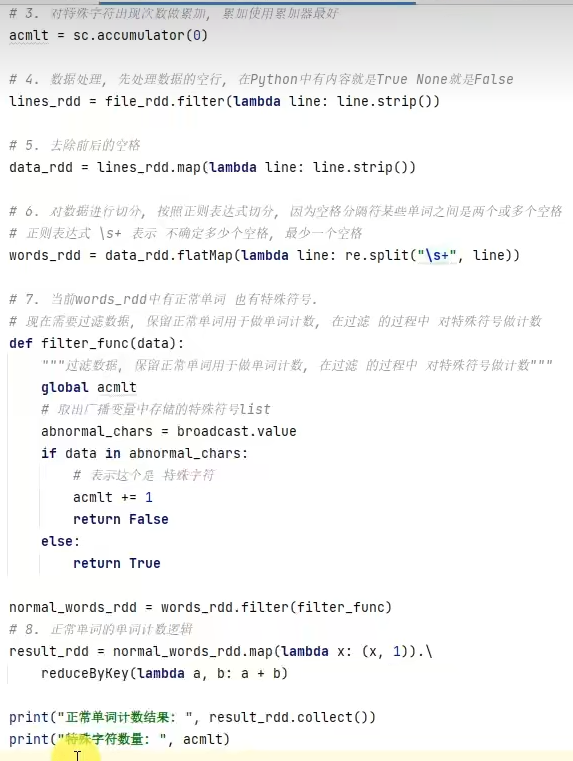
分布式代码执行中,进行全局累加。


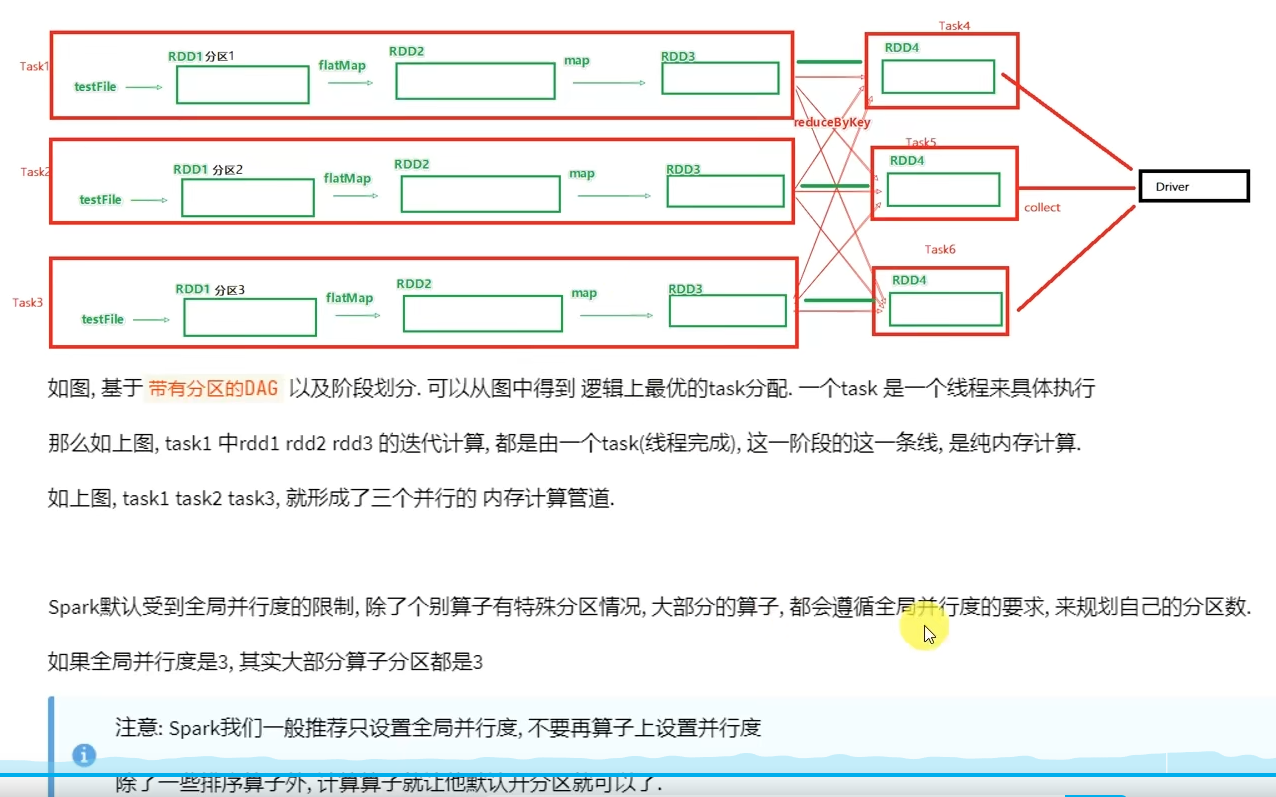








如果一台服务器内开多个executor,会进行进程间的通信(所以建议一台服务器就开一个executor)


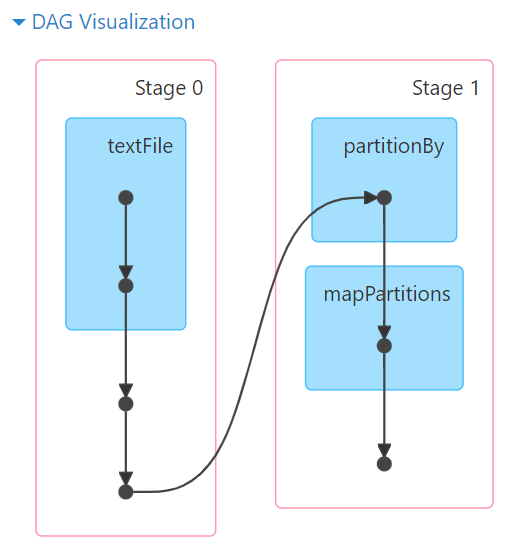
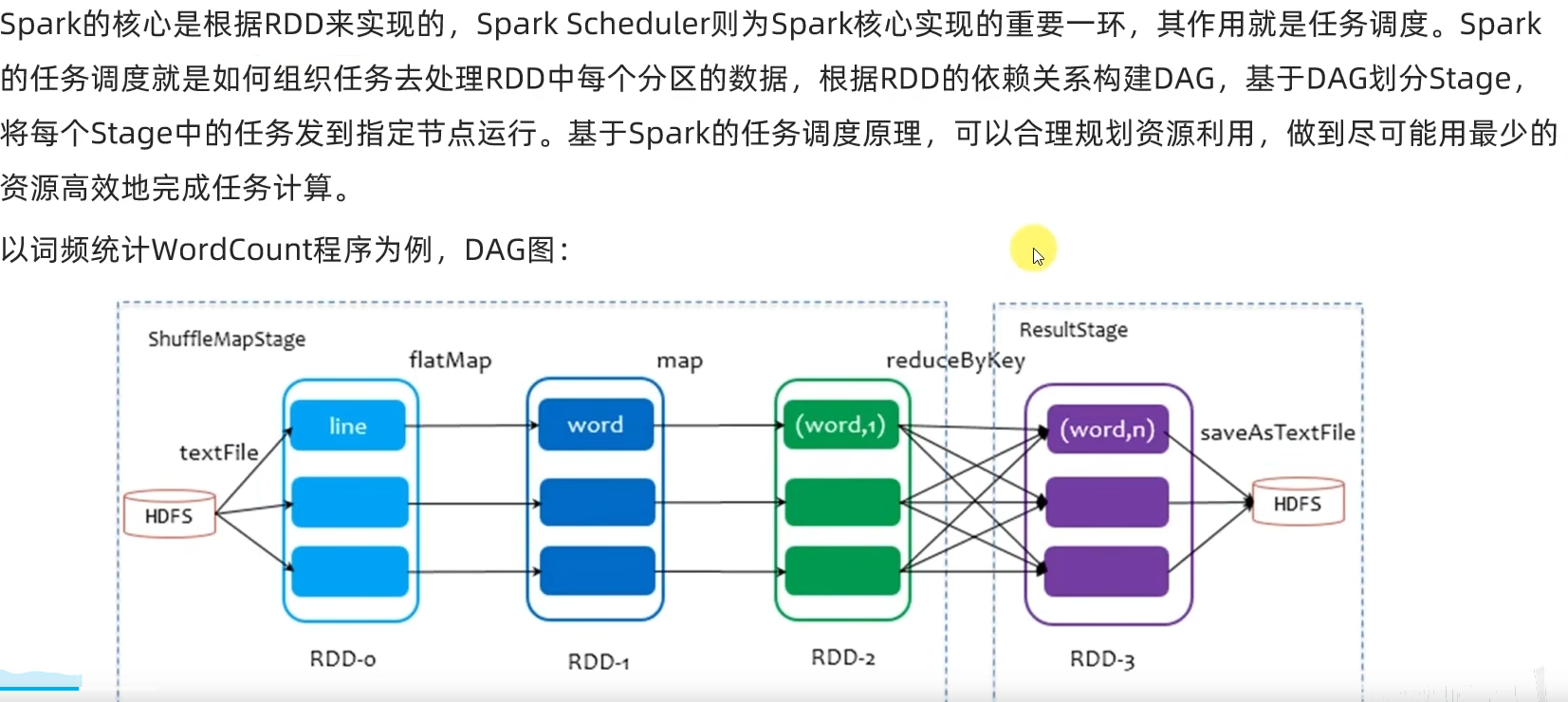
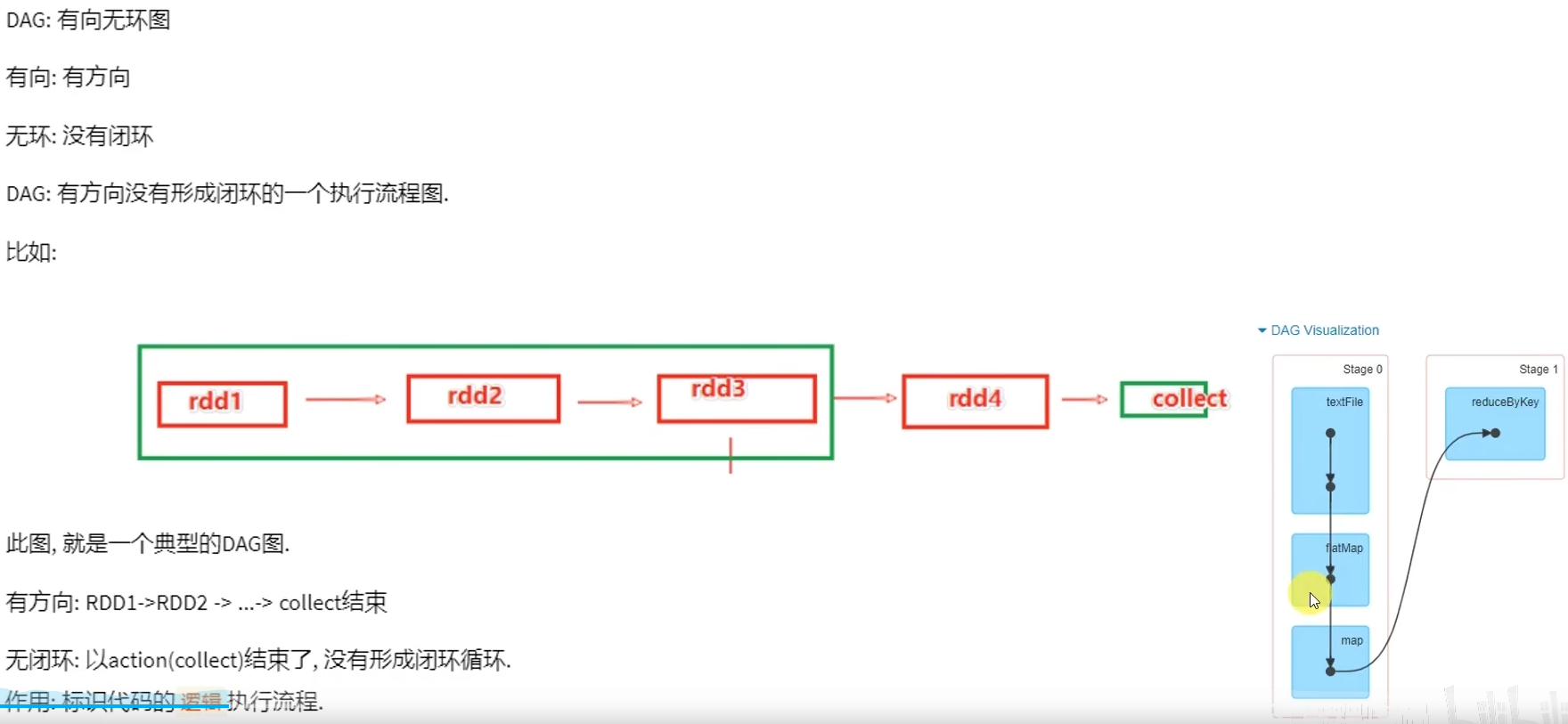
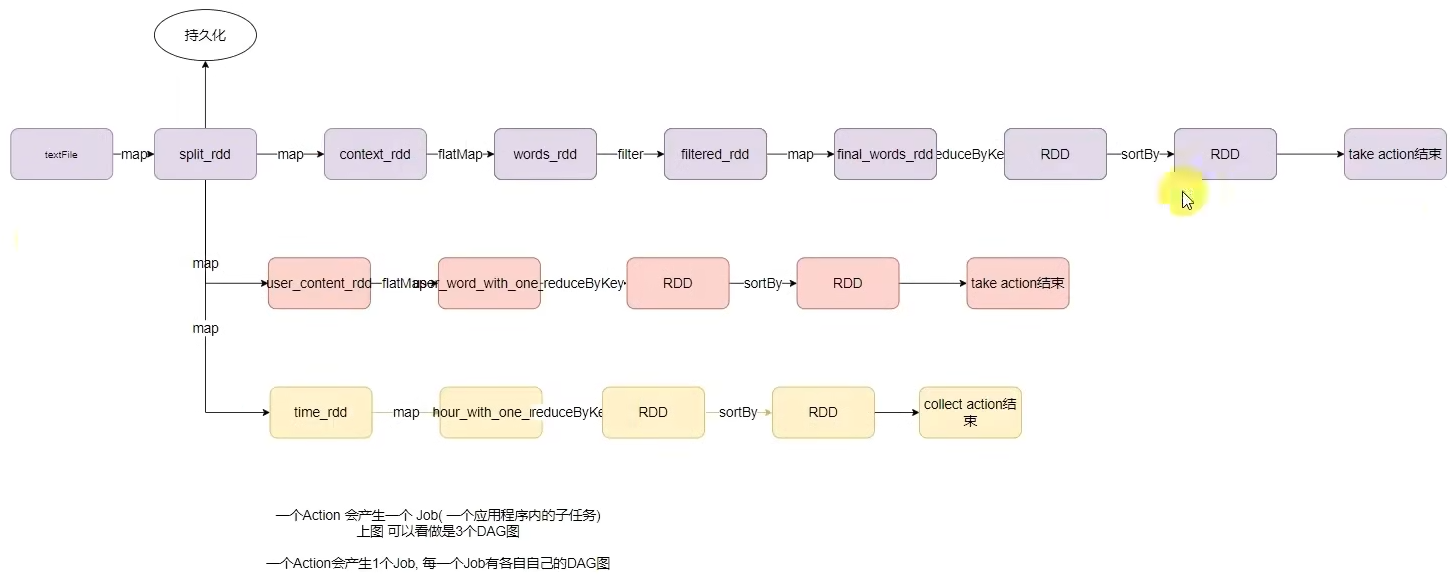
