文章目录
-version
-help
-server
-cp

-Xint 解释执行
-Xcomp 第一次使用就编译成本地代码
-Xmixed 混合模式,JVM自己来决定
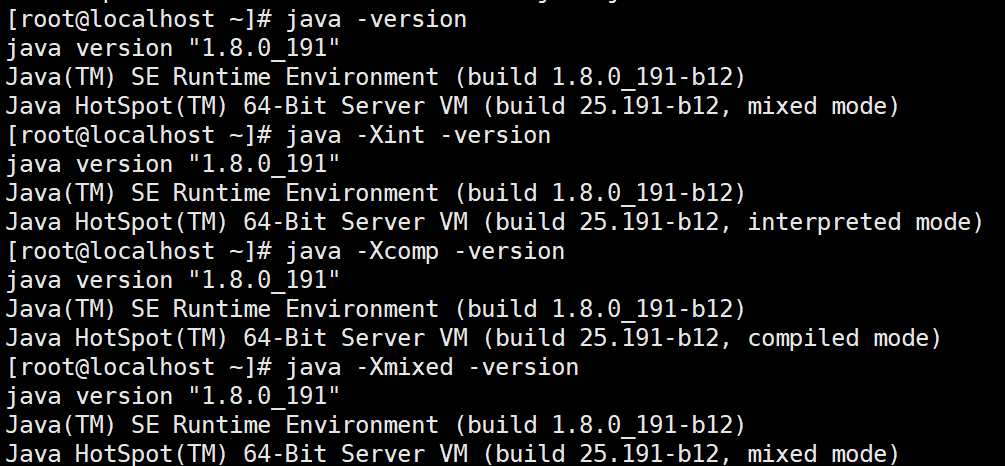
使用得最多的参数类型,主要用于JVM调优和Debug
a.Boolean类型
格式:-XX:[+-]<name> +或-表示启用或者禁用name属性
比如:-XX:+UseConcMarkSweepGC 表示启用CMS类型的垃圾回收器
-XX:+UseG1GC 表示启用G1类型的垃圾回收器
b.非Boolean类型
格式:-XX<name>=<value>表示name属性的值是value
比如:-XX:MaxGCPauseMillis=500
这块也相当于是-XX类型的参数
-Xms1000M等价于-XX:InitialHeapSize=1000M
-Xmx1000M等价于-XX:MaxHeapSize=1000M
-Xss100等价于-XX:ThreadStackSize=100
java -XX:+PrintFlagsFinal -version > flags.txt

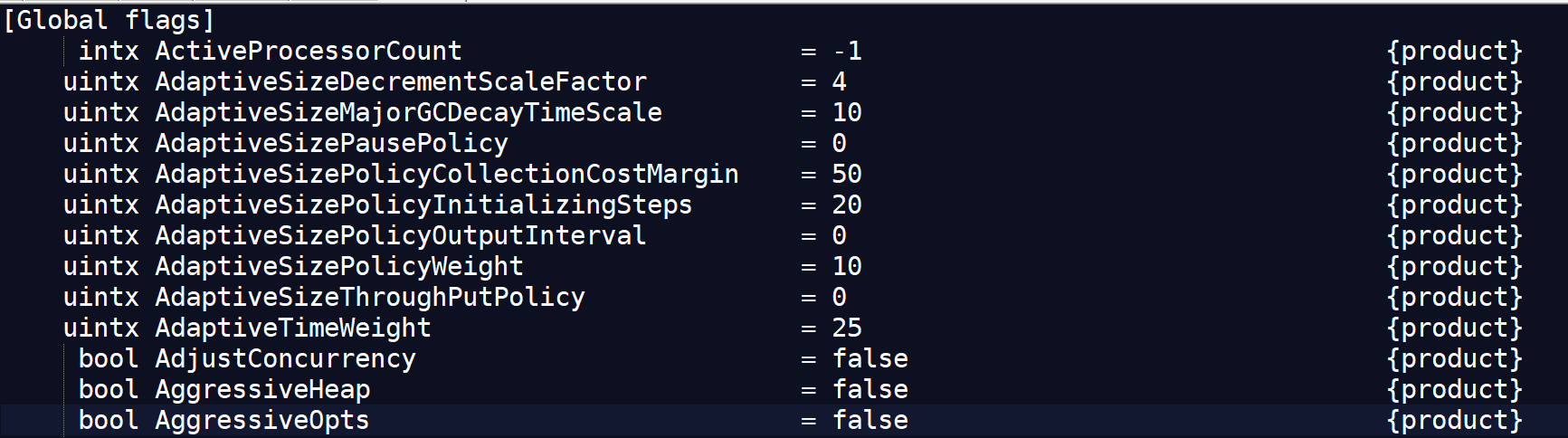
值得注意的是"=“表示默认值,”:="表示被用户或JVM修改后的值
一般要设置参数,可以先查看一下当前参数是什么,然后进行修改
| 参数 | 含义 | 说明 |
|---|---|---|
| -XX:CICompilerCount=3 | 最大并行编译数 | 如果设置大于1,虽然编译速度会提高,但是同样影响系统稳定性,会增加JVM崩溃的可能 |
| -XX:InitialHeapSize=100M | 初始化堆大小 | 简写-Xms100M |
| -XX:MaxHeapSize=100M | 最大堆大小 | 简写-Xms100M |
| -XX:NewSize=20M | 设置年轻代的大小 | |
| -XX:MaxNewSize=50M | 年轻代最大大小 | |
| -XX:OldSize=50M | 设置老年代大小 | |
