
Bug一词的原意是虫子,而在电脑系统或程序中隐藏着的一些未被发现的缺陷或问题,人们也叫它"bug"。这是为什么呢?这就要追溯到一个程序员与飞蛾的故事了。
Bug的创始人格蕾丝·赫柏(Grace Murray Hopper),是一位为美国海军工作的电脑专家,也是最早将人类语言融入到电脑程序的人之一。而代表电脑程序出错的“bug” 这名字,正是由赫柏所取的。1947年9月9日,赫柏对Harvard Mark II设置好17000个继电器进行编程后,技术人员正在进行整机运行时,它突然停止了工作。于是他们爬上去找原因,发现这台巨大的计算机内部一组继电器的触点之间有一只飞蛾,这显然是由于飞蛾受光和热的吸引,飞到了触点上,然后被高电压击死。所以在报告中,赫柏用胶条贴上飞蛾,并把“bug”来表示“一个在电脑程序里的错误”,“Bug”这个说法一直沿用到今天。

格蕾丝·赫柏的报告
所有发生的事情都一定有迹可循,如果问心无愧,就不需要掩盖也就没有迹象了,如果问心有愧,就必然需要掩盖,那就一定会有迹象,迹象越多就越容易顺藤而上,这就是 推理的途径。顺着这条途径顺流而下就是犯罪,逆流而上,就是真相。
而我们程序员就好比一个侦探,一个用来寻找bug,修改bug的侦探。人们将这个过程叫做"Debug"(中文称作"调试"),意即"捉虫子"或"杀虫子"。每一次调试都是尝试破案的过程。
调试(英语:Debugging / Debug),又称除错,是发现和减少计算机程序或电子仪器设备中程序错误的一个过程。
发现程序错误的存在
以隔离、消除等方式对错误进行定位
确定错误产生的原因
提出纠正错误的解决办法
对程序错误予以改正,重新测试
本文将详细介绍在windows系统的 VS环境下的调试过程。
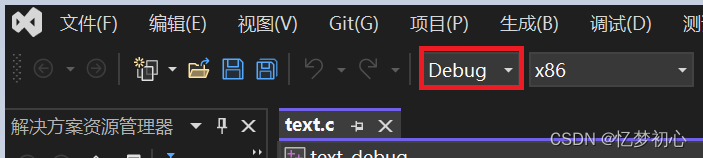
在VS中,我们会发现我们的程序可以在两个环境下运行,这两个环境就是Debug版本和Release版本,它们二者有何区别呢?
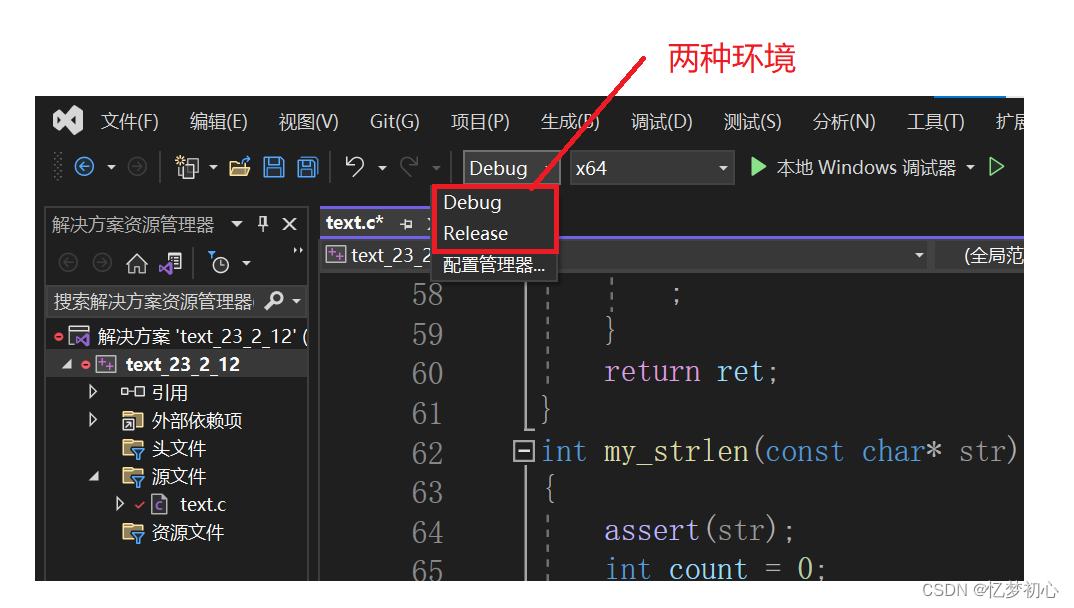
VS中的Debug与Release
Debug 通常称为 调试版本,它包含调试信息,并且不作任何优化, 便于程序员调试程序。
Release 称为 发布版本,它往往是 进行了各种优化,使得程序在代码大小和运行速度上都是最优的, 以便用户很好地使用。
我们可以分别在两种环境下编译代码生成对应的可执行程序如下:
