本文主要讲述了在Windows10环境下,通过blender将pmx格式文件转化为fbx文件的具体步骤
1.下载blender到电脑上
blender下载
建议下载2.83版本,3.0版本以上在修理模型时会丢失材质
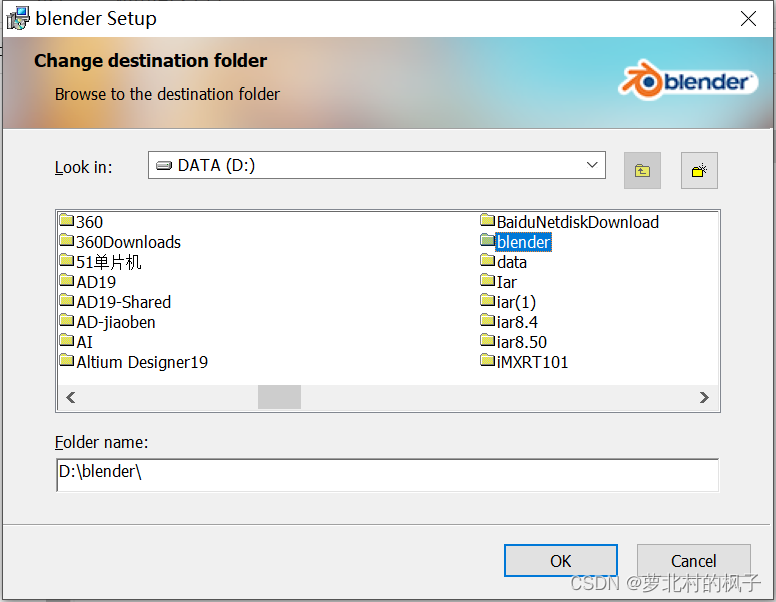
2.下载后双击打开安装文件,除了安装地址(建议安装在D盘)之外,其他均默认即可
1.cats插件下载
要将pmx转为fbx格式,需要我们去安装一个名为cats的插件
Gitee加速地址
下载好的插件是一个名为cats-blender-plugin-master压缩文件,如下图所示,我们需要记住此文件的路径

2.打开blender,可以先切换到中文版(任意)
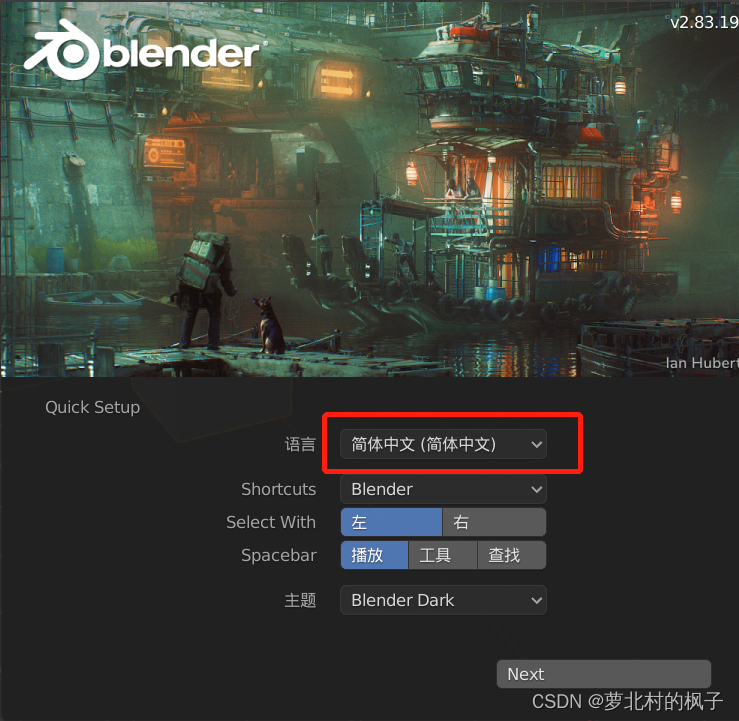
3.依次点击编辑→偏好设置
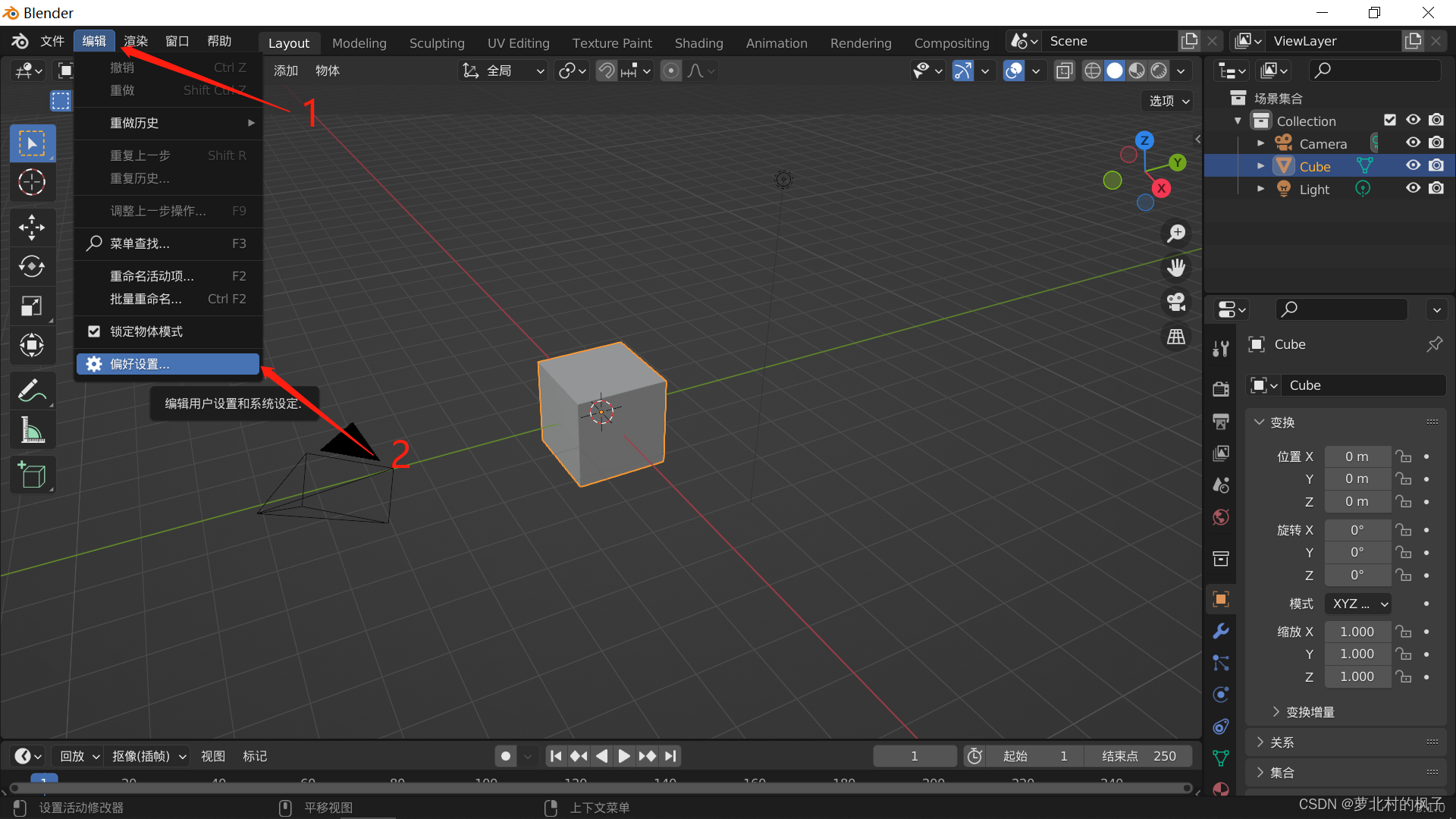
4.依次点击插件→安装
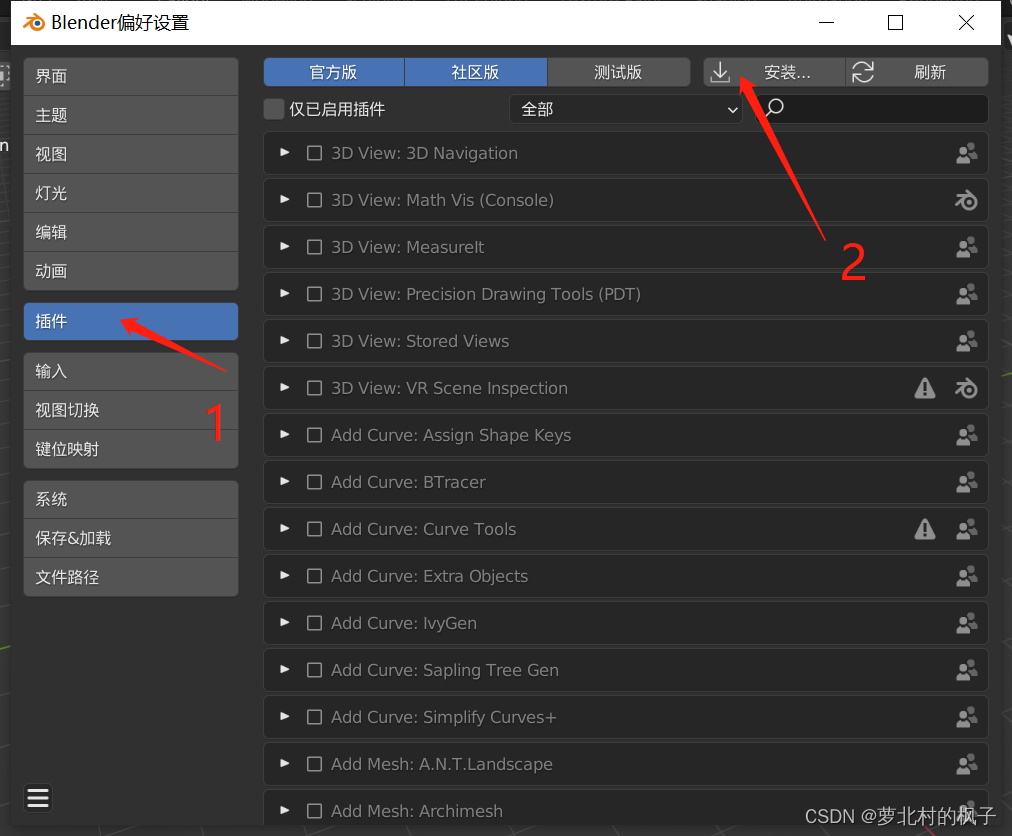
5.选择刚刚下载的cats-blender-plugin-master压缩文件,并点击安装插件
6.安装完成后注意勾选3D View:Cats Blender Plugin,如果没勾选,插件是禁用的
