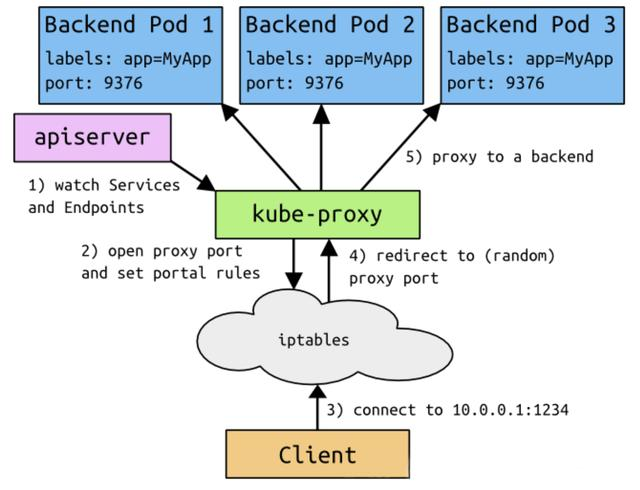
kube-proxy负责为Service提供cluster内部的服务发现和负载均衡,它运行在每个Node计算节点上,负责Pod网络代理, 它会定时从etcd服务获取到service信息来做相应的策略,维护网络规则和四层负载均衡工作。在K8s集群中微服务的负载均衡是由Kube-proxy实现的,它是K8s集群内部的负载均衡器,也是一个分布式代理服务器,在K8s的每个节点上都有一个,这一设计体现了它的伸缩性优势,需要访问服务的节点越多,提供负载均衡能力的Kube-proxy就越多,高可用节点也随之增多。
service是一组pod的服务抽象,相当于一组pod的LB,负责将请求分发给对应的pod。service会为这个LB提供一个IP,一般称为cluster IP。kube-proxy的作用主要是负责service的实现,具体来说,就是实现了内部从pod到service和外部的从node port向service的访问。
简单来说:
Kubernetes Service定义了这样一种抽象: Service是一种可以访问 Pod逻辑分组的策略, Service通常是通过 Label Selector访问 Pod组。
Service能够提供负载均衡的能力,但是在使用上有以下限制:只提供 4 层负载均衡能力,而没有 7 层功能,但有时我们可能需要更多的匹配规则来转发请求,这点上 4 层负载均衡是不支持的。
Service在 K8s中有以下四种类型:
默认类型,自动分配一个仅Cluster内部可以访问的虚拟IP(VIP)。
在ClusterIP基础上为Service在每台机器上绑定一个端口,这样就可以通过NodeIP:NodePort访问来访问该服务。
端口范围:30000~32767
在NodePort的基础上,借助Cloud Provider创建一个外部负载均衡器,并将请求转发到NodePort。
创建一个dns别名指到service name上,主要是防止service name发生变化,要配合dns插件使用。通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容。这只有 Kubernetes 1.7或更高版本的kube-dns才支持(我这里是Kubernetes 1.22.1版本)。
endpoint是k8s集群中的一个资源对象,存储在etcd中,用来记录一个service对应的所有pod的访问地址。service配置selector,endpoint controller才会自动创建对应的endpoint对象;否则,不会生成endpoint对象。
【例如】k8s集群中创建一个名为hello的service,就会生成一个同名的endpoint对象,ENDPOINTS就是service关联的pod的ip地址和端口。