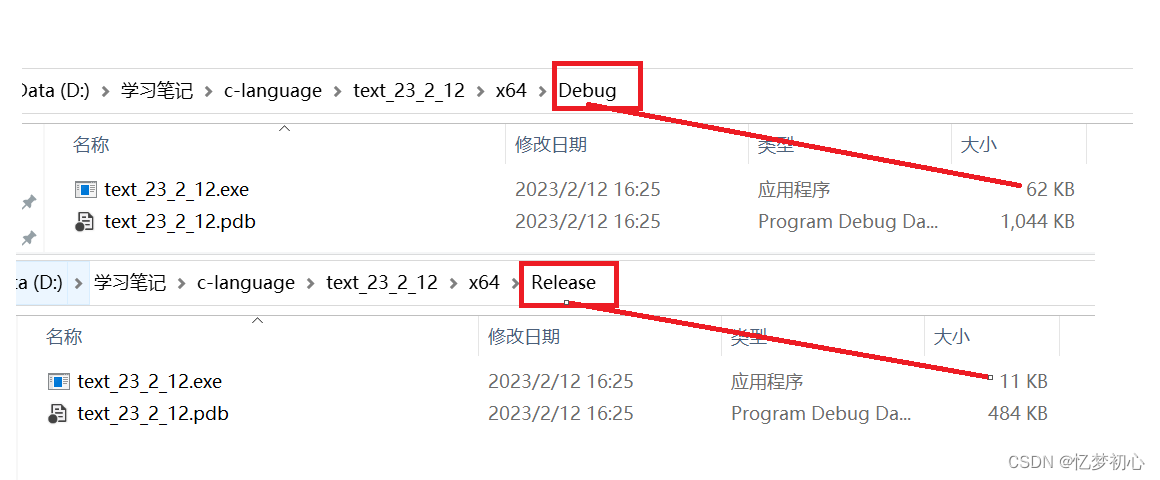
显然,Release版本的可执行文件比Debug版本的小很多,说明编译器对其作了优化。
因此,我们日常所说的调试是在Debug版本的环境下进行的,这是因为Release版本在不加以配置的情况下其调试信息会被编译器优化,对于程序员来说,调试基本都是在Debug环境下运行(本文下面的调试也都是在Debug环境下进行调试)。而对于测试人员来说,由于要站在用户的角度上来测试程序是否能正常使用,因此测试是在Release版本的环境下进行的。
👉但不排除编写的程序在Debug环境下没有问题,在Release版本出现问题的情况。有些问题在Release环境下才会浮现,这时我们就需要对Release版本进行配置,进行"调试"排查错误。我们有以下几种方法:
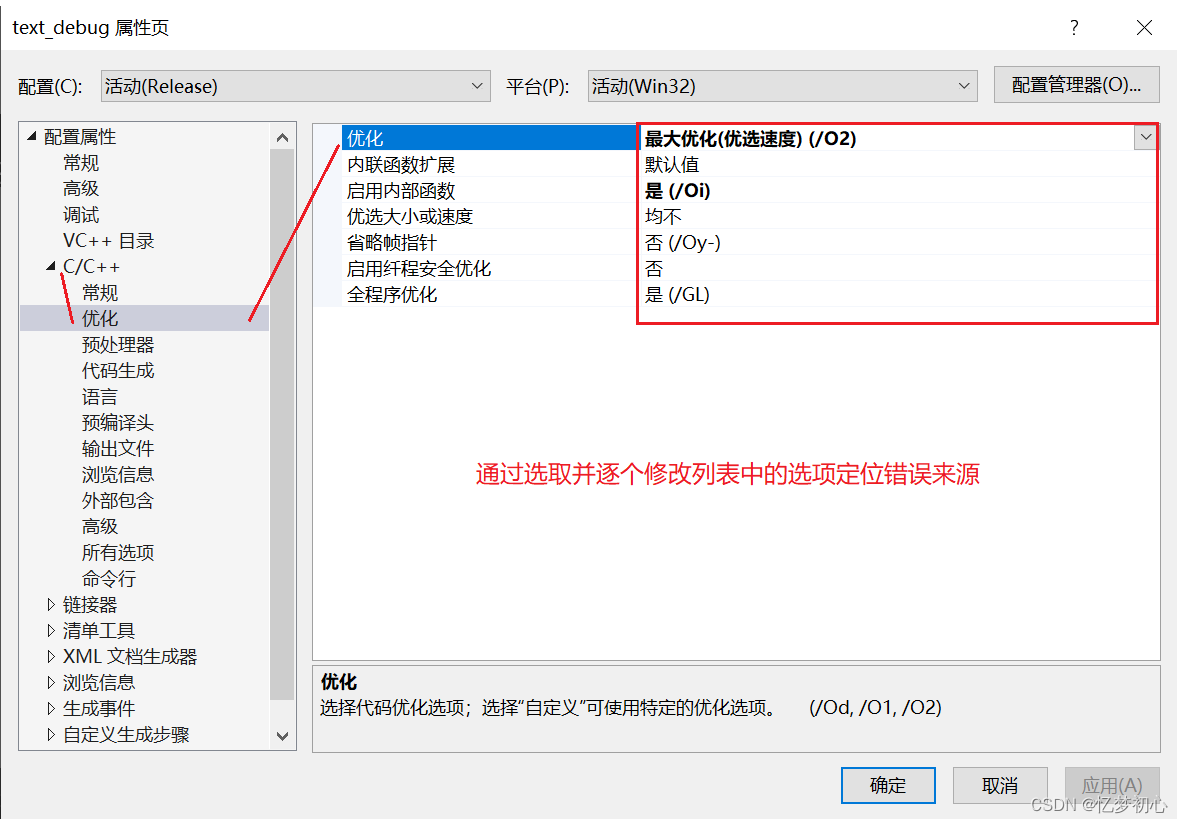
项目 -> 属性 -> C/C++ -> 优化 -> 禁用优化,通过禁用优化使其能生成调试信息进行排错,如下:
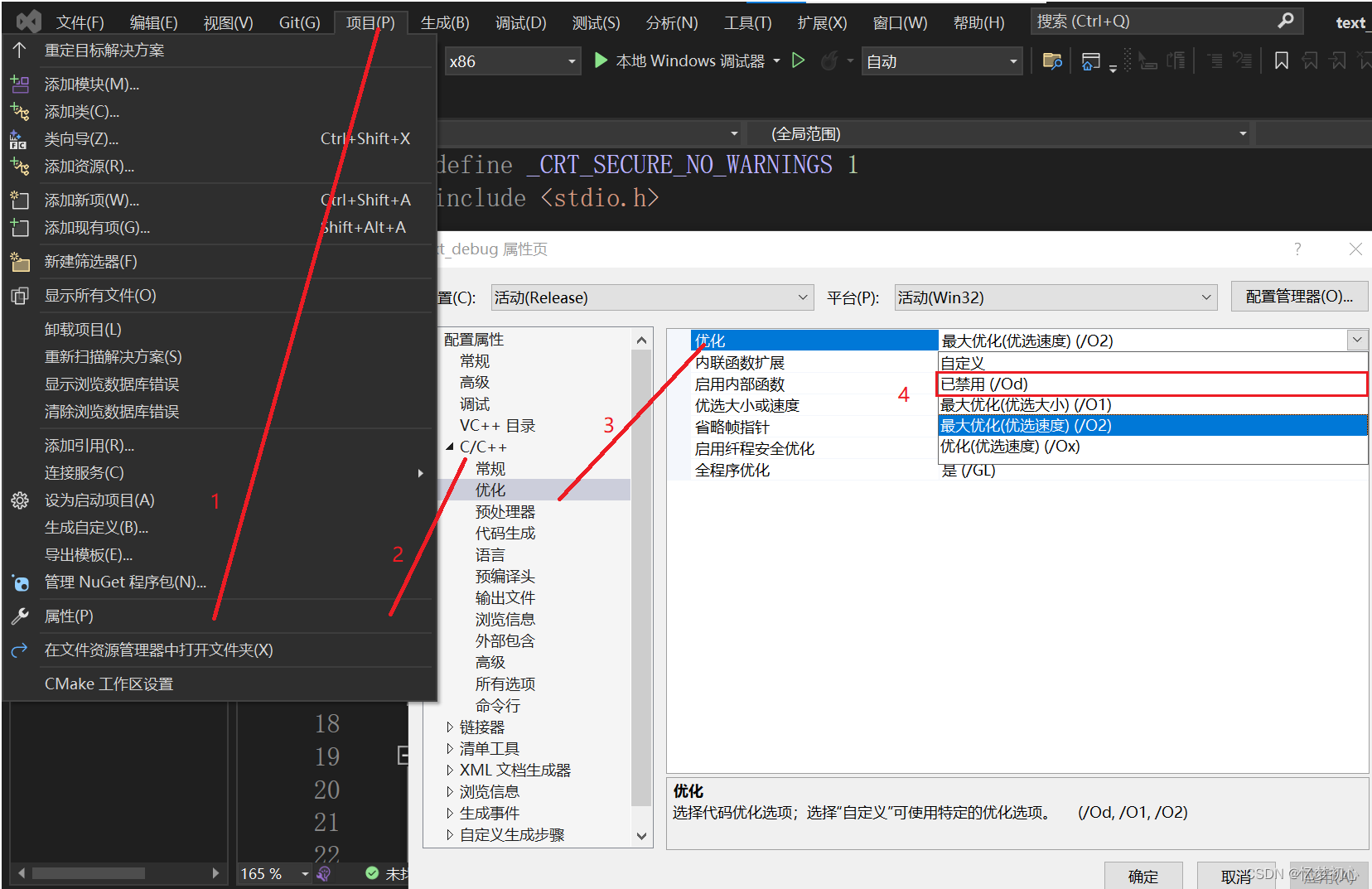
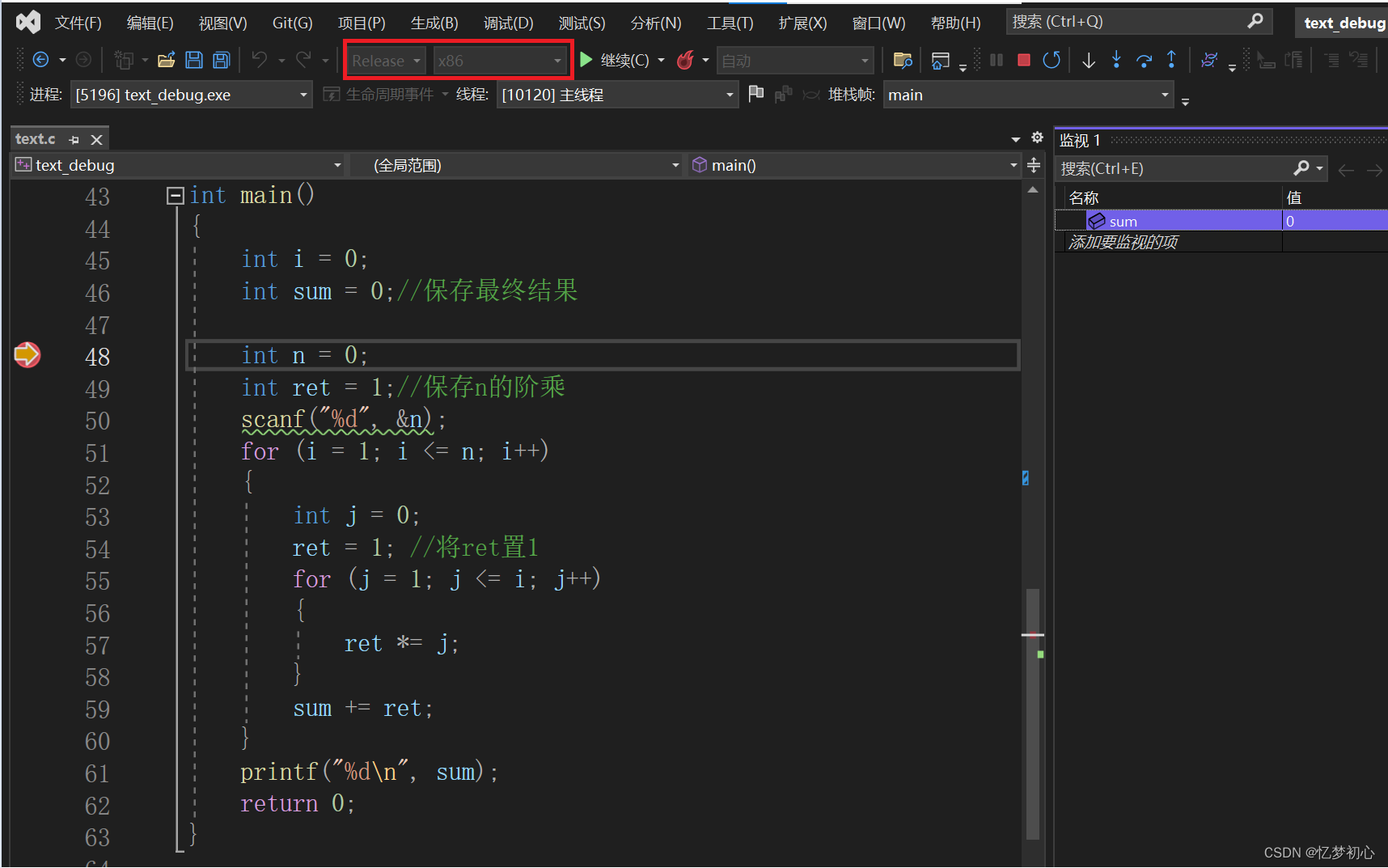
在项目 -> 属性 -> C/C++ -> 优化界面处,将选项逐个改为对应的Debug选项,如/O2改为/O1、/Oy改为/Oy-或者将运行时间优化改为程序大小优化。注意的是,一般一次只改一个选项,通过观察改哪个选项时错误消失来锁定该选项相关的错误,针对性地查找。个人较推荐这种方法。
话又说回来,Release版本下编译器到底可能会做什么优化呢?请看如下代码:
#include <stdio.h>
int main()
{
int i = 0;
int arr[10] = {0};
for(i=0; i<=12; i++)
{
arr[i] = 0;
printf("hehe\n");
}
return 0;
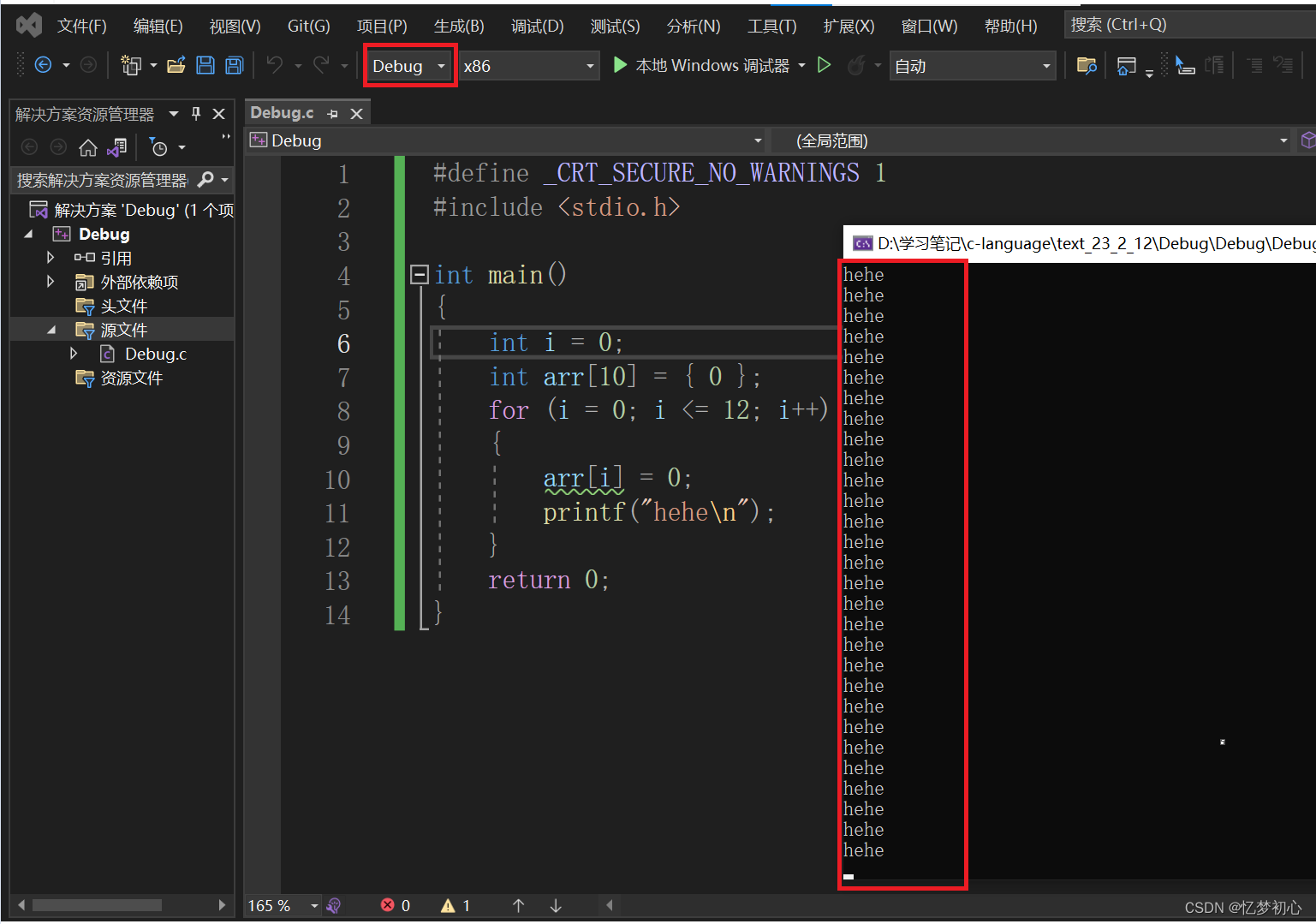
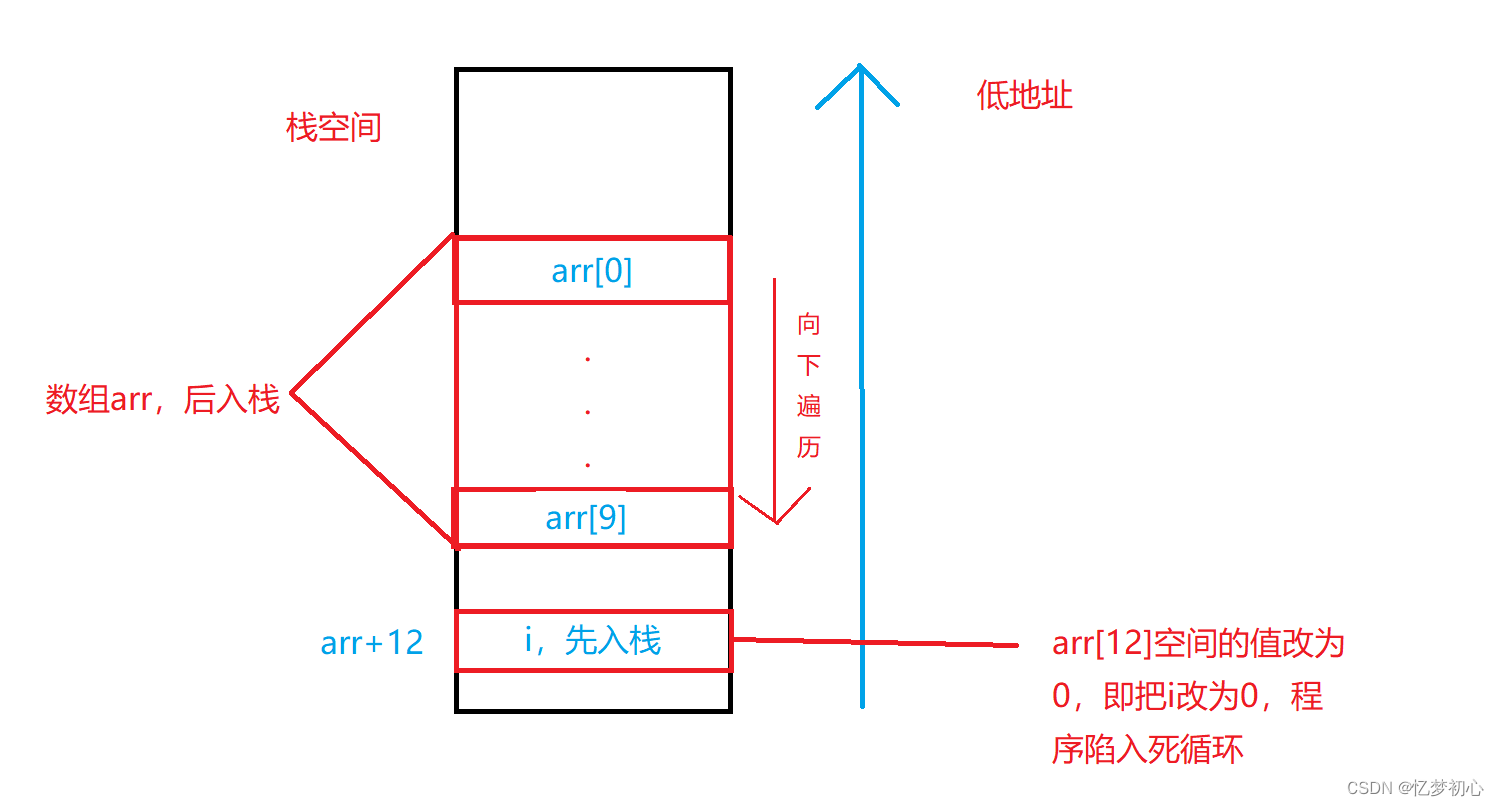
}我们很容易就发现对数组进行了越界访问,当程序运行起来时应该会崩溃。但是在Debug环境下我们发现程序并没有崩溃而是陷入了死循环:
我们运行调试代码转到反汇编如下:
