分享嘉宾:牟娜 阿里巴巴 高级算法工程师
编辑整理:孙锴
内容来源:DataFun AI Talk《定向广告新一代点击率预估主模型——深度兴趣演化网络》
出品社区:DataFun
导读: 本次带给大家分享是阿里妈妈在2018年做的模型上的创新——深度兴趣演化网络(Deep Interest Evolution Network),分享将从以下几个方面展开——
提出该模型的背景及原因
该模型的结构详解
该模型的最终效果
--

在介绍该模型创新背景之前,先来看一下我们的业务形态:当我们打开淘宝的时候,首先呈现的是一个banner形式的广告;在首页猜你喜欢场景下,或者购物链路的其他场景下,会出现一些单品的广告:在推荐的商品浏览列表,即信息流场景下,会在列表中穿插广告投放,且投放位置固定,这些广告将和正常推荐浏览的商品一起呈现出来。
tips:如果广告的形态特别明显,会破坏用户的体验,比如浏览的顺畅感。所以,推荐用户感兴趣的东西,使得用户感觉不到广告的存在,是十分重要的。
在一般的广告建模里,通常根据广告信息、用户信息、上下文信息,去判断用户是否会点击这个广告。区别于搜索广告这种用户带有明显意图的主动的query查询行为,在展示广告业务场景下,用户并没有明确的意图。此时,应当如何建模,用户会有什么样的兴趣,了解并解决这些问题,对我们工作非常重要。
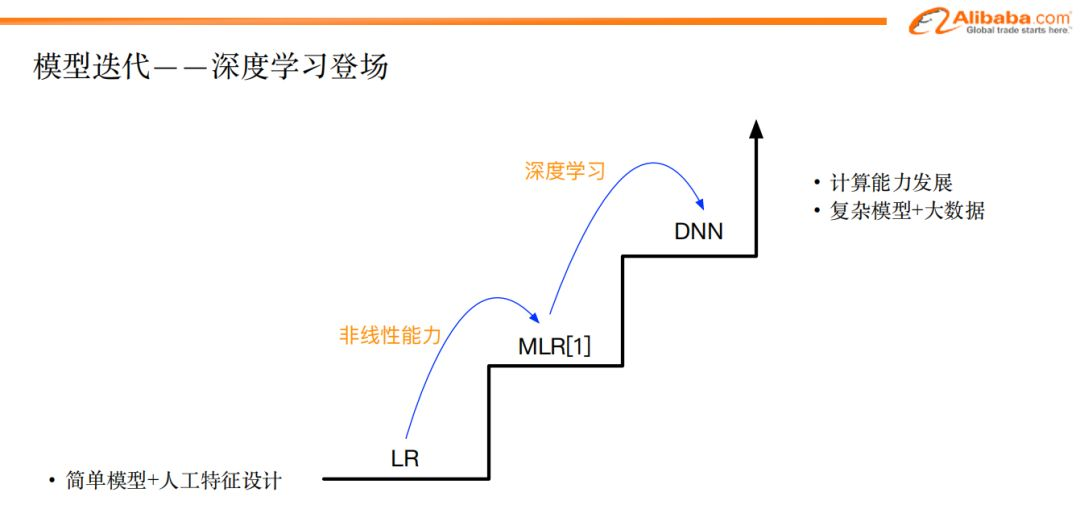
从模型的视角来看,早期的模型形态为:简单模型+复杂的人工设计特征。很多公司在初期都是这样的形式:LR模型+非常复杂的特征工程。
而随着计算机的性能的提升,大家能够利用的数据和计算资源也越来越多的时候,我们便尝试把挖掘潜在特征的工作交给模型来做,这就是深度学习出场的过程。
在LR时代,我们团队做了一些尝试,其中一个是引入了MLR模型,即:把LR模型分成多片,每片建模一部分数据,此方式相当于引入一部分非线性能力。在这个过程中,我们发现,与只用LR相比,MLR模型引入的这部分非线性,对我们的最终效果产生了明显的提升。
