近红外光谱分析技术属于交叉领域,需要化学、计算机科学、生物科学等多领域的合作。为此,在(北京邮电大学杨辉华老师团队)指导下,近期准备开源传统的PLS,SVM,ANN,RF等经典算和SG,MSC,一阶导,二阶导等预处理以及GA等波长选择算法以及CNN、AE等最新深度学习算法,以帮助其他专业的更容易建立具有良好预测能力和鲁棒性的近红外光谱模型。
文章目录
本篇主要讲述基于python语言的光谱预处理方法,稍后更新matlab语言版本的光谱预处理方法,
# 最大最小值归一化
def MMS(data):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:return: data after MinMaxScaler :(n_samples, n_features)
"""
return MinMaxScaler().fit_transform(data)
# 标准化
def SS(data):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:return: data after StandScaler :(n_samples, n_features)
"""
return StandardScaler().fit_transform(data)
# 均值中心化
def CT(data):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:return: data after MeanScaler :(n_samples, n_features)
"""
for i in range(data.shape[0]):
MEAN = np.mean(data[i])
data[i] = data[i] - MEAN
return data
# 标准正态变换
def SNV(data):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:return: data after SNV :(n_samples, n_features)
"""
m = data.shape[0]
n = data.shape[1]
print(m, n) #
# 求标准差
data_std = np.std(data, axis=1) # 每条光谱的标准差
# 求平均值
data_average = np.mean(data, axis=1) # 每条光谱的平均值
# SNV计算
data_snv = [[((data[i][j] - data_average[i]) / data_std[i]) for j in range(n)] for i in range(m)]
return data_snv
# 移动平均平滑
def MA(data, WSZ=11):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:param WSZ: int
:return: data after MA :(n_samples, n_features)
"""
for i in range(data.shape[0]):
out0 = np.convolve(data[i], np.ones(WSZ, dtype=int), 'valid') / WSZ # WSZ是窗口宽度,是奇数
r = np.arange(1, WSZ - 1, 2)
start = np.cumsum(data[i, :WSZ - 1])[::2] / r
stop = (np.cumsum(data[i, :-WSZ:-1])[::2] / r)[::-1]
data[i] = np.concatenate((start, out0, stop))
return data
# Savitzky-Golay平滑滤波
def SG(data, w=11, p=2):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:param w: int
:param p: int
:return: data after SG :(n_samples, n_features)
"""
return signal.savgol_filter(data, w, p)
# 一阶导数
def D1(data):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:return: data after First derivative :(n_samples, n_features)
"""
n, p = data.shape
Di = np.ones((n, p - 1))
for i in range(n):
Di[i] = np.diff(data[i])
return Di
# 二阶导数
def D2(data):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:return: data after second derivative :(n_samples, n_features)
"""
data = deepcopy(data)
if isinstance(data, pd.DataFrame):
data = data.values
temp2 = (pd.DataFrame(data)).diff(axis=1)
temp3 = np.delete(temp2.values, 0, axis=1)
temp4 = (pd.DataFrame(temp3)).diff(axis=1)
spec_D2 = np.delete(temp4.values, 0, axis=1)
return spec_D2
# 趋势校正(DT)
def DT(data):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:return: data after DT :(n_samples, n_features)
"""
x = np.asarray(range(350, 2501), dtype=np.float32)
out = np.array(data)
l = LinearRegression()
for i in range(out.shape[0]):
l.fit(x.reshape(-1, 1), out[i].reshape(-1, 1))
k = l.coef_
b = l.intercept_
for j in range(out.shape[1]):
out[i][j] = out[i][j] - (j * k + b)
return out
# 多元散射校正
def MSC(data):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:return: data after MSC :(n_samples, n_features)
"""
n, p = data.shape
msc = np.ones((n, p))
for j in range(n):
mean = np.mean(data, axis=0)
# 线性拟合
for i in range(n):
y = data[i, :]
l = LinearRegression()
l.fit(mean.reshape(-1, 1), y.reshape(-1, 1))
k = l.coef_
b = l.intercept_
