大家好,我是三友~~
随着微服务盛行,很多公司都把系统按照业务边界拆成了很多微服务,在排错查日志的时候,因为业务链路贯穿着很多微服务节点,导致定位某个请求的日志以及上下游业务的日志会变得有些困难。
这时候可能有的小伙伴就会想到使用SkyWalking,Pinpoint等分布式追踪系统来解决,并且这些系统通常都是无侵入性的,同时也会提供相对友好的管理界面来进行链路Span的查询,但是搭建分布式追踪系统还是需要一定的成本的,所以本文要说的并不是这些分布式追踪系统,而是一款简单、易用、几乎零侵入、适合中小型公司使用的日志追踪框架TLog。
TLog提供了一种最简单的方式来解决日志追踪问题,TLog会自动的对你的日志进行打标签,帮你自动生成traceId贯穿你微服务的一整条链路,在排查日志的时候,可以根据traceId来快速定位请求处理的链路。
TLog不收集日志,只在对你原来打印的日志上增强,将请求链路信息traceId绑定到你打印的日志上。当出现微服务中那么多节点的情况,官方推荐使用TLog+日志收集方案来解决。当然分布式追踪系统其实是链路追踪一个最终的解决方案,如果项目中已经上了分布式追踪系统,那TLog并不适用。
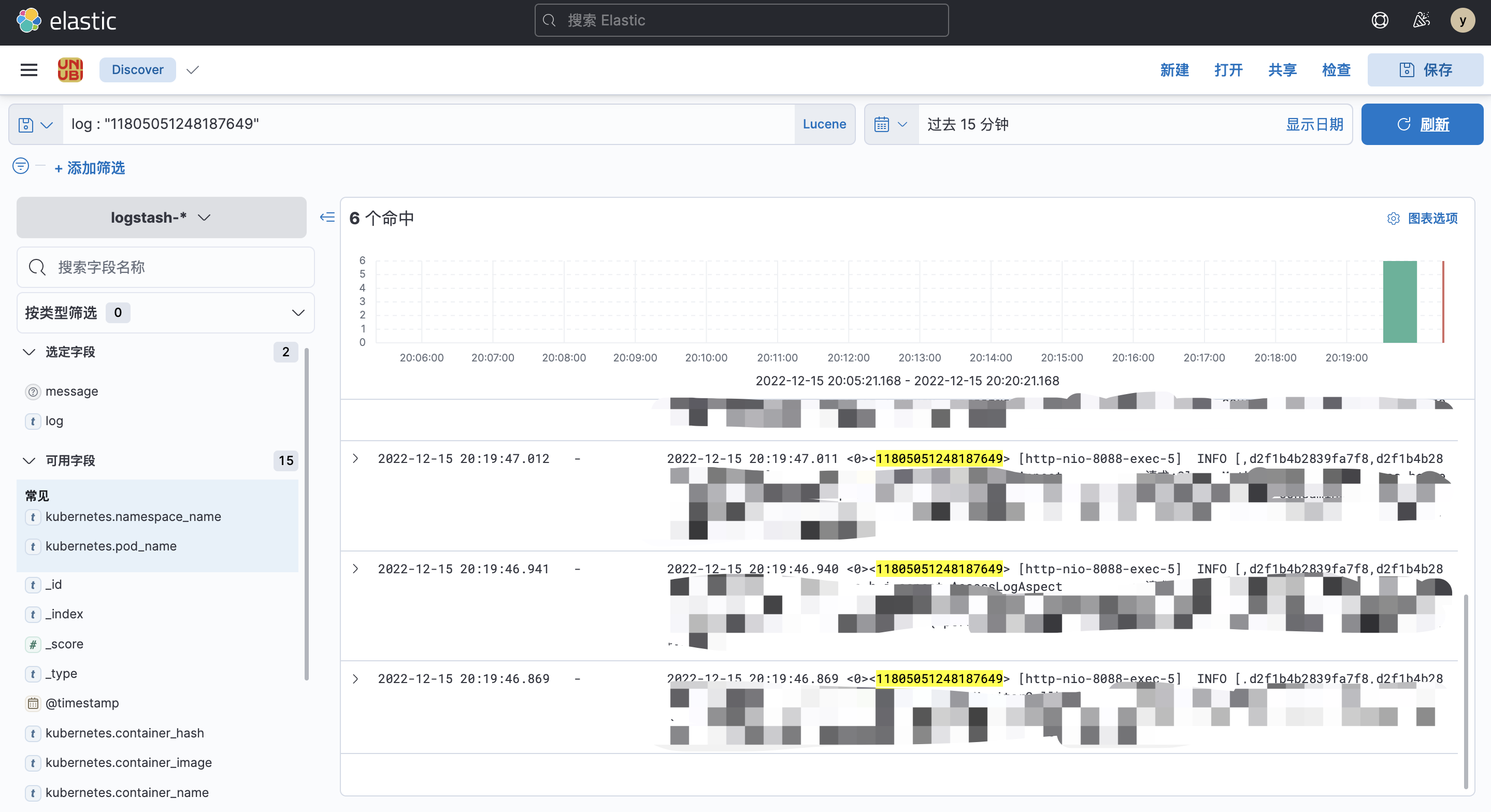
如下图,是ELK配合TLog,快速定位请求处理的链路的示例。
<dependency>
<groupId>com.yomahub</groupId>
<artifactId>tlog-all-spring-boot-starter</artifactId>
<version>1.5.0</version>
</dependency>
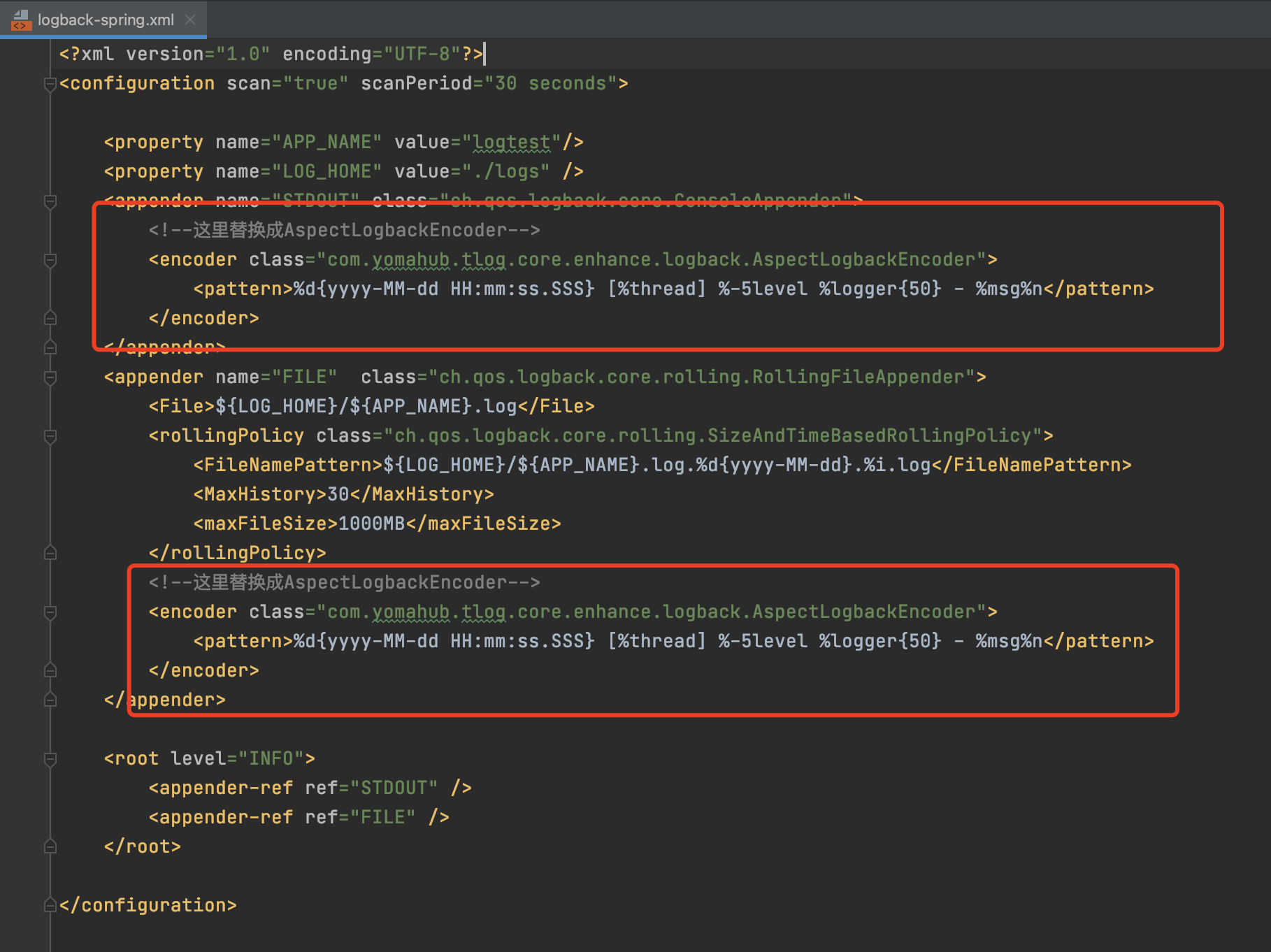
到这其实就已经完成了配置。
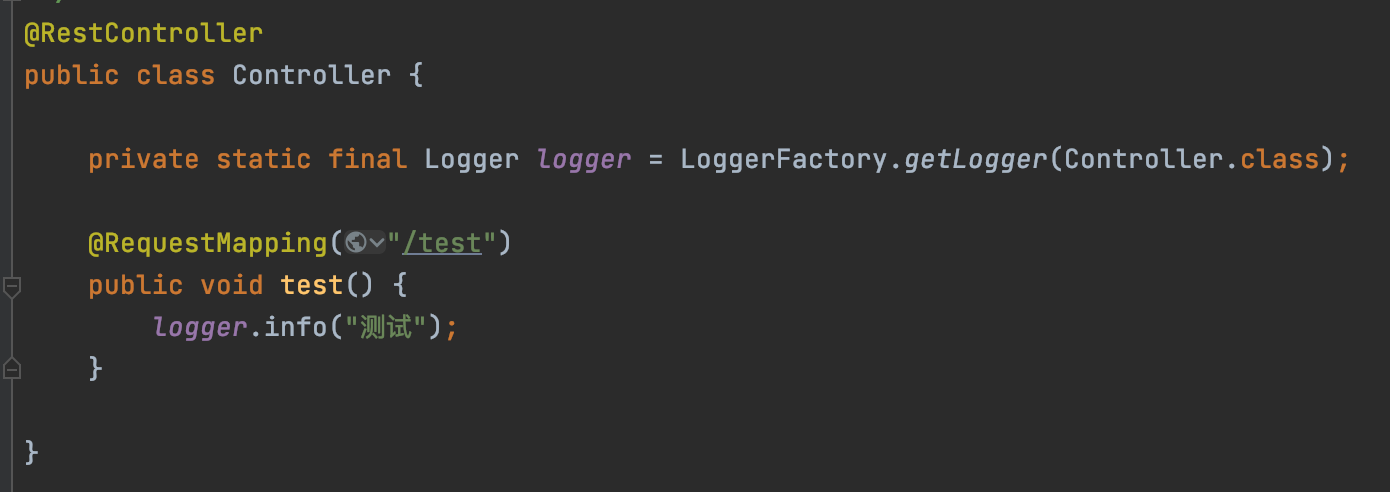