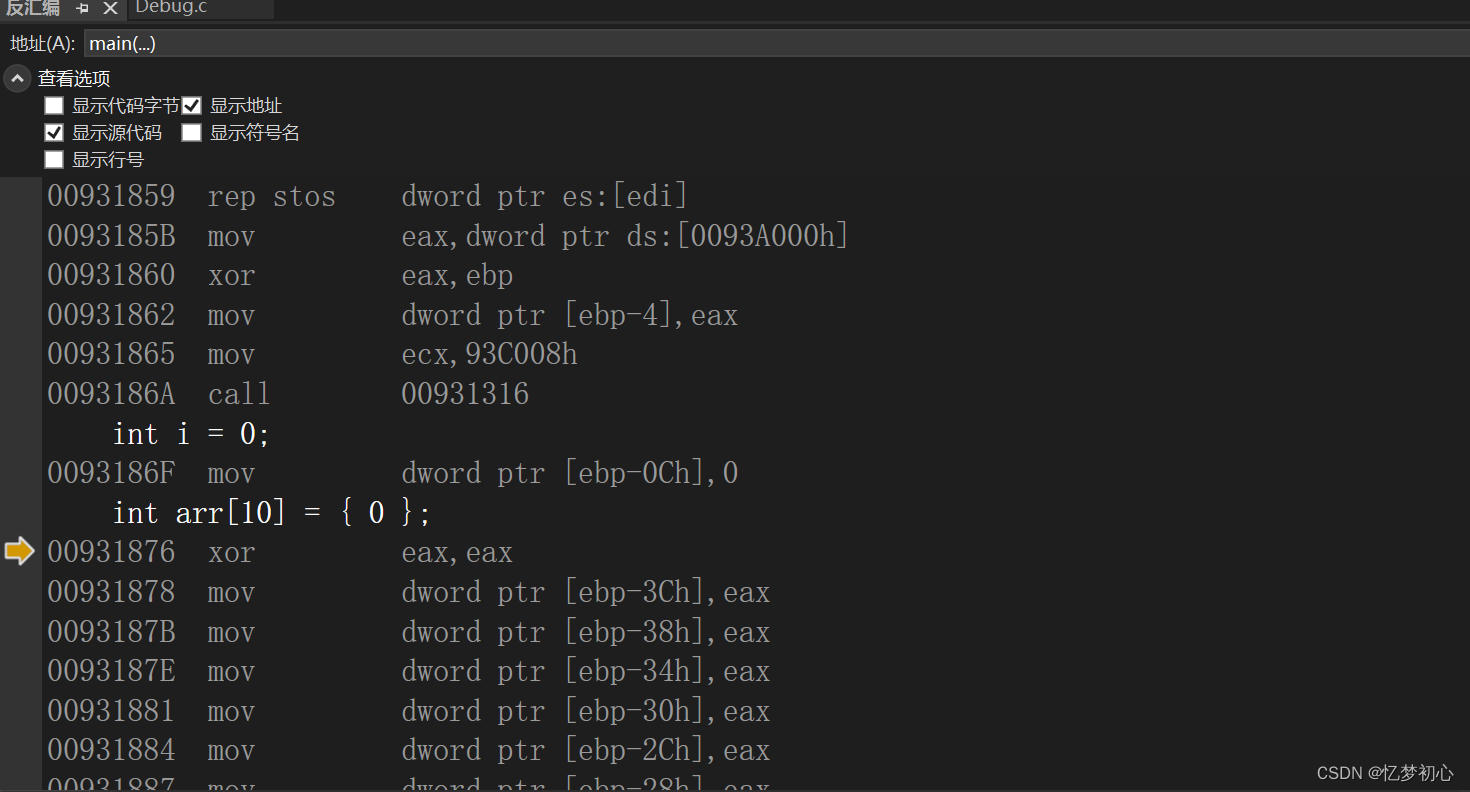
我们知道,数据在栈上的开辟是从高地址向低地址处开辟的,因此在Debug环境下变量i的地址比数组arr的地址高。而在数组内部数据的存储是从低地址向高地址的,因此首元素地址arr是在数组所在空间的低位,如下:
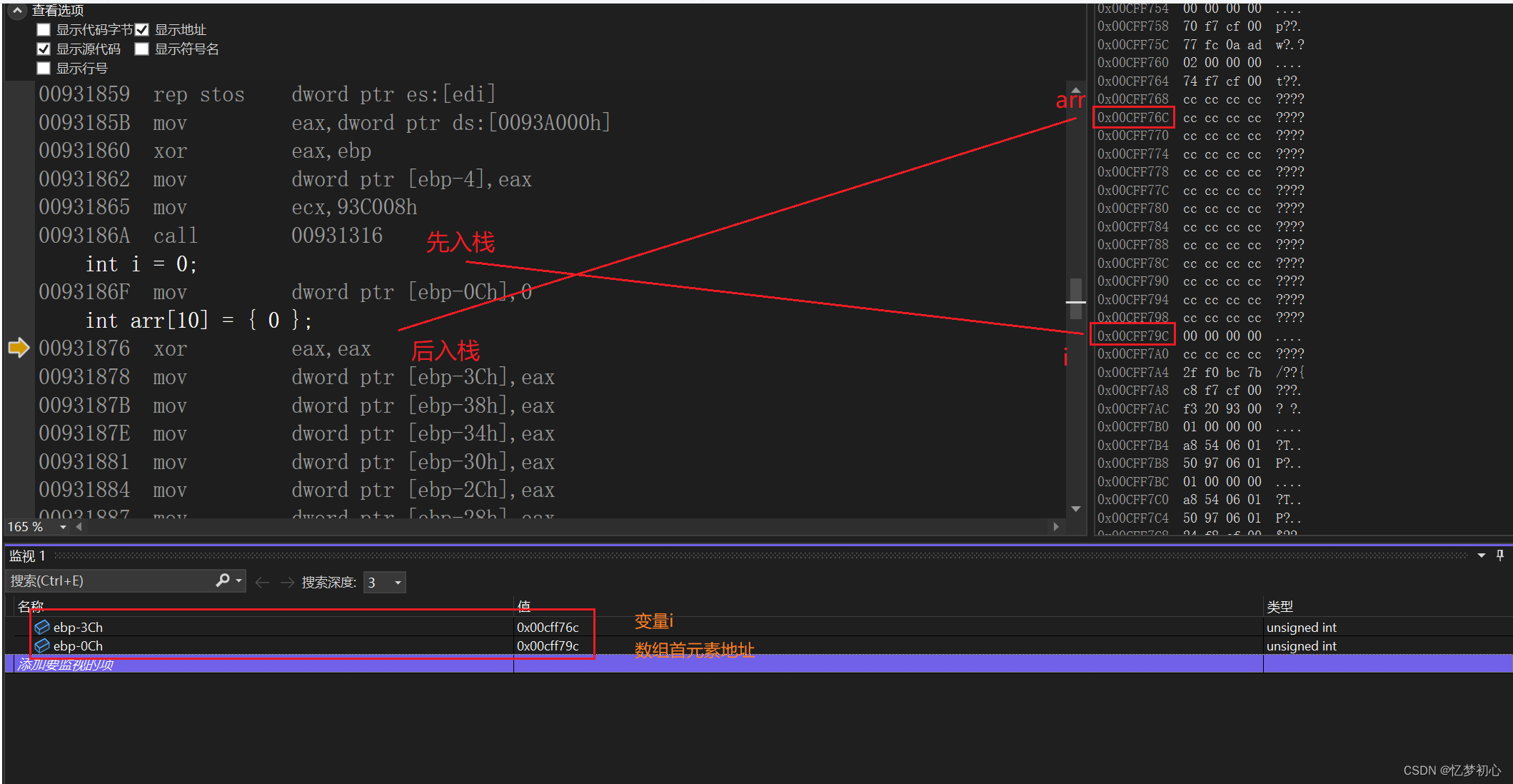
我们很惊讶的发现(arr+12)就是变量i的地址。当循环过程中i等于12时,此时将arr[i]改为0就等价于将i的值修改为0,然后i++后i等于1小于12,继续进行循环,依次反复形成了死循环。如下:
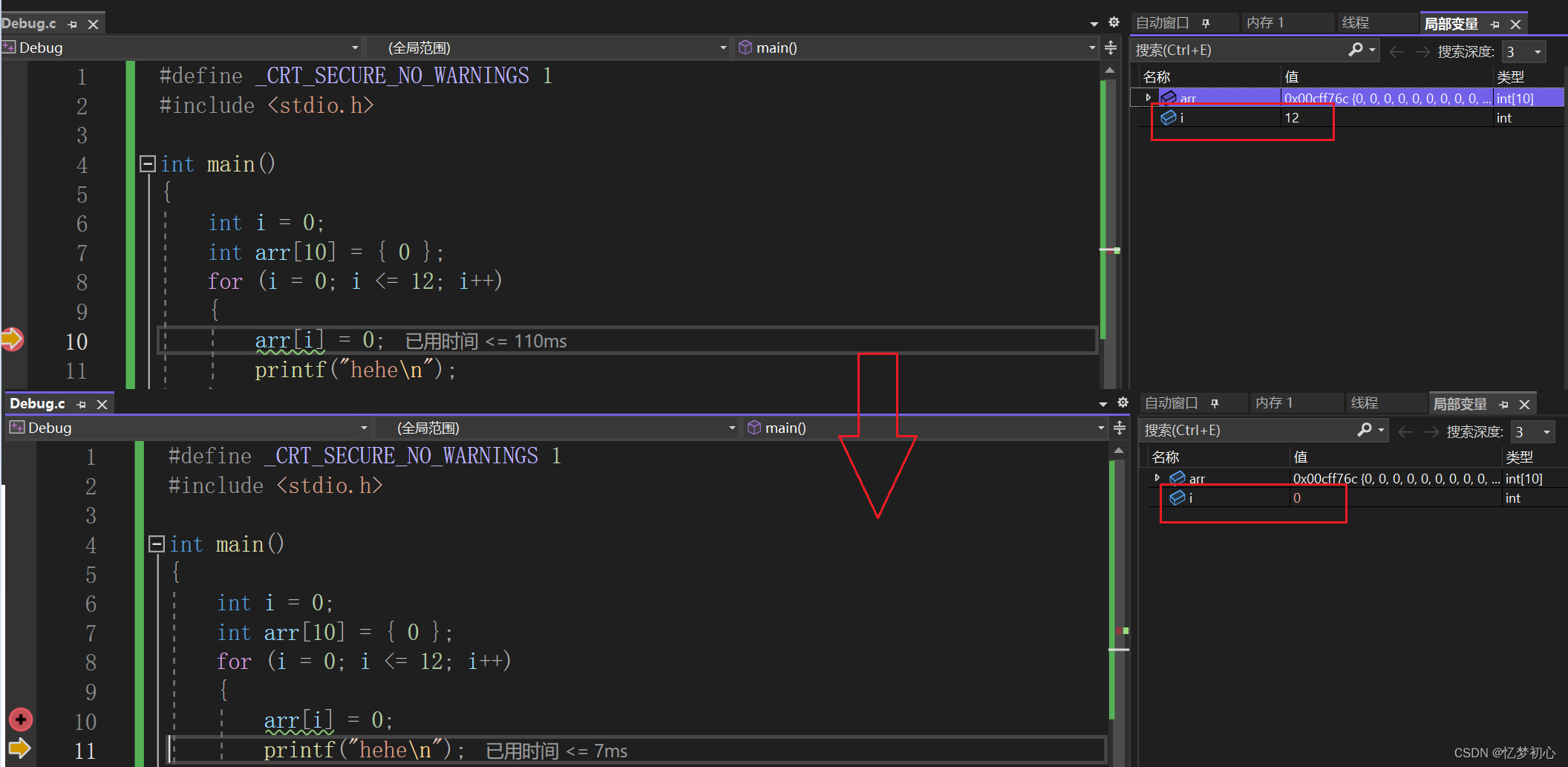
整个过程简化图如下:
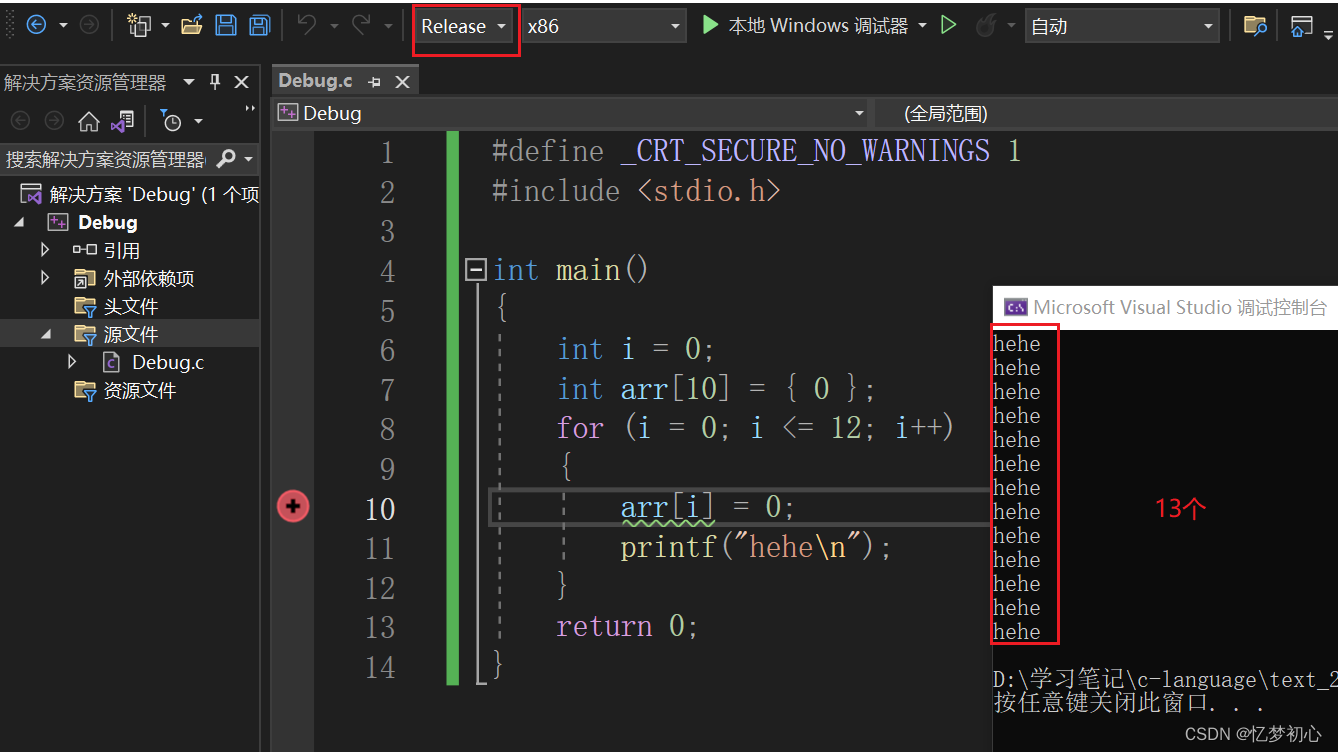
而在Release版本的环境下程序并不会出现死循环的问题:
我们可以打印出此时变量i和数组在栈上的地址如下:
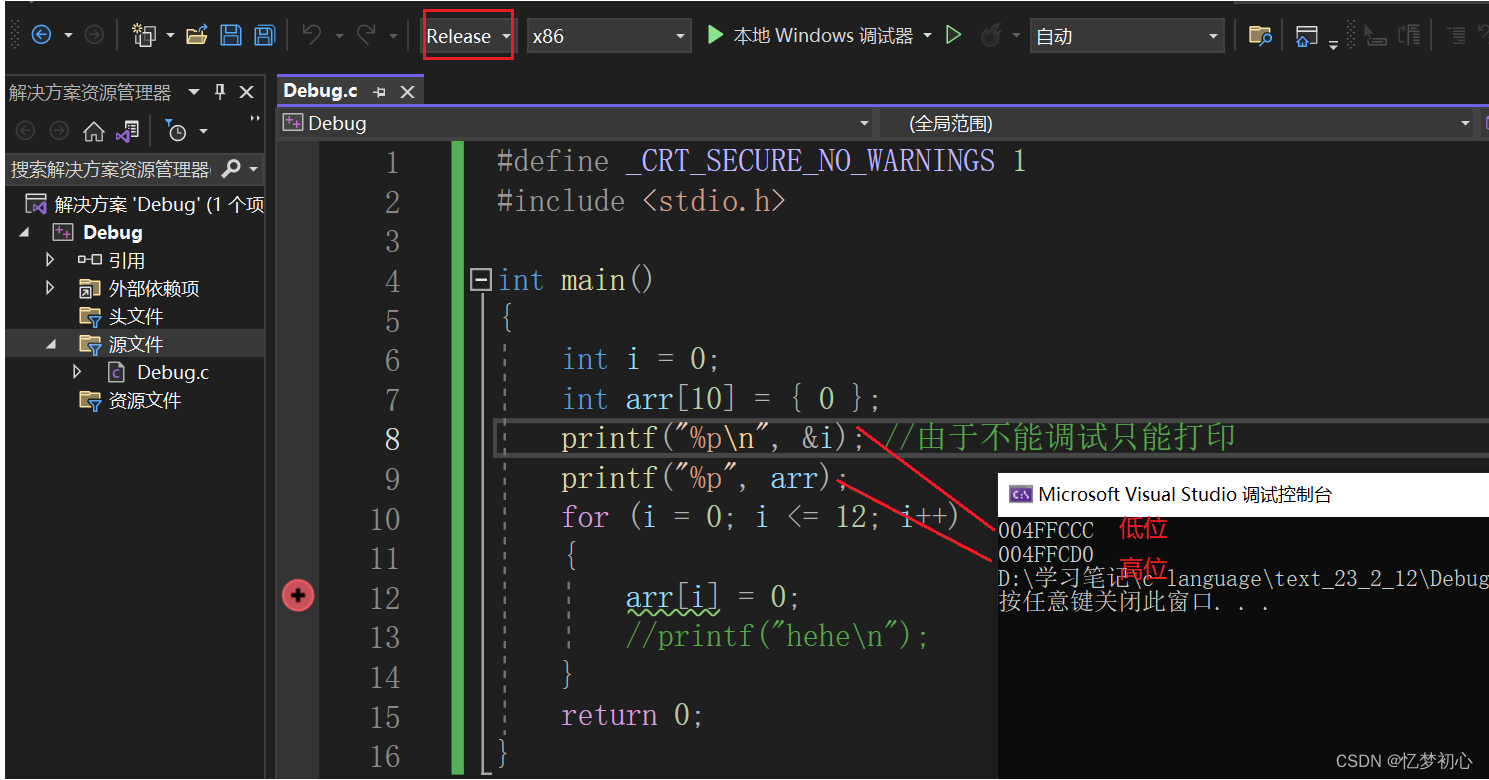
我们发现此时变量i被编译器优化到低地址处,arr[12]存储的值就不是i了,便不会出现死循环的情况。
综上,以上代码在Release版本下,编译器使 变量在内存中开辟的顺序发生了变化,影响到了程序执行的结果,这便是优化带来的好处。
首先第一步,我们需要将环境切换为Debug版本,才能进行调试
以下是在调试过程中最为常用的几个快捷键:
快捷键 | 功能 |
Ctrl+F5 | 开始执行而不进行调试。用于想让程序直接运行起来而不调试时。 |
F9 | 作用:创建断点和取消断点 断点:可以使程序在任何你想停下的地方停止执行,继而一步步执行下去。我们可以在任何地方设置断点,一个程序也可以有多个断点。 |
F10 | 逐过程,通常用来处理一个过程,一个过程可以是一次函数调用,或者是一条语句。 |
F11 | 逐语句,每次只执行一条语句,我们可以通过这个快捷键使我们的执行逻辑进入函数内部(这是F10所不具备的,F11是我们在调试过程中最常用的) |
F5 | 启动调试到下一断点处,需要配合F9进行使用,如果程序没有断点则无异于Ctrl+F5 |
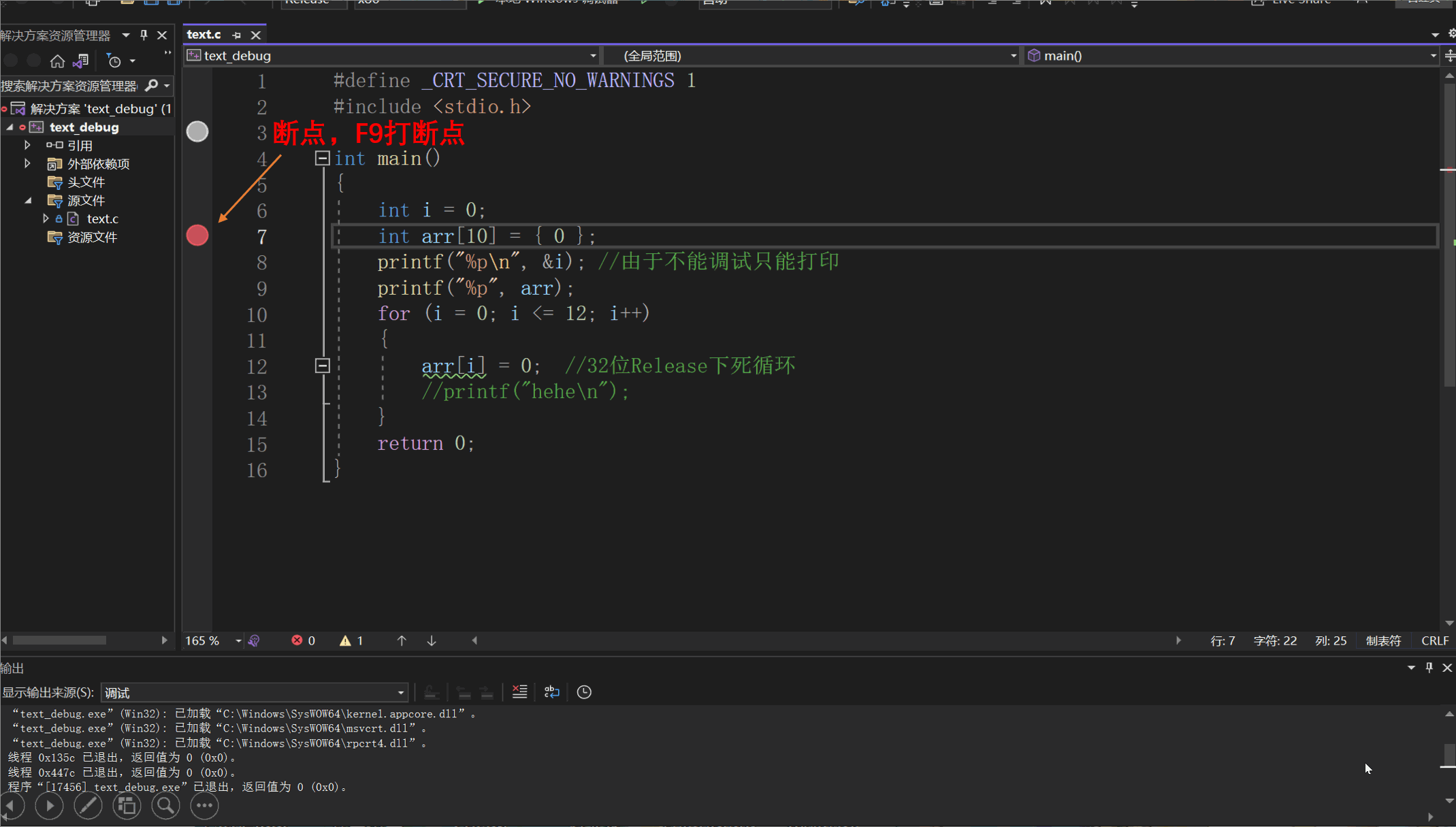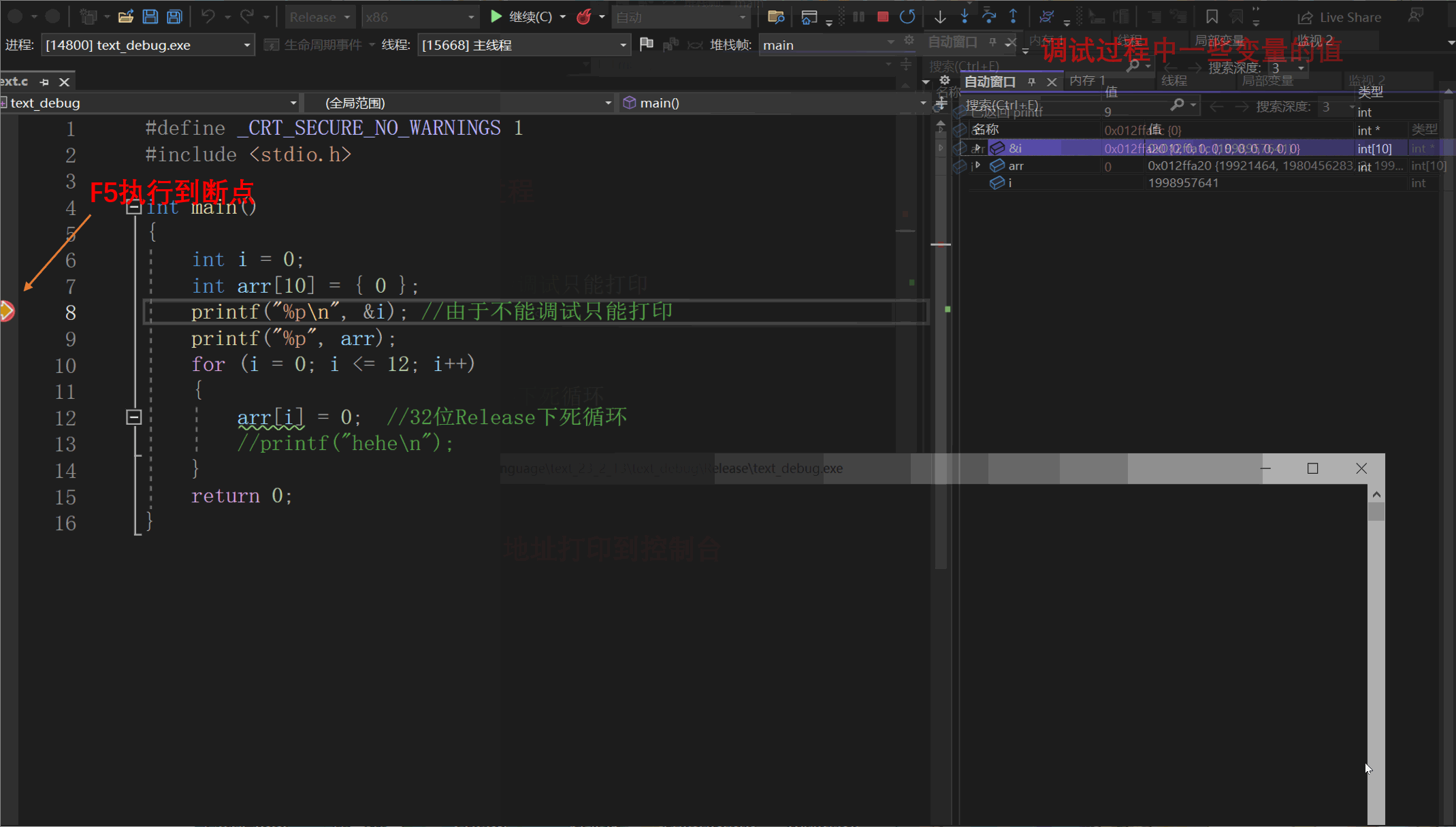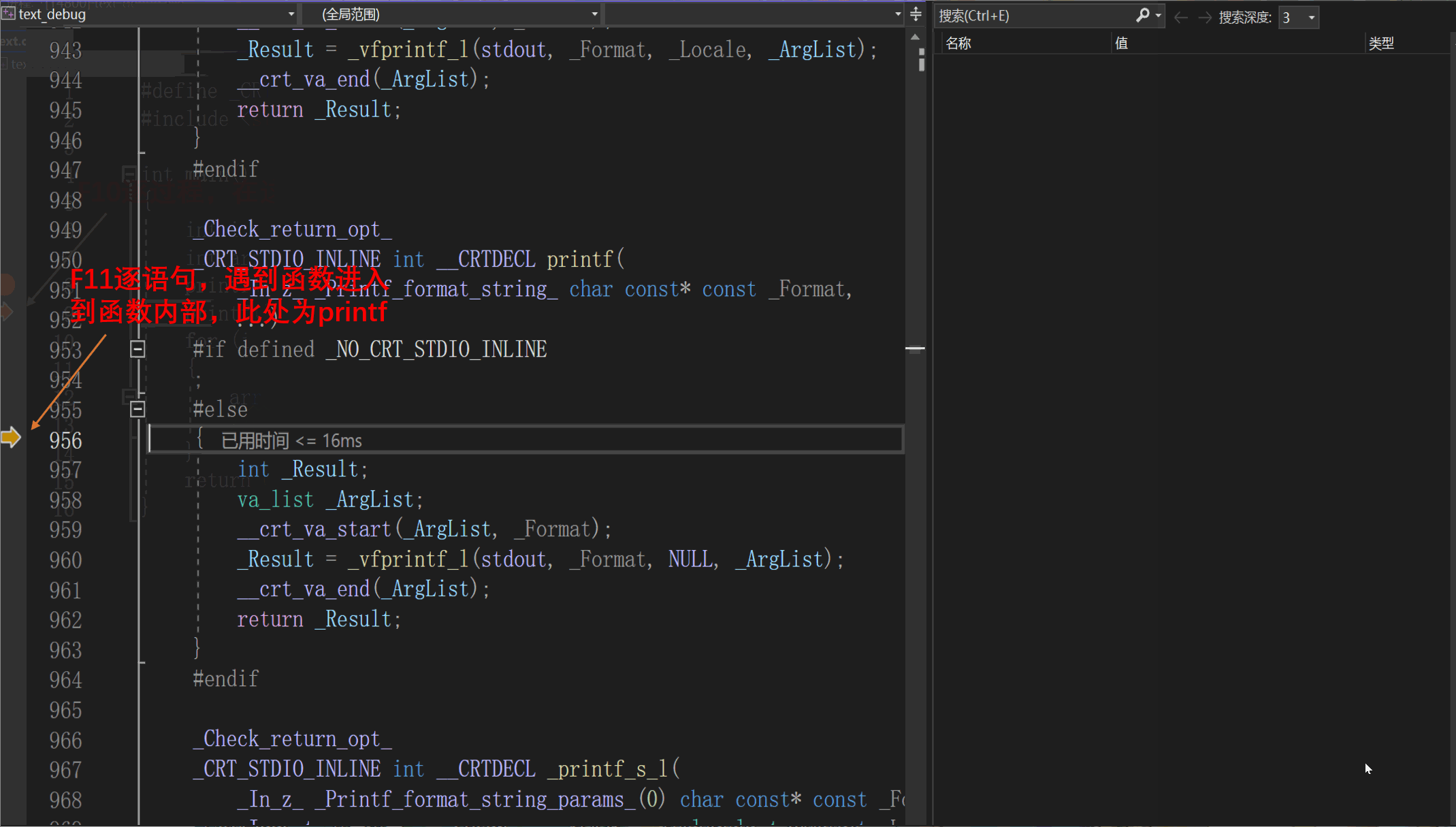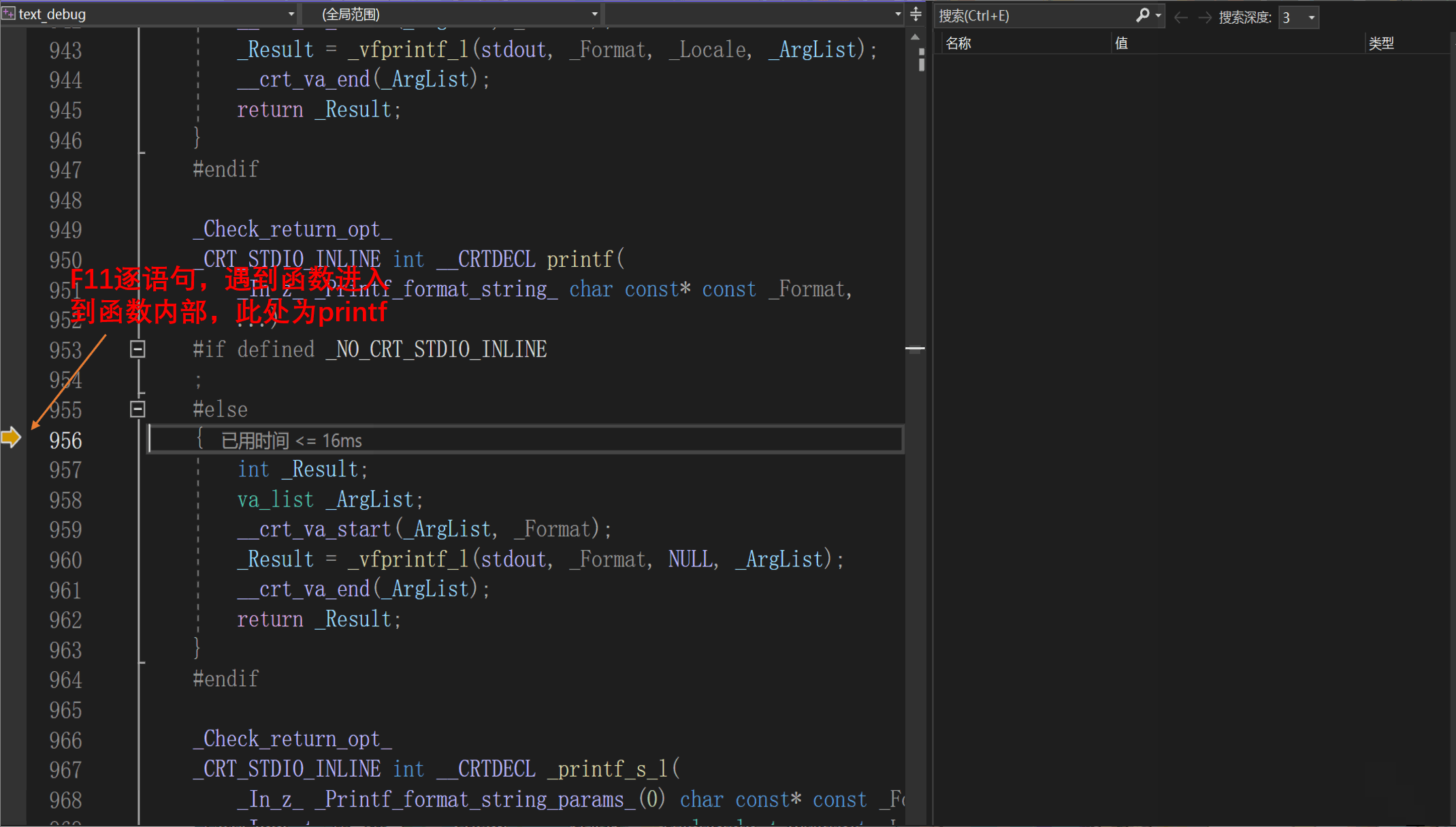
