链表在内存中的存储
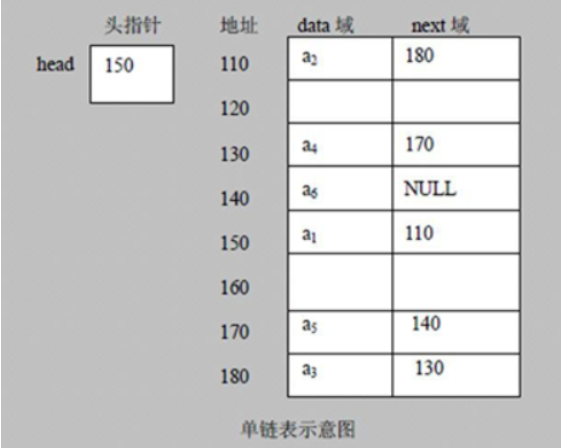
特点
带头结点的逻辑示意图
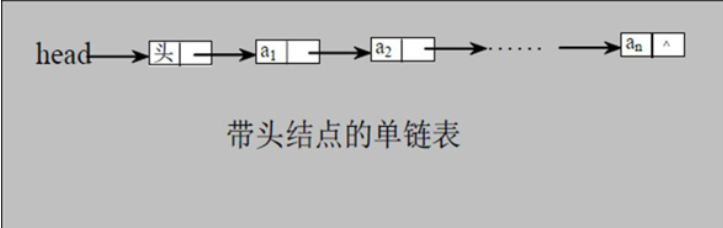
创建(添加)
遍历
有序插入
根据某个属性节点修改值
删除某个节点
求倒数第n个节点的信息
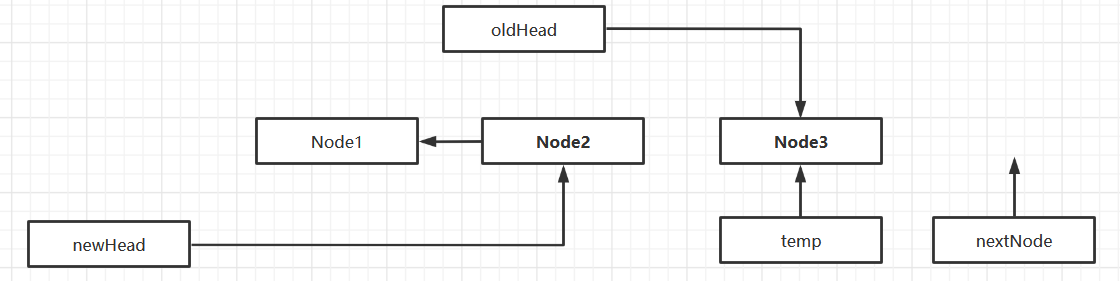
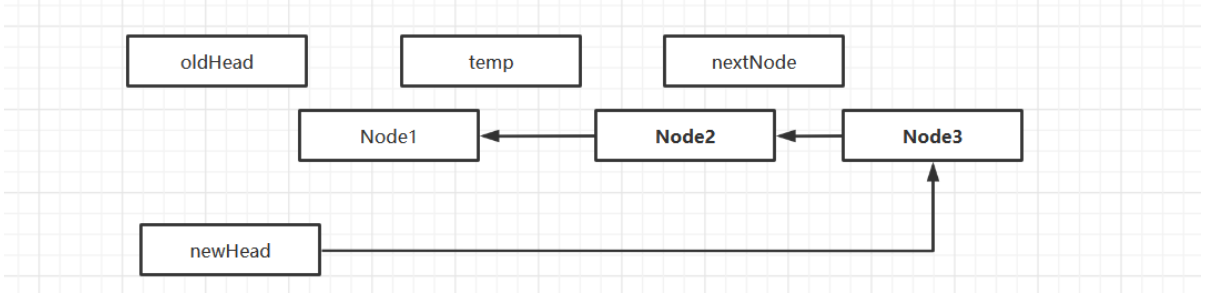
翻转链表
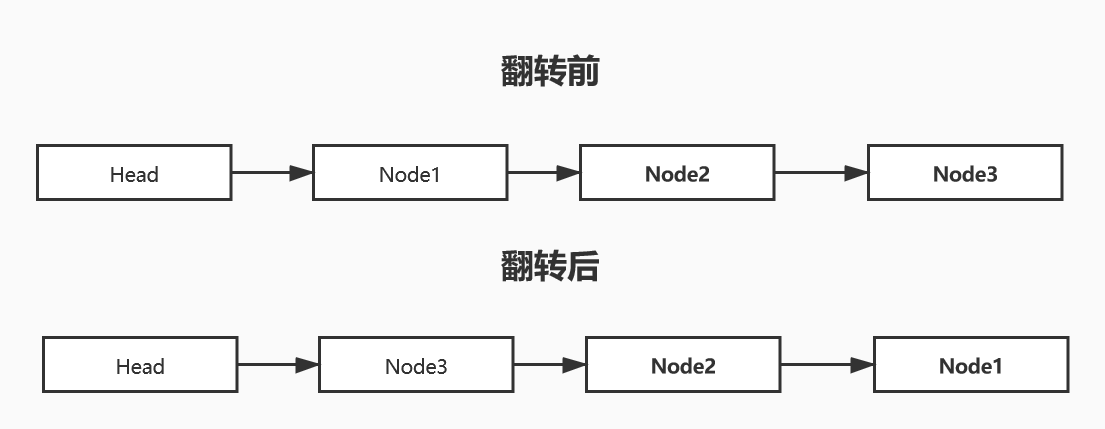


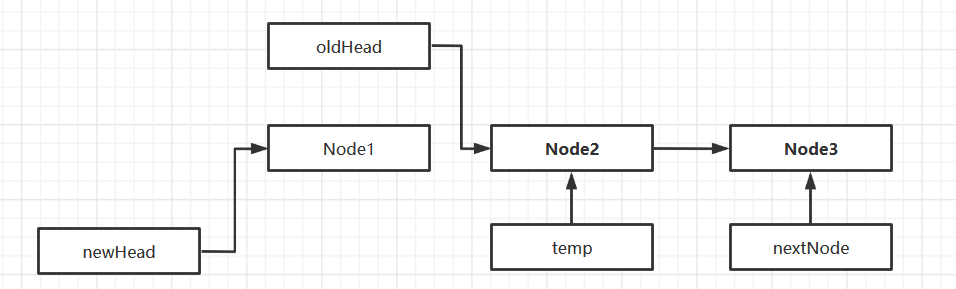
逆序打印
代码
public class Demo1 {
public static void main(String[] args) {
LinkedList linkedList = new LinkedList();
linkedList.traverseNode();
System.out.println();
//创建学生节点,并插入链表
StudentNode student1 = new StudentNode(1, "Nyima");
StudentNode student3 = new StudentNode(3, "Lulu");
linkedList.addNode(student1);
linkedList.addNode(student3);
linkedList.traverseNode();
System.out.println();
//按id大小插入
System.out.println("有序插入");
StudentNode student2 = new StudentNode(0, "Wenwen");
linkedList.addByOrder(student2);
linkedList.traverseNode();
System.out.println();
//按id修改学生信息
System.out.println("修改学生信息");
student2 = new StudentNode(1, "Hulu");
linkedList.changeNode(student2);
linkedList.traverseNode();
System.out.println();
//根据id删除学生信息
System.out.println("删除学生信息");
student2 = new StudentNode(1, "Hulu");
linkedList.deleteNode(student2);
linkedList.traverseNode();
System.out.println();
//获得倒数第几个节点
System.out.println("获得倒数节点");
System.out.println(linkedList.getStuByRec(2));
System.out.println();
//翻转链表
System.out.println("翻转链表");
LinkedList newLinkedList = linkedList.reverseList();
newLinkedList.traverseNode();
System.out.println();
//倒叙遍历链表
System.out.println("倒序遍历链表");
newLinkedList.reverseTraverse();
}
}
/**
* 创建链表
*/
class LinkedList {
//头节点,防止被修改,设置为私有的
private StudentNode head = new StudentNode(0, "");
/**
* 添加节点
* @param node 要添加的节点
*/
public void addNode(StudentNode node) {
//因为头节点不能被修改,所以创建一个辅助节点
StudentNode temp = head;
//找到最后一个节点
while (true) {
//temp是尾节点就停止循环
if(temp.next == null) {
break;
}
//不是尾结点就向后移动