在2016年的时候,我们团队开始尝试引入深度学习来解决ctr提升的问题。
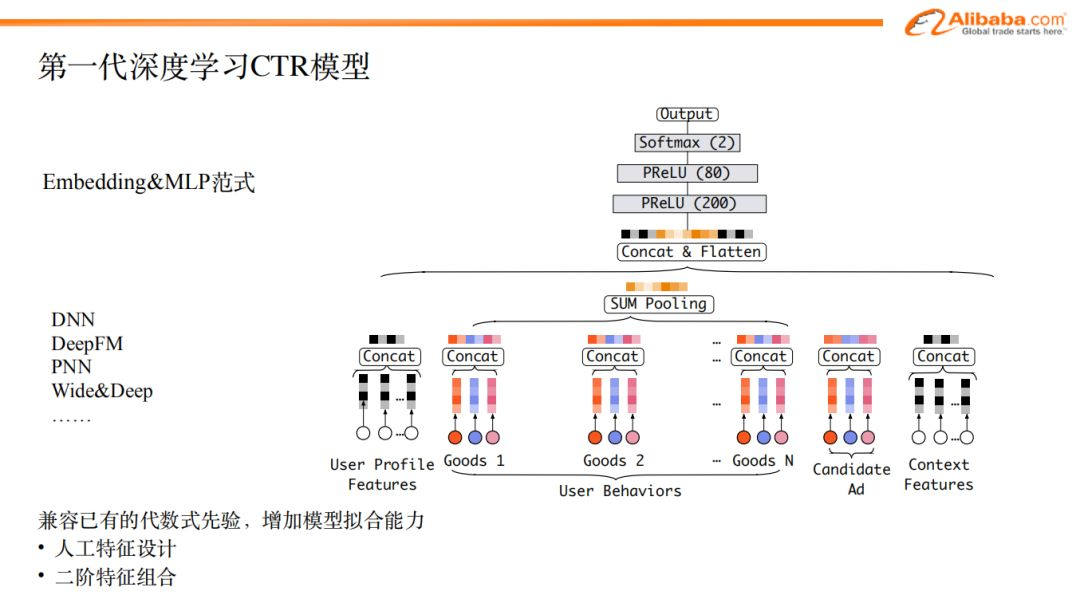
第一代神经网络ctr模型如图所示,第一层是非常简单的原生特征,包括:用户特征,候选广告特征,上下文特征。这些特征在经过lookup的方式做embedding之后,被concat一起,送入多层的dnn网络,最后做一个softmax。这是一个最基础的ctr神经网络模型。
在这种最简单的dnn模型基础之上,衍生出了非常多的其他的模型,比如DeepFm,做一些特征之间的交叉;pnn也是;然后是deep&wide模型,其中的deep部分可以通过多层MLP学习数据中的非线性规律,同时设计了wide部分以复用传统浅层模型时代保留下来的丰富的人工设计特征。
tips:模型演进的路线:增强泛化能力、保留记忆能力、挖掘组合关系。

然而上述通用的设计,还不足以应对我们的业务场景,因为淘宝的用户个性化程度非常高,千人千面,每个人看的东西都不一样,每个人的兴趣点也不一样,行为非常丰富,所以一些简单的神经网络模型,单靠增加人工设计的特征或者简单的代数式先验设计,在我们的场景下太过于低效了,还不足以把用户的兴趣挖掘的特别透彻。
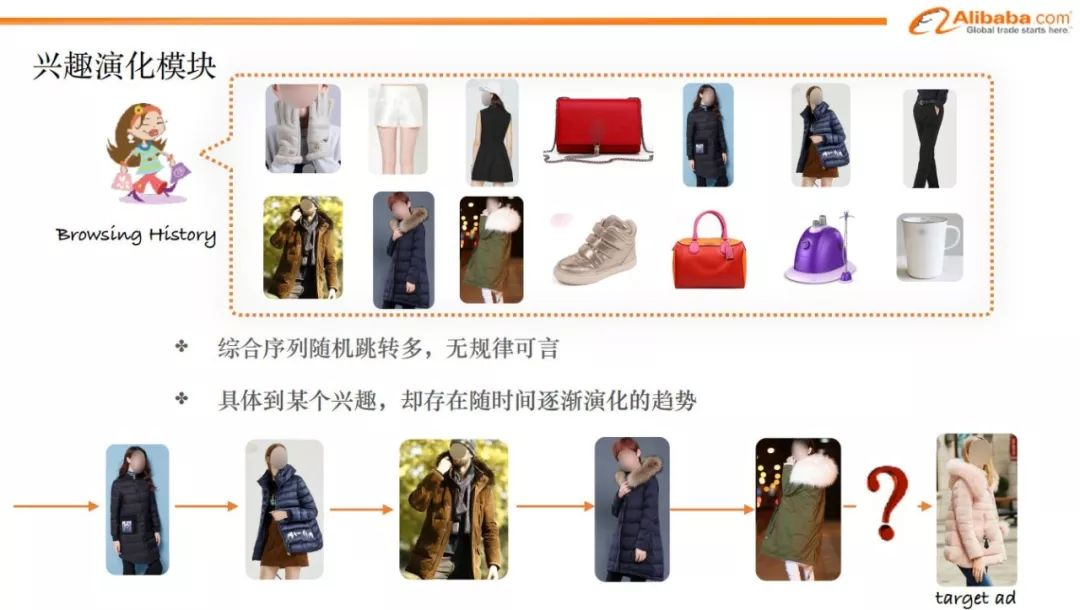
如图所示,根据用户的历史行为,我们看到用户的兴趣点是非常宽泛并且杂乱的。此时,在通用的Embedding&MLP范式下设计出的模型,是无法针对用户丰富多样的兴趣,做出特别操作的,仅仅是把所有行为的Embedding sum在一起作为用户的历史行为表达。而这一操作存在大量信息损失。
tips:这里需要强调的是,用户行为的多样性,反映了用户兴趣的多样性,即每个人感兴趣的物品、种类是很多的,尤其是在淘宝这样综合性的购物网站。
此外,兴趣本身也会随着时间逐渐演化,前面提到的模型对于这种包含演化信息的数据,就更加无能为力了。
tips:大家可以想象一下,自己在网络上购物,比如买衣服的时候,一年前喜欢的风格和现在喜欢的风格可能是不一样的,是存在一个逐渐演变的过程的,如果用前面提出的模型,会把这种逐渐演变的信息丢失掉。
