文章目录
正常工作中,有的客户可能资产列表给的会很详细,但是有的可能就会给个主域名甚至就给个名字,所以这个时候就需要我们自己手动信息收集了。
| 链接 | 说明 |
|---|---|
| https://beian.miit.gov.cn/#/Integrated/index | 工信部备案 |
| https://www.beian.gov.cn/portal/registerSystemInfo | 公安备案 |
| http://icp.chinaz.com/ | 站长之家 |
| https://www.aizhan.com/cha/ | 爱站网 |
| 链接 | 说明 |
|---|---|
| https://dnsdb.io/zh-cnl | Dnsdb |
| https://site.ip138.com | 查询网 |
| https://ti.360.net/#/homepage | 360威胁情报中心 |
| https://x.threatbook.com | 微步在线 |
| https://viewdns.info | viewdns.info |
| https://securitytrails.com | securitytrails |
| https://tools.ipip.net/cdn.php | tools.ipip |
注册域名的时候留下的信息。比如域名注册人的邮箱、电话号码、姓名等。根据这些信息可以尝试制作社工密码,或者查出更多的资产等等,也可以反查注册人,邮箱,电话,机构及更多的域名。
| 在线网站链接 | 说明 |
|---|---|
| https://beian.miit.gov.cn/#/Integrated/index | 工信部备案网站 |
| https://www.beian.gov.cn/portal/registerSystemInfo | 公安备案网站 |
| http://whois.chinaz.com/ | 站长之家 |
| https://whois.aizhan.com/ | 爱站网 |
| https://webwhois.cnnic.cn/WelcomeServlet | 中国互联网信息中心 |
| https://whois.cloud.tencent.com/ | 腾讯云 |
| https://whois.aliyun.com/ | 阿里云 |
| http://whois.xinnet.com/domain/whois/index.jsp | 新网 |
| 反查邮箱链接 | 说明 |
|---|---|
| https://bbs.fobshanghai.com/checkemail.html | 福人 |
| https://www.benmi.com/rwhois | whois反查 |
| http://whois.chinaz.com/reverse?ddlSearchMode=1 | 站长工具 |
| https://phonebook.cz | phonebook |
| https://hunter.io/ | hunter |
| 链接 | 说明 |
|---|---|
| https://ti.360.net/ | 360威胁情报中心 |
| https://x.threatbook.com/ | 微步在线 |
DNS服务器分为主服务器,备份服务器,缓存服务器。