| -XX:MetaspaceSize=50M | 设置方法区大小 | |
| -XX:MaxMetaspaceSize=50M | 方法区最大大小 | |
| -XX:+UseParallelGC | 使用UseParallelGC | 新生代,吞吐量优先 |
| -XX:+UseParallelOldGC | 使用UseParallelOldGC | 老年代,吞吐量优先 |
| -XX:+UseConcMarkSweepGC | 使用CMS | 老年代,停顿时间优先 |
| -XX:+UseG1GC | 使用G1GC | 新生代,老年代,停顿时间优先 |
| -XX:NewRatio | 新老生代的比值 | 比如-XX:Ratio=4,则表示新生代:老年代=1:4,也就是新生代占整个堆内存的1/5 |
| -XX:SurvivorRatio | 两个S区和Eden区的比值 | 比如-XX:SurvivorRatio=8,也就是(S0+S1):Eden=2:8,也就是一个S占整个新生代的1/10 |
| -XX:+HeapDumpOnOutOfMemoryError | 启动堆内存溢出打印 | 当JVM堆内存发生溢出时,也就是OOM,自动生成dump文件 |
| -XX:HeapDumpPath=heap.hprof | 指定堆内存溢出打印目录 | 表示在当前目录生成一个heap.hprof文件 |
| -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -Xloggc:g1-gc.log | 打印出GC日志 | 可以使用不同的垃圾收集器,对比查看GC情况 |
| -Xss128k | 设置每个线程的堆栈大小 | 经验值是3000-5000最佳 |
| -XX:MaxTenuringThreshold=6 | 提升年老代的最大临界值 | 默认值为 15 |
| -XX:InitiatingHeapOccupancyPercent | 启动并发GC周期时堆内存使用占比 | G1之类的垃圾收集器用它来触发并发GC周期,基于整个堆的使用率,而不只是某一代内存的使用比. 值为 0 则表示”一直执行GC循环”. 默认值为 45. |
