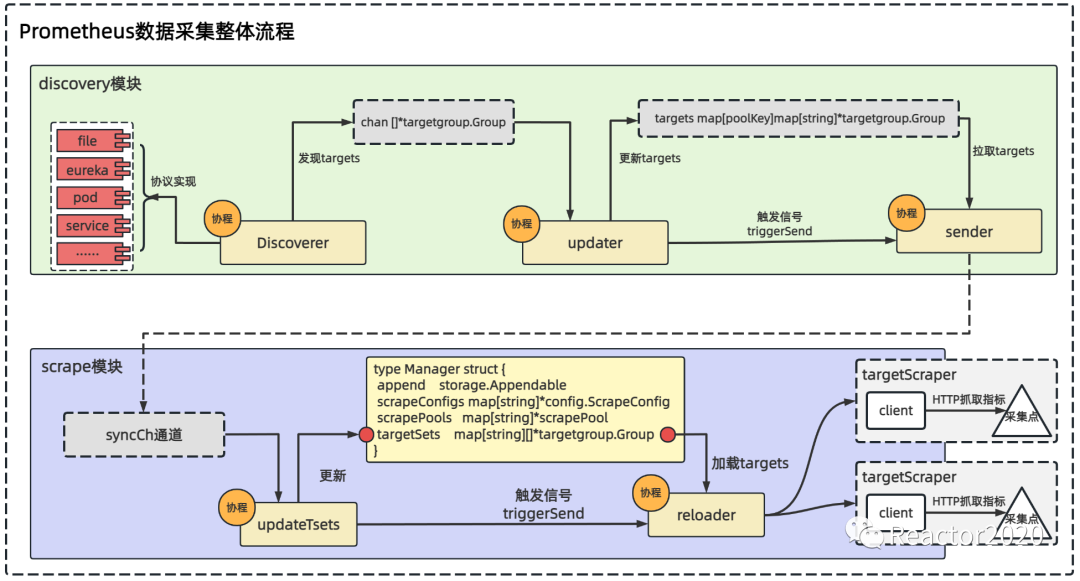
上节分析了Prometheus服务发现核心流程(如下图),Discoverer基于不同协议发现采集点,通过channel通知到updater协程,然后更新到discoveryManager结构体trargets字段中,最终由sender协程将discoveryManager的targets字段数据发送给scrape采集模块。
Discoverer定义的接口类型,不同的服务发现协议基于该接口进行实现:
type Discoverer interface {
// Run hands a channel to the discovery provider (Consul, DNS, etc.) through which
// it can send updated target groups. It must return when the context is canceled.
// It should not close the update channel on returning.
Run(ctx context.Context, up chan<- []*targetgroup.Group)
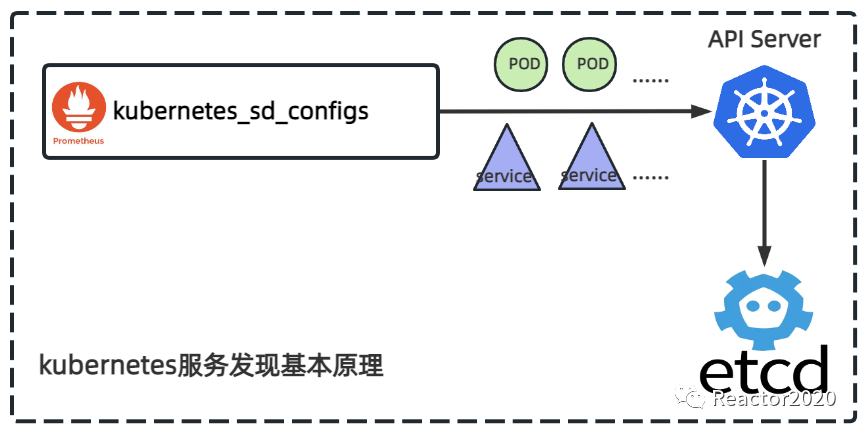
}Prometheus本身就是作为云原生监控出现的,所以对云原生服务发现支持具有天然优势。kubernetes_sd_configs 服务发现协议核心原理就是利用API Server提供的Rest接口获取到云原生集群中的POD、Service、Node、Endpoints、Endpointslice、Ingress等对象的元数据,并基于这些信息生成Prometheus采集点,并且可以随着云原生集群状态变更进行动态实时刷新。
❝❞
kubernetes云原生集群的POD、Service、Node、Ingress等对象元数据信息都被存储到etcd数据库中,并通过API Server组件暴露的Rest接口方式提供访问或操作这些对象数据信息。