面对这些问题,我们提出了对模型的改造。
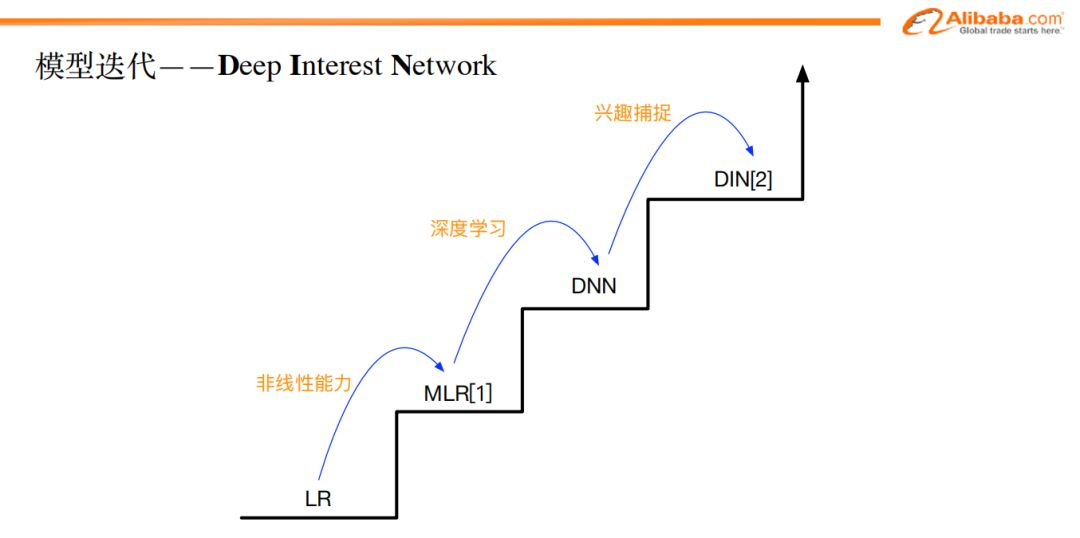
针对用户的兴趣信息的挖掘,我们迈出的第一步对模型的改造是DIN(Deep Interest Network),这是我们在2017年展开的主要工作。

虽然说用户的兴趣是多种多样的,但是我们回过头看一下我们的ctr预估要解决的是什么问题。我们是在给定一个候选广告和用户的情况下,去预测点击的结果。当候选广告给定的时候,我们可以用候选广告去反向激活历史行为中的商品,把跟广告相关的商品拉出来,计算用户的兴趣可能是什么。我们利用了候选广告集,最终通过反向激活挖掘出历史行为中与候选广告相关的兴趣。
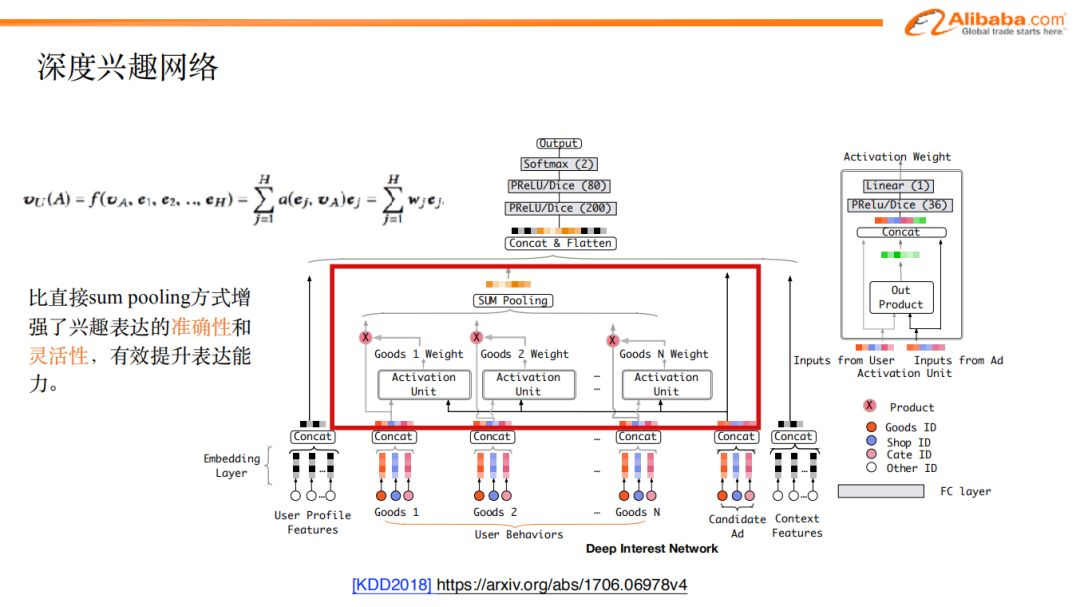
具体的模型设计如图:通过候选广告,用反向激活的方式,与用户历史行为相关联,按照候选广告与历史点击商品的相关性的高低,来赋予历史行为不同的权重。通过这种方式获取到和当前广告相关的历史行为表达向量以及对应的相关权重,做weighted sum pooling之后,就得到了跟候选广告相关的用户兴趣向量表达。这种方式比直接对所有历史行为做sum pooling增加了兴趣表达的灵活性,同时,随着候选广告的不同,该方式也会得到不同的兴趣表达。

如图是一个基于din所得到不同历史行为中包含的广告的权重的例子。候选广告是羽绒服,我们看到历史行为集中衣服相关的广告权重较高,而杯子之类的广告相关性很低。这个例子我们也可以看到din的优点。但是,从刚才的过程中,我们也发现到din还是有一些不足, 这个模型忽略了兴趣随着时间之间演化这样一个重要的性质。
同样一件羽绒服,你会发现以前喜欢的款式和现在喜欢的款式会发生一些变化。

那么在2018年,我们的工作重点就是针对这样一个兴趣随时间演化的特点来进行建模以及模型的改造。
--
由此引出DIEN(Deep Interest Evolution Netowork)。

