谱减法 (Spectral Subtraction) 是最早出现的语音增强算法之一,由于实现简单且实时性较好,获得了广泛的应用。它假设语音和噪声是加性混合,且噪声是缓慢变化的,通过在静音段估计和更新噪声频谱,从带噪语音谱中减去噪声来增强语音。
设
y
(
n
)
y(n)
y(n) 为带噪语音信号,由纯净语音信号
x
(
n
)
x(n)
x(n) 和 噪声信号
d
(
n
)
d(n)
d(n) 混合形成
y
(
n
)
=
x
(
n
)
+
d
(
n
)
y(n)=x(n)+d(n)
y(n)=x(n)+d(n)
对等式两边做傅里叶变换转换到频域
Y
(
ω
)
=
X
(
ω
)
+
D
(
ω
)
Y(\omega)=X(\omega)+D(\omega)
Y(ω)=X(ω)+D(ω)
Y
(
ω
)
Y(\omega)
Y(ω)也可以表示成极坐标形式
Y
(
ω
)
=
∣
Y
(
ω
)
∣
e
j
ϕ
y
(
ω
)
Y(\omega)=|Y(\omega)|e^{j\phi_{y}(\omega)}
Y(ω)=∣Y(ω)∣ejϕy(ω)
其中
∣
Y
(
ω
)
∣
|Y(\omega)|
∣Y(ω)∣为幅度谱,
ϕ
y
(
ω
)
\phi_{y}(\omega)
ϕy(ω)为相位谱,
D
(
ω
)
D(\omega)
D(ω)也可以表示成
D
(
ω
)
=
∣
D
(
ω
)
∣
e
j
ϕ
d
(
ω
)
D(\omega)=|D(\omega)|e^{j\phi_{d}(\omega)}
D(ω)=∣D(ω)∣ejϕd(ω),谱减法是在幅度谱上进行的,
∣
D
(
ω
)
∣
|D(\omega)|
∣D(ω)∣无法获得,但是可以用静音段(无语音活动的片段)的平均频谱进行估计和更新,由于相位对于语音的可懂度和质量影响较小,所以用带噪相位
ϕ
y
(
ω
)
\phi_{y}(\omega)
ϕy(ω)来代替,纯净语音谱的估计为
X
^
(
ω
)
=
(
∣
Y
(
ω
)
∣
−
∣
D
^
(
ω
)
∣
)
e
j
ϕ
y
(
ω
)
\hat{X}(\omega)=(|Y(\omega)|-|\hat{D}(\omega)|)e^{j\phi_{y}(\omega)}
X^(ω)=(∣Y(ω)∣−∣D^(ω)∣)ejϕy(ω)
对估计结果做傅里叶逆变换即可得到增强后的语音。上述的
∣
Y
(
ω
)
∣
−
∣
D
^
(
ω
)
∣
|Y(\omega)|-|\hat{D}(\omega)|
∣Y(ω)∣−∣D^(ω)∣过程可能会产生负的幅度值,这显然是有问题的,早期的做法是通过半波整流将负值直接置零
∣
X
^
(
ω
)
∣
=
{
∣
Y
(
ω
)
∣
−
∣
D
^
(
ω
)
∣
if
∣
Y
(
ω
)
∣
>
∣
D
^
(
ω
)
∣
0
else
|\hat{X}(\omega)|=\begin{cases} |Y(\omega)|-|\hat{D}(\omega)| & \text{ if } |Y(\omega)|>|\hat{D}(\omega)| \\ 0 & \text{ else } \end{cases}
