相信大家对接口自动化已经不陌生了,这是几乎我们每个迭代都会投入的事情,但耗费了这么多精力去编写和维护,实际的收益如何呢?如果收益不好,是不是说明我们自动化case的实现方式、使用方式还有改进的地方呢?以下是接入得物接口自动化平台后的一些实践和想法,欢迎大家积极交流~
在接入自动化平台前,我们只能本地拉取代码->执行用例,所以执行者也只有测试人员。接入平台后,通过宣导or分享,开发可以方便的找到需要的用例(用例模块和标题需描述清晰),从而帮助他们造数或自测。
对于一些核心场景,即使业务迭代,通常结果也不会发生太大变化,这一类的场景case如果设计地较为稳定(当然这里的稳定不是只校验code=200就行),可以分享给开发用于自测,根据开发同学使用后的反馈,他们自测简单了许多,也有帮助他们发现过问题。
另外有一些本迭代内的新增接口,在接口评审完成后,我们可以提前编写好,根据具体情况决定是先保证接口状态的正常,后续再补充数据逻辑的校验,还是直接先把case写好。因为很多时候开发自测都只是调用本地代码,提测后连接口都调不通,如果提测前可以先进行基本的校验,就能减少冒烟测试被阻塞的概率。
冒烟测试:针对改动点挑出涉及的接口case,再加上P0级别case,提测后先执行一遍看看是否正常,如果核心链路异常,阻塞了后续测试,就可以直接打回了。
验证bug:有些复杂场景,测试链路较长,测试数据准备又很困难,很容易出现bug,而出现bug也就算了,偏偏改一遍还不一定能改好...这时候自动化的价值就体现了,把这些场景利用自动化实现,验证bug时直接一键执行就能得出结果,大大节省了时间,同时也稳定了自己濒临暴躁的情绪。
回归测试:在每次的bvt测试、覆盖率跟进中,有些case可能并不涉及本次需求改动范围,场景又比较简单基础,我们就可以利用自动化去覆盖。执行通过,视具体情况可以简单看一眼或者不再回归。
虽然我们现在有了造数平台,但实现起来有一定的成本,一些场景可能除了自己没有别的业务方有造数需求,并且场景很简单,只需调个接口,改个数据表就行,那么最快的造数方法就是自动化脚本。现在有了自动化平台,我们可以更好地分享给有造数需求的开发、产品、测试。
当然,以上效果的前提是我们的自动化case比较稳定,不能每次执行都一堆不通过,这样时间都耗费在排查问题上了,效果会大打折扣,别人也不会再愿意使用。
通常一部分同学会在用例评审结束,开发提测之前进行case编写,此时需要实现自动化的场景已经明确,基本上涉及的接口和出入参都已确定,自动化case的大致框架就形成了。这时候实现自动化,就可以最大化地发挥其价值,在上述涉及到的几个场景都能投入使用。如果因为时间不够或接口尚未明确,可以先梳理好需要实现自动化的场景步骤,在提测后一边手动执行用例一边补充接口参数和校验点。针对级别较低的接口场景,也可以放在版本结束后再实现,只是效果会降低一些。
我们维护的case一般有两种,一是自己写的,二是别人写的。自己写的,含着泪也要日常维护。别人写的,由于大家的编码风格千差万别,在接入自动化平台前,维护起来简直困难重重,当我们为了通过率去推进case更新时,往往这一类的难以推进。现在接入了平台,基本上统一了case模板,当因为需求变动需要更新时,有时只需要修改出入参和断言即可,一定程度上已经降低了维护成本。
另外,当case经常报错时,可以看看设计上是否能优化。有些依赖性强的数据,是否可以通过其他手段让这部分数据稳定下来。比如发优惠券的场景,前提需要一张有效的券,那我们在发券前可以先获取一张有效的券信息,或者在发券前先创建一张券,发完券后如果需要对券信息进行校验,也通过变量的方式。针对单个测试点实现自动化时,可以尽可能地与其他测试点解藕,充分利用前置脚本,通过修改数据表等方式较少依赖。case中也可以设置失败重试次数,减少由于环境不稳定等原因造成的失败。
