目录
适用场景:批量拉取代码,仓库转移
脚本适用于:python2
测试版本:2.7.18

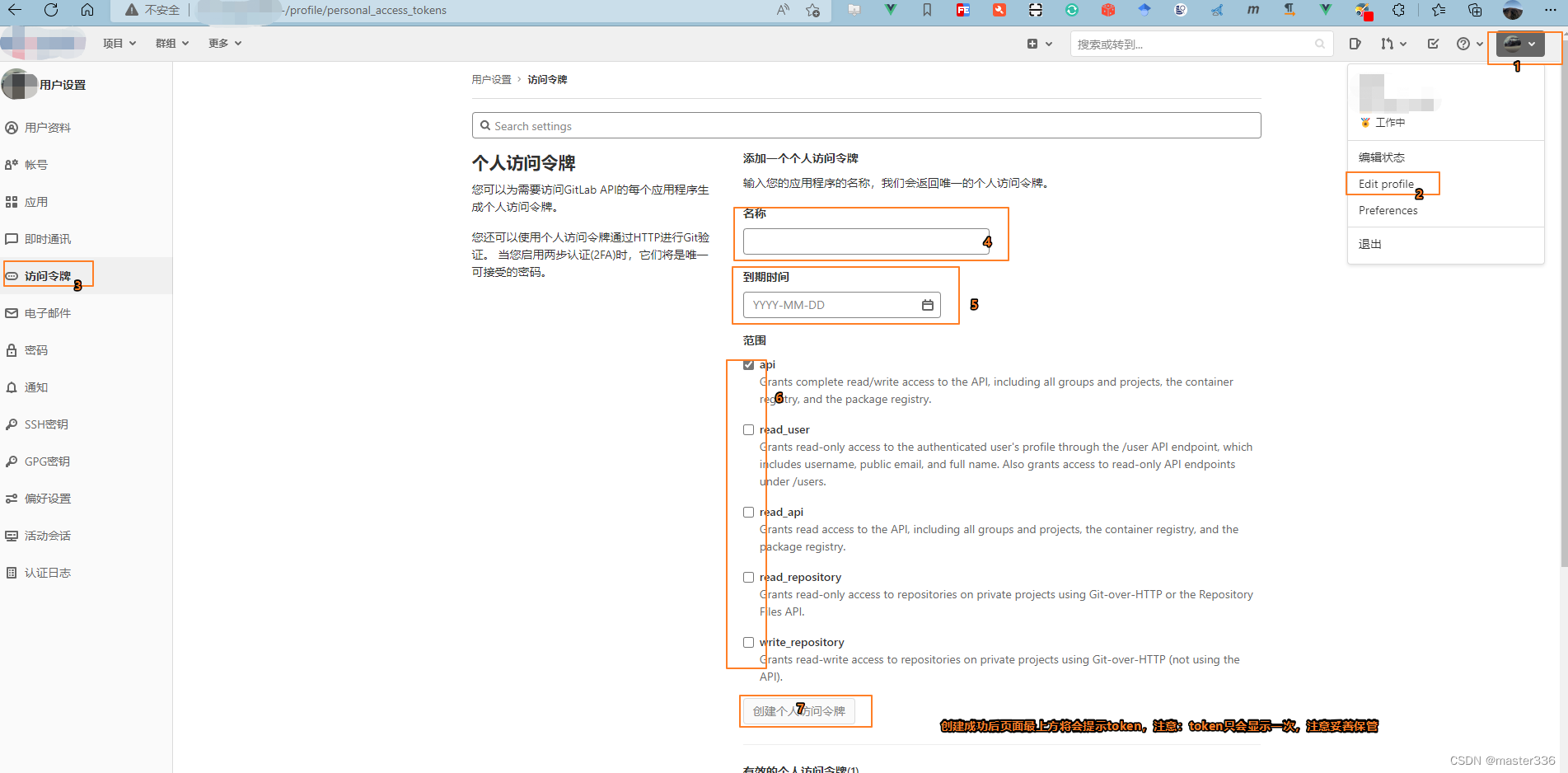
apiToken: gitlab个人账户授权的apitoken ,通过点击右上角【用户头像】->选择【Edit profile】 ->菜单中选择【 访问令牌】,右侧 进行创建,建议给予全部权限

projectUrl: gitlab地址,一般只需要修改ip和端口
python git.py
allproject.json: 所有有权限的非空项目信息
projectclone.sh : 所有项目组成的git clone 命令
projectclonemirror.sh 所有项目组成的git clone -mirror命令
projectpull.sh 所有项目组成的git pull命令
通过gitlab 提供的api接口访问项目信息
# coding: utf-8
import os
import requests
import json
import sys
#python2
reload(sys)
sys.setdefaultencoding('utf-8')
#配置信息,根据实际情况修改
apiToken="X******Seq-******tc"
projectUrl='http://127.0.0.1/api/v4/projects'
#页容量
pageSize=100
projectInfo=[]
currPath=os.getcwd()
#所有项目信息(路径根据所使用环境信息,可能需要修改分隔符)
projectJson=open(currPath+"\\allproject.json",mode="w")
#clone所有项目
projectClone=open(currPath+"\\projectclone.sh",mode="w")
#clone --mirror所有项目
projectCloneMirror=open(currPath+"\\projectclonemirror.sh",mode="w")
#pull所有分支
projectPull=open(currPath+"\\projectpull.sh",mode="w")
projectClone.write("#!/bin/bash\nworkpath=$(cd \"$(dirname \"$0\")\";pwd)\n")
projectCloneMirror.write("#!/bin/bash\nworkpath=$(cd \"$(dirname \"$0\")\";pwd)\n")
projectPull.write("#!/bin/bash\nworkpath=$(cd \"$(dirname \"$0\")\";pwd)\n")
#get请求gitlab的v4 api接口
def get(getUrl):
pageNo = 1
totalPage = 1
totaldata = [];
while pageNo < totalPage+1:
res = requests.get(url=getUrl+'?per_page='+str(pageSize)+'&page='+str(pageNo),headers={"PRIVATE-TOKEN":apiToken})
#print(res.headers)
totalPage=int(res.headers.get('X-Total-Pages'))
totaldata.extend(json.loads(res.text));
#print('total:',totalPage,'pageNo',pageNo)
pageNo+=1
#print(len(totaldata))
return totaldata;
#获取所有分支
def getBranch(branchRepo):
branchR = []
branchs = get(branchRepo)
for branch in branchs:
branchR.append(branch['name'])
return branchR
#获取所有tag
def getTages(branchRepo):
tagRepo = branchRepo.replace("/branches","/tags")
branchR = []
branchs = get(tagRepo)
for branch in branchs:
branchR.append(branch['name'])
return branchR
#获取所有项目
def getAllProject():
projectList = get(projectUrl)
for proj in projectList:
if proj['empty_repo']:
print('null project:',proj['path_with_namespace'])
else:
projInfo = {}
projInfo['id'] = proj['id']
projInfo['path_with_namespace'] = proj['path_with_namespace']
projInfo['empty_repo'] = proj['empty_repo']