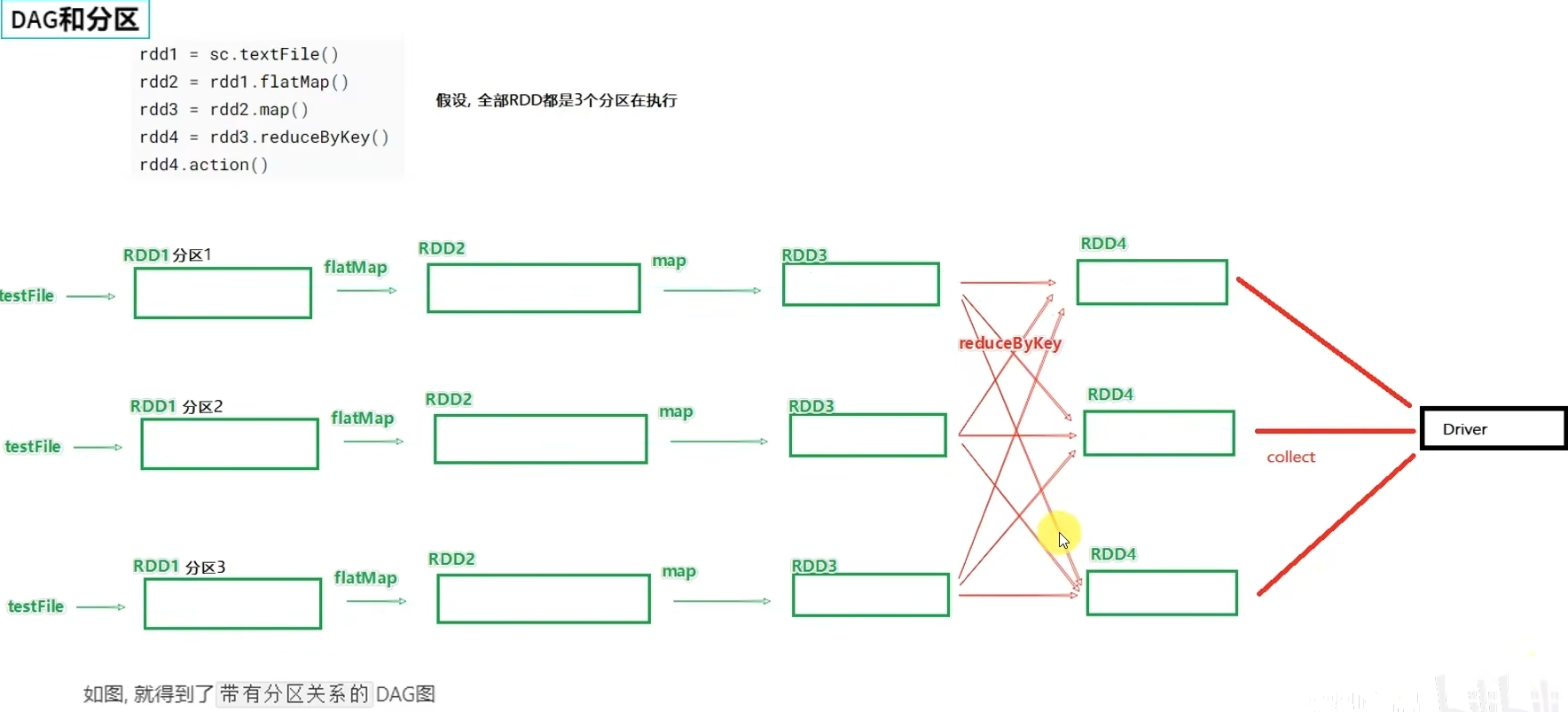
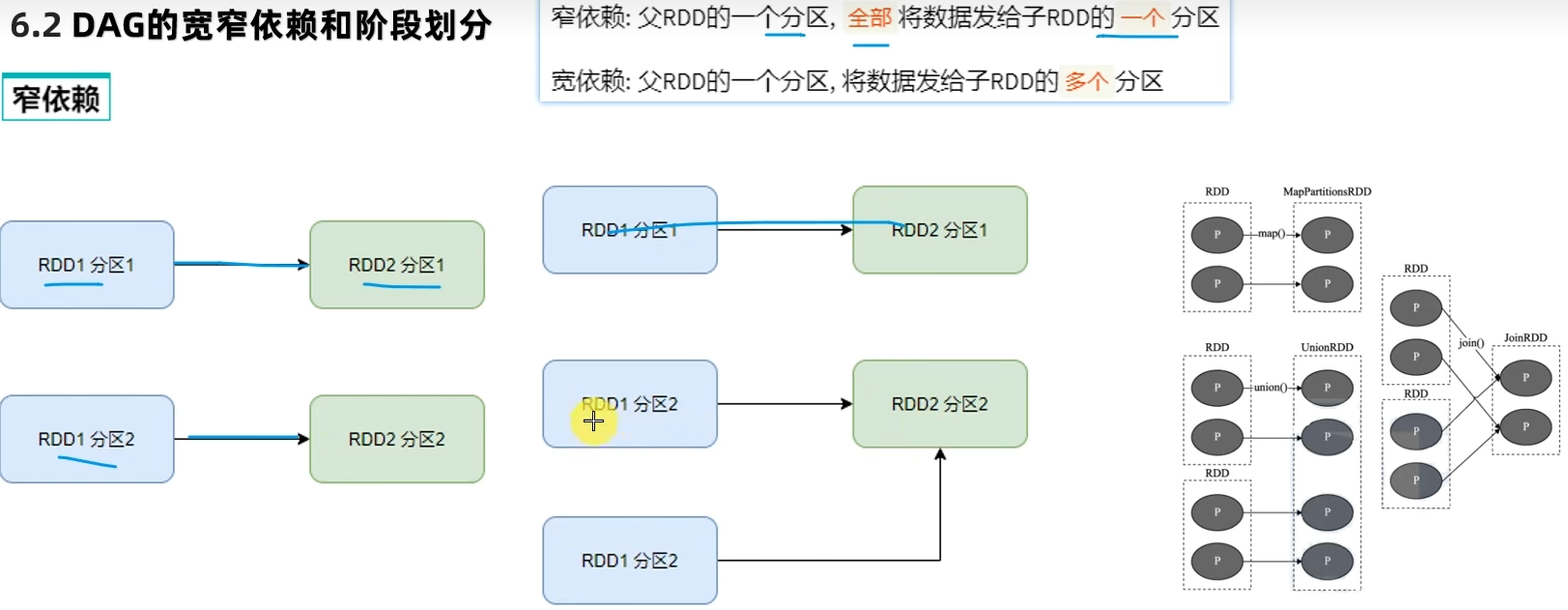
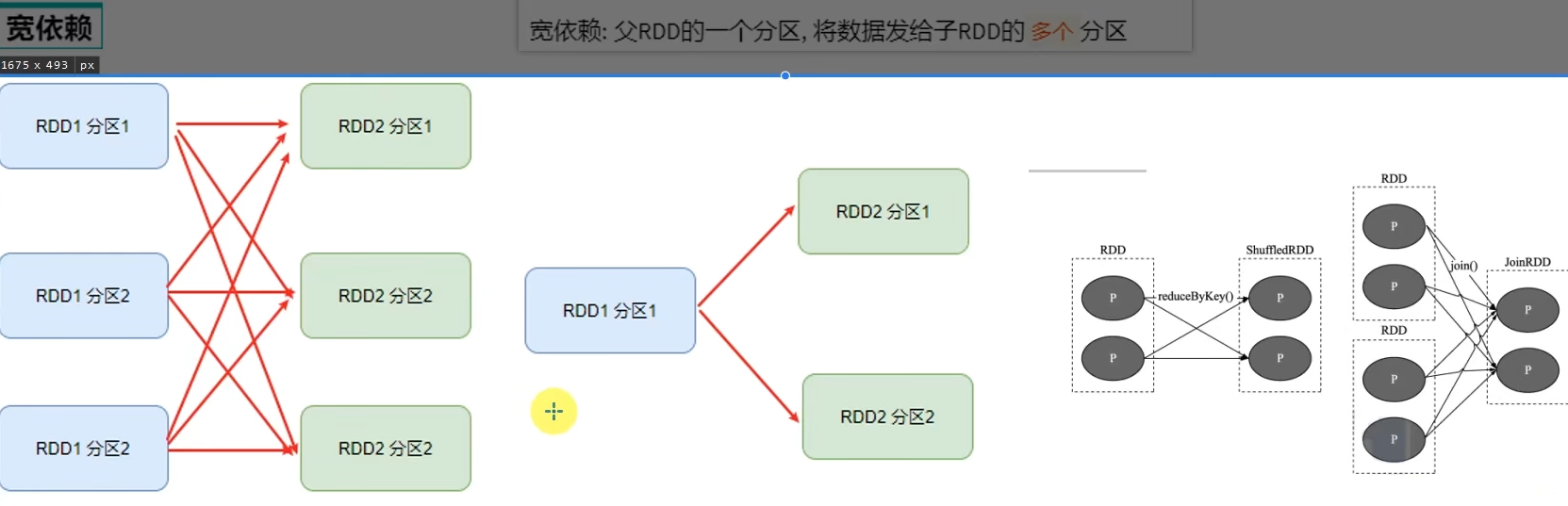
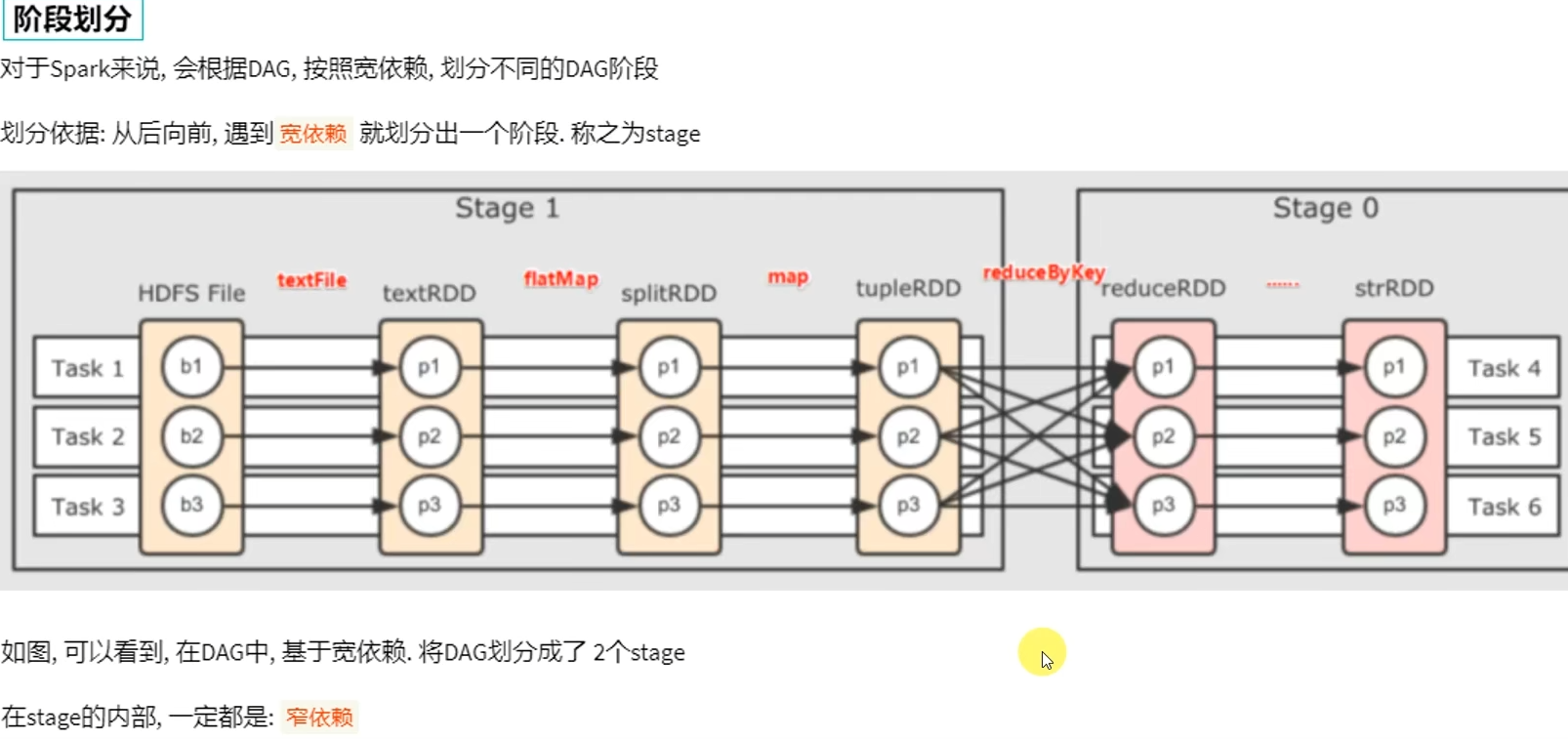
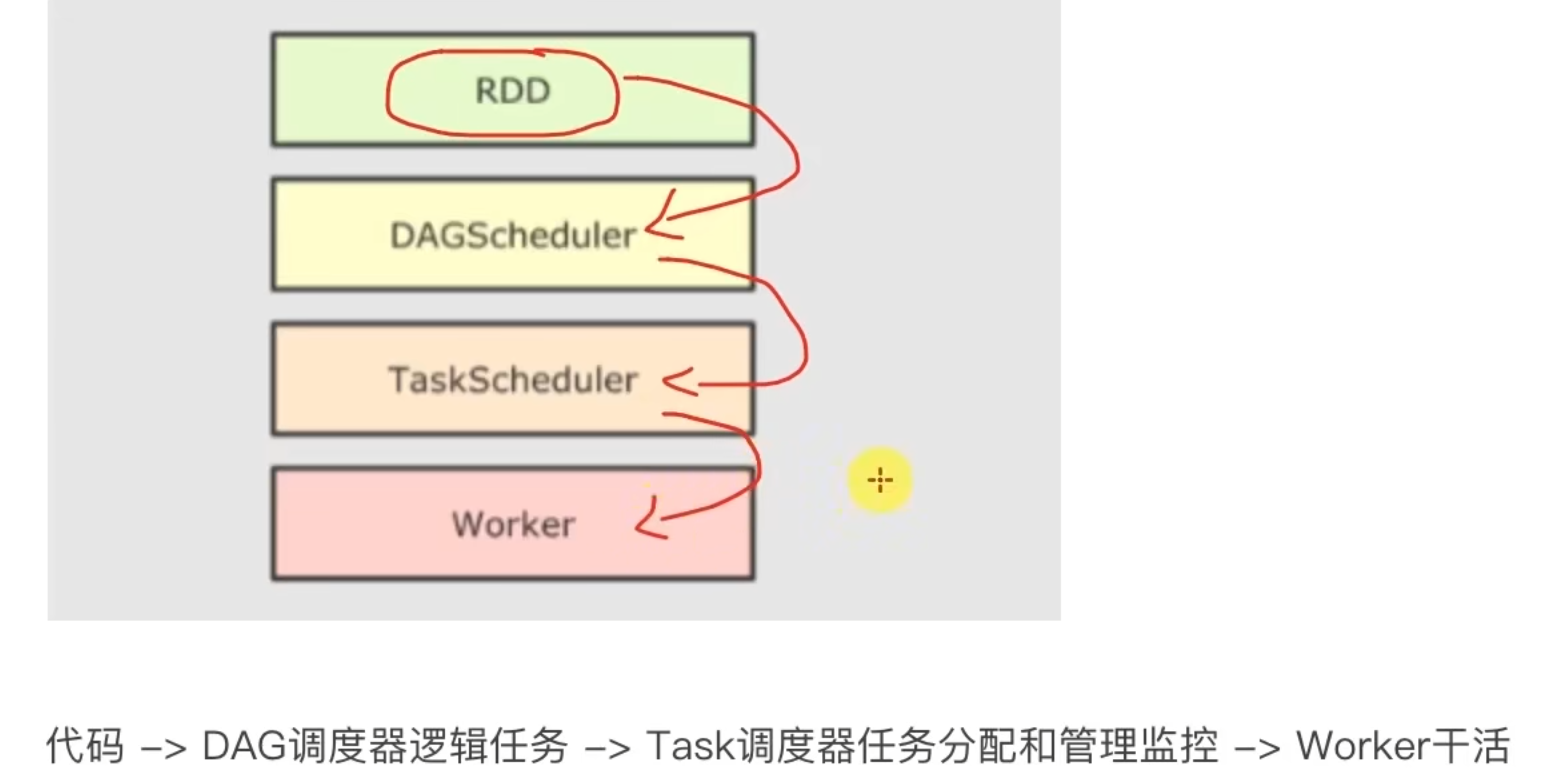
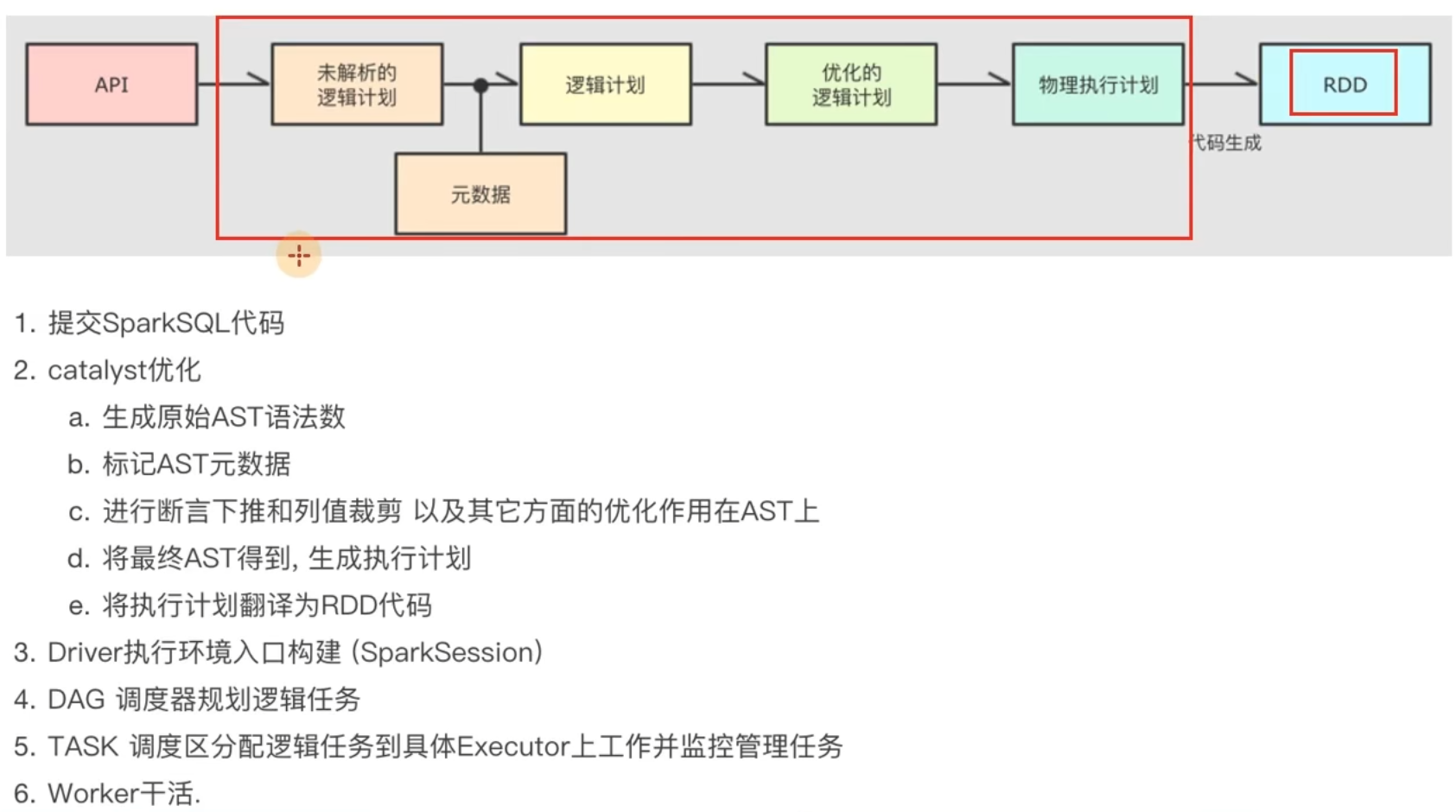
DAG有向无环图,用以描述任务执行流程,主要作用是协助DAG调度器构建Task分配用以做任务管理。
基于DAG的宽窄依赖划分阶段,阶段内部都是窄依赖可以构建内存迭代的管道。
构建Task分配用以做任务管理。