快捷键用法
我们还可以对某一断点设置停止条件,方法是 右键断点->单击条件->输入断点条件->关闭
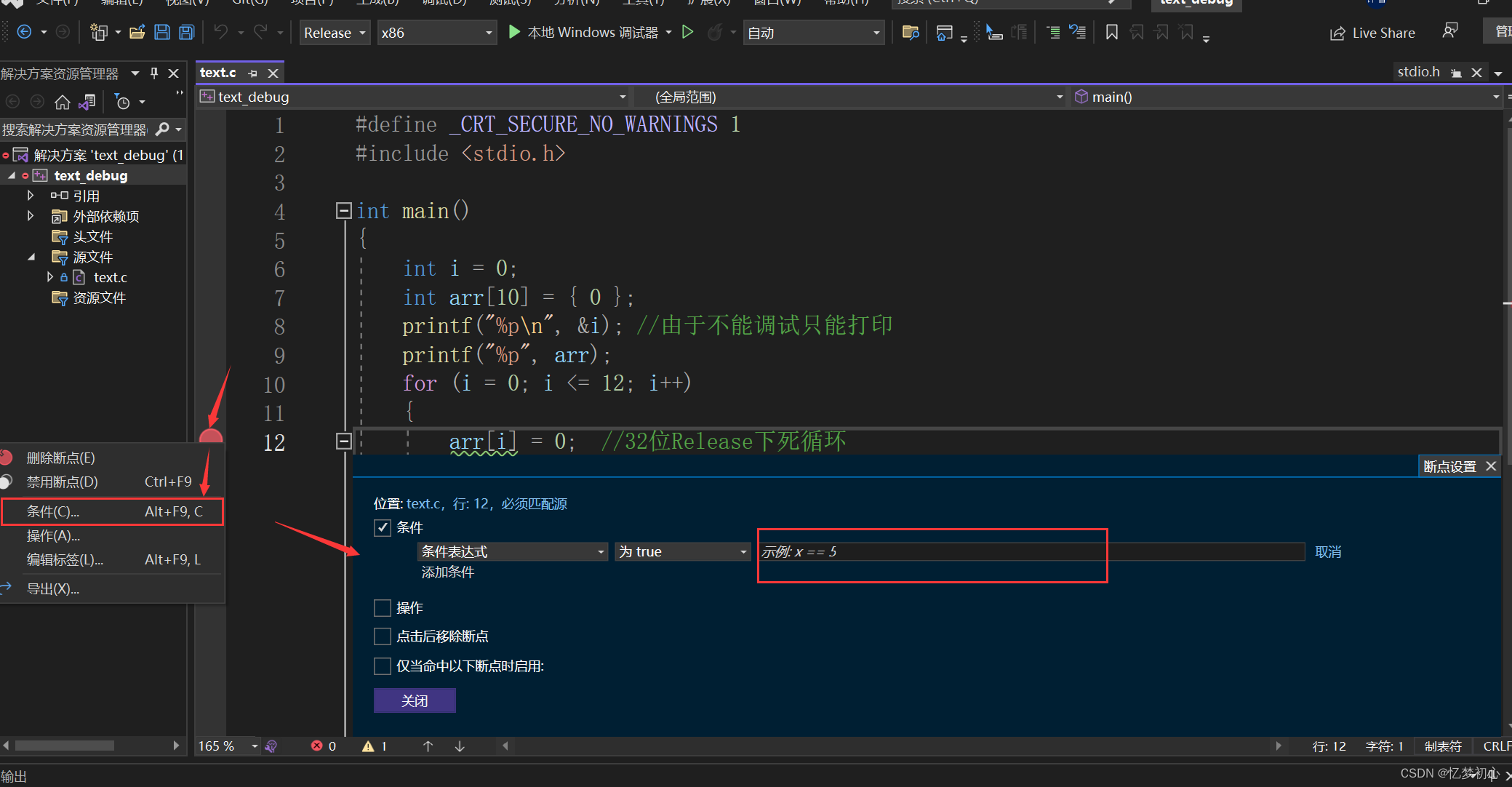
例如:我们需要让程序停止在第4次循环处,我们可以输入i==4
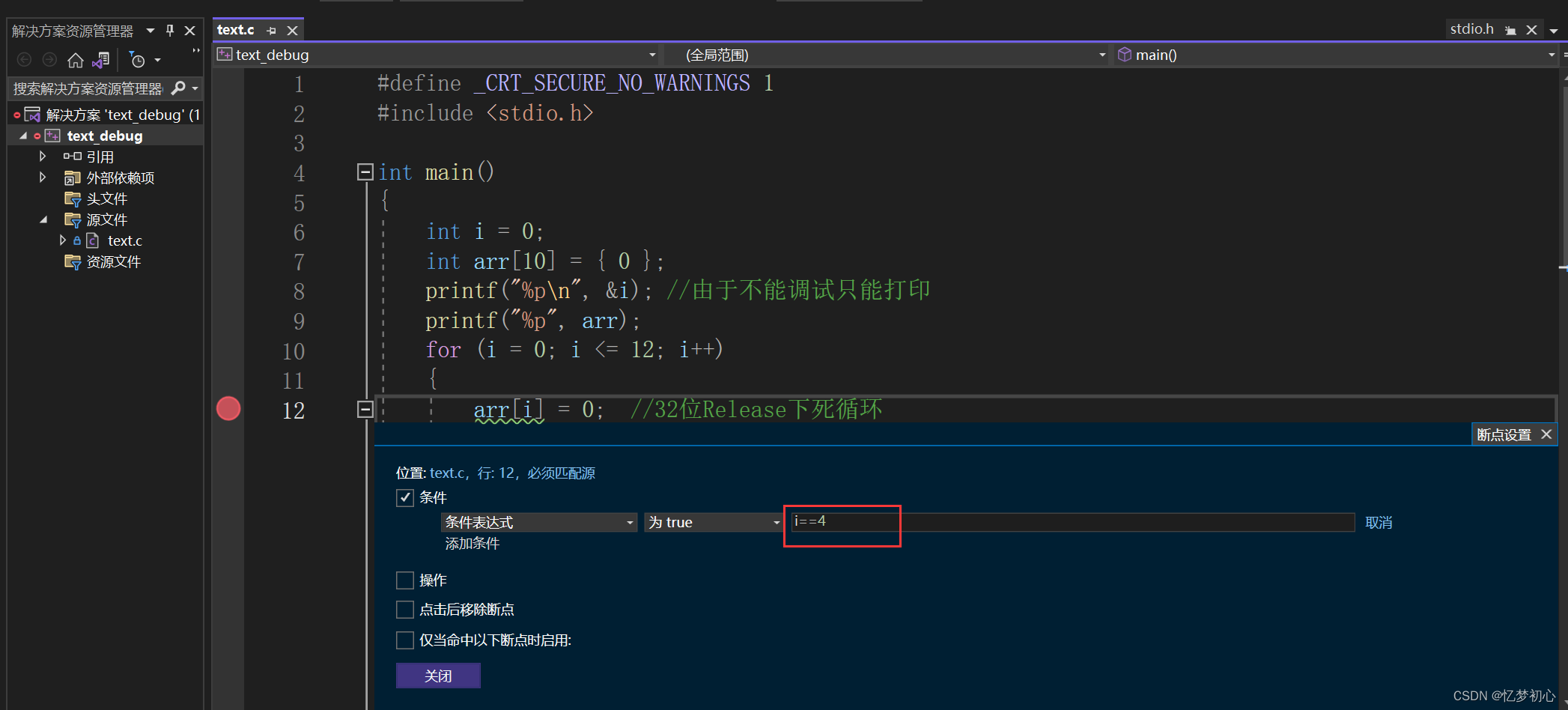
此时单击F5运行到断点,我们查看自动窗口发现程序在停止时i的值为4
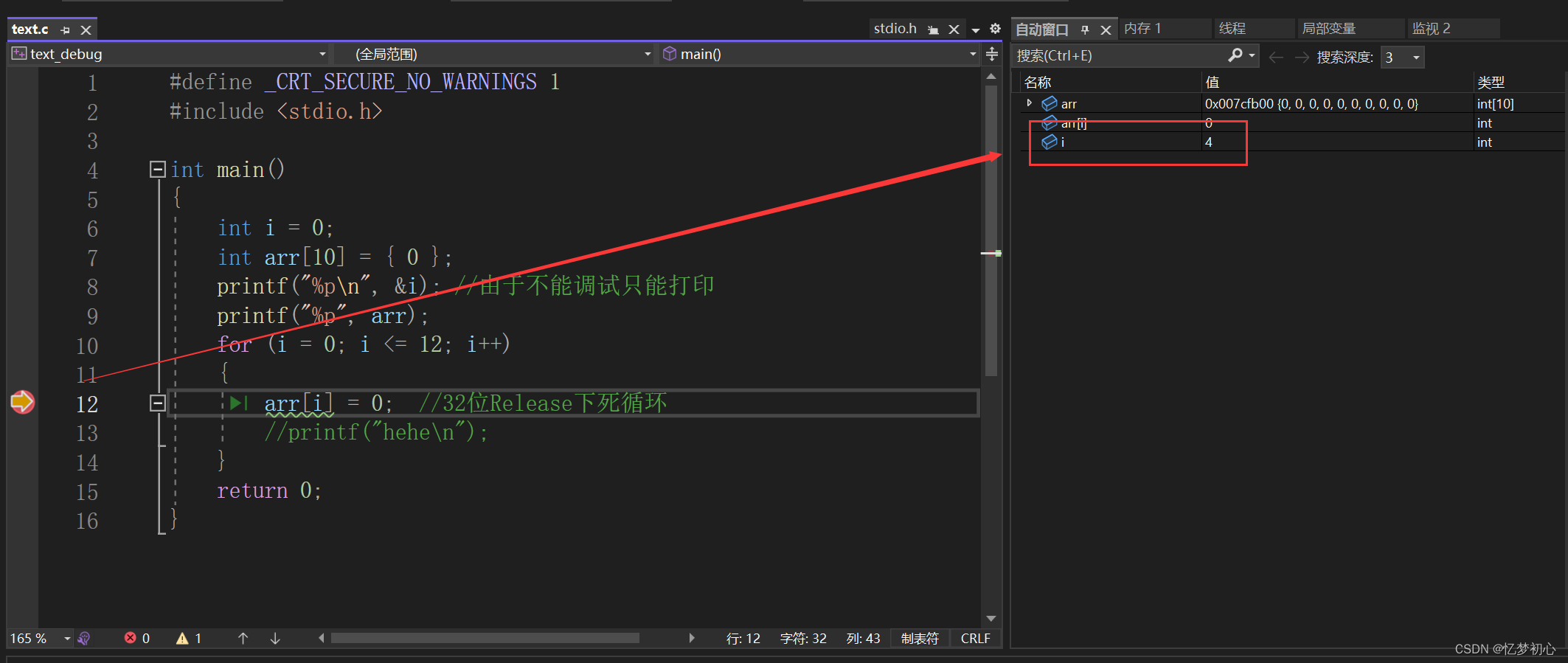
开启调试后,我们可以在VS上方的调试->窗口看到许多用来查看数据信息的窗口:
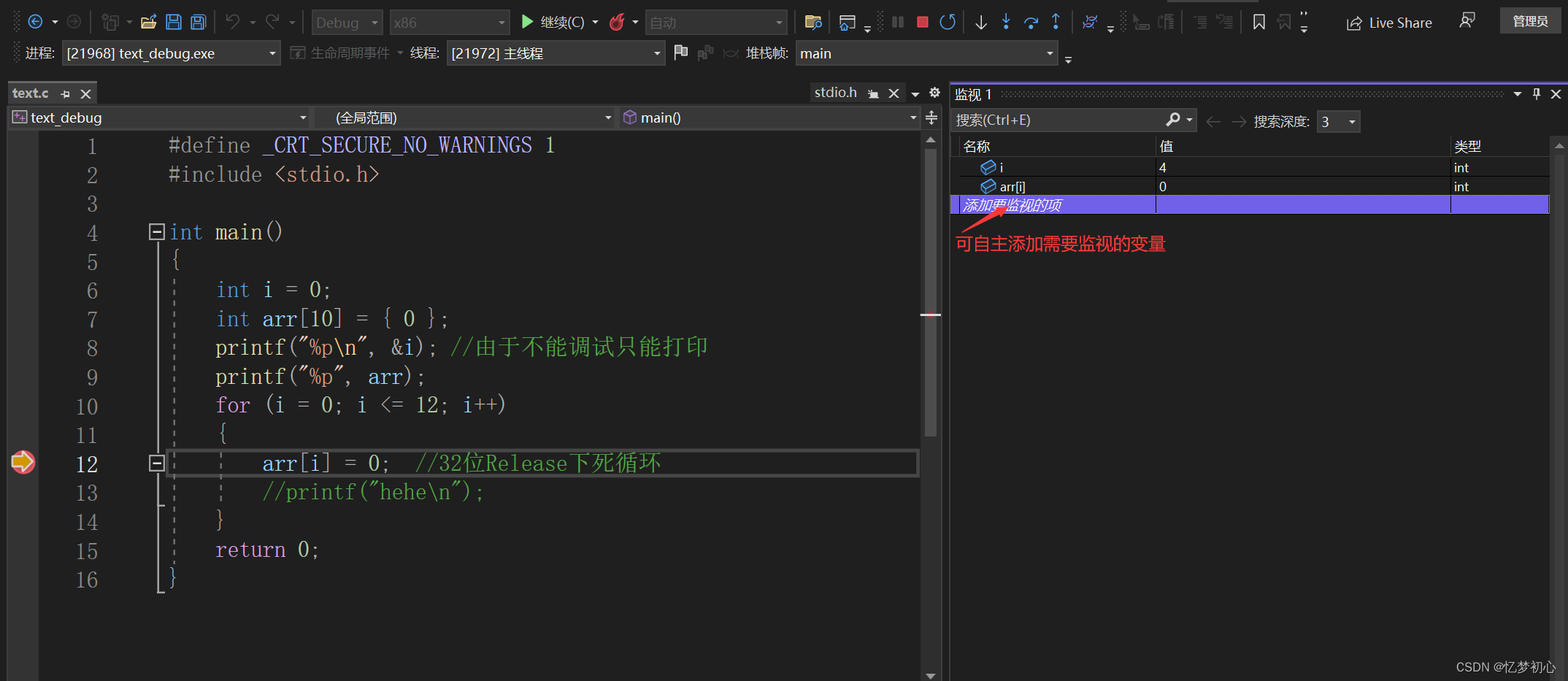
通过监视窗口我们可以查看我们想要查看的 变量甚至是表达式的值在程序运行过程中的变化,十分灵活,这是我们调试中用得最多的窗口之一。如下:
打开自动窗口后,编译器会将一些可能需要观察的变量显示在窗口中,较为方便。其缺陷是可能无法显示我们真正需要观察的变量,并且 无法灵活显示表达式等的值。如下:
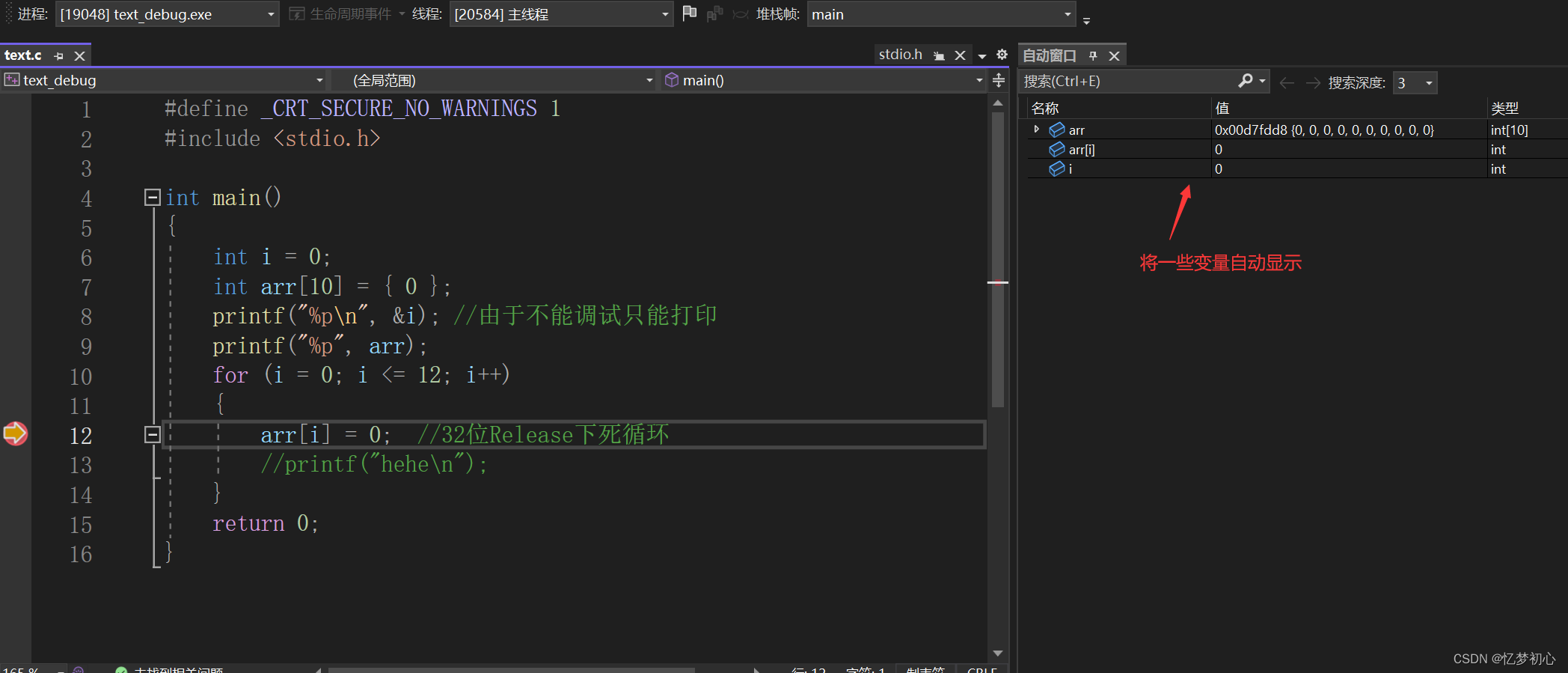
打开局部变量变量窗口,会将程序中的所有 局部变量全部显示出来。如下:
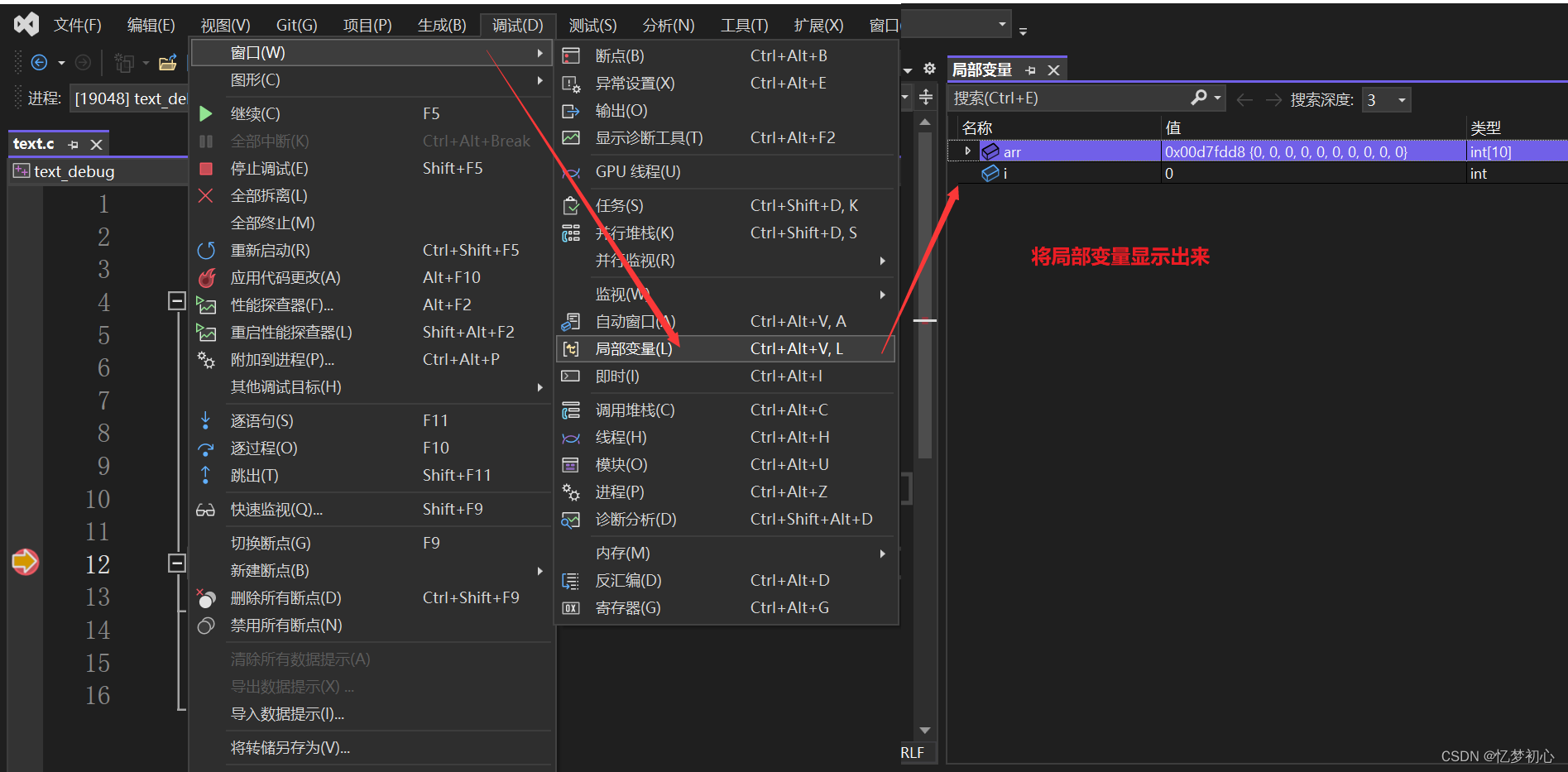
通过调用堆栈,可以清晰的反应 函数的调用关系以及当前调用所处的位置。如下:
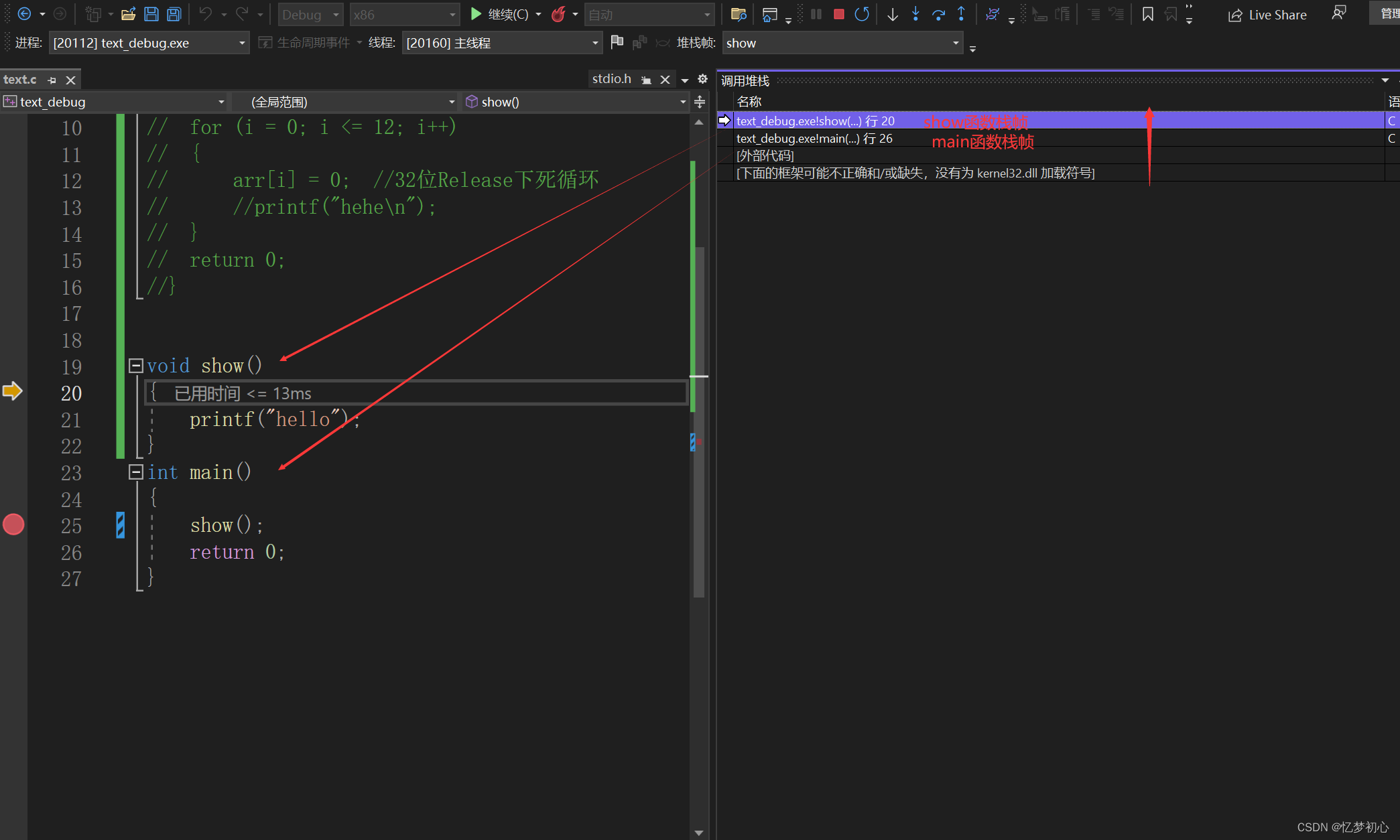
通过调用堆栈窗口,我们可以发现,show函数栈帧在main函数栈帧之上,即 show函数是由main函数调用的。并且可以看出此时show函数运行到第20行。
通过内存窗口我们可以看到内存中的信息,可以 观察变量在内存中的存储情况。如下:
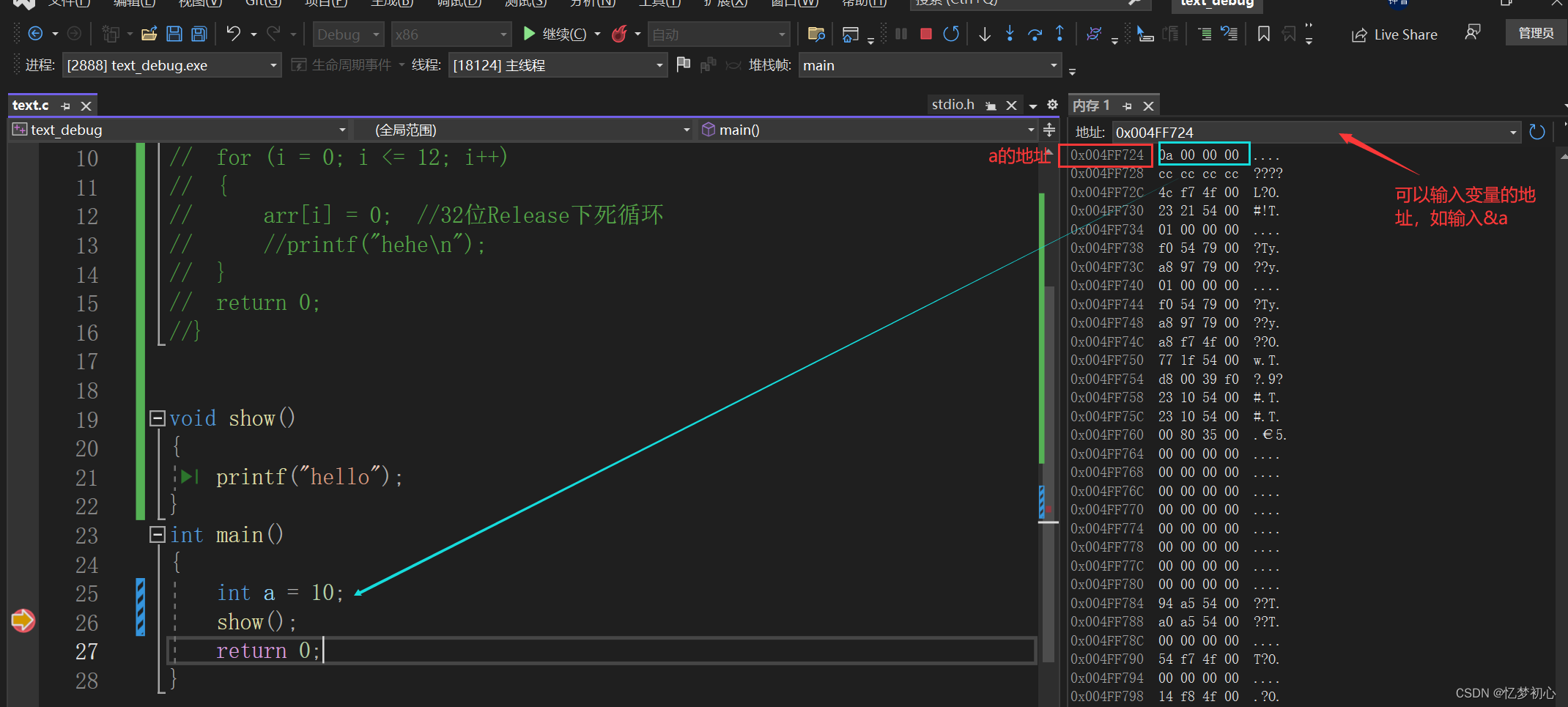
我们可以查看当前程序转化后的汇编代码,进而从更底层的角度观察程序的执行过程。如下:
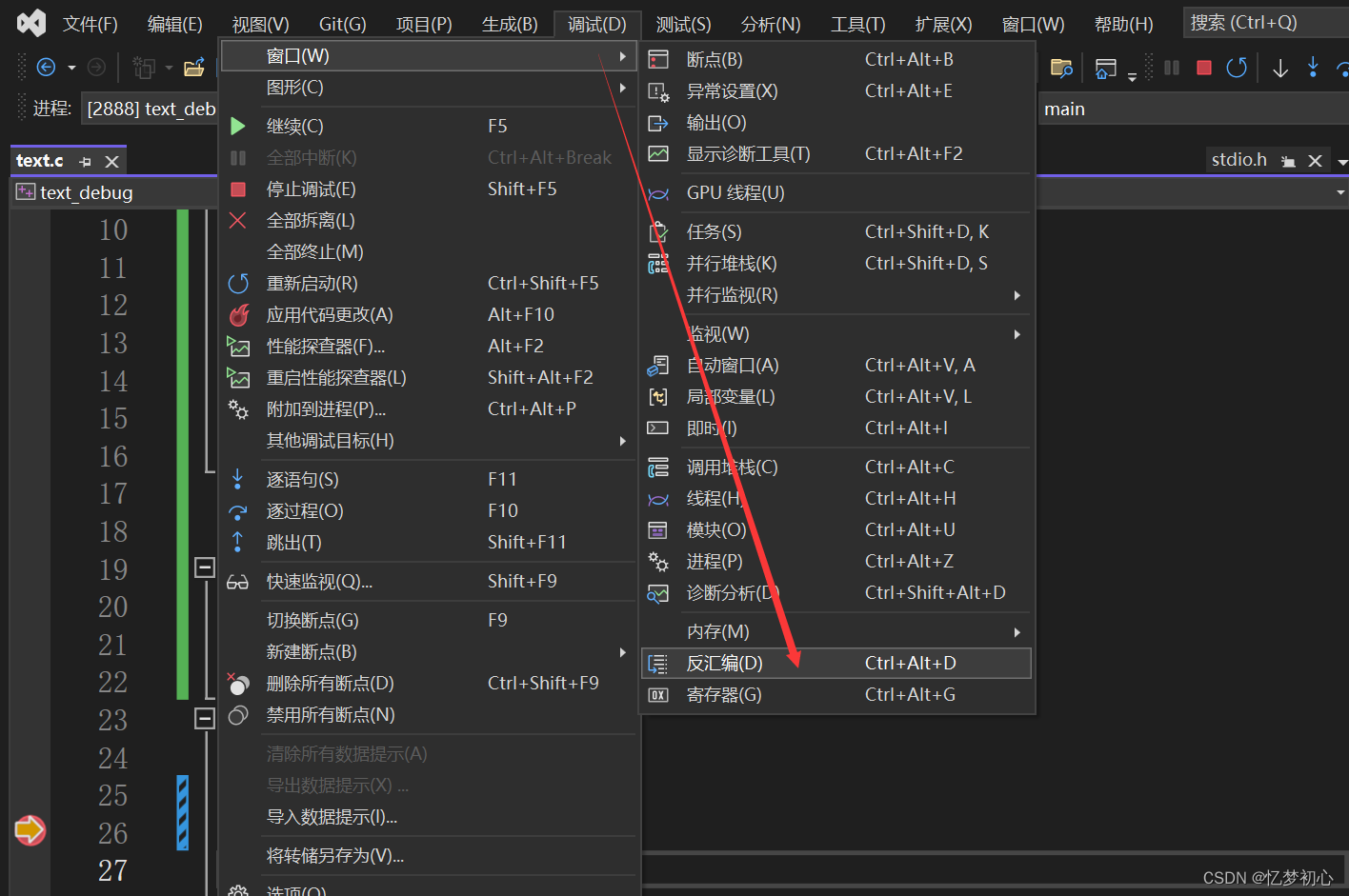
通过寄存器窗口,我们可以观察在当前环境下CPU内的寄存器的使用信息,如ebp栈底寄存器、esp栈顶寄存器等等。
