
目录
二、斯坦福基于 Meta 的 LLaMA 7B 模型微调出Alpaca
三、基于TencentPretrain训练中文LLaMA大规模语言模型
新年伊始,火爆全网的 ChatGPT,仿佛开启了第四次工业革命,它像个无所不能的六边形战士,可以聊天、写代码、修改 bug、做表格、写论文、写作业、做翻译、搜索答案等……
自发布以来,ChatGPT 便已摧枯拉朽之势席卷各个行业,不仅 5 天时间便突破百万用户,月活用户更是仅用时 2 个月便突破 1 亿,成为史上增速最快的消费级应用,远超其他知名应用。
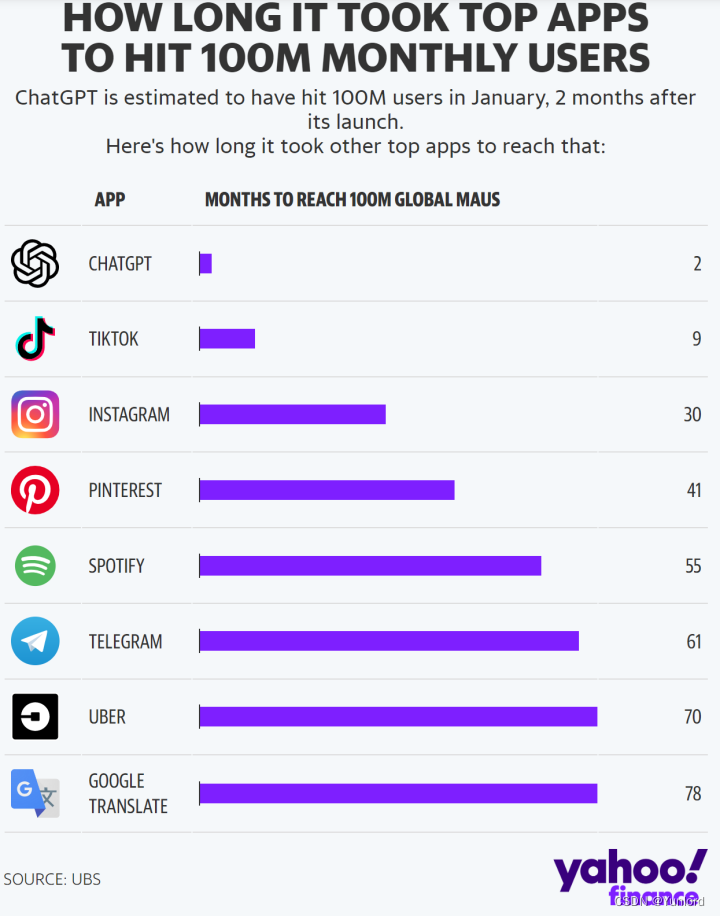
然而由于 OpenAI 没有开源 ChatGPT,如何有效的复现针对中文的 ChatGPT 已成为摆在大家面前的头号难题。
下面我会介绍一些对标ChatGPT的中文开源方案,代码地址也列在每个项目的介绍最上面,希望这些方案能够对大家有所帮助!
