学习如何在Discord上使用MidJourney机器人,从简单的文本提示中创建自定义图像。
前往Midjourney.com,选择“加入Beta”,或直接进入MidJourney Discord。
在加入MidJourney Discord服务器之前,您必须拥有Discord帐户。
链接: 了解如何创建Discord帐户,请点击这里。
在左侧边栏中选择任何一个可见的newbies-#频道。
您可以在任何已邀请MidJourney机器人的服务器上生成图像。查找您所在服务器上使用机器人的指南。
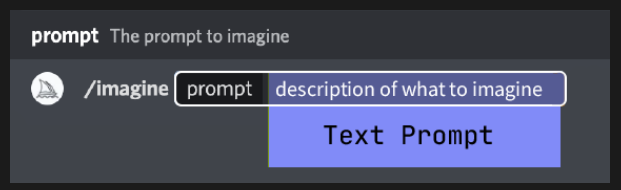
使用命令与Discord上的MidJourney机器人进行交互。命令可用于创建图像、更改默认设置、监视用户信息和执行其他有用的任务。/imagine命令从短文本描述(称为Prompt)生成唯一的图像。
请遵守社区准则。Midjourney机器人在任何地方使用时都适用社区准则。
如果在输入/imagine命令时没有看到弹出窗口,请尝试注销、更新Discord应用并重新登录。
命令仅在机器人频道中起作用。在常规频道(如#trial-support)中不起作用。


MidJourney机器人需要大约一分钟来生成四个选项。
生成图像会激活免费的Midjourney试用。试用用户在需要订阅之前可以制作大约25个作业。
作业是使用Midjourney机器人的任何操作。作业包括使用/imagine命令创建图像网格、放大图像或创建图像变体,所有这些操作都使用您的免费试用时间。
使用/info命令检查您的快速剩余时间以查看您剩余的试用时间。
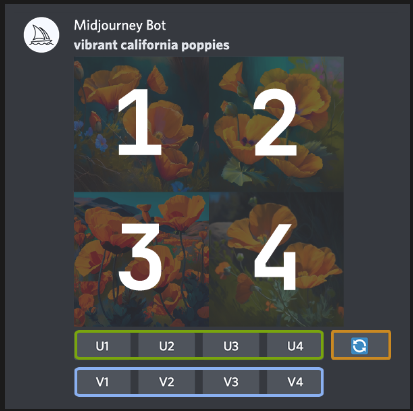
在初始图像网格生成完成后,会出现两行按钮:
在放大图像后,会出现一组新选项:
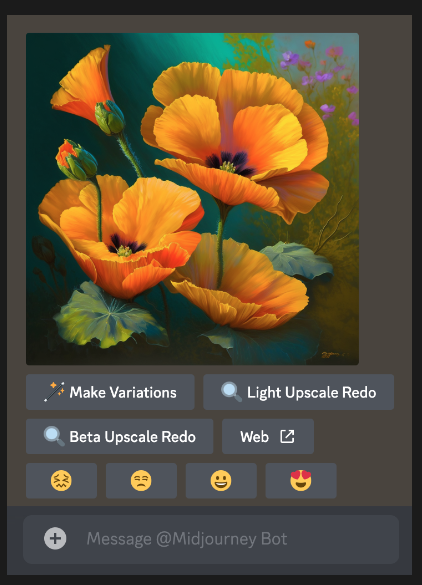
单击图像以打开它并查看完整尺寸,然后右键单击并选择“保存图像”。在移动设备上,长按图像,然后在右上角点击下载图标。
所有图像都可以立即在midjourney.com/app上查看。请使用Discord帐户登录以查看。
试用用户有大约25个免费作业。作业目前不会过期,但也不会自动续订。要创建更多图像,请在任何机器人频道中使用/subscribe命令生成个人链接到MidJourney帐户页面。请勿与他人分享此个人链接。
有关价格和更多信息,请访问订阅计划。
仔细检查 请确保使用现有的Discord帐户进行登录。很容易意外创建一个新帐户。
提示Prompts是Midjourney Bot解释为生成一张图片的短文本短语。Midjourney Bot将提示中的单词和短语分解成较小的片段,称为标记,这些标记可以与其训练数据进行比较,然后用于生成图片。一个精心设计的提示可以帮助制作出独特和令人兴奋的图片。
基本提示可以简单到只有一个单词、短语或表情符号。
高级提示
更高级的提示可以包括一个或多个图像URL、多个文本短语和一个或多个参数。

提示可以非常简单。单词(甚至表情符号!)就可以生成图像。非常简短的提示会严重依赖Midjourney的默认样式,因此更具描述性的提示可以为图像创造独特的外观。但是,过于冗长的提示并不总是更好。集中精力关注您想要创建的主要概念。
Midjourney Bot不理解语法、句子结构或人类使用的单词。单词的选择也很重要。在许多情况下,更具体的同义词效果更好。例如,可以使用“gigantic”、“enormous”或“immense”代替“big”。尽可能删除不必要的单词。较少的单词意味着每个单词的影响更为强烈。使用逗号、括号和连字符来帮助组织您的想法,但要知道Midjourney Bot不能可靠地解释它们。Midjourney Bot不考虑大小写。
Midjourney Model Version 4在解释传统句子结构方面略胜一筹。
最好描述您想要的内容,而不是不想要的内容。如果您要求“没有蛋糕”的聚会,您的图像可能会包括蛋糕。如果您要确保某个对象不在最终图像中,请尝试使用–no参数进行提前提示。
任何未提及的内容都可能会让您感到惊讶。可以具体或模糊,但您省略的任何内容都将被随机生成。模糊是获得多样性的好方法,但您可能无法得到您想要的具体细节。
尽量明确您认为重要的任何上下文或细节。考虑以下方面:
复数词留下了很多机会。尝试使用具体的数字。例如,“三只猫”比“猫”更具体。集体名词也可以使用,“一群鸟”而不是“鸟”。
即使是简短的单词提示也可以在Midjourney的默认样式下生成美丽的图像,但是您可以通过组合艺术媒介、历史时期、位置等概念来创建更有趣的个性化结果。例如,您可以尝试以下提示:
Softly-lit sunset over a Parisian street
Neon lights shining on a rainy Tokyo night
Warm candlelight in an old Gothic cathedral
Bright sunshine over a lush jungle canopy
Harsh fluorescent lighting in a sterile laboratory
这些提示都包含了光的不同形式和环境,这些因素可以影响图像的氛围和色彩。加入更多细节,比如特定的媒介或时期,可以进一步定制您的图像。
使用颜料、蜡笔、刮画板、印刷机、闪粉、墨水和彩色纸张等材料创作画作。指定艺术媒介是生成时尚图像的最佳方式之一。
例如,可以尝试以下提示:
/imagine prompt <any art style> style cat
/imagine prompt <任何艺术风格> 风格的猫
在此提示中,指定了一种艺术媒介(例如绘画、素描、水彩等)和一种主题(猫),以生成一幅符合特定艺术风格的图像。加入更多细节,例如颜色、纹理或特定艺术家的风格,可以进一步定制您的图像。
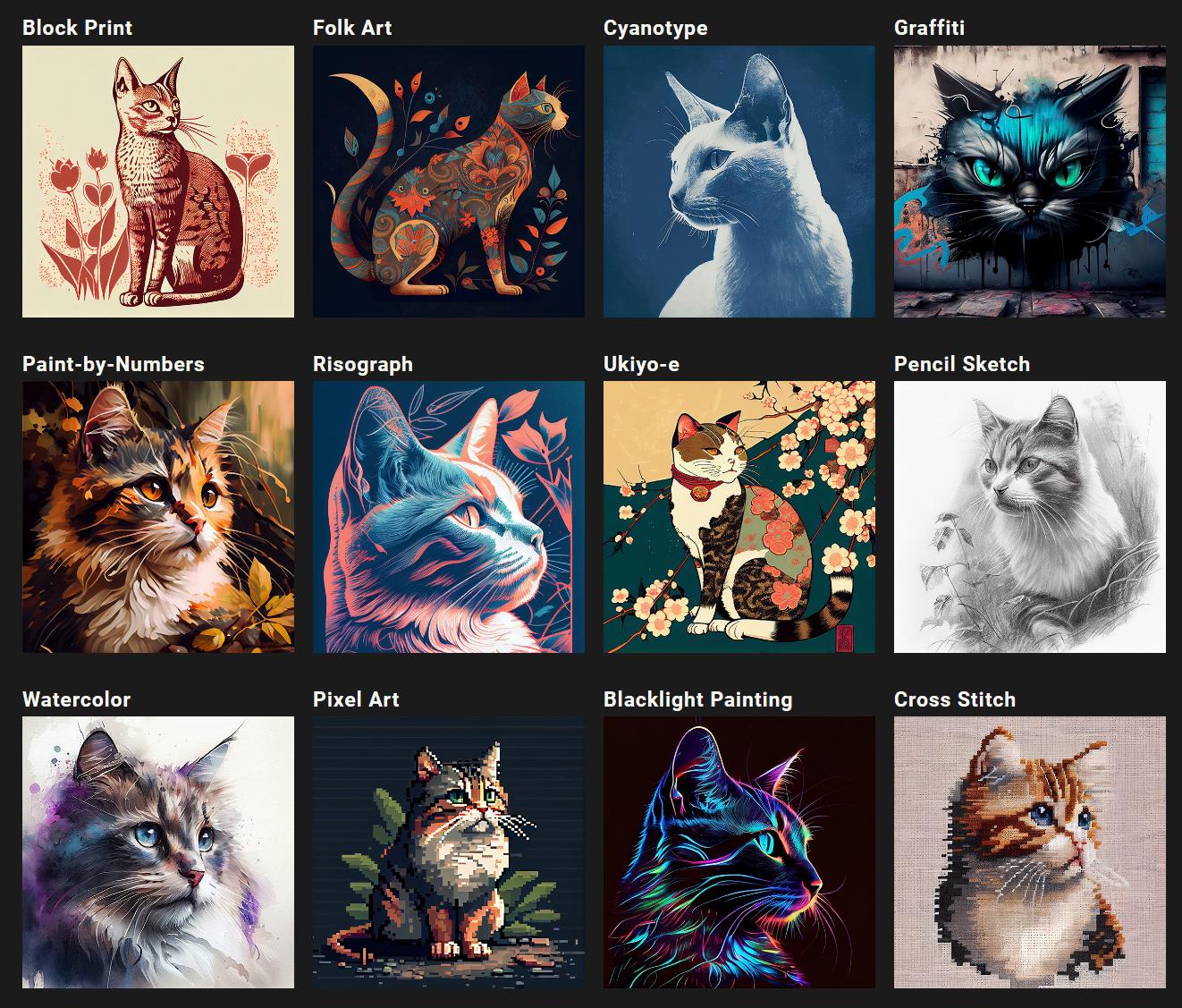
更精确的单词和短语将有助于创建具有完全正确外观和感觉的图像。
例如,可以尝试以下提示:
/imagine prompt <style> sketch of a cat
/imagine prompt <风格> 猫的素描
在此提示中,使用“素描”这一更加具体的单词,以指定您想要的特定艺术风格。使用更精确的词汇和短语,例如特定的颜色或细节,可以进一步定制您的图像,以确保其符合您的预期。
不同的时代具有独特的视觉风格。
例如,可以尝试以下提示:
/imagine prompt <decade> cat illustration
/imagine prompt <年代> 猫的插图
在此提示中,使用特定的年代(例如20世纪60年代、70年代等)来指定您想要的特定视觉风格。您可以使用一些关键词或特定事件,例如“二战期间”或“夏威夷海滩度假”,来进一步指导Midjourney生成更具特色的图像。