首先,用户的兴趣随时间演化这样一个特点,做过深度学习的同学们会容易想到序列建模,即把历史行为按时间序列铺开做序列建模。这样一个直观的想法,我们当然也做过尝试,但是效果并不理想。
如图是一个用户的真实足迹,用户在看窗帘,突然买了别的产品;用户在看旅游产品,突然买了猫咪用品。
tips:选购旅游产品的时间线一般拉的比较长,因此选购期间难免会看一些日常的其他商品。
这样一个行为序列是一个杂乱无章的过程,这样的序列与自然语言处理遇到的有序序列是完全不同的,在这样的场景下,序列被打断是一个常规行为。因此单纯的序列建模在这种场景下会失败就不难理解了。用户的兴趣是隐藏在杂乱无章的行为序列背后的,针对这样的情况,我们提出了新的解决方案。

我们已知:用户的兴趣隐藏在行为之后,虽然行为杂乱无章,透过行为,我们发现,其实兴趣的表达要比行为的表达更为稳定的。
当我们提取了兴趣表达之后,还需要对兴趣随时间演化的趋势进行建模。
因此我们将这些问题归纳、抽象、并最终设计了两个模块:兴趣提取模块、兴趣演化模块。
关于兴趣提取模块:

假设用户浏览了一条裤子,那么裤子id是一个特征,该特征对于推荐系统来说是一个较为随机的特征,然而这个id类特征代表的物品的背后,比如用户是喜欢这个裤子的颜色、样式、功能等某些特点,这些特点是我们希望兴趣提取模块可以获取到的,也即,找到与这些随机特征相关联的泛化特征,并进行建模。
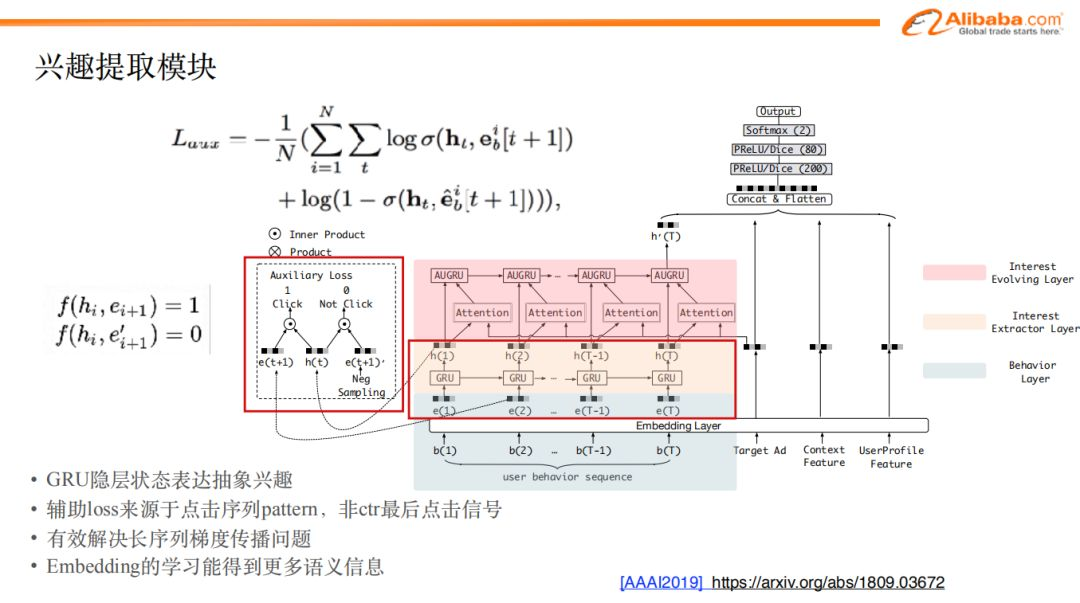
如图我们可以看到,在embedding层之后,我们对用户特征,上下文特征,广告特征的处理方式并没有改变。而行为序列特征做embedding之后,我们增加了兴趣提取模块。
由于我们的目标是挖掘商品背后的兴趣表达,用户某一时刻的兴趣,不仅与当前的行为相关,也与历史各个时刻的行为相关,因此,我们决定使用GRU模型来对历史行为序列建模,并提取兴趣特征。
tips:我们用GRU代替LSTM是因为在效果相差无几的前提下,前者比后者要节省更多的参数。在神经网络模型整体结构非常复杂的大前提下,我们会尽量将每一个模块简单化、轻量化。