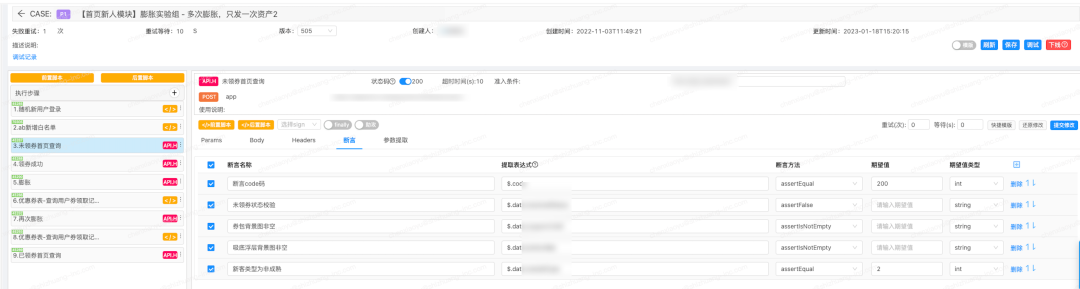
举个例子:“得物App新客人群领取优惠券并触发金额膨胀,多次触发膨胀应该只有一次膨胀成功”。
这个case在迭代中提高了测试效率,并且在后续需求变更时,帮助开发自测,解决造数问题并发现了bug。
import json
import requests
from util.db_mysql import DBMySQL
from util.db_redis import DbRedis
def call(env_vars, g_vars, l_vars, sys_funcs, asserts, logger, **kwargs):
userId = l_vars.get('userId')
n = int(userId)%4
dbA = DBMySQL(env_vars.get("db.A"))
dbB = DBMySQL(env_vars.get("db.B"))
try:
sql_1 = "SELECT * FROM table_A WHERE user_id = %s;"%userId
# 领券后,用户领券状态校验
user_coupon_info = dbA.select(sql_1)
logger.info(newbie_res)
asserts.assertEqual(user_coupon_info[0].get("status"), 1, msg="数据表领券状态为true")
asserts.assertEqual(user_coupon_info[0].get("type"), 0, msg="当前券类型为0")
asserts.assertIsEmpty(user_coupon_info[0].get("coupon1"), msg="无资产1")
asserts.assertIsEmpty(user_coupon_info[0].get("coupon2"), msg="无资产2")
asserts.assertIsEmpty(user_coupon_info[0].get("coupon4"), msg="无资产4")
asserts.assertIsNotEmpty(user_coupon_info[0].get("info"), msg="券包信息非空")
#获取用户分组,确定用户是命中了实验组的
group = user_coupon_info[0].get("group")
asserts.assertNotEqual(group, 0, msg="用户命中对照组,无膨胀券")
#获取膨胀资产配置
sql_2 = "SELECT * FROM table_B WHERE id = 50%s and deleted=0"%group
logger.info("sql_2:"+sql_2)
coupon_config = dbA.select(sql_2)
logger.info("coupon_config:"+coupon_config)
content = json.loads(coupon_config[0].get("content_info"))
for i in range(3):
activityId = content[i]["activityId"]
l_vars.set('activityId_{}'.format(i+1), activityId)
# 优惠券表校验
sql_3 = "SELECT * FROM a_coupon_%s WHERE user_id = %s and activity_id = %s;"%(n,userId,activityId)