使用情感词汇为角色赋予个性。
例如,可以尝试以下提示:
/imagine prompt <emotion> cat
/imagine prompt <情感> 猫
在此提示中,使用情感词汇(例如“快乐”、“害怕”、“温柔”等)来指定您想要的特定情感和角色性格。这些情感词汇可以让Midjourney更好地理解您想要的图像氛围和色彩,从而生成更具个性化的结果。

各种可能性的完整光谱。
例如,可以尝试以下提示:
/imagine prompt <color word> colored cat
/imagine prompt <颜色词> 的彩色猫
在此提示中,使用颜色词汇(例如“红色”、“蓝色”、“黄色”等)来指定您想要的特定颜色方案。您可以使用更具体的词汇,例如“柿子橙”、“深海蓝”等,来定制您的图像颜色,以确保其符合您的预期。使用多种颜色词汇可以进一步指导Midjourney生成更具特色的图像。
环境探索
不同的环境可以营造独特的氛围。
例如,可以尝试以下提示:
/imagine prompt <location> cat
/imagine prompt <地点> 的猫
在此提示中,使用地点(例如“海滩”、“山区”、“夜市”等)来指定您想要的特定环境,以营造特定的氛围和感觉。使用特定的地点和环境可以帮助Midjourney生成更具特色的图像,以符合您的预期。可以考虑加入更多细节,例如特定时间的天气或特定场所的建筑风格,以进一步定制您的图像。
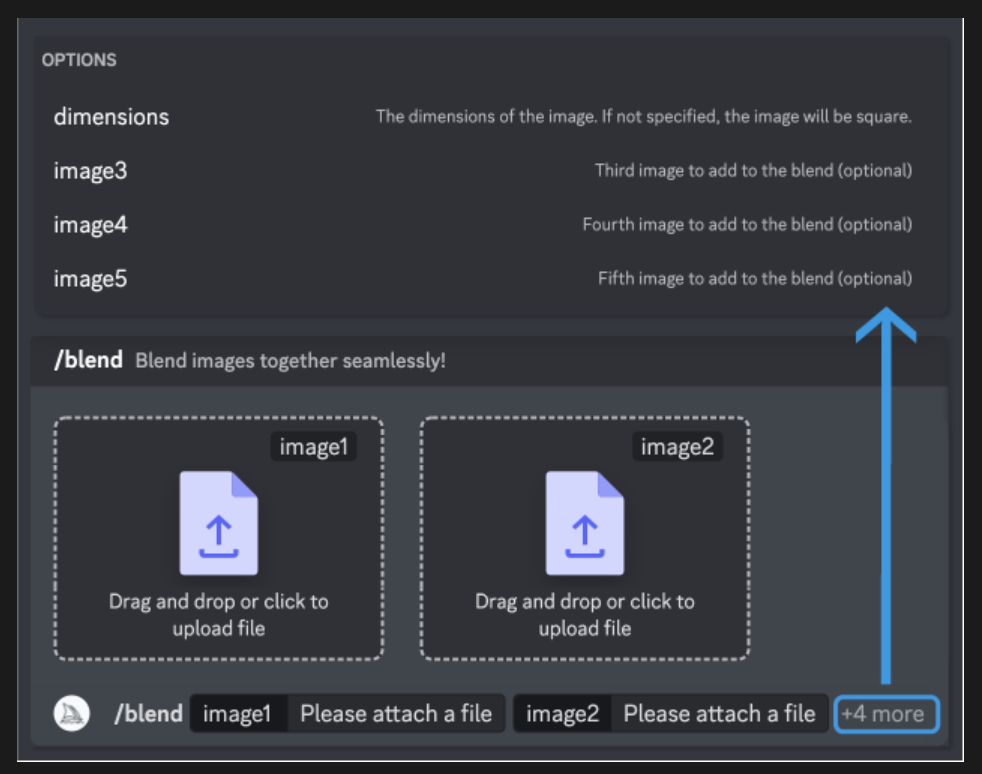
/blend命令允许您快速上传2-5张图片,然后查看每张图片的概念和美学,并将它们合并成新的图像。
/blend与在/imagine中使用多个图像提示相同,但其界面经过优化,便于在移动设备上使用。/blend可与最多5张图片一起使用。如果要在一个提示中使用超过5张图片,请使用/imagine中的图像提示。/blend不能与文本提示一起使用。要同时使用文本和图像提示,请使用/imagine中的图像提示和文本。
在键入/blend命令后,系统会提示您上传两张照片。您可以从硬盘中拖放照片,或者在使用移动设备时,从照片库中添加照片。如果您想添加更多的图片,可以选择可选字段,然后选择image3、image4或image5。由于Midjourney Bot在处理请求之前必须上传您的图片,因此/blend命令启动可能需要更长时间。
混合图像具有默认的1:1宽高比,但是您可以使用可选的尺寸字段选择正方形宽高比(1:1)、纵向宽高比(2:3)或横向宽高比(3:2)。
与其他/imagine提示一样,自定义后缀将添加到/blend提示的末尾。作为/blend命令的一部分指定的宽高比会覆盖自定义后缀中的宽高比。
混合提示
为了获得最佳结果,请上传与所需结果相同宽高比的图像。这将有助于Midjourney Bot更好地将所有图像混合在一起,并生成符合预期的图像。如果您上传的图像具有不同的宽高比,可能会出现截断、压缩或拉伸的情况,影响混合图像的质量。
使用/blend创建混合图像的步骤如下:

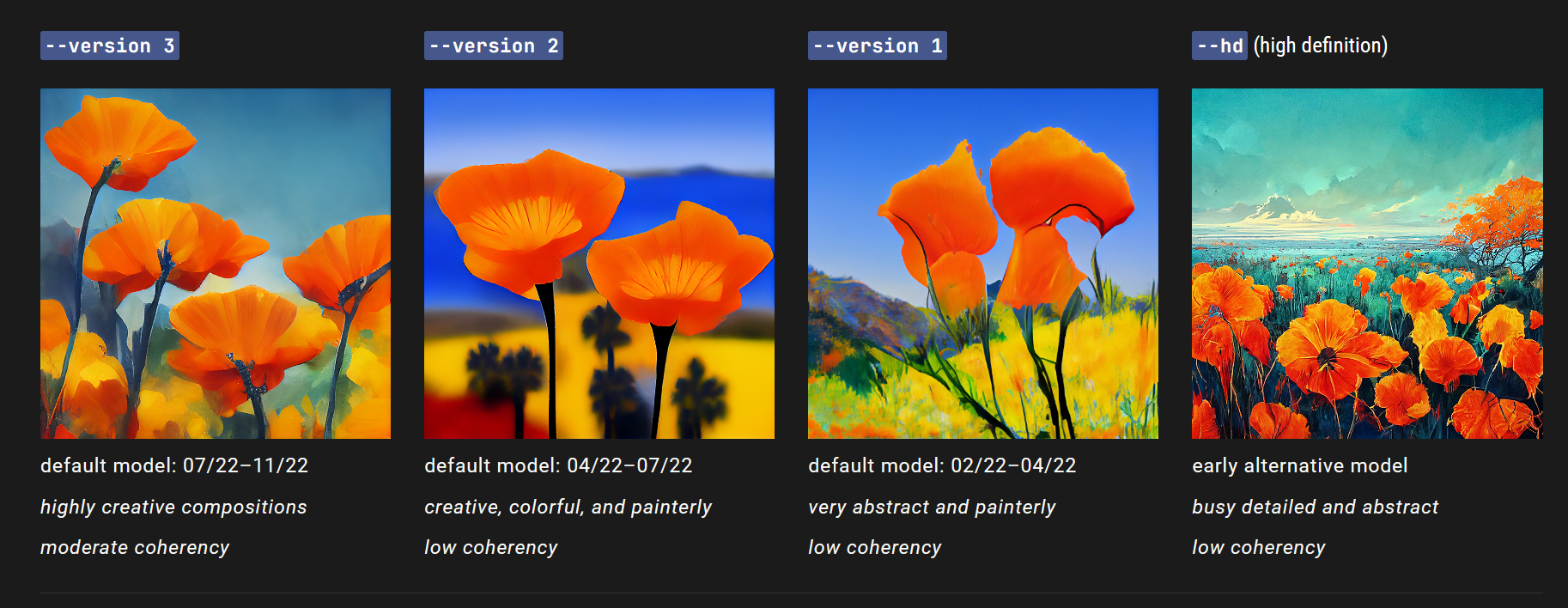
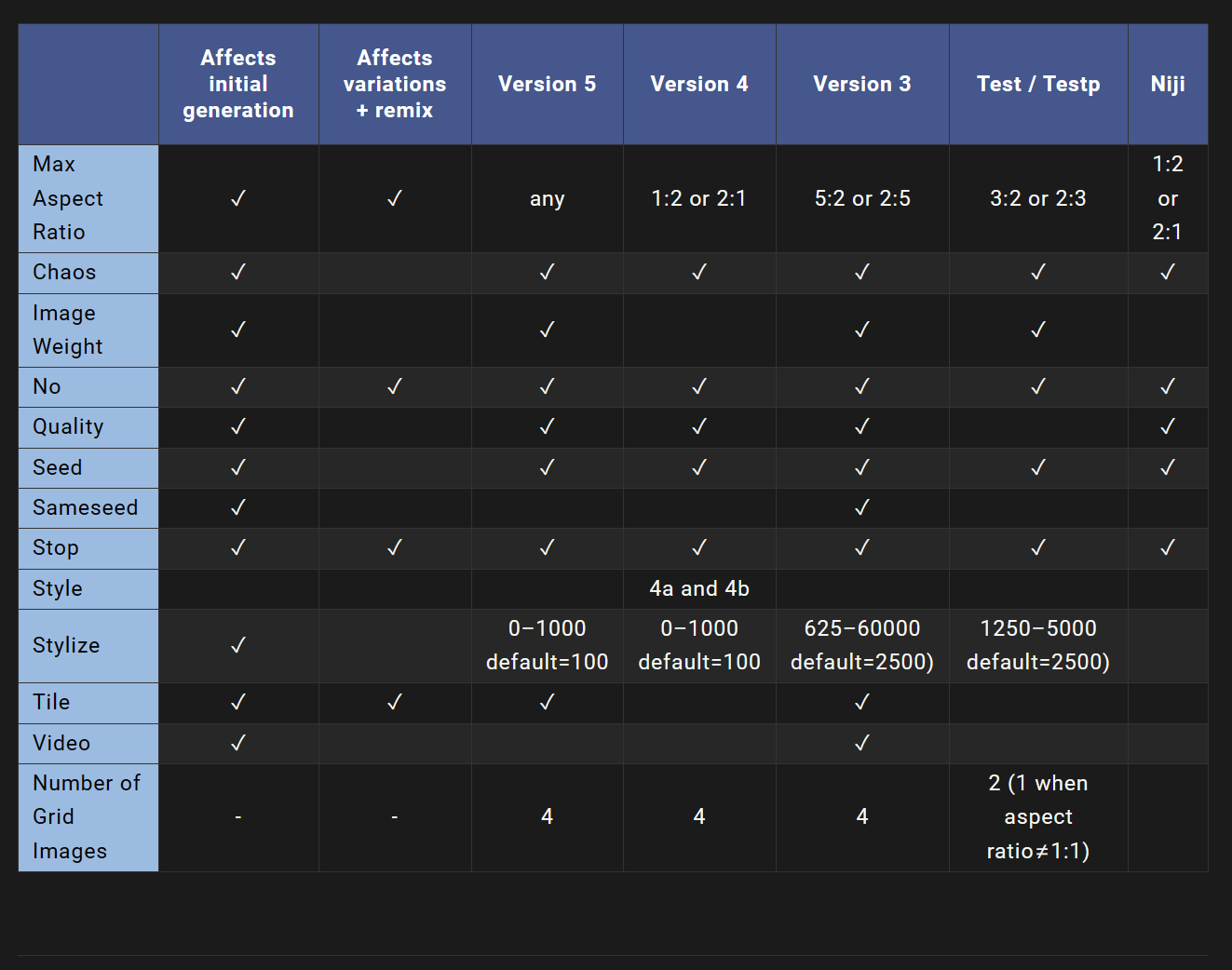
Midjourney定期发布新的模型版本,以提高效率、连贯性和质量。最新的模型是默认的,但可以使用–version或–v参数使用其他模型,或者使用/settings命令选择一个模型版本。不同的模型在不同类型的图像上表现出色。
–version 接受1、2、3、4和5这些值。
–version 可以缩写为–v。
Midjourney V5模型是最新和最先进的模型,于2023年3月15日发布。要使用此模型,在提示的末尾添加–v 5参数,或使用/settings命令选择5️⃣ MJ Version 5。
该模型具有非常高的连贯性,擅长解释自然语言提示,具有更高的分辨率,并支持高级功能,例如使用–tile进行重复图案。
使用Midjourney V5模型,您可以生成更具真实感和细节的图像,并更好地控制生成的结果。无论是在视觉效果还是使用体验上,它都是Midjourney Bot的一个重大进步。