∣X^(ω)∣={∣Y(ω)∣−∣D^(ω)∣0 if ∣Y(ω)∣>∣D^(ω)∣ else
谱减法可以拓展到功率谱,假定
d
(
n
)
d(n)
d(n)为零均值,且
d
(
n
)
d(n)
d(n)和
x
(
n
)
x(n)
x(n)不相关,由幅度谱减公式两边平方,去掉交叉项后得到
∣
X
^
(
ω
)
∣
2
=
∣
Y
(
ω
)
∣
2
−
∣
D
^
(
ω
)
∣
2
|\hat{X}(\omega)|^{2}=|Y(\omega)|^{2}-|\hat{D}(\omega)|^{2}
∣X^(ω)∣2=∣Y(ω)∣2−∣D^(ω)∣2
∣
X
^
(
ω
)
∣
2
|\hat{X}(\omega)|^{2}
∣X^(ω)∣2也可能出现负值,可用前述的半波整流方法处理,上式也可以写成:
∣
X
^
(
ω
)
∣
2
=
H
2
(
ω
)
∣
Y
(
ω
)
∣
2
|\hat{X}(\omega)|^{2}=H^{2}(\omega)|Y(\omega)|^{2}
∣X^(ω)∣2=H2(ω)∣Y(ω)∣2
其中
H
(
ω
)
=
1
−
∣
D
^
(
ω
)
∣
2
∣
Y
(
ω
)
∣
2
H(\omega)=\sqrt{1-\frac{|\hat{D}(\omega)|^{2}}{|Y(\omega)|^{2}} }
H(ω)=1−∣Y(ω)∣2∣D^(ω)∣2
H
(
ω
)
H(\omega)
H(ω)为增益函数或抑制函数,取值范围为
0
≤
H
(
ω
)
≤
1
0\le H(\omega) \le 1
0≤H(ω)≤1。
综上,谱减法更通用的形式可定义为
∣
X
^
(
ω
)
∣
p
=
∣
Y
(
ω
)
∣
p
−
∣
D
^
(
ω
)
∣
p
|\hat{X}(\omega)|^{p}=|Y(\omega)|^{p}-|\hat{D}(\omega)|^{p}
∣X^(ω)∣p=∣Y(ω)∣p−∣D^(ω)∣p
谱减法最显著的缺点是会引入“音乐噪声”,由于谱减过程中可能出现负的幅度值,半波整流是一种直接的解决办法,但是这种非线性处理会导致频谱随机频率位置上出现小的、独立的峰值,在时域中表现为明显的多频颤音,也称为“音乐噪声”。如果处理不当,在某些语音段,“音乐噪声”的影响甚至比干扰噪声更为明显。造成“音乐噪声”的常见原因有:
为了减小音乐噪声,学者们提出了一系列的改进方法,感兴趣的读者可以自行了解。这里介绍Boll使用的方法,相比直接置零,该方法设置了一个谱值下限。在噪声估计阶段,计算一个最大噪声帧,如果谱减后某时频点的值小于最大噪声帧的对应频点值,则将其替换为相邻帧的最小值。具体可表示为:
∣
X
i
^
(
ω
)
∣
=
{
∣
Y
i
(
ω
)
∣
−
∣
D
^
(
ω
)
∣
if
∣
Y
i
(
ω
)
∣
−
∣
D
^
(
ω
)
∣
>
m
a
x
∣
D
^
(
ω
)
∣
min
j
=
i
−
1
,
i
,
i
+
1
∣
X
i
^
(
ω