logger.info("sql_3:"+sql_3)
coupon_res = dbB.select(sql_3)
logger.info("coupon_res:"+coupon_res)
if(i==0):
asserts.assertIsEmpty(coupon_res, msg="未到账资产1")
if(i==2):
asserts.assertIsNotEmpty(coupon_res, msg="到账资产3")
finally:
dbA.close()
dbB.close()import json
import requests
from util.db_mysql import DBMySQL
from util.db_redis import DbRedis
def call(env_vars, g_vars, l_vars, sys_funcs, asserts, logger, **kwargs):
call_param = sys_funcs.get_call_param()
userId = call_param.get('userId')
activityId = call_param.get('activityId')
dbB = DBMySQL(env_vars.get("db.B"))
if not userId:
user_var = l_vars.get(call_param.get('var_userId'))
userId = user_var
if not activityId:
activityId_var = l_vars.get(call_param.get('var_activityId'))
activityId = activityId_var
if not userId and not activityId:
raise '请传入查询条件'
try:
if not activityId:
sql = "SELECT * FROM a_coupon_%s WHERE user_id = %s;"%(int(userId)%4,userId)
elif not userId:
sql = "SELECT * FROM a_coupon_%s WHERE activity_id = %s;"%(n,activityId)
else:
sql = "SELECT * FROM a_coupon_%s WHERE user_id = %s and activity_id = %s;"%(int(userId)%4,userId,activityId)
logger.info(sql)
res = dbB.select(sql)
logger.info(res)
l_vars.set("select_tableB_res",res)
except Exception as e:
logger.info(f'查询失败【{str(e)}】')
raise e
finally:
dbB.close()
return resimport json
import requests
def call(env_vars, g_vars, l_vars, sys_funcs, asserts, logger, **kwargs):
select_tableB_res = l_vars.get('select_tableB_res')
asserts.assertIsNotEmpty(select_tableB_res, msg="到账资产1")import json
import requests
def call(env_vars, g_vars, l_vars, sys_funcs, asserts, logger, **kwargs):
