软件:VM Ware
iso镜像:CentOS7
Hadoop版本:Hadoop-3.3.3
目录
# 切换成root用户
su
# 检查网络是否连通
ping www.baidu.com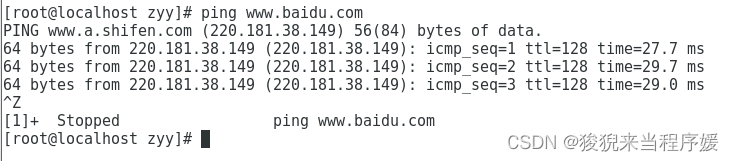
# centOS换源
https://blog.csdn.net/qq_35261940/article/details/122019530# 安装net-tools
yum upgrade
yum install net-tools需要输入y,确保继续运行
【这种情况是已经存在了,所以什么都不用做,如果没有,等待安装完成就行】

# 查看防火墙状态
systemctl status firewalld.service
# 关闭防火墙
systemctl stop firewalld.service
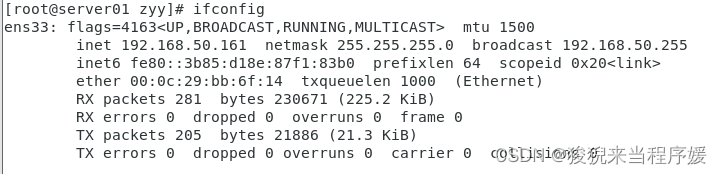
# 查看ip地址和Mac地址(ens33 的 enter 后面)
ifconfig
# 这里我的ip地址是192.168.50.160
# Mac地址是00:0c:29:e5:8a:93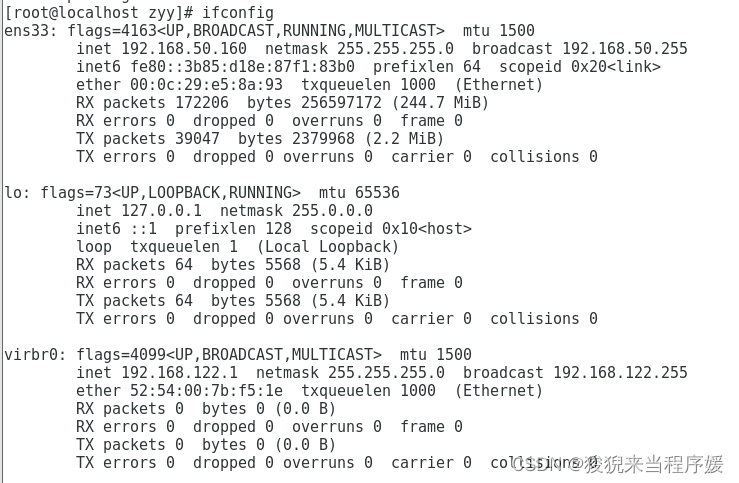
# 配置网络文件
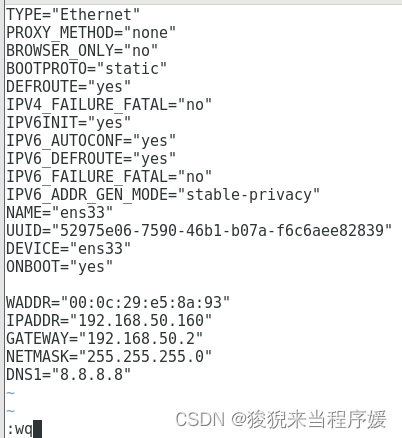
vi /etc/sysconfig/network-scripts/ifcfg-ens33
【使用 i 进入编辑模式,依次按下 esc : 输入wq 后按回车键,进行保存并退出】
BOOTPROTO的值设置为static
ONBOOT的值设置为yes
子网掩码默认设置为255.255.255.0
网关的值为将ip地址中最后一段的值改为2
DNS使用谷歌提供的免费dns1:8.8.8.8