域传送是指备份服务器从主服务器上复制数据,然后更新自身的数据库,以达到数据同步的目的,这样是为了增加冗余,一旦主服务器出现问题可直接让备份服务器做好支撑工作。
而域传送漏洞则是由于DNS配置不当,导致匿名用户可以获取某个域的所有记录,造成整个网络的拓扑结构泄露给潜在的攻击者,凭借这份网络蓝图,攻击者可以节省大量的扫描时间,同时提升了目标的准确度。
DNS域传送漏洞检测方式有三种:nslookup,dig,和使用nmap脚本。
https://hackertarget.com/find-dns-host-records/
https://www.netcraft.com/
通过谷歌、百度、搜狗、360、bing等hack搜索语法搜索子域名。
| 链接 | 说明 |
|---|---|
| https://www.google.com | Google 语法:intitle=公司名称;site:xxxx.com |
| https://www.baidu.com | 百度 语法:intitle=公司名称;site:xxxx.com |
| https://www.sogou.com/ | 搜狗 |
| https://www.so.com/ | 360 |
| https://cn.bing.com/ | Bing |
| 链接 | 说明 |
|---|---|
| https://www.zoomeye.org/ | 钟馗之眼 |
| https://fofa.info/ | fofa |
| https://www.shodan.io/ | shadon |
| https://hunter.qianxin.com/ | 鹰图 |
| https://quake.360.cn/ | 360 |
a)可利用github直接搜索域名或者网站的js文件泄露子域名,JSFinder,JSINFO-SCAN和SubDomainizer都是从网站js文件中搜索子域名的工具。
| 链接 | 说明 |
|---|---|
| https://github.com/Threezh1/JSFinder | JSFinder是一款用作快速在网站的js文件中提取URL,子域名的工具。 |
| https://github.com/p1g3/JSINFO-SCAN | 对网站中引入的JS进行信息搜集的一个工具 |
| https://github.com/nsonaniya2010/SubDomainizer | 查找子域名的工具 |
| https://github.com/rtcatc/Packer-Fuzze | 针对webpack打包方式的 |
| https://github.com/momosecurity/FindSomething | FindSomething |
b)利用文件泄漏,很多网站有跨域策略文件crossdomain.xml、站点地图sitemap.xml和robots.txt等,其中也可能存在子域名的信息。
c)利用网络爬虫,很多网站的页面中,会有跳转到其他系统的功能,如OA、邮箱系统等,其中可能就包含有其他子域名相关的信息,此外部署了内容安全策略(CSP)的网站在header头Content-Security-Policy中,也可能存在域名的信息。可使用burpsuite或者awvs类工具对站点进行爬取分析。
| 链接 | 说明 |
|---|---|
| https://site.ip138.com/ | 查询网 |