select_tableB_res = l_vars.get('select_tableB_res')
asserts.assertEqual(len(select_tableB_res),1,msg="只到账资产1一张")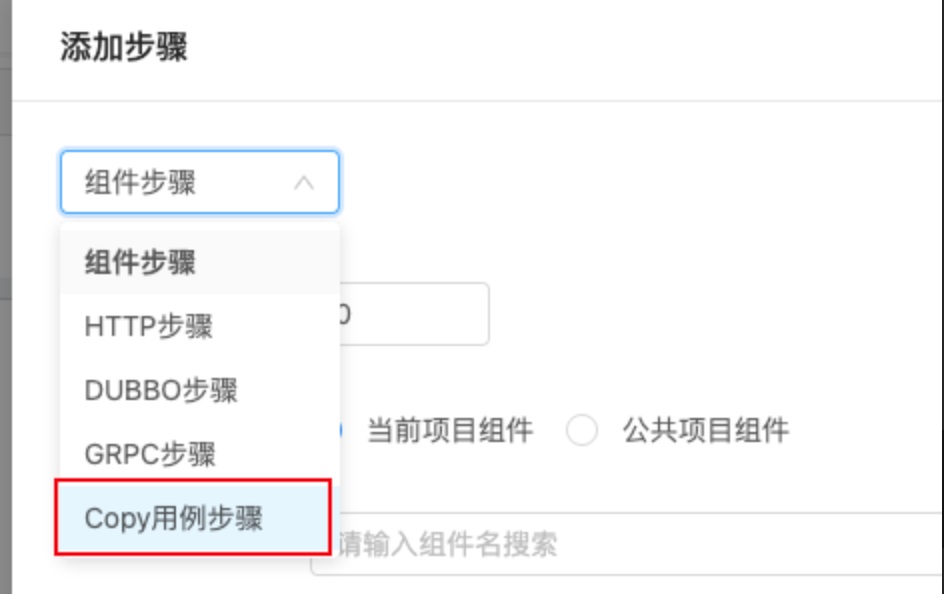
import json
import requests
from util.db_mysql import DBMySQL
from util.db_redis import DbRedis
def call(env_vars, g_vars, l_vars, sys_funcs, asserts, logger, **kwargs):
call_param = sys_funcs.get_call_param()
userId = call_param.get('userId')
activityId = call_param.get('activityId')
dbA = DBMySQL(env_vars.get("db.A"))
if not userId:
user_var = l_vars.get(call_param.get('var_userId'))
userId = user_var
if not activityId:
activityId_var = l_vars.get(call_param.get('var_activityId'))
activityId = activityId_var
if not userId and not activityId:
raise '请传入查询条件'
try:
if not activityId:
sql = "SELECT * FROM a_coupon_%s WHERE user_id = %s;"%(int(userId)%4,userId)
elif not userId:
sql = "SELECT * FROM a_coupon_%s WHERE activity_id = %s;"%(n,activityId)
else:
sql = "SELECT * FROM a_coupon_%s WHERE user_id = %s and activity_id = %s;"%(int(userId)%4,userId,activityId)
logger.info(sql)
res = dbA.select(sql)
logger.info(res)
l_vars.set("select_tableA_res",res)
except Exception as e:
logger.info(f'查询失败【{str(e)}】')
raise e
finally:
dbA.close()
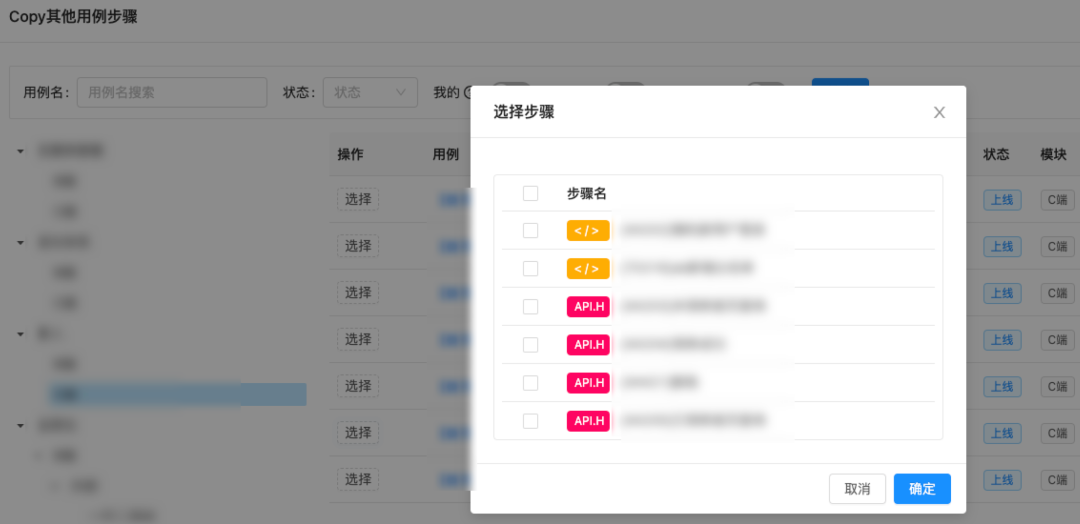
return res配置平台用例计划,选择依赖应用,按照自己的需要选择执行频次。然后再编辑计划,配置匹配规则,可以看到关联的自动化用例。
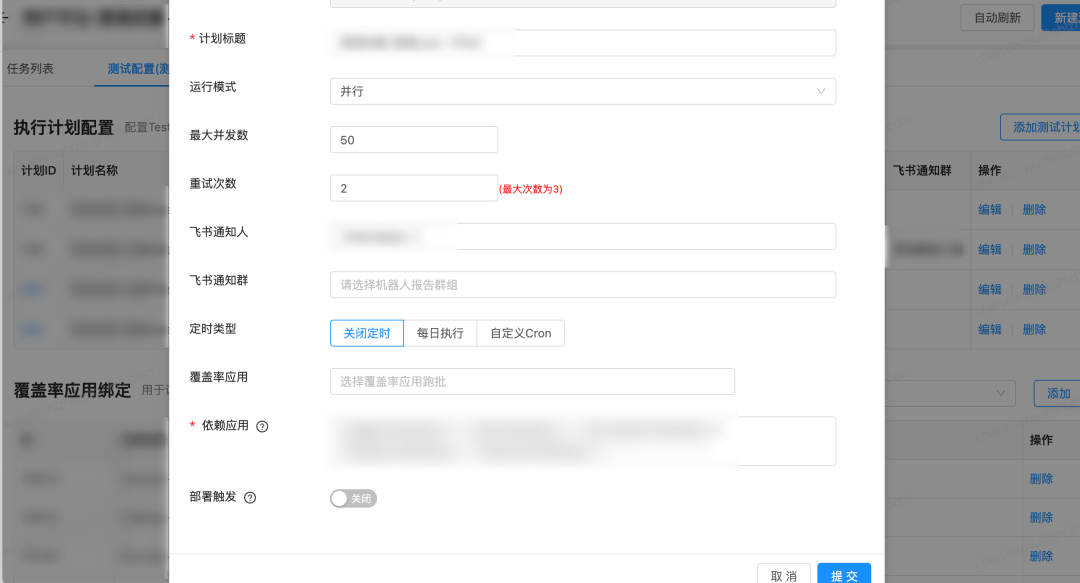
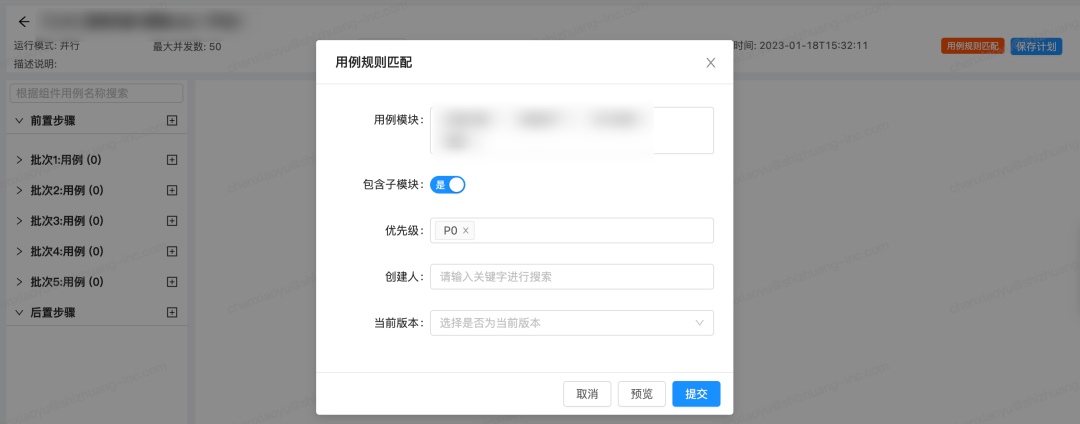
在用例平台绑定自动化case,在转测单平台添加自动化计划,已关联的用例在执行结束后会自动更新执行状态,提高手动执行的效率。
import json
import requests
from util.db_mysql import DBMySQL
from util.db_redis import DbRedis
def call(env_vars, g_vars, l_vars, sys_funcs, asserts, logger, **kwargs):