我们上面通过调试分析了数组越界陷入死循环的问题。下面,我们再通过一道实例来掌握调试的技巧:
实现代码:求 1!+2!+3! ...+ n! ;不考虑溢出。我们可能会写出以下代码:
#include<stdio.h>
int main()
{
int i = 0;
int sum = 0;//保存最终结果
int n = 0;
int ret = 1;//保存n的阶乘
scanf("%d", &n);
for(i=1; i<=n; i++)
{
int j = 0;
for(j=1; j<=i; j++)
{
ret *= j;
}
sum += ret;
}
printf("%d\n", sum);
return 0;
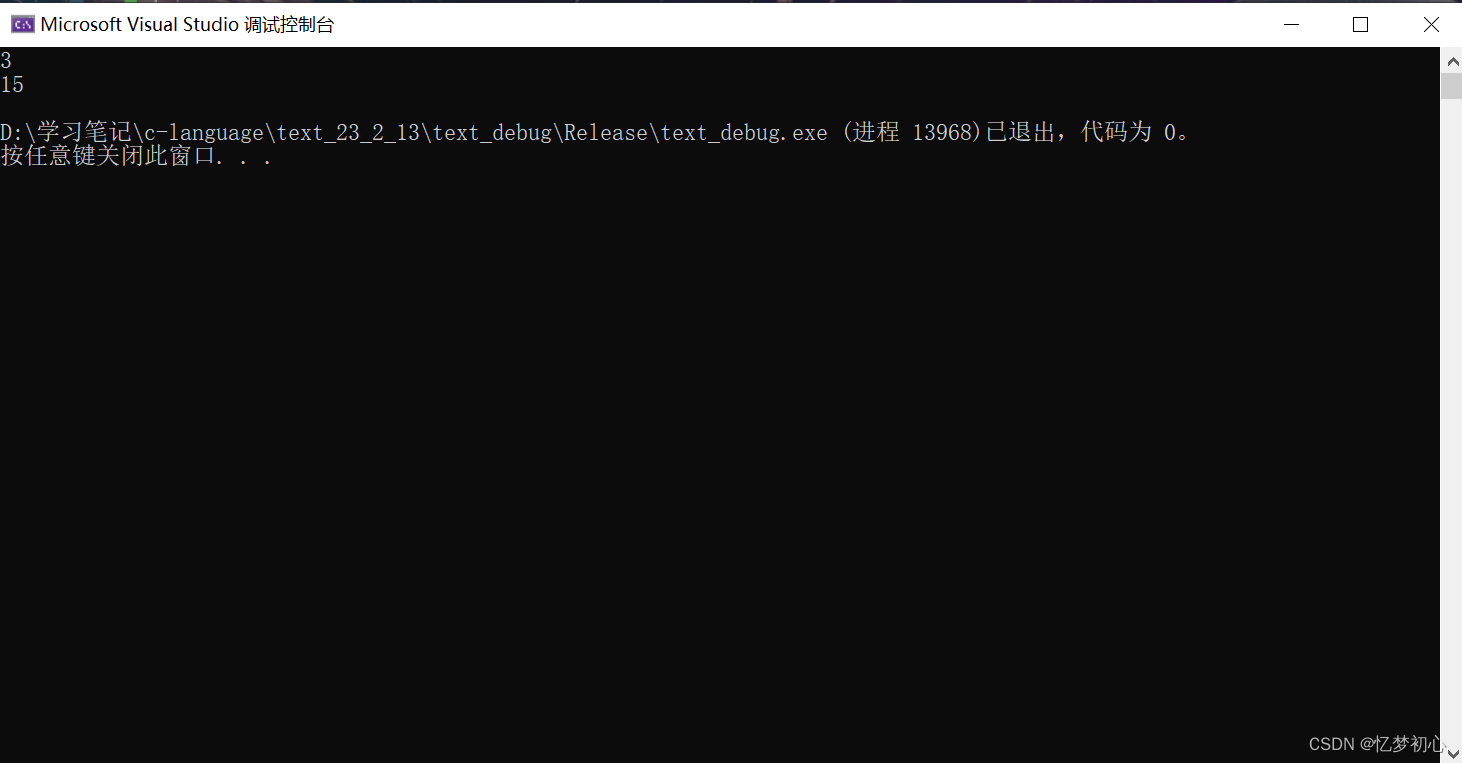
}当你输入3时,理论上应该输出9,但实际上程序却输出了15:
是什么问题导致出错了呢?这就需要我们动手进行调试。在调试之前我们可以先 预测问题的所在,比如 算阶乘时出错、 求和时出错等等。做到心里有数,而不是盲目的进行调试。
我们可以在ret*=j处设置一个断点,打开监视窗口监视ret和sum观察每个数阶乘的值和累加后的值,如下:
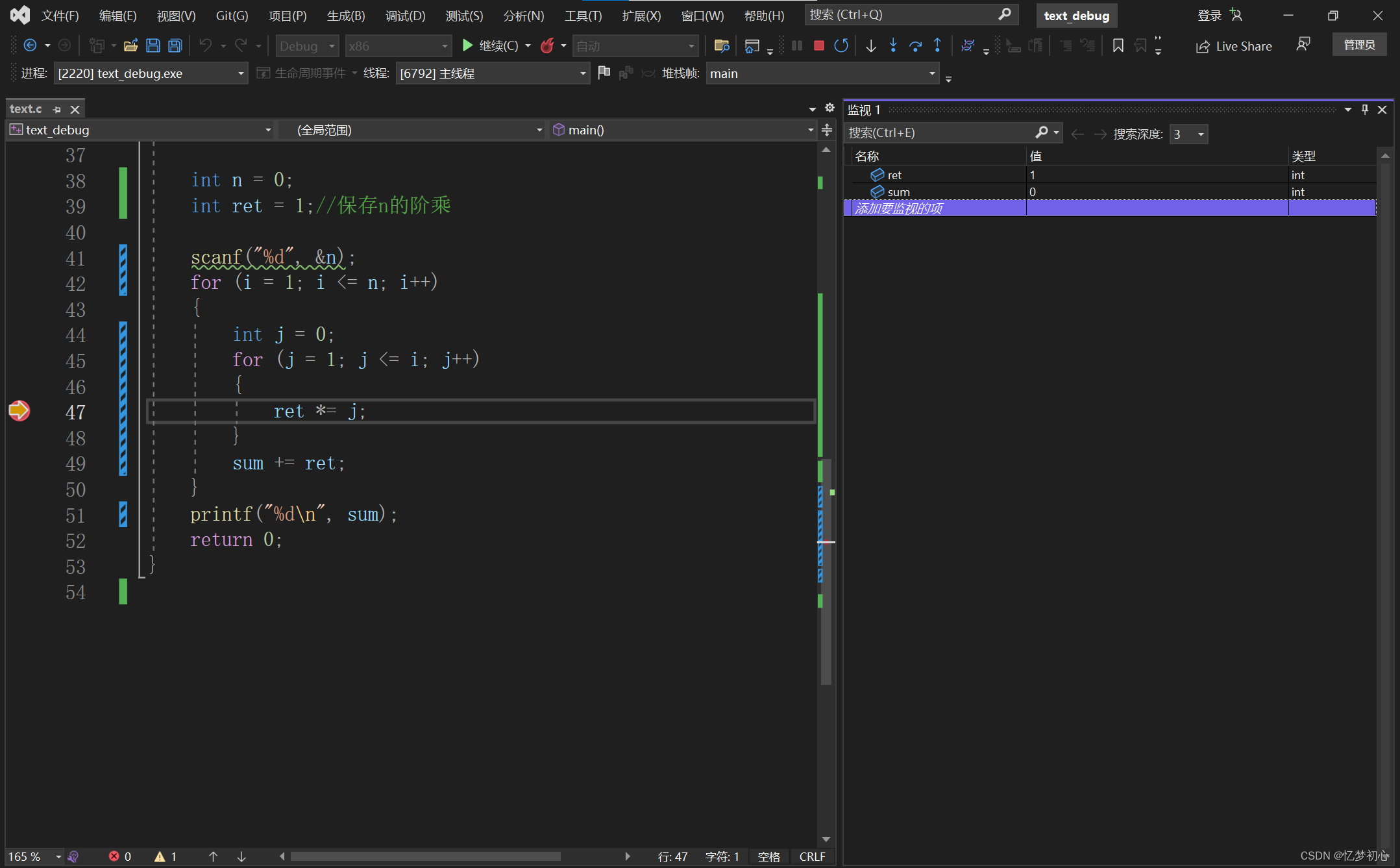
我们单击F10逐过程执行,当外层循环i的值为3时,即计算3的阶乘时,我们发现ret的初始值并非为1,而是2的阶乘。此时再计算3的阶乘,就是2*1*2*3=12 != 6,结果出错:
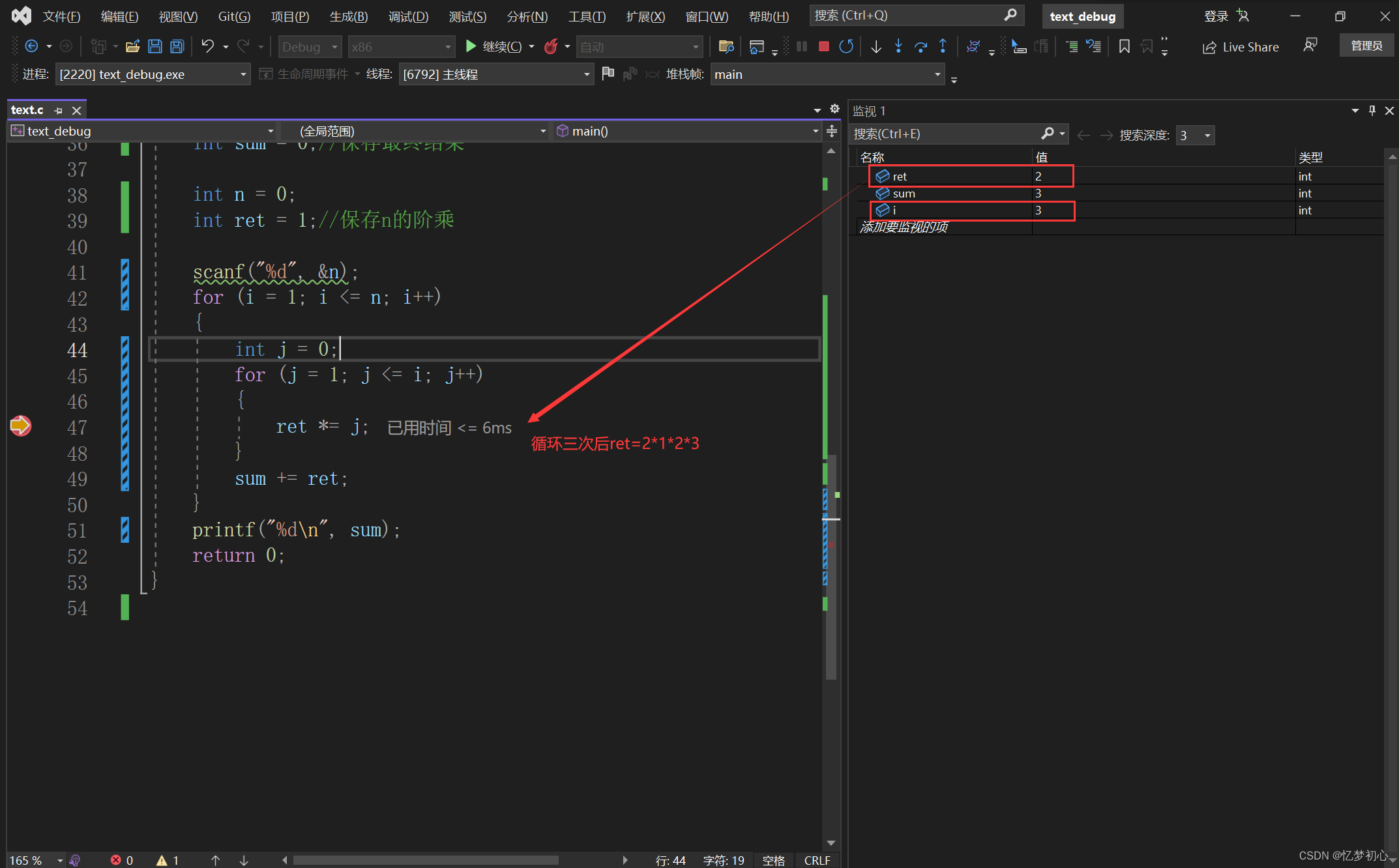
最后sum+ret的值就为15,与我们的输出相符:

可见,每次在求阶乘时,我们都应该把ret重置为1,正确的代码如下:
int main()
{
int i = 0;
int sum = 0;//保存最终结果
int n = 0;
int ret = 1;//保存n的阶乘
scanf("%d", &n);
for (i = 1; i <= n; i++)
{
int j = 0;
ret = 1; //将ret置1
for (j = 1; j <= i; j++)
{
ret *= j;
}
sum += ret;
}
printf("%d\n", sum);
return 0;
}任何事情都不可能一蹴而就,一定要多加练习,才能熟练掌握调试技巧。