temp = temp.next;
}
//现在temp是尾节点了,再次插入
temp.next = node;
}
/**
* 遍历链表
*/
public void traverseNode() {
System.out.println("开始遍历链表");
if(head.next == null) {
System.out.println("链表为空");
}
//创建辅助节点
StudentNode temp = head.next;
while(true) {
//遍历完成就停止循环
if(temp == null) {
break;
}
System.out.println(temp);
temp = temp.next;
}
}
/**
* 按id顺序插入节点
* @param node
*/
public void addByOrder(StudentNode node) {
//如果没有首节点,就直接插入
if(head.next == null) {
head.next = node;
return;
}
//辅助节点,用于找到插入位置和插入操作
StudentNode temp = head;
//节点的下一个节点存在,且它的id小于要插入节点的id,就继续下移
while (temp.next!=null && temp.next.id < node.id) {
temp = temp.next;
}
//如果temp的下一个节点存在,则执行该操作
//且插入操作,顺序不能换
if(temp.next != null) {
node.next = temp.next;
}
temp.next = node;
}
/**
* 根据id来修改节点信息
* @param node 修改信息的节点
*/
public void changeNode(StudentNode node) {
if(head == null) {
System.out.println("链表为空,请先加入该学生信息");
return;
}
StudentNode temp = head;
//遍历链表,找到要修改的节点
while (temp.next!= null && temp.id != node.id) {
temp = temp.next;
}
//如果temp已经是最后一个节点,判断id是否相等
if(temp.id != node.id) {
System.out.println("未找到该学生的信息,请先创建该学生的信息");
return;
}
//修改学生信息
temp.name = node.name;
}
/**
* 根据id删除节点
* @param node 要删除的节点
*/
public void deleteNode(StudentNode node) {
if(head.next == null) {
System.out.println("链表为空");
return;
}
StudentNode temp = head.next;
//遍历链表,找到要删除的节点
if(temp.next!=null && temp.next.id!=node.id) {
temp = temp.next;
}
//判断最后一个节点的是否要删除的节点
if(temp.next.id != node.id) {
System.out.println("请先插入该学生信息");
return;
}
//删除该节点
temp.next = temp.next.next;
}
/**
* 得到倒数的节点
* @param index 倒数第几个数
* @return
*/
public StudentNode getStuByRec(int index) {
if(head.next == null) {
System.out.println("链表为空!");
}
StudentNode temp = head.next;
//用户记录链表长度,因为head.next不为空,此时已经有一个节点了
//所以length初始化为1
int length = 1;
while(temp.next != null) {
temp = temp.next;
length++;
}
if(length < index) {