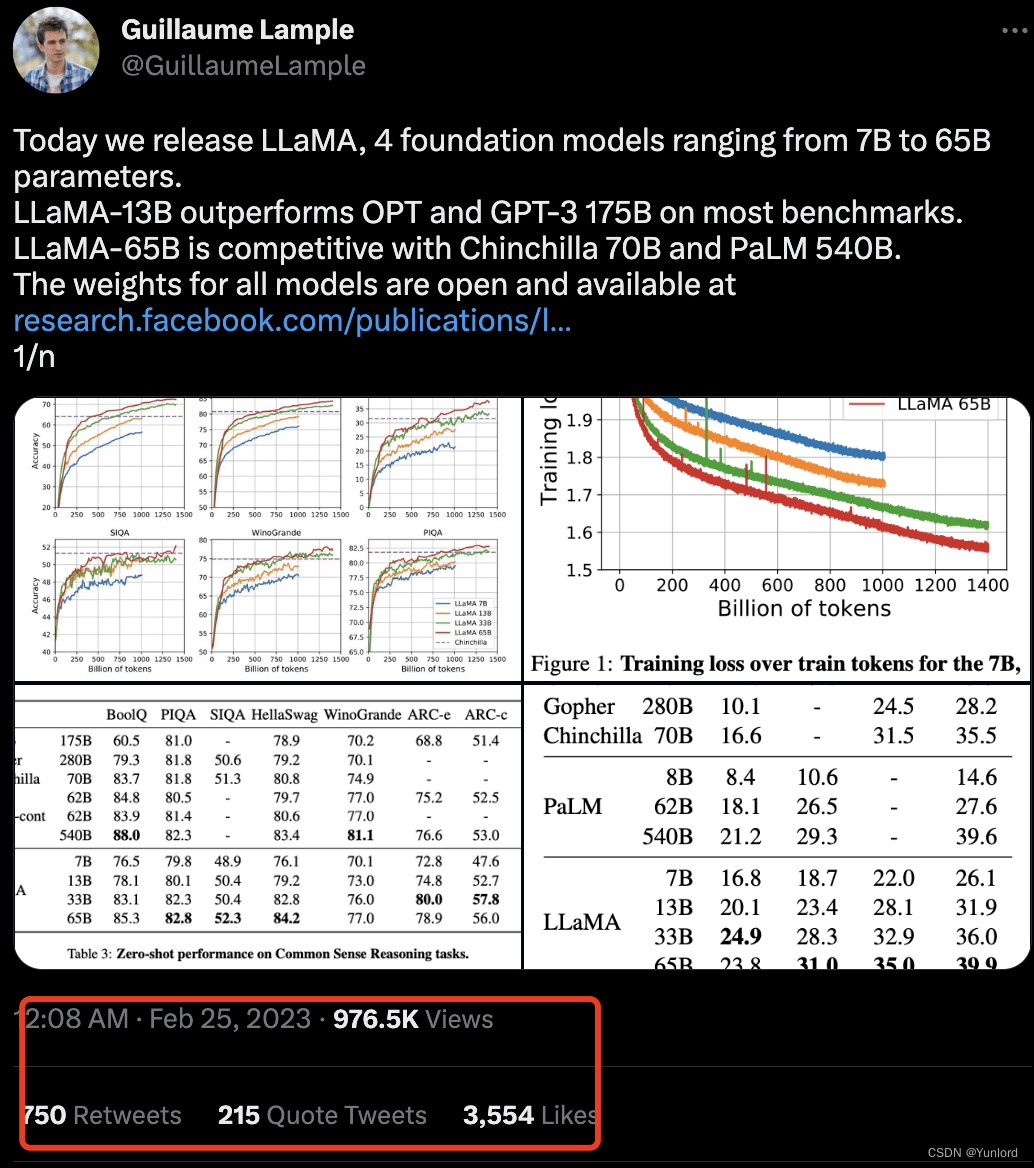
项目地址:GitHub - facebookresearch/llama: Inference code for LLaMA models
Meta一次性发布四种尺寸的大语言模型 LLaMA:7B、13B、33B和65B。还声称, 效果好过GPT,偏向性更低,更重要的是所有尺寸均开源,甚至13B的LLaMA在 单个GPU上就能运行。
Meta发布的LLaMA是 通用大语言模型,原理就不多赘述,和以往的大语言模型一样:将一系列单词作为输入,并预测下一个单词以递归生成文本。
这次,Meta之所以一次给出不同大小的LLaMA模型,论文中给出了这样的解释:
近来的研究表明,对于给定的计算预算,最佳性能不是由最大的模型实现的,而是由 基于更多数据训练的 更小的模型实现的。也就是说,较小的模型规模加上比较大的数据集,获得的性能可能会比更大规模模型的要好很多。一方面,小规模模型需要的计算能力和资源相对来说都会少很多,另一方面,它还能基于更多数据集 训练更多token,更容易针对特定的潜在产品用例进行重新训练和微调。
除了一次性给出四种尺寸的LLaMA,Meta这次还直接开源了这个大语言模型。更重要的是,Meta为了让自己的工作与开源兼容,使用的都是公开的数据。
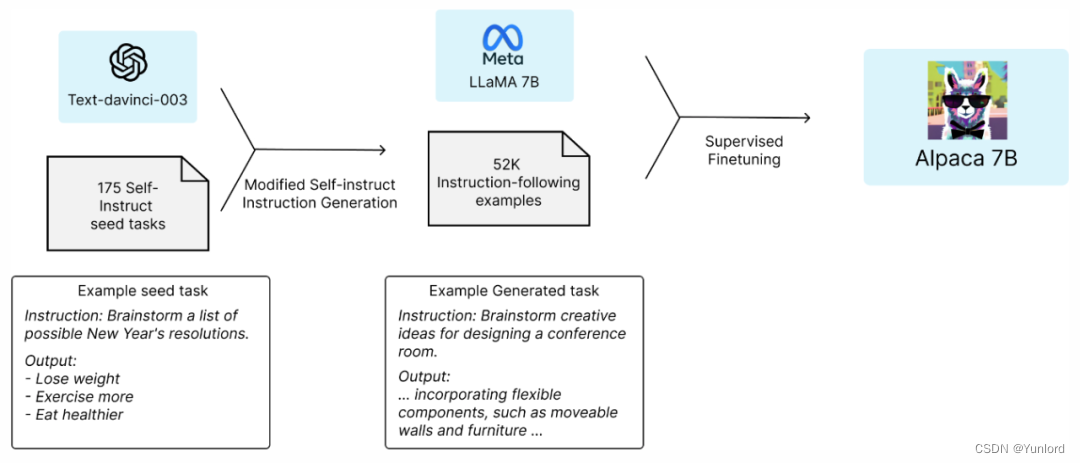
项目地址:https://github.com/tatsu-lab/stanford_alpaca
三月初,斯坦福基于 Meta 的 LLaMA 7B 模型微调出一个新模型 Alpaca。该研究让 OpenAI 的 text-davinci-003 模型以 self-instruct 方式生成 52K 指令遵循(instruction-following)样本,以此作为 Alpaca 的训练数据。研究团队已将训练数据、生成训练数据的代码和超参数开源,后续还将发布模型权重和训练代码。
实验结果表明,Alpaca 的很多行为都与 text-davinci-003 类似。也就是说,只有 7B 参数的轻量级模型 Alpaca 性能可媲美 GPT-3.5 这样的超大规模语言模型。
项目地址:https://github.com/Tencent/TencentPretrain
TencentPretrain 是 UER-py 预训练框架的多模态版本,支持 BERT、GPT、T5、ViT、Dall-E、Speech2Text 等模型,支持文本、图像和语音模态预训练及下游任务。TencentPretrain 基于模块化设计,用户可以通过模块组合的方式构成各种模型,也可以通过复用已有的模块进行少量修改来实现新的模型。例如,LLaMA 的模型架构基于 Transformer 有三项改动:前置 normalization [GPT3]、SwiGLU 激活函数[PaLM]、旋转位置编码[GPTNeo]。