通过GRU提取出隐层状态的表达,我们认为这是对用户兴趣的抽象。除了使用GRU之外,我们还引入了辅助loss的功能,用来辅助提取兴趣表达。
tips:引入辅助loss的原因在于:原始的GRU所提取的隐层状态的表达,受到最后时刻的兴趣的影响程度更高一些,而历史时刻的兴趣随着时间越来越远,会被模型慢慢遗忘。辅助loss将所有历史时刻的loss叠加,学习时可以学到更多历史兴趣特征。
并且,由于辅助loss的数据的来源是全网的点击信息,而不仅仅是广告样本的点击,这样会增加很多额外的信息,会更好的刻画用户在全网的兴趣。
辅助loss的作用有三点:
辅助loss的构建方式:我们将历史行为序列中的有点击行为的样本label标记为1,有曝光无点击行为的样本label标记为0并进行负采样,组合后送入GRU模型,并构建辅助的loss信号,与最终的loss相加后进行学习。
在兴趣演化模块,回想我们的业务场景,有两点值得注意:
那么我们有没有办法使我们的模型可以有区别对待这些历史行为,然后只关注与候选广告相关性较强演化。这就是兴趣演化模块引入的背景。
现在的状态如下:
此刻,我们开始针对性的对演化过程进行建模。
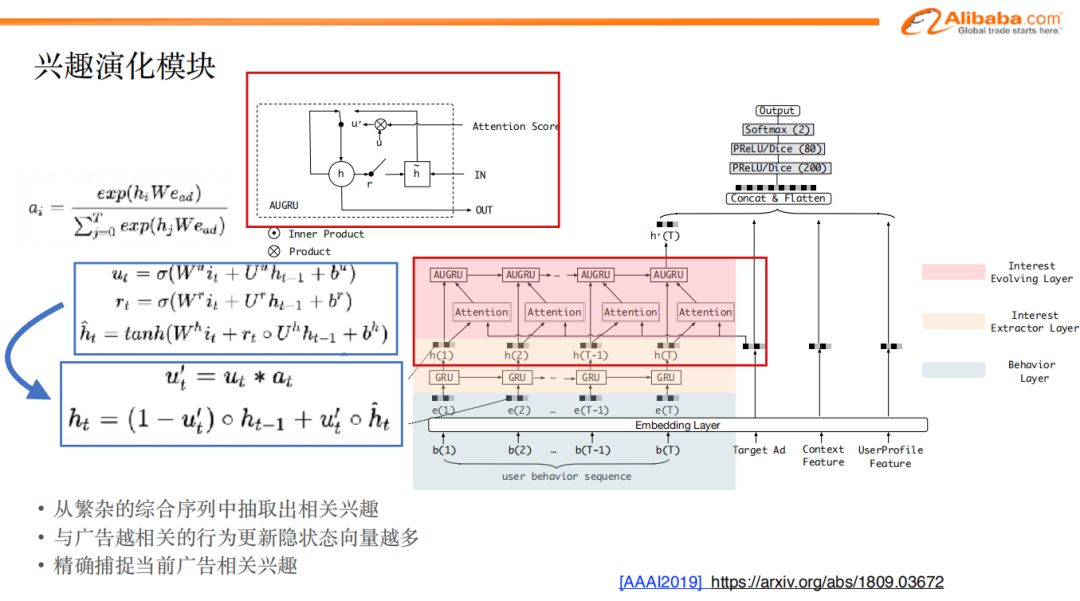
首先是加入attention机制,根据与候选广告的相关性,对历史序列里的商品进行加权;以此得到attention score。
在attention机制之后,再加入一层改进的GRU,称之为AUGRU。
tips:引入该模型的原因在于,在AUGRU里面,我们使用attention score来控制update门的权重,这样既保留了原始的更新方向,又能根据与候选广告的相关程度来控制隐层状态的更新力度。
举个极端的例子:假如该时刻的行为与候选广告相关度为1,我们希望这个行为能更新用户兴趣的隐状态即h(t)=f(h(t-1), i_t),而当行为与候选广告不相关的时候我们要保留当前状态,即:h(t)=h(t-1)。
