
目录
这个女娃娃是否有一种初恋的感觉呢,但是她很明显不是一个真正意义存在的图片,我们需要很复杂的推算以及各种炼丹模型生成的AI图片,我自己认为难度系数很高,我仅仅用了64个文字形容词就生成了她,很有初恋的感觉,符合审美观,对于计算机来说她是一组数字,可是这个数字是怎么推断出来的就是很复杂了,我们在模型训练中可以看到基本上到处都存在着Pandas处理,在最基础的OpenCV中也会有很多的Pandas处理,所以我OpenCV写到一般就开始写这个专栏了,因为我发现没有Pandas处理基本上想好好的操作图片数组真的是相当的麻烦,可以在很多AI大佬的文章中发现都有这个Pandas文章,每个人的写法都不同,但是都是适合自己理解的方案,我是用于教学的,故而我相信我的文章更适合新晋的程序员们学习,期望能节约大家的事件从而更好的将精力放到真正去实现某种功能上去。本专栏会更很多,只要我测试出新的用法就会添加,持续更新迭代,可以当做【Pandas字典】来使用,期待您的三连支持与帮助。
系统环境:win11
Python版本:python3.9
编译工具:PyCharm Community Edition 2022.3.1
Numpy版本:1.19.5
Pandas版本:1.4.4
在数据操作的时候我们经常会见到NaN空值的情况,很耽误我们的数据清理,那我们使用dropna函数删除DataFrame中的空值。
实际上能处理的有3个函数,我们用dropna来删除这帮空值。
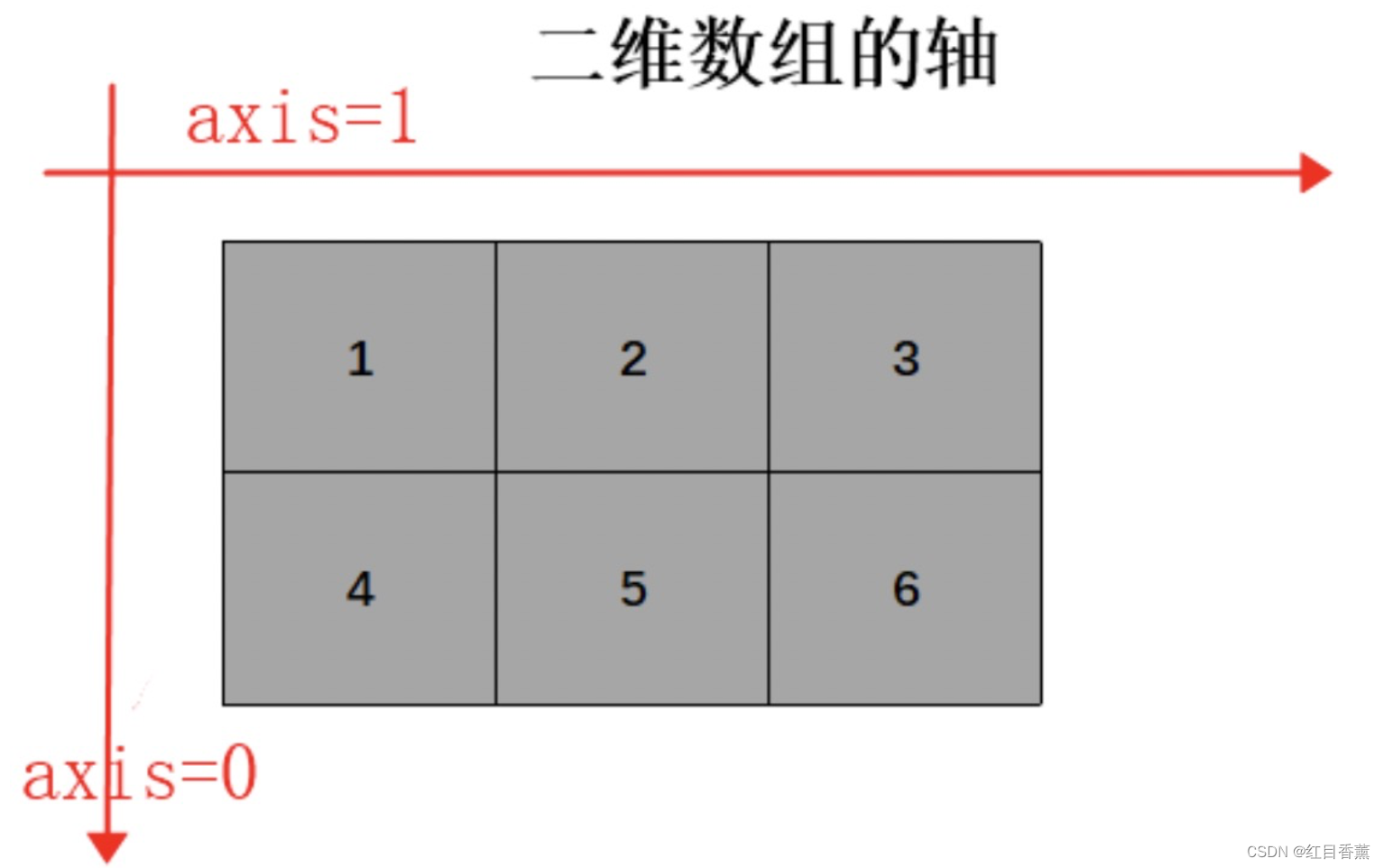
DataFrame.dropna([axis, how, thresh, …]) #返回对象与给定的轴上的标签省略或者任何地方
DataFrame.fillna([value, method, axis, …]) #填充空值
DataFrame.replace([to_replace, value, …]) #值在“to_replace”替换为“value”。axis:操作的轴向,X/Y
how:两个参数any与all,all代表整个行都是空才会删除
thresh:某行的空值超过这个阈值才会删除
subset:处理空值时,只考虑给定的列。需要提供列名数组
inplace:值是True和False,True是在原DataFrame上修改,False则创建新副本
import pandas as pd
import numpy as np
df = pd.DataFrame(
{'name': ['张丽华', '李诗诗', '王语嫣', '赵飞燕', '阮玲玉'],
'sex': ['girl', 'woman', np.nan, 'girl', 'woman'],
'age': [22, np.nan, 16, np.nan, 27]
}
)