得益于模块化特性,该项目在 TencentPretrain 中基于 GPT2 模型的已有模块,仅添加约 100 行代码就能实现以上三个改动从而训练 LLaMA 模型。
效果如下所示:
| Human | Computer |
| 中国的首都在哪里 | 中国首都是北京。 |
| 北京9月的平均气温是多少 | 秋分,中国北京的平均气温为25.5℃。 |
| 列出一些能用于登山的装备 | To climb mountains, you should bring a lot of > climbing equipment, including a compass, a climbing harness, a helmet, > gloves, good shoes with plenty of ankle support, and a backpack. |
| 介绍一下自然语言处理技术 | Natural language processing (NLP) is the study and design of algorithms that are able to understand and manipulate human language. |
| 帮我解答这个数学题: 6+3*2 | 6+3*2=11 |
| 生成一段代码来创建一个从1到100的列表 | def gen_list(n): """Generate a list from 1 to n""" return [i for i in range(1, n+1)] |
项目地址:https://github.com/LianjiaTech/BELLE
为了提升在中文上的效果,本项目基于Stanford Alpaca优化了中文种子任务,对生成代码进行了一些修改,同时选用BLOOMZ-7B作为基础模型训练得到了一个可以更好支持中文指令的开源模型 - BELLE。同时基于Alpaca的数据收集代码,基于这段代码生成了约100万条中文数据,结合Alpaca的5万条英文数据,在BLOOMZ-7B模型训练得到的checkpoint上传在Hugging Face。
项目包含以下内容:
效果如下所示:
| Human | Computer |
| 小明的爸爸有三个孩子,老大叫王一,老二叫王二,老三叫什么? |
小明
|