假如我们不采用这种改进的GRU方式,而直接把attention score乘在每个兴趣向量上作为下一层普通GRU的输入的话, 这种做法会直接影响了输入的scale,而不是准确的控制什么时候该更新,更新的程度和方向是怎么样的,因此可能存在信息的损失。
还是举个极端的例子:假如某行为与候选广告不相关,那么隐状态的更新是h(t)=f(h(t-1), 0), 0向量并不会不更新,而是会将hidden state更新到一个新的地方去,这并不是我们期望的。
通过attention机制,我们得以从繁杂的商品中选取相关的兴趣,并通过AUGRU模型,最终更精准的得到广告的相关兴趣。
--
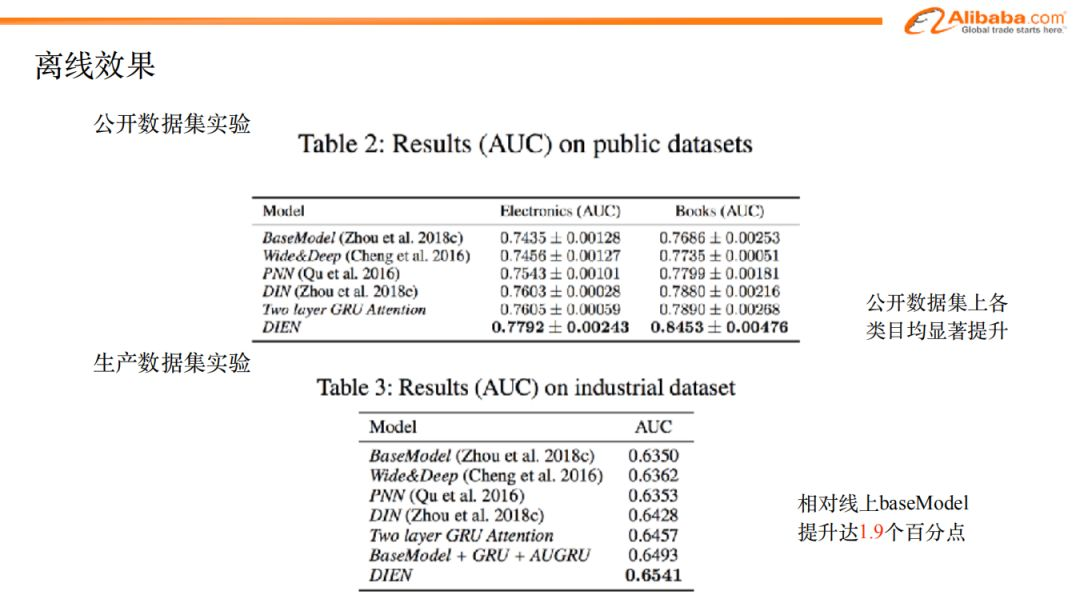
最后,我们给大家介绍一下实际的效果。这个模型不仅在生产任务上取得了良好的效果,在学术界也取得了不错的成果。
如图,上半部分是我们在公开数据集(来自于亚马逊商城)上所做的实验。我们对电子产品、书籍两个类目的数据用不同的模型做了实验。可以看出来,DIEN模型的效果是最好的。
图中下半部分是生产任务数据集的实验,我们采用了和公开数据集相同的模型,图中也可以看出,DIEN在列出的模型中,表现也是最优的,而且相对base_model,AUC提升了1.9个百分点。
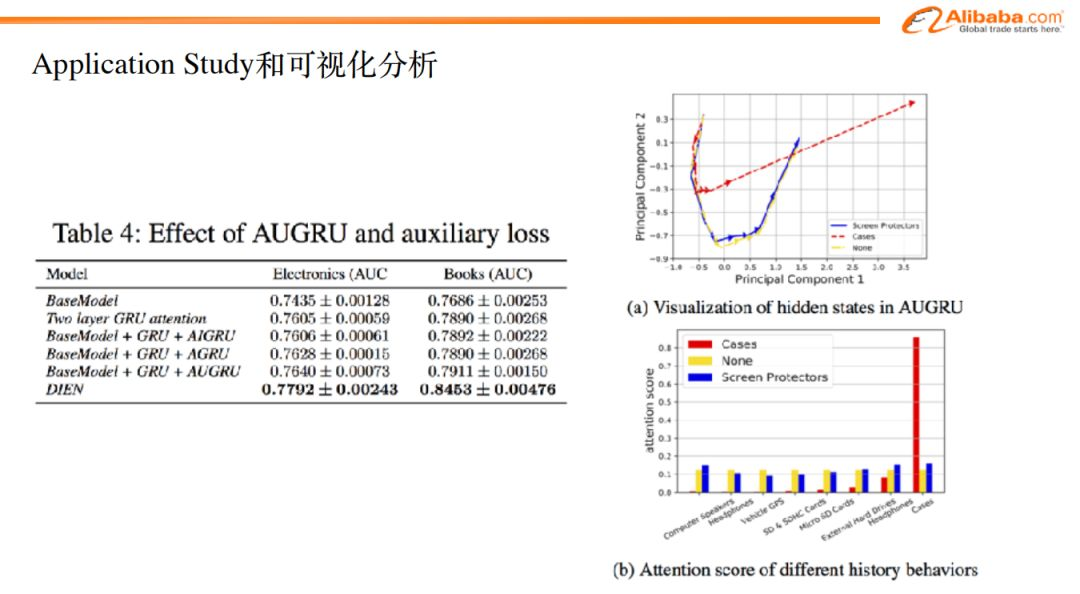
在公开数据集上,我们将不同步骤进行了拆分,可以看到每个模块的提升效果。

我们通过A/B test 观察了一个月的数据,平均带来了17%的ecpm提升,带来了巨大的商业价值。
今天的分享就到这里,谢谢大家。
阅读更多技术原创文章,请关注微信公众号“DataFunTalk”。
本文首发于微信公众号“DataFunTalk”。
我想使用spawn(针对多个并发子进程)在Ruby中执行一个外部进程,并将标准输出或标准错误收集到一个字符串中,其方式类似于使用Python的子进程Popen.communicate()可以完成的操作。我尝试将:out/:err重定向到一个新的StringIO对象,但这会生成一个ArgumentError,并且临时重新定义$stdxxx会混淆子进程的输出。 最佳答案 如果你不喜欢popen,这是我的方法:r,w=IO.pipepid=Process.spawn(command,:out=>w,:err=>[:child,:out])