# 重启网络服务,检查是否配置成功
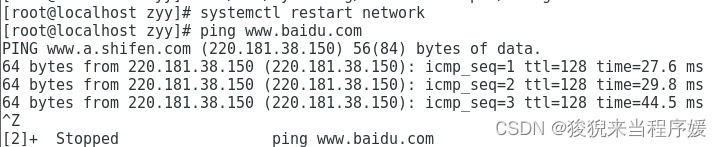
systemctl restart network
ping www.baidu.com
# 重启虚拟机,检查是否在ip没有改变的情况下仍然能连通网络
reboot
ifconfig
ping www.baidu.com
# 新建目录
mkdir -p /export/data
mkdir -p /export/servers
mkdir -p /export/softwareIndex of /dist/hadoop/common/hadoop-3.1.3
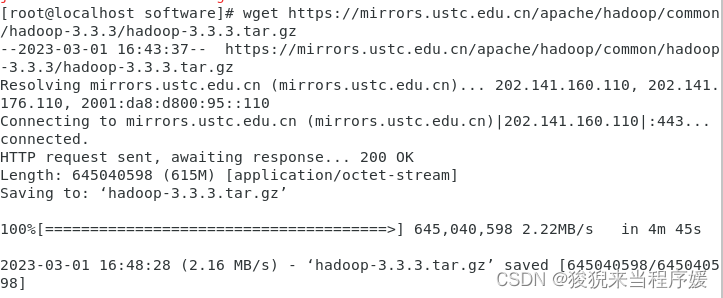
wget https://mirrors.ustc.edu.cn/apache/hadoop/common/hadoop-3.3.3/hadoop-3.3.3.tar.gz
# 官网下载JDK版本
https://www.oracle.com/java/technologies/javase-downloads.html
# 上传至 /export/software 文件夹下
使用 Filezilla 进行上传
# 解压压缩包
tar -zxvf jdk-8u361-linux-x64.tar.gz -C /export/servers/
tar -zxvf hadoop-3.3.3.tar.gz -C /export/servers/
# ls 查看一下解压缩后的内容

# 配置java环境
vi /etc/profile # 编辑profile配置文件
# 添加以下内容
export JAVA_HOME=/export/servers/jdk1.8.0_361
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