)
∣
else
|\hat{X_{i}}(\omega)|=\begin{cases} |Y_{i}(\omega)|-|\hat{D}(\omega)| & \text{ if } |Y_{i}(\omega)|-|\hat{D}(\omega)| > max|\hat{D}(\omega)| \\ \underset{j=i-1,i,i+1}{\min} |\hat{X_{i}}(\omega)| & \text{ else } \end{cases}
∣Xi^(ω)∣={∣Yi(ω)∣−∣D^(ω)∣j=i−1,i,i+1min∣Xi^(ω)∣ if ∣Yi(ω)∣−∣D^(ω)∣>max∣D^(ω)∣ else
其中
∣
X
i
^
(
ω
)
∣
|\hat{X_{i}}(\omega)|
∣Xi^(ω)∣表示第i帧估计得到的增强谱,该方法的思想在于检测到当前帧能量较低时,则保持语音信息,因此可以减小音乐噪声。但由于需要用到下一帧的信息,该方法的实时性会降低。
这里给出Boll改进方法的matlab仿真代码。数据采样率为8kHz,噪声类型为白噪声,输入信噪比5dB。
addpath('./STFT')
clc
clear all
close all
[x,fs]=audioread('s2.wav'); %读取纯净语音信号
[d,fs]=audioread('white.wav'); %读取噪声信号
x=x(1:fs*10);
d=d(1:fs*10);
nfft=256;
stepsize=0.5;
snr=5;
d=sqrt(norm(x)^2/(10^(snr/10)*norm(d)^2))*d; %考虑信噪比
y=[zeros(fs*1,1);x(1:fs*9)]+d(1:fs*10); %生成带噪信号,前1s 为纯噪声段
Y=stft(y,nfft,stepsize*nfft,1);%带噪信号的时频谱
Ya=abs(Y);%幅度谱
Yp=angle(Y);%相位谱
Xa=zeros(size(Ya));
%带噪语音谱平滑
Ys=Ya;
for i=2:(size(Ya,2)-1)
Ys(:,i)=(Ya(:,i-1)+Ya(:,i)+Ya(:,i+1))/3;
end
N=mean(Ya(:,1:10),2); %噪声谱初始化 使用前0.32s的纯噪声段
N_max=zeros(size(N)); %最大噪声残留初始化
alpha=0.9;%噪声谱更新 平滑系数
beta=0.03;
%静音段噪声谱估计和更新
for i=1:floor(fs/256)
N=alpha*N+(1-alpha)*Ya(:,i);
N_max=max(N_max,Ya(:,i)-N);
Xa(:,i)=beta*Ya(:,i);
end
%带噪语音段降噪
for i=(floor(fs/256)+1):size(Y,2)-1
X1=Ys(:,i)-N; %语音谱的初始估计
for j =1:length(X1)
if X1(j)<N_max(j)
X1(j)=min(X1(j),min(Ys(j,i-1)-N(j),Ys(j,i+1)-N(j)));