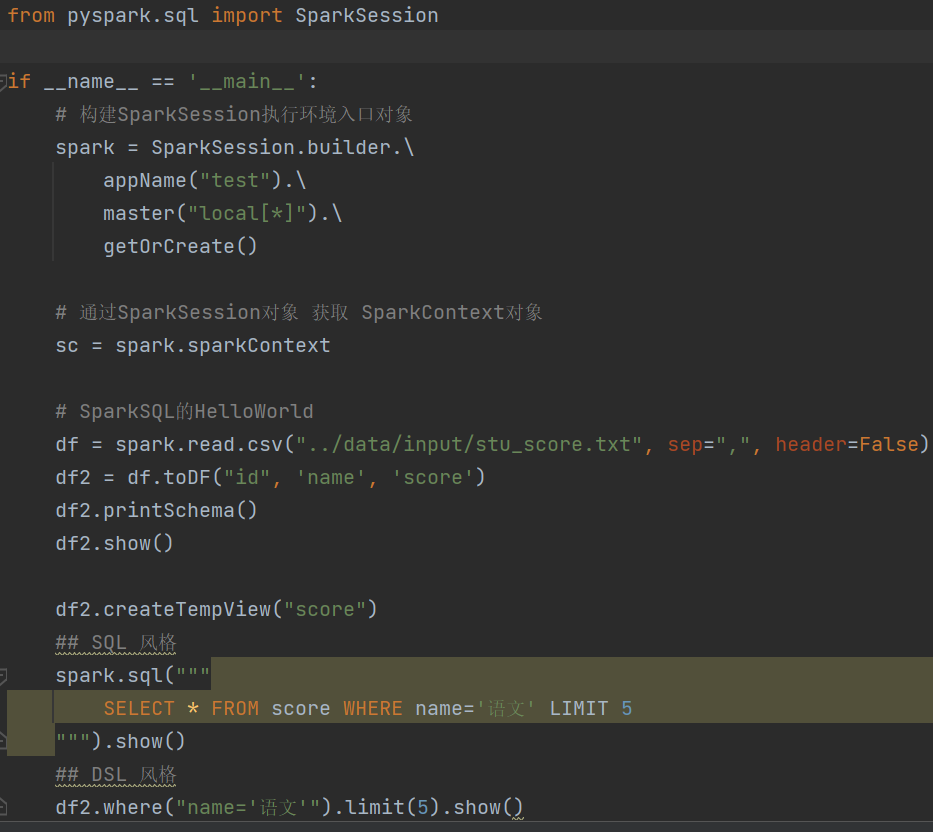

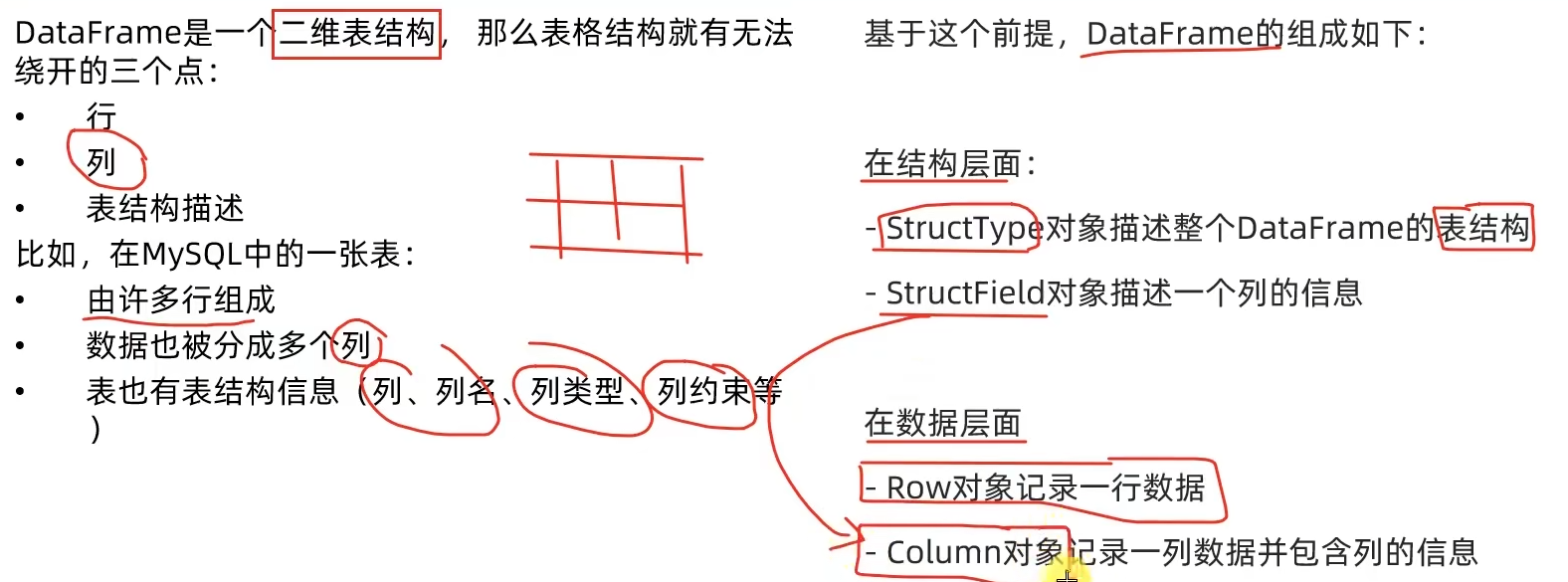


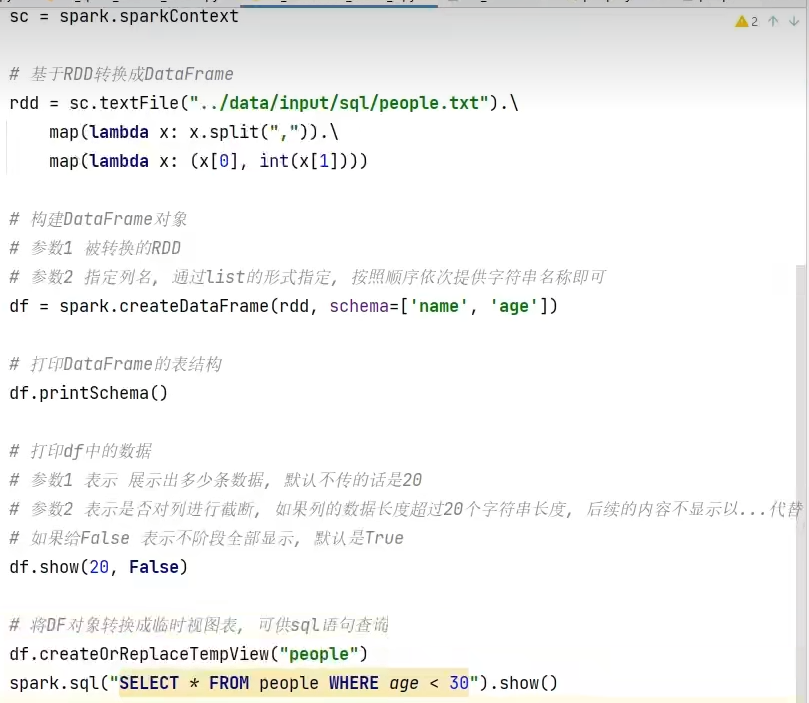
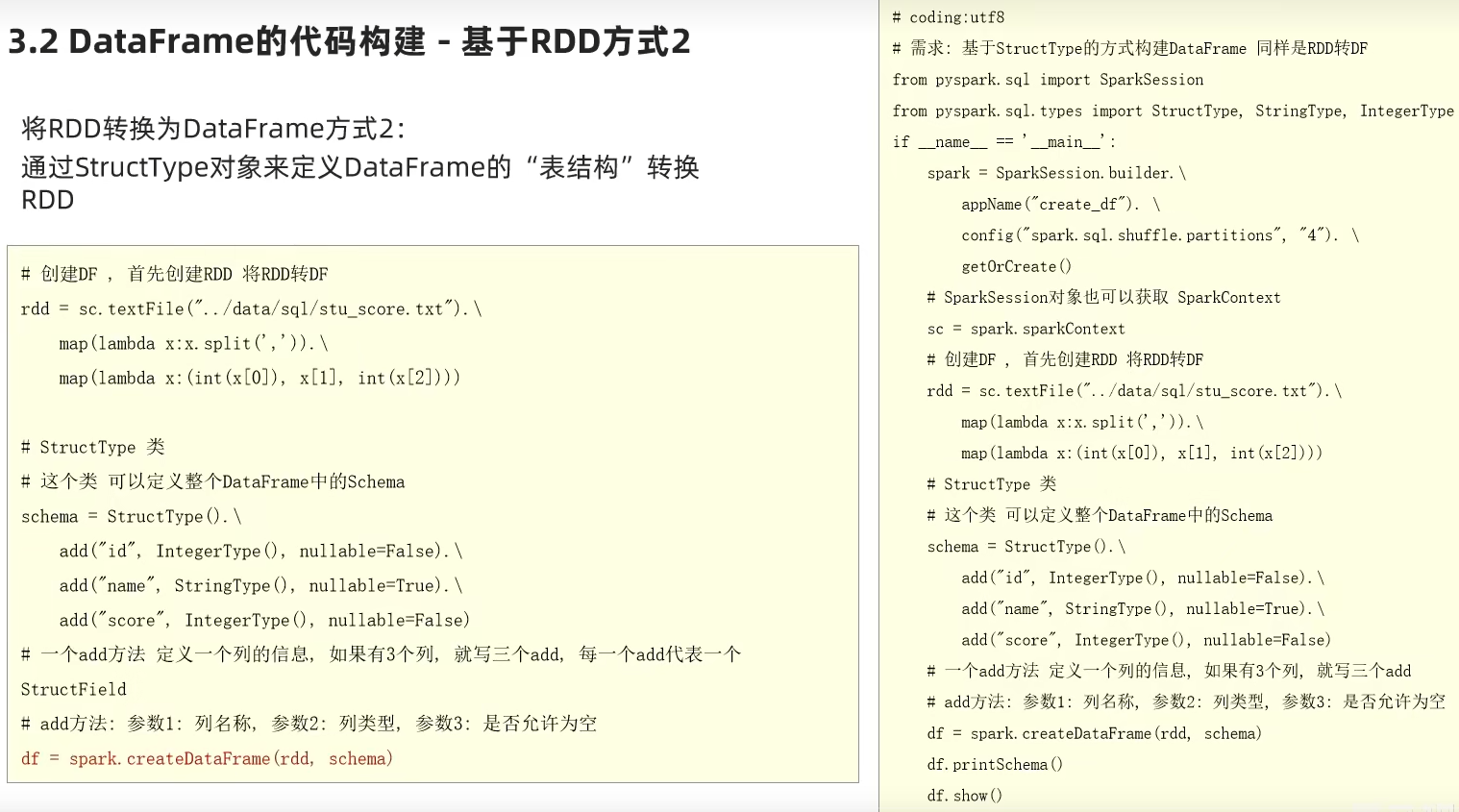
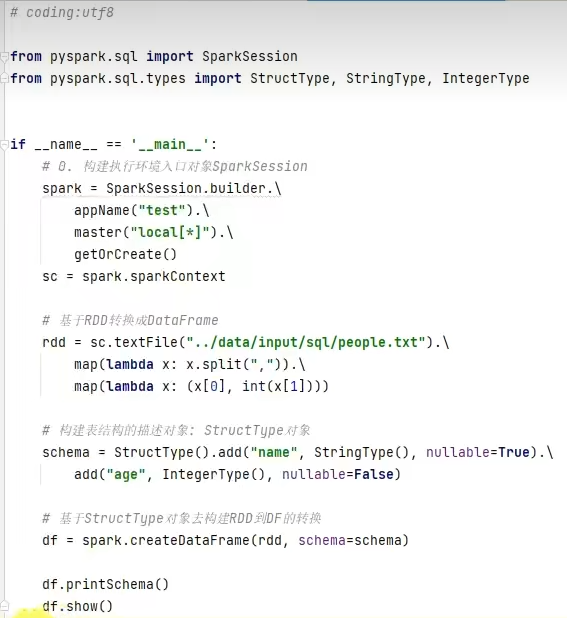
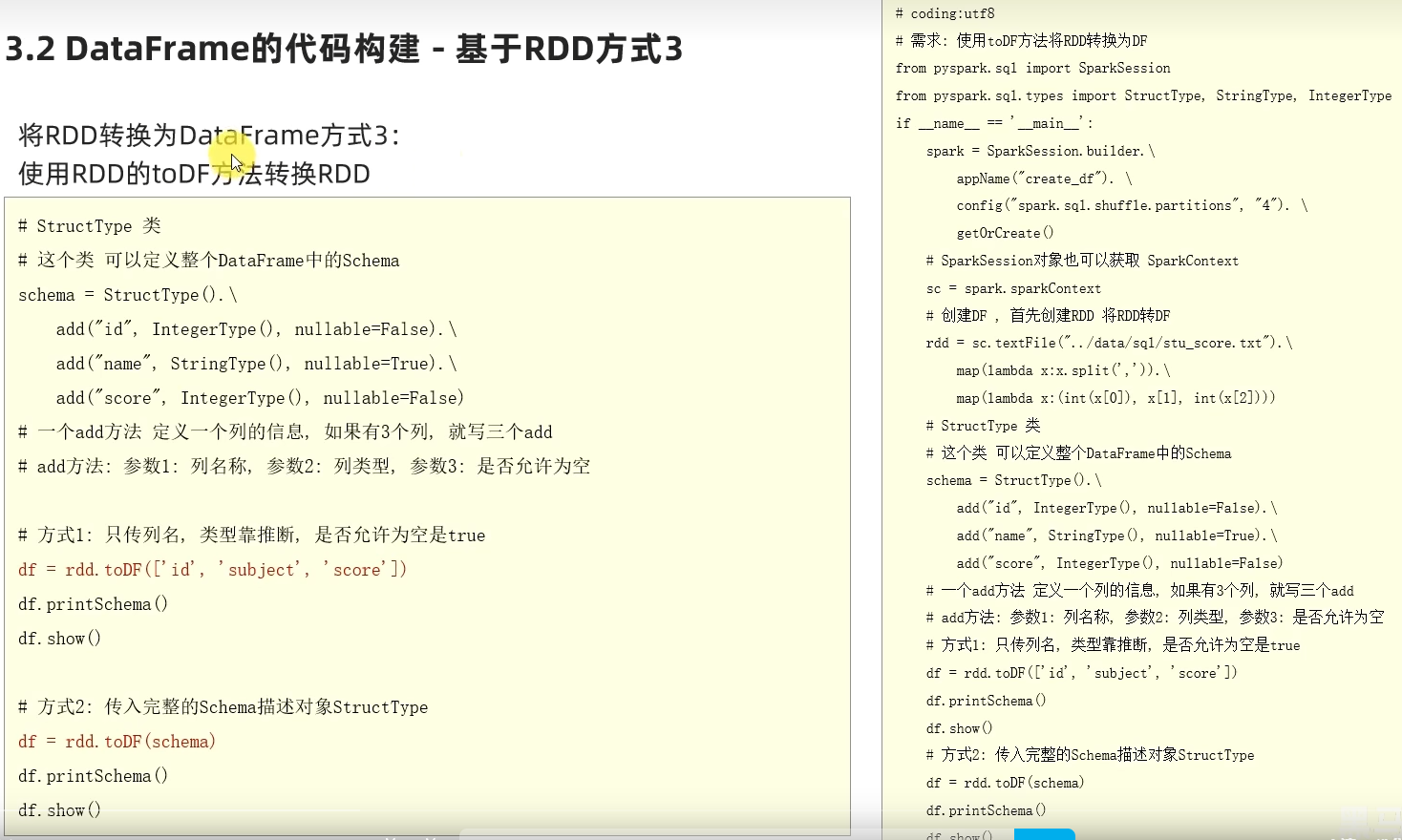
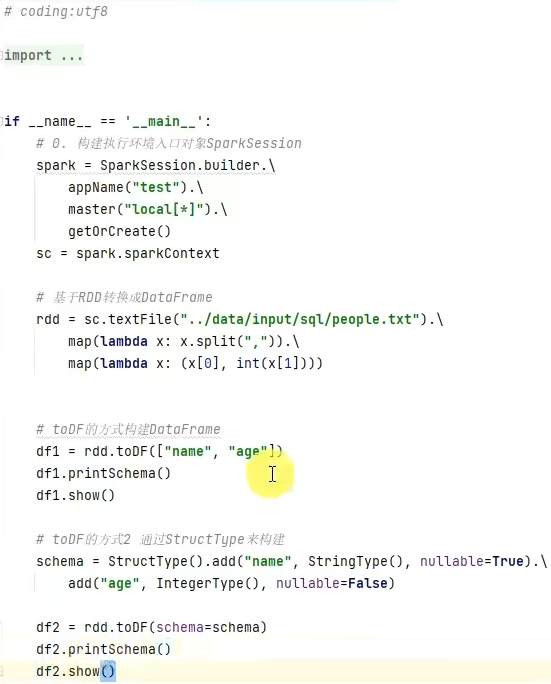
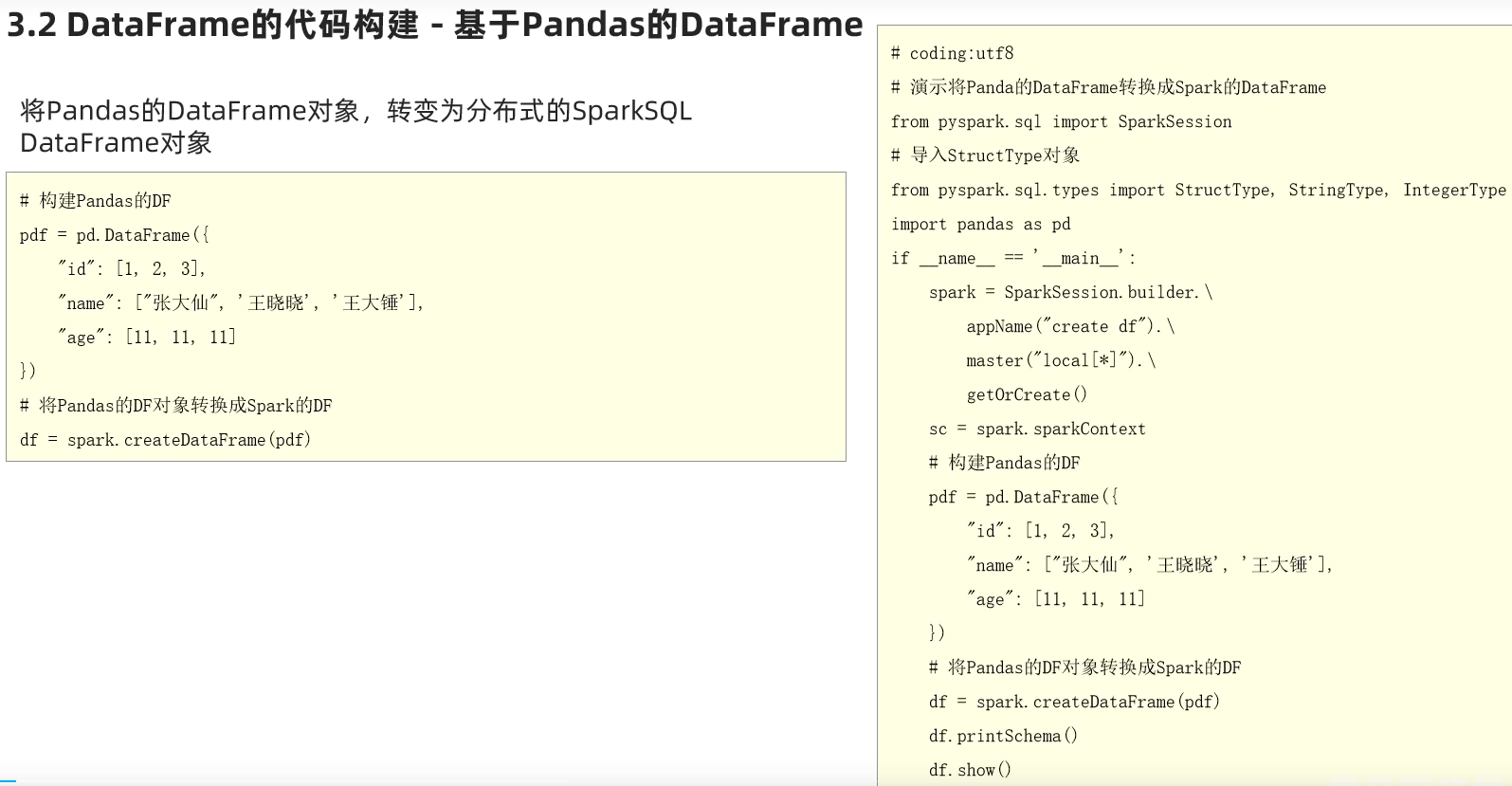

