来自微信公众号:算法梦工厂,二维码见文末。可关注公众号获取往年试题题解。
欢迎加入蓝桥杯备赛群:768245918,获取往届试题,测试数据,算法课程等相关资源。

涉及知识点:计算机基础知识
主要考察一些计算机的基础知识, 32 32 32 位二进制数需要占 4 4 4 个字节, 256 M B = 256 ∗ 1024 K B = 256 ∗ 1024 ∗ 1024 256MB = 256*1024KB = 256*1024*1024 256MB=256∗1024KB=256∗1024∗1024 字节,所以一共可以存储的 32 32 32 位二进制整数的数量就是: 256 ∗ 1024 ∗ 1024 / 4 = 67108864 256*1024*1024/4 = 67108864 256∗1024∗1024/4=67108864 。
#include <bits/stdc++.h>
int main() {
printf("%d", 256 * 1024 * 1024 / 4);
return 0;
}

#include <bits/stdc++.h>
using namespace std;
vector<int> Split(int x) { // 将x按照十进制拆分每一位
vector<int> ret;
if (x == 0) {
ret.push_back(0);
return ret;
}
while (x > 0) {
ret.push_back(x % 10);
x /= 10;
}
return ret;
}
const int maxn = 2021;
int rest_num[10] = {0}; // 记录当前每种数字卡牌剩余数量
bool Sub(const vector<int> &x) { // 将当前需要的数字卡牌从卡牌库中去除,卡牌库剩余卡牌不足则返回false
for (unsigned int i = 0; i < x.size(); i++) {
rest_num[x[i]]--;
if (rest_num[x[i]] < 0) {
return false;
}
}
return true;
}
int main() {
for (int i = 0; i < 10; i++) {
rest_num[i] = maxn;
}
int ans = 1;
while (1) { // 尝试利用剩余卡牌组合出数字ans,剩余卡牌不足则跳出循环
vector<int> need = Split(ans);
bool succFlag = Sub(need);
if (!succFlag) {
break;
}
ans++;
}
printf("ans = %d\n", ans - 1);
return 0;
}

#include <bits/stdc++.h>
using namespace std;
struct Point {
int x, y;
Point() {}
Point(int x, int y) {
this->x = x;
this->y = y;
}
};
struct Line {
Point a, b;
Line(Point a, Point b) {
this->a = a;
this->b = b;
}
};
vector<Line> lineList;
double Dis(Point p0, Point p1) { // 计算点p0和p1之间的直线距离
return sqrt((p0.x - p1.x) * (p0.x - p1.x) + (p0.y - p1.y) * (p0.y - p1.y));
}
bool CheckPointInLine(Line x, Point p) { // 检查点p是否在直线x上
double dis[3];
dis[0] = Dis(x.a, x.b);
dis[1] = Dis(x.a, p);
dis[2] = Dis(x.b, p);
sort(dis, dis + 3);
if (fabs(dis[0] + dis[1] - dis[2]) < 1e-5) { // 三点在一条直线则较短两距离相加等于较长距离
return true;
} else {
return false;
}
}
// 检查当先直线cur是否和之前已经出现过得直线集合(lineList)中的某一直线重合
bool CheckLineRepeat(Line cur) {
for (unsigned int i = 0; i < lineList.size(); i++) {
if (CheckPointInLine(lineList[i], cur.a) &&
CheckPointInLine(lineList[i], cur.b)) {
return true;
}
}
return false;
}
int main() {
vector<Point> pointList;
// 将所有点记入pointList中
for (int i = 0; i < 20; i++) {
for (int j = 0; j < 21; j++) {
pointList.push_back(Point(i, j));
}
}
// 尝试任意两点的组合组成的直线,如果直线没出现过则记录下来,否则跳过
int ans = 0;
for (unsigned int i = 0; i < pointList.size(); i++) {
for (unsigned int j = i + 1; j < pointList.size(); j++) {
Line curLine = Line(pointList[i], pointList[j]);
if (!CheckLineRepeat(curLine)) {
ans++;
lineList.push_back(curLine);
}
}
}
printf("ans = %d\n", ans);
return 0;
}