一个初学者可能80%的时间在写代码,20%的时间在进行调试;而一个程序员,可能80%的时间在进行调试,剩余20%的时间才是在写代码。
随之学习的深入,后续可能会出现很多更加复杂的调试场景,如多线程等。只有打好基础,在未来才能融会贯通,利于不败之地。
多多使用快捷键可以很大程度上提高效率。
1. 代码运行正常
2. bug很少
3. 效率高
4. 可读性高
5. 可维护性高
6. 注释清晰
7. 文档齐全
1.多使用assert断言,可以告知你出错的位置
2.尽量使用const,避免意外修改
3.养成良好的编码风格
4.添加必要的注释
5.避免编码的陷阱
试模拟实现一个strcpy函数,尽量用到上述的编码技巧。如下:
char* strcpy(char* dst, const char* src) //const修饰防止对源字符串进行修改
{
assert(dst && src); //避免传入空指针
char cur = dst; //保存起始位置
//将src的字符一个个拷贝到det中,包括'\0'
while ((*dst++ = *src++)!='\0')
{
;
}
return cur; //返回目标字符串,以便链式访问
}在 编译期间出现的错误。直接看错误提示信息(双击鼠标),解决问题。或者凭借经验就可以搞定。相对来说简单。
在 链接期间出现的错误。看错误提示信息,主要在代码中找到错误信息中的标识符,然后定位问题所在。一般是 标识符名不存在或者 拼写错误。
在 运行期间出现的错误。借助 调试,逐步定位问题。最难搞的一种错误
不要害怕遇到错误,每出现一次的错误就是一次突破自我的机会。
学会积累排错经验,勇于尝试。不经风雨 🌂 ,怎能见彩虹 🌈
以上,就是本期的全部内容啦🌸
制作不易,能否点个赞再走呢🙏
在railstutorial中,作者为什么选择使用这个(代码list10.25):http://ruby.railstutorial.org/chapters/updating-showing-and-deleting-usersnamespace:dbdodesc"Filldatabasewithsampledata"task:populate=>:environmentdoRake::Task['db:reset'].invokeUser.create!(:name=>"ExampleUser",:email=>"example@railstutorial.org",:passwo