| -XX:G1HeapWastePercent | 允许的浪费堆空间的占比 | 默认是10%,如果并发标记可回收的空间小于10%,则不会触发MixedGC。 |
| -XX:MaxGCPauseMillis=200ms | G1最大停顿时间 | 暂停时间不能太小,太小的话就会导致出现G1跟不上垃圾产生的速度。最终退化成Full GC。所以对这个参数的调优是一个持续的过程,逐步调整到最佳状态。 |
| -XX:ConcGCThreads=n | 并发垃圾收集器使用的线程数量 | 默认值随JVM运行的平台不同而不同 |
| -XX:G1MixedGCLiveThresholdPercent=65 | 混合垃圾回收周期中要包括的旧区域设置占用率阈值 | 默认占用率为 65% |
| -XX:G1MixedGCCountTarget=8 | 设置标记周期完成后,对存活数据上限为 G1MixedGCLIveThresholdPercent 的旧区域执行混合垃圾回收的目标次数 | 默认8次混合垃圾回收,混合回收的目标是要控制在此目标次数以内 |
| -XX:G1OldCSetRegionThresholdPercent=1 | 描述Mixed GC时,Old Region被加入到CSet中 | 默认情况下,G1只把10%的Old Region加入到CSet中 |
查看java进程
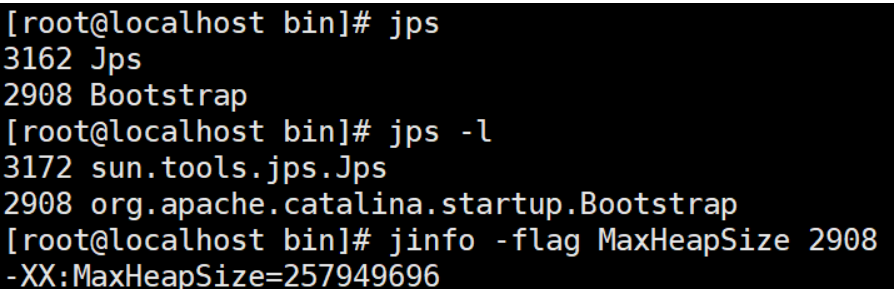
实时查看和调整JVM配置参数
# 查看某个java进程属性的值
jinfo -flag MaxHeapSize PID
jinfo -flag UseG1GC PID

# 参数只有被标记为manageable的flags可以被实时修改
jinfo -flag [+|-] PID
jinfo -flag <name>=<value> PID
# 查看曾经赋过值的一些参数
jinfo -flags PID
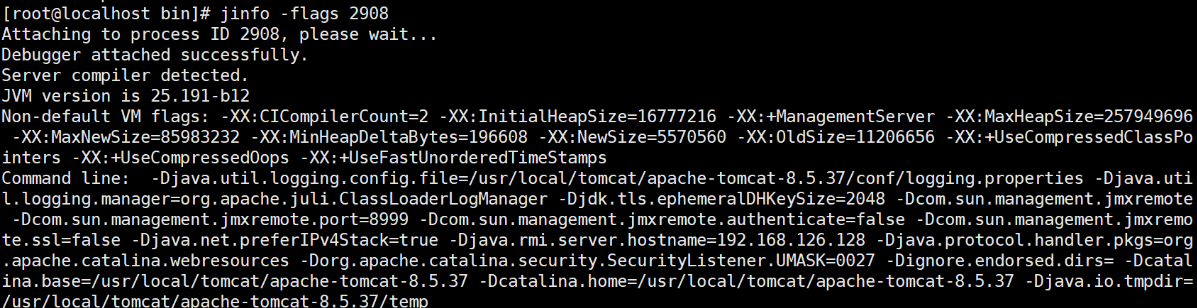
查看虚拟机性能统计信息
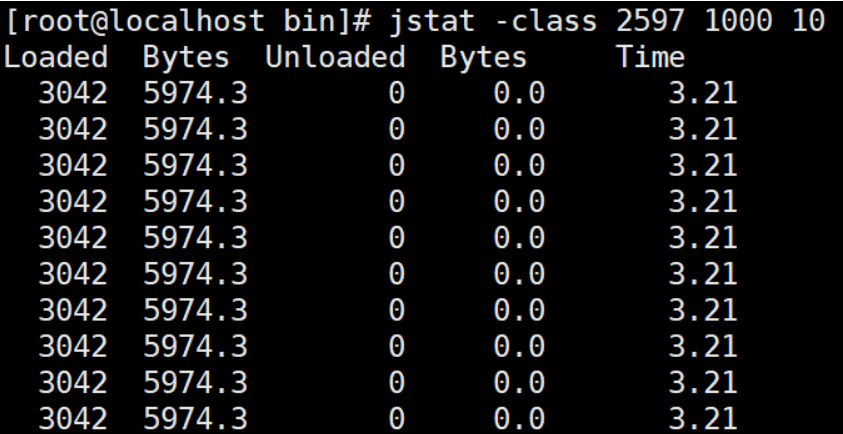