# 保存文件
esc
:wq 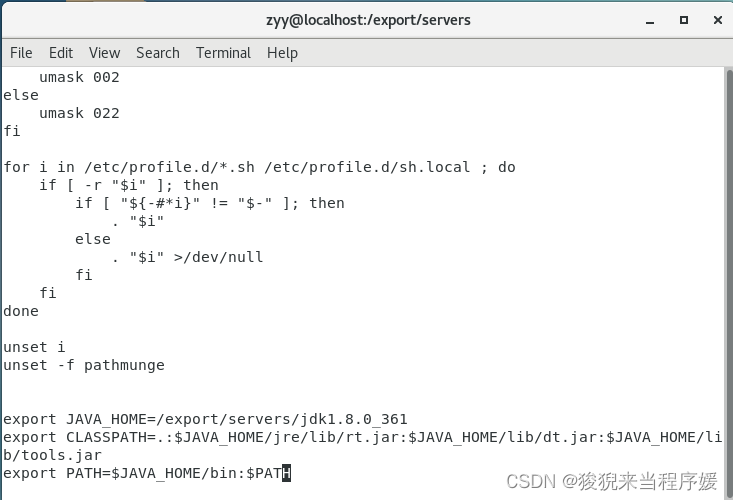
# 更新配置文件
source /etc/profile
# 查看 java 版本
java -version
javac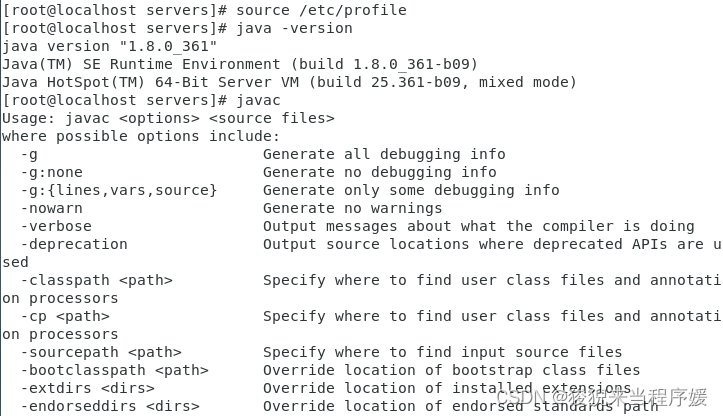
# 配置Hadoop
vi /etc/profile
# 在文件末尾添加以下内容
export HADOOP_HOME=/export/servers/hadoop-3.3.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 保存文件
esc :wq
# 更新文件
source /etc/profile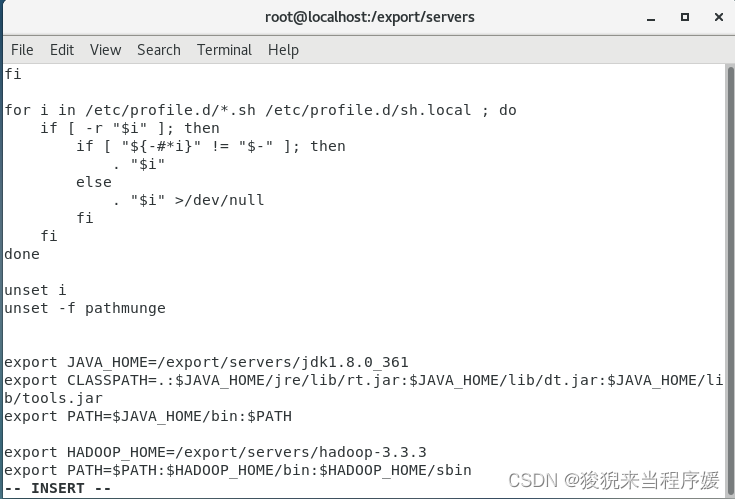
# 查看是否配置成功
hadoop version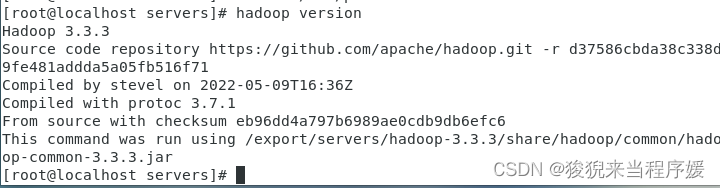
先去下面配置完集群再克隆,就不用最后一个问题解决了。
如果按先克隆,最后在格式化之前,将server01,server02的配置文件修改完再格式化也不会出问题。
# 修改虚拟机主机名
# 查看现在的名字
hostname
# 修改第一台为master
hostnamectl1 set-hoatname master
# hostname再次查看一下,是否修改成功
hostname
# 克隆两台虚拟机
# 关机后,右键相应虚拟机->管理->克隆选择创建完整克隆
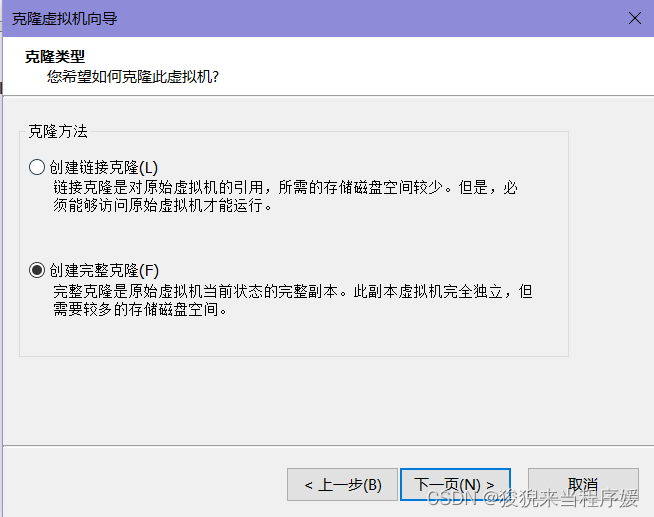
一个起名字server01,另一个起名字server02
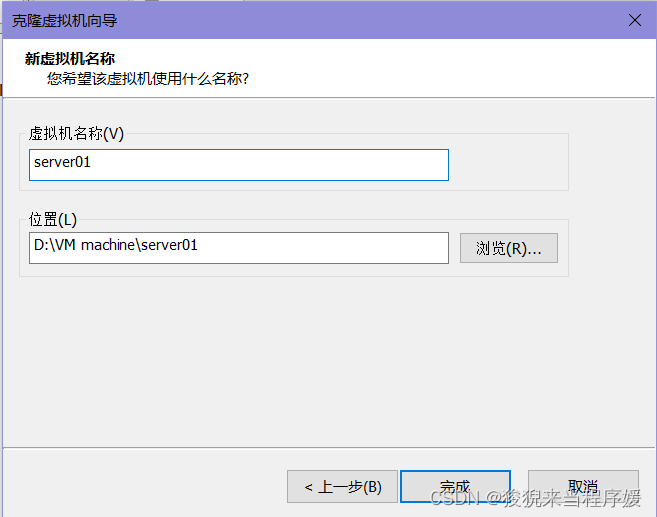
# 分别修改主机名
hostnamectl set-hostname server01