「kubernetes_sd_configs配置示例:」
- job_name: kubernetes-pod
kubernetes_sd_configs:
- role: pod
namespaces:
names:
- 'test01'
api_server: https://apiserver.simon:6443
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt配置说明:
api_server指定API Server地址,出于安全考虑,这些接口是带有安全认证的,bearer_token_file和ca_file则指定访问API Server使用到的认证信息;
role指定基于云原生集群中哪种对象类型做服务发现,支持POD、Service、Node、Endpoints、Endpointslice、Ingress六种类型;
namespaces指定作用于哪个云原生命名空间下的对象,不配置则对所有的云原生命名空间生效;
「为什么没有配置api server信息也可以正常进行服务发现?」
很多时候我们并不需要配置api server相关信息也可以进行服务发现,如我们将上面示例简化如下写法:
- job_name: kubernetes-pod
kubernetes_sd_configs:
- role: pod
namespaces:
names:
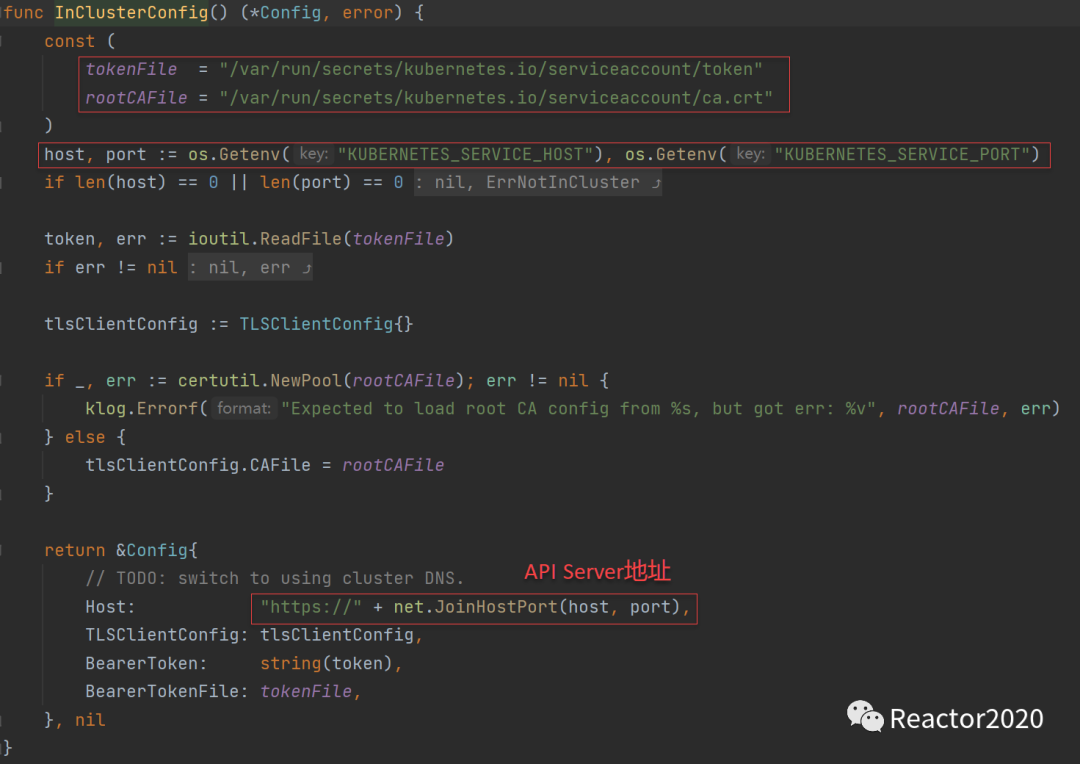
- 'test01'一般Prometheus部署在监控云原生集群上,从 Pod 使用 Kubernetes API 官方客户端库(client-go)提供了更为简便的方法:rest.InClusterConfig()。API Server地址是从POD的环境变量KUBERNETES_SERVICE_HOST和KUBERNETES_SERVICE_PORT构建出来, token 以及 ca 信息从POD固定的文件中获取,因此这种场景下kubernetes_sd_configs中api_server和ca_file是不需要配置的。