call_param = sys_funcs.get_call_param()
userId = call_param.get('userId')
activityId = call_param.get('activityId')
dbA = DBMySQL(env_vars.get("db.A"))
if not userId:
user_var = l_vars.get(call_param.get('var_userId'))
userId = user_var
if not activityId:
activityId_var = l_vars.get(call_param.get('var_activityId'))
activityId = activityId_var
if not userId and not activityId:
raise '请传入查询条件'
try:
if not activityId:
sql = "SELECT * FROM a_coupon_%s WHERE user_id = %s;"%(int(userId)%4,userId)
elif not userId:
sql = "SELECT * FROM a_coupon_%s WHERE activity_id = %s;"%(n,activityId)
else:
sql = "SELECT * FROM a_coupon_%s WHERE user_id = %s and activity_id = %s;"%(int(userId)%4,userId,activityId)
logger.info(sql)
res = dbA.select(sql)
logger.info(res)
l_vars.set("select_tableA_res",res)
except Exception as e:
logger.info(f'查询失败【{str(e)}】')
raise e
finally:
dbA.close()
return resimport json
import requests
def call(env_vars, g_vars, l_vars, sys_funcs, asserts, logger, **kwargs):
l_vars.set("user1",l_vars.get("sys.public.login.headers"))import json
import requests
def call(env_vars, g_vars, l_vars, sys_funcs, asserts, logger, **kwargs):
l_vars.set("sys.public.login.headers", l_vars.get("user1"))解决方法一:不使用平台的工具,代码如下:
import redis
redisConn = redis.Redis(host='redis.host', port=666, password='test123',db=1, decode_respnotallow=True)解决方法二:redis平台工具返回是数据是 bytes 类型,需要encoding一下
re = DbRedis.ger_redis(link_info)
test = re.get(test_key)
test_str = test.decode(encoding='utf-8')
key = key+test_str
re.set(key,"aaa")解决方式:需要db.commit() ,select语句不需要该语句
dbA = DBMySQL(db_A)
