日常开发系统中通常需要对接多个系统,需要用到适配器模式。
例如:支付方式就涉及多个系统对接。
国际惯例,先引入概念。
适配器模式:
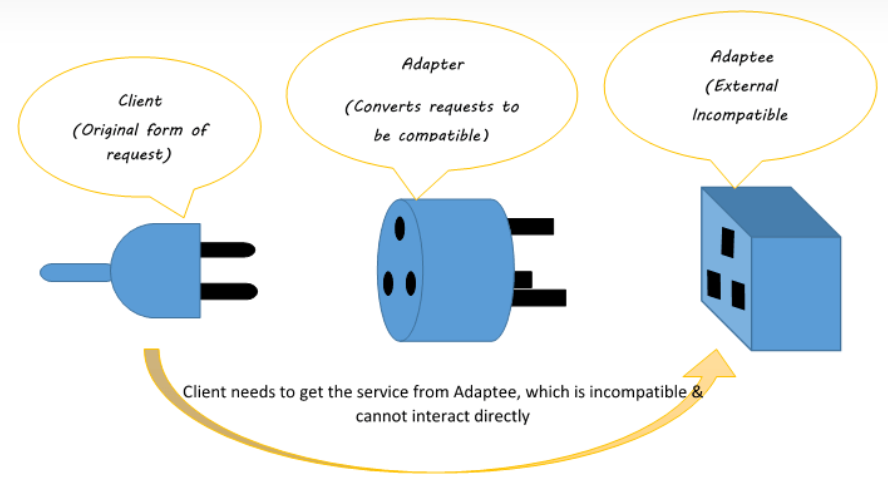
提到适配器自然就能想到手机用的电源适配器。
他的作用就是将220V交流电转换成手机使用的5V直流电。
适配器作用:将一个接口转换成另外一个接口,已符合客户的期望。

软件系统中,比如一期我们使用了阿里云的sdk包的一些功能接口。
但是二期我想换腾讯云sdk相同的功能。但是他们相同的功能,接口参数确不同。
我们不想按照腾讯云的接口修改我们的业务代码,毕竟业务逻辑已经经过反复测试验证了。可以把腾讯云的接口包装起来,实现一个一期的接口。这个工作叫【适配】。
在例如:
在软件系统中,你可能有很多种支付方式,微信支付,支付宝支付,各种银行。
但是他们的支付接口肯定都是不一样的,我不希望我新加一种支付方式就加去修改代码。
此时就需要有一个统一支付的适配器服务帮我们屏蔽各个支付方式的不同。
我的业务服务只和统一支付交互。统一支付向业务系统提供统一接口,统一支付负责路由不同支付系统后台,并屏蔽掉各系统差异。这个工作也叫【适配】
适配模式:

/**
* 目标接口:提供5V电压的一个接口
*/
public interface V5Power
{
public int provideV5Power();
}
/**
* 被适配者、已有功能:家用220V交流电
*/
public class V220Power
{
/**
* 提供220V电压
*/
public int provideV220Power()
{
System.out.println("我提供220V交流电压。");
return 220 ;
}
}
/**
* 适配器,有已有对象已有功能实现接口,把220V电压变成5V
*/
public class V5PowerAdapter implements V5Power
{
/**
* 组合的方式
*/
private V220Power v220Power ;
public V5PowerAdapter(V220Power v220Power)
{
this.v220Power = v220Power ;
}
@Override
public int provideV5Power()
{
int power = v220Power.provideV220Power() ;
//power经过各种操作-->5
System.out.println("适配器:我悄悄的适配了电压。");
return 5 ;
}
}public class Mobile
{
// 使用目标接口功能
public void inputPower(V5Power power)
{
int provideV5Power = power.provideV5Power();
System.out.println("手机(客户端):我需要5V电压充电,现在是-->" + provideV5Power + "V");
}
}
//测试
public class Test
{
public static void main(String[] args)
{
Mobile mobile = new Mobile();
V5Power v5Power = new V5PowerAdapter(new V220Power()) ;
mobile.inputPower(v5Power);
}
}定义:
将一个类的接口,转换成客户期望的另一个接口。适配器让原本接口不兼容的类可以合作无间。
适配模式说的通俗点就是用一个已有的功能类,去实现一个接口。这样该功能类,和原来的客户端代码都不需要改变,对于客户端来说相当于换了一种实现方式。
好处就是让客户从实现中【解耦】,下次在换其他的功能类,我就再写一个适配器。有点像策略模式中,我们换一个实现类一样。
当然,我们适配器可以包装很多被适配对象,即可以组合很多已有功能类。因为很多接口很复杂需要使用很多类。
同样,适配器也可以不使用【组合】对象形式,而是使用【继承】。
示例:
以前java集合类都实现了Enumeration枚举接口,可以遍历集合中每个元素,而无需知道它们在集合内元素是如何被管理。
之后推出了新的Iterator迭代器接口,这个接口和枚举接口很像,都可以让你遍历集合中每个元素。