❝❞
client-go是kubernetes官方提供的go语言的客户端库,go应用使用该库可以访问kubernetes的API Server,这样我们就能通过编程来对kubernetes资源进行增删改查操作。
从之前分析的服务发现协议接口设计得知,了解k8s服务发现协议入口在discovery/kubernetes.go的Run方法:
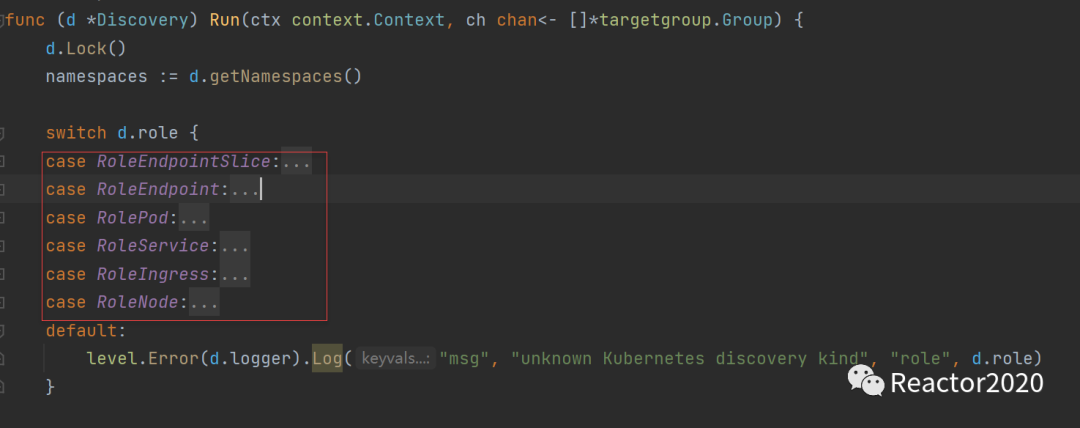
Run方法中switch罗列出不同role的处理逻辑,刚好和配置示例中role支持的六种云原生对象类型对应,只是基于不同的对象进行服务发现,基本原理都是一致的。
云原生服务发现基本原理是访问API Server获取到云原生集群资源对象,Prometheus与API Server进行交互这里使用到的是client-go官方客户端里的Informer核心工具包。Informer底层使用ListWatch机制,在Informer首次启动时,会调用List API获取所有最新版本的资源对象,缓存在内存中,然后再通过Watch API来监听这些对象的变化,去维护这份缓存,降低API Server的负载。除了ListWatch,Informer还可以注册自定义事件处理逻辑,之后如果监听到事件变化就会调用对应的用户自定义事件处理逻辑,这样就实现了用户业务逻辑扩展。
Informer机制工作流程如下图:
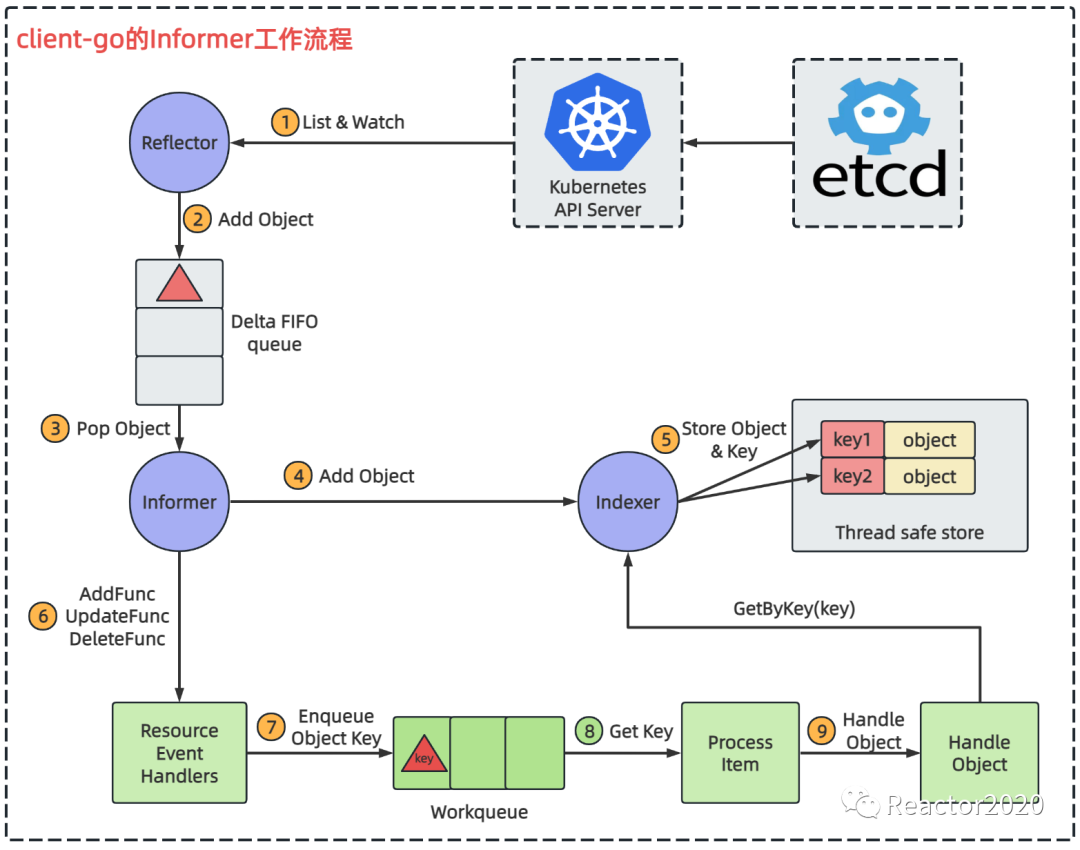
Informer机制本身比较复杂,这里先暂时不太具体说明,只需要理解Prometheus使用Informer机制获取和监听云原生资源对象,即上图中只有「绿色框部分是自定义业务逻辑」,其它都是client-go框架informer工具包提供的功能。