一个 Service 由一组 backend Pod 组成。这些 Pod 通过 endpoints 暴露出来。 Service Selector 将持续评估,结果被 POST 到一个名称为 Service-hello 的 Endpoint 对象上。 当 Pod 终止后,它会自动从 Endpoint 中移除,新的能够匹配上 Service Selector 的 Pod 将自动地被添加到 Endpoint 中。 检查该 Endpoint,注意到 IP 地址与创建的 Pod 是相同的。现在,能够从集群中任意节点上使用 curl 命令请求 hello Service <CLUSTER-IP>:<PORT> 。
1、deployment-hello.yaml
$ cat << EOF > deployment-hello.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: hello
spec:
replicas: 3
selector:
matchLabels:
run: hello
template:
metadata:
labels:
run: hello
spec:
containers:
- name: nginx
image: nginx:1.17.1
EOF
2、service-hello.yaml
$ cat << EOF > service-hello.yaml
apiVersion: v1
kind: Service
metadata:
name: service-hello
labels:
name: service-hello
spec:
type: NodePort #这里代表是NodePort类型的,另外还有ingress,LoadBalancer
ports:
- port: 80
targetPort: 8080
protocol: TCP
nodePort: 31111 # 所有的节点都会开放此端口30000--32767,此端口供外部调用。
selector:
run: hello
EOF
3、查看验证
$ kubectl apply -f deployment-hello.yaml
$ kubectl apply -f service-hello.yaml
# 查看pod,如果本地没有镜像,可能等待的时候比较长,一定要等到所有pod都在运行中才行。
$ kubectl get pod -o wide|grep hello-*
# 查看service
$ kubectl get service service-hello -o wide
# 查看service详情
$ kubectl describe service service-hello
# 查看pointer
$ kubectl get endpoints service-hello
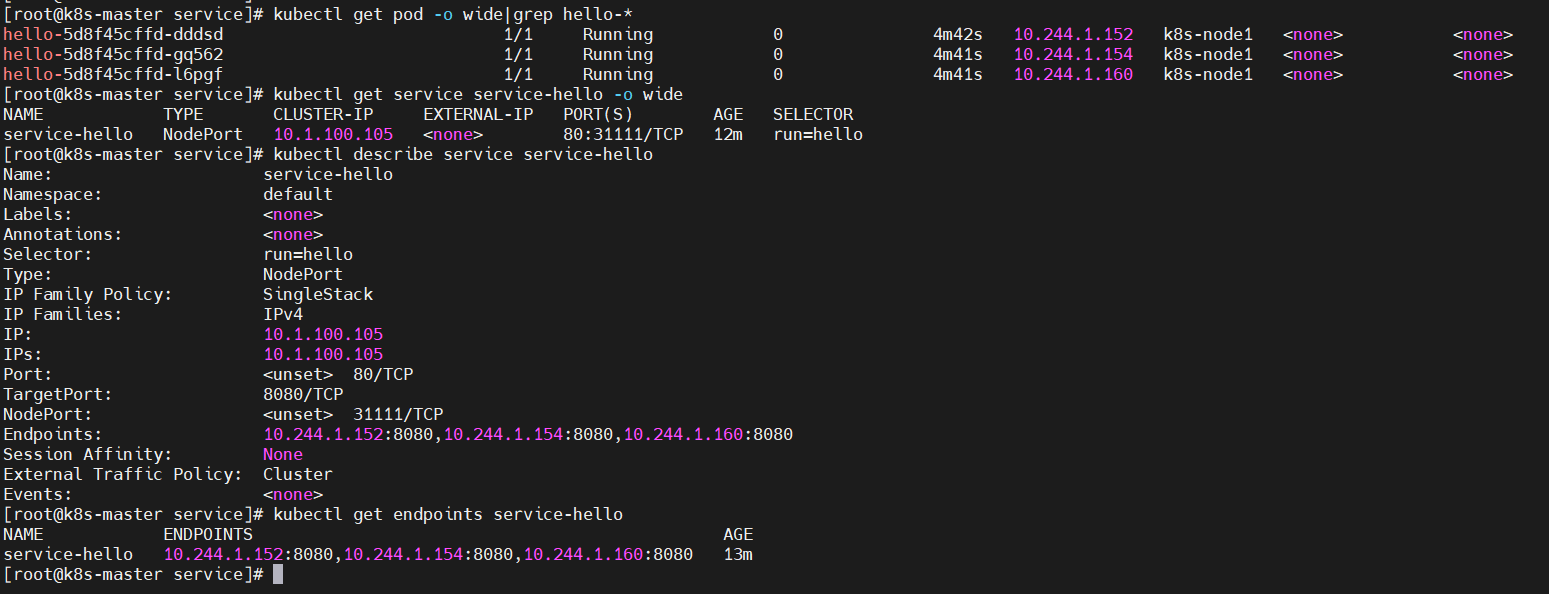