projInfo['http_url_to_repo'] = proj['http_url_to_repo']
projInfo['default_branch'] = proj['default_branch']
projInfo['repo_branches'] = proj['_links']['repo_branches']
projInfo['branchs'] = getBranch(projInfo['repo_branches'])
projInfo['tages'] = getTages(projInfo['repo_branches'])
projectInfo.append(projInfo)
#处理输出文件,可单独处理
#处理clone脚本
projectClone.write("cd $workpath\n")
projectClone.write("git clone " + projInfo['http_url_to_repo'] + " " + projInfo['path_with_namespace'] +" \n")
projectClone.write("cd "+projInfo['path_with_namespace']+"\n")
#处理clone --mirror脚本
projectCloneMirror.write("cd $workpath\n")
projectCloneMirror.write("git clone --mirror " + projInfo['http_url_to_repo'] + " " + projInfo['path_with_namespace'] +" \n")
projectCloneMirror.write("cd "+projInfo['path_with_namespace']+"\n")
#处理pull脚本
projectPull.write("cd $workpath\n")
projectPull.write("cd "+projInfo['path_with_namespace']+"\n")
for branch in projInfo['branchs']:
projectClone.write("git checkout \""+branch+"\"\n")
projectClone.write("git pull\n")
projectCloneMirror.write("git checkout \""+branch+"\"\n")
projectCloneMirror.write("git pull\n")
projectPull.write("git checkout \""+branch+"\"\n")
projectPull.write("git pull\n")
for tag in projInfo['tages']:
projectClone.write("git checkout \""+tag+"\"\n")
projectCloneMirror.write("git checkout \""+tag+"\"\n")
projectPull.write("git checkout \""+tag+"\"\n")
#projectCloneMirror.write("#!/bin/bash\nworkpath=$(cd \"$(dirname \"$0\")\";pwd)\n")
#projectPull.write("#!/bin/bash\nworkpath=$(cd \"$(dirname \"$0\")\";pwd)\n")
return projectInfo
#
getAllProject()
#将所有项目信息写入文件
projectJson.write(json.dumps(projectInfo))
projectJson.flush()
projectJson.close()
projectClone.flush()
projectClone.close()
projectCloneMirror.flush()
projectCloneMirror.close()
projectPull.flush()
projectPull.close()
#直接调起系统命令
print(os.system('git --version'))
#自动识别仓库类型(git/svn)并更新
#!/bin/bash
basepath=$(pwd)
echo $basepath
updateSource(){
#local currpath=$1
cd $1
if [ -d $1/.git ]; then
echo 'start update sourcecode'$1
echo "开始更新"$currpath
git pull
#老版本的svn每个文件夹一个.svn文件夹,
elif [ -d $1/.svn ]; then
#revision=`svn info |grep "Last Changed Rev:" |awk '{print $4}'`
revision=`svn info |grep "最后修改的版本" |awk '{print $2}'`
if [ $revision > 0 ]; then
echo '$revision 开始更新代码'$1
svn update .