这其中的关键就是注册自定义AddFunc、DeleteFunc和UpdateFunc三种事件处理器,分别对应增、删、改操作,当触发对应操作后,事件处理器就会被回调感知到。比如云原生集群新增一个POD资源对象,则会触发AddFunc处理器,该处理器并不做复杂的业务处理,只是将该对象的key放入到Workqueue队列中,然后Process Item组件作为消费端,不停从Workqueue中提取数据获取到新增POD的key,然后交由Handle Object组件,该组件通过Indexer组件提供的GetByKey()查询到该新增POD的所有元数据信息,然后基于该POD元数据就可以构建采集点信息,这样就实现kubernetes服务发现。
「为什么需要Workqueue队列?」
Resource Event Handlers组件注册自定义事件处理器,获取到事件时只是把对象key放入到Workerqueue中这种简单操作,而没有直接调用Handle Object进行事件处理,这里主要是避免阻塞影响整个informer框架运行。如果Handle Object比较耗时放到Resource Event Handlers组件中直接处理,可能就会影响到④⑤功能,所以这里引入Workqueue类似于MQ功能实现解耦。
熟悉了上面Informer机制,下面以role=POD为例结合Prometheus源码梳理下上面流程。
1、创建和API Server交互底层使用的ListWatch工具;
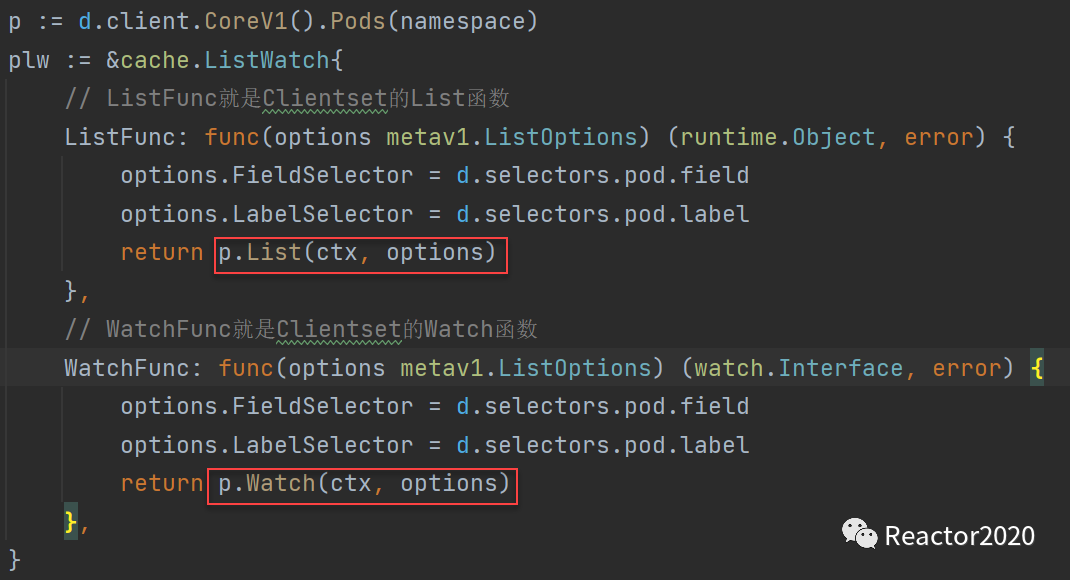
2、基于ListWatch创建Informer;

3、注册资源事件,分别对应资源创建、资源删除和资源更新事件处理;
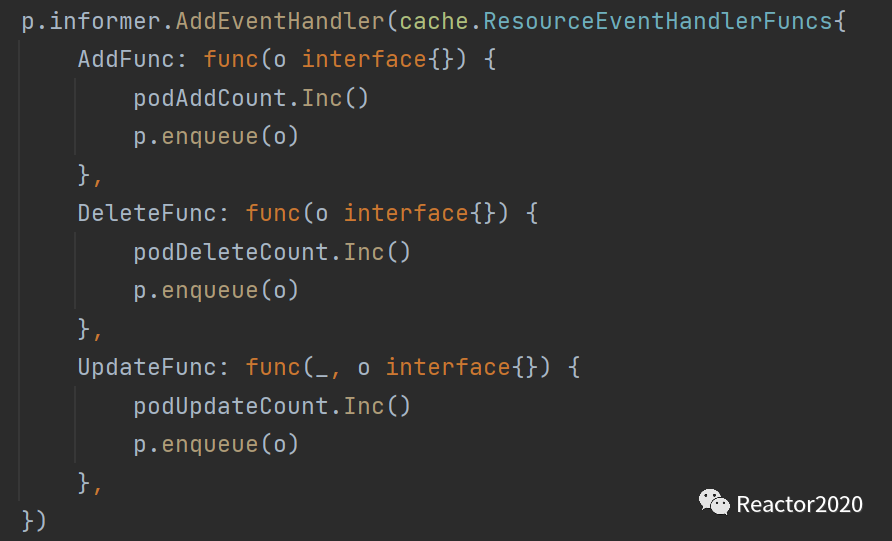
❝这里的
podAddCount、podDeleteCount和podUpdateCount分别对应下面三个指标序列,指标含义也比较明显:
prometheus_sd_kubernetes_events_total(role="pod", event="add")
prometheus_sd_kubernetes_events_total(role="pod", event="delete")