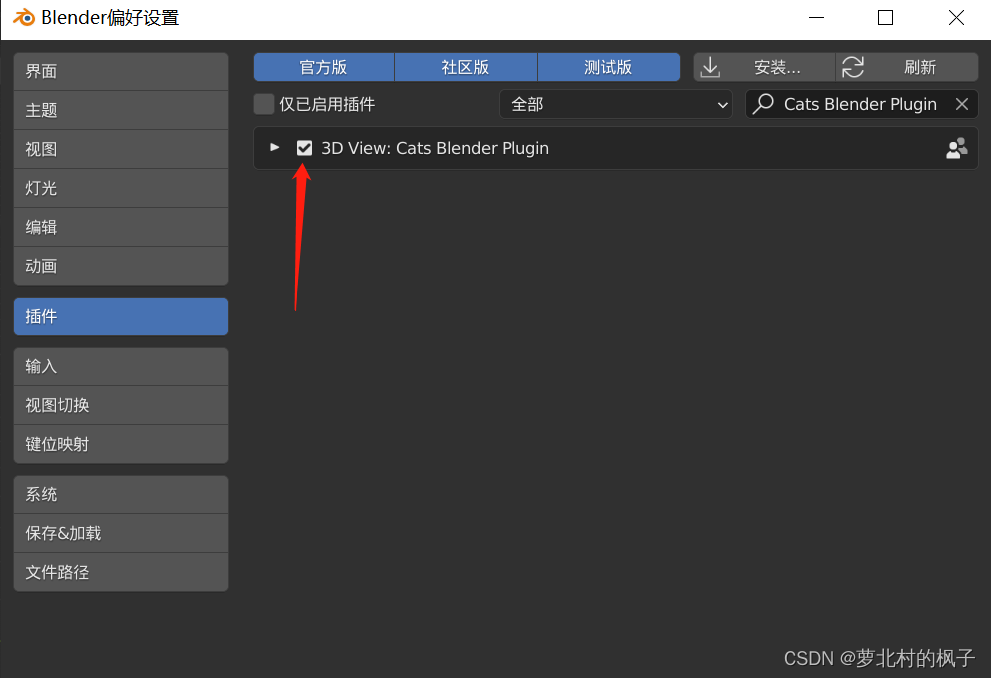
7.此时我们就可以在编辑区的侧边栏看到CATS插件了
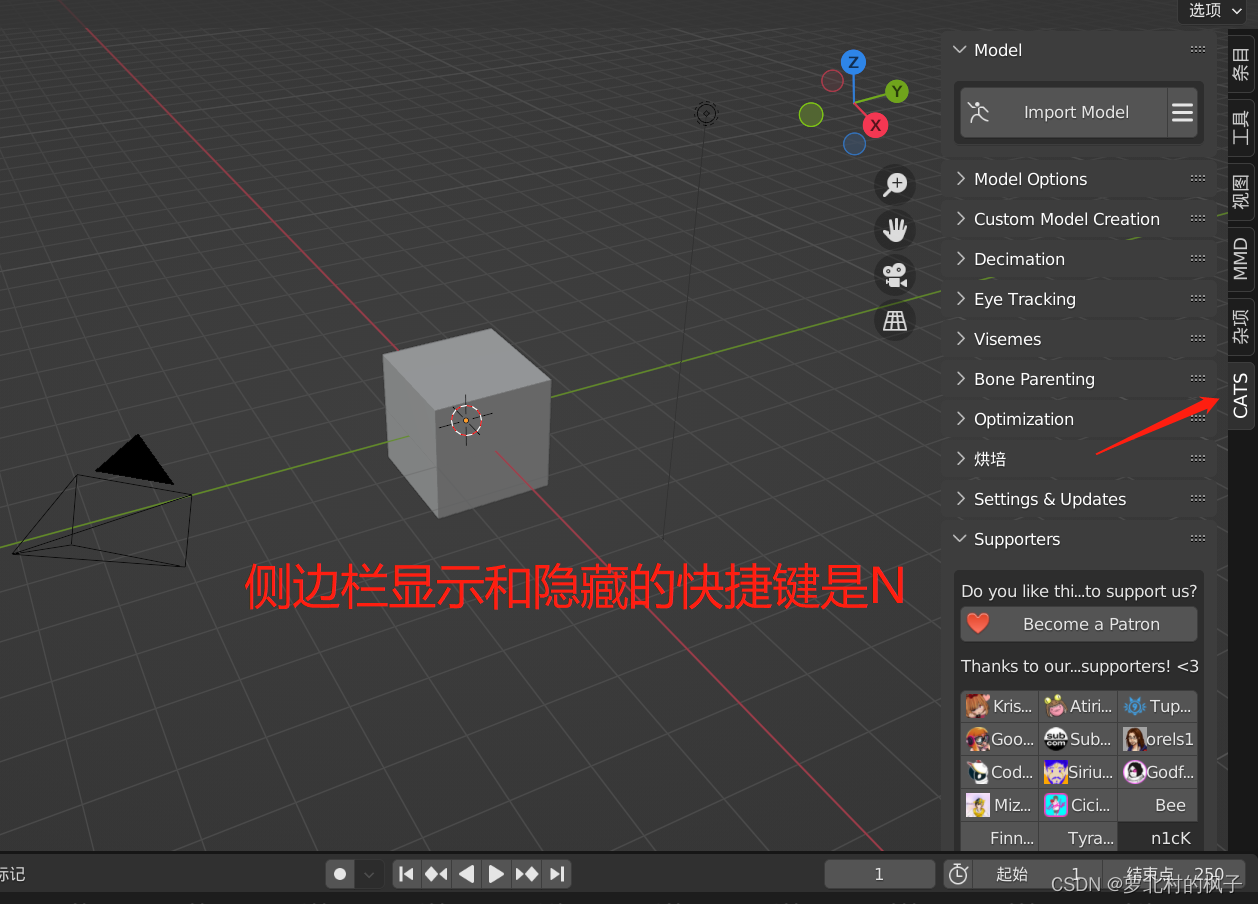
1.点击Import Model
2.找到需要转换的pmx文件,选择后点击Import Any Model
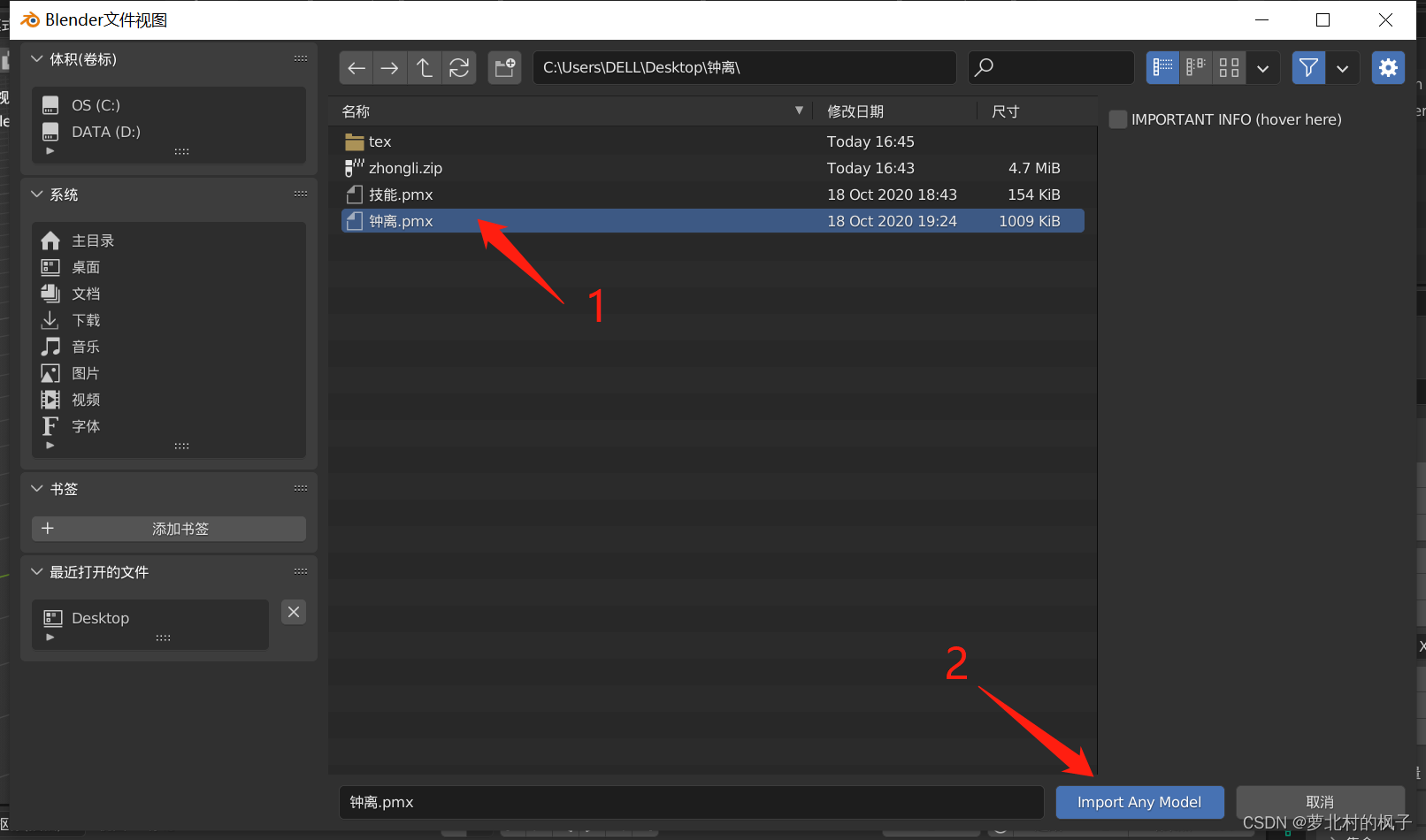
此时导进来的模型并没有包含材质,如下图所示:
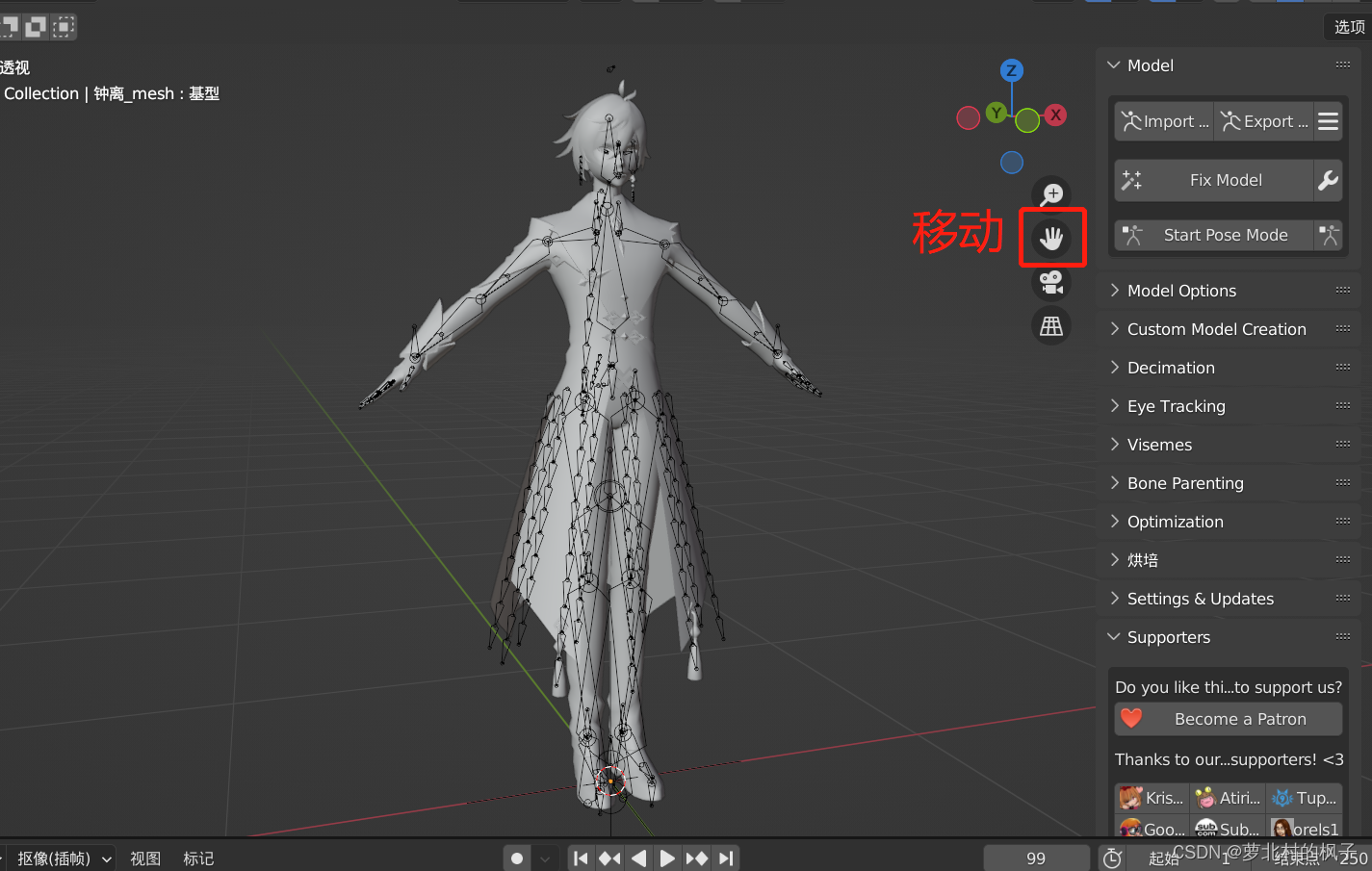
3.依次点击杂项→Shadeless,然后我们就可以看到材质已经被修复了(卡通材质)
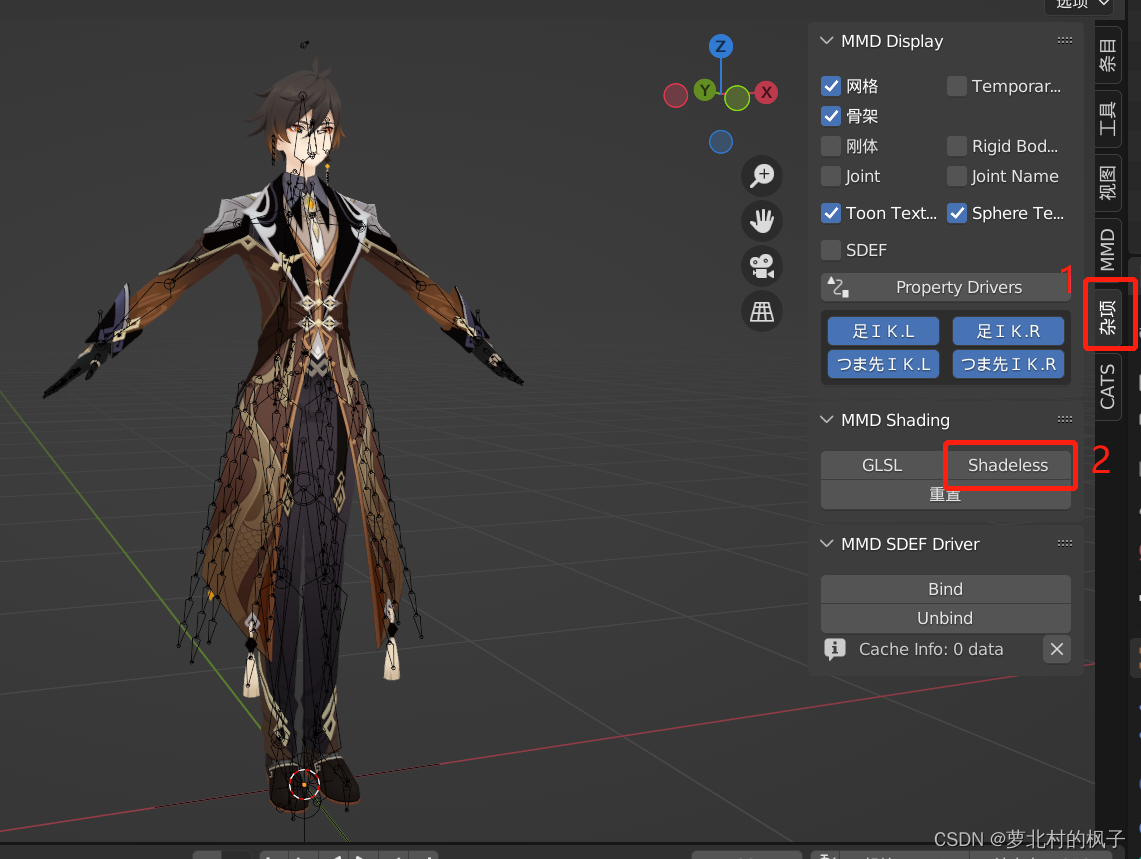
点击关闭右侧骨骼视图,就可以使其不显示,如下图所示:
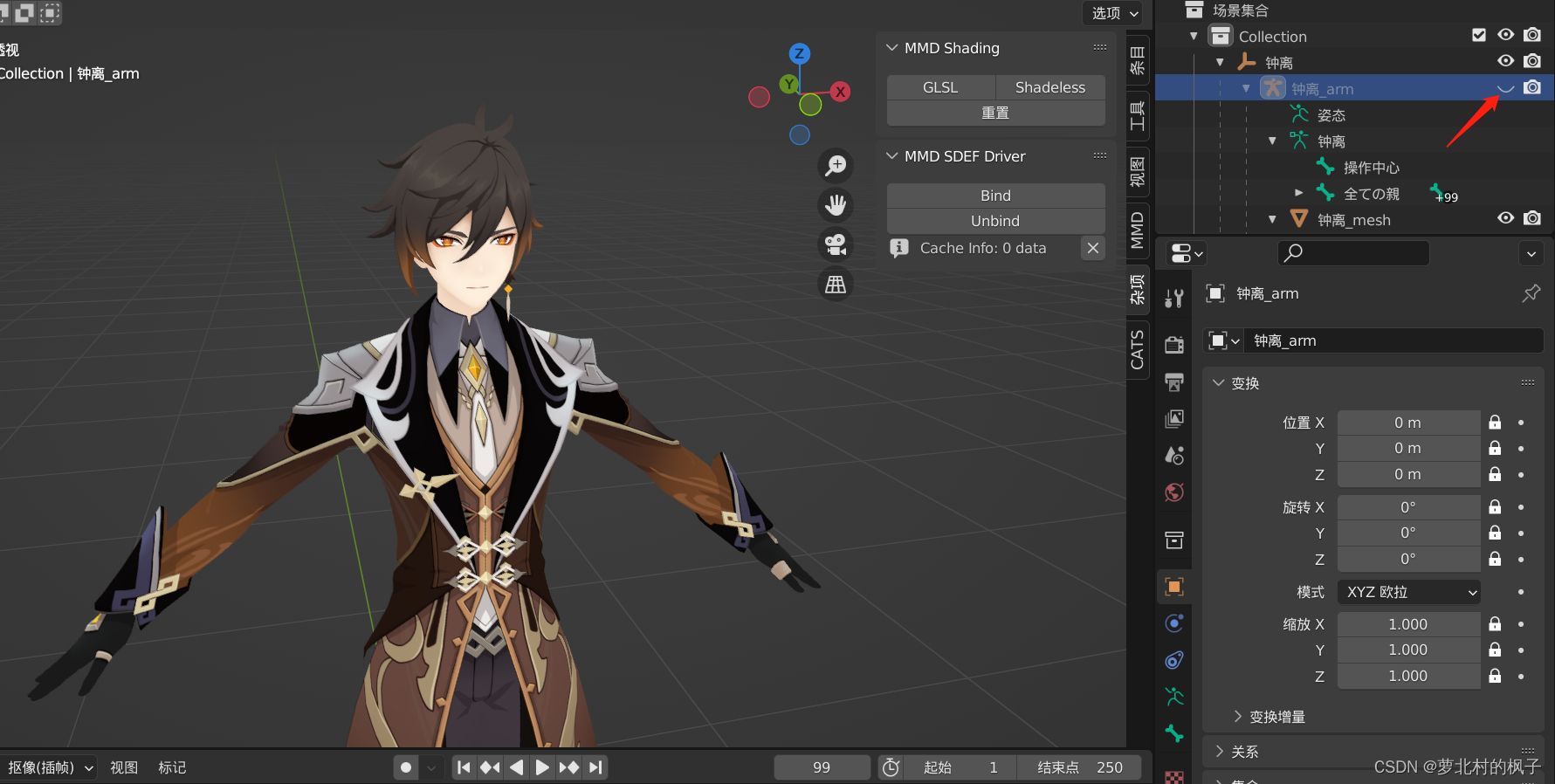
同时我们可以看到,模型的节点命名并不是按照Unity骨骼映射的英文命名
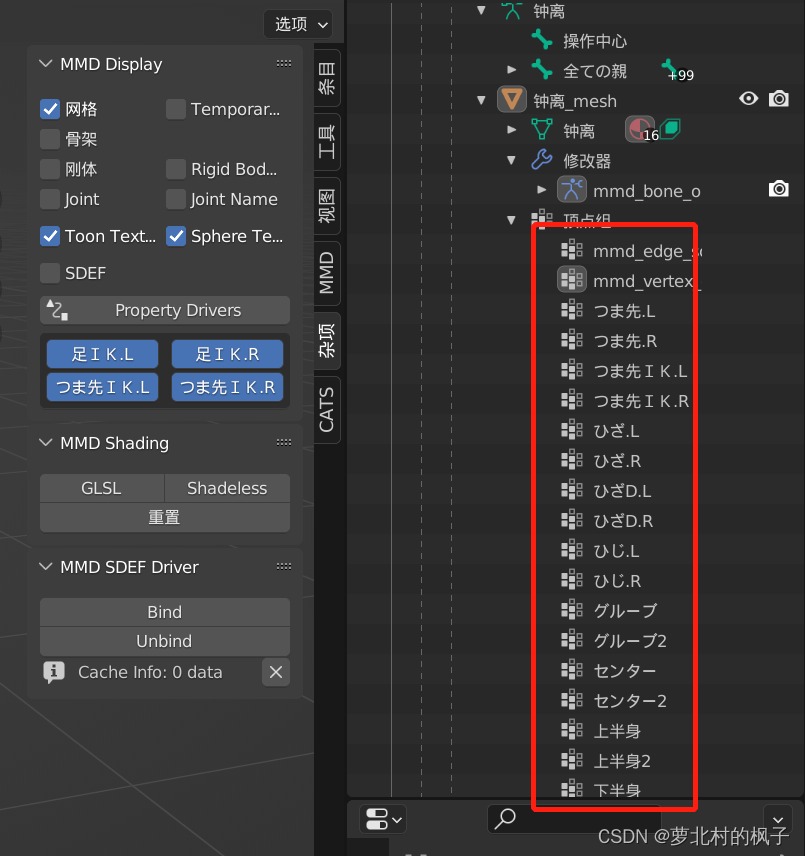
4.点击CATS插件中的Fix Model,即可自动对命名进行修复