Midjourney V4模型是全新的代码库和全新的AI架构,由Midjourney设计并在新的Midjourney AI超级集群上进行训练。最新的Midjourney模型具有更多关于生物、地点、物品等方面的知识。它在准确把握小细节方面表现得更好,并且可以处理带有多个角色或物体的复杂提示。第四版模型支持高级功能,例如图像提示和多提示。
该模型具有非常高的连贯性,擅长处理图像提示。它可以生成更逼真和细节丰富的图像,并支持多个角色或物体的复杂提示。在使用Midjourney Bot时,它是一个非常有用和可靠的工具。

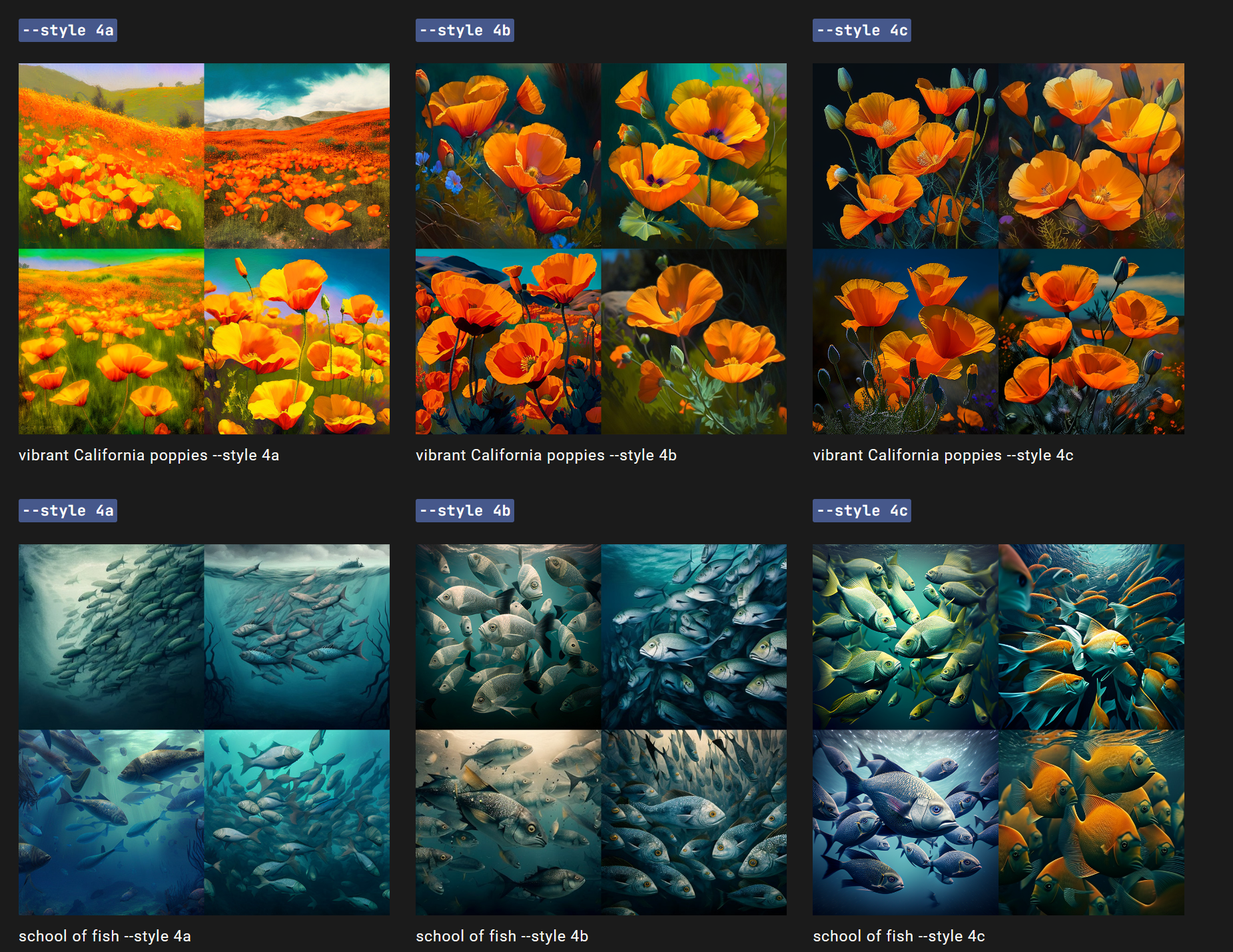
Midjourney模型V4有三种略微不同的“风格”,对模型的风格调整进行了轻微的微调。
通过在V4提示的末尾添加--style 4a、--style 4b或--style 4c来尝试这些版本。
--v 4 --style 4c是当前的默认选项,不需要添加到提示的末尾。
关于风格4a和4b的说明
--style 4a和--style 4b只支持1:1、2:3和3:2的宽高比。
--style 4c支持高达1:2或2:1的宽高比。
您可以使用--version或--v参数,或使用/settings命令选择一个模型版本来访问早期的midjourney模型。不同的模型在不同类型的图像上表现出色。
例如,使用--v 1参数创建如下提示:
/imagine prompt vibrant California poppies --v 1
这将使用Midjourney V1模型生成一张充满活力的加州yingsu花的图像。请注意,旧版模型可能不如新版模型在处理复杂的提示时表现出色,并且可能生成较少细节丰富的图像。
niji模型是Midjourney和Spellbrush之间的合作,旨在产生动漫和插图风格的图像。–niji模型具有更多的动漫、动漫风格和动漫美学知识。它在动态和行动镜头以及一般的角色重心构图方面表现出色。
例如,使用–niji参数创建如下提示:
/imagine prompt vibrant California poppies --niji
这将使用niji模型生成一张充满活力的加州罂粟花的图像,具有动漫风格的特点。请注意,与其他Midjourney模型不同,niji模型在动漫和插图风格的图像上表现出色,并可能生成更多的细节和较为独特的图像。
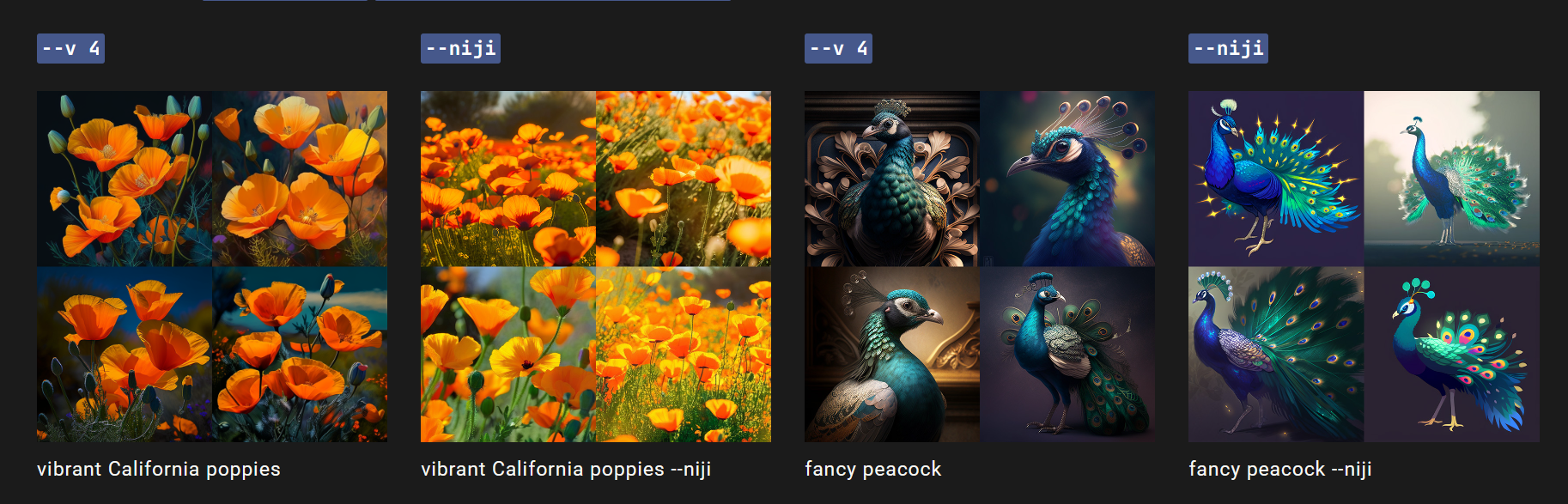
关于–niji模型的注意事项
–niji模型不支持–stylize参数。如果需要重新设置默认样式设置,请使用/settings命令并选择“Style Med”选项来重置所有–niji提示的默认样式设置。
–niji模型支持多个提示或图像提示。请注意,与其他Midjourney模型不同,–niji模型在生成动漫和插图风格的图像方面表现出色,但不支持所有其他Midjourney模型的高级功能,例如–stylize参数。
偶尔会发布新的模型供社区测试和反馈。目前有两个可用的测试模型:–test和–testp,可以与–creative参数结合使用,以生成更多样化的构图。
例如,使用–testp和–creative参数创建如下提示:
/imagine prompt vibrant California poppies --testp --creative
这将使用Midjourney的测试模型(testp)生成一张充满活力的加州罂粟花的图像,并尝试使用创意方式进行构图。请注意,测试模型仅供测试和反馈之用,可能不如正式模型在生成质量和速度方面表现出色。
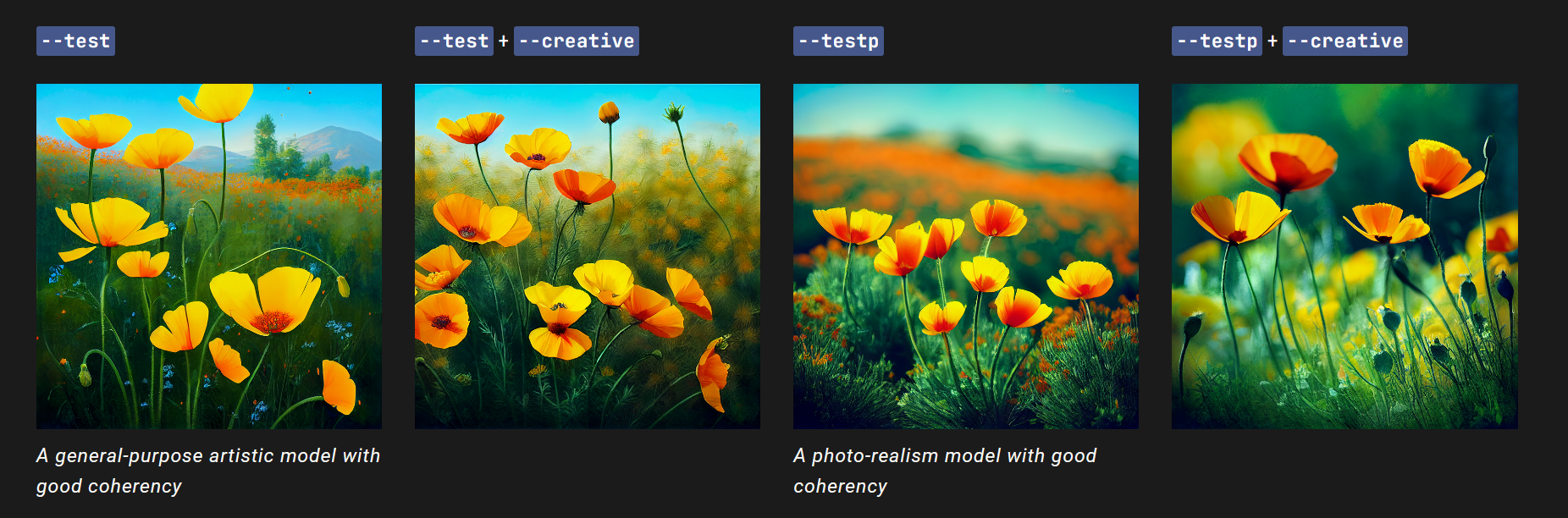
关于当前测试模型–test和–testp的注意事项
测试模型仅支持–stylize值在1250-5000之间。 测试模型不支持多个提示或图像提示。 测试模型的最大宽高比为3:2或2:3。
当宽高比为1:1时,测试模型仅生成两个初始网格图像。 当宽高比不为1:1时,测试模型仅生成一个初始网格图像。
提示文本中靠前的单词可能比靠后的单词更重要。
请注意,测试模型仅供测试和反馈之用,可能不如正式模型在生成质量和速度方面表现出色,并且可能具有其他限制和限制。
使用Version或Test参数
在提示的末尾添加
--v 1、--v 2、--v 3、--v 4、--v 4 --style 4a、--v 4 --style 4b、--test、--testp、--test --creative、--testp --creative或--niji。
例如,如果您想在Midjourney的测试模型上生成一张狗的图片,请使用以下提示:
/imagine prompt dog --test
这将使用Midjourney的测试模型生成一张狗的图片。请注意,与其他Midjourney模型不同,测试模型仅供测试和反馈之用,可能不如正式模型在生成质量和速度方面表现出色,并且可能具有其他限制和限制。