prometheus_sd_kubernetes_events_total(role="pod", event="update")
role标识资源类型,包括:"endpointslice", "endpoints", "node", "pod", "service", "ingress"五种类型;❞
event标识事件类型,包括:"add", "delete", "update"三种类型。
4、事件处理,AddFunc、DeleteFunc和UpdateFunc注册的事件处理逻辑一样,处理逻辑也比较简单:就是获取资源对象key,并将其写入到Workqueue中;
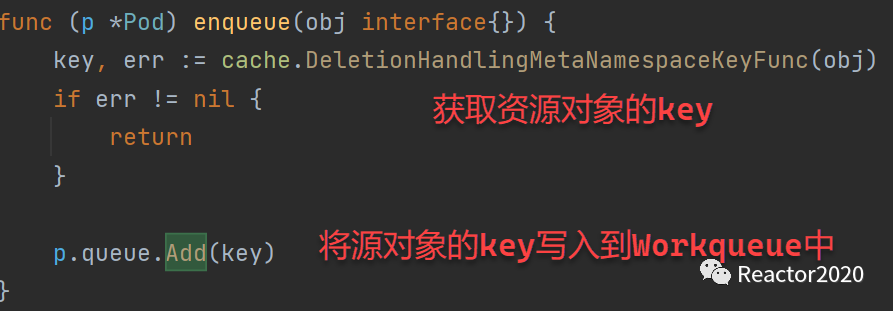
❝对于
❞POD资源,这里的key就是:namespace/pod_name格式,比如key=test01/nginx-deployment-5ffc5bf56c-n2pl8。
5、给Workqueue注册一个无限循环处理逻辑,就能持续从Workqueue中取出key进行处理;
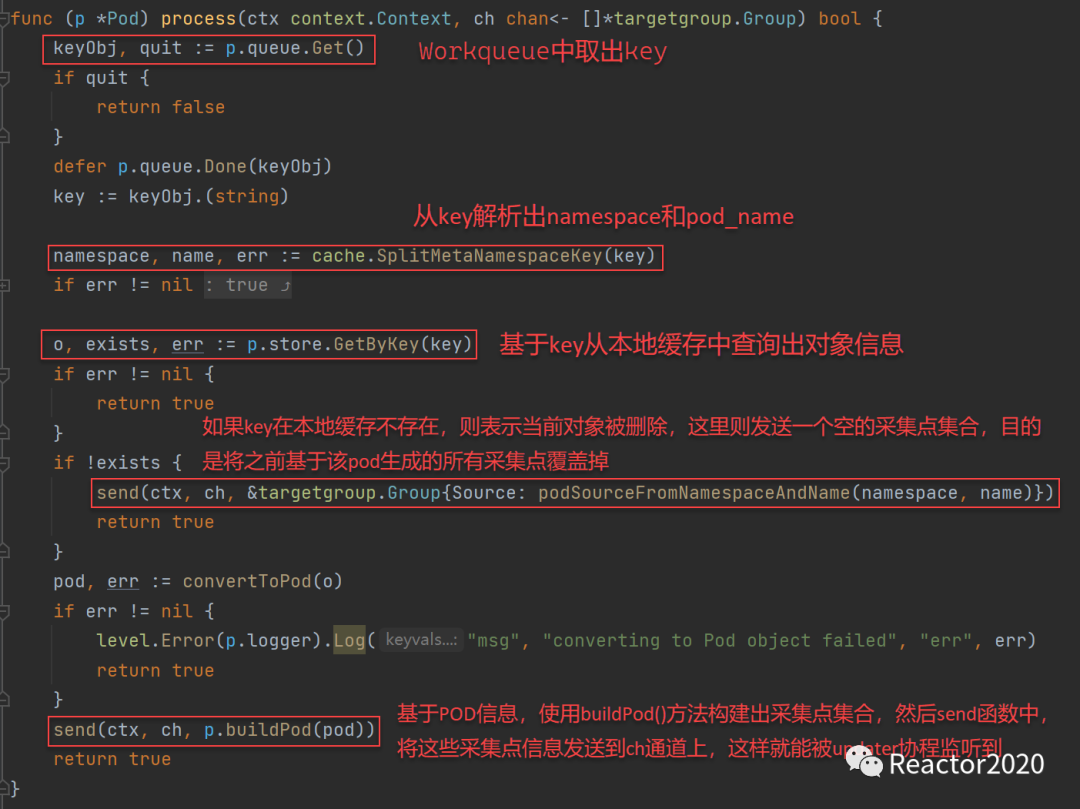
❝针对
❞Pod里的每个Container上的每个port,都会生成一个对应采集点target,其中__address__就是PodIP+port组合。
6、最后启动Informer,让整个流程运转起来;


「更多云原生监控运维知识,请关注公众号:Reactor2020」
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除
require"socket"server="irc.rizon.net"port="6667"nick="RubyIRCBot"channel="#0x40"s=TCPSocket.open(server,port)s.print("USERTesting",0)s.print("NICK#{nick}",0)s.print("JOIN#{channel}",0)这个IRC机器人没有连接到IRC服务器,我做错了什么? 最佳答案 失败并显示此消息::irc.shakeababy.net461*USER:Notenoughparame