| https://phpinfo.me/domain/ | 在线子域名查询 |
| http://tool.chinaz.com | 站长之家 |
| https://www.t1h2ua.cn/tools/ | 子域名扫描 |
| https://dnsdumpster.com/ | dnsdumpster |
| http://dns.aizhan.com | 爱站 |
| 链接 | 说明 |
|---|---|
| https://github.com/euphrat1ca/LayerDomainFinder | layer子域名挖掘机 |
| https://github.com/lijiejie/subDomainsBrute | subDomainsBrute |
| https://github.com/shmilylty/OneForAll | OneforAll |
| https://github.com/aboul3la/Sublist3r | Sublist3r |
| https://github.com/laramies/theHarvester | theHarvester |
| https://github.com/projectdiscovery/subfinder | subfinder |
| https://github.com/knownsec/ksubdomain | ksubdomain |
| 链接 | 说明 |
|---|---|
| https://github.com/dr0op/bufferfly | bufferfly |
| https://github.com/broken5/WebAliveScan | WebAliveScan 可进行批量目标存活扫描和目录扫描 |
| https://github.com/EASY233/Finger | Finger |
| 链接 | 说明 |
|---|---|
| https://myssl.com | SSL/TLS安全评估报告 |
| https://crt.sh/ | crt.sh |
| https://spyse.com/tools/ssl-lookup | SPYSE |
| https://censys.io/ | censy |
要向用户提供加密流量,网站必须先向可信的证书授权中心 (CA) 申请证书。然后,当用户尝试访问相应网站时,此证书即会被提供给浏览器以验证该网站。近年来,由于 HTTPS 证书系统存在结构性缺陷,证书以及签发证书的 CA 很容易遭到入侵和操纵。Google 的证书透明度项目旨在通过提供一个用于监测和审核 HTTPS 证书的开放式框架,来保障证书签发流程安全无虞。可以使用以下网站来查询
crtsh
entrust
censys
google
spyse
certspotter(每小时免费查询100次)
facebook(需要登录)
a)多地ping,可以使用以下两个网站。
http://ping.chinaz.com/
http://ping.aizhan.com/
采用各地 dns 解析的方式来判断是否存在cdn,如果ip一致则不存在相反就是存在的。
知乎是使用了腾讯云的cdn,所以无法直接获取到它的真实IP,这对后续的工作造成了困扰,可以采用网站标题匹配的方法来进行查找,
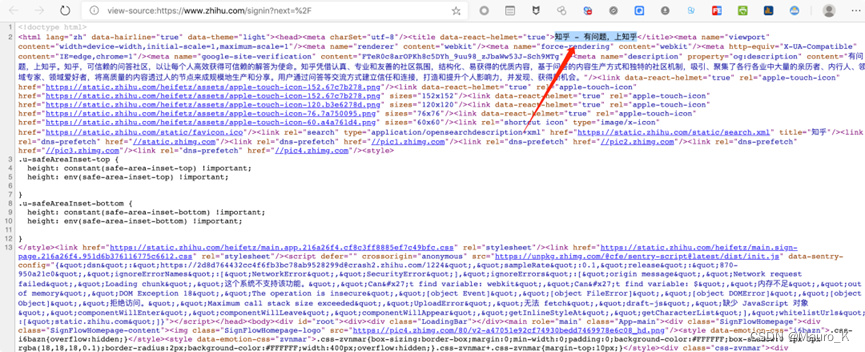