键入/settings并从菜单中选择您喜欢的版本。例如,如果您想在Midjourney的V4模型上生成一张狗的图片,请执行以下操作:
/settings
选择4️⃣ MJ Version 4
这将设置Midjourney的V4模型为默认模型,以便在下一次生成图片时使用它。请注意,如果您希望使用其他版本的模型(如–niji或测试模型),则需要在提示的末尾添加相应的参数,而不是使用/settings命令。

Midjourney首先为每个Job生成低分辨率图像选项的网格。您可以使用Midjourney升频器对任何网格图像进行升级,增加大小并添加额外的细节。有多个升频器模型可用于放大图像。
每个图像网格下方的U1 U2 U3 U4按钮用于升级所选的图像。
Midjourney的尺寸和大小
所有大小均适用于1:1的正方形宽高比。
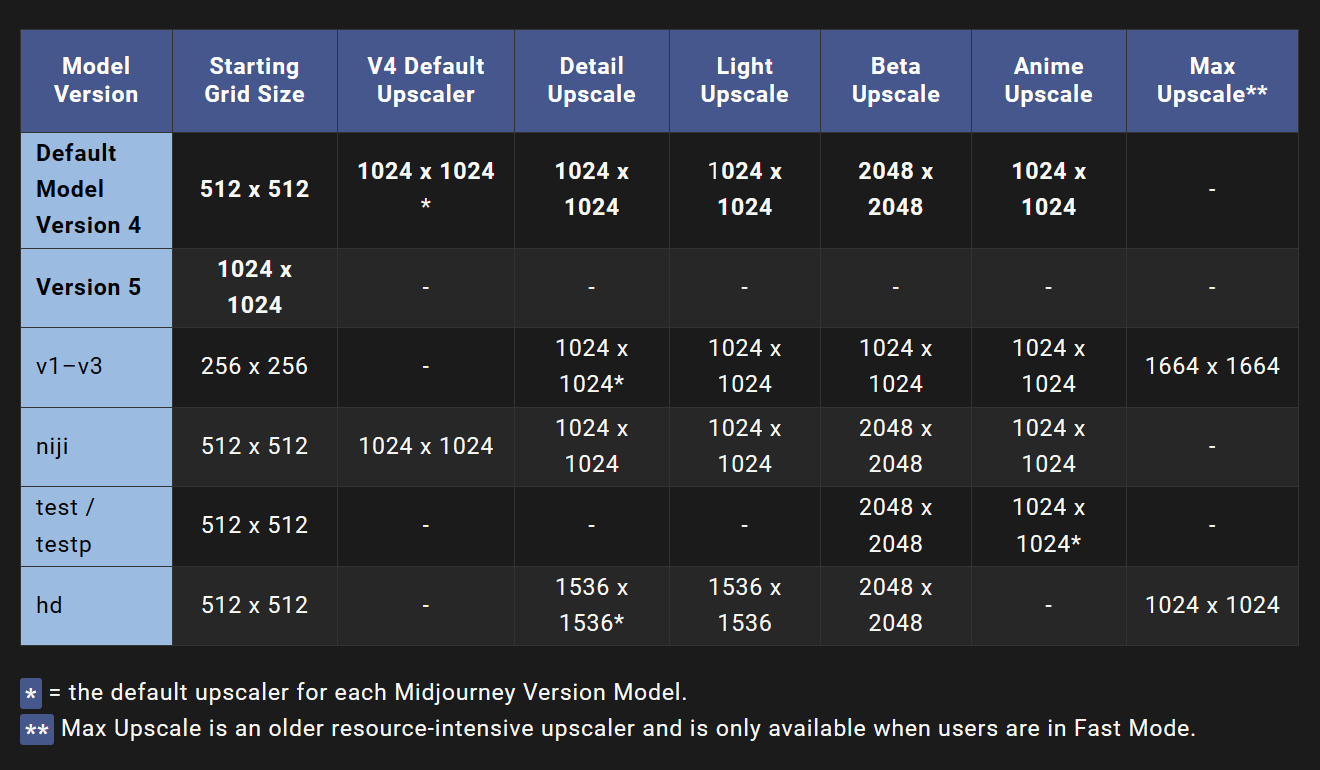
中文版表格
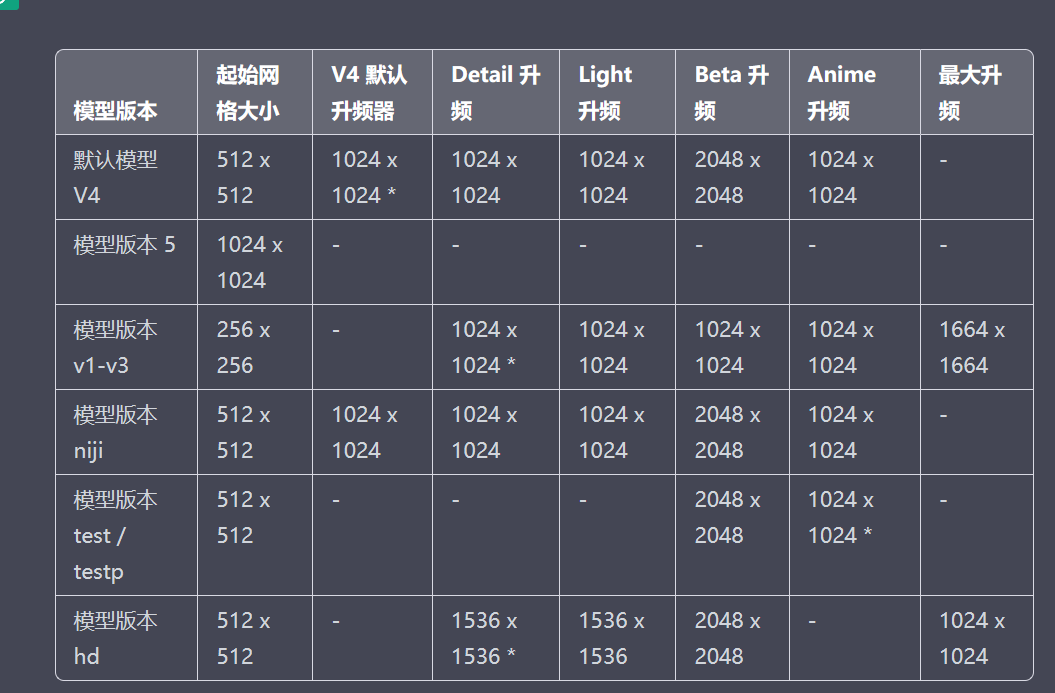
每个Midjourney版本模型的默认升频器。
Max Upscale是一个旧的资源密集型升频器,仅在用户处于快速模式时可用。
Midjourney Model 5 最新的Midjourney模型版本5可以生成高分辨率1024 x1024
px的图像网格,无需额外的升频步骤即可完成。当使用Midjourney模型版本5时,每个图像网格下方的U1 U2 U3
U4按钮将从初始图像网格中分离所选图像。
常规(默认)升频器
最新的默认升频器会增加图像大小,同时平滑或精细化细节。在初始网格图像和完成的升频图像之间,一些小元素可能会发生变化。