这里是通过slf4j的LoggerFactory获取Logger对象,因为logback适配了slf4j,最终会通过logback来输出日志。

从这可以看出,11794076298070144 就是本次日志输出的时候生成的一个请求的traceId,在排查日志的时候就可以通过这个traceId去搜索出整个请求的链路日志。
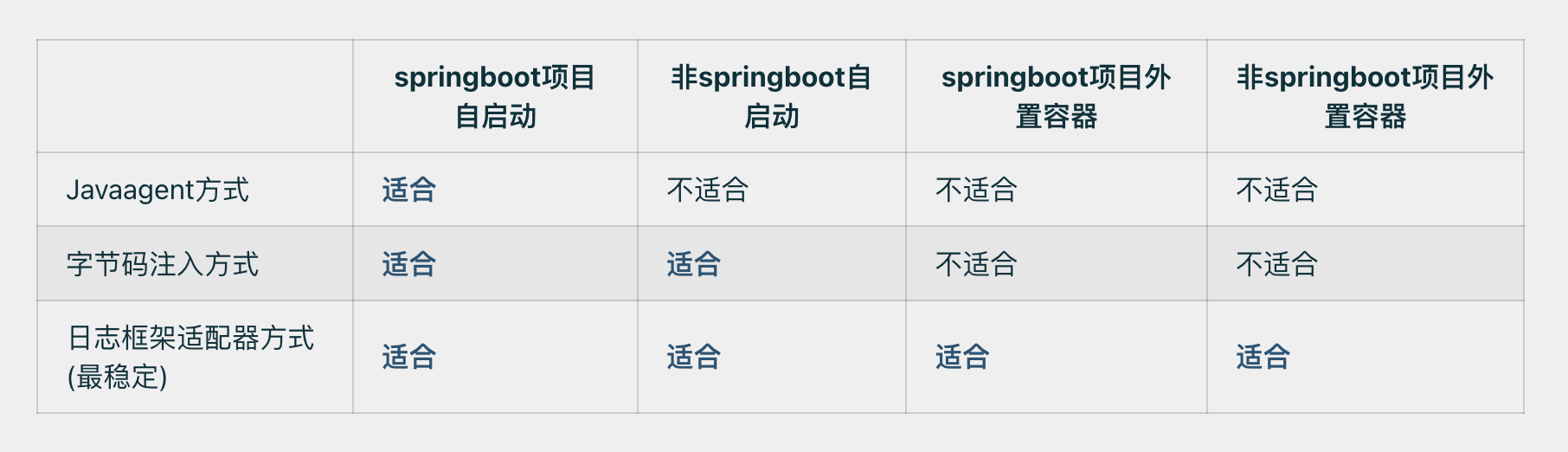
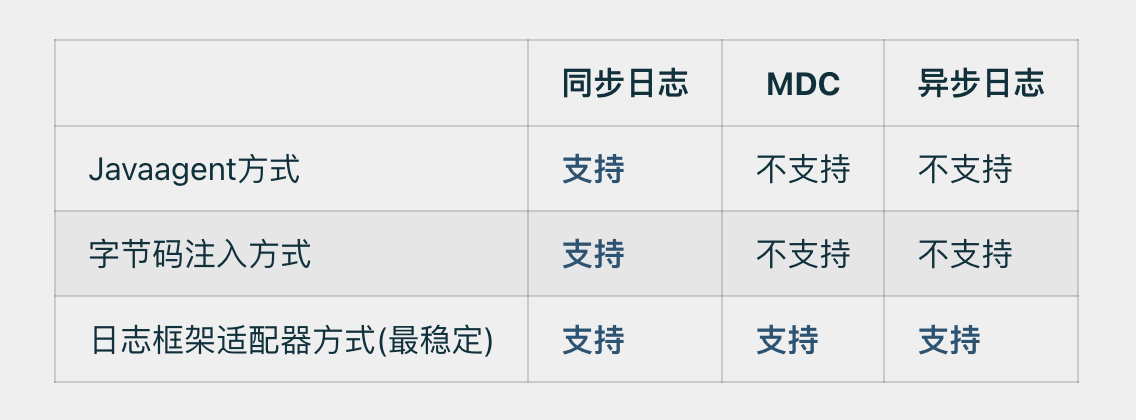
TLog总共提供了三种方式接入项目
上面案例的接入方式其实是属于日志框架适配器方式,并且是对于Logback框架的适配。TLog除了适配了Logback框架,还适配了Log4j框架和Log4j2框架,项目中可自行选择。
Javaagent接入方式和字节码注入方式相比与日志框架适配器方式对代码的入侵性更小,但是这两种方式仅仅只支持SpringBoot项目,并且相较于日志框架适配器的方式,MDC和异步日志功能并不支持,所以要想完整体验TLog的功能,还是建议选择日志框架适配器方式,日志框架适配器方式其实接入也很快,其实也就是修改一下配置文件的事。
前面在介绍TLog的时候,提到TLog会自动的对你的日志进行打标签,这个标签就是日志标签,一个日志标签最多可以包含如下信息:
默认是按照如下labelPattern进行数据拼接生成日志标签,所以默认只打出spanId和traceId。

这也就是上面为什么示例中会输出 <0><11794076298070144> 这种格式的原因,前面的0其实就是spanId。
如果你想改变日志标签输出其它信息或者输出的顺序,只需要在SpringBoot配置文件中配置日志标签的生成样式就行。
tlog.pattern=[$preApp][$preIp][$spanId][$traceId]
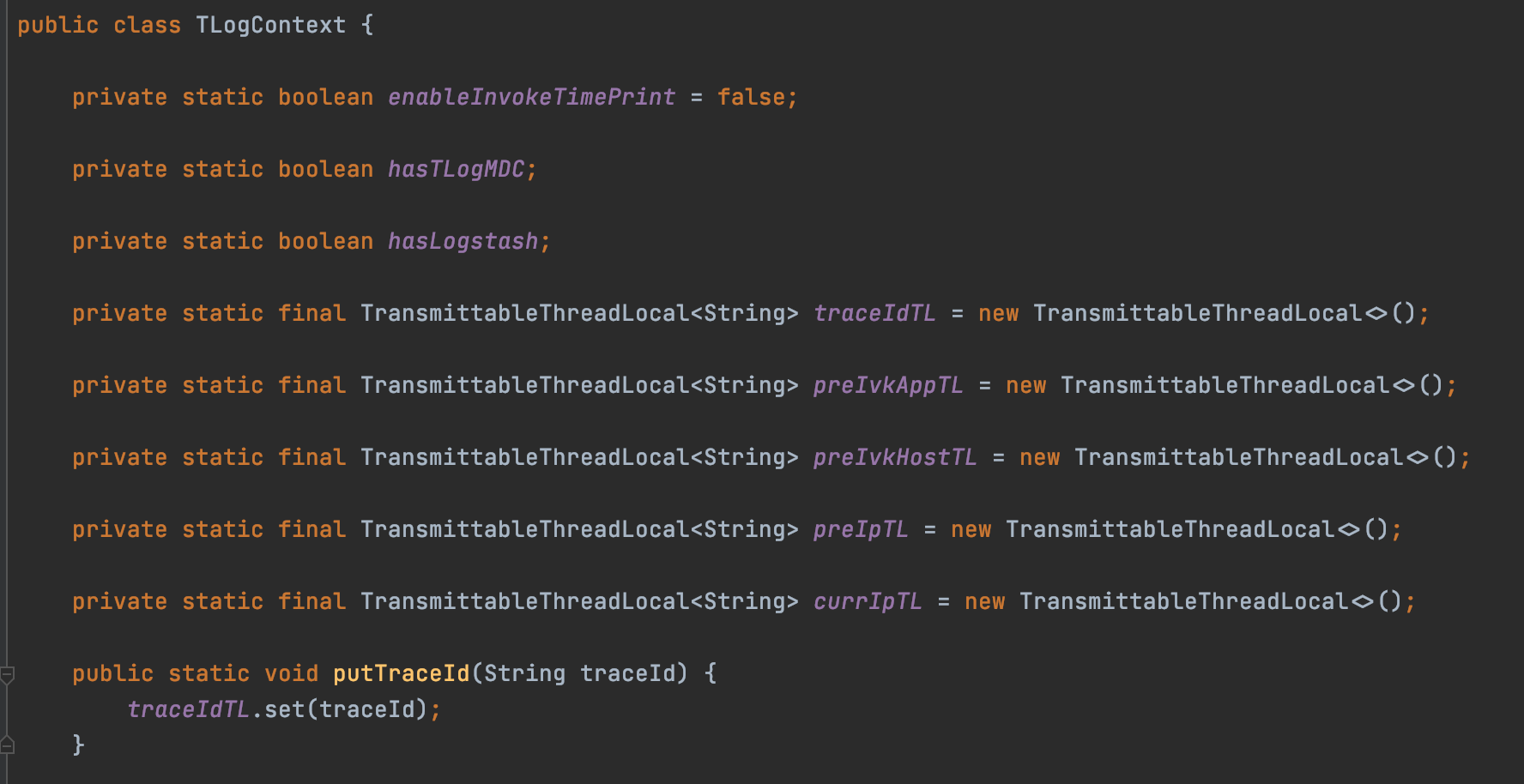