hostnamectl set-hostname server02# 分别修改网络配置
# 查看Mac地址
ifconfig
# 进入root用户
su
# 配置ip地址,保证三台虚拟机在同一个网段
vi /etc/sysconfig/network-scripts/ifcfg-ens33
# server01的配置为192.168.50.161
# server02的配置为192.168.50.162
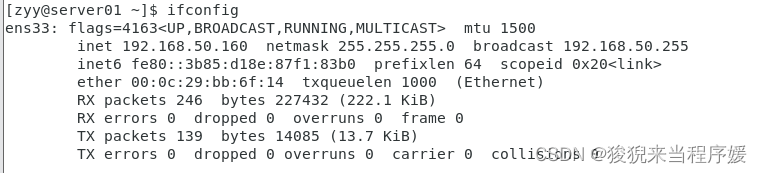
部分文件内容修改如下

# 重启网络,检查是否连通
systemctl restart network
ping www.baidu.com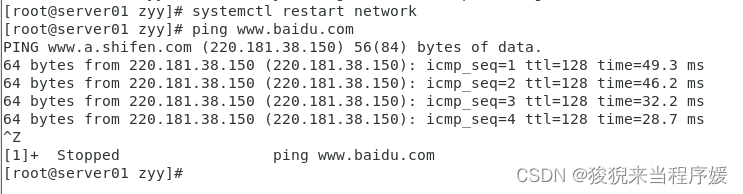
此时用ifconfig检查ip,发现已经修改成功
修改hosts文件
vi /etc/hosts
# 添加以下内容
192.168.50.160 master
192.168.50.161 server01
192.168.50.162 server02
# 保存并退出
# 检查节点是否配置成功
ping master
# ping slave1
# ping slave2
配置免密登录
# master主机上生成密钥文件(四次回车)
ssh-keygen -t rsa 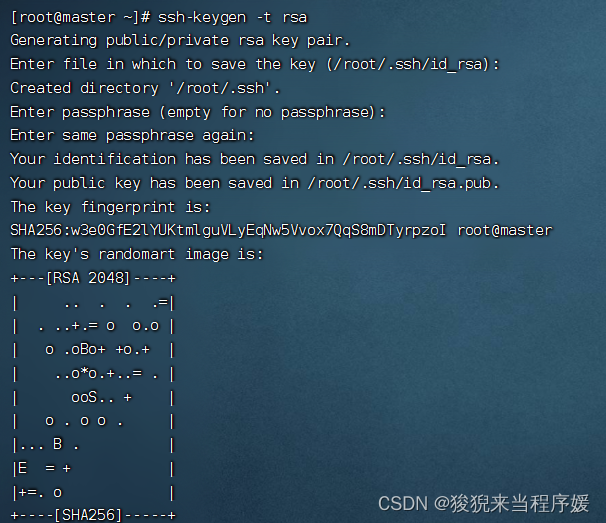
# 本机密钥复制到另外的机器(三台主机都执行)
ssh-copy-id master
ssh-copy-id server01
ssh-copy-id server02
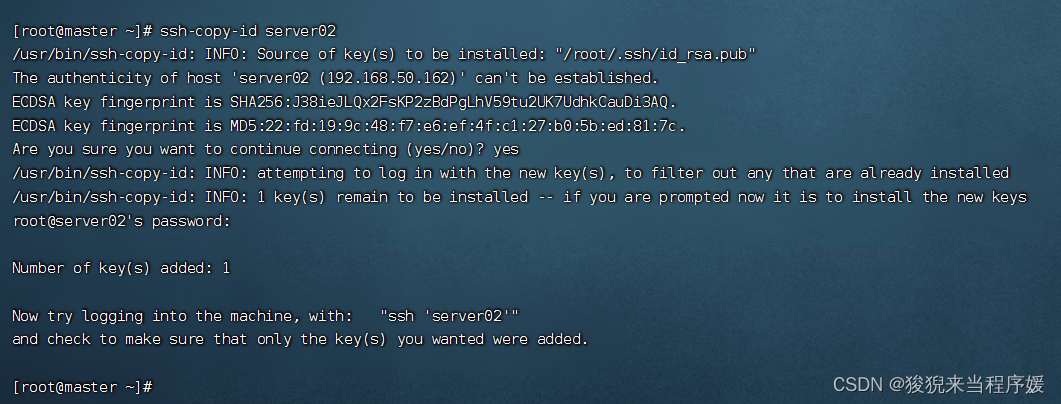
# 检查是否成功免密登录,
# master执行
ssh server01