print(df)
可以看到有好多空值:
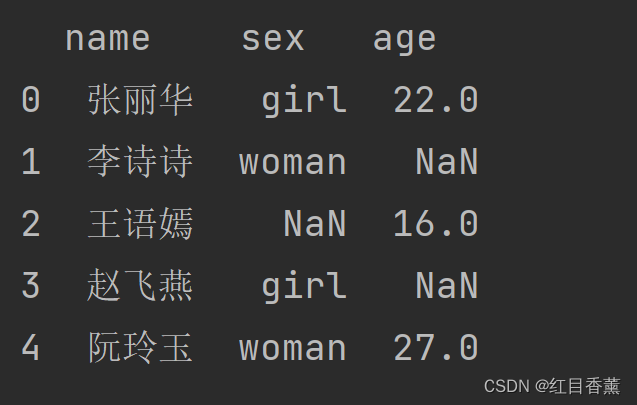
这里的dropna只填写了【axis】一个参数,其中0的值代表行,1的值代表列。
import pandas as pd
import numpy as np
df = pd.DataFrame(
{'name': ['张丽华', '李诗诗', '王语嫣', '赵飞燕', '阮玲玉'],
'sex': ['girl', 'woman', np.nan, 'girl', 'woman'],
'age': [22, np.nan, 16, np.nan, 27]
}
)
print(df)
print("----axis=0----")
# 删除所有有空的行
df = df.dropna(axis=0)
print(df)
axis=0效果测试:

axis=1效果测试:

很明显我们能看的出来,只要是axis=0有空的行就删除了,axis=1有空的列就删除了。
import pandas as pd
import numpy as np
df = pd.DataFrame(
{'name': ['张丽华', '李诗诗', '王语嫣', '赵飞燕', '阮玲玉'],
'sex': ['girl', 'woman', np.nan, 'girl', 'woman'],
'age': [22, np.nan, 16, np.nan, 27]
}
)
print(df)
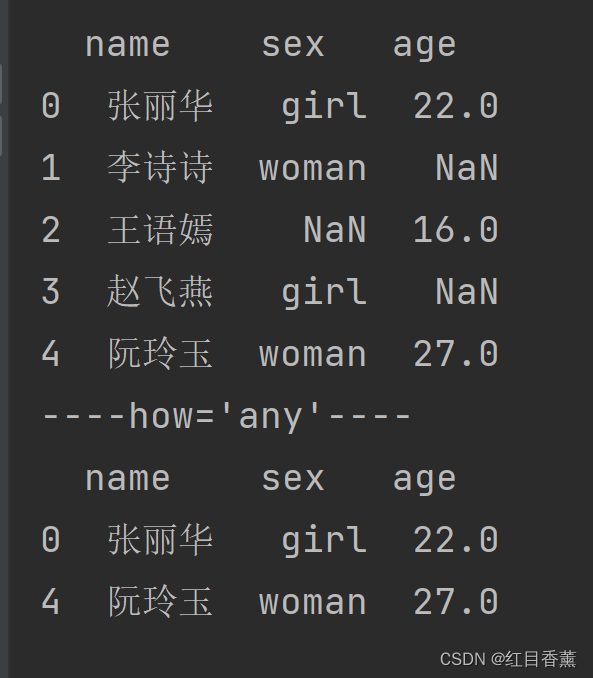
print("----how='any'----")
# any有空行就删除·all必须都是空行才能删除
df = df.dropna(how='any')
print(df)
any效果:
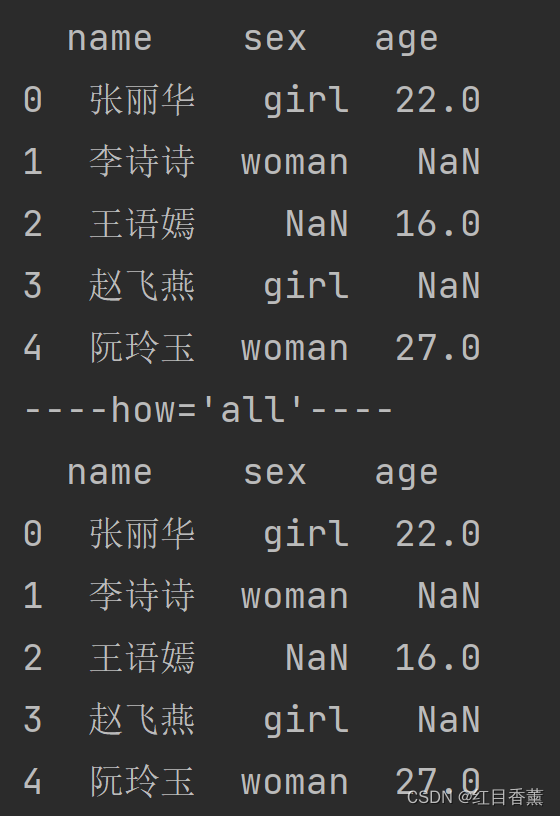
all效果:由于没有都是NaN的行,故而都没有删除。
import pandas as pd
import numpy as np
df = pd.DataFrame(
{'name': ['张丽华', '李诗诗', '王语嫣', '赵飞燕', '阮玲玉'],
'sex': ['girl', 'woman', np.nan, 'girl', 'woman'],
'age': [22, np.nan, np.nan, np.nan, 27]
}
)
print(df)
print("----thresh=2----")
# 有空的都删掉
df = df.dropna(thresh=2)
print(df)
有2个nan就会删除行

我这里清除的是[name,age]两列只要有NaN的值就会删除行
import pandas as pd