TLogContext是TLog是一个核心的组件,这个组件内部是使用了TransmittableThreadLocal来传递traceId、preApp等信息。
当有一个请求过来的时候,会从解析出traceId、preApp等信息,然后设置到TransmittableThreadLocal中,之后就可以在整个调用链路中从TLogContext中获取到traceId等信息。
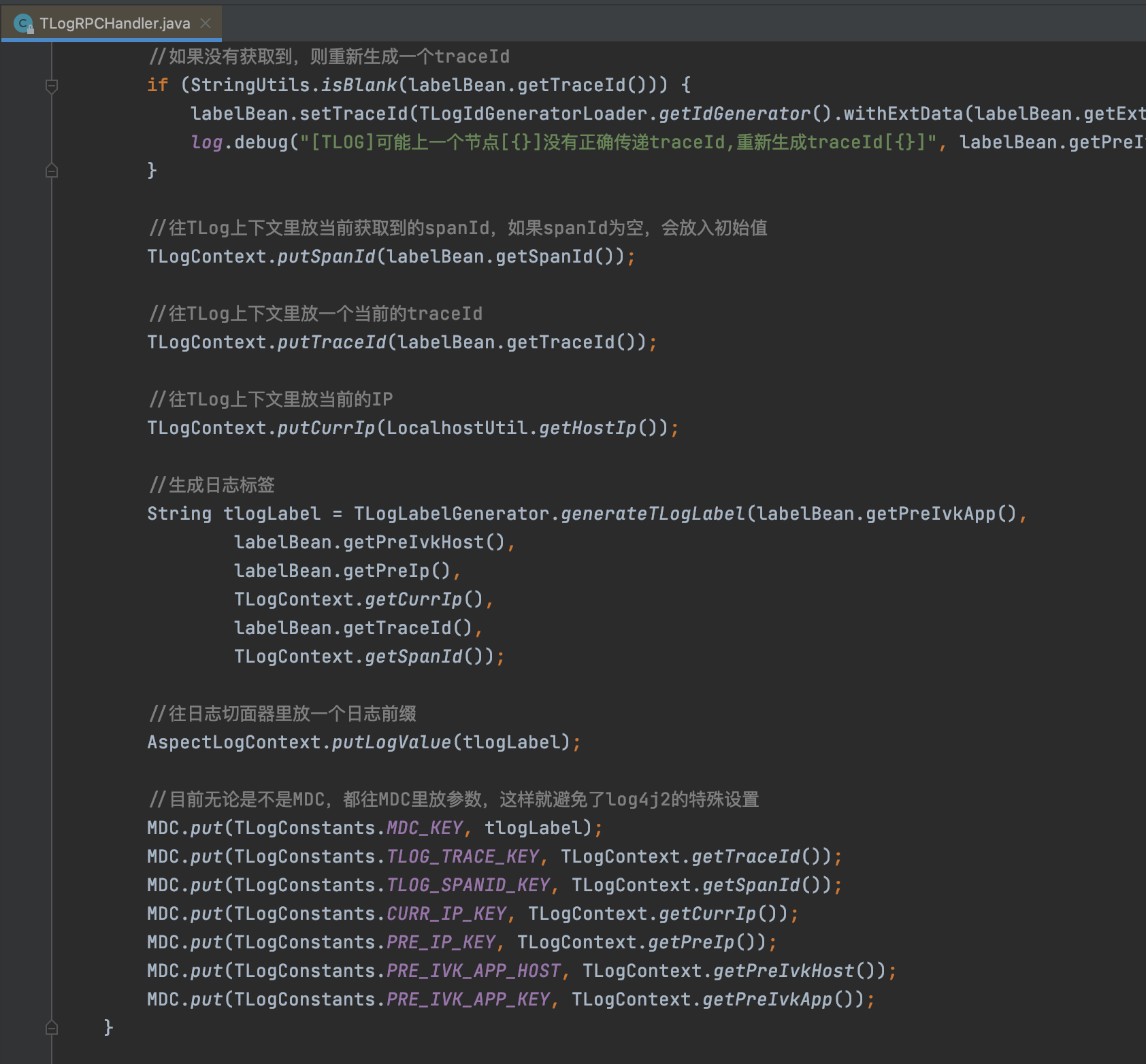
这个组件是用来处理调用方传递的traceId、preApp等信息,设置到TLogContext和MDC中,同时根据日志标签的格式生成日志标签。
在实际项目中,一个请求处理过程可能会出现以下情况
那么对于这些情况来说,traceId应该需要在异步线程、跨服务、MQ等中传递,以便更好地排查一个请求的处理链路。
而TLog对于以上可能出现的情况都做了大量的适配,保证traceId能够在异步线程、微服务间、MQ等中能够正确传递。
所谓的一般异步线程就是指直接通过new Thread的方法来创建异步线程,然后来执行,这种方式TLog是天然支持携带traceId的,如图。

执行结果
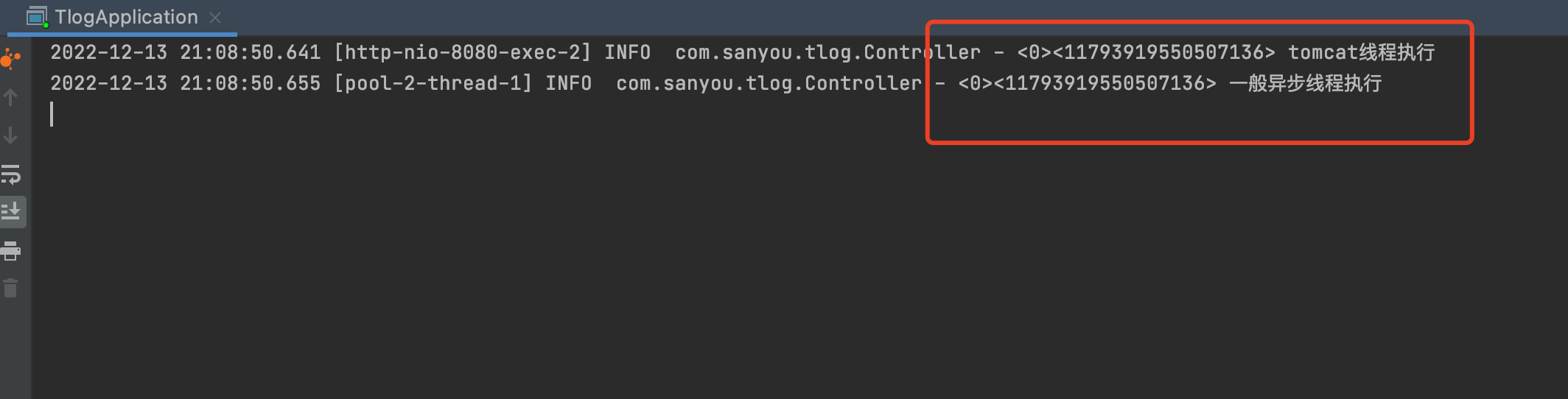
从这可以看出这种异步方式的确成功传递了traceId。
对于线程池来说,其实默认也是支持传递traceId,但是由于线程池中的线程是可以复用了,为了保证线程间的数据互不干扰,需要使用TLogInheritableTask将提交的任务进行包装。
ThreadPoolExecutor pool =
new ThreadPoolExecutor(1, 2, 1, TimeUnit.SECONDS, new LinkedBlockingQueue<>(10));
pool.execute(new TLogInheritableTask() {
@Override