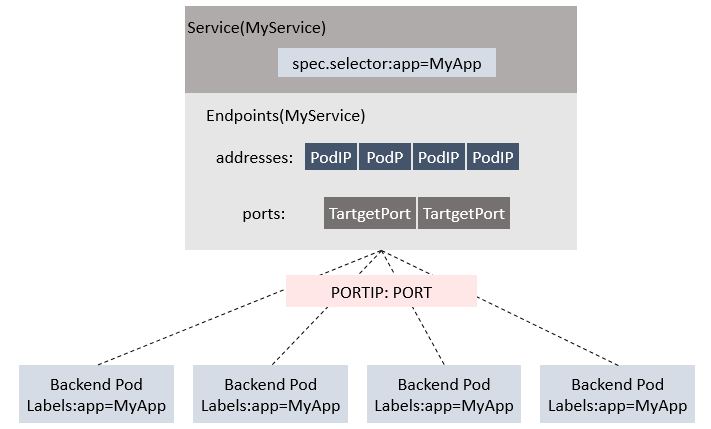
Kube-proxy进程获取每个Service的Endpoints,实现Service的负载均衡功能。
Service的负载均衡转发规则
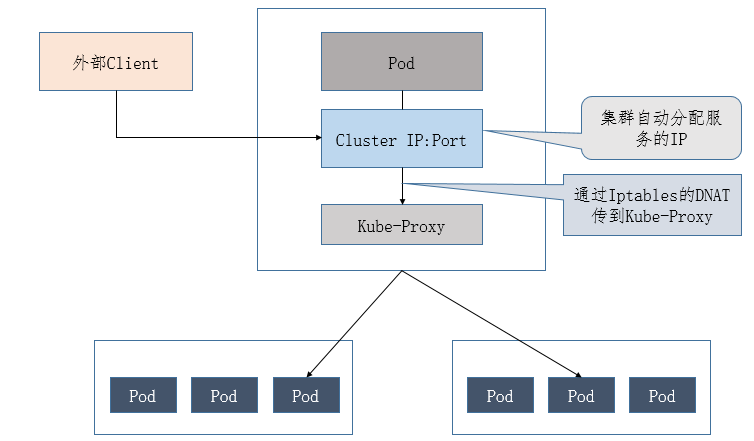
访问Service的请求,不论是Cluster IP+TargetPort的方式;还是用Node节点IP+NodePort的方式,都被Node节点的Iptables规则重定向到Kube-proxy监听Service服务代理端口。kube-proxy接收到Service的访问请求后,根据负载策略,转发到后端的Pod。
apiVersion: v1
kind: Service
metadata:
#元数据
name: string
#Service名称
namespace: string
#命名空间,不指定时默认为default命名空间
labels:
#自定义标签属性列表
- name: string
annotations:
#自定义注解属性列表
- name: string
spec:
#详细描述
selector: []
#这里选择器一定要选择容器的标签,也就是pod的标签
#selector:
# app: web
#Label Selector配置,选择具有指定label标签的pod作为管理范围
type: string
#service的类型,指定service的访问方式,默认ClusterIP
#ClusterIP:虚拟的服务ip地址,用于k8s集群内部的pod访问,在Node上kube-porxy通过设置的iptables规则进行转发
#NodePort:使用宿主机端口,能够访问各Node的外部客户端通过Node的IP和端口就能访问服务器
#LoadBalancer:使用外部负载均衡器完成到服务器的负载分发,
#需要在spec.status.loadBalancer字段指定外部负载均衡服务器的IP,并同时定义nodePort和clusterIP用于公有云环境。
clusterIP: string
#虚拟服务IP地址,当type=ClusterIP时,如不指定,则系统会自动进行分配,也可以手动指定。当type=loadBalancer,需要指定
sessionAffinity: string
#是否支持session,可选值为ClietIP,默认值为空
#ClientIP表示将同一个客户端(根据客户端IP地址决定)的访问请求都转发到同一个后端Pod
ports:
#service需要暴露的端口列表
- name: string
#端口名称
protocol: string
#端口协议,支持TCP或UDP,默认TCP
port: int
#服务监听的端口号
targetPort: int
#需要转发到后端的端口号