fi
else
for childfile in `ls .`
do
pwd
if [ -d $1/$childfile ]; then
updateSource $1/$childfile
else
echo $1/$childfile' is not dir , will ignore-------<'
fi
done
fi
}
#main run
updateSource $basepath
通过api创建分组、项目
通过git clone --mirror 及 git push --mirror 迁移仓库
接口异常未处理!
# coding: utf-8
import os
import requests
import json
import sys
import time
#python2
reload(sys)
sys.setdefaultencoding('utf-8')
#源库信息
apiToken="****-******"
projectUrl='http://127.0.0.1:1307/api/v4/projects'
#目标库信息
targetapiToken="****-******"
targetHostUrl='http://127.0.0.1:1306/api/v4/'
#目标库分组id(将按源目录自动提交到此分组下)
targetNamespaceId=6
#目标库分组名称
targetNamespaceName="demo/"
#目标库删除异步等待时间(重新创建)
deleteWaitsec=5
pageSize=100
projectInfo=[]
currPath=os.getcwd()
#所有项目信息
projectJson=open(currPath+"\\allproject.json",mode="w")
#clone --mirror所有项目
projectCloneMirror=open(currPath+"\\projectclonemirrorpush.sh",mode="w")
projectCloneMirror.write("#!/bin/bash\nworkpath=$(cd \"$(dirname \"$0\")\";pwd)\n")
#get请求gitlab的v4 api接口
def get(getUrl):
pageNo = 1
totalPage = 1
totaldata = [];
while pageNo < totalPage+1:
res = requests.get(url=getUrl+'?per_page='+str(pageSize)+'&page='+str(pageNo),headers={"PRIVATE-TOKEN":apiToken})
#print(res.headers)
totalPage=int(res.headers.get('X-Total-Pages'))
totaldata.extend(json.loads(res.text));
#print('total:',totalPage,'pageNo',pageNo)
pageNo+=1
#print(len(totaldata))
return totaldata;
#获取所有分支
def getBranch(branchRepo):
branchR = []
branchs = get(branchRepo)
for branch in branchs:
branchR.append(branch['name'])
return branchR
#获取所有tag
def getTages(branchRepo):
tagRepo = branchRepo.replace("/branches","/tags")
branchR = []
branchs = get(tagRepo)
for branch in branchs:
branchR.append(branch['name'])
return branchR
def createGroup(pgroupId,groupName):
print("startcreateGroup",pgroupId,groupName)
res = requests.get(url=targetHostUrl+'groups?id='+str(pgroupId)+'&search='+groupName,headers={"PRIVATE-TOKEN":targetapiToken})
if res.status_code<300 and res.status_code >= 199:
#请求成功
resdata = (json.loads(res.text));
if len(resdata) > 0:
#存在,返回groupid
print("hasgroup",pgroupId,groupName)
return resdata[0]['id']
else:
#不存在,创建
print("newgroup",pgroupId,groupName)
reqdata={"name":groupName,"path":groupName,"parent_id":pgroupId}
res = requests.post(url=targetHostUrl+'groups',data=reqdata,headers={"PRIVATE-TOKEN":targetapiToken})
resdata = (json.loads(res.text));
return resdata['id']
else:
print("errorgroup",pgroupId,groupName)
def pushOnGroup(prowithNamespace,groupId):
#验证项目是否存在
res = requests.get(url=targetHostUrl+'projects?search='+targetNamespaceName+prowithNamespace+'&search_namespaces=true',headers={"PRIVATE-TOKEN":targetapiToken})
resdata = (json.loads(res.text));
if len(resdata) > 0:
#项目存在
print("projecthas",prowithNamespace,groupId)
proId = resdata[0]["id"]