public void runTask() {
logger.info("异步执行");
}
});
上述代码的写法会有点耦合,每次提交任务都需要创建一个TLogInheritableTask,比较麻烦,可以按如下写法进行简化。
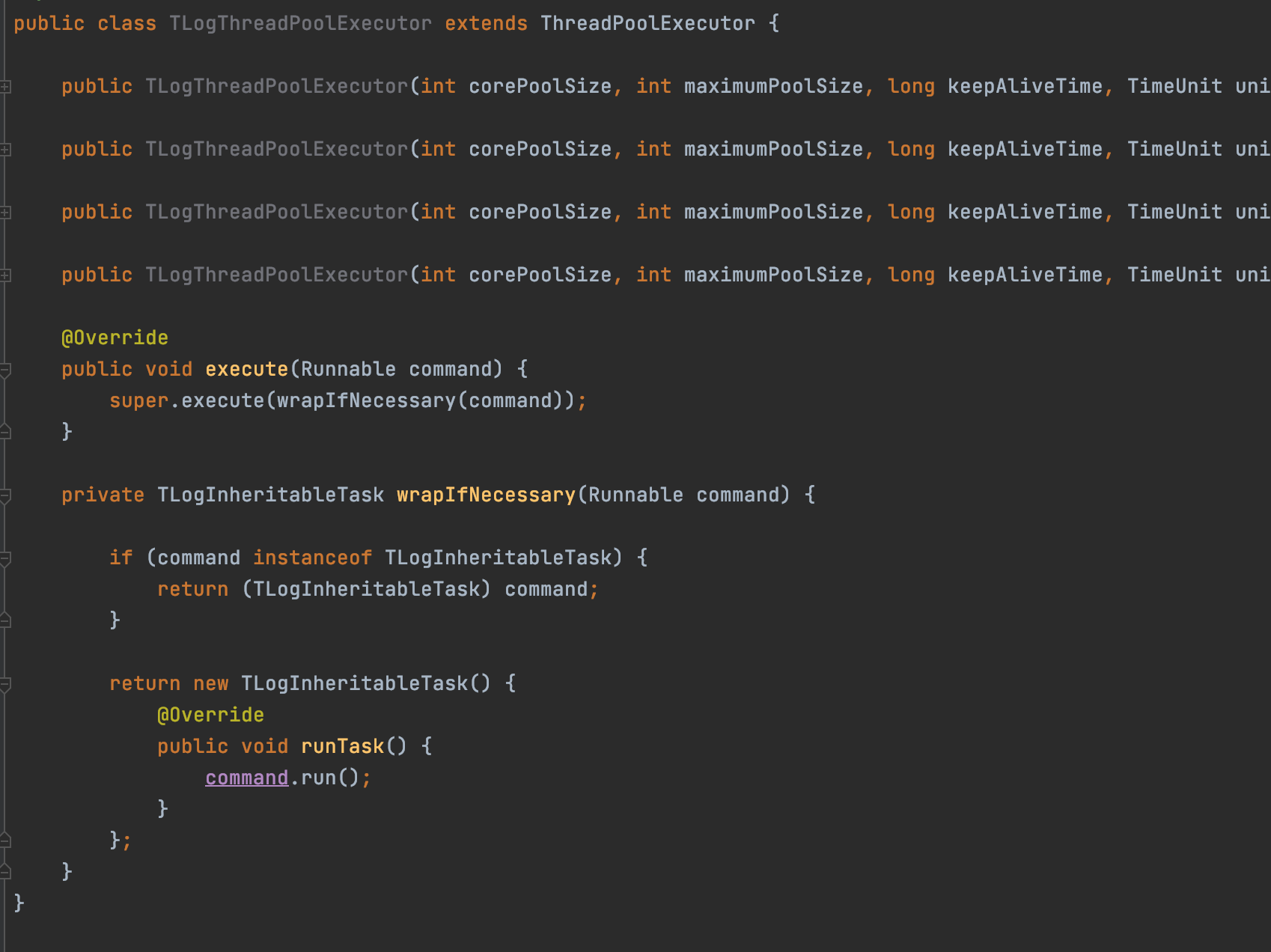
自己写个TLogThreadPoolExecutor继承ThreadPoolExecutor,重写execute方法(submit最终也会调用execute方法执行),然后将提交的任务统一包装成TLogInheritableTask,这样需要使用线程池的地方直接创建TLogThreadPoolExecutor就可以了,就不需要在提交任务的时候创建TLogInheritableTask了。
ThreadPoolExecutor pool =
new TLogThreadPoolExecutor(1, 2, 1, TimeUnit.SECONDS, new LinkedBlockingQueue<>(10));
pool.execute(() -> logger.info("异步执行"));
除了对异步线程的支持,TLog也支持常见的Dubbo,Dubbox,OpenFeign三大RPC框架,在SpringBoot项目中不需要任何配置,只需要引入依赖就可以实现traceId在服务之间的传递
对于Dubbo和Dubbox的支持是基于Dubbo的Filter扩展点来的

TLog通过SPI机制扩展Filter,在消费者发送请求前从TLogContext获取到traceId,然后将traceId和其它调用者数据设置请求数据中,服务提供者在处理请求的时候,也会经过Filter,从请求中获取到traceId等信息,然后设置到TLogContext中,从而实现了traceId在dubbo的消费者和提供者之间的传递。
对于OpenFeign的支持其实也是通过Feign提供的扩展点RequestInterceptor来实现的