# server01执行
ssh server02

# 进入主节点配置目录
cd /export/servers/hadoop-3.3.3/etc/hadoop/

# 修改配置文件(三台机器都配置)
vi hadoop-env.sh
# 修改JAVEHOME(找到这句话,等号后面输入这个)
export JAVA_HOME=/export/servers/jdk
export HADOOP_CLASSPATH=$JAVA_HOME/lib/tools.jar
# 保存并退出

# 修改core-site.xml文件
vi core-site.xml添加以下内容:
<configuration>
<!--用于设置Hadoop的文件系统,由URI指定-->
<property>
<name>fs.defaultFS</name>
<!--用于指定namenode地址在hadoop01机器上-->
<value>hdfs://hadoop01:9000</value>
</property>
<!--配置Hadoop的临时目录,默认/tem/hadoop-${user.name}-->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.7.4/tmp</value>
</property>
</configuration>

# 修改hdfs-site.xml文件
vi hdfs-site.xml添加以下内容:
<configuration>
<!--指定HDFS的数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondary namenode 所在主机的IP和端口-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>server01:50090</value>
</property>
</configuration>
# 进行文件备份
cp mapred-site.xml.template mapred-site.xml**
# 修改mapred-site.xml文件
vi mapred-site.xml
添加以下内容:
<configuration> <!--指定MapReduce运行时的框架,这里指定在YARN上,默认在local--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/export/servers/hadoop-3.3.3</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/export/servers/hadoop-3.3.3</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/export/servers/hadoop-3.3.3</value> </property> </configuration>
# 编辑文件
vi yarn-site.xml
添加以下内容
<configuration>
<!--指定YARN集群的管理者(ResourceManager)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
# 修改slaves文件
# 将文件中的localhost删除,添加主节点和子节点的主机名称
# 主节点master,子节点server01,server02
vi workers # hadoop3.x不使用slaves了
# master上格式化节点
hdfs namenode -format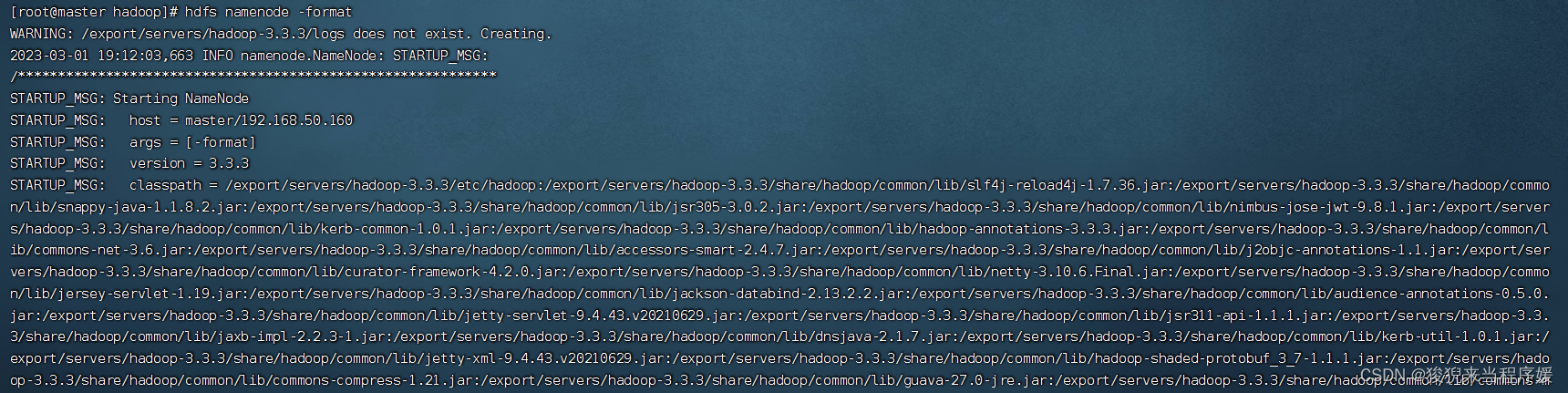