end
end
Xa(:,i)=max(X1,0);
end
Xa(:,end)=max(Ys(:,end)-N,0);
%反变换得到增强语音
X=Xa.*exp(1i*Yp);
x_est=istft(X,nfft,stepsize*nfft,1);
figure
subplot(311)
plot((0:length(x)-1)/fs,[zeros(fs,1);x(1:fs*9)]);
title('纯净语音')
subplot(312)
plot((0:length(y)-1)/fs,y);
title('带噪语音')
subplot(313)
plot((0:length(x_est)-1)/fs,x_est);
title('增强语音')
figure
subplot(311)
spectrogram(x(1:fs*9),hann(256),50,256,fs,'yaxis')
title('纯净语谱图')
subplot(312)
spectrogram(y(fs+1:end),hann(256),50,256,fs,'yaxis')
title('带噪语谱图')
subplot(313)
spectrogram(x_est(fs+1:end),hann(256),50,256,fs,'yaxis')
title('增强语谱图')
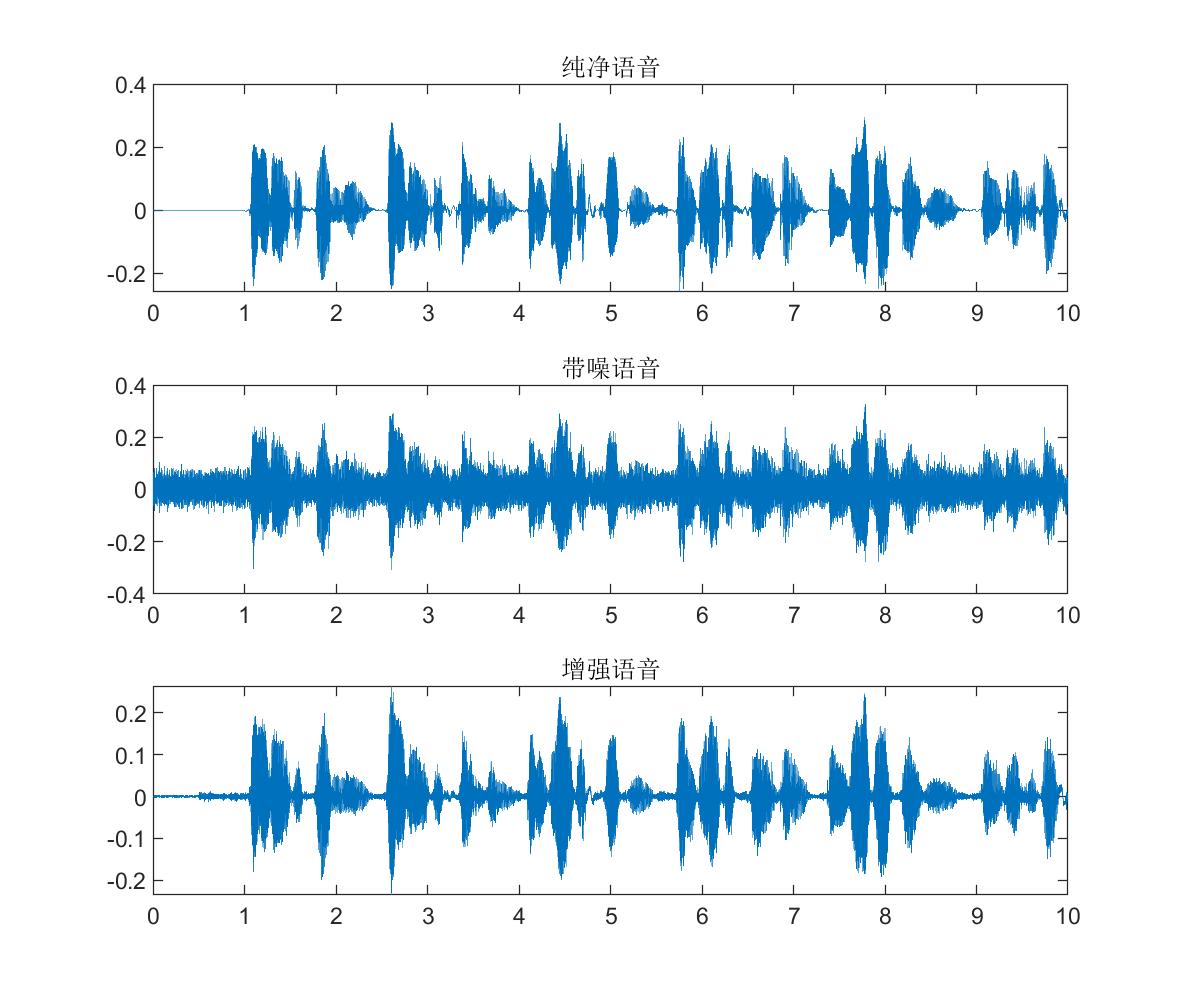
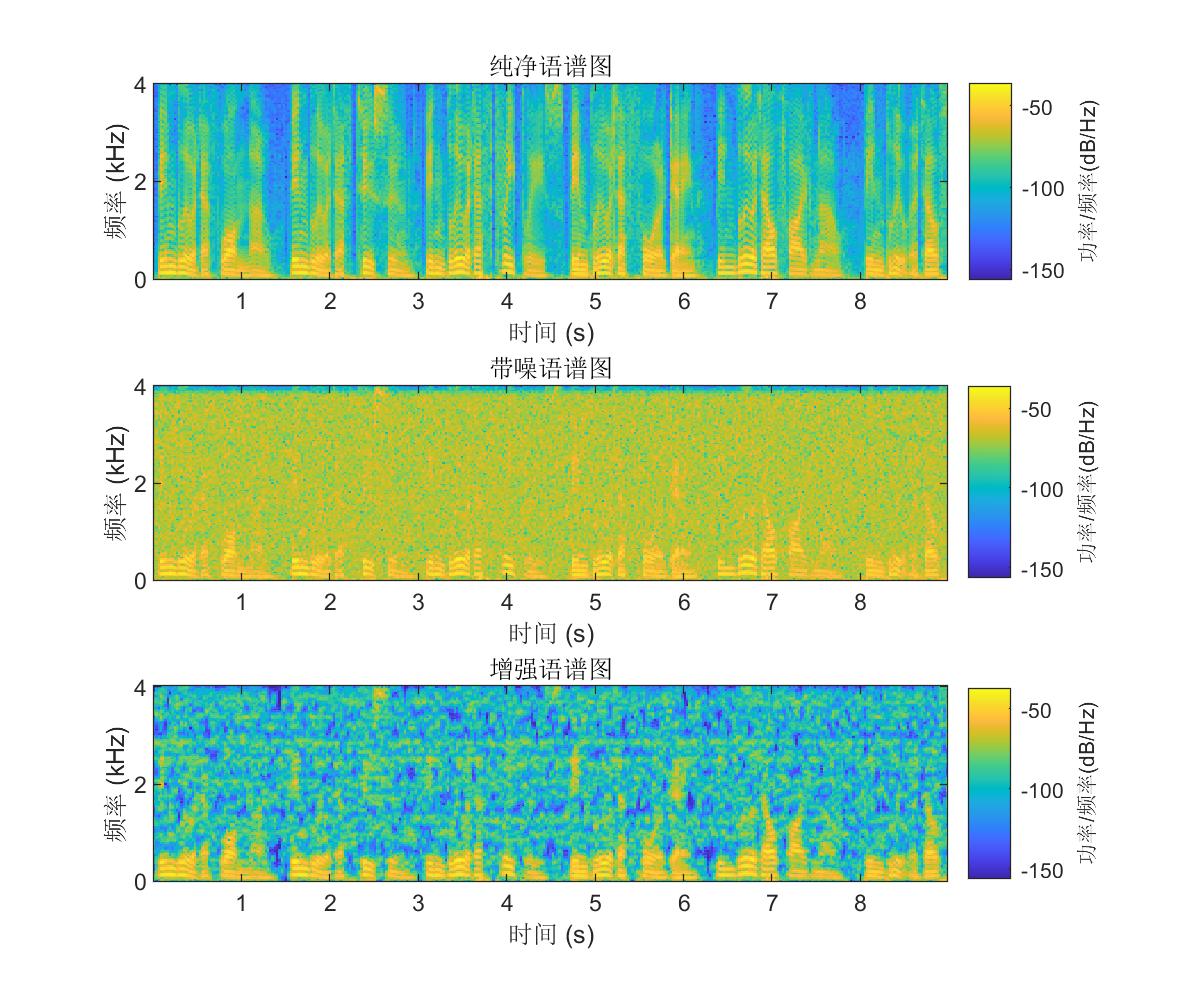
由图中可以看出纯净语音的时域波形有明显的谐波细节,语谱图的能量主要集中在低频;添加噪声污染后,语音的波形细节被淹没,语谱图时频点也变得模糊;经过谱减法增强后,波形得到了明显的恢复,语谱图的噪声点被抑制,同时低频特征得到了保留,不过中高频的一些本属于语音的时频点也有不同程度的削减,也就是常说的语音失真。如何最大程度的抑制噪声,同时减小失真,是语音增强的一大难点,也是学者们不断研究的方向。
[1] Philipos C.Loizou. 语音增强:理论与实践:theory and practice[M]. 电子科技大学出版社, 2012.
[2] Boll S. Suppression of acoustic noise in speech using spectral subtraction[J]. IEEE Transactions on acoustics, speech, and signal processing, 1979, 27(2): 113-120
当我调用Array#-时,它似乎没有对我正在比较的字符串调用任何比较方法:classStringdef(v)puts"#{self}#{v}"super(v)enddef==(v)puts"#{self}==#{v}"super(v)enddef=~(v)puts"#{self}=~#{v}"super(v)enddef===(v)puts"#{self}==#{v}"super(v)enddefeql?(v)puts"#{self}.eql?#{v}"super(v)enddefequal?(v)puts"#{self}.equal?#{v}"super(v)enddefhash()