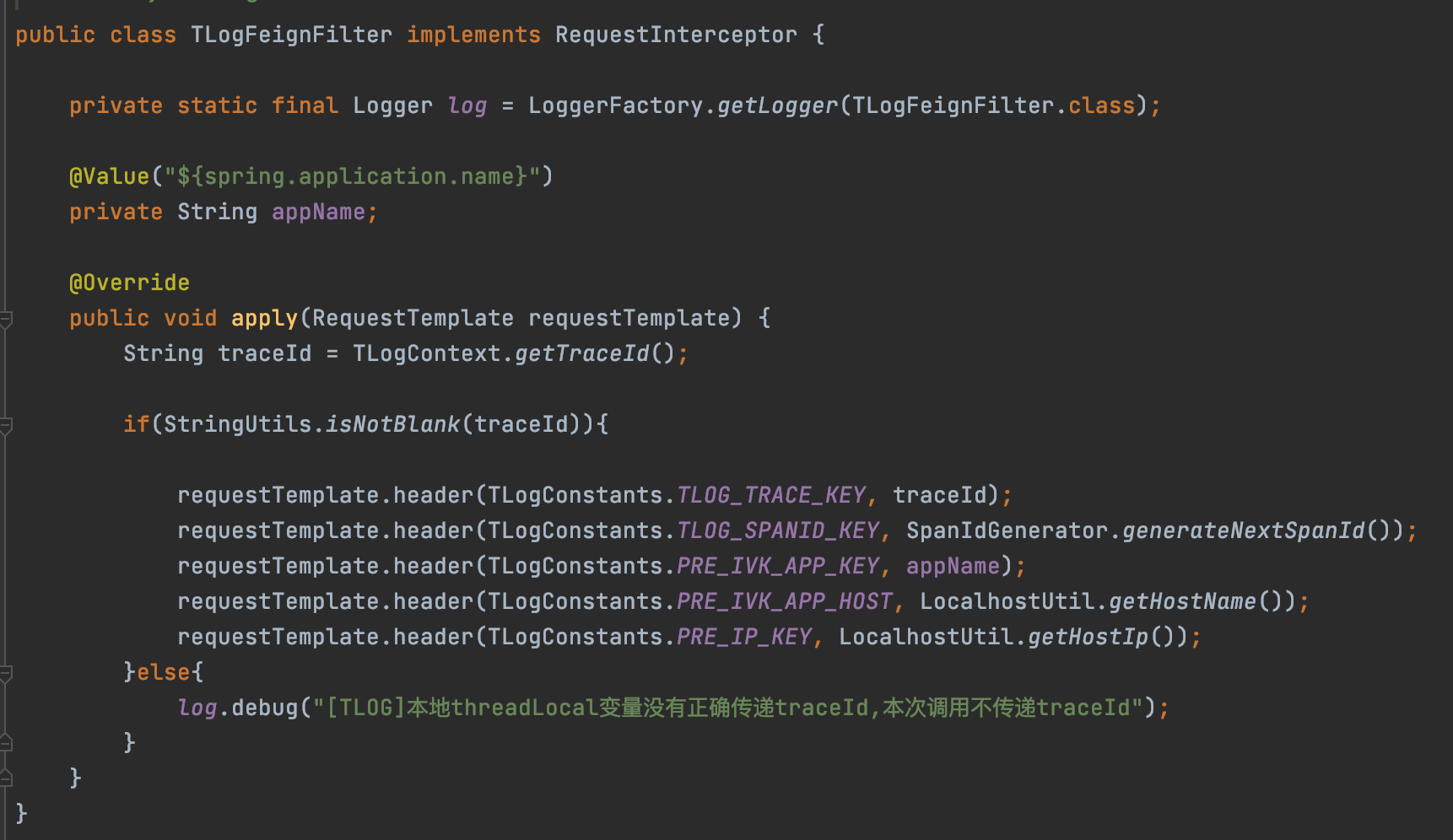
发送请求之前,从TLogContext获取到traceId,将traceId等信息添加到请求头中,然后就可以通过Http请求将traceId等信息传递。
当被调用方接收到请求之后,会经过TLogWebInterceptor这个拦截器进行拦截,从请求头中获取到这些参数,设置到TLogContext中。

除了一些RPC框架,TLog也对一些Http框架进行了适配,比如
使用这些Http框架也可以实现traceId的传递
其实这些框架的适配跟Feign的适配都是大同小异,都是基于这些Http框架各自提供的扩展点进行适配的,将traceId等信息放到请求头中,这里都不举例了,具体的使用方法可以在官网查看。
同样的,TLog也适配了SpringCloud Gateway

原理也是一样的,就是适配了Gateway的GlobalFilter,从请求头中获取traceId等信息。
除了适配了Gateway网关,TLog也适配了Soul网关。
对于MQ的支持跟异步线程差不多,需要将你发送的消息包装成TLogMqWrapBean对象
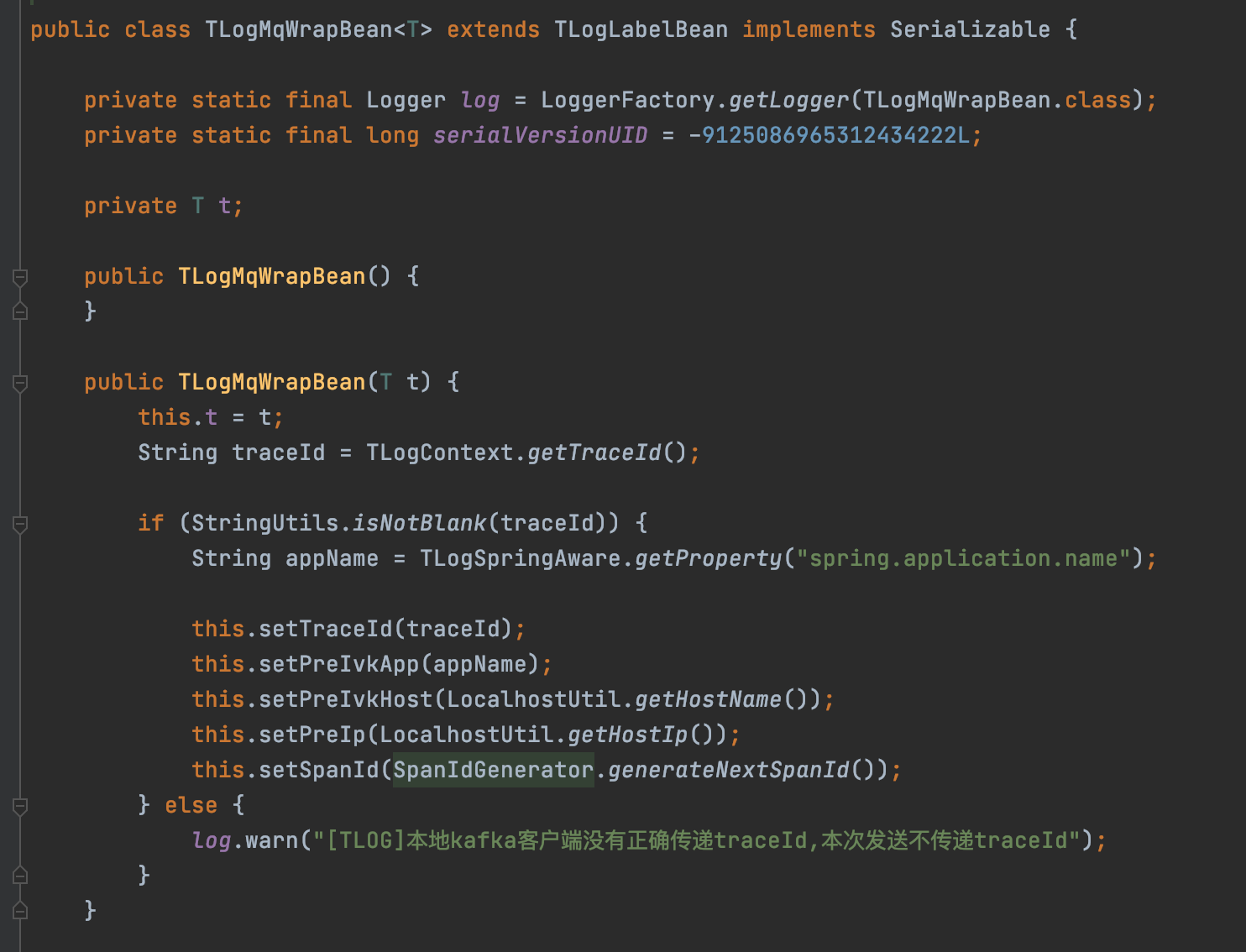
发送的时候直接发送TLogMqWrapBean对象过去
TLogMqWrapBean<BizBean> tLogMqWrap = new TLogMqWrapBean(bizBean);
mqClient.send(tLogMqWrap);
TLogMqWrapBean会将traceId等信息携带,消费者接受到TLogMqWrapBean,然后通过TLogMqConsumerProcessor处理业务消息。
TLogMqConsumerProcessor.process(tLogMqWrapBean, new TLogMqRunner<BizBean>() {