之后我们到fofa来进行titie匹配,然后逐个查看。
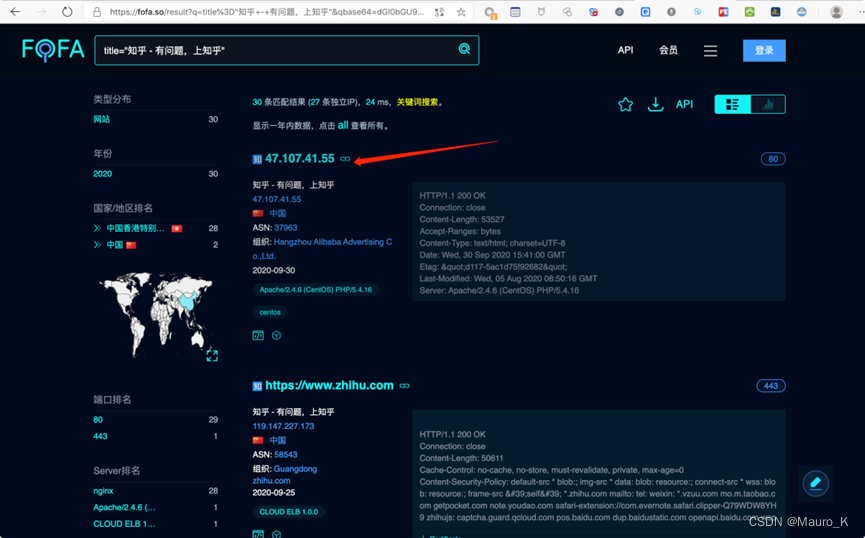
b)利用证书序列号
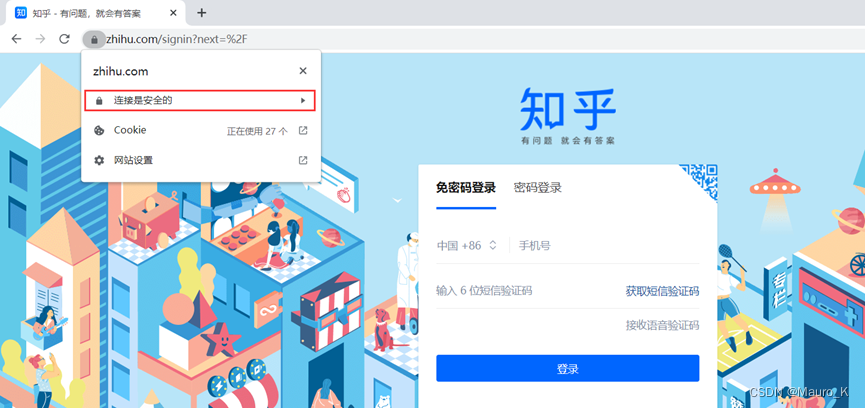
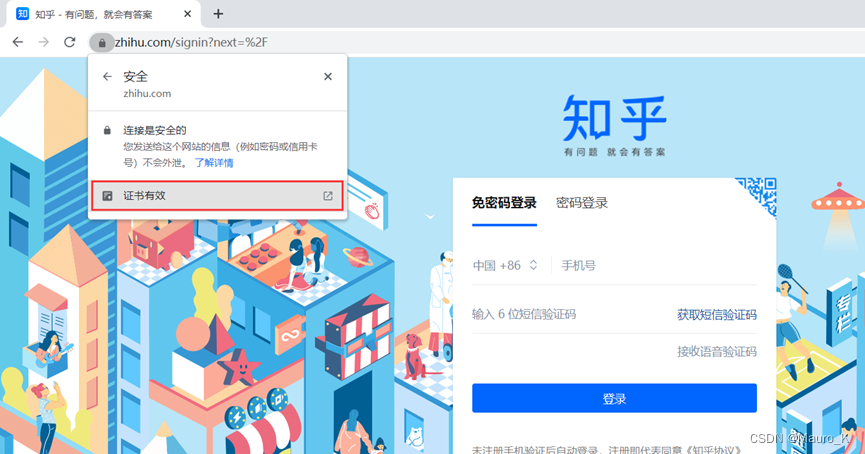
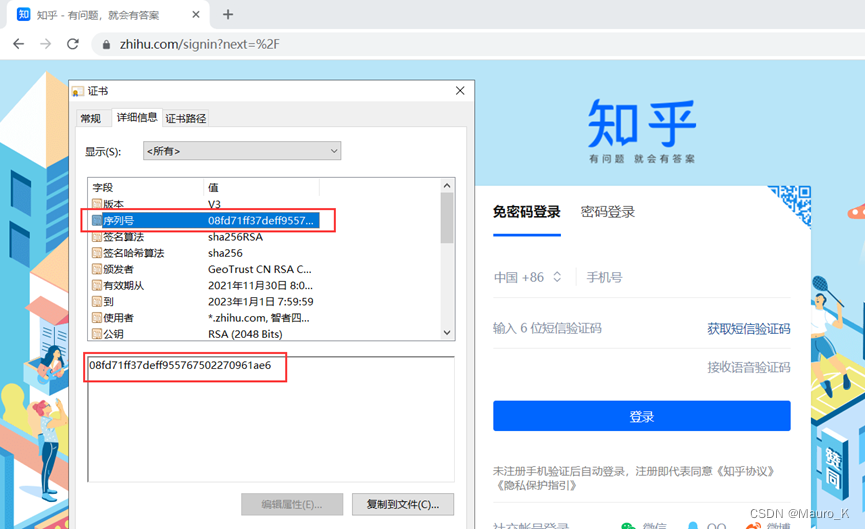
一串16进制字符,我们需要将其调整为10进制来满足知乎的搜索结果。
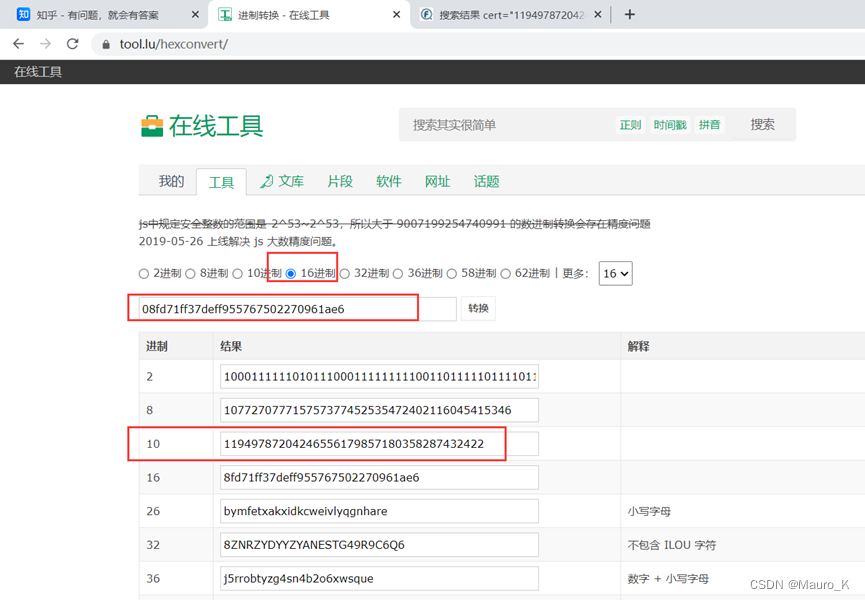
然后在fofa中使用cert 语法进行查询,域名和ip能够都访问网站就为真实ip。
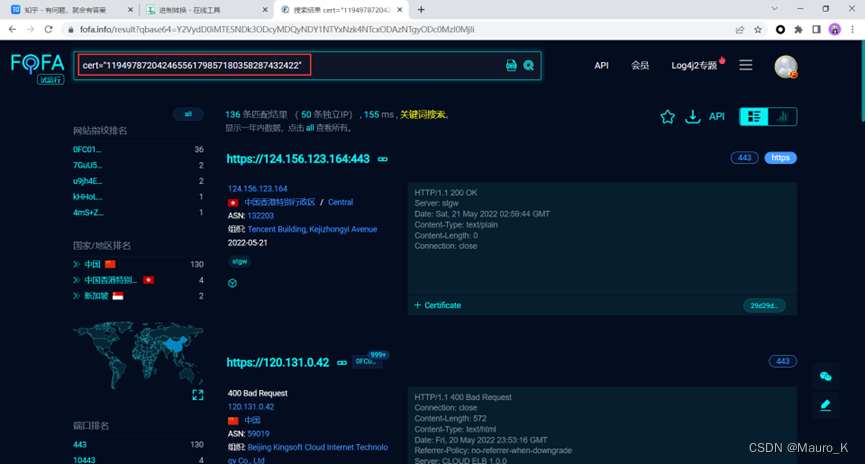
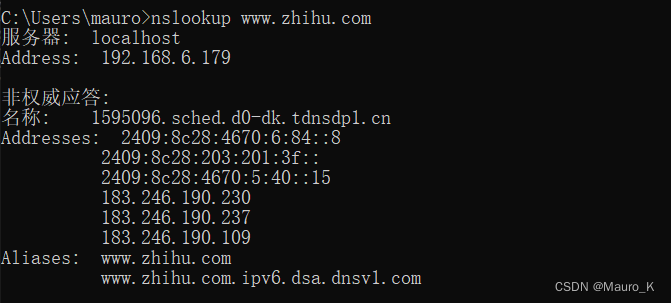
c)利用nslookup
nslookup 进行检测,原理同上,如果返回域名解析对应多个 IP 地址多半是使用了 CDN
d)利用Fofa、Shadon等搜索引擎。
e)ping域名而不带主机名
一般我们都ping www.hasee.com,而www主机名一定会被cdn保护(前提是企业使用cdn)
f)采用国外DNS,这个方法主要就是针对一些cdn 只对国内的ip部署了cdn,对于国外的ip并没有部署,这样就会得到真实IP。
| 链接 | 说明 |
|---|---|
| https://www.wepcc.com/ | wepcc |
| http://www.ab173.com/dns/dns_world.php | ab173 |
| https://dnsdumpster.com/ | dnsdumpster |
| https://who.is/whois/zkaq.cn | who.is |
g)利用邮件去查
很多网站存在注册功能,注册时获取验证码,他会向邮箱发送一封邮件,这时你可以显示邮件全文查看ip
h)利用子域名
这种方法的主要原理就是因为很多公司没有必要为每一个子域名都使用cdn,而且子域名和主站使用
同一个服务器,此时就会导致真实IP泄漏,可以用子域名挖掘机,Subdomainbrute等等去查询子域名,
获取子域名ip。
i)DNS历史解析记录,有一些网站可以查询到DNS历史解析记录,可能在很多网站并未采用cdn时候的解析记录就被记录了下来,之后也并未更换服务器,此时就能查询到真实IP地址。可以使用以下网站等等。
| 链接 | 说明 |
|---|---|
| https://dnsdb.io/zh-cnl | Dnsdb |
| https://site.ip138.com | 查询网 |
| https://ti.360.net/#/homepage | 360威胁情报中心 |
| https://x.threatbook.com | 微步在线 |
| https://viewdns.info | viewdns.info |
| https://securitytrails.com | securitytrails |
| https://tools.ipip.net/cdn.php | tools.ipip |
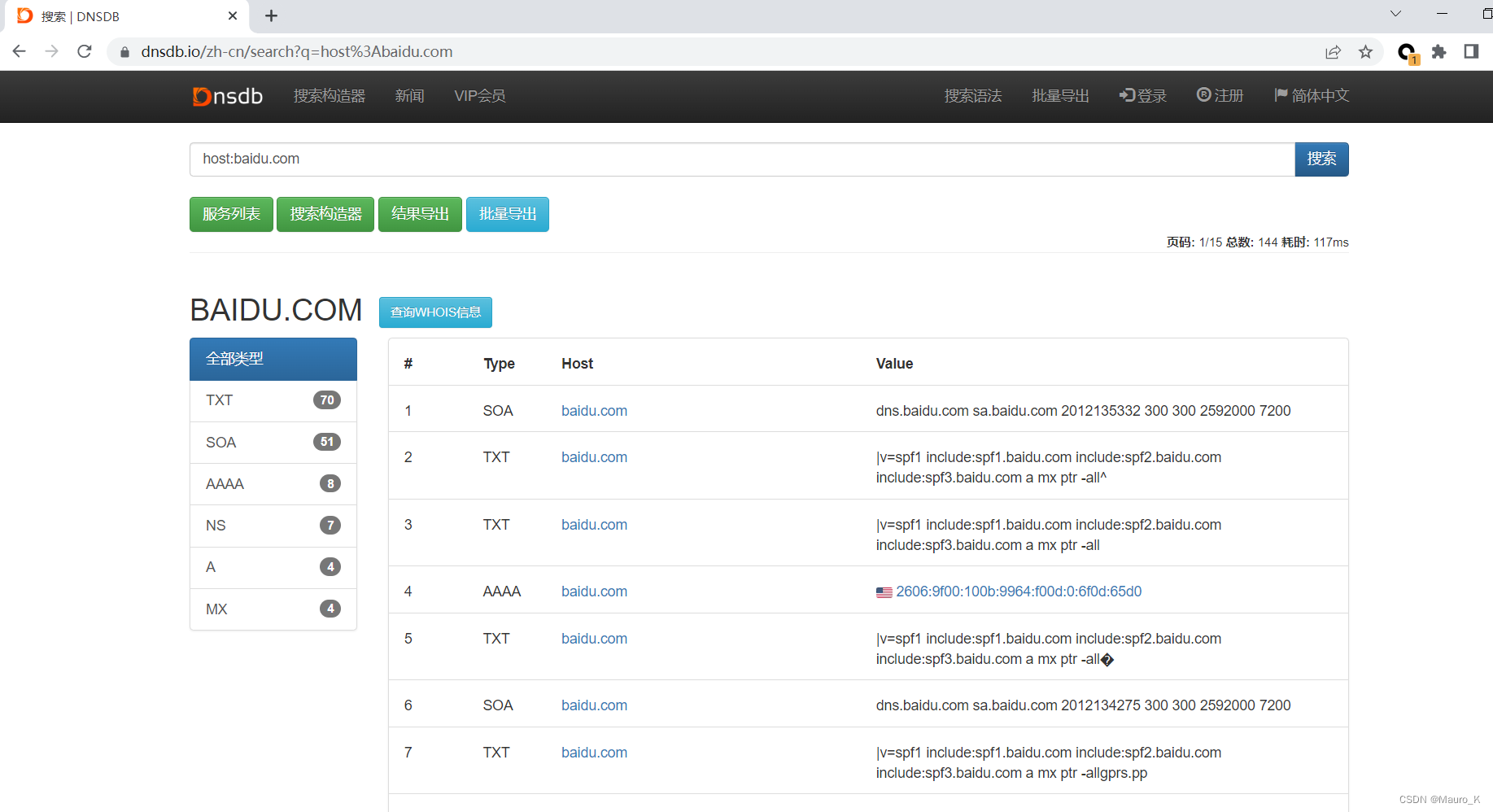
j)HTML 页面信息匹配
采用FOFA搜索引擎(https://fofa.info/)可以对html 进行匹配(shodan也能做到,就是费点劲),