nodePort: int
#当type=NodePort时,指定映射到物理机的端口号
status:
#当type=LoadBalancer时,设置外部负载均衡的地址,用于公有云环境
loadBalancer:
#外部负载均衡器
ingress:
#外部负载均衡器
ip: string
#外部负载均衡器的IP地址
hostname: string
#外部负载均衡器的机主机
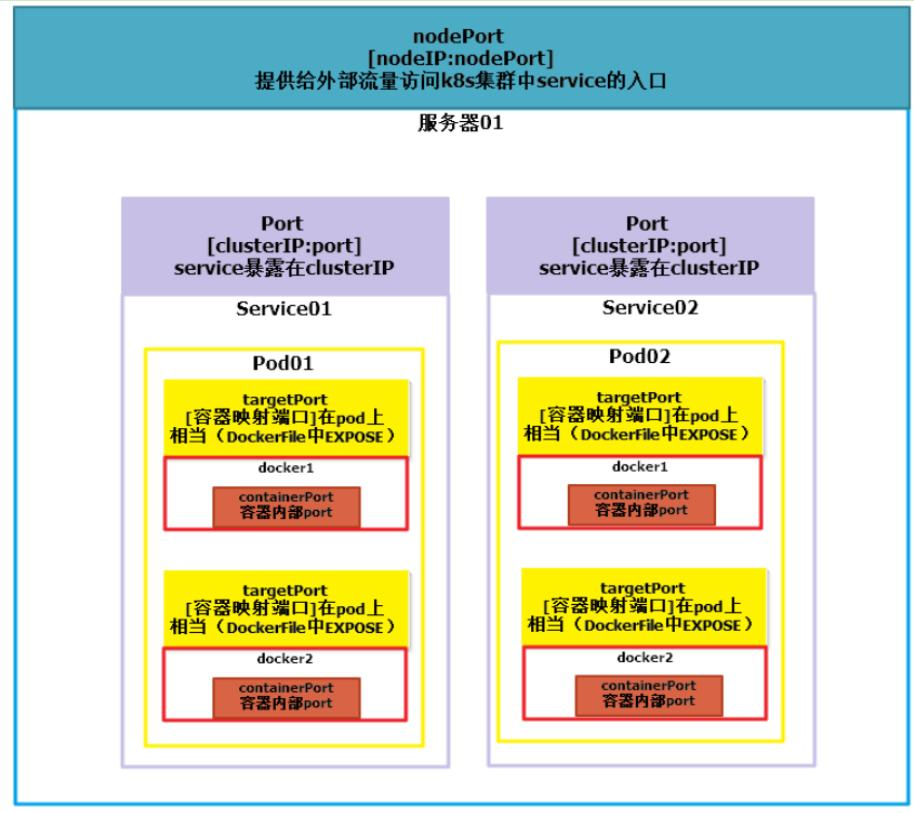
nodePort是外部访问k8s集群中service的端口,通过nodeIP: nodePort可以从外部访问到某个service。
port是k8s集群内部访问service的端口,即通过clusterIP: port可以访问到某个service。
targetPort是pod的端口,从port和nodePort来的流量经过kube-proxy流入到后端pod的targetPort上,最后进入容器。
containerPort是pod内部容器的端口,targetPort映射到containerPort。
Kubernetes提供了两种方式进行服务发现, 即环境变量和DNS, 简单说明如下:
当你创建一个Pod的时候,kubelet会在该Pod中注入集群内所有Service的相关环境变量。
【注意】要想一个Pod中注入某个Service的环境变量,则必须Service要比该Pod先创建。这一点,几乎使得这种方式进行服务发现不可用。比如,一个ServiceName为redis-master的Service,对应的ClusterIP:Port为172.16.50.11:6379,则其对应的环境变量为:
REDIS_MASTER_SERVICE_HOST=172.16.50.11
REDIS_MASTER_SERVICE_PORT=6379
REDIS_MASTER_PORT=tcp://172.16.50.11:6379
REDIS_MASTER_PORT_6379_TCP=tcp://172.16.50.11:6379
REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
REDIS_MASTER_PORT_6379_TCP_PORT=6379
REDIS_MASTER_PORT_6379_TCP_ADDR=172.16.50.11
这是k8s官方强烈推荐的方式!!! 可以通过cluster add-on方式轻松的创建KubeDNS来对集群内的Service进行服务发现。
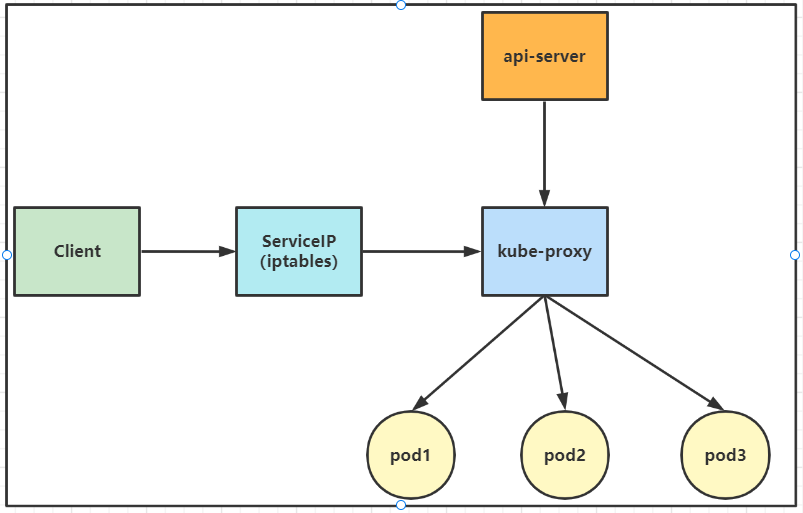
k8s群集中的每个节点都运行一个kube-proxy的组件,kube-proxy其实是一个代理层负责实现service。