sql = "INSERT INTO t(name,age) VALUES (%s, %s);"
try:
res = db.insert(sql,['lucy', 18])
db.commit()
finally:
dbA.close()备注:delete方式,删除数据量是0.会有error。
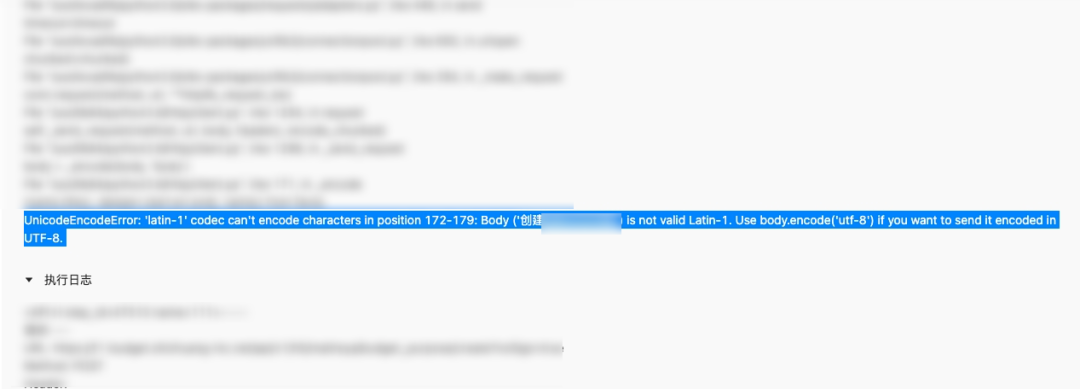
解决方式:请求头配置 application/json;charset=UTF-8

接入自动化平台后,方便了很多,也还有更多的使用场景待探索和交流。自动化最主要的目的是提效,时间节省下来后我们可以有更多的时间去思考异常场景以及复杂场景,做一些探索测试,减少因为用例设计遗漏而发生的问题。
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
查看Ruby的CSV库的文档,我非常确定这是可能且简单的。我只需要使用Ruby删除CSV文件的前三列,但我没有成功运行它。 最佳答案 csv_table=CSV.read(file_path_in,:headers=>true)csv_table.delete("header_name")csv_table.to_csv#=>ThenewCSVinstringformat检查CSV::Table文档:http://ruby-doc.org/stdlib-1.9.2/libdoc/csv/rdoc/CSV/Table.html
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我正在阅读SandiMetz的POODR,并且遇到了一个我不太了解的编码原则。这是代码:classBicycleattr_reader:size,:chain,:tire_sizedefinitialize(args={})@size=args[:size]||1@chain=args[:chain]||2@tire_size=args[:tire_size]||3post_initialize(args)endendclassMountainBike此代码将为其各自的属性输出1,2,3,4,5。我不明白的是查找方法。当一辆山地自行车被实例化时,因为它没有自己的initialize方法
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
我喜欢使用Textile或Markdown为我的项目编写自述文件,但是当我生成RDoc时,自述文件被解释为RDoc并且看起来非常糟糕。有没有办法让RDoc通过RedCloth或BlueCloth而不是它自己的格式化程序运行文件?它可以配置为自动检测文件后缀的格式吗?(例如README.textile通过RedCloth运行,但README.mdown通过BlueCloth运行) 最佳答案 使用YARD直接代替RDoc将允许您包含Textile或Markdown文件,只要它们的文件后缀是合理的。我经常使用类似于以下Rake任务的东西:
我想让一个yaml对象引用另一个,如下所示:intro:"Hello,dearuser."registration:$introThanksforregistering!new_message:$introYouhaveanewmessage!上面的语法只是它如何工作的一个例子(这也是它在thiscpanmodule中的工作方式。)我正在使用标准的rubyyaml解析器。这可能吗? 最佳答案 一些yaml对象确实引用了其他对象:irb>require'yaml'#=>trueirb>str="hello"#=>"hello"ir