import numpy as np
df = pd.DataFrame(
{'name': ['张丽华', '李诗诗', '王语嫣', '赵飞燕', '阮玲玉'],
'sex': ['girl', 'woman', np.nan, 'girl', 'woman'],
'age': [22, np.nan, 16, np.nan, 27]
}
)
print(df)
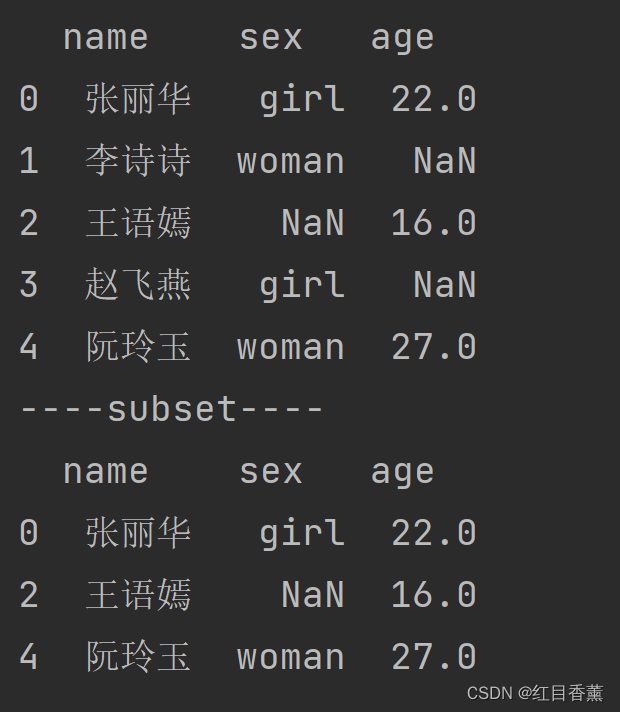
print("----subset----")
# subset传的参数是列名的数组
df = df.dropna(subset=['name', 'age'])
print(df)
实际效果:
inplace=False,不复制副本,我们不二次赋值。
import pandas as pd
import numpy as np
df = pd.DataFrame(
{'name': ['张丽华', '李诗诗', '王语嫣', '赵飞燕', '阮玲玉'],
'sex': ['girl', 'woman', np.nan, 'girl', 'woman'],
'age': [22, np.nan, 16, np.nan, 27]
}
)
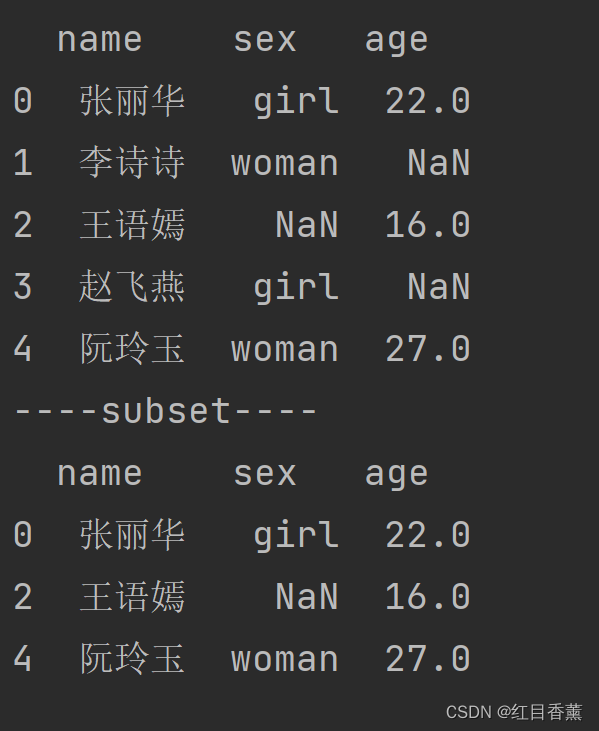
print(df)
print("----subset----")
# subset传的参数是列名的数组
df.dropna(subset=['name', 'age'], inplace=False)
print(df)
复制副本,但是未重新赋值效果

不复制副本
import pandas as pd
import numpy as np
df = pd.DataFrame(
{'name': ['张丽华', '李诗诗', '王语嫣', '赵飞燕', '阮玲玉'],
'sex': ['girl', 'woman', np.nan, 'girl', 'woman'],
'age': [22, np.nan, 16, np.nan, 27]
}
)
print(df)
print("----subset----")
# subset传的参数是列名的数组
df.dropna(subset=['name', 'age'], inplace=True)
print(df)
可以很直接的看到效果。
pandas.DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)value:用于填充的空值的值。
method: {'backfill', 'bfill', 'pad', 'ffill', None}, default None。定义了填充空值的方法,