我在lib/tasks/foo.rake中有这个:Rake::Task["assets:precompile"].enhancedoprint">>>>>>>>hellofromprecompile"endRake::Task["assets:precompile:nondigest"].enhancedoprint">>>>>>>>hellofromprecompile:nondigest"end当我在本地运行rakeassets:precompile时,两条消息都会被打印出来。当我推送到heroku时,只打印非摘要消息。然而,accordingtothebuildpack,推送正在
我需要减去两个DateTime对象,以便找出它们之间的小时差。我尝试执行以下操作:a=DateTime.new(2015,6,20,16)b=DateTime.new(2015,6,21,16)putsa-b我得到(-1/1),Rational类的对象。那么,问题是,我如何找出两个日期之间的区别?数小时或数天,或其他时间。当我像那样减去DateTimes时,这个Rational意味着/代表什么?顺便说一句:当我尝试用相差1年的时间减去DateTime时,我得到(366/1),所以当我执行(366/1).to_i,我得到天数。但是,当我尝试用相差1小时的时间减去两个DateTime时,得
Ruby中规范的Array差异示例是:[1,1,2,2,3,3,4,5]-[1,2,4]#=>[3,3,5]获得以下行为的最佳方法是什么?[1,1,2,2,3,3,4,5].subtract_once([1,2,4])#=>[1,2,3,3,5]也就是说,只有第二个数组中每个匹配项的第一个实例从第一个数组中移除。 最佳答案 减去值在另一个数组或任何Enumerable中出现的次数:classArray#Subtracteachpassedvalueonce:#%w(1231).subtract_once%w(112)#=>["3"]
我被以下的joda-timeAPI宠坏了:DateTimenow=newDateTime();DateTimeninetyDaysAgo=now.minusDays(90);我正尝试在Ruby中做类似的事情,但我是now=Time.nowninetyDaysAgo=now-(90*24)但是,数学不在这里(我真的在午夜处理日期)。是否有用于日期减法的友好API? 最佳答案 require'date'now=Date.todayninety_days_ago=(now-90)通过IRB控制台运行这个我得到:>>require'date