throw new RuntimeException("链表越界");
}
temp = head.next;
for(int i = 0; i<length-index; i++) {
temp = temp.next;
}
return temp;
}
/**
* 翻转链表
* @return 反转后的链表
*/
public LinkedList reverseList() {
//链表为空或者只有一个节点,无需翻转
if(head.next == null || head.next.next == null) {
System.out.println("无需翻转");
}
LinkedList newLinkedList = new LinkedList();
//给新链表创建新的头结点
newLinkedList.head = new StudentNode(0, "");
//用于保存正在遍历的节点
StudentNode temp = head.next;
//用于保存正在遍历节点的下一个节点
StudentNode nextNode = temp.next;
while(true) {
//插入新链表
temp.next = newLinkedList.head.next;
newLinkedList.head.next = temp;
//移动到下一个节点
temp = nextNode;
nextNode = nextNode.next;
if(temp.next == null) {
//插入最后一个节点
temp.next = newLinkedList.head.next;
newLinkedList.head.next = temp;
head.next = null;
return newLinkedList;
}
}
}
public void reverseTraverse() {
if(head == null) {
System.out.println("链表为空");
}
StudentNode temp = head.next;
//创建栈,用于存放遍历到的节点
Stack<StudentNode> stack = new Stack<>();
while(temp != null) {
stack.push(temp);
temp = temp.next;
}
while (!stack.isEmpty()) {
System.out.println(stack.pop());
}
}
}
/**
* 定义节点
*/
class StudentNode {
int id;
String name;
//用于保存下一个节点的地址
StudentNode next;
public StudentNode(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "StudentNode{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
这个问题有两个部分。在RubyProgrammingLanguage一书中,有一个使用模块扩展字符串对象和类的示例(第8.1.1节)。第一个问题。为什么如果您使用新方法扩展类,然后创建该类的对象/实例,则无法访问该方法?irb(main):001:0>moduleGreeter;defciao;"Ciao!";end;end=>nilirb(main):002:0>String.extend(Greeter)=>Stringirb(main):003:0>String.ciao=>"Ciao!"irb(main):004:0>x="foobar"=>"foobar"irb(main):
目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式
前文,我们实现了认识了链表这一结构,并实现了无头单向非循环链表,接下来我们实现另一种常用的链表结构,带头双向循环链表。如有仍不了解单向链表的,请看这一篇文章(7条消息)【数据结构和算法】认识线性表中的链表,并实现单向链表_小王学代码的博客-CSDN博客目录前言一、带头双向循环链表是什么?二、实现带头双向循环链表1.结构体和要实现函数2.初始化和打印链表3.头插和尾插4.头删和尾删5.查找和返回结点个数6.在pos位置之前插入结点7.删除指定pos结点8.摧毁链表三、完整代码1.DSLinkList.h2.DSLinkList.c3.test.c总结前言带头双向循环链表,是链表中最为复杂的一种结