#include <bits/stdc++.h>
using namespace std;
vector<long long int> primeNum, primeVal;
// 将x质因数分解
void CalaPrime(long long int x) {
printf("%lld = ", x);
for (long long int i = 2; i * i <= x; i++) {
if (x % i == 0) {
int num = 0;
while (x % i == 0) {
x /= i;
num++;
}
primeNum.push_back(num);
primeVal.push_back(i);
}
}
if (x > 1) {
primeNum.push_back(1);
primeVal.push_back(x);
}
for (unsigned int i = 0; i < primeNum.size(); i++) {
if (i != 0) {
printf(" * ");
}
printf("\n(%lld ^ %lld)", primeVal[i], primeNum[i]);
}
printf("\n");
}
int main() {
CalaPrime(2021041820210418);
long long int ans = 0;
ans = 3 * 3 * 3 * 3 * 3;
ans *= 10;
printf("ans = %lld\n", ans);
return 0;
}

#include <bits/stdc++.h>
using namespace std;
const int maxn = 2021;
vector<int> u[maxn + 52];
vector<int> v[maxn + 52];
int disDijk[maxn + 52];
int disFloyd[maxn + 52][maxn + 52];
bool vis[maxn + 52];
// 初始化建图,u[i][j]表示i的第j条出边编号,v[i][j]表示i的第j条边的长度,也就是i和u[i][j]的距离
void InitGroup() {
for (int i = 1; i <= maxn; i++) {
for (int j = i + 1; j <= maxn; j++) {
if (j - i <= 21) {
u[i].push_back(j);
v[i].push_back(i * j / __gcd(i, j));
u[j].push_back(i);
v[j].push_back(i * j / __gcd(i, j));
}
}
}
}
// floyd算法计算最短路,disFloyd[i][j] 表示i到j的最短距离
void Floyd() {
// 初始化disFloyd为一个较大值
memset(disFloyd, 0x3f, sizeof(disFloyd));
for (unsigned int i = 1; i <= maxn; i++) {
for (unsigned int j = 0; j < v[i].size(); j++) {
disFloyd[i][u[i][j]] = v[i][j];
disFloyd[u[i][j]][i] = v[i][j];
}
}
// 执行floyd算法
for (int k = 1; k <= maxn; k++) {
for (int i = 1; i <= maxn; i++) {
for (int j = 1; j <= maxn; j++) {
disFloyd[i][j] = disFloyd[j][i] = min(disFloyd[i][j], disFloyd[i][k] + disFloyd[k][j]);
}
}
}
printf("floyd ans = %d\n", disFloyd[1][maxn]);
}
// Dijkstra算法计算最短路,disDijk[i]表示i距离结点1的最短距离
void Dijkstra() {
memset(disDijk, 0x3f, sizeof(disDijk));
memset(vis, 0, sizeof(vis));
disDijk[1] = 0;
for (int i = 1; i <= maxn; i++) {
int curMin = 0x3f3f3f3f;
int curIndex = -1;
for (int j = 1; j <= maxn; j++) {
if (vis[j]) {
continue;
}
if (curMin > disDijk[j] || curIndex == -1) {
curMin = disDijk[j];
curIndex = j;
}
}
vis[curIndex] = true;
for (unsigned int j = 0; j < u[curIndex].size(); j++) {
int t = u[curIndex][j], val = v[curIndex][j];
disDijk[t] = min(disDijk[t], disDijk[curIndex] + val);
}
}
printf("Dijkstra ans = %d vis = %d\n", disDijk[2021], vis[2021]);
}
int main() {
InitGroup();
Floyd();
Dijkstra();
return 0;
}


涉及知识点:取模,时间计算,格式化输出
注意题目中给定的是毫秒,利用整除和取模就可以完成计算。具体细节可以参照代码中的注释。
#include <bits/stdc++.h>
using namespace std;
int main() {
long long int dayMs = 24 * 60 * 60 * 1000; //一天包含多少毫秒
long long int n;
scanf("%lld", &n);
// 扣除整天的描述之后,得到最后一天剩下了多少毫秒
n = n % dayMs;
// 忽略毫秒,得到还剩多少秒
n = n / 1000;
// 一小时3600秒,走过了多少个完整的3600秒就代表当前小时数是多少
int hour = n / (3600);
// 扣除整小时之后剩下的秒数,可以走过多少个完整的60秒就代表当前分钟数是多少
int minutes = (n - hour * 3600) / 60;
// 走完全部的完整60秒之后剩下的秒数就是秒数
int second = n % 60;
printf("%02d:%02d:%02d\n", hour, minutes, second);
}