Kubernetes v1.2之前默认是userspace,v1.2之后默认是iptables模式,iptables模式性能和可靠性更好,但是iptables模式依赖健康检查,在没有健康检查的情况下如果一个pod不响应,iptables模式不会切换另一个pod上。
客户端访问ServiceIP(clusterIP)请求会先从用户空间到内核中的iptables,然后回到用户空间kube-proxy,kube-proxy负责代理工作。
缺点:
可见,userspace这种mode最大的问题是,service的请求会先从用户空间进入内核iptables,然后再回到用户空间,由kube-proxy完成后端Endpoints的选择和代理工作,这样流量从用户空间进出内核带来的性能损耗是不可接受的。这也是k8s v1.0及之前版本中对kube-proxy质疑最大的一点,因此社区就开始研究iptables mode。
详细工作流程:
userspace这种模式下,kube-proxy 持续监听 Service 以及 Endpoints 对象的变化;对每个 Service,它都为其在本地节点开放一个端口,作为其服务代理端口;发往该端口的请求会采用一定的策略转发给与该服务对应的后端 Pod 实体。kube-proxy 同时会在本地节点设置 iptables 规则,配置一个 Virtual IP,把发往 Virtual IP 的请求重定向到与该 Virtual IP 对应的服务代理端口上。其工作流程大体如下:
【分析】该模式请求在到达 iptables 进行处理时就会进入内核,而 kube-proxy 监听则是在用户态, 请求就形成了从用户态到内核态再返回到用户态的传递过程, 一定程度降低了服务性能。
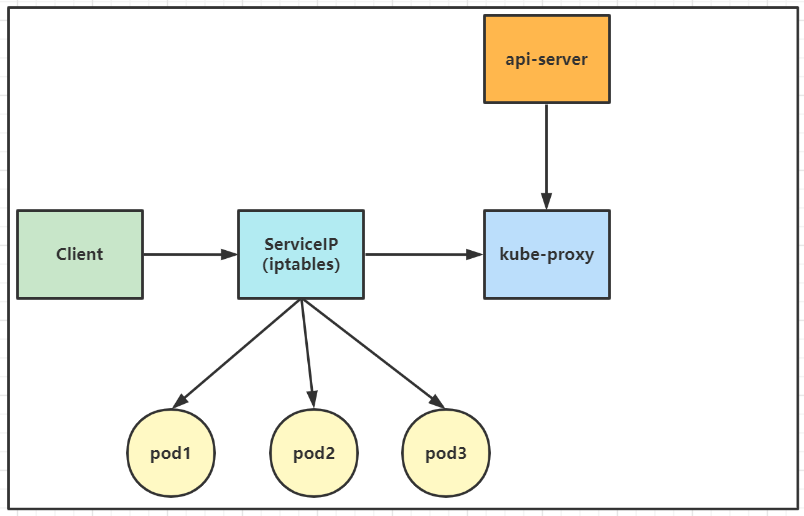
该模式完全利用内核iptables来实现service的代理和LB, 这是K8s在v1.2及之后版本默认模式. 工作原理如下:
iptables mode因为使用iptable NAT来完成转发,也存在不可忽视的性能损耗。另外,如果集群中存在上万的Service/Endpoint,那么Node上的iptables rules将会非常庞大,性能还会再打折扣。这也导致目前大部分企业用k8s上生产时,都不会直接用kube-proxy作为服务代理,而是通过自己开发或者通过Ingress Controller来集成HAProxy, Nginx来代替kube-proxy。
详细工作流程:
iptables 模式与 userspace 相同,kube-proxy 持续监听 Service 以及 Endpoints 对象的变化;但它并不在本地节点开启反向代理服务,而是把反向代理全部交给 iptables 来实现;即 iptables 直接将对 VIP 的请求转发给后端 Pod,通过 iptables 设置转发策略。其工作流程大体如下:
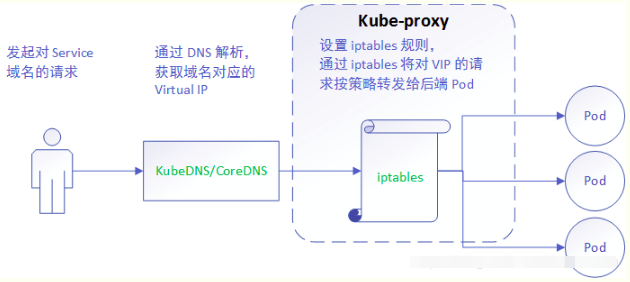