代码请进行一定修改后使用,本代码保证100%通过率,本题目提供了java、python、c++三种代码。复盘思路在文章的最后题目描述祖国西北部有一片大片荒地,其中零星的分布着一些湖泊,保护区,矿区;整体上常年光照良好,但是也有一些地区光照不太好。某电力公司希望在这里建设多个光伏电站,生产清洁能源对每平方公里的土地进行了发电评估,其中不能建设的区域发电量为0kw,可以发电的区域根据光照,地形等给出了每平方公里年发电量x千瓦。我们希望能够找到其中集中的矩形区域建设电站,能够获得良好的收益。输入描述第一行输入为调研的地区长,宽,以及准备建设的电站【长宽相等,为正方形】的边长最低要求的发电量之后每行为
最近更新的博客华为OD机试-卡片组成的最大数字(Python)|机试题算法思路华为OD机试-网上商城优惠活动(一)(Python)|机试题算法思路华为OD机试-统计匹配的二元组个数(Python)|机试题算法思路华为OD机试-找到它(Python)|机试题算法思路华为OD机试-九宫格按键输入(Python)|机试算法备考思路华为OD机试-身高排序(Python)|备考思路使用说明参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,通过率才会高。华为OD清单查看地址:blog.csdn.net/hihell/catego
为什么需要服务网关传统的单体架构中只需要开放一个服务给客户端调用,但是微服务架构中是将一个系统拆分成多个微服务,如果没有网关,客户端只能在本地记录每个微服务的调用地址,当需要调用的微服务数量很多时,它需要了解每个服务的接口,这个工作量很大。有了网关之后,网关作为系统的唯一流量入口,封装内部系统的架构,所有请求都先经过网关,由网关将请求路由到合适的微服务。使用网关的好处1)简化客户端的工作。网关将微服务封装起来后,客户端只需同网关交互,而不必调用各个不同服务;(2)降低函数间的耦合度。一旦服务接口修改,只需修改网关的路由策略,不必修改每个调用该函数的客户端,从而减少了程序间的耦合性(3)解放开发
我发现python的细节自动完成很好RubyonRails有类似的方法描述吗? 最佳答案 有篇不错的文章"UsingVIMasacompleteRubyonRailsIDE"其中引用rails.vim.这似乎是RailsforVIM的实际标准。(不过,我还没有使用过它,但很快就会尝试。)这允许你做很多与Rails相关的任务,但对自动完成没有帮助。还有一篇"RubyAutocompleteinVim"(遗憾的是不再可用)这就是您要搜索的内容。我不知道,理解Rails的所有插件魔法和元编程的东西是否足够聪明。它至少在vim的配置中提到了
防火墙防火墙分类第一代防火墙:包过滤防火墙包过滤防火墙的缺点第二代防火墙:代理防火墙第三代防火墙:状态防火墙第四代防火墙:UTM防火墙第五代防火墙:下一代防火墙华为防火墙介绍安全策略防火墙的会话表防火墙分类第一代防火墙:包过滤防火墙属于第一代防火墙技术,在没有专用防火墙设备时,一般由路由器实现该功能。将网络上传送数据包的IP首部以及TCP/UDP首部,获取发送源的IP地址和端口号,以及目的地的IP地址和端口号,并将这些信息作为过滤条件,决定是否将该分组转发至目的地网络分组过滤的执行需要设置访问控制列表。访问控制列表也可以称为安全策略(简称策略)或安全规则(简称规则)。类似于进站检票的做法,符合
内容来自Qt样式表之QSS语法介绍-3YL的博客Qt样式表是一个可以自定义部件外观的十分强大的机制,可以用来美化部件。Qt样式表的概念、术语和语法都受到了HTML的层叠样式表(CascadingStyleSheets, CSS教程)的启发,不过与CSS不同的是,Qt样式表应用于部件的世界。类型选择器QPushButton匹配QPushButton及其子类的实例ID选择器QPushButton#okButton匹配所有objectName为okButton的QPushButton实例。 CSS常用样式1CSS文字属性注:px:相对长度单位,像素(Pixel)。pt:绝对长度单位,点(Point