# 查看类装载信息 每1000毫秒输出一次,共输出10次
jstat -class PID 1000 10
# 查看垃圾收集信息
jstat -gc PID 1000 10

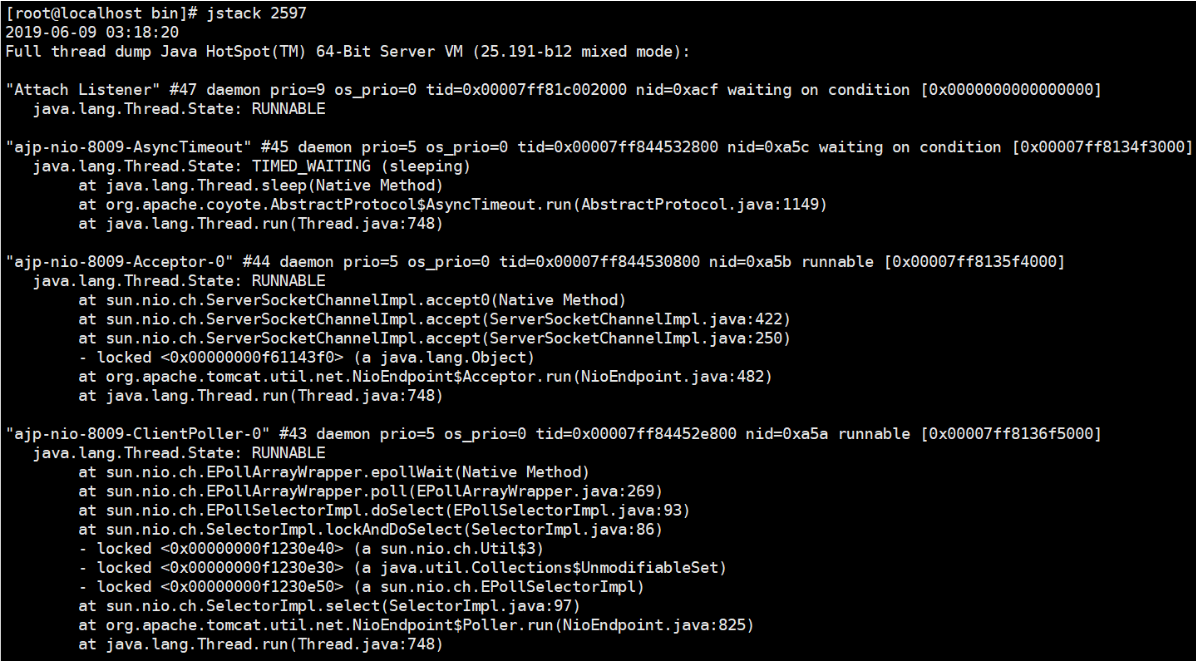
查看线程堆栈信息
jstack PID
排查死锁案例
//运行主类
public class DeadLockDemo
{
public static void main(String[] args)
{
DeadLock d1=new DeadLock(true);
DeadLock d2=new DeadLock(false);
Thread t1=new Thread(d1);
Thread t2=new Thread(d2);
t1.start();
t2.start();
}
}
//定义锁对象
class MyLock{
public static Object obj1=new Object();
public static Object obj2=new Object();
}
//死锁代码
class DeadLock implements Runnable{
private boolean flag;
DeadLock(boolean flag){
this.flag=flag;
}
public void run() {
if(flag) {
while(true) {
synchronized(MyLock.obj1) {
System.out.println(Thread.currentThread().getName()+"----if获得obj1锁");
synchronized(MyLock.obj2) {
System.out.println(Thread.currentThread().getName()+"----if获得obj2锁");
}
}
}
}
else {
while(true){
synchronized(MyLock.obj2) {
System.out.println(Thread.currentThread().getName()+"----否则获得obj2锁");