| 用python写一个二分查找的代码 | def binary_search(arr, target): low = 0 high = len(arr) - 1 while (low <= high): mid = low + high // 2 if arr[mid] == target: return mid elif target < arr[mid]: low = mid + 1 else: high = mid - 1 return -1 |
| 今天天气怎么样,把这句话翻译成英语 | What's the weather like today? |
| 怎么让自己精力充沛,列5点建议 | 以下是一些可以让你保持精力充沛的建议: 1. 睡眠充足。确保每天晚上得到充足的睡眠时间。 2. 多运动。进行适度的有氧运动,如慢跑、游泳等,可以帮助你提高能量和耐力。 3. 吃健康食品。选择富含蛋白质的食物,如鸡肉、鱼肉和鸡蛋,以及新鲜的水果和蔬菜。 4. 减少咖啡因的摄入量。尽量避免在白天喝含咖啡因的饮料或吃含有咖啡因的食物。 5. 放松身心。尝试冥想、瑜伽或其他形式的放松活动来减轻压力和焦虑感。 |
| 推荐几本金庸的武侠小说 | 以下是三本我最喜欢的金庸武侠小说的推荐: 1. 《射雕英雄传》 - 一部充满智慧和机智的小说,讲述了郭靖、黄蓉夫妇的故事。 2. 《神雕侠侣》- 这是一部浪漫而感人的故事,讲述了一对情侣小龙女与杨过之间的爱情故事。 3. 《倚天屠龙记》- 这是一个宏伟而壮观的故事,描绘了明教领袖张无忌如何成为一位出色的英雄 |
项目地址:https://github.com/THUDM/ChatGLM-6B
据官方介绍,ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
效果如下所示:

项目地址:https://github.com/LC1332/Chinese-alpaca-lora
这个模型是在Meta开源的LLaMA基础上,参考Alpaca和Alpaca-LoRA两个项目,对中文进行了训练,0.1版本的模型取得了基础的中文会话能力。
效果如下所示:
| Human | Computer |
| 中国的首都在哪里? | 中国的首都是北京。 |
| 麦当劳是哪个国家的? | 美国 |
| 2017年美国总统是谁? | 特朗普 |
| 华中师范大学在哪里? | 华中师范大学在武汉市。 |
ChatGPT掀起的新一轮人工智能狂欢下,隐藏在背后的“大模型”正进入越来越多开发者的视野。正如有一句话说的那样:数据是燃料、模型是引擎、算力是加速器。ChatGPT的出现,恰如其分地诠释了数据、模型和算力的“化学反应”。
如何在垂直领域做出更有针对性模型也是未来的发展方向之一,尤其是算力以及数据不那么充足的情况下。
大家如果有什么好的想法和项目,也欢迎在评论区里留言评论!