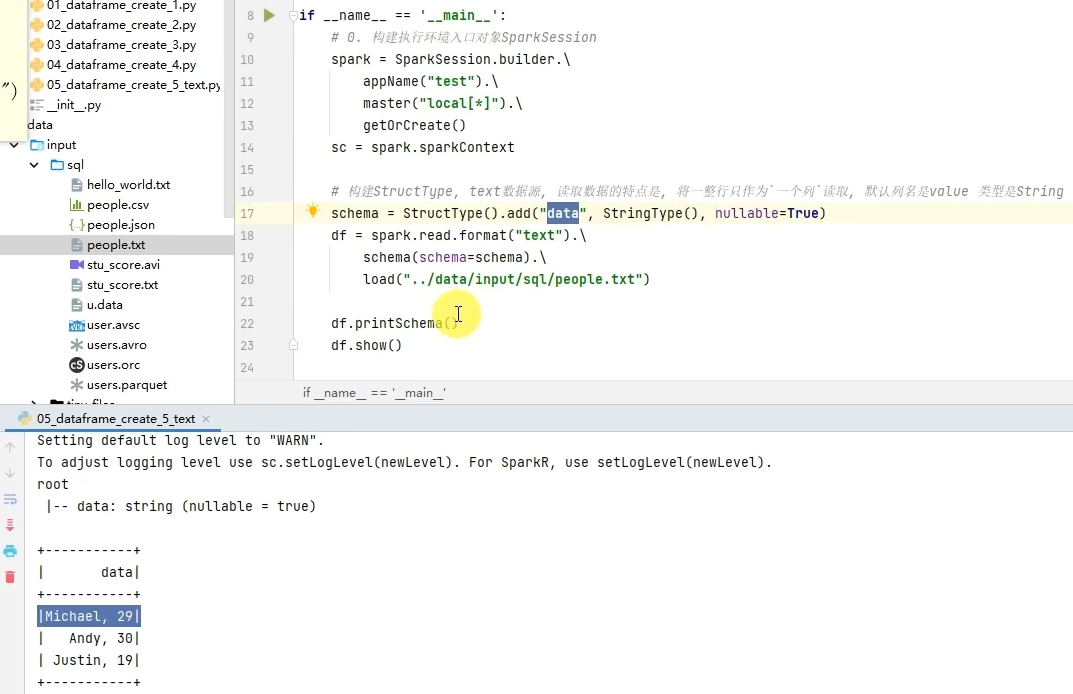


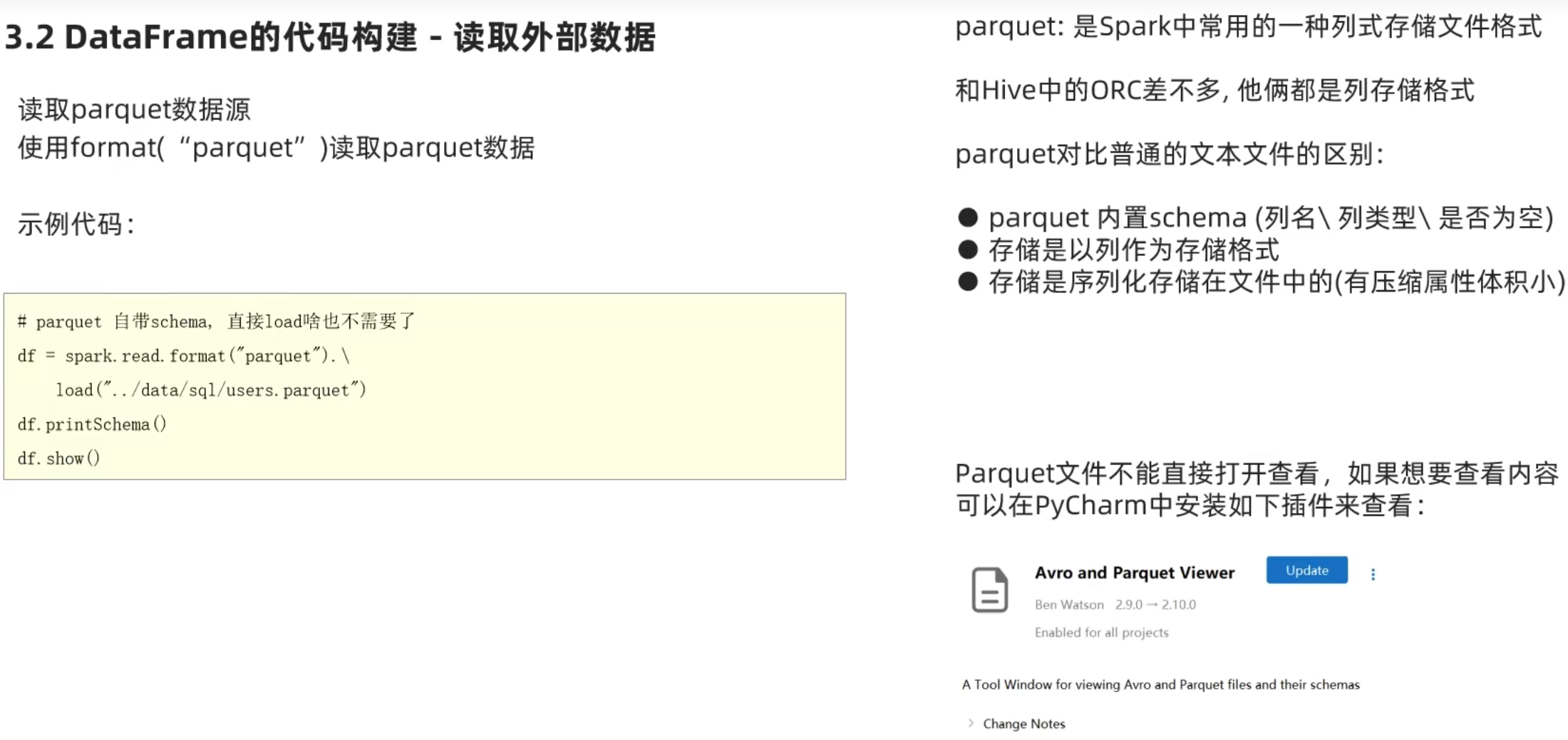

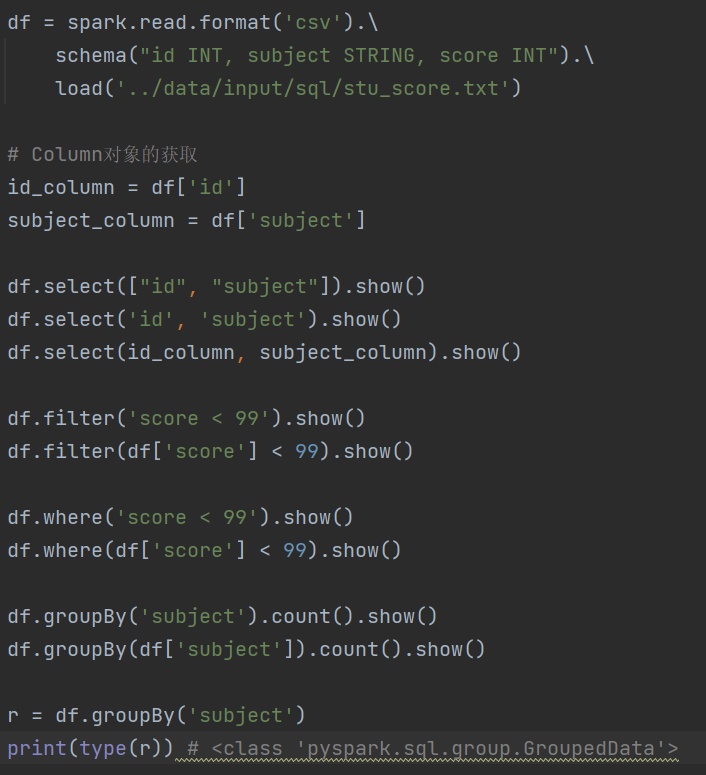

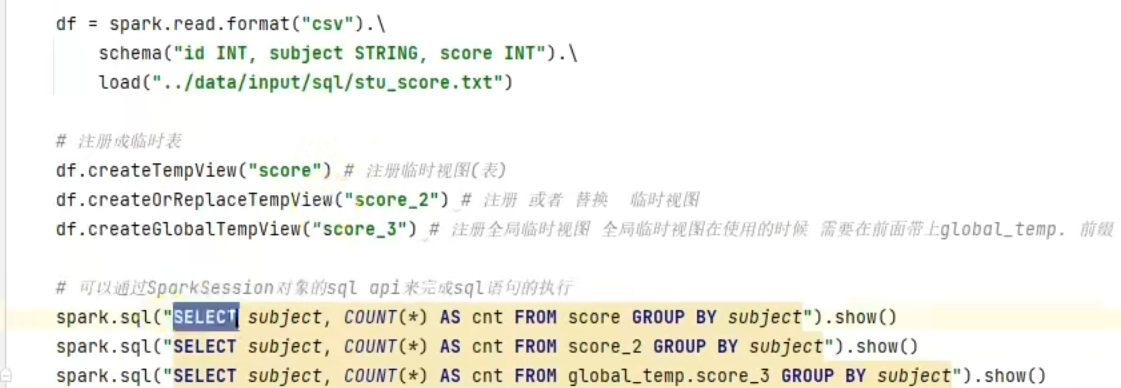


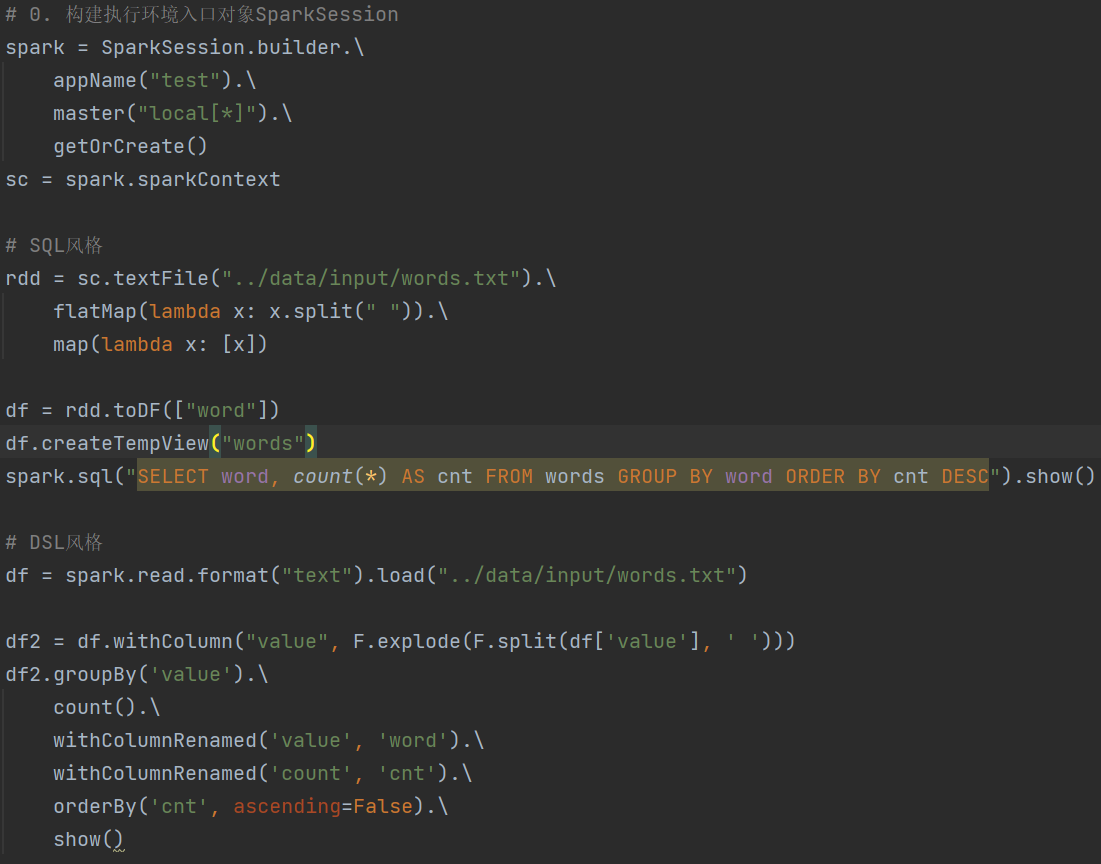
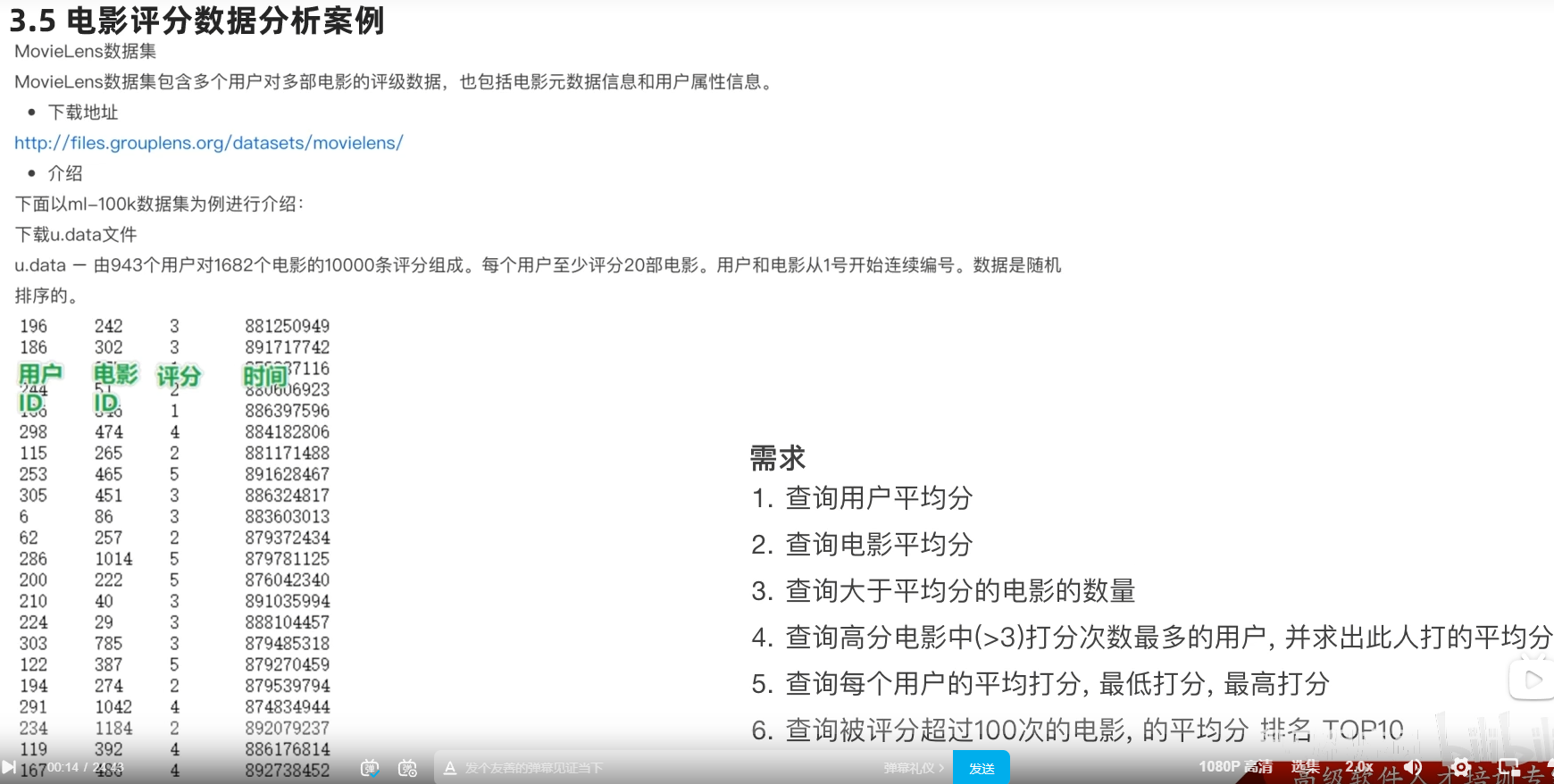
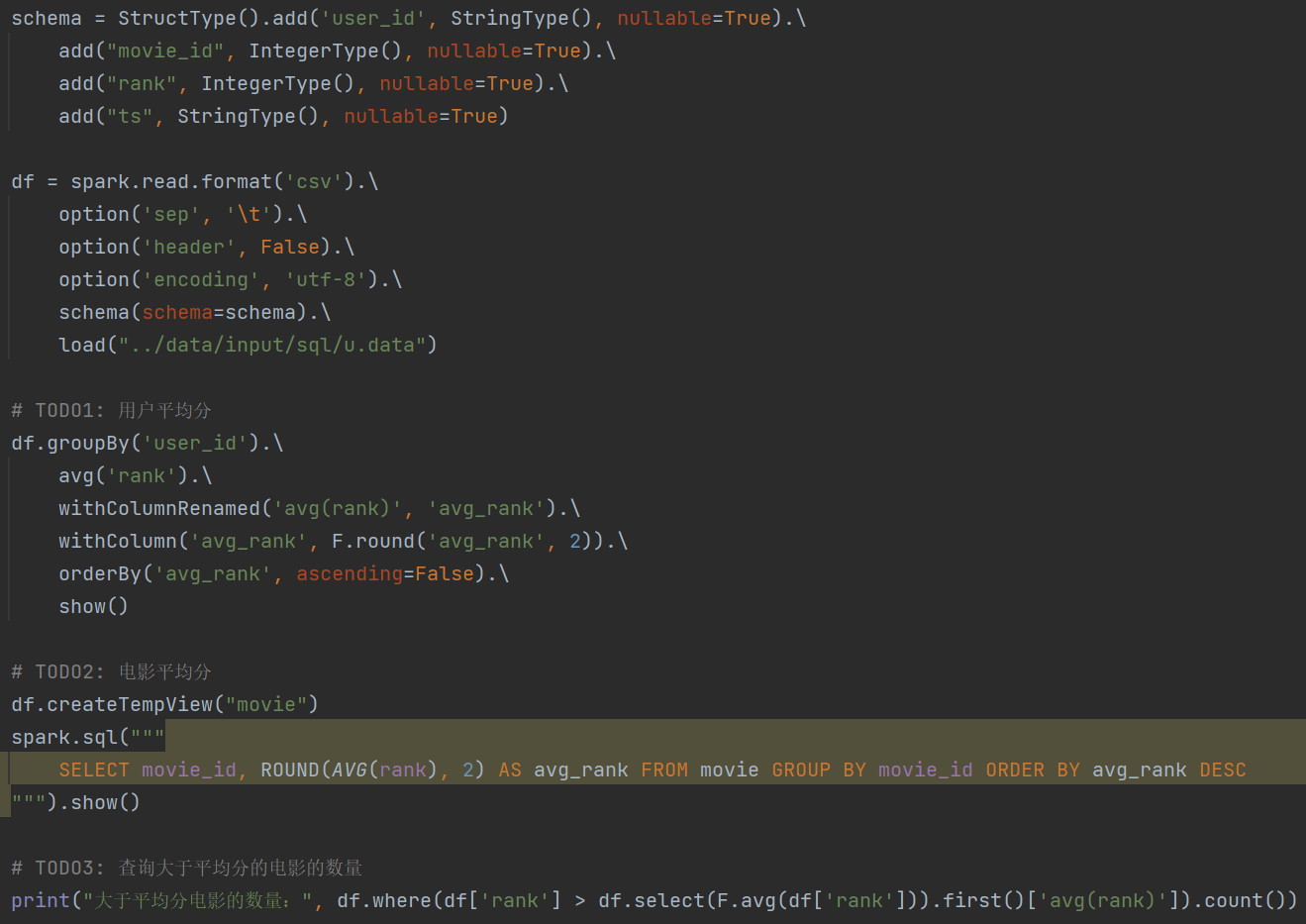
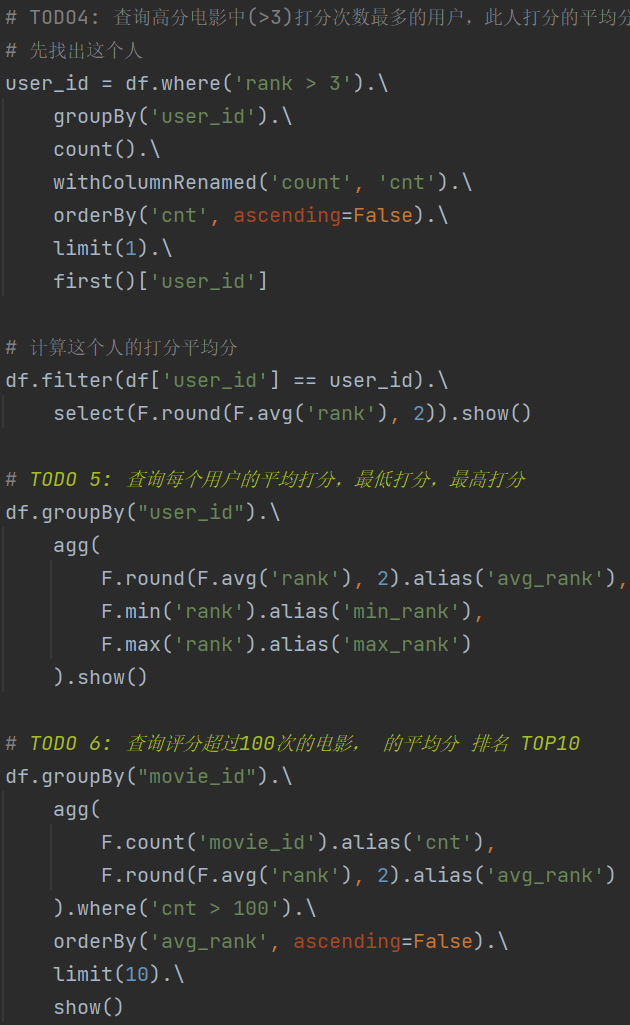