pad / ffill表示用前面行/列的值,填充当前行/列的空值,
backfill / bfill表示用后面行/列的值,填充当前行/列的空值。
axis:轴。0或'index',表示按行删除;1或'columns',表示按列删除。
inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操 作,返回值为None。
limit:int,default None。如果method被指定,对于连续的空值,这段连续区域,最多填充前,limit 个空值(如果存在多段连续区域,每段最多填充前 limit 个空值)。如果method未被指定, 在该axis下,最多填充前 limit 个空值(不论空值连续区间是否间断)downcast:dict, default is None,字典中的项为,为类型向下转换规则。
示例代码:替换成10
import pandas as pd
import numpy as np
df = pd.DataFrame(
{'name': ['张丽华', '李诗诗', '王语嫣', '赵飞燕', '阮玲玉'],
'sex': ['girl', 'woman', np.nan, 'girl', 'woman'],
'age': [22, np.nan, np.nan, np.nan, 27]
}
)
print(df)
print("----fillna----")
# 有空的都删掉
df2 = df.fillna(10,
method=None,
axis=1, # axis=0或"index":沿着行的向(纵向); axis=1或"column":是沿着列的方向(横向)
limit=2, # 在没指定method的情况下,沿着axis指定方向上填充的个数不大于limit设定值
inplace=False) # 返回新的DataFrame
print("用10替换后的df2 = \n", df2)
实际效果:

我们很多的时候在处理SQL的时候需要去掉空值,其实和这个操作是一样的,空值是很多的时候没有太大意义,数据清洗的时候就会用到这块了。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
我希望我的UserPrice模型的属性在它们为空或不验证数值时默认为0。这些属性是tax_rate、shipping_cost和price。classCreateUserPrices8,:scale=>2t.decimal:tax_rate,:precision=>8,:scale=>2t.decimal:shipping_cost,:precision=>8,:scale=>2endendend起初,我将所有3列的:default=>0放在表格中,但我不想要这样,因为它已经填充了字段,我想使用占位符。这是我的UserPrice模型:classUserPrice回答before_val