不同的是,迭代器还提供了删除元素的能力。
面对遗留代码,这些代码暴露出来的是枚举接口,他们是老版本的java只支持枚举,但是我们希望新的代码中使用迭代器。只能用枚举实现一个迭代器。
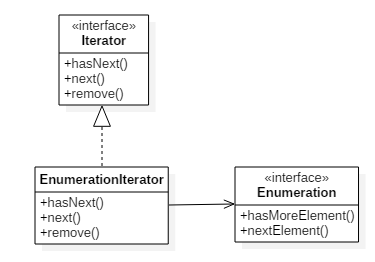
public class EnumerationIterator implements Iterator{
Enumeration enum;
public EnumerationIterator(Enumeration enum){
this.enum = enum;
}
public boolean hasNext(){
return enum.hasMoreElements();
}
public Object next(){
return enum.nextElement();
}
public void remove(){
throw new UnsupportedOperationException();
}
}
/*
枚举接口是只读的,适配器无法实现一个有实际功能的remove()方法
我们的实现方式并不完美,客户必须小心潜在的异常。
只要客户足够小心,并且在适配器的文档中作出说明,这也算是一个合理的解决方案。
*/
外观模式:
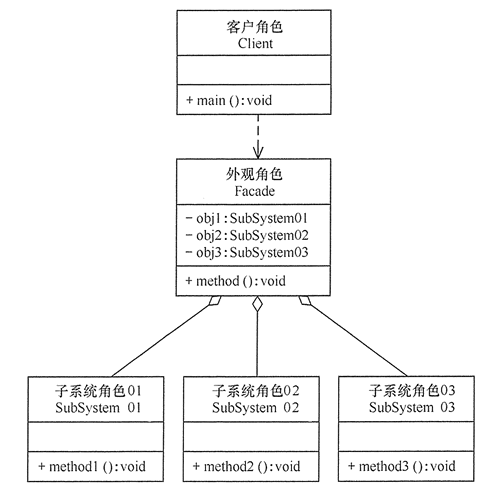
外观模式:提供一个统一接口,用来访问子系统中的一群接口。外观定义了一个高层接口,让子系统更容易使用。
例如:我们遥控器点击下自动就打开幕布、打开投影机、打开音响、开始放电影。而不是一步一步的自己操作。
不仅仅是简化了接口,也将客户从组建汇总解耦了出来。
目的就是让系统更加容易使用,也符合【最少知道】原则,因为客户只有【外观角色】一个朋友。
【最少知道】原则就是不要让太多类耦合在一起,免得修改系统时候,牵一发而动全身。对象尽量“少交朋友”。之和自己有关的交互即可。
就对象而言,在该对象的方法内,我们只应该调用属于以下范围的方法:
1.该对象本身
2.被当做方法的参数而传递进来的对象
3.此方法所创建或实例化的任何对象
4.对象的任何组建,即属性变量引用的对象
如果调用返回对象的方法,相当于向另外一个对象的子部分发出请求。我们就多依赖了一个对象。
|
// 不应用【最少知道】原则 public float getTemp(){ Thermometer thermometer = station.getThermometer(); return thermometer.getTemperature(); // 我们从气象站获取了温度计对象,然后从该对象获取了温度。 } |
|
// 应用【最少知道】原则 public float getTemp(){ return station.getTemperature(); // 应该直接让气象站给我温度,我不想依赖温度计对象。 } |
装饰模式:

用面向对象的方式对饮料进行描述。这种描述方式的局限在于。
我们饮料可以添加辅料。例如:大杯、加冰、加奶、双倍咖啡。
我们不可能一种组合就建一个类。那样类数量就爆炸了。
此时计算价格就非常困难。
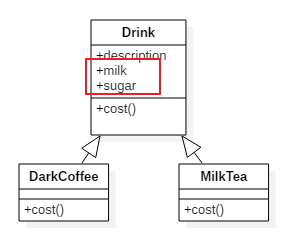
将各种调料放在基类中。调料可以是boolean或者数据或者枚举类型。
每种饮料计算价钱的时候就看这些调料是否有,或者有多少。
public class Drink{
private boolean milk;
private boolean sugar;
public double cost(){
double price = 0d;
if(milk){ price +=0.5; }
if(sugar){price +=0.1; }
return price;
}
public void addMilk(){
this.mocha=true;
}
public void addSugar(){
this.whip= true;
}
}
public class DarkCoffee extends Drink{
public double cost(){
double price = super.cost();
price += 2.0;
return price;
}
}
测试:
public class Test{
public static void main(String[] args){