涉及知识点:动态规划,类背包问题
思路一:问题可以转化成:给定 n n n 个正整数,计算从中选出若个数字组合,每个数字可以加或者减,最终能得到多少种正整数结果。
思路二:问题还可以转化成:给定 2 ∗ n 2*n 2∗n 个正整数, a 0 , a 1 , . . . , a n , − a 0 , − a 1 , . . . , − a n a_0,a_1,...,a_n,-a_0,-a_1,...,-a_n a0,a1,...,an,−a0,−a1,...,−an ,每个数字可以选或者不选,问相加可以组合成多少种不同的正整数。这样就是一个经典的01背包问题了,只要注意一下负数问题即可。
其它技巧注意事项:
#include <bits/stdc++.h>
using namespace std;
const int offset = 100052; // 为处理负数情况引入的偏移量
const int maxn = 100052 + offset;
int n, vis[2][maxn], a[2000];
int main() {
scanf("%d", &n);
for (int i = 0; i < n; i++) {
scanf("%d", &a[i]);
}
memset(vis, 0, sizeof(vis));
vis[0][offset] = 1;
int pre = 0, cur = 1;
// 三种情况分别是,不选择a[i],选择a[i],选择-a[i]
for (int i = 0; i < n; i++) {
for (int j = 0; j < maxn; j++) {
vis[cur][j] = max(vis[cur][j], vis[pre][j]);
if (j - a[i] >= 0) {
vis[cur][j] = max(vis[pre][j - a[i]], vis[cur][j]);
}
if (j + a[i] < maxn) {
vis[cur][j] = max(vis[pre][j + a[i]], vis[cur][j]);
}
}
swap(pre, cur); // 滚动循环利用数组的pre行和cur行
}
// 注意要从offset+1开始,因为能称出来的重量不应该是负数
int ans = 0;
for (int i = offset + 1; i < maxn; i++) {
if (vis[pre][i]) {
ans++;
}
}
printf("%d", ans);
return 0;
}


涉及知识点:二分,组合数计算,打表
这里其实需要知道或者自己分析出一些杨辉三角的性质,首先为了方便表示,将这个杨辉三角表示成这种形式:
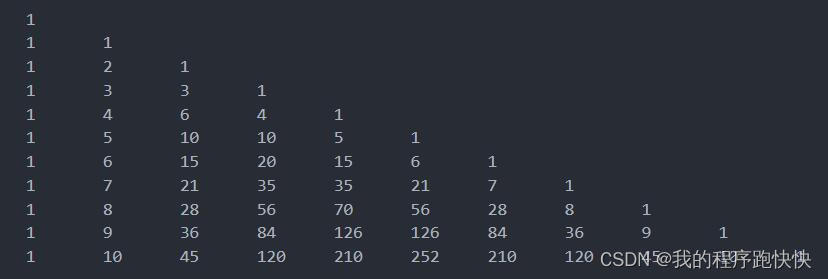
第
i
i
i 行第
j
j
j 个数表示成
c
(
i
,
j
)
c(i,j)
c(i,j) ,行数和列数都从
0
0
0 开始计算。
可以发现如下的结论:
考虑到每一行是对称的,所以如果如果一个数字在某一行的右半边出现,那么它一定也在这一行的左半边出现,因此每一行右半边的数字一定不会作为第一个出现的数字。此外可以发现 c ( i , 1 ) = i c(i,1) = i c(i,1)=i ,所以任意一个数字 n n n 一定会在这个杨辉三角矩阵中出现过。另外根据上面的公式1可以发现,每一行的数字都是呈现一个先增后减的形式,并且增长速度极快。每一列数字则是完全单调递增的。因此可以尝试在每一列二分搜索是否有该数字。只需要考虑前 20 20 20 列即可,因为后面的数字大小已经完全超过了 n n n 的最大范围,所以一定不会等于 n n n。
#include <bits/stdc++.h>
using namespace std;
// 打印杨辉三角前x行,帮助直观感受
void Print(int x) {
long long int c[100][100];
for (int i = 1; i <= x; i++) {
c[i][0] = 1;
printf("%lld\t", c[i][0]);
for (int j = 1; j < i; j++) {
c[i][j] = c[i - 1][j - 1] + c[i - 1][j];
printf("%lld\t", c[i][j]);
}
printf("\n");
}
}
// 二分方法
long long int n;
long long int C(long long int a, long long int b) {
long long int ret = 1;
for (long long int i = a, j = 1; j <= b; i--, j++) {
ret = ret * i / j;
if (ret > n) {
return n + 1;
}
}
return ret;
}
long long int GetAns(int col) {
long long int l = col, r = max(n, (long long int)col);
while (l < r) {
long long int mid = (l + r) / 2;
if (C(mid, col) >= n)
r = mid;
else
l = mid + 1;
}
if (C(r, col) != n) { // 没有出现则返回出现位置无限大
return 4e18;
} else {
return r * (r + 1) / 2 + col + 1;
}
}
int main() {
scanf("%lld", &n);
long long int ans = 4e18;
for (int i = 0; i < 20; i++) { // 枚举前20列,记录最早出现位置
long long int cur = GetAns(i);
ans = min(ans, cur);
}
printf("%lld\n", ans);
return 0;
}