目前,我正在制作一个简单的应用程序,其中使用语音合成API来朗读文本。我想在说话时突出显示单词(粗体)。我目前有一个非常基本的实现,使用'onboundary'事件来执行此操作。但是,我想知道是否有更好/更好的方法,因为我的实现是基于一些假设。varwords;varwordIdx;vartext;varutterance=newSpeechSynthesisUtterance();utterance.lang='en-UK';utterance.rate=1;window.onload=function(){document.getElementById('textarea').in
我目前正在尝试创建自己的J.A.R.V.I.S系统作为网络应用程序。所以当然,就像任何好的J.A.R.V.I.S系统一样,它需要良好的语音识别。我进行了研究,试图找到一个我可以根据需要自定义的JavaScript语音识别API,并决定使用Annyang。(很简单,效果很好)我花了一些时间试用它,就在我认为它可以正常工作时,我遇到了一个问题。当我尝试在本地查看该文件时它不起作用,所以我将它与MAMP一起托管在我的计算机上以查看它是否有效。它出现了一个对话框,上面写着“本地主机想要访问麦克风”,但是当我点击允许时,它又出现了。它不断出现并且不会消失,直到我单击拒绝。我正在使用以下代码:if
我正在研究Angular库并寻找一种使用装饰器模式扩展指令的方法:angular.module('myApp',[]).decorator('originaldirectiveDirective',['$delegate',function($delegate){varoriginalLinkFn;originalLinkFn=$delegate[0].link;return$delegate;}]);使用此模式扩充原始指令的最佳方式是什么?(示例用法:在不直接修改其代码的情况下对指令进行额外的监视或额外的事件监听器)。 最佳答案
我有两个文本框分别接受StartDate和EndDate,格式为YYYY/MM/DD。如果用户选择的结束日期超过开始日期50天,我需要提醒他。这是我目前所拥有的:varstartDate=newDate(document.getElementsByName('MYSTARTDATE').value);varendDate=newDate(document.getElementsByName('MYENDDATE').value);if((endDate-startDate)>50){alert('Enddateexceedsspecification');returnfalse;}举个
我有两套。Setb是Seta的子集。它们都是非常大的集合。我想从a中减去b,执行此常见操作的最佳做法是什么?我写过很多这样的代码,但我觉得效率不高。你有什么想法?伪代码:(这不是JavaAPI)。for(inti=0;i我想找到一种算法,不仅适用于集合,也适用于数组。编辑:这里的Set不是JAVAAPI,它是一个数据结构。所以我不关心JavaAPI是否有removeAll()方法,我想为这个问题找到一个通用的解决方案,我在使用Javascript和Actionscript时遇到过很多这样的问题。 最佳答案 我认为您不会更快地获得