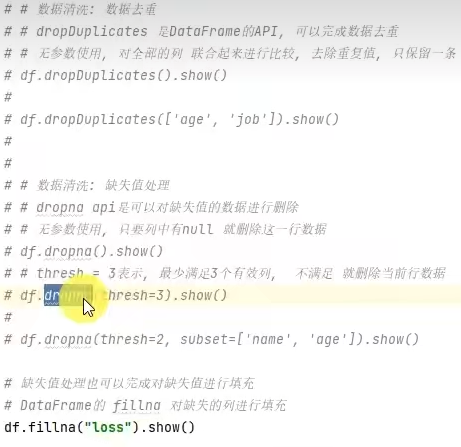
1.dataframe对象经过多次.之后,IDE无法自动补全得到withColumnRenamed方法?
仍未解决。
其他解决方案:使用AI代码补全插件
2.需要安装pytest模块
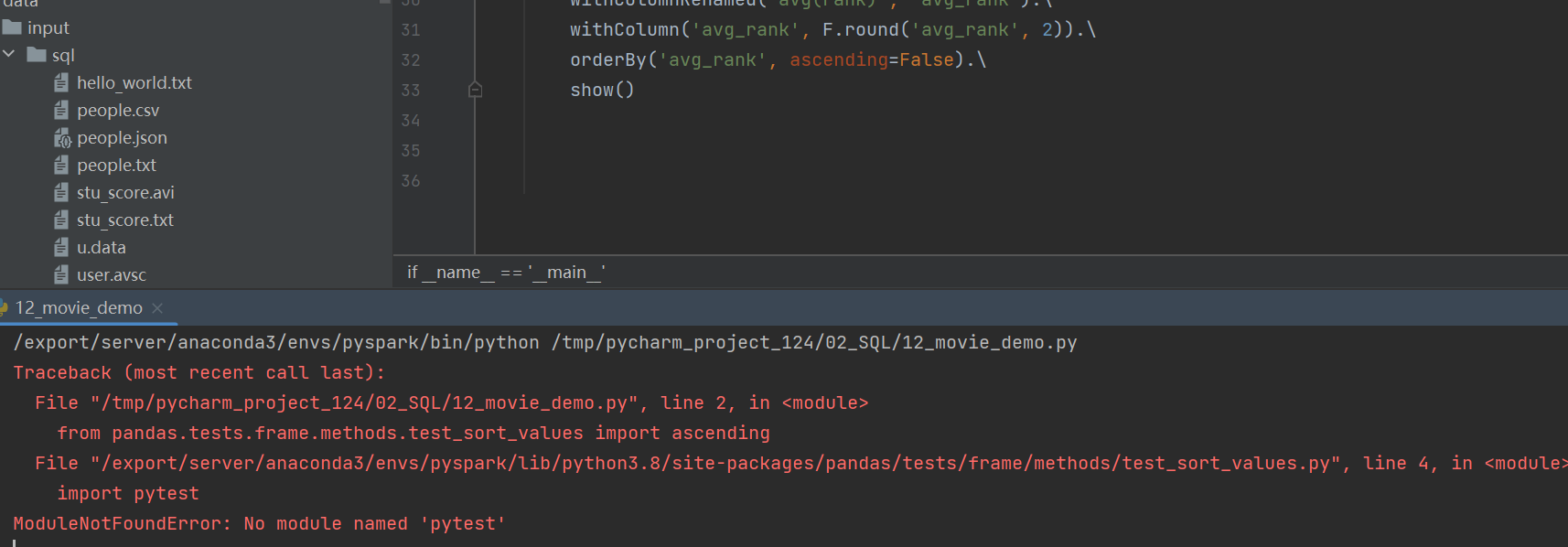
解决方案:在虚拟环境中安装pytest
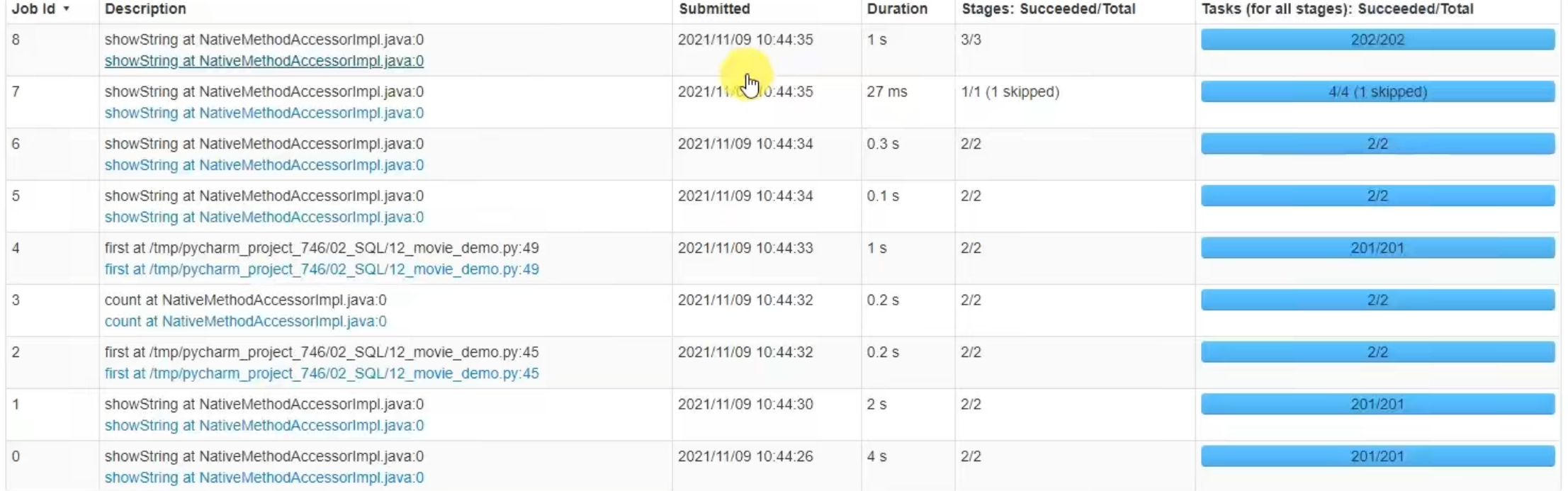
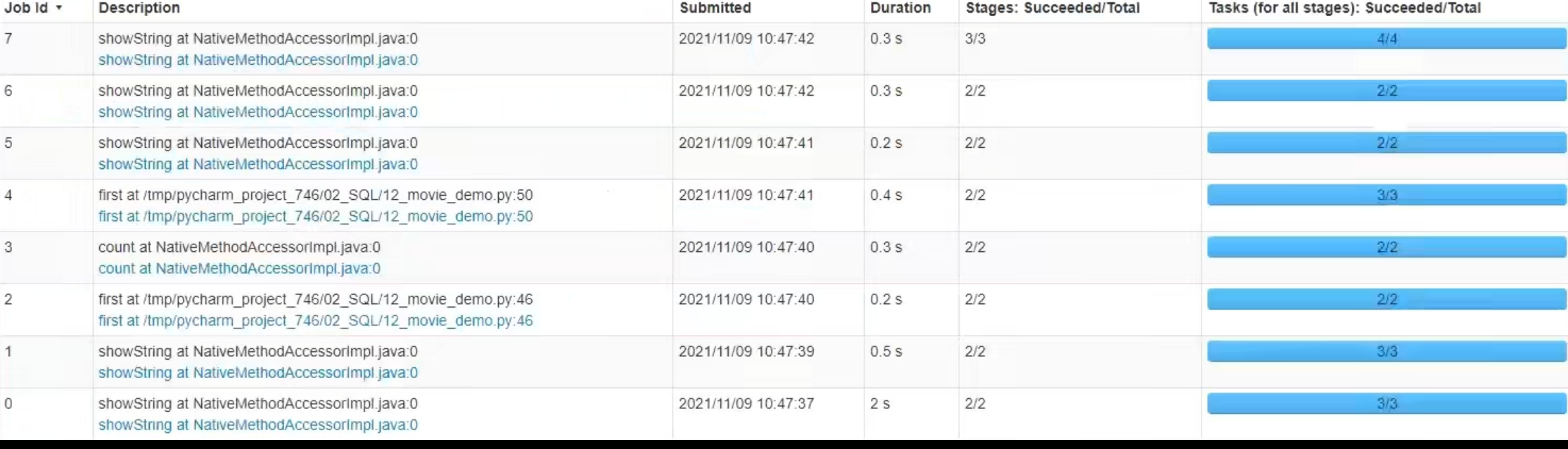
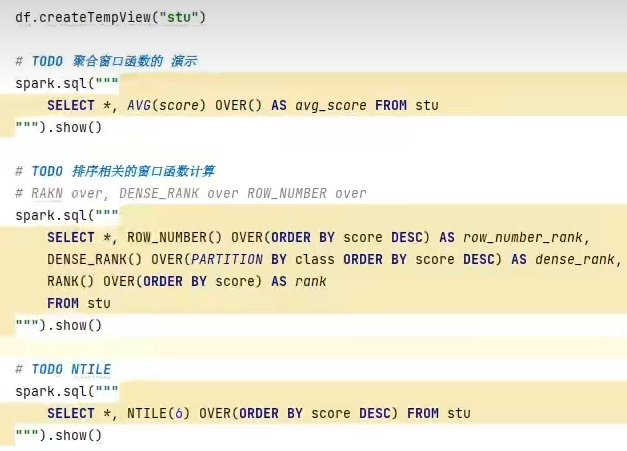
可以看出,速度变快了



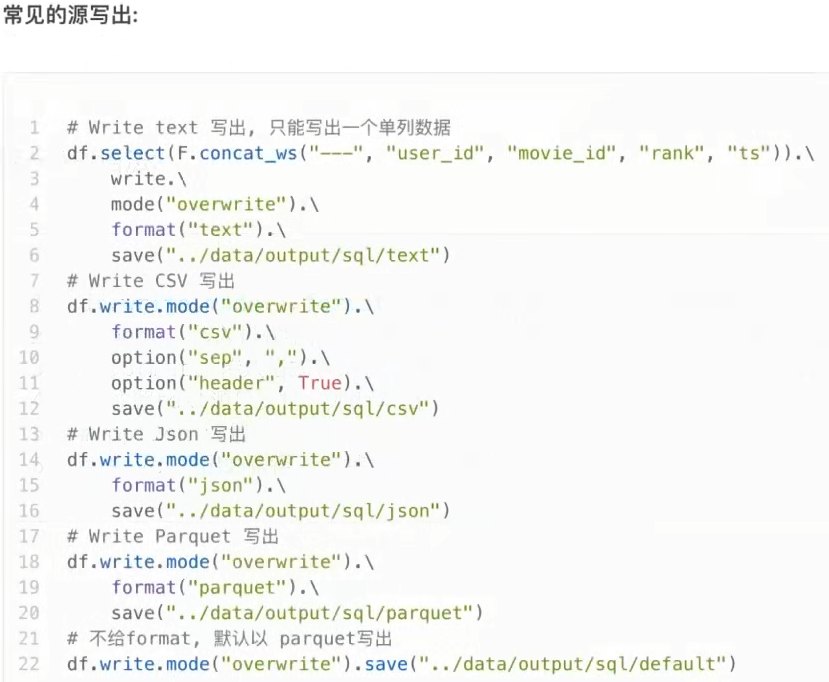
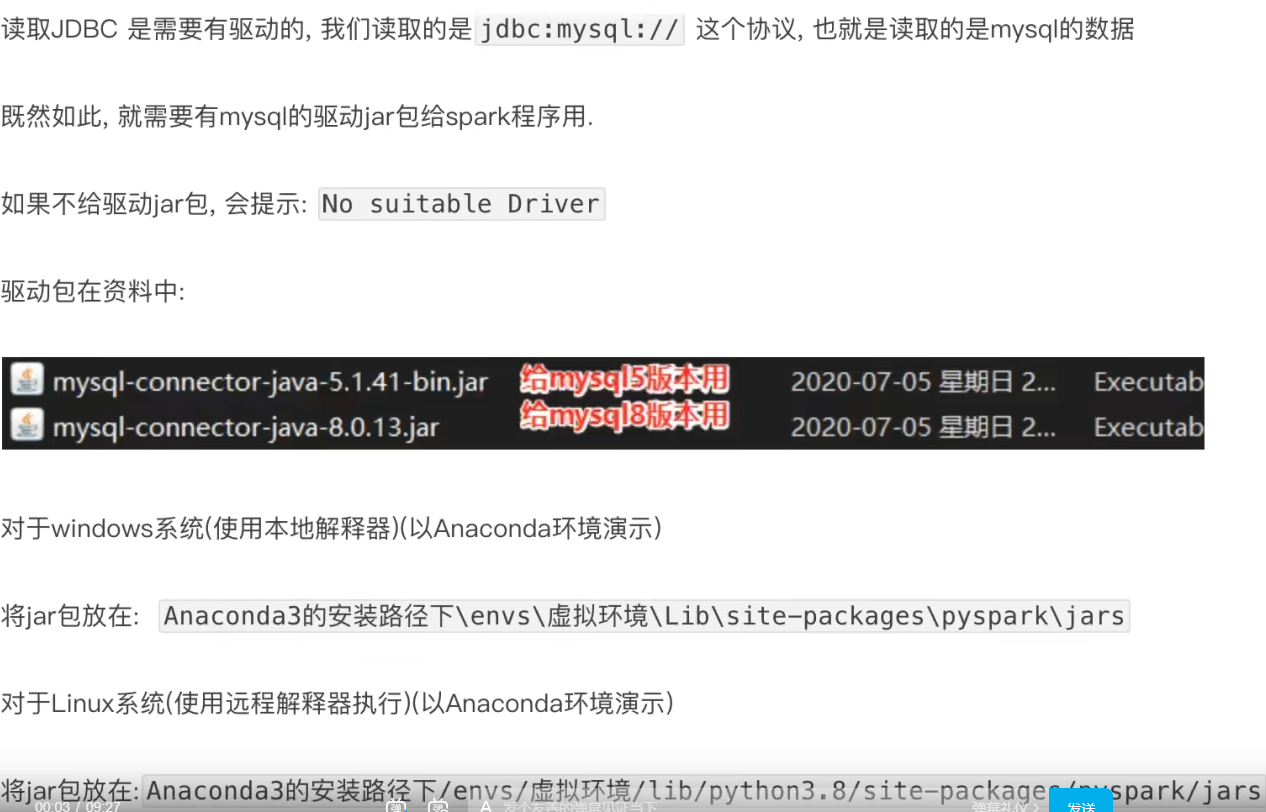
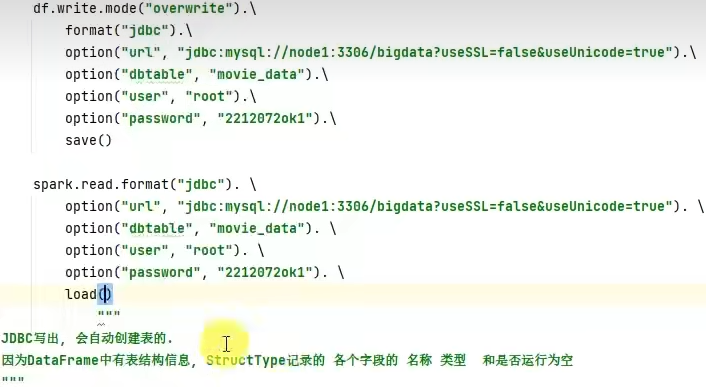

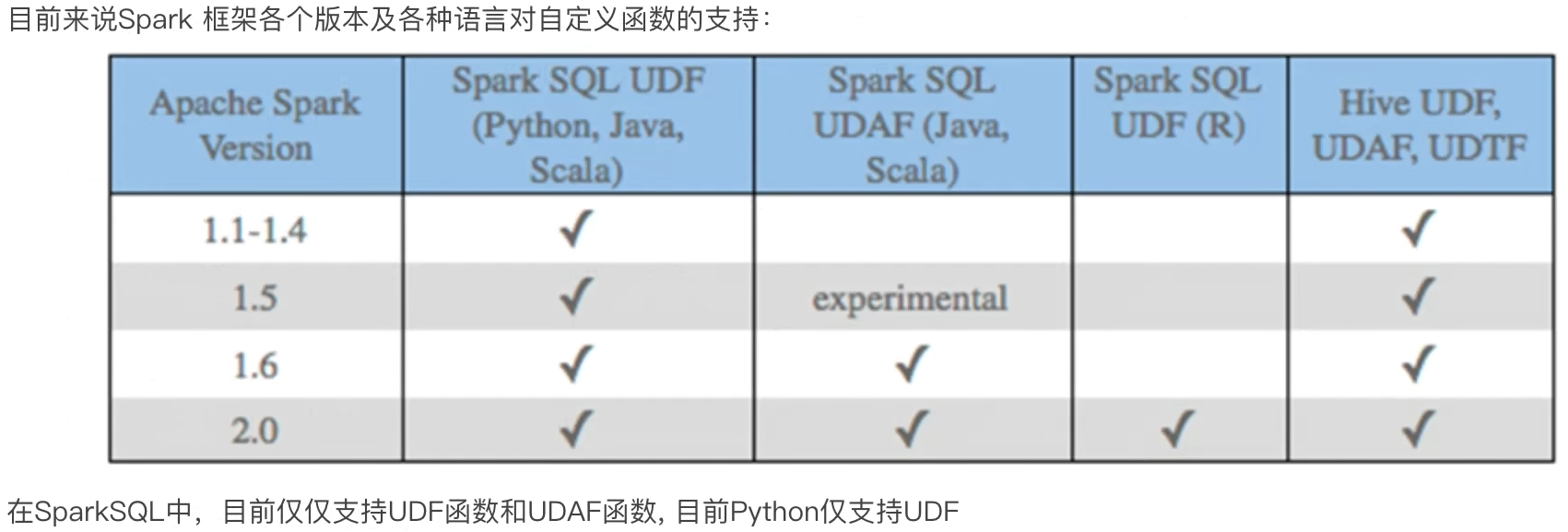



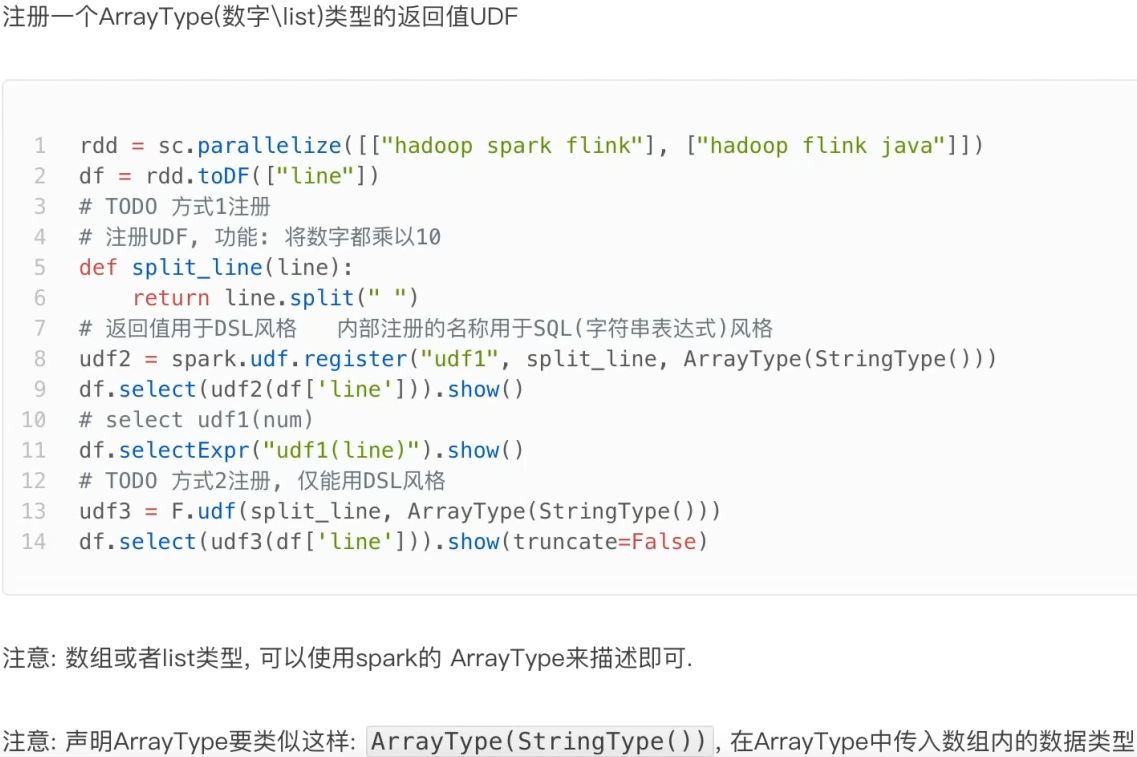
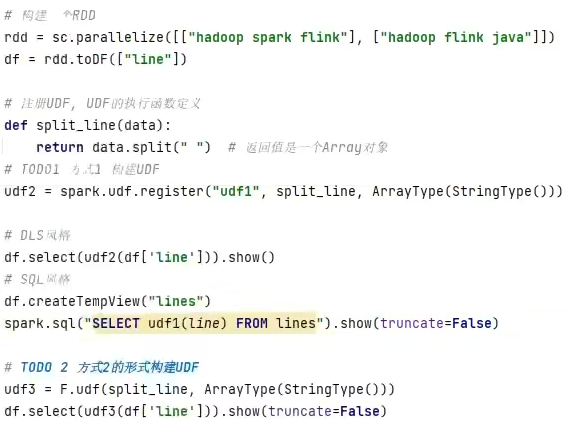
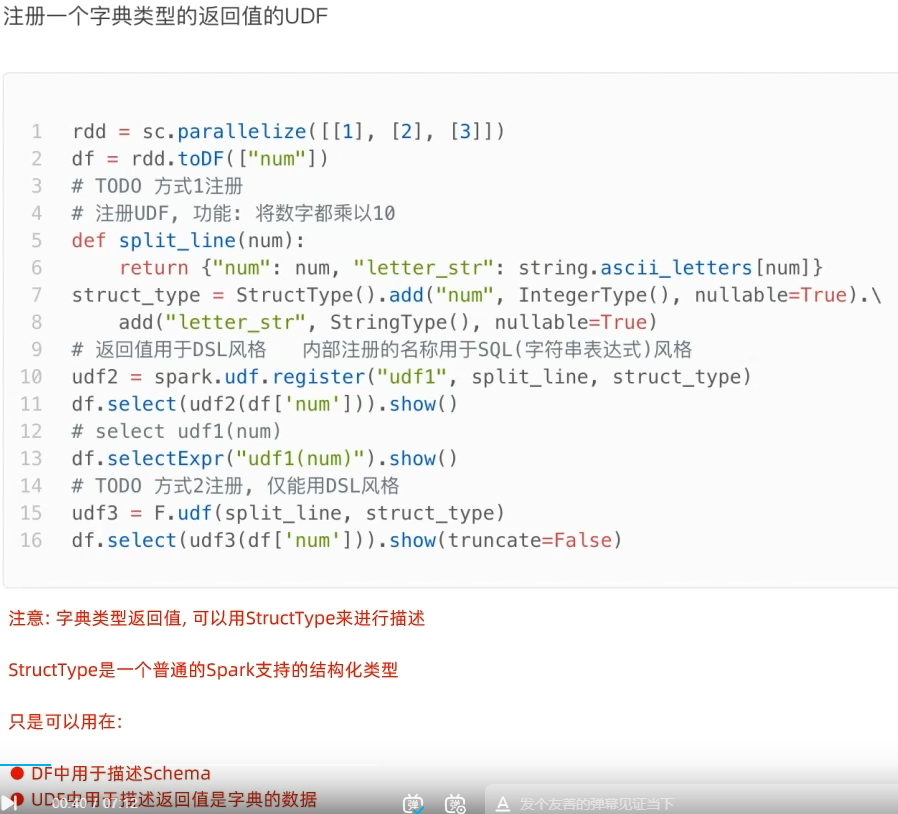
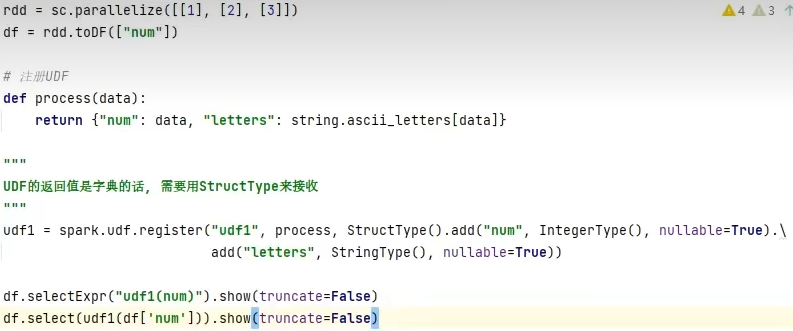
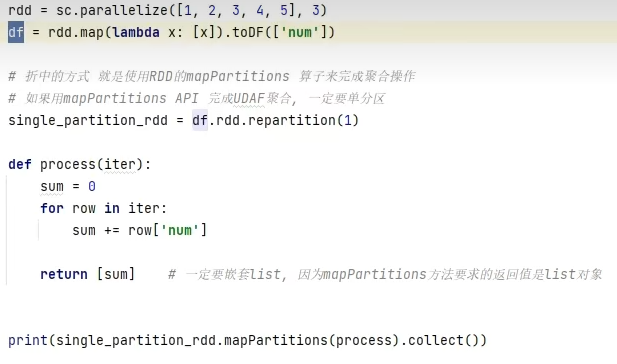