比如我们匹配标题,我们先来查看一下网站首页的标题,然后去fofa搜索就会搜索到。

| 链接 | 说明 |
|---|---|
| https://www.zoomeye.org/ | 钟馗之眼 |
| https://fofa.info/ | fofa |
| https://www.shodan.io/ | shadon |
| https://hunter.qianxin.com/ | 鹰图 |
| https://quake.360.cn/ | 360 |
工具有:Nmap,msscan,Goby,水泽,fscan,EHole(棱洞)等等。
| 链接 | 说明 |
|---|---|
| https://nmap.org/download.html | Nmap |
| https://gobies.org/ | Goby |
| https://github.com/0x727/ShuiZe_0x727 | 水泽 |
| https://github.com/shadow1ng/fscan | fscan |
| https://github.com/EdgeSecurityTeam/EHole | EHole(棱洞) |
| https://github.com/codeyso/CodeTest | ARL灯塔 |
a)二层发现,主要利用arp协议,速度快,结果可靠,不过只能在同网段内的主机。
arping工具:arping 192.168.1.2 -c 1
nmap工具:192.168.1.1-254 –sn
netdiscover -i eth0 -r 192.168.1.0/24
scapy工具:sr1(ARP(pdst="192.168.1.2"))
b)三层发现,主要利用ip、icmp协议,速度快但没有二层发现快,可以经过路由转发,理论上可以探测互联网上任意一台存活主机,但很容易被边界防火墙过滤。
ping工具:ping 192.168.1.2 –c 2
fping工具:fping 192.168.1.2 -c 1
Hping3工具:hping3 192.168.1.2 --icmp -c 2
Scapy工具:sr1(IP(dst="192.168.1.2")/ICMP())
nmap工具:nmap -sn 192.168.1.1-255
c)四层发现,主要利用tcp、udp协议,速度比较慢,但是结果可靠,可以发现所有端口都被过滤的存活主机,不太容易被防火墙过滤。
Scapy工具:
sr1(IP(dst="192.168.1.2")/TCP(dport=80,flags='A') ,timeout=1)) #tcp发现
sr1(IP(dst="192.168.1.2")/UDP(dport=33333),timeout=1,verbose=1) #udp发现
nmap工具:
nmap 192.168.1.1-254 -PA80 –sn #tcp发现
nmap 192.168.1.1-254 -PU53 -sn #udp发现
hping3工具:
hping3 192.168.1.1 -c 1 #tcp发现
hping3 --udp 192.168.1.1 -c 1 #udp发现
知道目标存活主机的操作系统后,可以依据操作系统来实施针对性的测试。
大小写敏感判断
开启22端口的话就是Linux系统
TTL值:Windows(65~128),Linux/Unix(1-64),某些Unix(255)