@Override
public void mqConsume(BizBean o) {
//业务操作
}
});
如此就实现了traceId通过MQ传递。
在实际使用中,根据不同的MQ的类型,可以将消息包装成TLogMqWrapBean对象的过程和处理消息的过程做统一的封装处理,以减少发送消息和处理消息对于TLog的耦合。
TLog主要是支持一下四种任务框架
其中,spring-scheduled和XXL-JOB在SpringBoot环境底下是无需任务配置的,只需要引入依赖即可。
Timer在使用的时候需要将任务包装成TLogTimerTask,Quartz需要把QuartzJobBean替换成TLogQuartzJobBean就可以了。
其实从上面的各种适配可以看出,其实本质都是一样的,就是根据具体框架的扩展点,在发送请求之前从TLogContext获取到traceId,将traceId等调用者的信息在请求中携带,然后被调用方解析请求,取出traceId和调用者信息,设置到被调用方服务中的TLogContext中。
所以,如果一旦需要遇到官方还未适配的框架或者组件,可以参照上述适配过程进行适配即可。
总的来说,TLog是一款非常优秀的日志追踪的框架,很适合中小公司使用。这里来总结一下TLog的特性
由于本文篇幅有限,无法全面对TLog进行讲解,如果想深入了解该框架,可自行阅读官网或者源码。
官网:https://tlog.yomahub.com
github地址:https://github.com/dromara/TLog
往期热门文章推荐
撸了一个简易的配置中心,顺带还给整合到了SpringCloud
扫码或者搜索关注公众号 三友的java日记 ,及时干货不错过,公众号致力于通过画图加上通俗易懂的语言讲解技术,让技术更加容易学习,回复 面试 即可获得一套面试真题。