requests.delete(url=targetHostUrl+'projects/'+str(proId),headers={"PRIVATE-TOKEN":targetapiToken})
time.sleep(deleteWaitsec)
grouppros = prowithNamespace.split("/")
currgroupId = groupId;
proName=""
for index in range(len(grouppros)):
#最后一层是项目名
if index == len(grouppros)-1:
proName = grouppros[index]
else:
currgroupId = createGroup(currgroupId,grouppros[index])
#创建项目
print("startCreateProject",proName,currgroupId)
prodata={"name": proName,"description":proName,"path": proName,"namespace_id": str(currgroupId),"initialize_with_readme": "false"}
res = requests.post(url=targetHostUrl+'projects',data=prodata,headers={"PRIVATE-TOKEN":targetapiToken})
resdata = (json.loads(res.text));
return resdata['http_url_to_repo']
#获取所有项目
def getAllProject():
projectList = get(projectUrl)
for proj in projectList:
if proj['empty_repo']:
print('null project:',proj['path_with_namespace'])
else:
projInfo = {}
projInfo['id'] = proj['id']
projInfo['path_with_namespace'] = proj['path_with_namespace']
projInfo['empty_repo'] = proj['empty_repo']
projInfo['http_url_to_repo'] = proj['http_url_to_repo']
projInfo['default_branch'] = proj['default_branch']
projInfo['repo_branches'] = proj['_links']['repo_branches']
projectInfo.append(projInfo)
#写入拉取代码
projectCloneMirror.write("cd $workpath\n")
projectCloneMirror.write("git clone --mirror " + projInfo['http_url_to_repo'] + " " + projInfo['path_with_namespace'] +" \n")
#写入提交代码
projectCloneMirror.write("cd "+projInfo['path_with_namespace']+"\n")
projectCloneMirror.write("git push --mirror " + pushOnGroup(projInfo['path_with_namespace'],targetNamespaceId) +" \n")
return projectInfo
#
getAllProject()
#将所有项目信息写入文件
projectJson.write(json.dumps(projectInfo))
projectJson.flush()
projectJson.close()
#直接调起系统命令
print(os.system('git --version'))
官网:https://about.gitlab.com/
官方api地址: https://docs.gitlab.com/ee/api/
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我正在使用puppet为ruby程序提供一组常量。我需要提供一组主机名,我的程序将对其进行迭代。在我之前使用的bash脚本中,我只是将它作为一个puppet变量hosts=>"host1,host2"我将其提供给bash脚本作为HOSTS=显然这对ruby不太适用——我需要它的格式hosts=["host1","host2"]自从phosts和putsmy_array.inspect提供输出["host1","host2"]我希望使用其中之一。不幸的是,我终其一生都无法弄清楚如何让它发挥作用。我尝试了以下各项:我发现某处他们指出我需要在函数调用前放置“function_”……这
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我正在尝试修改当前依赖于定义为activeresource的gem:s.add_dependency"activeresource","~>3.0"为了让gem与Rails4一起工作,我需要扩展依赖关系以与activeresource的版本3或4一起工作。我不想简单地添加以下内容,因为它可能会在以后引起问题:s.add_dependency"activeresource",">=3.0"有没有办法指定可接受版本的列表?~>3.0还是~>4.0? 最佳答案 根据thedocumentation,如果你想要3到4之间的所有版本,你可以这
我在理解Enumerator.new方法的工作原理时遇到了一些困难。假设文档中的示例:fib=Enumerator.newdo|y|a=b=1loopdoy[1,1,2,3,5,8,13,21,34,55]循环中断条件在哪里,它如何知道循环应该迭代多少次(因为它没有任何明确的中断条件并且看起来像无限循环)? 最佳答案 Enumerator使用Fibers在内部。您的示例等效于:require'fiber'fiber=Fiber.newdoa=b=1loopdoFiber.yieldaa,b=b,a+bendend10.times.m