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
GivenIamadumbprogrammerandIamusingrspecandIamusingsporkandIwanttodebug...mmm...let'ssaaay,aspecforPhone.那么,我应该把“require'ruby-debug'”行放在哪里,以便在phone_spec.rb的特定点停止处理?(我所要求的只是一个大而粗的箭头,即使是一个有挑战性的程序员也能看到:-3)我已经尝试了很多位置,除非我没有正确测试它们,否则会发生一些奇怪的事情:在spec_helper.rb中的以下位置:require'rubygems'require'spork'
使用Ruby1.9.2运行IDE提示说需要gemruby-debug-base19x并提供安装它。但是,在尝试安装它时会显示消息Failedtoinstallgems.Followinggemswerenotinstalled:C:/ProgramFiles(x86)/JetBrains/RubyMine3.2.4/rb/gems/ruby-debug-base19x-0.11.30.pre2.gem:Errorinstallingruby-debug-base19x-0.11.30.pre2.gem:The'linecache19'nativegemrequiresinstall
我有:When/^(?:|I)follow"([^"]*)"(?:within"([^"]*)")?$/do|link,selector|with_scope(selector)doclick_link(link)endend我打电话的地方:Background:GivenIamanexistingadminuserWhenIfollow"CLIENTS"我的HTML是这样的:CLIENTS我一直收到这个错误:.F-.F--U-----U(::)failedsteps(::)nolinkwithtitle,idortext'CLIENTS'found(Capybara::Element
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