(Fix Model还会帮我们删除多余无用的骨骼,将使用同一张贴图的节点合并为一个Mesh并重命名为Body等)
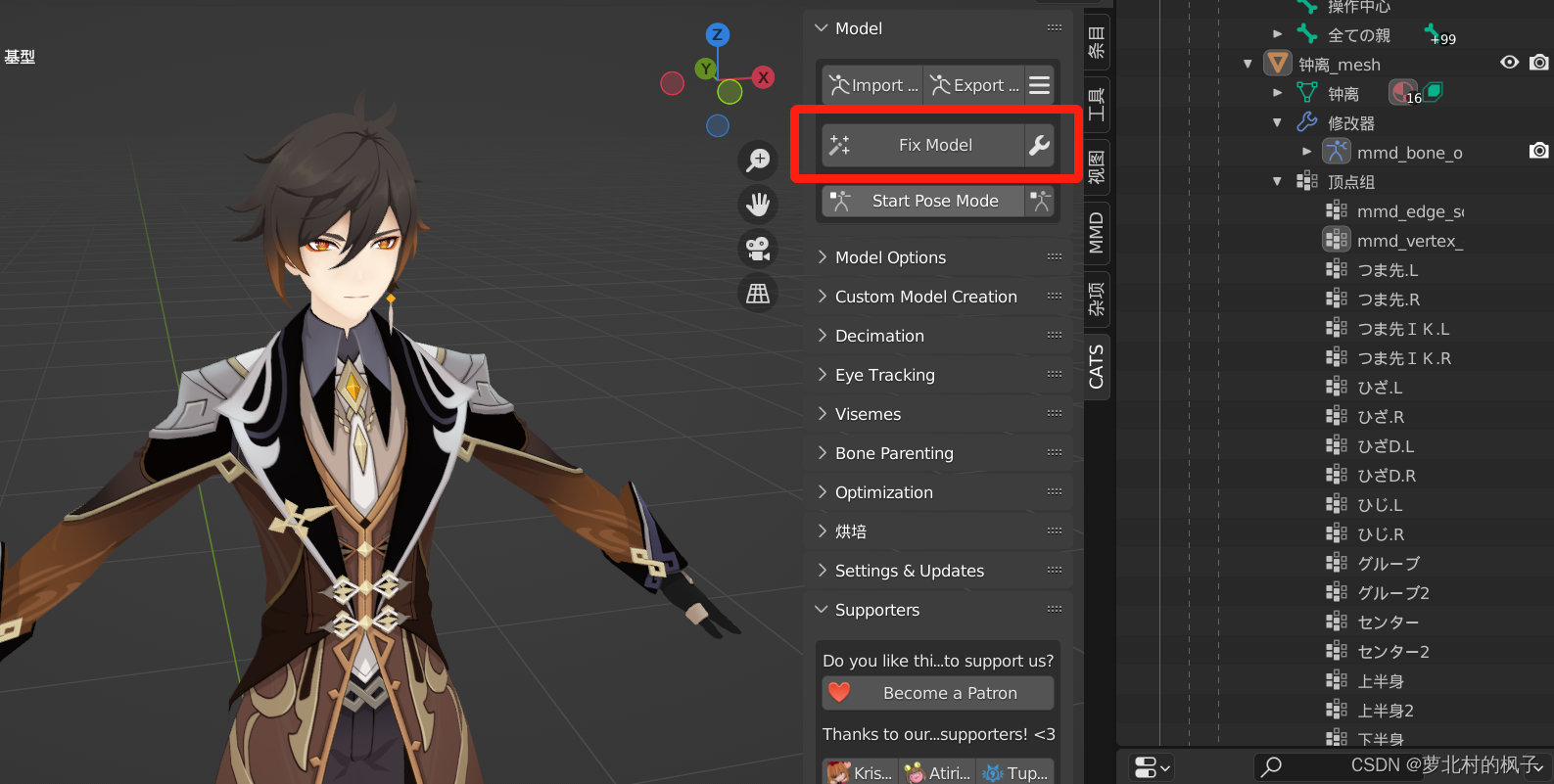
修复完成后如下图所示:
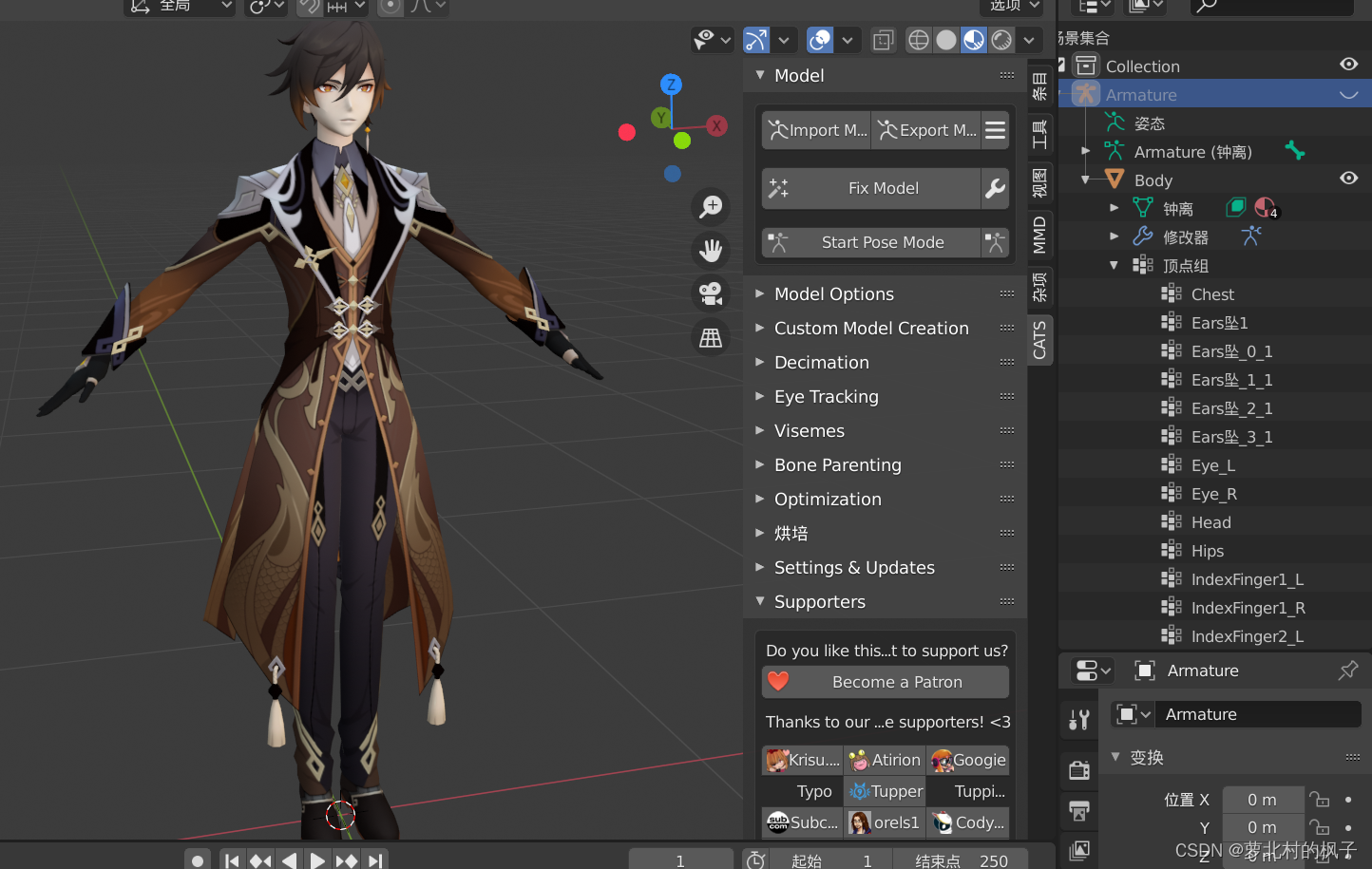
注意:
在此步骤中出现下图所示材质丢失的情况,是因为blender的版本问题(3.0版本造成),这也是在一开始要安装2.83版本的原因
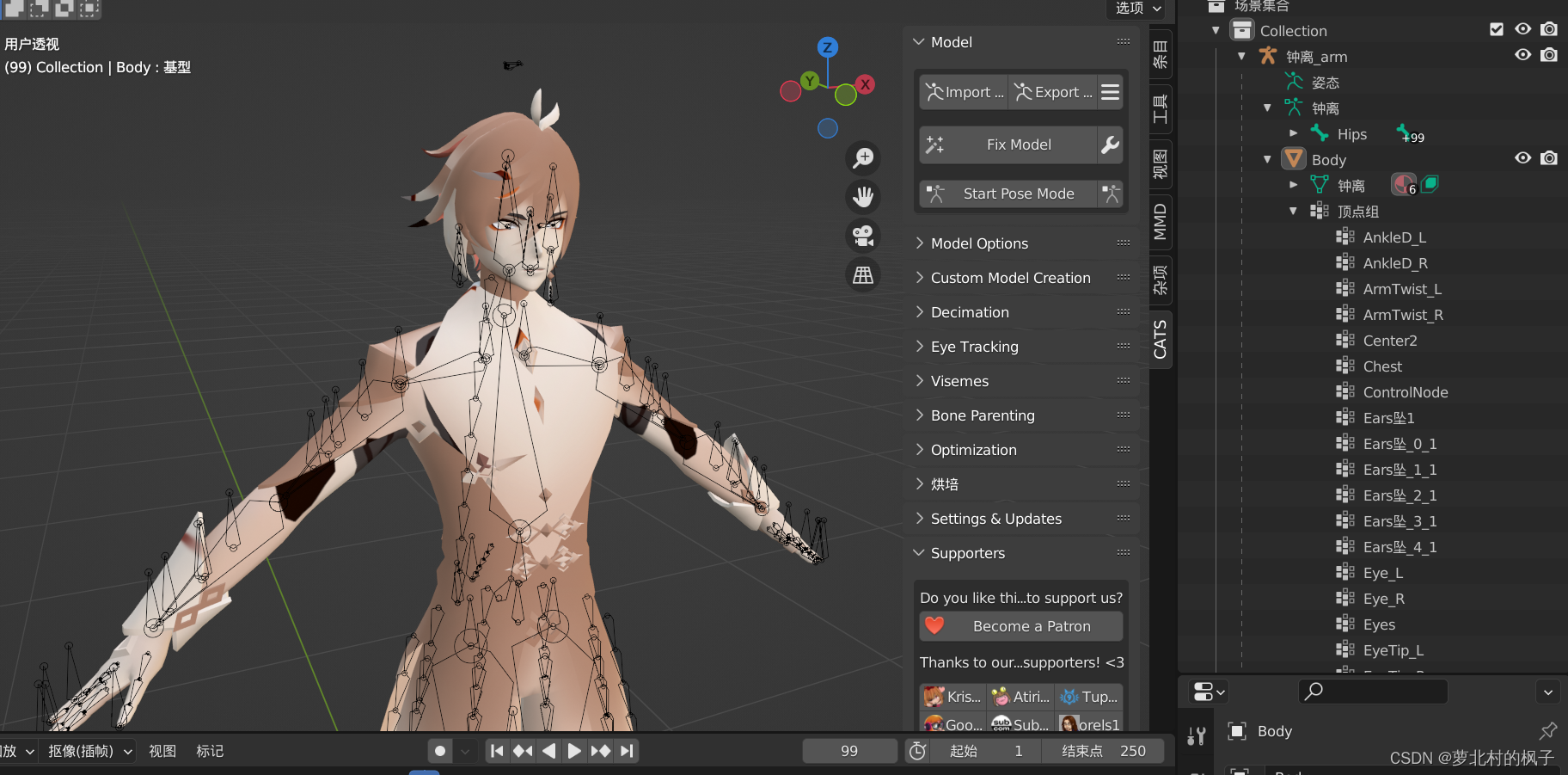
5.点击Export Model
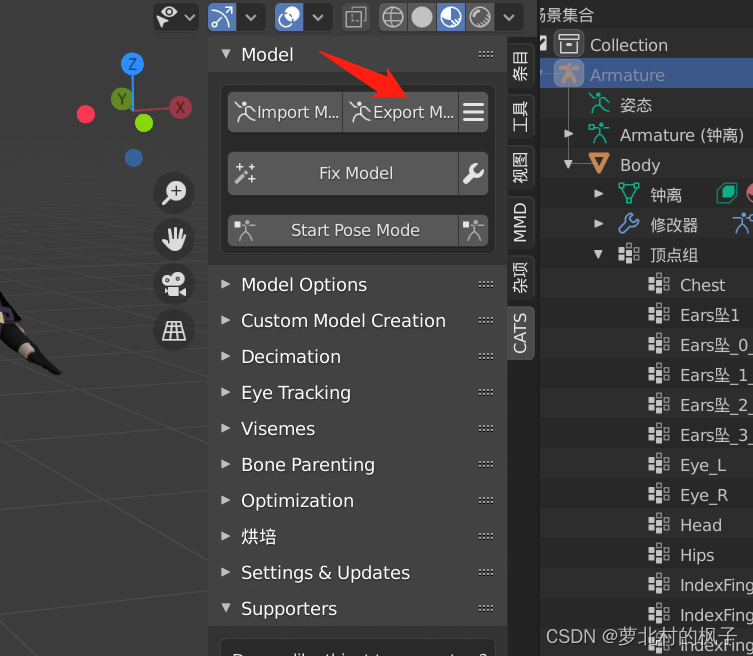
6.选择好文件保存路径并命名之后,点击右下角的导出FBX
7.在文件保存路径就可以看到生成的fbx文件

在unity中打开如下图所示:
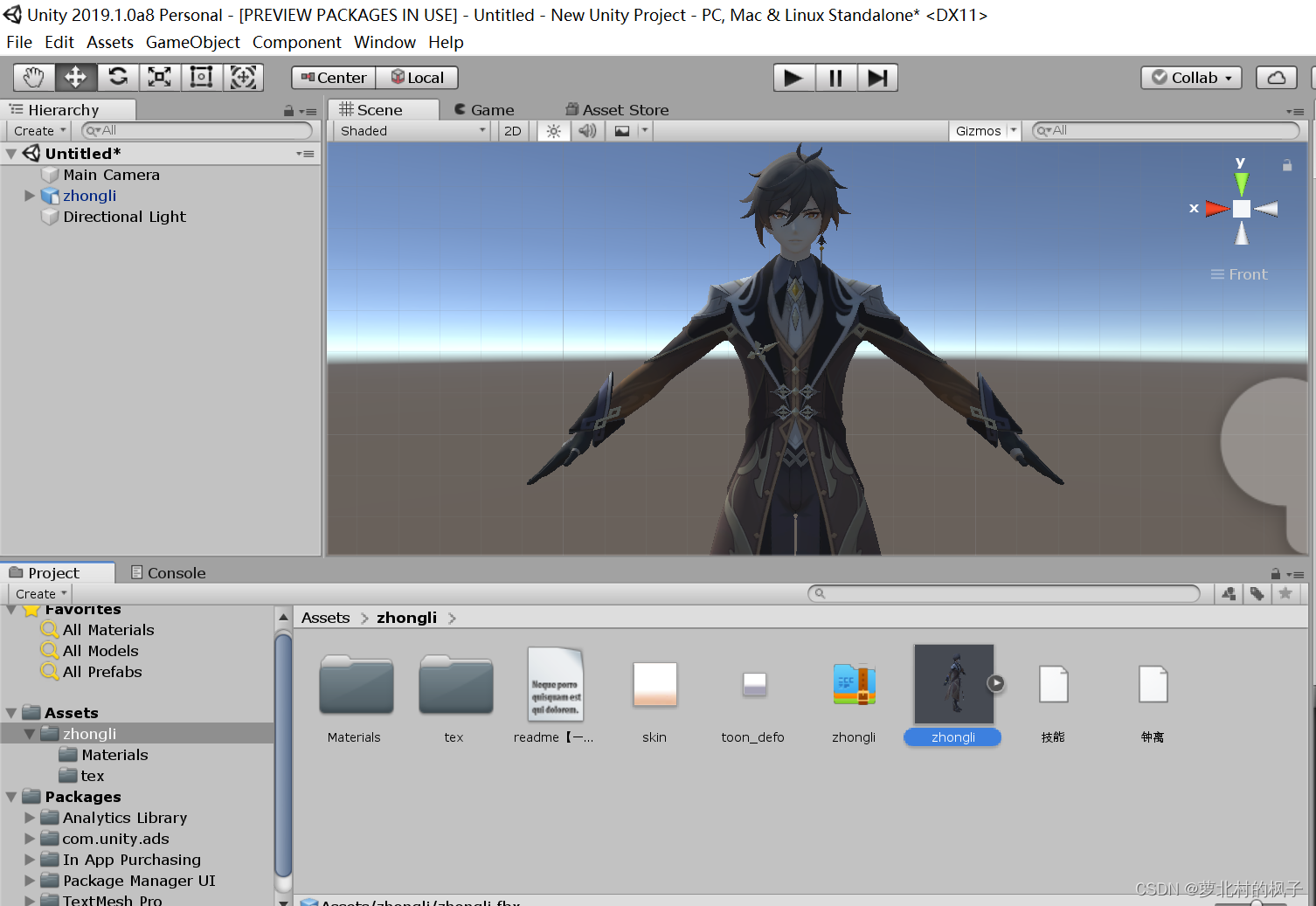
以上是pmx转fbx的具体步骤
我是Cucumber测试的新手。我创建了两个特征文件:events.featurepartner.feature并将我的步骤定义放在step_definitions文件夹中:./step_definitions/events.rbpartner.rbCucumber似乎在所有.rb文件中查找步骤信息。