如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
我正在尝试创建一个带有项目符号字符的Ruby1.9.3字符串。str="•"+"helloworld"但是,当我输入它时,我收到有关非ASCII字符的语法错误。我该怎么做? 最佳答案 你可以把Unicode字符放在那里。str="\u2022"+"helloworld" 关于ruby-如何在Ruby字符串中插入项目符号字符?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1195
我的Rails站点使用了一个确实不是很好的gem。每次我需要做一些新的事情时,我最终不得不花费与向实际Rails项目添加代码一样多的时间来为gem添加功能。但我不介意,我将我的Gemfile设置为指向我的gem的GitHub分支(我尝试提交PR,但维护者似乎已经下台)。问题是我真的没有找到一种合理的方法来测试我添加到gem的新东西。在railsc中测试它会特别好,但我能想到的唯一方法是a)更改~/.rvm/gems/.../foo。rb,这看起来不对或者b)升级版本,推送到Github,然后运行bundleup,这除了耗时之外显然是一场灾难,因为我不确定我所做的promise是否正
如何在出现异常时指定全局救援,如果您将Sinatra用于API或应用程序,您将如何处理日志记录? 最佳答案 404可以在not_found方法的帮助下处理,例如:not_founddo'Sitedoesnotexist.'end500s可以通过调用带有block的错误方法来处理,例如:errordo"Applicationerror.Plstrylater."end错误的详细信息可以通过request.env中的sinatra.error访问,如下所示:errordo'Anerroroccured:'+request.env['si