Drink coffee = new DarkCoffee();
coffee.addMocha();
coffee.addWhip();
System.out.println(coffee.cost());
}
}这种设计存在问题:
1.如果调味品很多,Drink类非常庞大,且新加和删除调味品都需要修改类,调料改价格需要调整价格。
2.双倍调味料的情况boolean值无法满足。
3.很多调料是互斥的,例如iceCoffee是不能加mocha的,但是他还是继承了父类的addMocha()方法。这个方法他不适用,他必须覆盖这个方法让它什么都不做。
不符合【开闭原则】
装饰模式解释:
调料可以包装基础饮料,因为装饰者和被装饰者有相同的超类型,所以可以套娃形式一直套下去。
装饰者可以在所委托被装饰者的行为前后,加上自己的行为,已达到特定目的。
计算价格类似于递归,不断委托给父类,最后统一回溯。
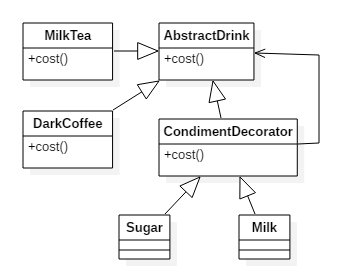
abstract class Drink{
public String description = "Unknown beverage";
public String getDescription(){
return description;
}
public abstract double cost();
}
// 装饰类
abstract class CondimentDecorator extends Drink{
public abstract String getDescription();
}
// 饮料
class DarkCoffee extends Drink{
public DarkCoffee(){
this.description = "DarkCoffee";
}
public double cost(){
return 1.99;
}
}
// 包装类:调料
class Sugar extends CondimentDecorator{
Drink drink;
public Sugar(Drink drink){
this.drink = drink;
}
public String getDescription(){
return drink.getDescription() + ", add sugar";
}
public double cost(){
return .20 + drink.cost();
}
}
//测试
class Test{
public static void main(String[] args){
Drink drink = new DarkCoffee();
drink = new Sugar(drink);
// 加双份糖
drink = new Sugar(drink);
System.out.println(drink.getDescription() + " ,$"+drink.cost());
//输出:DarkCoffee, add sugar, add sugar ,$2.39
}
}public interface Drink{
public double cost();
}
public class DarkCoffee implements Drink{
public double cost(){
return 2.5;
}
}
public class Decorator implements Drink{
private Drink drink;
public Decorator (Drink drink){
this.drink= drink;
}
public double cost(){
return drink.cost();
}
}
public class Sugar extends Decorator {
public Sugar (Drink drink){
super(drink);
}
public double cost(){
return super.cost() + 0.1;
}
}
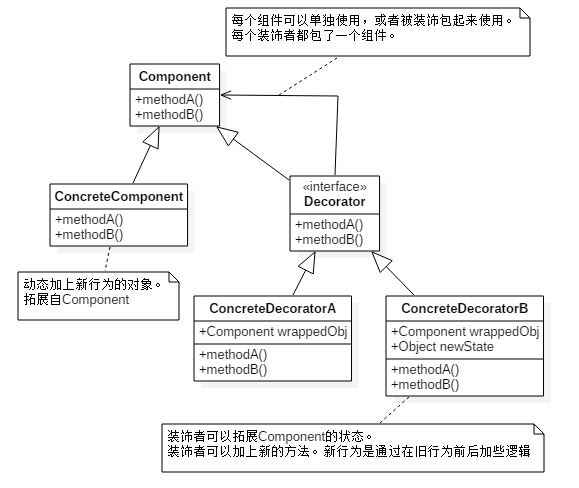
装饰模式:动态将责任附加到对象上,若要拓展功能,装饰者提供了比继承更有弹性的替代方案。
装饰者模式容易造成设计中大量的小类。数量太多。容易把人看懵。例如:java.io