有没有办法限制该功能查看特定的步骤定义文件?我之所以要这样做,是因为即使我使用了--guess标志,我也会遇到不明确的匹配错误。我之所以要这样做,有以下几个原因。我正在测试CMS,并希望在不同的功能中测试每种不同的内容类型(事件和合作伙伴)。事件.特征Feature:AddpartnerA
我在下面有一个步骤定义,它执行我想要它执行的操作,即它根据“PAGES”哈希的“page”元素检查页面的url。Then(/^Ishould(still)?beatthe"(.*)"page$/)do|still,page|BROWSER.url.should==PAGES[page]end步骤定义用于两者我应该在...页面我应该还在...页面但是,我不需要将“still”传递到block中。我只需要它是可选的以匹配步骤但不传递到block中。我该怎么做?谢谢。 最佳答案 您想将“静止”组标记为非捕获。这是通过使用?:启动组来完成的
我们想测试cucumber的步骤定义。我们希望能够检查的一件事是我们期望失败的测试实际上失败了。为此,我们想编写我们知道会失败的场景并将它们添加到我们的测试套件中,但标记或以其他方式表示它们以便当且仅当它们失败时它们“通过”。如何解决这个问题? 最佳答案 您应该测试负面状态。失败的步骤只是通过步骤的倒数。所以做这样的事情:Then/ishouldnotbetrue/dosome_value.should_notbe_trueend这就是我进行失败测试的方式。您还可以捕获异常等,并验证block是否确实抛出该异常lambdadosom
我已经阅读了有关此主题的stackoverflow帖子以及包括APrimeronRubyMethodLookup在内的几篇文章,WhatisthemethodlookuppathinRuby.此外,我查看了RubyMetaprogramming2中的对象模型章节,在几个聊天室中询问,并做了thisredditthread。.除了学习C,我已经尽我所能来解决这个问题。如上述资源所述,这6个位置在接收对象(如fido_instance)的方法查找期间(按顺序)被检查。:fido_instance的单例类IClass(来自扩展模块)IClass(来自前置模块)类IClass(来自包含的模块)
对于体育新闻中文文本的关键字提取,常用的算法包括TF-IDF、TextRank和LDA等。它们的基本步骤如下:1.TF-IDF算法: -将文本进行分词和词性标注处理。