轻量级升频器创建一个1024px x 1024px的图像,添加适量的细节和纹理。当使用旧版Midjourney模型时,对于面部和平滑表面,轻量级升频器非常有用。
使用--uplight参数更改U1 U2 U3 U4升频按钮的行为,以使用轻量级升频器。

详细升频器创建一个1024px x 1024px的图像,并在图像中添加许多额外的细节。
使用详细升频器升频的图像可以再次使用“Upscale to Max”按钮进行升频,以获得最终分辨率为1664px x 1664px的图像。Upscale to Max仅在快速模式下可用。
详细升频器是Midjourney模型版本V1、V2、V3和hd的默认升频器。

Beta Upscaler是一种能够创建2048像素x2048像素图像的算法,而不会添加太多额外的细节。Beta Upscaler适用于处理人脸和光滑表面。
使用“–upbeta”参数可以改变U1、U2、U3、U4升级按钮的行为,使其使用Beta Upscaler算法。

Anime Upscaler是“–niji”模型的默认放大器。它将图像放大到1024px x 1024px,并且经过优化,可很好地处理插画和动漫风格的图像。
使用“–upanime”参数可以更改U1 U2 U3 U4升级按钮的行为,以使用Anime Upscaler。

Remaster是对使用V1、V2或V3模型版本之一进行先前放大的图像的另一种选项。Remaster将使用–test和–creative参数再次对图像进行放大,以融合原始图像的构图和新的–test模型的连贯性。
通过单击原始放大下方的🆕 Remaster按钮,可以对先前放大的任何作业进行Remaster。
要Remaster非常旧的作业,请使用/show命令在Discord中刷新该作业。

左边:使用默认放大器放大的图像。右边:重新制作的图像。
Remaster注意事项
仅适用于长宽比高达2:3或3:2的图像。
在多个Prompts情况下结果不一致。
不适用于图像提示。

⏫ 常规放大 ⬆️ 轻放大 🔥 Beta Upscale
输入/settings,然后从菜单中选择您喜欢的放大器。
在提示的末尾添加–uplight、–upbeta或–upanime。

⏫ 常规放大 ⬆️ 轻放大 🔥 Beta Upscale
放大图像后,您将看到图像下面一排按钮,让您可以使用不同的放大器模型重新进行放大。
您可以通过输入命令与Midjourney Bot在Discord上进行交互。命令用于创建图像、更改默认设置、监视用户信息和执行其他有用的任务。Midjourney命令可以在任何Bot频道中使用,在允许Midjourney Bot运行的私人Discord服务器上使用,或在与Midjourney Bot的直接消息中使用。
获取问题的答案。
轻松混合两个图像。
切换通知ping以获取#每日主题频道更新
在官方Midjourney Discord服务器中使用,快速生成链接以涵盖本用户指南中的主题!
在官方Midjourney Discord服务器中使用,快速生成流行的提示craft频道FAQ链接。
切换到快速模式。
显示有关Midjourney Bot的有用基本信息和提示。
使用提示生成图像
查看有关您的帐户以及任何排队或正在运行的作业的信息。
对于Pro Plan订户:切换到隐身模式
对于Pro Plan订户:切换到公共模式
为用户的帐户页面生成个人链接。
查看和调整Midjourney Bot的设置
创建或管理自定义选项。
查看当前自定义选项。
指定要添加到每个提示结尾的后缀。
使用图像作业ID在Discord中重新生成作业。
切换到放松模式。
切换Remix模式。
/private(已替换为’/ stealth’)
/pixels
/idea
使用/info命令查看有关您当前排队和运行作业、订阅类型、续订日期等信息。
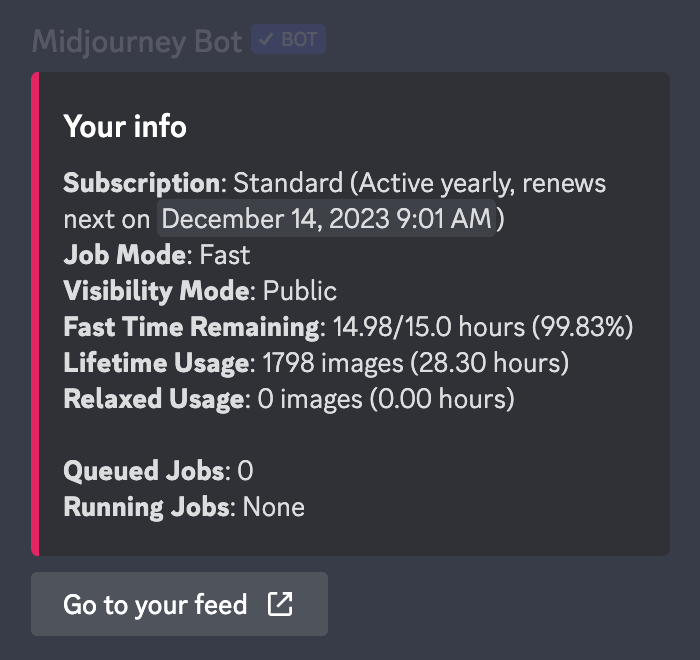
订阅部分显示您订阅的计划以及下一个续订日期。
显示您当前是否处于快速模式或放松模式。只有标准计划和专业计划订户才能使用放松模式。
显示您当前是否处于公共模式或隐身模式。只有专业计划订户才能使用隐身模式。
显示您本月剩余的快速GPU时间。快速GPU时间每月重置,不会累积。
显示您的Midjourney生命周期统计信息。图像包括所有类型的生成(初始图像网格、放大、变化、Remix等)。
显示您本月的放松模式使用情况。重度放松模式用户将体验稍慢的排队时间。放松使用量每月重置。
列出所有等待运行的作业。最多可以同时排队七个作业。
列出所有当前正在运行的作业。最多可以同时运行三个作业。
在任何Bot频道或您的直接消息中输入/info。只有您能够看到您的Info弹出窗口。

设置命令提供了常见选项的切换按钮,例如模型版本、样式值、质量值和放大器版本。设置还具有/stealth和/public命令的切换按钮。

设置用于作业的模型版本。
只有Midjourney订阅用户才能使用模型版本5。

设置用于作业的质量参数。
半质量=–q .5,基本质量=–q 1,高质量=–q 2。

设置用于作业的Stylize参数。
Style Low = --s 50,Style Med = --s 100,Style High = --s 250,Style Very High = --s 750。

在公共模式和隐身模式之间切换。对应于/public和/stealth命令。
切换到Remix模式。

在快速模式和放松模式之间切换。对应于/fast和/relax命令。
设置注意事项
添加到提示末尾的参数将覆盖使用/settings所做的选择。
使用prefer命令创建自定义选项,以便自动将常用参数添加到提示的末尾。
/prefer auto_dm已完成的作业将自动发送到直接消息
/prefer option创建或管理自定义选项。
/prefer option list查看当前自定义选项。
/prefer suffix指定要添加到每个提示末尾的后缀。
/prefer option set <name> <value>创建一个自定义参数,您可以使用它快速地将多个参数添加到提示的末尾。

/prefer option set mine --hd --ar 7:4创建一个名为“mine”的选项,它转换为–hd --ar 7:4。

使用/imagine prompt vibrant California poppies --mine,被解释为/imagine prompt vibrant California poppies --hd --ar 7:4。
将“value”字段留空以删除选项。
/prefer option list列出使用prefer option set创建的所有选项。用户最多可以拥有20个自定义选项。