synchronized(MyLock.obj1) {
System.out.println(Thread.currentThread().getName()+"----否则获得obj1锁");
}
}
}
}
}
}
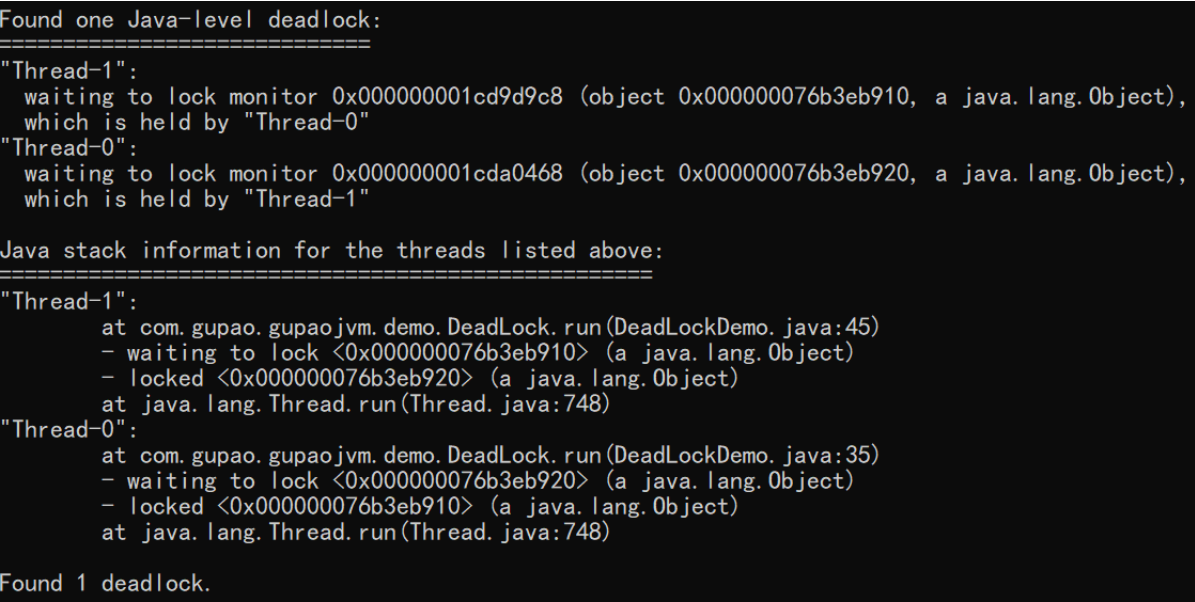
jstack分析
把打印信息拉到最后可以发现1个死锁信息。
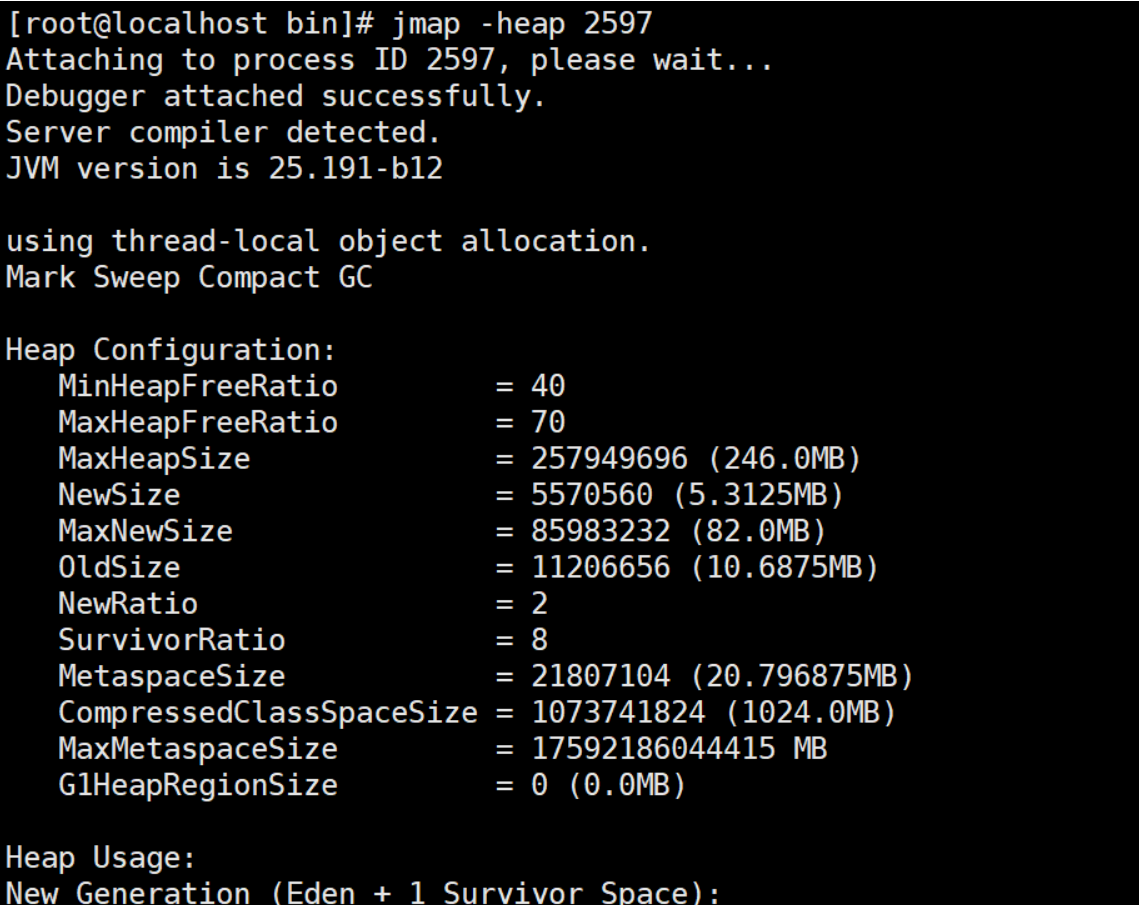
# 打印出堆内存相关信息
jmap -heap PID
# 生成堆快照
jmap -dump:format=b,file=heap.hprof PID

一般在开发中,JVM参数可以加上下面两句,这样内存溢出时,会自动dump出该文件
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=heap.hprof
正常情况我们应该根据我们的系统来进行一个内存的估算,这个我们可以在测试环境进行测试,最开始可以将内存设置的大一些,比如4G这样,当然这也可以根据业务系统估算来的。
比如从数据库获取一条数据占用128个字节,需要获取1000条数据,那么一次读取到内存的大小就是((128 B/1024 Kb/1024M)* 1000 = 0.122M,那么我们程序可能需要并发读取,比如每秒读取100次,那么内存占用就是0.122100 = 12.2M,如果堆内存设置1个G,那么年轻代大小大约就是333M,那么333M*80%/12.2M =21.84s,也就是说我们的程序几乎每分钟进行两到三次youngGC。这样可以让我们对系统有一个大致的估算。
发生内存溢出一般会有两个原因:
缓存、CDN、集群+负载均衡、限流等方式解决
jstack查看线程情况,有没有死锁或者IO阻塞的情况,查找可能出现问题的类名或等待时间最长的进程号。
jstack PID
查看堆内存的使用,获取到jvm.hprof文件,上传到指定的工具分析,比如heaphero.io
jmap -heap PID
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