我正在使用ruby标准记录器,我想要每天轮换一次,所以在我的代码中我有:Logger.new("#{$ROOT_PATH}/log/errors.log",'daily')它运行完美,但它创建了两个文件errors.log.20130217和errors.log.20130217.1。如何强制它每天只创建一个文件? 最佳答案 您的代码对于长时间运行的应用程序是正确的。发生的事情是您在给定的一天多次运行代码。第一次运行时,Ruby会创建一个日志文件“errors.log”。当日期改变时,Ruby将文件重命名为“errors.log
在运行Cucumber测试时,我得到(除了测试结果)大量调试/日志相关的输出形式:D,[2013-03-06T12:21:38.911829#49031]DEBUG--:SOAPrequest:D,[2013-03-06T12:21:38.911919#49031]DEBUG--:Pragma:no-cache,SOAPAction:"",Content-Type:text/xml;charset=UTF-8,Content-Length:1592W,[2013-03-06T12:21:38.912360#49031]WARN--:HTTPIexecutesHTTPPOSTusingt
我最近将我的http客户端切换到faraday,一切都按预期工作。我有以下代码来创建连接:@connection=Faraday.new(:url=>base_url)do|faraday|faraday.useCustim::Middlewarefaraday.request:url_encoded#form-encodePOSTparamsfaraday.request:jsonfaraday.response:json,:content_type=>/\bjson$/faraday.response:loggerfaraday.adapterFaraday.default_ada