报错,发现没有设置用户
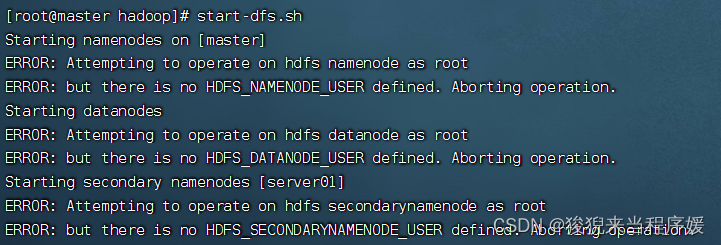
编辑资源文件
# 编辑资源文件
vi ~/.bash_profile
添加以下内容
export HADOOP_HOME=/export/servers/hadoop-3.3.3
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root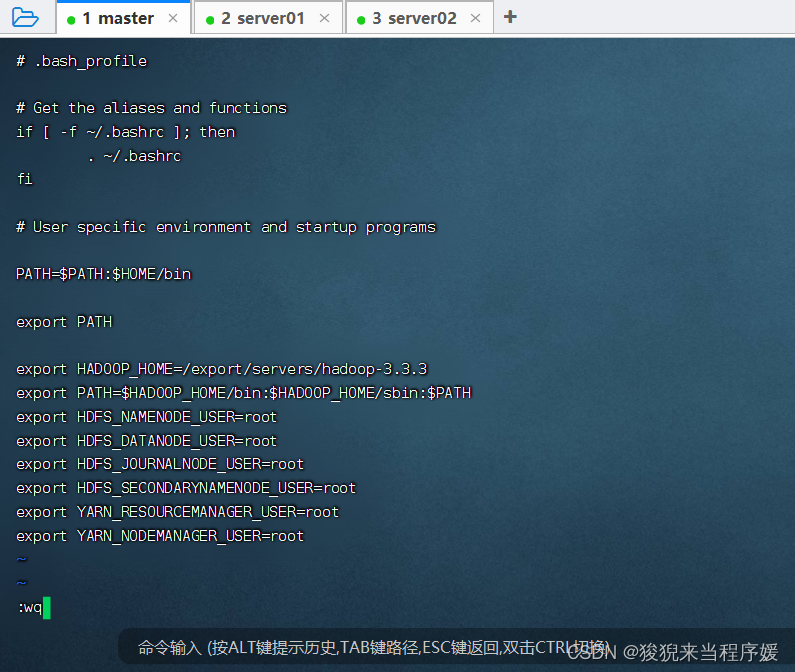
保存后更新资源文件

# 查看启动情况
jps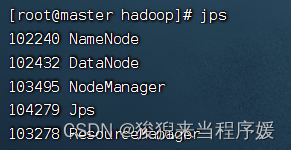
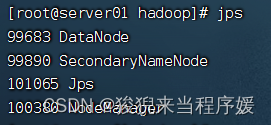
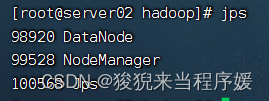
问题解决:
【发现子节点没有datanode】
# 停止所有集群
stop-all.sh【重新格式化集群】
# 删除$HADOOP_HOME下的tmp目录下的所有文件
# 删除logs下的所有文件
【三台机器,只有master有tmp目录】再次格式化就行
在web中检查
【虚拟机中使用火狐浏览器】
在浏览器地址栏中输入http://master:9870/,检查NameNode和DataNode是否正常;【3.0.0之前使用50070端口】
在浏览器地址栏中输入http://master:8088/,检查YARN是否正常
去C:\Windows\System32\drivers\etc
管理员方式打开hosts文件
添加
192.168.50.160 master
192.168.50.161 server01
192.168.50.162 server02
然后在浏览器中输入上面的网址
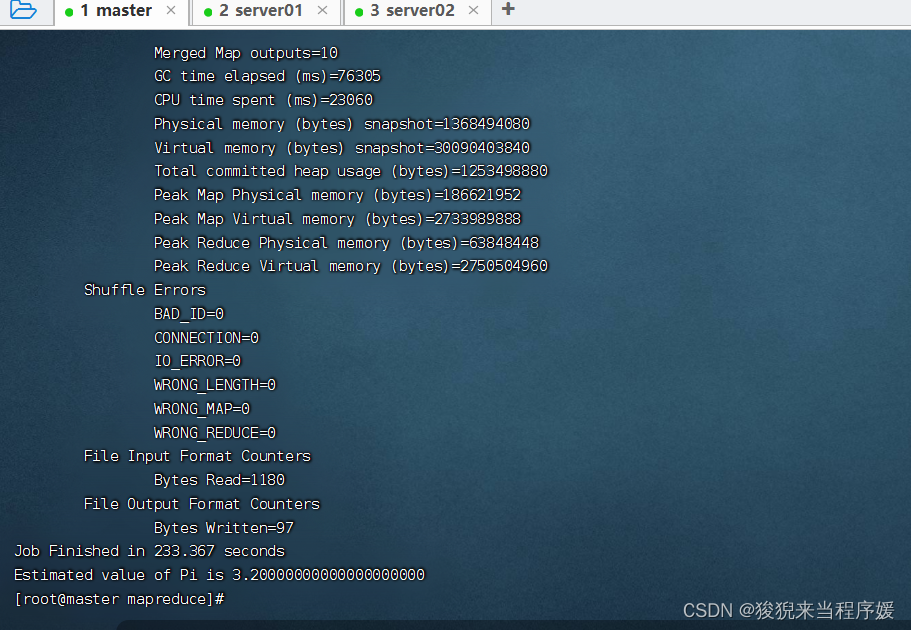