查看Ruby的CSV库的文档,我非常确定这是可能且简单的。我只需要使用Ruby删除CSV文件的前三列,但我没有成功运行它。 最佳答案 csv_table=CSV.read(file_path_in,:headers=>true)csv_table.delete("header_name")csv_table.to_csv#=>ThenewCSVinstringformat检查CSV::Table文档:http://ruby-doc.org/stdlib-1.9.2/libdoc/csv/rdoc/CSV/Table.html
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个具有一些属性的模型:attr1、attr2和attr3。我需要在不执行回调和验证的情况下更新此属性。我找到了update_column方法,但我想同时更新三个属性。我需要这样的东西:update_columns({attr1:val1,attr2:val2,attr3:val3})代替update_column(attr1,val1)update_column(attr2,val2)update_column(attr3,val3) 最佳答案 您可以使用update_columns(attr1:val1,attr2:val2
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我可以得到Infinity和NaNn=9.0/0#=>Infinityn.class#=>Floatm=0/0.0#=>NaNm.class#=>Float但是当我想直接访问Infinity或NaN时:Infinity#=>uninitializedconstantInfinity(NameError)NaN#=>uninitializedconstantNaN(NameError)什么是Infinity和NaN?它们是对象、关键字还是其他东西? 最佳答案 您看到打印为Infinity和NaN的只是Float类的两个特殊实例的字符串
我有这个html标记:我想得到这个:我如何使用Nokogiri做到这一点? 最佳答案 require'nokogiri'doc=Nokogiri::HTML('')您可以通过xpath删除所有属性:doc.xpath('//@*').remove或者,如果您需要做一些更复杂的事情,有时使用以下方法遍历所有元素会更容易:doc.traversedo|node|node.keys.eachdo|attribute|node.deleteattributeendend 关于ruby-Nokog