【分析】 该模式相比 userspace 模式,克服了请求在用户态-内核态反复传递的问题,性能上有所提升,但使用 iptables NAT 来完成转发,存在不可忽视的性能损耗,而且在大规模场景下,iptables 规则的条目会十分巨大,性能上还要再打折扣。
示例:
cat << EOF > mysql-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
name: mysql
role: service
name: mysql-service
spec:
ports:
- port: 3306
targetPort: 3306
nodePort: 30964
type: NodePort
selector:
mysql-service: "true"
name: mysql
EOF
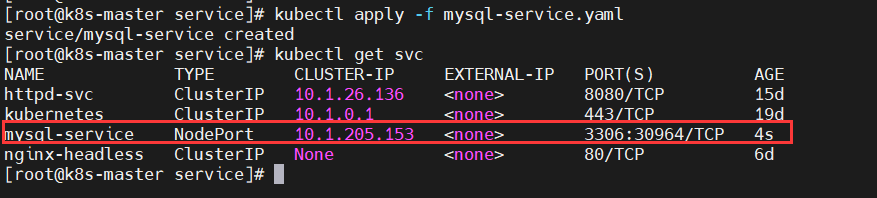
$ kubectl apply -f mysql-service.yaml
$ kubectl get svc
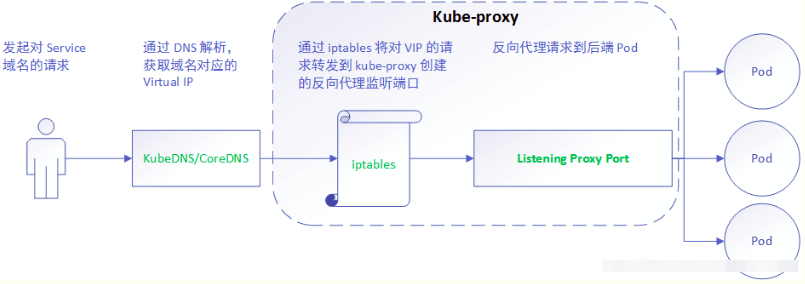
在kubernetes 1.8以上的版本中,对于kube-proxy组件增加了除iptables模式和用户模式之外还支持ipvs模式。kube-proxy ipvs 是基于 NAT 实现的,通过ipvs的NAT模式,对访问k8s service的请求进行虚IP到POD IP的转发。当创建一个 service 后,kubernetes 会在每个节点上创建一个网卡,同时帮你将 Service IP(VIP) 绑定上,此时相当于每个 Node 都是一个 ds,而其他任何 Node 上的 Pod,甚至是宿主机服务(比如 kube-apiserver 的 6443)都可能成为 rs;
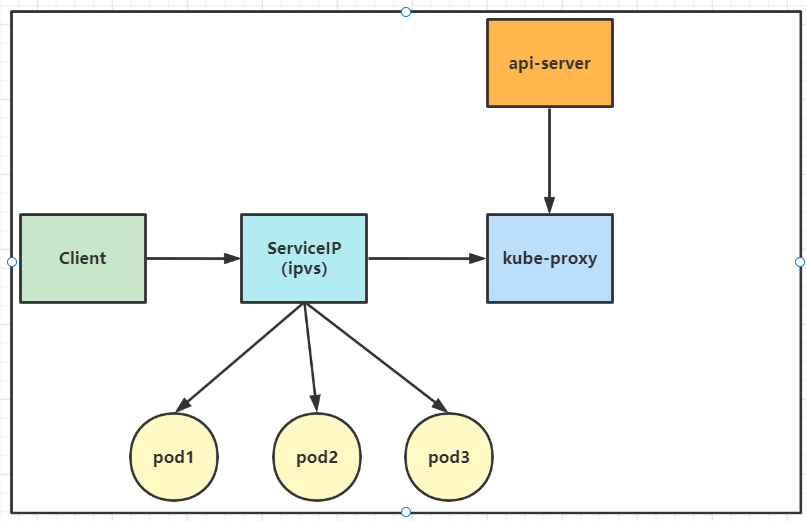
详细工作流程:
与iptables、userspace 模式一样,kube-proxy 依然监听Service以及Endpoints对象的变化, 不过它并不创建反向代理, 也不创建大量的 iptables 规则, 而是通过netlink 创建ipvs规则,并使用k8s Service与Endpoints信息,对所在节点的ipvs规则进行定期同步; netlink 与 iptables 底层都是基于 netfilter 钩子,但是 netlink 由于采用了 hash table 而且直接工作在内核态,在性能上比 iptables 更优。其工作流程大体如下:
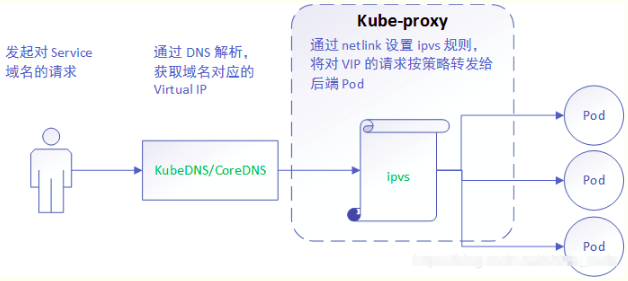
【分析】ipvs 是目前 kube-proxy 所支持的最新代理模式,相比使用 iptables,使用 ipvs 具有更高的性能。