cd hadoop-3.3.3/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-3.3.3.jar pi 10 10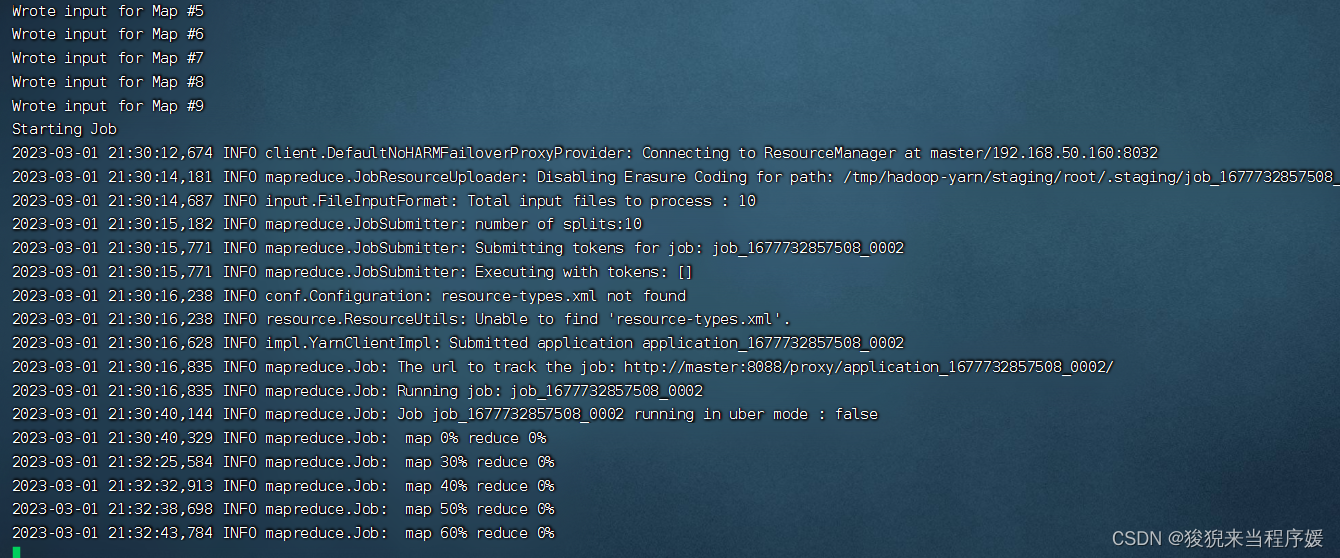
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
注意:本文主要掌握DCN自研无线产品的基本配置方法和注意事项,能够进行一般的项目实施、调试与运维AP基本配置命令AP登录用户名和密码均为:adminAP默认IP地址为:192.168.1.10AP默认情况下DHCP开启AP静态地址配置:setmanagementstatic-ip192.168.10.1AP开启/关闭DHCP功能:setmanagementdhcp-statusup/downAP设置默认网关:setstatic-ip-routegeteway192.168.10.254查看AP基本信息:getsystemgetmanagementgetmanaged-apgetrouteAP配
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我试图在rails中了解rubygems是如何变得可以自动使用的,而不是在使用required的文件中gem? 最佳答案 这是通过bundler/setup完成的:http://bundler.io/v1.3/bundler_setup.html.它在您的config/boot.rb文件中是必需的。简而言之,它首先将环境变量设置为指向您的Gemfile:ENV['BUNDLE_GEMFILE']||=File.expand_path('../../Gemfile',__FILE__)然后它通过要求bundler/setup将所有ge