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭10年前。使用Railsv2.1,假设您有一个可从多个位置访问的Controller的操作。例如,在Rails应用程序中,您有一个链接可以从两个不同的View编辑用户,一个在用户索引View中,另一个在另一个View中(比方说从每个页面上的导航栏)。我想知道根据用户点击的链接将用户重定向回正确位置的最佳方法是什么。例如:示例1:列出所有用户点击列表中用户的“编辑”
我正在使用一个用RubyonRails构建的应用程序,目前错误处理非常差。如果通过ajax执行Controller方法,并且该方法导致500(或404或任何其他响应),则呈现500.html页面并将其作为AJAX请求的结果返回。显然,javascript不知道如何处理该HTML,网页看起来只是在等待响应。在AJAX调用期间发生错误时,rails是否有一种简单的方法来呈现error.rjs模板? 最佳答案 您可以在Controller的rescue_action或rescue_action_in_public方法中使用respond_
三大公有云厂商,香港地区主机测评一、ping时延比对(厦门电信本地测试):Ping时延测试腾讯云阿里云华为云延迟率最低时延44ms,最高72ms,平均46ms47.242段:最低时延59ms,最高204ms,平均107ms最低时延45ms,最高93ms,平均47ms丢包率丢包率小有的ip段丢包率较大每个段都会有概率丢包阿里云:47.242段:最低时延59ms,最高204ms,平均107ms,有的ip段丢包率较大8.210段:最低时延64ms,最高232ms,平均119ms,丢包率较好腾讯云:最低时延44ms,最高72ms,平均46ms,丢包率小华为云:最低时延45ms,最高93ms,平均47m