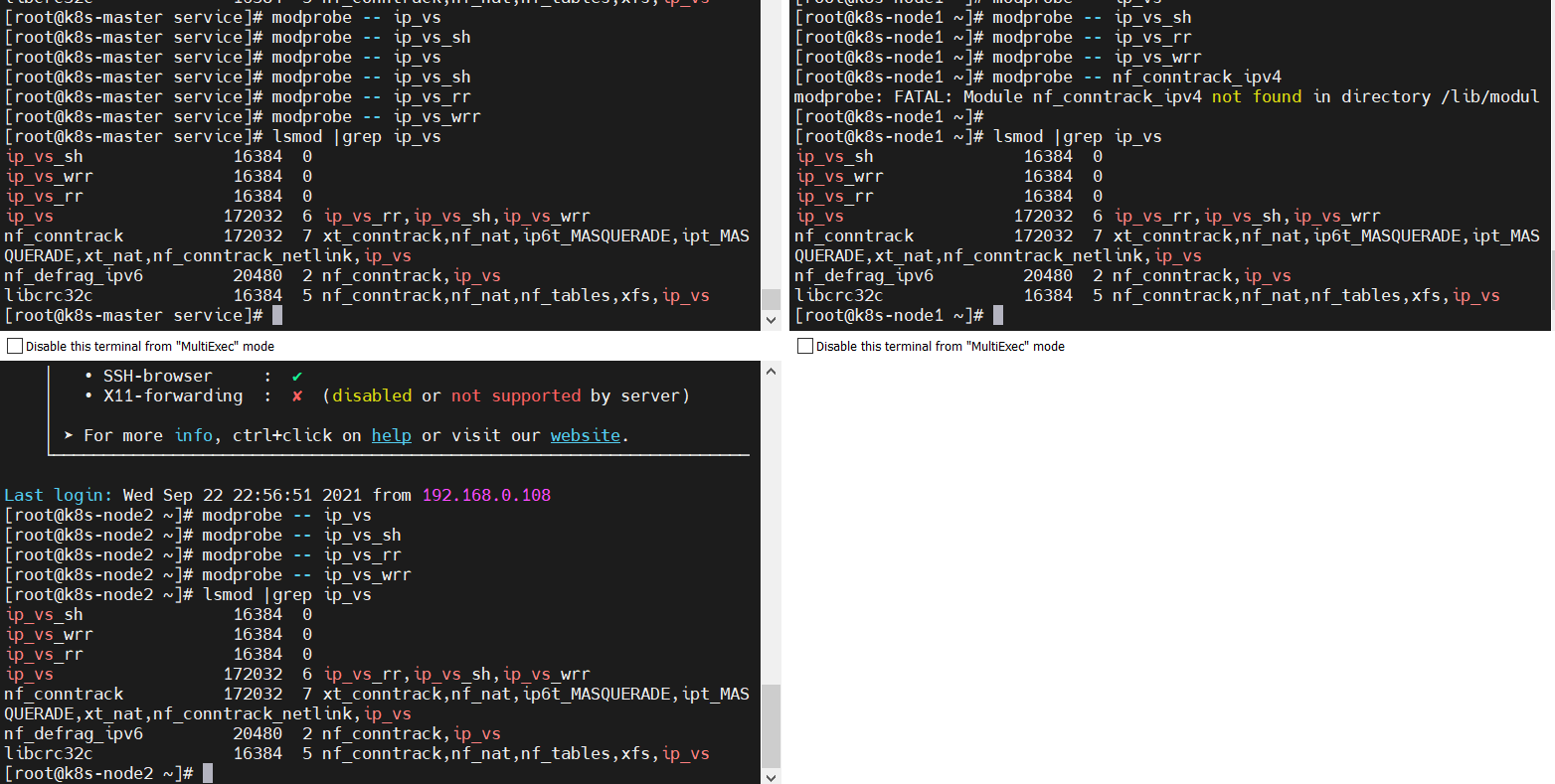
1、加载ip_vs相关内核模块
$ modprobe -- ip_vs
$ modprobe -- ip_vs_sh
$ modprobe -- ip_vs_rr
$ modprobe -- ip_vs_wrr
$ modprobe -- nf_conntrack_ipv4
所有节点验证开启了ipvs:
$ lsmod |grep ip_vs
2、安装ipvsadm工具
$ yum install ipset ipvsadm -y
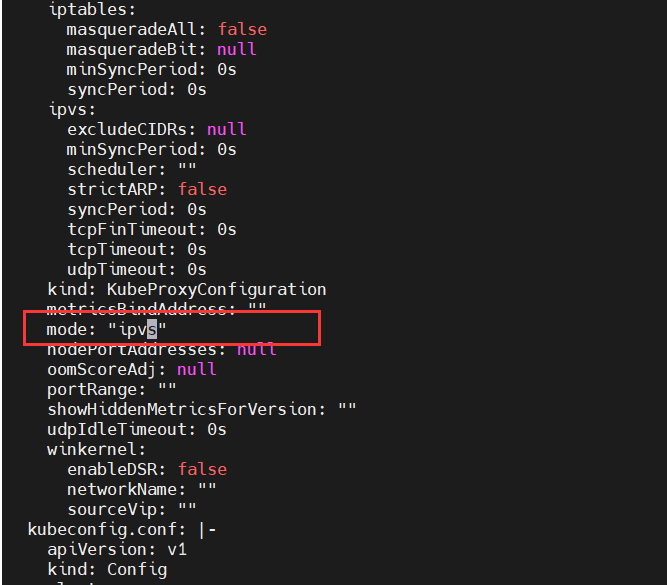
3、编辑kube-proxy配置文件,mode修改成ipvs
$ kubectl edit configmap -n kube-system kube-proxy
4、重启kube-proxy
先查看之前的kube-proxy
$ kubectl get pod -n kube-system | grep kube-proxy

删掉上面三个kube-proxy,重新拉起新的服务
$ kubectl get pod -n kube-system | grep kube-proxy |awk '{system("kubectl delete pod "$1" -n kube-system")}'
再查看
$ kubectl get pod -n kube-system | grep kube-proxy

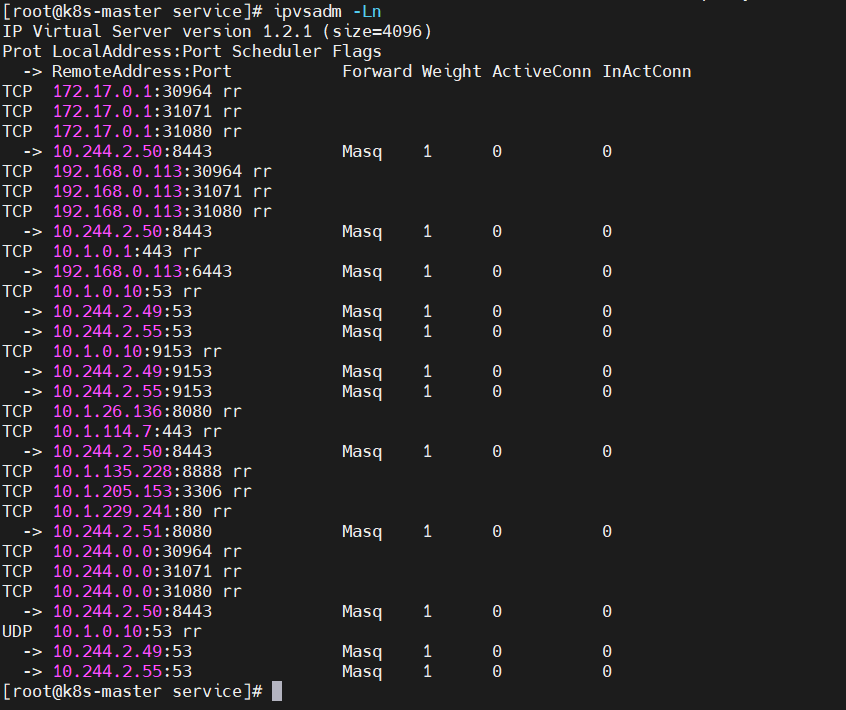
5、查看
$ ipvsadm -Ln
关于Kubernetes(k8s)kube-proxy、Service的介绍,就先到这里了,有疑问的小伙伴,欢迎给我留言哦~
很难说出这里要问什么。这个问题模棱两可、含糊不清、不完整、过于宽泛或夸夸其谈,无法以目前的形式得到合理的回答。如需帮助澄清此问题以便重新打开,visitthehelpcenter.关闭9年前。我需要从基于ruby的应用程序使用AmazonSimpleNotificationService,但不知道从哪里开始。您对从哪里开始有什么建议吗?
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
我正在按照我一直在研究的研讨会实现“服务对象”,我正在构建一个redditAPI应用程序。我需要对象返回一些东西,所以我不能只执行初始化程序中的所有内容。我有这两个选择:选项1:类需要实例化classSubListFromUserdefuser_subscribed_subs(client)@client=client@subreddits=sort_subs_by_name(user_subs_from_reddit)endprivatedefsort_subs_by_name(subreddits)subreddits.sort_by{|sr|sr[:name].downcase}