要删除自定义选项,请使用/prefer option set <name to delete>并留空值字段。
/prefer suffix自动在所有提示后追加指定的后缀。使用不带值的命令进行重置。
命令示例:/prefer suffix --uplight --video
只有参数可以与/prefer suffix一起使用,
prefer suffix --no orange是被接受的
prefer suffix orange::-1是不被接受的
您可以使用唯一的作业ID和/show命令将作业移动到另一个服务器或频道,恢复丢失的作业,或刷新旧作业以创建新的变体、放大或使用更新的参数和功能。
/show仅适用于您自己的作业。
作业ID是Midjourney生成的每个图像使用的唯一标识符。
作业ID看起来像这样:9333dcd0-681e-4840-a29c-801e502ae424,可以在所有图像文件名的第一部分、网站上的URL和图像文件名中找到。
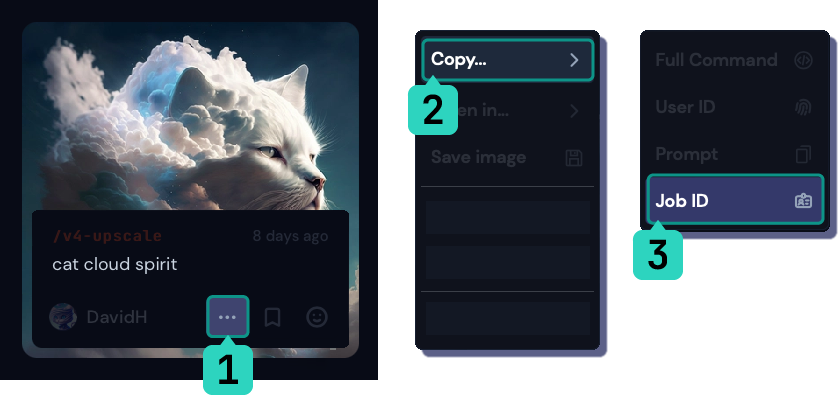
您可以通过选择… > 复制… > 作业ID在成员画廊中找到任何图像的作业ID。
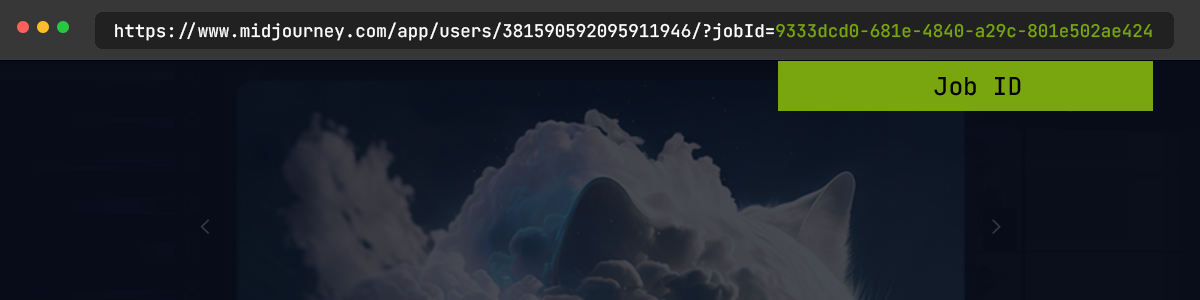
当在Midjourney画廊中查看图像时,作业ID是URL的最后一部分。
https://www.midjourney.com/app/users/381590592095911946/?jobId=9333dcd0-681e-4840-a29c-801e502ae424。
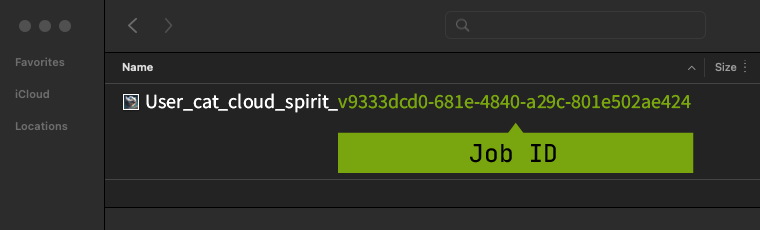
当查看您从画廊中下载的图像时,作业ID是文件名的最后一部分。
User_cat_cloud_spirit_9333dcd0-681e-4840-a29c-801e502ae424.png
使用信封表情符号✉️将完成的作业发送到直接消息中。直接消息将包括图像的种子编号和作业ID。✉️反应仅适用于您自己的作业。
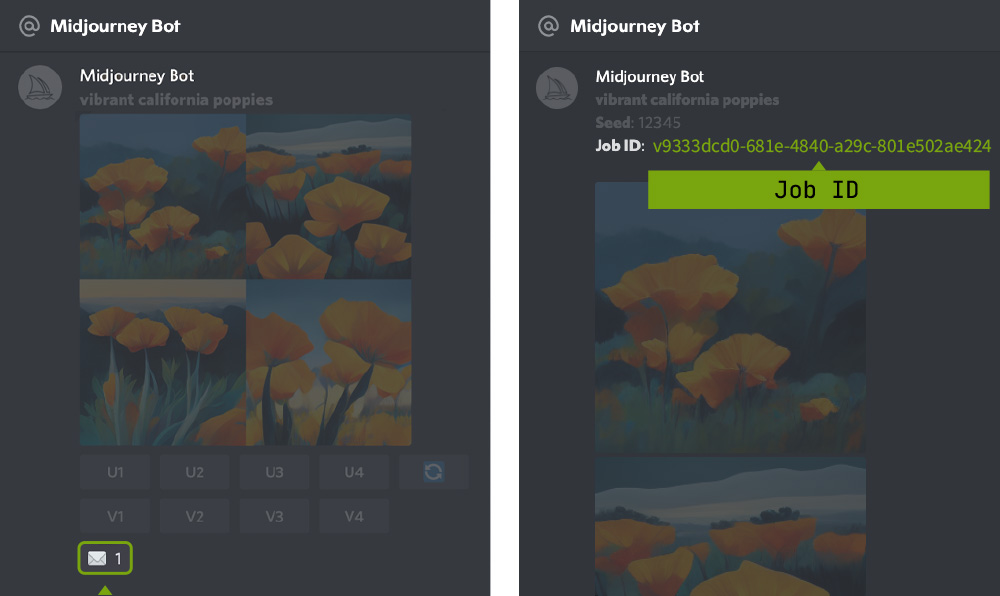
在任何机器人频道中使用/show <作业ID #>来恢复作业。

/blend命令允许您快速上传2-5个图像,然后查看每个图像的概念和美学,并将它们合并成一个新的图像。
/blend与在/imagine中使用多个图像提示相同,但接口经过优化,易于在移动设备上使用。
/blend可处理多达5个图像。要在提示中使用超过5个图像,请使用/imagine的图像提示。
/blend不适用于文本提示。要同时使用文本和图像提示,请使用图像提示和/imagine的文本。
在输入/blend命令后,您将被提示上传两张照片。当使用移动设备时,可以从硬盘拖放图像或从照片库中添加图像。要添加更多图像,请选择可选字段并选择image3、image4或image5。/blend命令启动可能比其他命令慢,因为必须在Midjourney Bot处理您的请求之前上传您的图像。
混合图像具有默认的1:1长宽比,但您可以使用可选的尺寸字段在正方形长宽比(1:1)、竖向长宽比(2:3)或横向长宽比(3:2)之间进行选择。
自定义后缀会添加到/blend提示的末尾,就像其他任何/imagine提示一样。作为/blend命令的一部分指定的长宽比将覆盖自定义后缀中的长宽比。
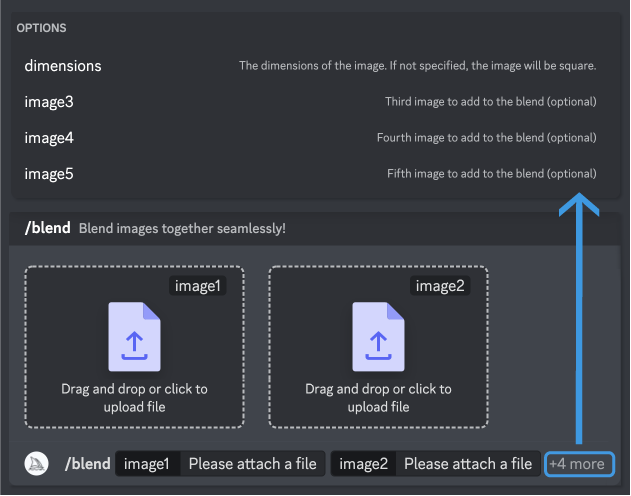
混合提示 为了获得最佳结果
请上传与所需结果相同长宽比的图像。

参数是添加到提示中的选项,它们可以改变图像生成的方式。参数可以改变图像的纵横比,切换 Midjourney 模型版本,更改使用的 Upscaler,以及许多其他选项。参数始终添加到提示的末尾,您可以为每个提示添加多个参数。
以下是 Midjourney 参数的使用示例。
使用苹果设备吗?
许多苹果设备会自动将双连字符(–)更改为短划线(—)。Midjourney 接受两种形式!