参考:
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
我有一个应用程序正在从Ruby迁移到JRuby(由于需要通过Java提供更好的Web服务安全支持)。我使用的gem之一是daemons创建后台作业。问题在于它使用fork+exec来创建后台进程,但这对JRuby来说是禁忌。那么-是否有用于创建后台作业的替代gem/wrapper?我目前的想法是只从shell脚本调用rake并让rake任务永远运行......提前致谢,克里斯。更新我们目前正在使用几个与Java线程相关的包装器,即https://github.com/jmettraux/rufus-scheduler和https://github.com/philostler/acts
2022年底,OpenAI的预训练模型ChatGPT给人工智能领域的爱好者和研究人员留下了深刻的印象和启发,他展现的惊人能力将人工智能的研究和应用热度推向高潮,网上也充斥着和ChatGPT的各种聊天,他可以作诗、写小说、写代码、讨论疫情问题等。下面就是一些他的神回复:人命关天的坑: 写歌,留给词作者的机会不多了。。。 回答人类怎么样面对人工智能: 什么是ChatGPT?借用网上的一段介绍,ChatGPT是由人工智能研究实验室OpenAI在2022年11月30日发布的全新聊天机器人模型,一款人工智能技术驱动的自然语言处理工具。它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动
目录ChatGPT简介技术原理应用未来发展ChatGPT的10 种用法ChatGPT简介ChatGPT是一种基于深度学习的大型语言模型,由OpenAI公司开发。技术原理GPT是GenerativePre-trainedTransformer的缩写,意为生成式预训练变压器。它的技术原理是使用了一个基于注意力机制的变压器(Trans
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。要求我们推荐或查找工具、库或最喜欢的场外资源的问题对于StackOverflow来说是偏离主题的,因为它们往往会吸引自以为是的答案和垃圾邮件。相反,describetheproblem以及迄今为止为解决该问题所做的工作。关闭9年前。Improvethisquestion我想知道是否有人知道Ruby的rubyzip替代品,它可以处理各种格式,特别是zip/rar/7z?我知道libarchive,但它对我的目的来说并不完整(它是一个很好的gem)。(澄清一下,libarchive-对我不起作用-因为
我爱Sanitize.这是一个了不起的实用程序。我遇到的唯一问题是,它需要永远准备一个开发环境,因为它使用Nokogiri,这对编译时间来说是一种痛苦。是否有任何程序可以在不使用Nokogiri的情况下执行Sanitize的操作(如果没有别的,只是温和地执行它的操作)?这将以指数方式提供帮助! 最佳答案 Rails有自己的SanitizeHelper。根据http://api.rubyonrails.org/classes/ActionView/Helpers/SanitizeHelper.html,它将Thissanitizehe
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭6年前。Improvethisquestion是否有任何用Ruby或Python编写的生产就绪的开源Twitter克隆?我对功能丰富的实现更感兴趣,而不仅仅是简单的Twitter消息(例如:API、FBconnect、通知等)谢谢!
我尝试每天在我的Rails应用程序中自动记录一些数据。我想知道是否有人知道一个好的解决方案?我找到了https://github.com/javan/whenever,但我想确保在选择之前了解所有选项。谢谢!艾略特 最佳答案 我真的很喜欢whenever-这是一个很棒的Gem,我已经在生产中使用了它。关于它还有一个很好的Railscasts插曲:http://railscasts.com/episodes/164-cron-in-ruby 关于ruby-on-rails-rails3中c
文章目录写在前面1、下载与安装(windows)1.1、idea中配置gradle2、基础知识(Gradle6.9为例)2.1、Gradle脚本语法2.1.1、dependsOn2.1.2、创建动态任务2.1.3、增加任务行为2.1.4、参数2.1.5、Ant任务2.1.6、方法2.1.7、默认任务2.1.6、依赖任务的不同输出3、java项目中使用3.1、在已有项目中构建gradle3.2、在新建项目时构建gradle(idea)3.3、gradle项目目录结构3.4、build.gradle3.4.1、plugins3.4.2、repositories3.4.3、dependencies3