UDAF可以通过rdd的mapPartitions算子模拟实现
UDTF可以通过返回array或者dict类型来模拟实现

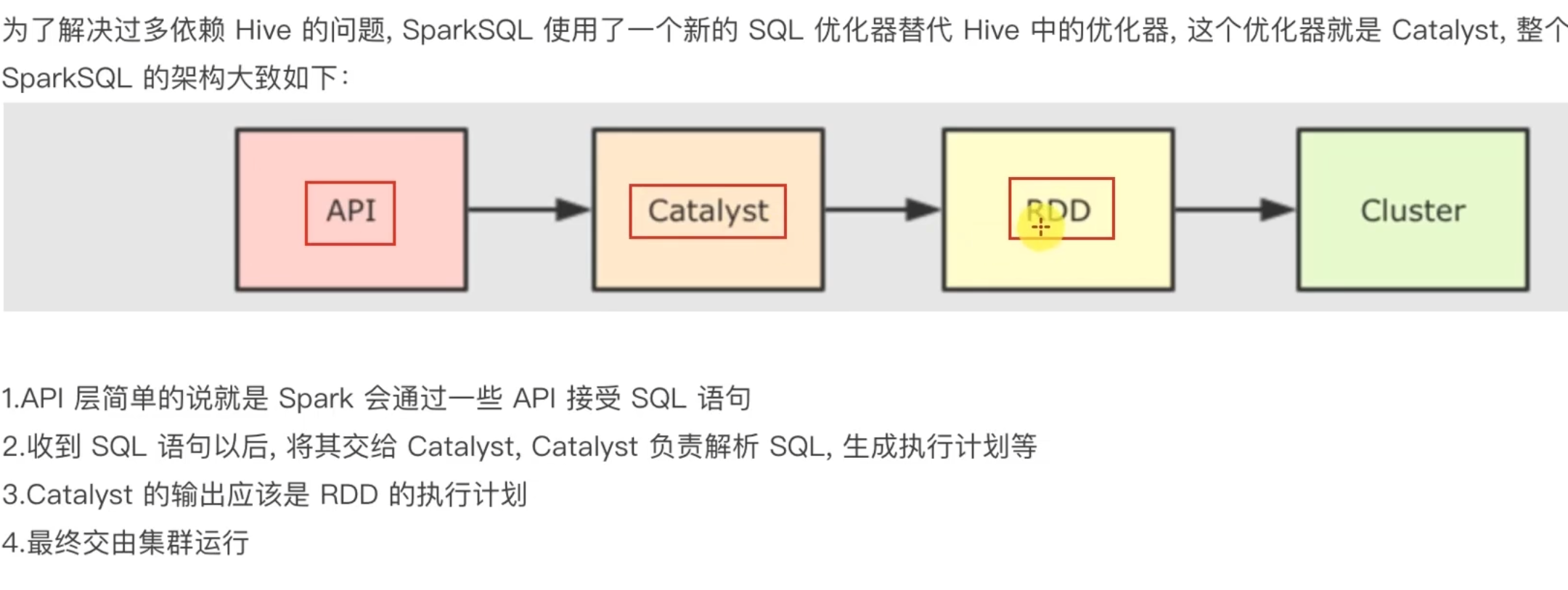
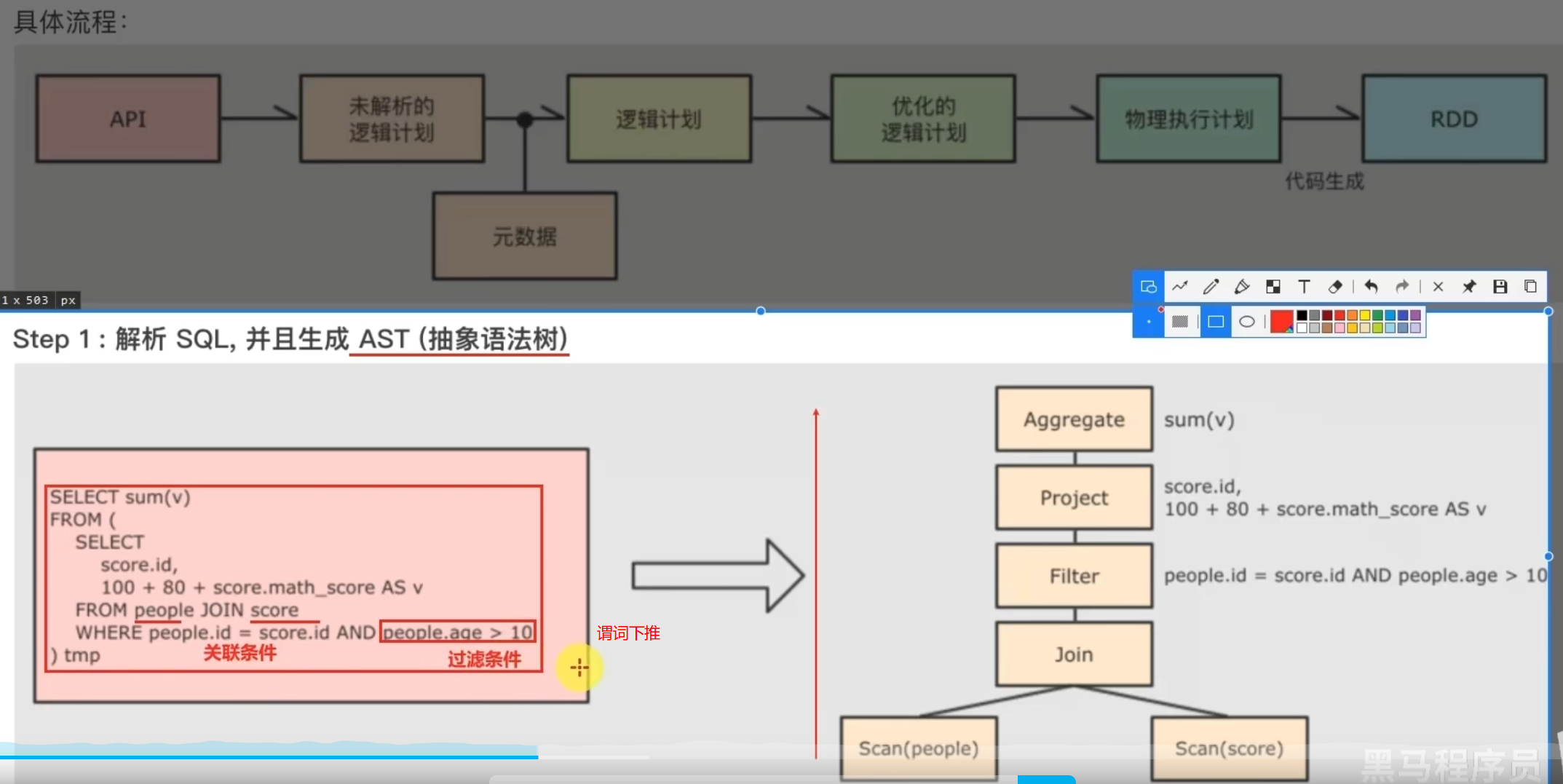

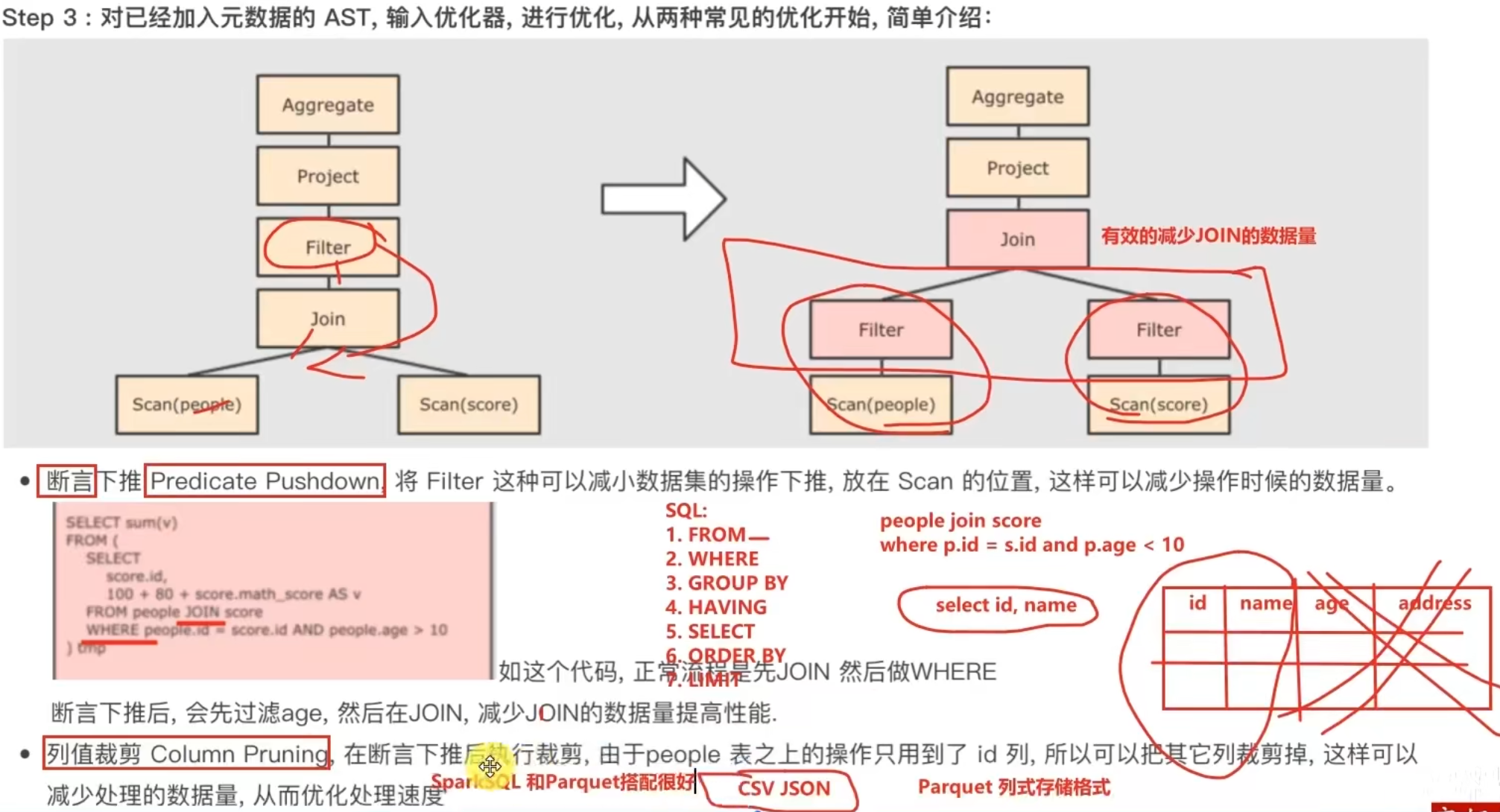
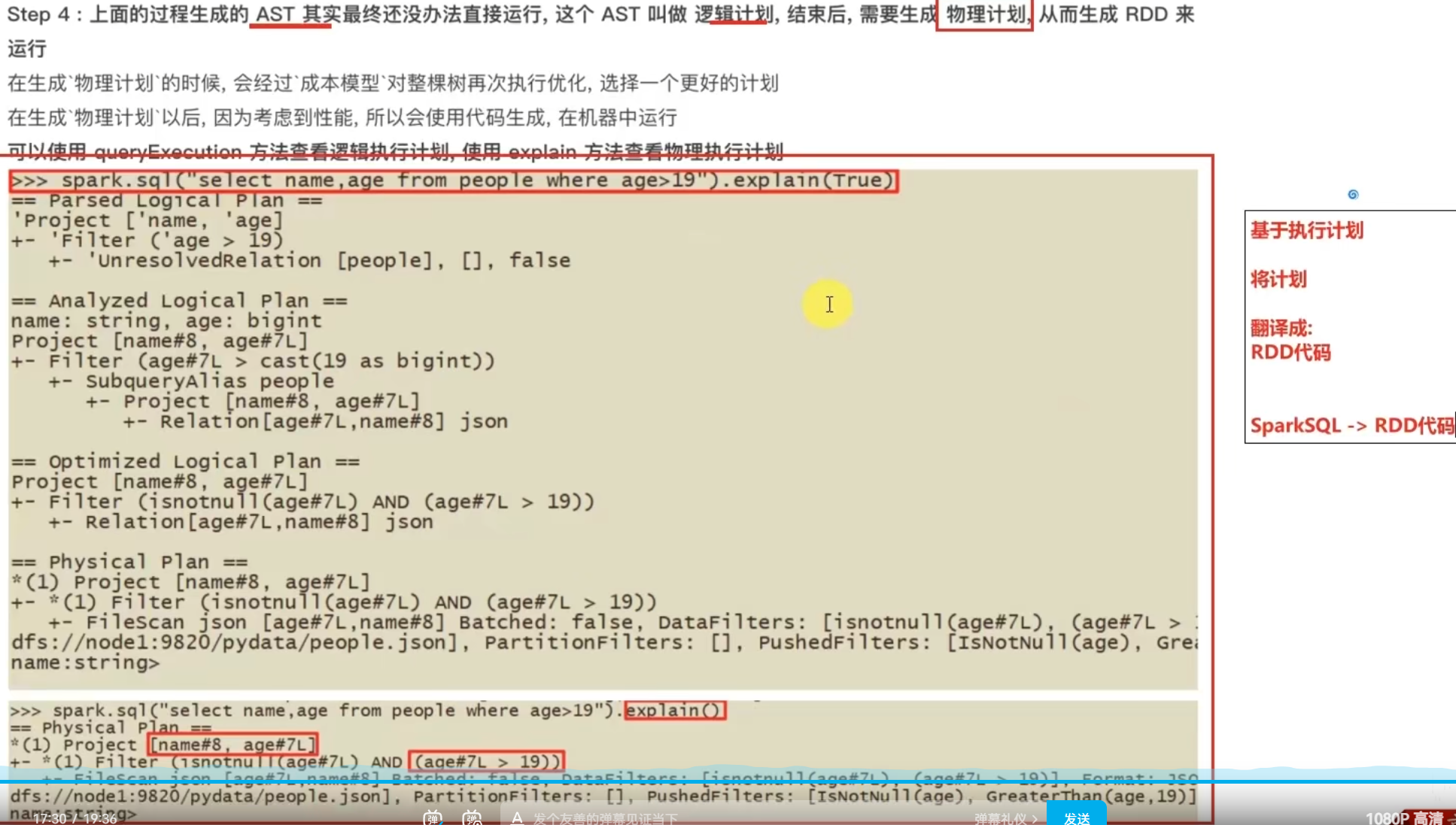


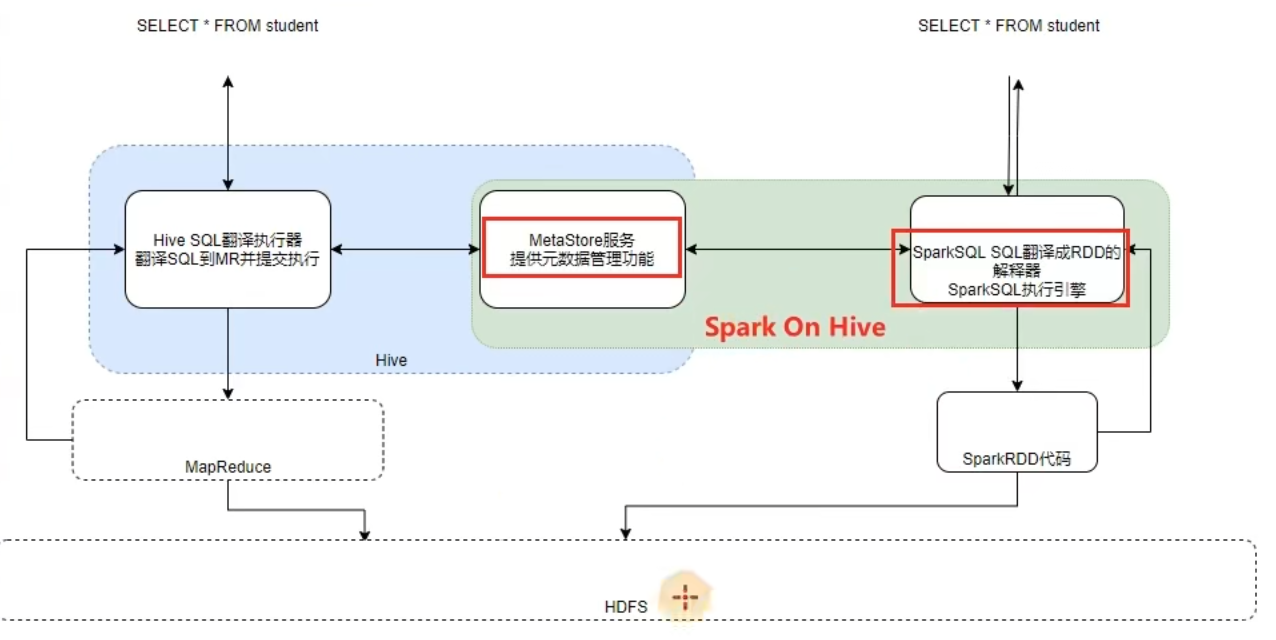


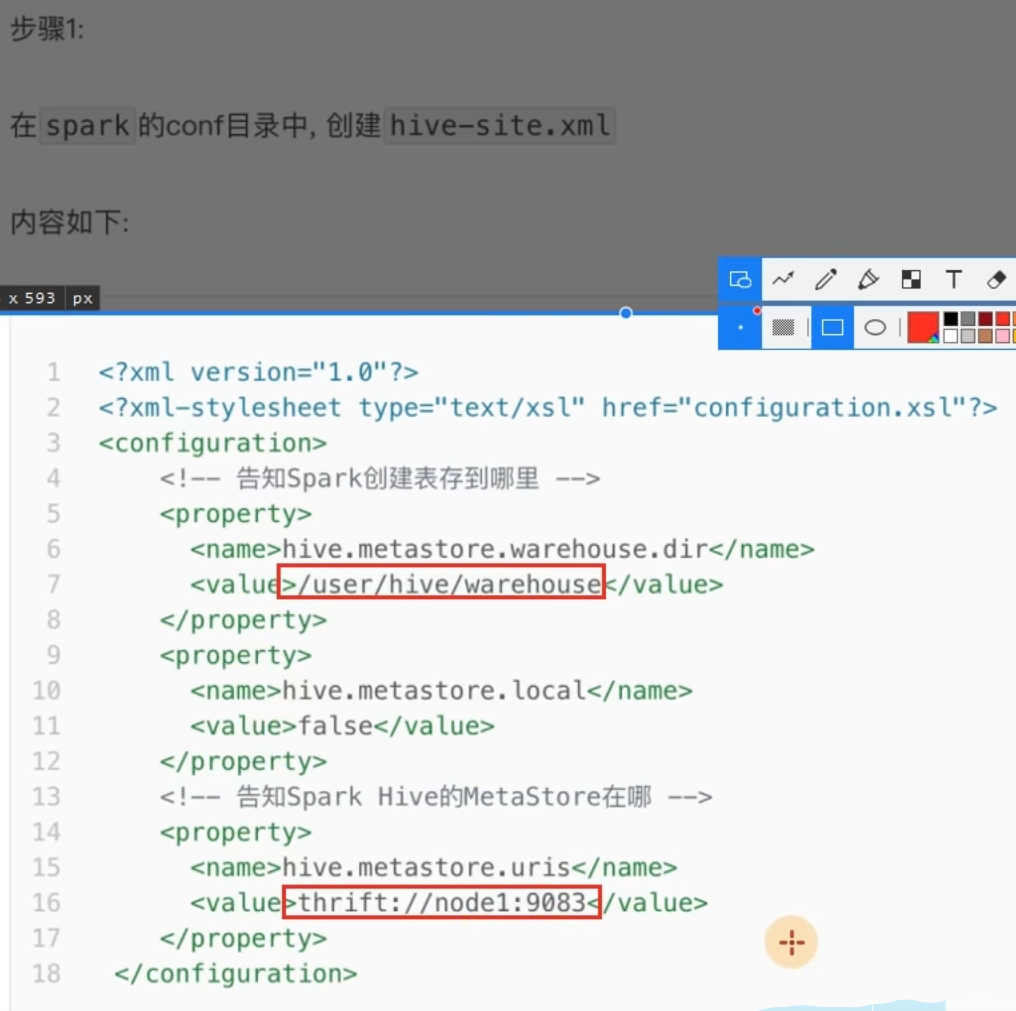

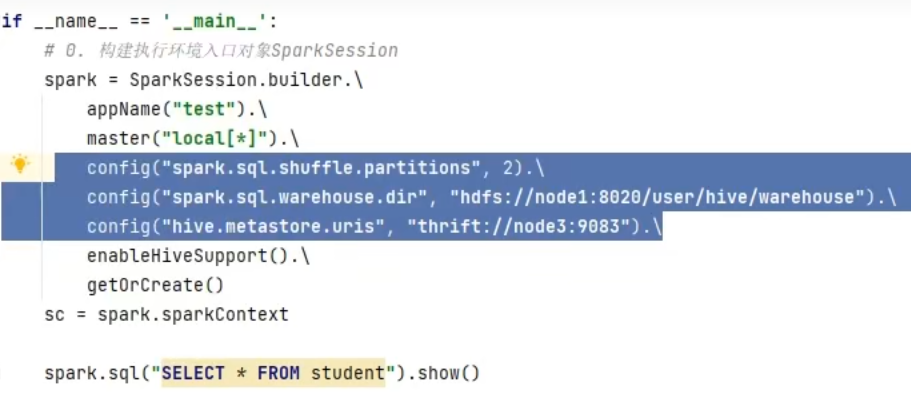
nohup /export/server/hive/bin/hive --service metastore 2>&1 >> /export/server/hive/metastore.log &
PS:2>&1的含义:将标准错误输出重定向到标准输出。
https://blog.csdn.net/icanlove/article/details/38018169