nmap工具:nmap 192.168.1.1 -O
xprobe2工具:xprobe2 192.168.1.1
p0f工具:使用后,直接访问目标即可
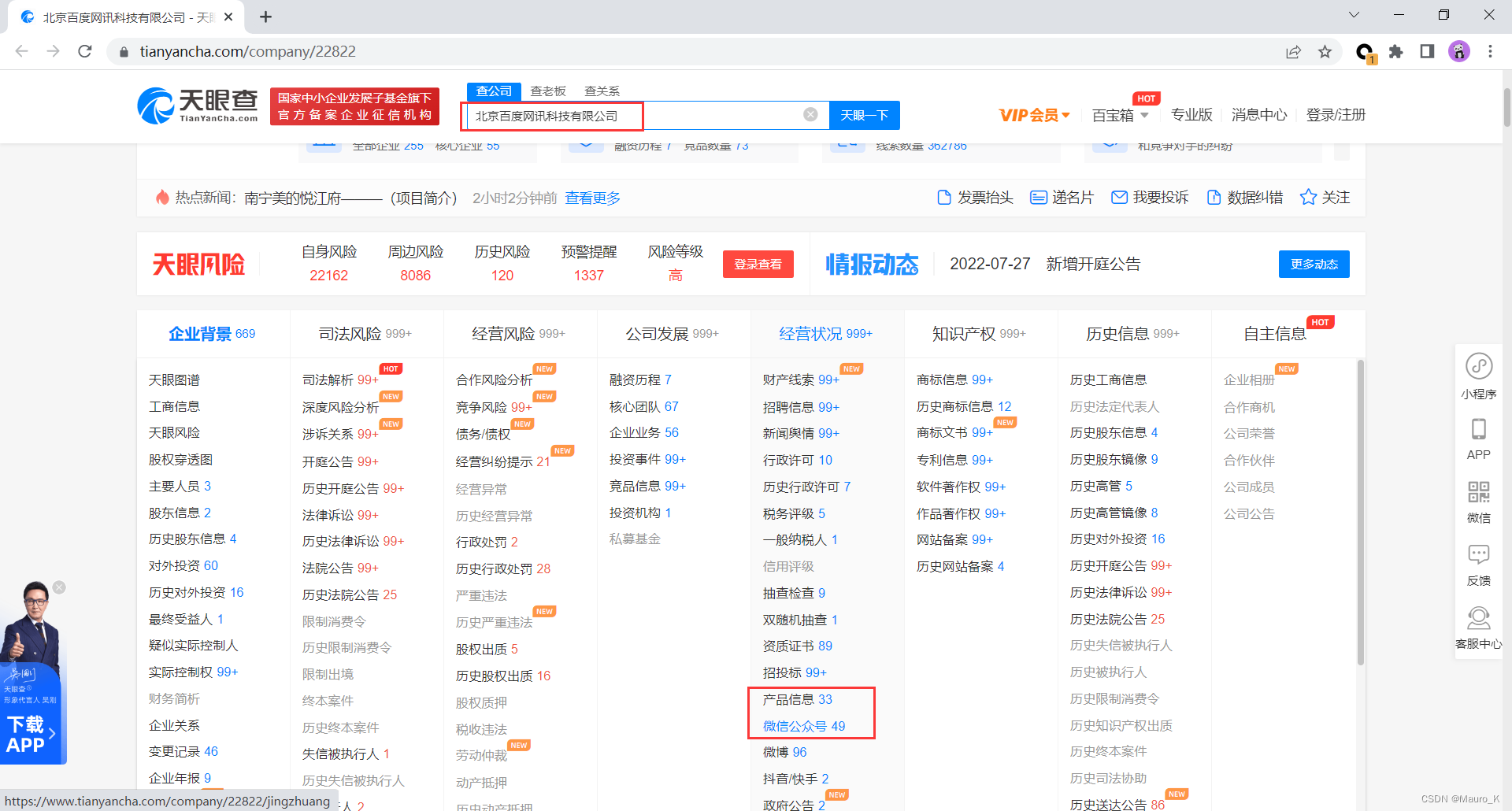
1)如果主站及子站没有思路可以尝试其他方式,如小程序或者APP。可采用天眼查,爱企查,企查查等网站查询该企业的公众号或者APP。
2)微信搜索公众号和小程序大家应该都知道就不举例了,支付宝也一样。
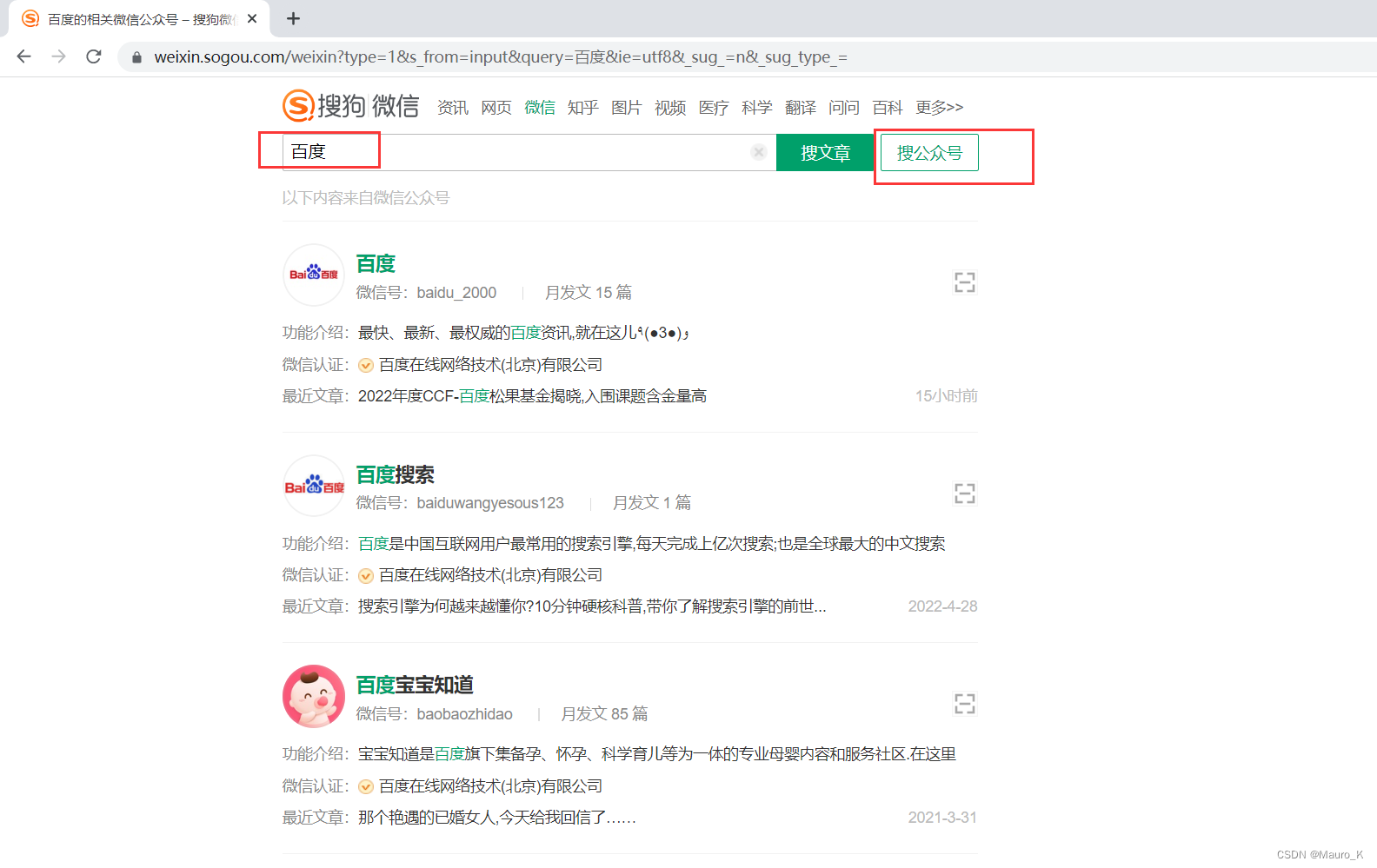
3)还可以用搜狗微信搜索公众号。
1)在线平台:
| 链接 | 说明 |
|---|---|
| http://whatweb.bugscaner.com/look/ | bugscaner 需要扫码登录 |
| https://fp.shuziguanxing.com/#/ | 数字观星 |
| http://www.yunsee.cn/finger.html | 云悉 需注册 |
| http://sso.tidesec.com/ | 潮汐 |
| http://whatweb.bugscaner.com/look/ | whatweb |
| https://github.com/search?q=cms识别 | github查找 |
WAF识别:wafw00f
| 链接 | 说明 |
|---|---|
| https://github.com/EnableSecurity/wafw00f | wafw00f |
网站漏洞扫描,各种扫描器了。如:nessus,极光,xray,AWVS,goby,AppScan,各种大神团队自己编写的扫描器等等。
目录扫描,主要扫描敏感信息、隐藏的目录和api、代码仓库、备份文件等。工具有:各种御剑,dirmap,Dirsearch,dirbuster,7kbstorm,gobuster等等。
在JS中可能会存在大量的敏感信息,包括但不限于:
| 链接 | 说明 |
|---|---|
| https://gitee.com/kn1fes/JSFinder | jsfinder |
| https://github.com/rtcatc/Packer-Fuzzer | Packer-Fuzzer |
| https://gitee.com/mucn/SecretFinder | SecretFinder |
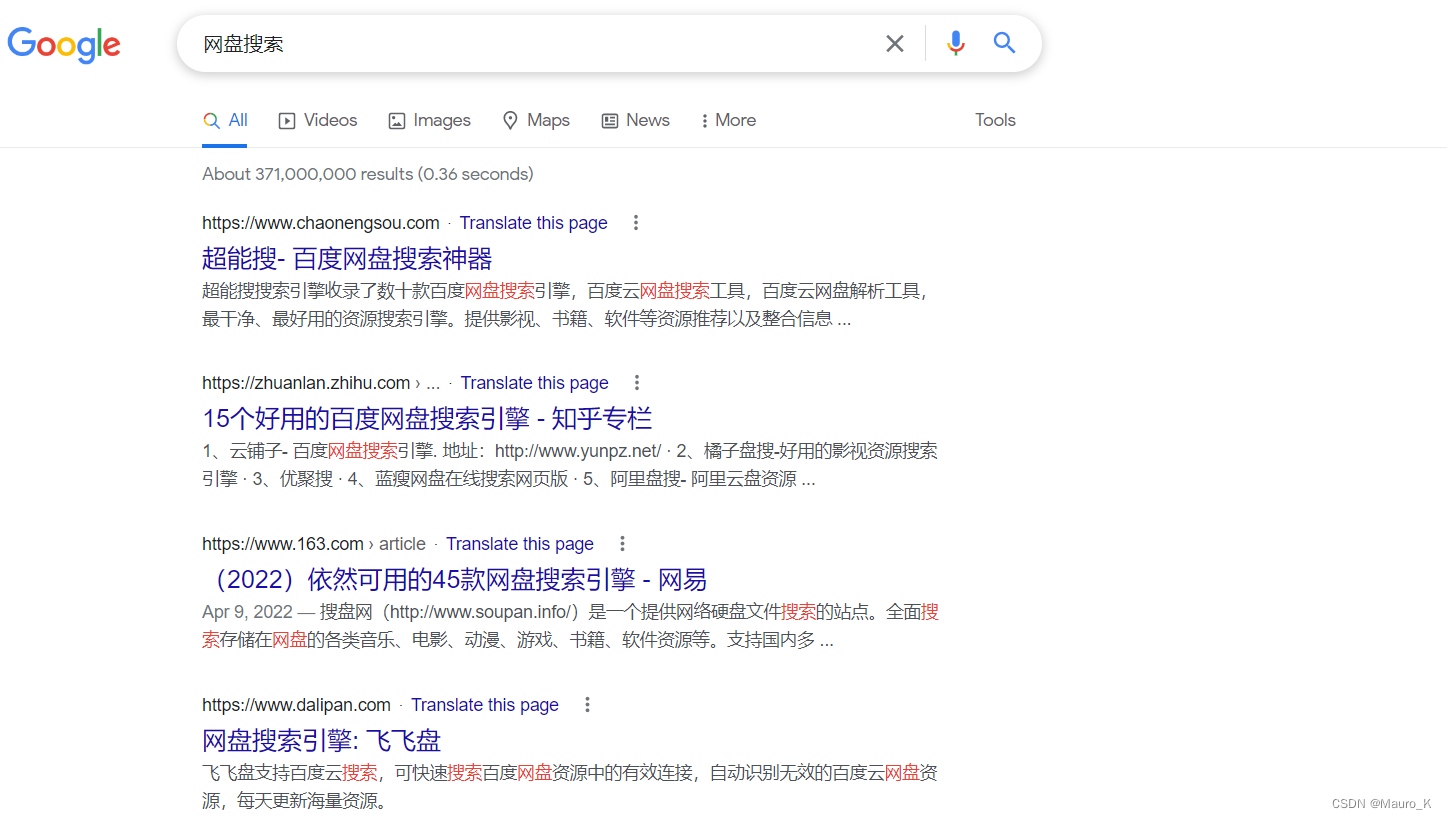
直接百度网盘搜索,就可搜到很多在线网盘,然后进入网盘搜索关键词,如单位名、单位别称等。
| 链接 | 说明 |
|---|---|
| https://wooyun.website/ | 乌云漏洞库 |
| https://www.lingfengyun.com/ | 凌云搜索 |
| http://www.pansoso.com | 盘搜搜 |
| http://www.pansou.com/ | 盘搜 |
通过搜索引擎,谷歌百度搜狗360等hack搜索语法搜索信息。以下示例为谷歌和github:
| Google语法 | 说明 |
|---|---|
| site:xxx.com 学号或管理/admin/login等 | 搜集学号或后台等 |
| site:xxx.com inurl:?=/login/sql.php等等 | 搜集SQL注入点 inurl:URL存在关键字的网页 |