msc[i, :] = (y - b) / k
return msc
# 小波变换
def wave(data):
"""
:param data: raw spectrum data, shape (n_samples, n_features)
:return: data after wave :(n_samples, n_features)
"""
data = deepcopy(data)
if isinstance(data, pd.DataFrame):
data = data.values
def wave_(data):
w = pywt.Wavelet('db8') # 选用Daubechies8小波
maxlev = pywt.dwt_max_level(len(data), w.dec_len)
coeffs = pywt.wavedec(data, 'db8', level=maxlev)
threshold = 0.04
for i in range(1, len(coeffs)):
coeffs[i] = pywt.threshold(coeffs[i], threshold * max(coeffs[i]))
datarec = pywt.waverec(coeffs, 'db8')
return datarec
tmp = None
for i in range(data.shape[0]):
if (i == 0):
tmp = wave_(data[i])
else:
tmp = np.vstack((tmp, wave_(data[i])))
return tmp
代码如下(示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
推荐基于anaconda安装python,参考安装如下:
基于anaconda安装python
import numpy as np
import matplotlib.pyplot as plt
from scipy import signal
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import MinMaxScaler, StandardScaler
#载入数据
data_path = './/data//data.csv' #数据
xcol_path = './/data//xcol.csv' #波长
data = np.loadtxt(open(data_path, 'rb'), dtype=np.float64, delimiter=',', skiprows=0)
xcol = np.loadtxt(open(xcol_path, 'rb'), dtype=np.float64, delimiter=',', skiprows=0)
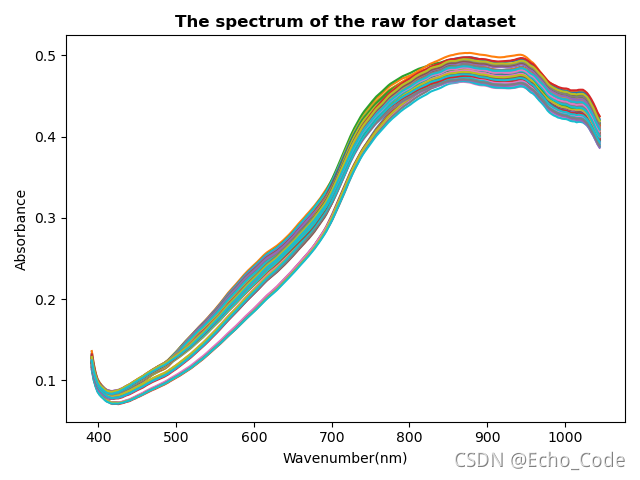
# 绘制MSC预处理后图片
plt.figure(500)
x_col = xcol #数组逆序
y_col = np.transpose(data)
plt.plot(x_col, y_col)
plt.xlabel("Wavenumber(nm)")
plt.ylabel("Absorbance")
plt.title("The spectrum of the raw for dataset",fontweight= "semibold",fontsize='large') #记得改名字MSC
plt.show()
#数据预处理、可视化和保存
datareprocessing_path = './/data//dataMSC.csv' #波长
Data_Msc = MSC(data) #改这里的函数名就可以得到不同的预处理
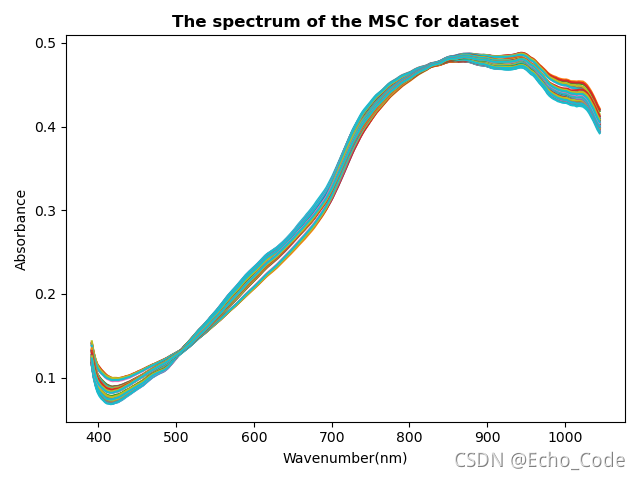
# 绘制MSC预处理后图片
plt.figure(500)
x_col = xcol #数组逆序
y_col = np.transpose(Data_Msc)
plt.plot(x_col, y_col)
plt.xlabel("Wavenumber(nm)")
plt.ylabel("Absorbance")
plt.title("The spectrum of the MSC for dataset",fontweight= "semibold",fontsize='large') #记得改名字MSC
plt.show()
#保存预处理后的数据
np.savetxt(datareprocessing_path, Data_Msc, delimiter=',')
原始光谱
msc预处理后
python代码参考湖南师范大学同学,完整代码可从获得GitHub仓库
代码仅供学术使用,如有问题,联系方式:QQ:1427950662,微信:Fu_siry
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我正在尝试修改当前依赖于定义为activeresource的gem:s.add_dependency"activeresource","~>3.0"为了让gem与Rails4一起工作,我需要扩展依赖关系以与activeresource的版本3或4一起工作。我不想简单地添加以下内容,因为它可能会在以后引起问题:s.add_dependency"activeresource",">=3.0"有没有办法指定可接受版本的列表?~>3.0还是~>4.0? 最佳答案 根据thedocumentation,如果你想要3到4之间的所有版本,你可以这
如果我使用ruby版本2.5.1和Rails版本2.3.18会怎样?我有基于rails2.3.18和ruby1.9.2p320构建的rails应用程序,我只想升级ruby的版本,而不是rails,这可能吗?我必须面对哪些挑战? 最佳答案 GitHub维护apublicfork它有针对旧Rails版本的分支,有各种变化,它们一直在运行。有一段时间,他们在较新的Ruby版本上运行较旧的Rails版本,而不是最初支持的版本,因此您可能会发现一些关于需要向后移植的有用提示。不过,他们现在已经有几年没有使用2.3了,所以充其量只能让更
我安装了ruby版本管理器,并将RVM安装的ruby实现设置为默认值,这样'哪个ruby'显示'~/.rvm/ruby-1.8.6-p383/bin/ruby'但是当我在emacs中打开inf-ruby缓冲区时,它使用安装在/usr/bin中的ruby。有没有办法让emacs像shell一样尊重ruby的路径?谢谢! 最佳答案 我创建了一个emacs扩展来将rvm集成到emacs中。如果您有兴趣,可以在这里获取:http://github.com/senny/rvm.el
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
有人知道在发布新版本的Ruby和Rails时收到电子邮件的方法吗?他们有邮件列表,RubyonRails有一个推特,但我不想听到那些随之而来的喧嚣,我只想知道什么时候发布新版本,尤其是那些有安全修复的版本。 最佳答案 从therailsblog获取提要.http://weblog.rubyonrails.org/feed/atom.xml 关于ruby-on-rails-如何在发布新的Ruby或Rails版本时收到通知?,我们在StackOverflow上找到一个类似的问题:
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非