WAF可以对网站进行扫描,识别API漏洞。API安全如何设置API安全_Web应用防火墙-阿里云帮助中心API安全如何划分API业务用途?登录认证手机验证码认证数据保存数据查询数据导出数据分享数据更新数据删除数据增加下线注销信息发送信息认证邮件信息发送邮箱验证码认证账号密码认证账号注册API安全支持检测哪些敏感数据?敏感数据级别敏感数据类型非敏感数据(N)不涉及。特级敏感数据(L0)与一级敏感数据(L1)或二级敏感数据(L2)相同。单次响应中一级敏感数据(L1)较多时,升级为特级敏感数据(L0)。单次响应中二级敏感数据(L2)较多时,升级为一级敏感数据(L1)或特级敏感数据(L0)。一级敏感数
我们想要一个Controller集合,我们将所有操作和下游方法的记录器输出路由到一个单独的日志文件。这是一个Rails3项目。在Rails2中,我们通过重新定义“logger”方法来做到这一点,但在Rails3中,记录的方式是使用“Rails.logger”。我试着把Rails::logger=Logger.new(File.join(Rails.root,'log',"reports_controller.log"),10,1000000)在Controller的顶部,但只有在操作中专门使用Rails.logger的特定情况才会发送到指定的日志文件,Controller的所有默认日志
在bash中,这给出了预期顺序的输出:ruby-e"puts'one';raise'two'"one-e:1:in`':two(RuntimeError)但是如果我将STDERR重定向到STDOUT,我会在输出之前收到错误,这是我不想要的:ruby-e"puts'one';raise'two'"2>&1|cat-e:1:in`':two(RuntimeError)one我想将输出重定向到一个文本文件(它的行为方式与上面的cat相同)并获得输出和异常,但顺序与查看我的输出时的顺序相同终端。这能实现吗? 最佳答案 发生这种情况是因为行缓