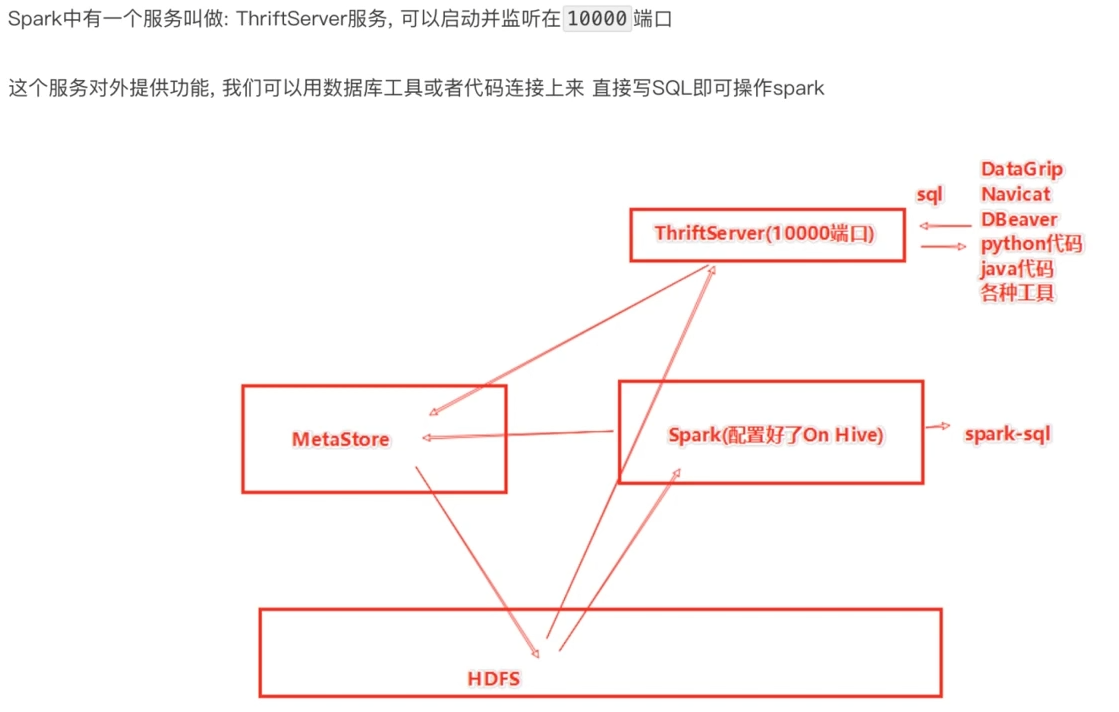
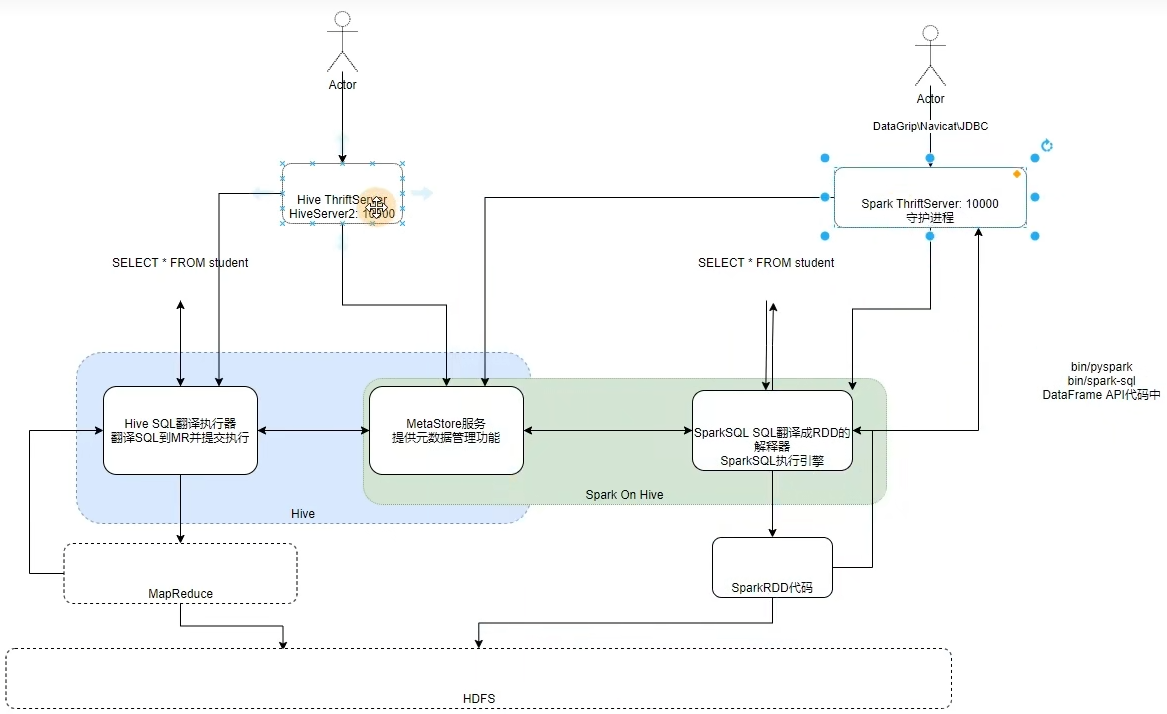

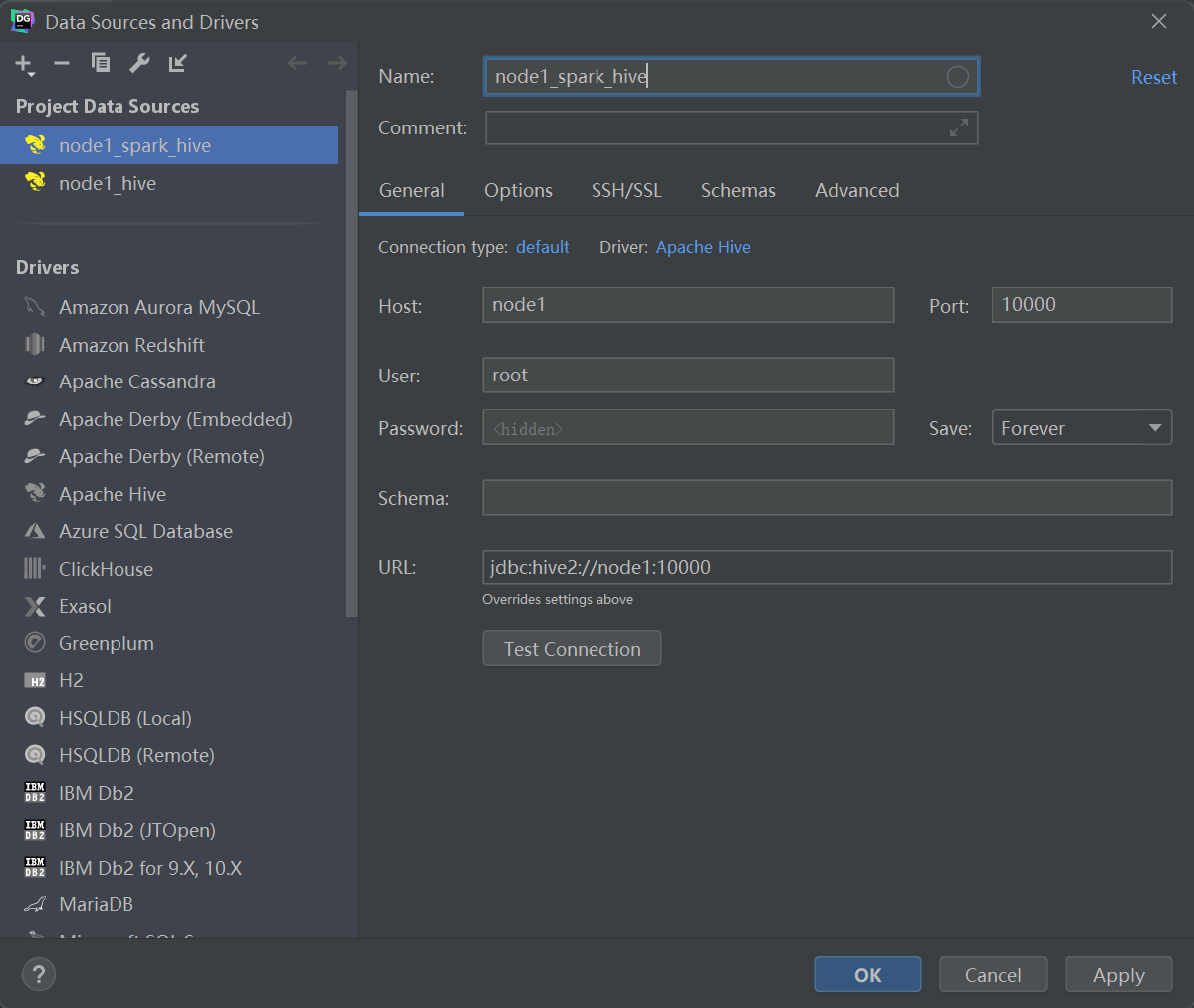
通过yum命令安装依赖
yum install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel libffi-devel gcc make gcc-c++ python-devel cyrus-sasl-devel cyrus-sasl-devel cyrus-sasl-plain cyrus-sasl-gssapi -y
切换到pyspark虚拟环境,通过pip命令安装
pip install pyhive pymysql sasl thrift thrift_sasl
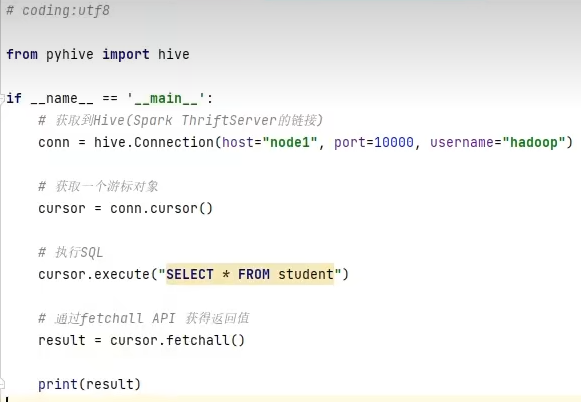



PS:
遇到问题:

解决方案:https://blog.csdn.net/debimeng/article/details/113101894
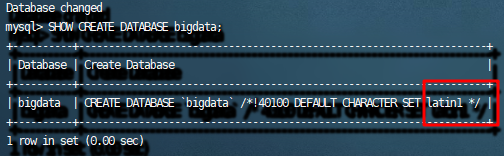
# 1.查看数据库和表的编码
SHOW CREATE DATABASE mydb;
# 2.修改数据库和表的编码
ALTER DATABASE mydb DEFAULT CHARACTER SET utf8;
3.检查数据库和表的编码
SHOW CREATE DATABASE mydb;
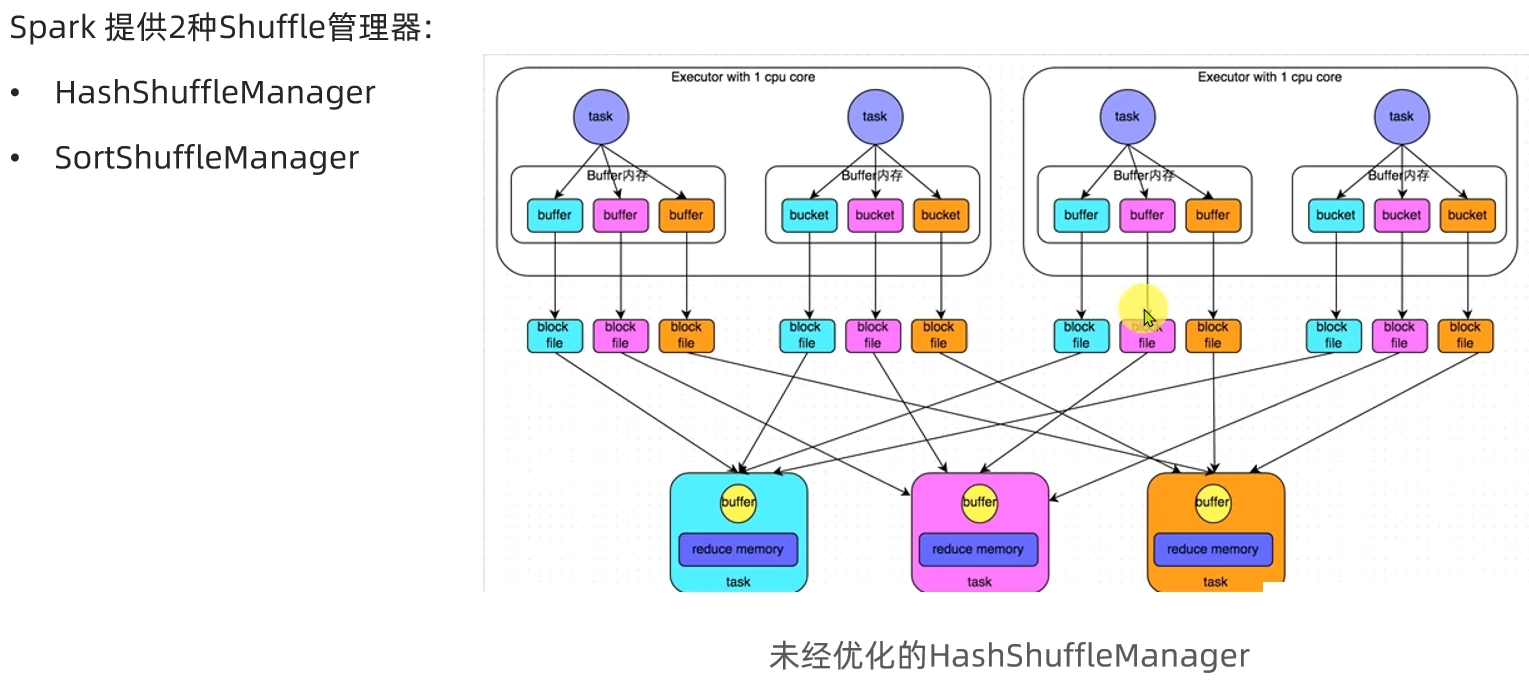
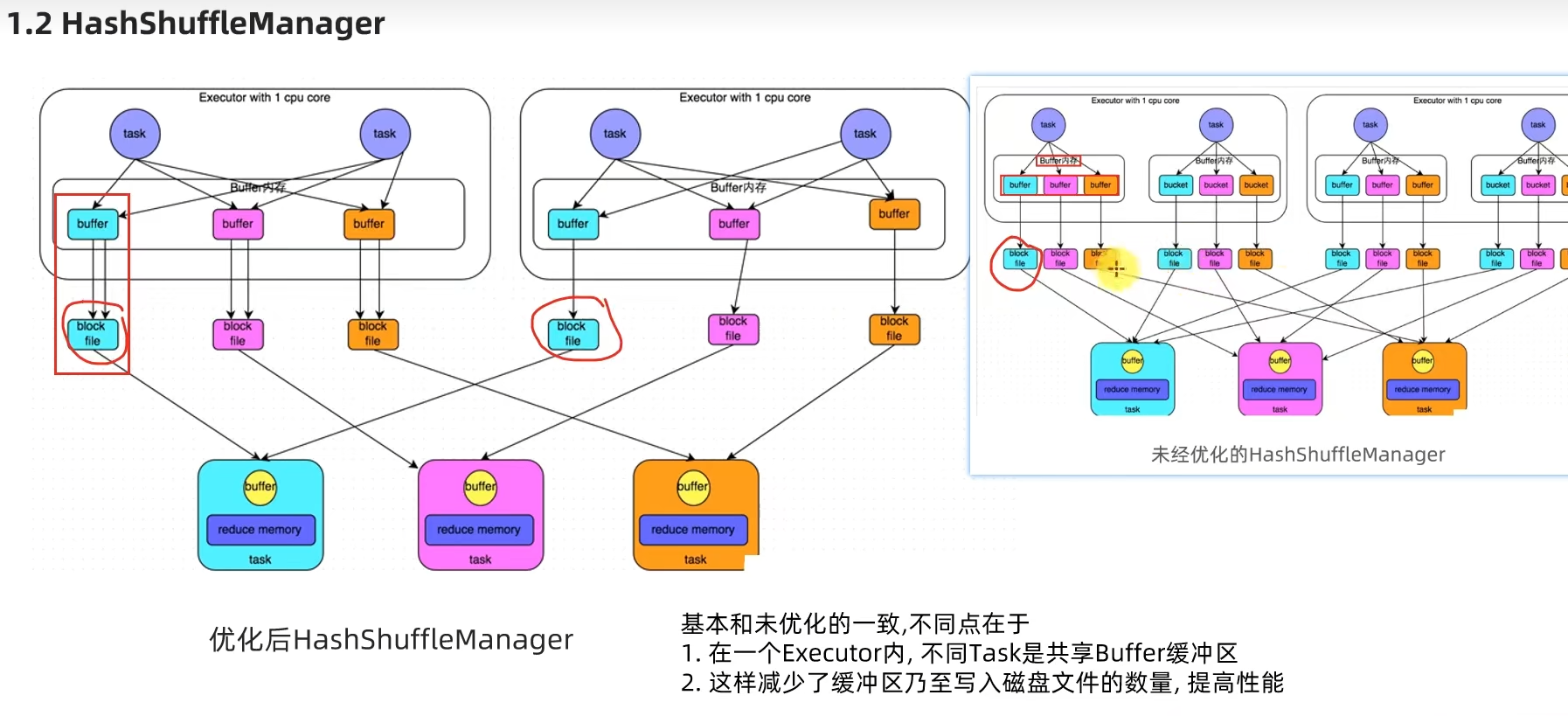
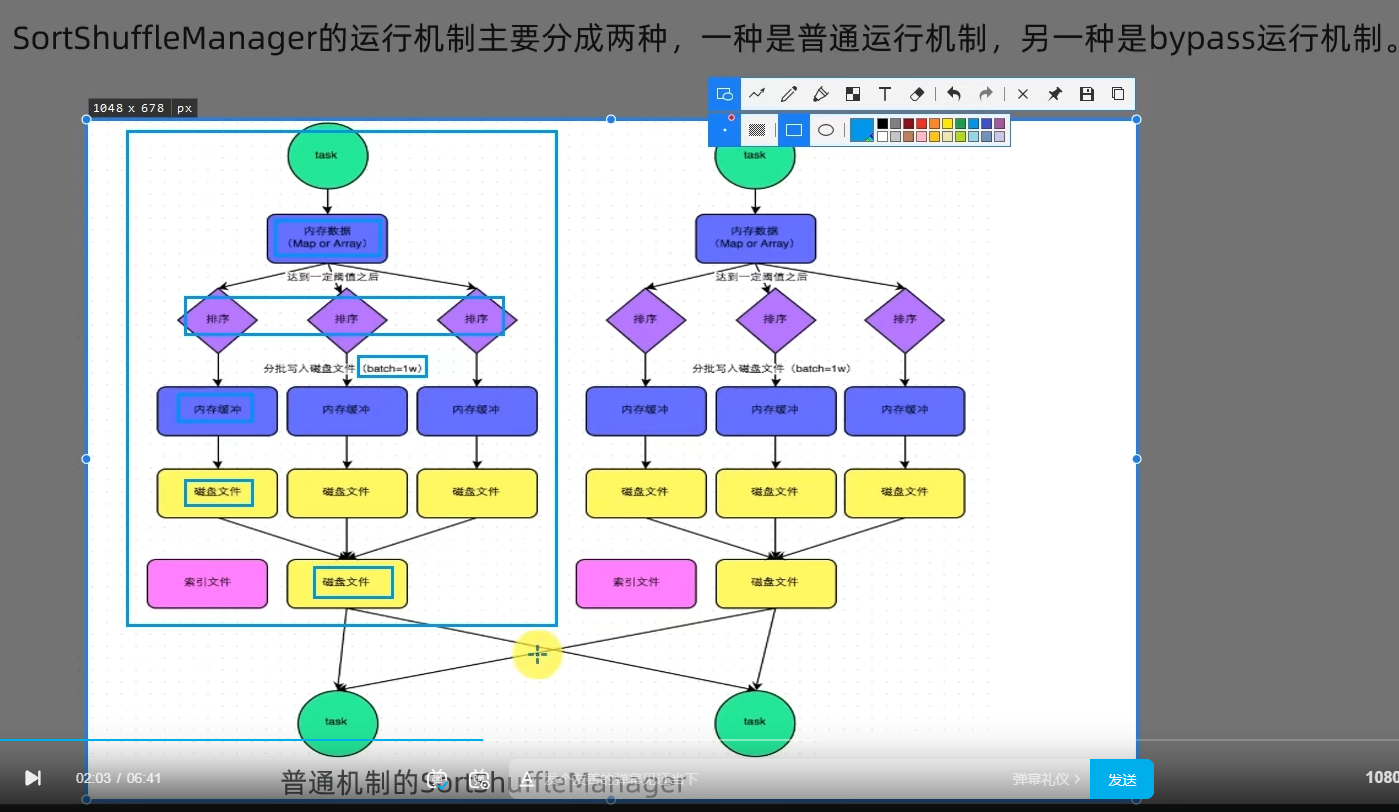