我有一个使用PDFKit呈现网页的pdf版本的Rails应用程序。我使用Thin作为开发服务器。问题是当我处于开发模式时。当我使用“bundleexecrailss”启动我的服务器并尝试呈现任何PDF时,整个过程会陷入僵局,因为当您呈现PDF时,会向服务器请求一些额外的资源,如图像和css,看起来只有一个线程.如何配置Rails开发服务器以运行多个工作线程?非常感谢。 最佳答案 我找到的最简单的解决方案是unicorn.geminstallunicorn创建一个unicorn.conf:worker_processes3然后使用它:
关于如何使用git设置类似Dropbox的服务,您有什么建议吗?您认为git是解决此问题的合适工具吗?我在考虑使用git+rush解决方案,你觉得怎么样? 最佳答案 检查这个开源项目:https://github.com/hbons/SparkleShare来自项目的自述文件:Howdoesitwork?SparkleSharecreatesaspecialfolderonyourcomputer.Youcanaddremotelyhostedfolders(or"projects")tothisfolder.Theseprojec
我将以下代码放在一起用于一个简单的RubyTFTP服务器。它工作正常,因为它监听端口69并且我的TFTP客户端连接到它,我能够将数据包写入test.txt,但我不只是写入数据包,我希望能够从我的客户端通过TFTP传输文件到/temp目录。预先感谢您的帮助!require'socket.so'classTFTPServerdefinitialize(port)@port=portenddefstart@socket=UDPSocket.new@socket.bind('',@port)whiletruepacket=@socket.recvfrom(1024)putspacketFile