-统计每个词在文本中的词频(TF)。-计算每个词在整个语料库中出现的文档频率(DF)和逆文档频率(IDF)。-计算每个词的TF-IDF值,并按照值的大小进行排序,选择排名前几的词作为关键字。2.TextRank算法:-将文本进行分词和词性标注处理。-将分词结果转化成图模型,每个词语为节点,根据词语之间的共现关系建立边。-对图模型进行迭代计算,计算每个节点的PageRank值,表示该节点的重要性。-选择排名前几的节点作为关键字。3.
我的Cucumber找不到步骤定义。文件结构(只有Rails根目录中的specs文件夹)如下所示:->specs->features->main_structure.feature->step_definitions->main_structure_steps.rb这是main_structure.feature:Feature:MainstructureScenario:ViewingtheStructurepageWhenIamonthestructurepage这是main_structure_steps.rb:When(/^Iamonthestructurepage$/)dov
我有一个cucumber步骤:鉴于我已登录我不明白我应该如何将它作为一个步骤定义来实现。谁能指出我正确的方向、教程、博客等。 最佳答案 这是我的做法。Given/^Ihaveone\s+user"([^\"]*)"withemail"([^\"]*)"andpassword"([^\"]*)"$/do|username,email,password|@user=User.new(:email=>email,:username=>username,:password=>password,:password_confirmation=>
我的演示.rb:putsARGV.sizeARGV.eachdo|a|puts"Argument:#{a}"end结果取决于我们如何运行脚本:>demo.rbfoobar0>rubydemo.rbfoobar2Argument:fooArgument:bar为什么会这样?可以用这个做点什么吗?编辑:感谢所有回复!这是我的设置:>assoc.rb.rb=rbFile>ftyperbFilerbFile="c:\ruby-1.8.6\bin\ruby.exe""%1"%*所以看起来是对的。但是我发现了>demo.rbfoobar使用这样的命令行启动进程:"C:\ruby-1.8.7\bin
我想了解使用rspec测试多步骤工作流的习惯用法或最佳实践。我们以“购物车”系统为例,其中的购买流程可能是当用户提交购物篮并且我们没有使用https时,重定向到https当用户提交购物篮并且我们使用https并且没有cookie时,创建并显示一个新的购物篮并发回cookie当用户提交到购物车并且我们使用https并且有一个有效的cookie并且新商品与第一个商品用于不同的产品时,向购物车添加一行并显示这两行当用户提交到购物篮并且我们使用https并且有一个有效的cookie并且新商品与之前的商品相同时,增加该购物篮行的数量并显示这两条线当用户点击购物车页面上的“结帐”并使用https并
我为我们的网络应用程序编写了一个模态幻灯片,它提供了一组文档的导航并公开了这些文档的各种元数据。这是一个具有深奥需求的应用程序的大型组件,因此我认为它的核心场景(作为验收标准提供给我)应该既多又内部一致是很公平的。为了避免对我们的许多场景中的每一个都有一个新的步骤,我已经改编了ahelper将人类可读的术语(例如documentcaption)翻译成选择器:moduleSelectorsHelperdefselector_for(term)caseterm#Lightbox/modal/fancyboxwhen'lightbox''#fancybox-inner'when'closeb