Ruby是否有逐步调试器,类似于Perl的“perl-d”? 最佳答案 ruby-debug(对于ruby1.8),debugger(对于ruby1.9),byebug(对于ruby2.0)以及trepanning系列都有一个-x或--trace选项。在调试器内部,命令setlinetrace将打开或关闭线路跟踪。这是themanualforruby-debug原来的答案已经修改,因为数据噪声文章的链接,唉,不再有效了。还添加了ruby-debug的后继者 关于ruby-Ruby
我有一个数组数组,想将元素附加到子数组。+=做我想做的,但我想了解为什么push不做。我期望的行为(并与+=一起工作):b=Array.new(3,[])b[0]+=["apple"]b[1]+=["orange"]b[2]+=["frog"]b=>[["苹果"],["橙子"],["Frog"]]通过推送,我将推送的元素附加到每个子数组(为什么?):a=Array.new(3,[])a[0].push("apple")a[1].push("orange")a[2].push("frog")a=>[[“苹果”、“橙子”、“Frog”]、[“苹果”、“橙子”、“Frog”]、[“苹果”、“
给定一个元素和一个数组,Ruby#index方法返回元素在数组中的位置。我使用二进制搜索实现了我自己的索引方法,期望我的方法会优于内置方法。令我惊讶的是,内置的在实验中的运行速度大约是我的三倍。有Rubyist知道原因吗? 最佳答案 内置#indexisnotabinarysearch,这只是一个简单的迭代搜索。但是,它是用C而不是Ruby实现的,因此自然可以快几个数量级。 关于Ruby#index方法VS二进制搜索,我们在StackOverflow上找到一个类似的问题:
随着ruby被引入为新的编程救世主,我想知道是否有人基于易用性、运行所需的资源、可用性和易定制性而有偏好。两者有更好的吗? 最佳答案 好吧,任何基于Rails的社交网络应用程序的比较都应该包括insoshi(http://portal.insoshi.com/)。话虽这么说,这三个都非常相似,区别在于实现细节。Lovd和Insoshi都是完整的Rails应用程序;它旨在供您将它们用作入门工具包,并使用您自己的自定义功能对其进行扩展。另一方面,CommunityEngine是一个Rails插件。这意味着您可以更轻松地向现有Rail