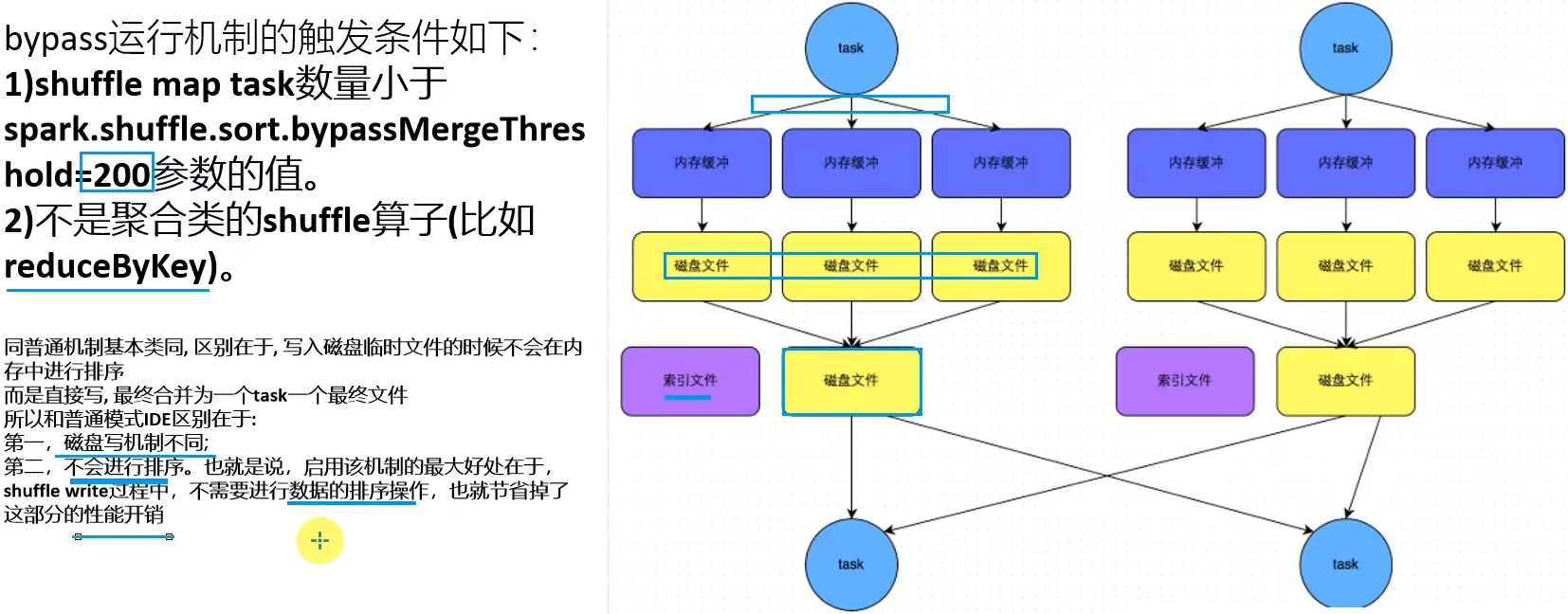


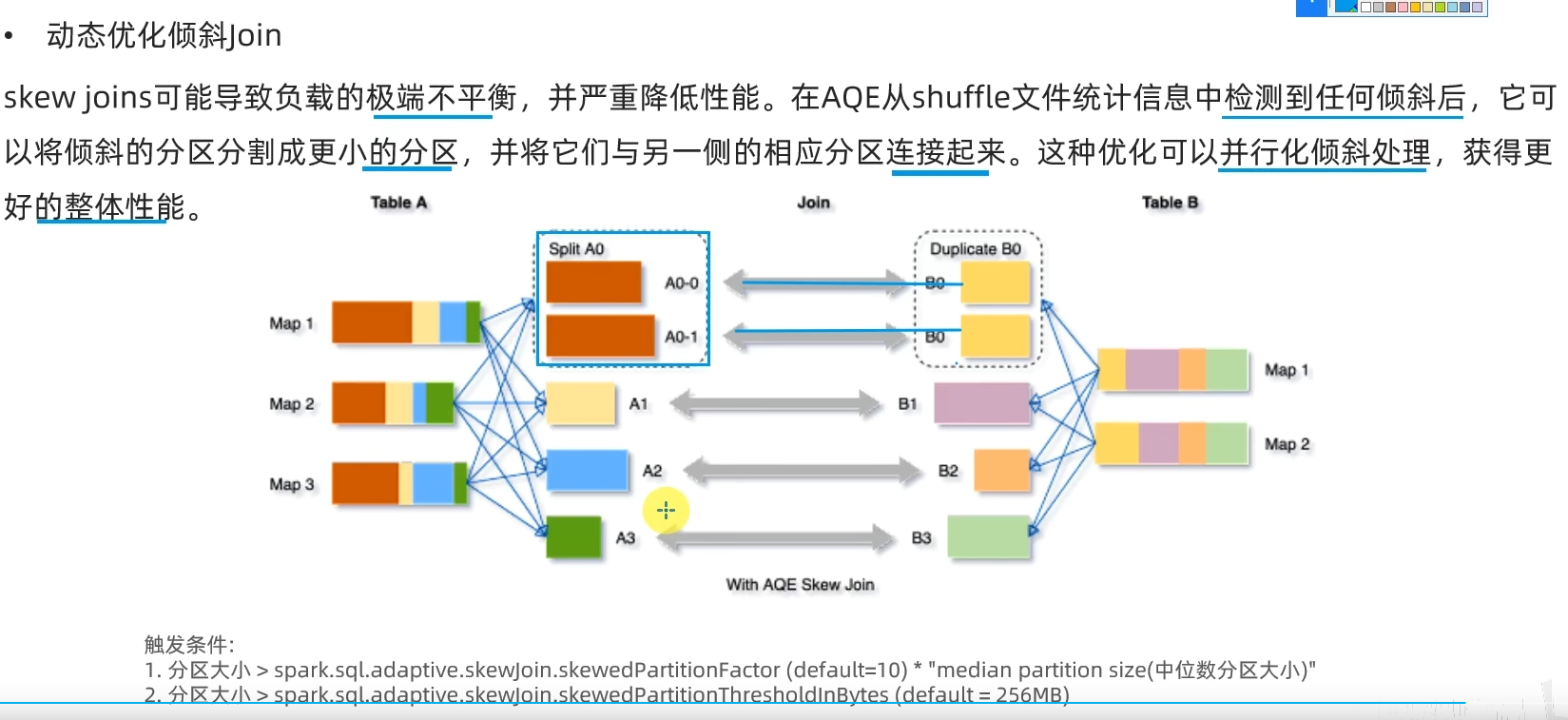
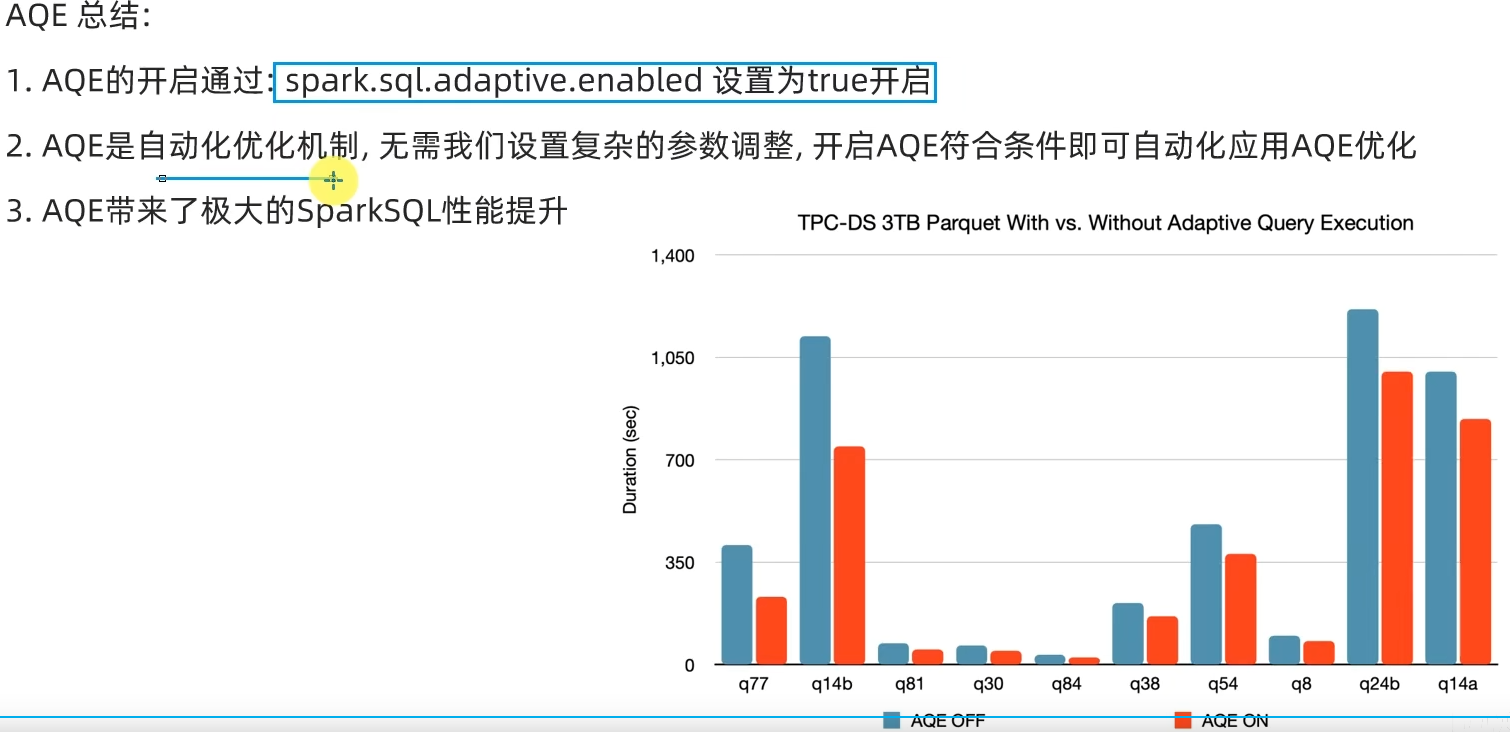
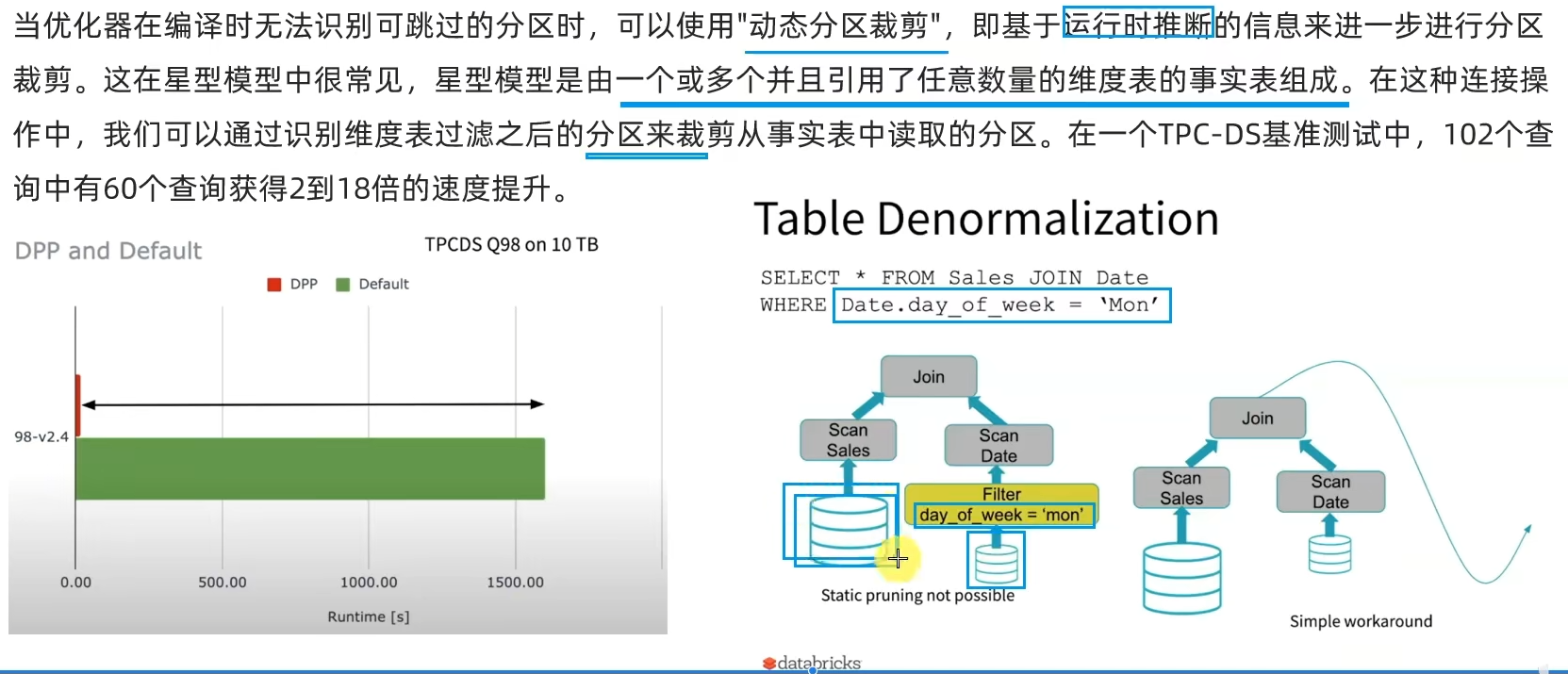
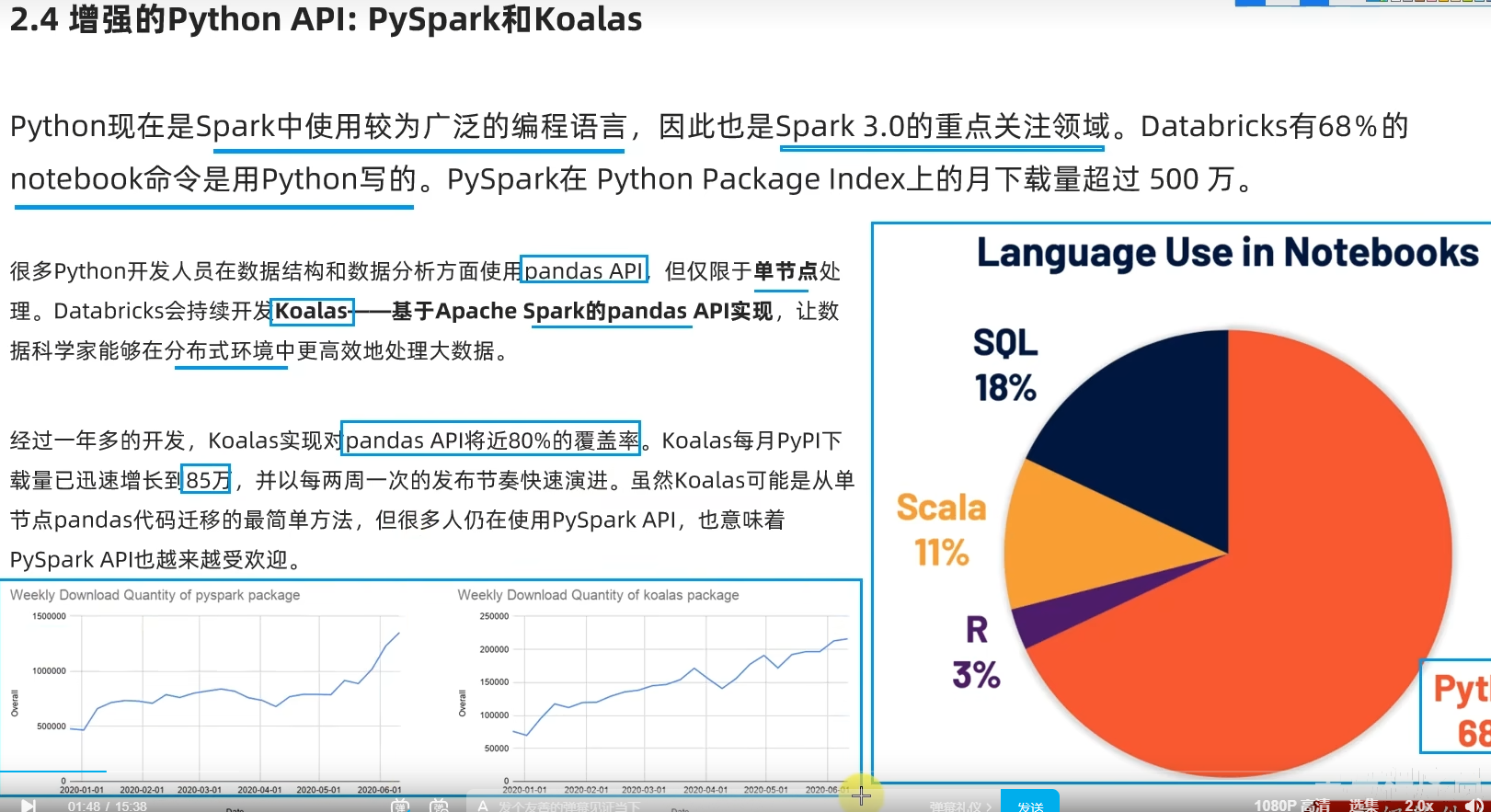
略
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p