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
HTTP缓存是指浏览器或者代理服务器将已经请求过的资源保存到本地,以便下次请求时能够直接从缓存中获取资源,从而减少网络请求次数,提高网页的加载速度和用户体验。缓存分为强缓存和协商缓存两种模式。一.强缓存强缓存是指浏览器直接从本地缓存中获取资源,而不需要向web服务器发出网络请求。这是因为浏览器在第一次请求资源时,服务器会在响应头中添加相关缓存的响应头,以表明该资源的缓存策略。常见的强缓存响应头如下所述:Cache-ControlCache-Control响应头是用于控制强制缓存和协商缓存的缓存策略。该响应头中的指令如下:max-age:指定该资源在本地缓存的最长有效时间,以秒为单位。例如:Ca
如何用IDEA2022创建并初始化一个SpringBoot项目?目录如何用IDEA2022创建并初始化一个SpringBoot项目?0. 环境说明1. 创建SpringBoot项目 2.编写初始化代码0. 环境说明IDEA2022.3.1JDK1.8SpringBoot1. 创建SpringBoot项目 打开IDEA,选择NewProject创建项目。 填写项目名称、项目构建方式、jdk版本,按需要修改项目文件路径等信息。 选择springboot版本以及需要的包,此处只选择了springweb。 此处需特别注意,若你使用的是jdk1
我有一个关于配置elasticsearch以连接AWSelasticsearch服务以在生产环境中运行项目的问题。我的gem文件:gem'searchkick'gem'faraday_middleware-aws-signers-v4'gem'aws-sdk','~>2'gem"elasticsearch",">=1.0.15"引用:https://github.com/ankane/searchkick我的config/initializers/elasticsearch.rb文件:require"faraday_middleware/aws_signers_v4"ENV["ELAS
前言上一篇我们简要讲述了粒子系统是什么,如何添加,以及基本模块的介绍,以及对于曲线和颜色编辑器的讲解。从本篇开始,我们将按照模块结构讲解下去,本篇主要讲粒子系统的主模块,该模块主要是控制粒子的初始状态和全局属性的,以下是关于该模块的介绍,请大家指正。目录前言本系列提要一、粒子系统主模块1.阅读前注意事项2.参考图3.参数讲解DurationLoopingPrewarmStartDelayStartLifetimeStartSpeed3DStartSizeStartSize3DStartRotationStartRotationFlipRotationStartColorGravityModif