涉及知识点:贪心,线段树,排序
此题完全通过较为困难,此处给出简单版本使用sort函数代码。可以考虑,对于连续的0操作或者1操作,只需要执行覆盖数组长度最长的操作即可,这样就可以一定程度上减少操作次数,从而提高程序运行效率。
#include <bits/stdc++.h>
using namespace std;
const int maxn = 100052;
int a[maxn];
bool cmp(int x, int y) { return x > y; }
struct Oper {
int pos, op;
};
int main() {
int n, m;
scanf("%d%d", &n, &m);
for (int i = 0; i < n; i++) {
a[i] = i + 1;
}
// 读取操作列表
vector<Oper> opList;
for (int i = 0; i < m; i++) {
Oper temp;
scanf("%d%d", &temp.op, &temp.pos);
opList.push_back(temp);
}
// 操作去重转变成01交错的操作序列
vector<Oper> newList;
Oper curOp = opList[0];
for (unsigned int i = 0; i < opList.size(); i++) {
if (curOp.op != opList[i].op) { // 操作01转换则保存当前等价操作并重新记录
newList.push_back(curOp);
curOp = opList[i];
continue;
}
if (opList[i].op == 0 && opList[i].pos > curOp.pos) {
curOp = opList[i];
}
if (opList[i].op == 1 && opList[i].pos < curOp.pos) {
curOp = opList[i];
}
}
newList.push_back(curOp);
// 模拟执行操作
for (unsigned int i = 0; i < newList.size(); i++) {
if (newList[i].op == 0) {
sort(a, a + newList[i].pos, cmp);
} else {
sort(a + newList[i].pos - 1, a + n);
}
}
// 打印结果
for (int i = 0; i < n; i++) {
if (i != 0) {
printf(" ");
}
printf("%d", a[i]);
}
return 0;
}

#include <bits/stdc++.h>
using namespace std;
const int maxn = 5052;
const long long int MOD = 1e9 + 7;
int dp[maxn][maxn];
bool vis[maxn][maxn];
char str[maxn];
int n;
long long int mod(long long int x) { return x % MOD; }
long long int GetAns() {
memset(dp, 0, sizeof dp);
memset(vis, 0, sizeof vis);
dp[0][0] = 1;
vis[0][0] = true;
for (int i = 1; i <= n; i++) {
if (str[i - 1] == '(') {
for (int j = 1; j <= n; j++) {
dp[i][j] = dp[i - 1][j - 1];
vis[i][j] = vis[i - 1][j - 1];
}
} else {
dp[i][0] = mod(dp[i - 1][0] + dp[i - 1][1]);
vis[i][0] = vis[i-1][0] | vis[i-1][1];
for (int j = 1; j <= n; j++) {
dp[i][j] = mod(dp[i - 1][j + 1] + dp[i][j - 1]);
vis[i][j] = vis[i - 1][j + 1] | vis[i][j - 1];
}
}
}
for (int i = 0; i <= n; i++) {
if (vis[n][i] != 0) {
return dp[n][i];
}
}
return -1;
}
int main() {
scanf("%s", str);
n = strlen(str);
long long int ansL = GetAns();
reverse(str, str + n);
for (int i = 0; i < n; i++) {
if (str[i] == ')') {
str[i] = '(';
} else {
str[i] = ')';
}
}
long long int ansR = GetAns();
printf("%lld\n", mod(ansL * ansR));
return 0;
}
获取更多题解,算法讲解欢迎关注公众号:算法梦工厂


我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und