/*
编写一个装饰者,将输入流内所有大写字符转小写。
我们需要拓展InputStream。
*/
public class LowerCaseInputStream extends FilterInputStream {
public LowerCaseInputStream(InputStream in) {
super(in);
}
public int read() throws IOException {
int c = in.read();
return (c == -1 ? c : Character.toLowerCase((char)c));
}
public int read(byte[] b, int offset, int len) throws IOException {
int result = in.read(b, offset, len);
for (int i = offset; i < offset+result; i++) {
b[i] = (byte)Character.toLowerCase((char)b[i]);
}
return result;
}
}
public class InputTest {
public static void main(String[] args) throws IOException {
int c;
InputStream in = null;
try {
in =
new LowerCaseInputStream(
new BufferedInputStream(
new FileInputStream("test.txt")));
while((c = in.read()) >= 0) {
System.out.print((char)c);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (in != null) { in.close(); }
}
System.out.println();
try (InputStream in2 =
new LowerCaseInputStream(
new BufferedInputStream(
new FileInputStream("test.txt"))))
{
while((c = in2.read()) >= 0) {
System.out.print((char)c);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}例如:我们对HttpServletRequest进行拦截进行处理,实现过滤请求参数。
1). Servlet API 中提供了一个 HttpServletRequestWrapper 类来包装原始的 request 对象,
HttpServletRequestWrapper 类实现了 HttpServletRequest 接口中的所有方法,
这些方法的内部实现都是仅仅调用了一下所包装的的 request 对象的对应方法
//包装类实现 ServletRequest 接口.
public class ServletRequestWrapper implements ServletRequest {
//被包装的那个 ServletRequest 对象
private ServletRequest request;
//构造器传入 ServletRequest 实现类对象
public ServletRequestWrapper(ServletRequest request) {
if (request == null) {
throw new IllegalArgumentException("Request cannot be null");
}
this.request = request;
}
//具体实现 ServletRequest 的方法: 调用被包装的那个成员变量的方法实现。
public Object getAttribute(String name) {
return this.request.getAttribute(name);
}
public Enumeration getAttributeNames() {
return this.request.getAttributeNames();
}
//...