–aspect 或 --ar 改变生成图像的纵横比。
–chaos <数字 0-100> 改变结果的多样性程度。较高的值会产生更不寻常和意外的生成物。
–no 否定提示,例如 --no plants 意味着从图像中删除植物。
–quality <.25、.5、1 或 2> 或 --q <.25、.5、1 或 2> 决定你想要花费多少时间来提高渲染质量。默认值为 1。较高的值会产生更高的成本,较低的值会产生较低的成本。
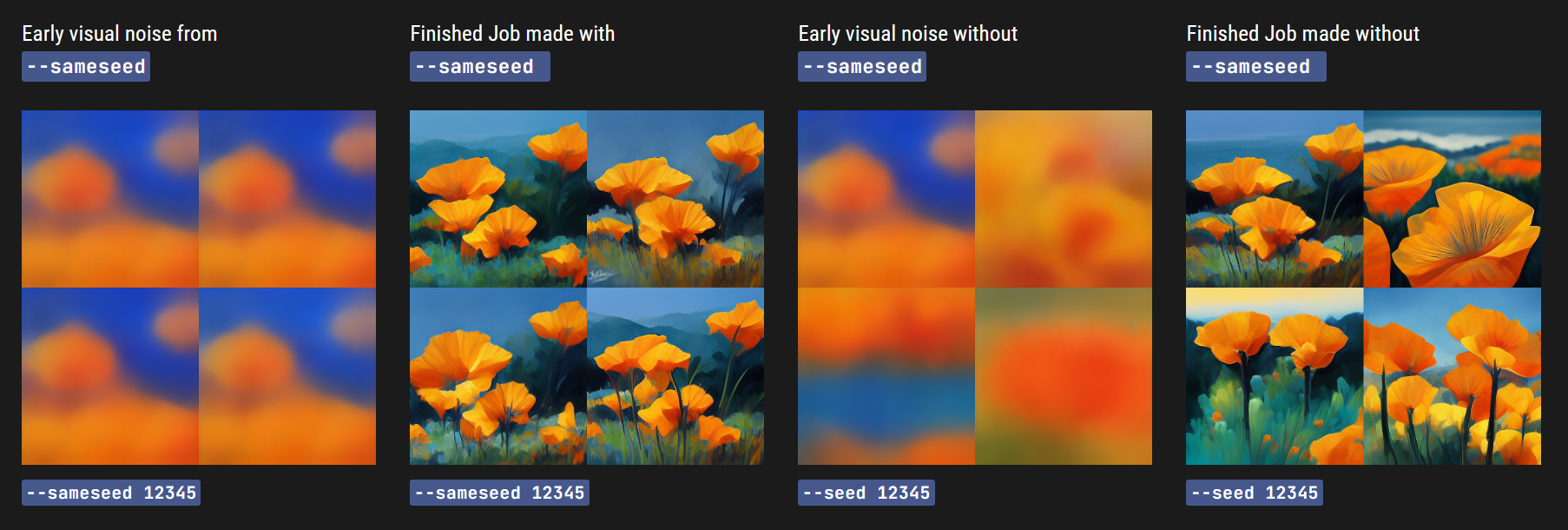
–seed <0-4294967295 之间的整数> Midjourney 机器人使用一个种子数字创建视觉噪音的图像,例如电视静态图像,作为生成初始图像网格的起点。每个图像都会随机生成种子数字,但可以使用 --seed 或 --sameseed 参数指定。使用相同的种子数字和提示将产生相似的最终图像。
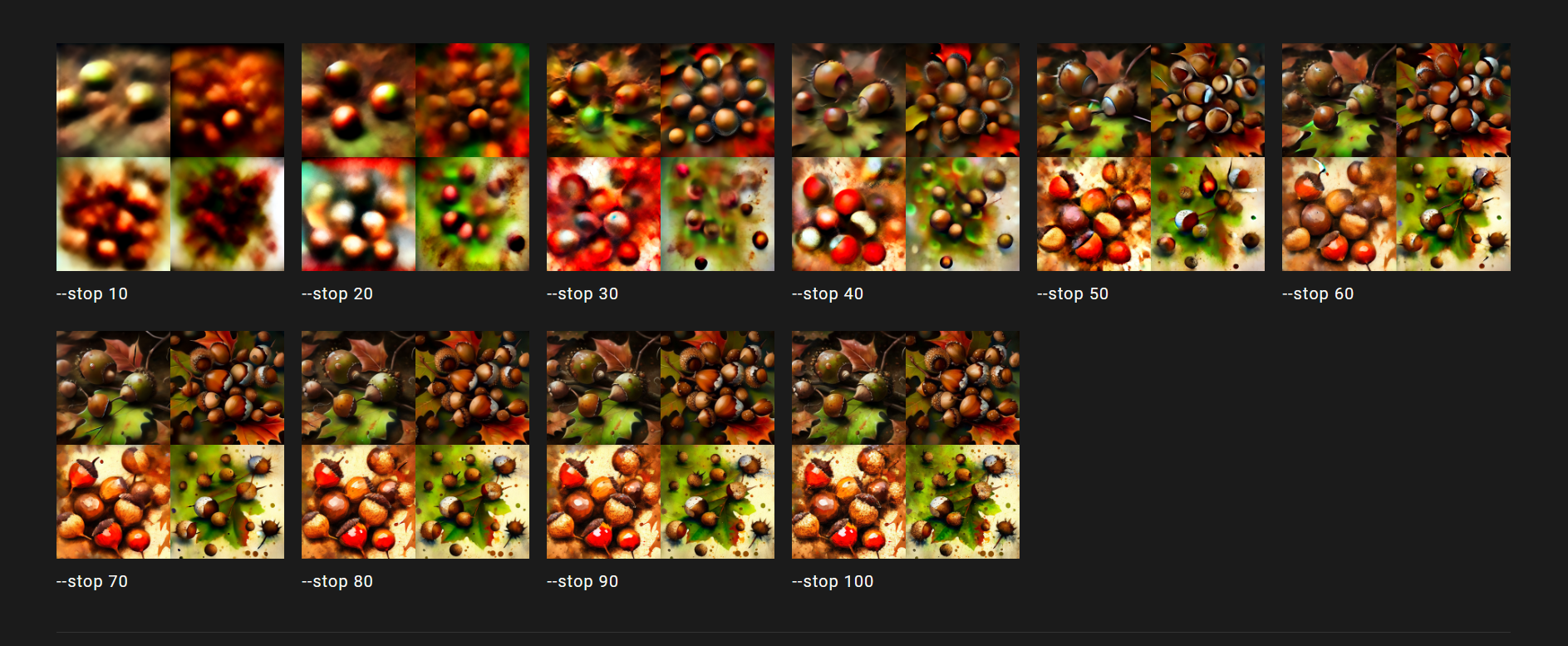
–stop <10-100 之间的整数> 使用 --stop 参数在作业处理过程的中途结束。在更早的百分比处停止作业可能会产生模糊、不太详细的结果。
–style <4a、4b 或 4c> 在 Midjourney 模型版本 4 的不同版本之间切换。
–stylize <数字> 或 --s <数字> 参数影响 Midjourney 默认美学风格对作业的应用程度。
–uplight 在选择 U 按钮时使用替代的“光线”上采样器。结果更接近原始的网格图像。上采样后的图像较少详细,更加平滑。
–upbeta 在选择 U 按钮时使用替代的 beta 上采样器。结果更接近原始的网格图像。上采样后的图像增加的细节显著减少。
Midjourney 定期发布新的模型版本,以提高效率、连贯性和质量。不同的模型擅长于不同类型的图像。
–niji 一种专注于动漫风格图像的替代模型。
–hd 使用早期的替代模型,生成更大、不太一致的图像。该算法可能适用于抽象和景观图像。
–test 使用 Midjourney 的特殊测试模型。
–testp 使用 Midjourney 的专门面向摄影的测试模型。
–version <1、2、3、4 或 5> 或 --v <1、2、3、4 或 5> 使用 Midjourney 算法的不同版本。当前算法(V4)是默认设置。
Midjourney 首先为每个作业生成低分辨率图像网格。您可以在任何网格图像上使用 Midjourney 上采样器来增加大小并添加额外的细节。有多个上采样模型可用于放大图像。
–uplight 在选择 U 按钮时使用替代的“光线”上采样器。结果更接近原始的网格图像。上采样后的图像较少详细,更加平滑。
–upbeta 在选择 U 按钮时使用替代的 beta 上采样器。结果更接近原始的网格图像。上采样后的图像增加的细节显著减少。
在选择 U 按钮时使用一个专门针对 --niji Midjourney 模型训练的替代上采样器。
这些参数仅适用于早期的 Midjourney 模型。
–creative 修改测试和测试p模型,使其更加多样和有创意。
–iw 相对于文本权重设置图像提示权重。默认值为 --iw 0.25。
–sameseed 种子值创建一个应用于初始网格中的所有图像的单个大随机噪声场。当指定 --sameseed 时,初始网格中的所有图像使用相同的起始噪声,将生成非常相似的生成图像。
–video 保存一个初始图像网格生成过程的进度视频。完成图像网格的表情符号以✉️的形式响应,触发将视频发送到您的直接消息中。在放大图像时,–video 不起作用。
宽高比(Aspect Ratios)是指图像的宽度与高度的比率。通常用冒号分隔的两个数字表示,例如 7:4 或 4:3。一个正方形图像的宽高比为 1:1,表示宽度和高度相等。例如,1000px × 1000px 或 1500px × 1500px 的正方形图像的宽高比都是 1:1。计算机屏幕通常有 16:10 的宽高比,表示宽度是高度的 1.6 倍。因此,图像可以是 1600px × 1000px、4000px × 2000px、320px × 200px 等等。
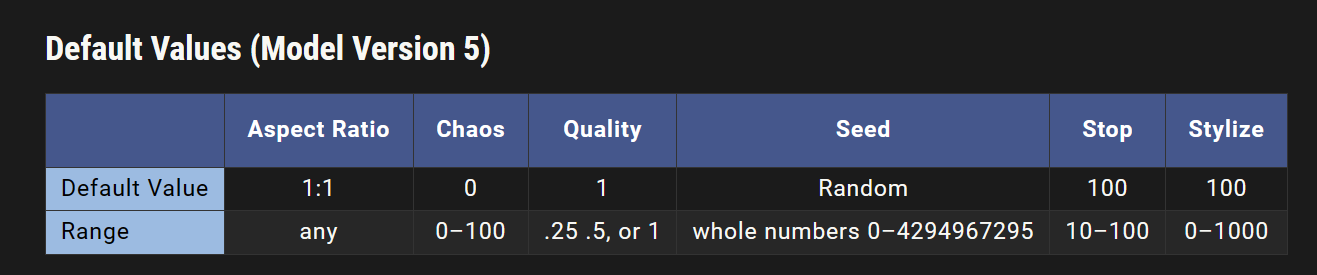
默认的宽高比是 1:1。
–aspect 参数必须使用整数,例如应该使用 139:100 而不是1.39:1。
宽高比会影响生成的图像的形状和构图。
在放大图像时,一些宽高比可能会略微改变。
不同版本的 Midjourney 模型有不同的最大宽高比限制。例如,以下是各个版本的最大宽高比:
Version 5:任何宽高比(*实验性的宽高比大于 2:1 可能会产生不可预测的结果)
Version 4c(默认):1:2 到 2:1
Version 4a 或 4b:仅限 1:1、2:3 或 3:2
Version 3:5:2 到 2:5
Test / Testp:3:2 到 2:3
niji:1:2 到 2:1

–ar 参数可以接受从 1:1(正方形)到每个模型的最大宽高比之间的任何宽高比。但是,在生成或放大图像时,最终输出的图像可能会略微修改。例如,使用 --ar 16:9(1.78)的提示会创建一个宽高比为 7:4(1.75)的图像。
需要注意的是,宽高比大于 2:1 的图像是实验性的,可能会产生不可预测的结果。因此需要谨慎使用。
虽然 --aspect 或 --ar 参数可以接受 1:1(正方形)到每个模型的最大宽高比之间的任何宽高比,但是在生成或放大图像时,最终输出的图像可能会略微修改。

prompt 例子: imagine/ prompt vibrant california poppies --ar 5:4
–aspect 1:1:默认宽高比,表示宽度和高度相等的正方形图像。
–aspect 5:4:常用的相框和印刷比例。
–aspect 3:2:印刷摄影中常见的宽高比。
–aspect 7:4:接近高清电视屏幕和智能手机屏幕的宽高比。
当然,还有其他各种宽高比可供选择,具体取决于使用的 Midjourney 模型。
在提示的末尾添加 --aspect : 或 --ar : 即可改变宽高比。例如,要生成一个宽高比为 5:4 的图像,可以在提示末尾添加 --aspect 5:4。具体使用方法如下:
–aspect ::用指定的宽高比生成图像。
–ar ::与 --aspect 等效,用指定的宽高比生成图像。