| site:xxx.com filetype:doc/pdf/xlsx/xls等 | 搜集敏感文件 filetype:搜索指定文件类型 |
| site:xxx.com intext:@xxx.com | 搜集mail intext:正文中存在关键字的网页 |
| site:xxx.com intitle:登录/注册 | 搜集敏感web路径 intitle:标题中存在关键字的网页 |
| site:huoxian.cn inurl:token | 搜索token |
| site:Github.com sa password | 密码搜索 |
| site:Github.com root password | 密码搜索 |
| site:Github.com User ID=‘sa’;Password | 密码搜索 |
| site:Github.com inurl:sql | 密码搜索 |
| site:Github.com svn | SVN 信息收集 |
| site:Github.com svn username | SVN 信息收集 |
| site:Github.com svn password | SVN 信息收集 |
| site:Github.com svn username password | SVN 信息收集 |
| site:Github.com password | 综合信息收集 |
| site:Github.com ftp ftppassword | 综合信息收集 |
| site:Github.com 密码 | 综合信息收集 |
| site:Github.com 内部 | 综合信息收集 |
| github语法 | 说明 |
|---|---|
| in:name xxxx | 仓库标题中含有关键字xxxx |
| in:descripton xxxx.com | 仓库描述搜索含有关键字xxxx |
| in:readme xxxx | Readme文件搜素含有关键字xxxx |
| smtp xxx.com password 3306 | 搜索某些系统的密码 |
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
Rails相对较新。我正在尝试调用一个API,它应该向我返回一个唯一的URL。我的应用程序中捆绑了HTTParty。我已经创建了一个UniqueNumberController,并且我已经阅读了几个HTTParty指南,直到我想要什么,但也许我只是有点迷路,真的不知道该怎么做。基本上,我需要做的就是调用API,获取它返回的URL,然后将该URL插入到用户的数据库中。谁能给我指出正确的方向或与我分享一些代码? 最佳答案 假设API为JSON格式并返回如下数据:{"url":"http://example.com/unique-url"
我遇到了这个奇怪的错误.../Users/gideon/Documents/ca_ruby/rubytactoe/lib/player.rb:13:in`gets':Isadirectory-spec(Errno::EISDIR)player_spec.rb:require_relative'../spec_helper'#theuniverseisvastandinfinite...itcontainsagame....butnoplayersdescribe"tictactoegame"docontext"theplayerclass"doit"musthaveahumanplay