}
2). 作用: 用于对 HttpServletRequest 或 HttpServletResponse 的某一个方法进行修改或增强.
public class MyHttpServletRequest extends HttpServletRequestWrapper{
public MyHttpServletRequest(HttpServletRequest request) {
super(request);
}
@Override
public String getParameter(String name) {
String val = super.getParameter(name);
if(val != null && val.contains(" fuck ")){
val = val.replace("fuck", "****");
}
return val;
}
}
3). 使用: 在 Filter 中, 利用 MyHttpServletRequest 替换传入的 HttpServletRequest
HttpServletRequest req = new MyHttpServletRequest(request);
filterChain.doFilter(req, response);例如:在一个方法前后打印时间
// 接口
public interface Dao {
public void insert();
public void delete();
public void update();
}
// 基础实现类
public class DaoImpl implements Dao {
@Override
public void insert() {
System.out.println("DaoImpl.insert()");
}
@Override
public void delete() {
System.out.println("DaoImpl.delete()");
}
@Override
public void update() {
System.out.println("DaoImpl.update()");
}
}
// 包装类
public class LogDao implements Dao {
private Dao dao;
public LogDao(Dao dao) {
this.dao = dao;
}
@Override
public void insert() {
System.out.println("insert()方法开始时间:" + System.currentTimeMillis());
dao.insert();
System.out.println("insert()方法结束时间:" + System.currentTimeMillis());
}
@Override
public void delete() {
dao.delete();
}
@Override
public void update() {
System.out.println("update()方法开始时间:" + System.currentTimeMillis());
dao.update();
System.out.println("update()方法结束时间:" + System.currentTimeMillis());
}
}
// 调用时候 Dao dao = new LogDao(new DaoImpl());
// 对于调用方来说,只知道调用了dao,不知道加上了日志功能
// 问题:1.输出日志的逻辑无法复用;2.输入日志和业务逻辑有耦合。
和装饰模式非常相似的还有一个就是代理模式:
代理模式:
为另外一个对象提供一个替身或者占位符控制对这个对象的访问。

代理模式的典型特点就是,将客户对subject施加的方法调用拦截下来。然后进行自己的处理。
我们通常使用工厂模式,返回相应对象的代理对象。
其实装饰模式和代理模式和适配器模式很像。都是包装一个对象,然后利用这个对象的功能搞出点对外提供的方法。
|
装饰模式 |
代理模式 |
适配器模式 |
外观模式 |
|
目的:不改变接口,加入责任 |
目的:控制对象的访问 |
目的:将一个接口转成另一个接口 |
目的:让接口跟简单 |
|
装饰者模式可以让新的行为和责任要加入到设计中。而无需修改现有的代码。 |
代理对象代表对象,不光是为对象加上动作。 |
可以整合若干类来提供客户需要的接口。 |
|
|
当一个方法调用被委托给装饰者的时候, 装饰者有点像递归套娃,你不知道当前是第几层。 |
可以使用新的库和子集合,而无需改变任何代码。适配器会按照原接口给你包好。 |
||
|
拓展包装对象的行为和责任,不是简单的传送 |
一定进行接口的装换。 |
示例:多支付系统解决方案

通过加入适配器模式,订单 Service 在进行支付时调用的不再是外部的支付接口,而是“支付方式”接口,与外部系统解耦。
只要保证“支付方式”接口是稳定的,那么订单 Service 就是稳定的。比如:
当支付宝支付接口发生变更时,影响的只限于支付宝 Adapter;
当微信支付接口发生变更时,影响的只限于微信支付 Adapter;
当要增加一个新的支付方式时,只需要再写一个新的 Adapter。
日后不论哪种变更,要修改的代码范围缩小了,维护成本自然降低了,代码质量就提高了。
问题:
在划分微服务过程中,经常纠结,对外的功能有没有必要抽象出一个代理服务。专门负责与某厂商对接。
根据适配器的理念,如果这个代理服务如果能抽象出标准的接口,那他就有独立的必要。核心业务服务只和代理服务交互,代理服务屏蔽外部厂商的不同。
日后厂商有变动,我们修改范围控制在代理服务内,不会涉及到核心业务服务。
例如:我们一般会开发一个统一支付的服务,这个服务对接各个支付系统,对内提供标准支付接口,业务服务只和统一支付交互。
同时统一支付还能帮助我们处理对账、过期自动退款等功能。让业务系统稳定,轻便。
本文来自博客园,作者:wanglifeng,转载请注明原文链接: https://www.cnblogs.com/wanglifeng717/p/16348529.html
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最