两者都可以defsetup(options={})options.reverse_merge:size=>25,:velocity=>10end和defsetup(options={}){:size=>25,:velocity=>10}.merge(options)end在方法的参数中分配默认值。问题是:哪个更好?您更愿意使用哪一个?在性能、代码可读性或其他方面有什么不同吗?编辑:我无意中添加了bang(!)...并不是要询问nobang方法与bang方法之间的区别 最佳答案 我倾向于使用reverse_merge方法:option
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano
我没有找到太多关于如何执行此操作的信息,尽管有很多关于如何使用像这样的redirect_to将参数传递给重定向的建议:action=>'something',:controller=>'something'在我的应用程序中,我在路由文件中有以下内容match'profile'=>'User#show'我的表演Action是这样的defshow@user=User.find(params[:user])@title=@user.first_nameend重定向发生在同一个用户Controller中,就像这样defregister@title="Registration"@user=Use
对于作为String#tr参数的单引号字符串文字中反斜杠的转义状态,我觉得有些神秘。你能解释一下下面三个例子之间的对比吗?我特别不明白第二个。为了避免复杂化,我在这里使用了'd',在双引号中转义时不会改变含义("\d"="d")。'\\'.tr('\\','x')#=>"x"'\\'.tr('\\d','x')#=>"\\"'\\'.tr('\\\d','x')#=>"x" 最佳答案 在tr中转义tr的第一个参数非常类似于正则表达式中的括号字符分组。您可以在表达式的开头使用^来否定匹配(替换任何不匹配的内容)并使用例如a-f来匹配一
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些