我正在使用Ruby/Mechanize编写一个“自动填写表格”应用程序。它几乎可以工作。我可以使用精彩CharlesWeb代理以查看服务器和我的Firefox浏览器之间的交换。现在我想使用Charles查看服务器和我的应用程序之间的交换。Charles在端口8888上代理。假设服务器位于https://my.host.com。.一件不起作用的事情是:@agent||=Mechanize.newdo|agent|agent.set_proxy("my.host.com",8888)end这会导致Net::HTTP::Persistent::Error:...lib/net/http/pe
我想在ruby中生成一个64位整数。我知道在Java中你有很多渴望,但我不确定你会如何在Ruby中做到这一点。另外,64位数字中有多少个字符?这是我正在谈论的示例......123456789999。@num=Random.rand(9000)+Random.rand(9000)+Random.rand(9000)但我认为这是非常低效的,必须有一种更简单、更简洁的方法来做到这一点。谢谢! 最佳答案 rand可以将范围作为参数:pa=rand(2**32..2**64-1)#=>11093913376345012184putsa.
我有两个文本文件,master.txt和926.txt。如果926.txt中有一行不在master.txt中,我想写入一个新文件notinbook.txt。我写了我能想到的最好的东西,但考虑到我是一个糟糕的/新手程序员,它失败了。这是我的东西g=File.new("notinbook.txt","w")File.open("926.txt","r")do|f|while(line=f.gets)x=line.chompifFile.open("master.txt","w")do|h|endwhile(line=h.gets)ifline.chomp!=xputslineendende
我刚刚在我的Ubuntu9.10服务器上安装了TeamBox。我使用提供的服务器脚本在端口3000上启动并运行它。它的运行速度非常慢,从另一台计算机连接时每个HTTP请求最多需要30秒。我使用链接从shell加载TeamBox,一点也不花时间。然后我设置了一个SSH隧道,它再次运行得非常快。我通过此服务器上的apache以及SAMBA等运行了大约30个虚拟主机,没有任何问题。我该如何解决这个问题? 最佳答案 我的redmine(ruby,webrick)太慢了。现在我解决了这个问题:apt-getinstallmongrelruby
我使用raise(ConfigurationError.new(msg))引发错误我试着用rspec测试一下:expect{Base.configuration.username}.toraise_error(ConfigurationError,message)但这行不通。我该如何测试呢?目标是匹配message。 最佳答案 您可以使用正则表达式匹配错误消息:it{expect{Foo.bar}.toraise_error(NoMethodError,/private/)}这将检查NoMethodError是否由privateme