–chaos 或 --c 参数可以影响初始图像网格的变化程度。高 --chaos 值会产生更多的不寻常和意外的结果和构图,而低 --chaos 值会产生更可靠、可重复的结果。
–chaos 参数接受 0-100 的值。
默认的 --chaos 值为 0。
使用较低的 --chaos 值,或不指定值,将在每次运行作业时生成稍微有所变化的初始图像网格。这将产生更加可靠和可重复的结果,但也可能会导致生成的图像缺乏想象力和创新性。
prompt example: imagine/ prompt watermelon owl hybrid

使用较高的 --chaos 值将在每次运行作业时生成更加多样和意外的初始图像网格。
例如,运行以下提示:
imagine/ prompt watermelon owl hybrid --c 50
这将生成一个宽高比为 1:1 的图像,其中包含西瓜和猫头鹰的元素,并使用 50 的混沌值来产生更多样化的结果。每次运行该提示都会产生一个略微不同的图像,但这些图像可能具有更多的想象力和创新性。

使用极高的 --chaos 值将在每次运行作业时生成更加多样化的初始图像网格,这些网格可能具有意想不到的构图或艺术媒介。
例如,运行以下提示:
imagine/ prompt watermelon owl hybrid --c 100
这将生成一个宽高比为 1:1 的图像,其中包含西瓜和猫头鹰的元素,并使用最高的 100 的混沌值来产生更加多样化和意外的结果。每次运行该提示都会产生一个截然不同的图像,可能包含更多独特和创意的元素。但需要注意的是,使用极高的混沌值可能会导致生成的图像与您的初始想法差异较大,所以需要谨慎使用。

您可以使用 --chaos 或 --c 参数来更改混沌值。在提示的末尾添加 --chaos 或 --c 即可更改混沌值。例如,要使用混沌值为 50 运行提示,可以在提示末尾添加 --c 50。具体使用方法如下:
–chaos :使用指定的混沌值运行提示。
–c :与 --chaos 等效,使用指定的混沌值运行提示。

–quality 或 --q 参数可以改变生成图像所需的时间。高质量设置需要更长的处理时间,可以生成更多的细节。更高的值也意味着每个作业将使用更多的 GPU 分钟。质量设置不会影响分辨率。
默认的 --quality 值为 1。 较高的值将使用订阅的更多 GPU 分钟。
–quality 接受值 .25、.5 和 1(默认模型)的值。 更大的值将舍入为 1。
–quality 只影响初始图像的生成。
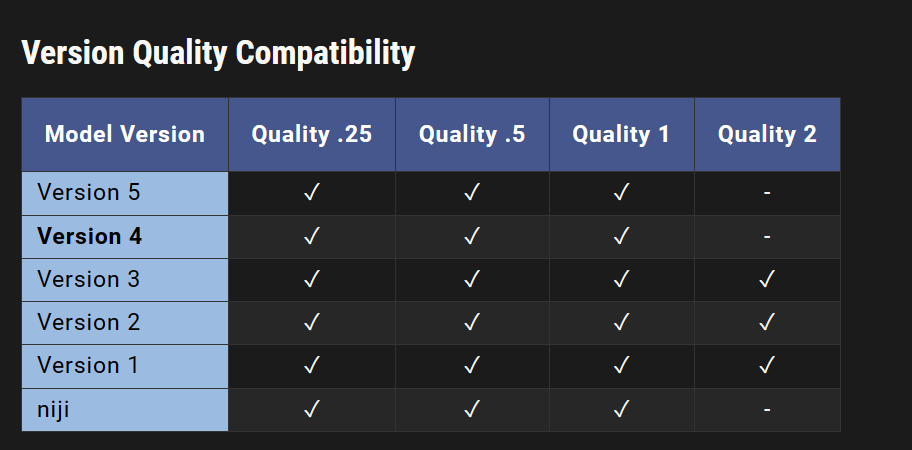
–quality 适用于模型版本 1、2、3、4、5 和 niji。
较高的 --quality 设置并不总是更好的。有时,较低的 --quality 设置可以生成更好的结果,这取决于您想要创建的图像。对于手势抽象的外观,较低的 --quality 设置可能更适合。而对于需要许多细节的建筑图像,较高的 --quality 值可能会改善其外观。选择最能匹配您所期望的图像的设置。
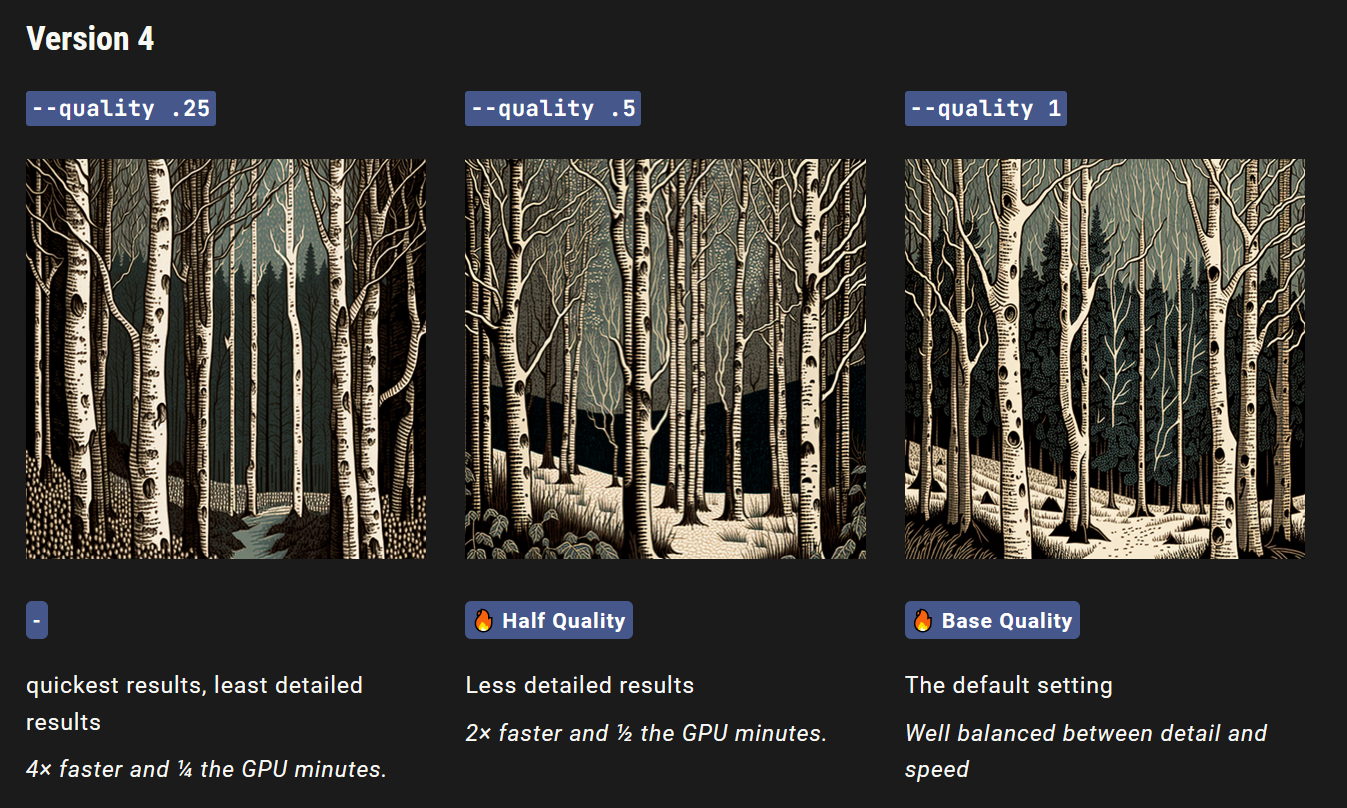
例如,以下提示使用质量设置为 0.25 来生成木刻白桦林的图像:
/imagine prompt woodcut birch forest --q .25

在提示的末尾添加 --quality 或 --q 即可设置质量。例如,要使用质量设置为 0.5 运行提示,可以在提示末尾添加 --q 0.5。具体使用方法如下:
–quality :使用指定的质量值运行提示。
–q :与 --quality 等效,使用指定的质量值运行提示。

键入 /settings 并从菜单中选择您喜欢的质量值。

Midjourney使用一个种子号来创建一个视觉噪声场,例如电视静态图像,作为生成初始图像网格的起点。对于每个图像,种子号是随机生成的,但可以使用 --seed 或 --sameseed 参数指定。使用相同的种子号和提示将生成类似的最终图像。
–seed 接受整数 0-4294967295。
–seed 值只影响初始图像网格。
版本 1、2、3、测试和测试p的 --seed 值是不确定性的,会生成相似但不完全相同的图像。
在版本 4、5 和 niji 中使用相同的 prompt+seed+parameters 将生成完全相同的图像。
如果未指定种子号,Midjourney 将使用随机生成的种子号,每次使用提示时产生各种各样的选项。
以下是使用随机种子号运行三次的提示示例:
/imagine prompt celadon owl pitcher
作业使用随机种子运行三次:
prompt example: /imagine prompt celadon owl pitcher

–种子值创建一个大的随机噪声场,应用于初始网格中的所有图像。指定 --sameseed 时,初始网格中的所有图像都使用相同的起始噪声,并且将产生非常相似的生成图像。
–sameseed接受整数0-4294967295。
–sameseed 仅与模型版本 1、2、3、test 和 testp 兼容。

使用Discord表情符号反应
通过对作业的信封表情符号做出✉️反应,在Discord中查找作业的种子编号。

若要获取过去映像的种子编号,请复制作业 ID,并将 /show <作业 ID #> 命令与该 ID 一起使用以恢复作业。然后,✉️您可以使用信封表情符号对新重新生成的作业做出反应。
使用 or 参数–seed–sameseed
将 或 添加到提示的末尾。–seed –sameseed

使用“–stop”参数来在处理过程中部分完成作业。在较早的百分比处停止作业可能会导致模糊、细节不够清晰的结果。
–stop接受值:10-100。
默认的–stop值为100。
放大时无法使用–stop。
示例:
/imagine prompt splatter art painting of acorns --stop 90
–stop参数在升级作业时不会产生影响。但是,停止将生成一个更柔和、细节较少的初始图像,这将影响最终放大结果的详细程度。下面的放大图像使用了Beta Upscaler。
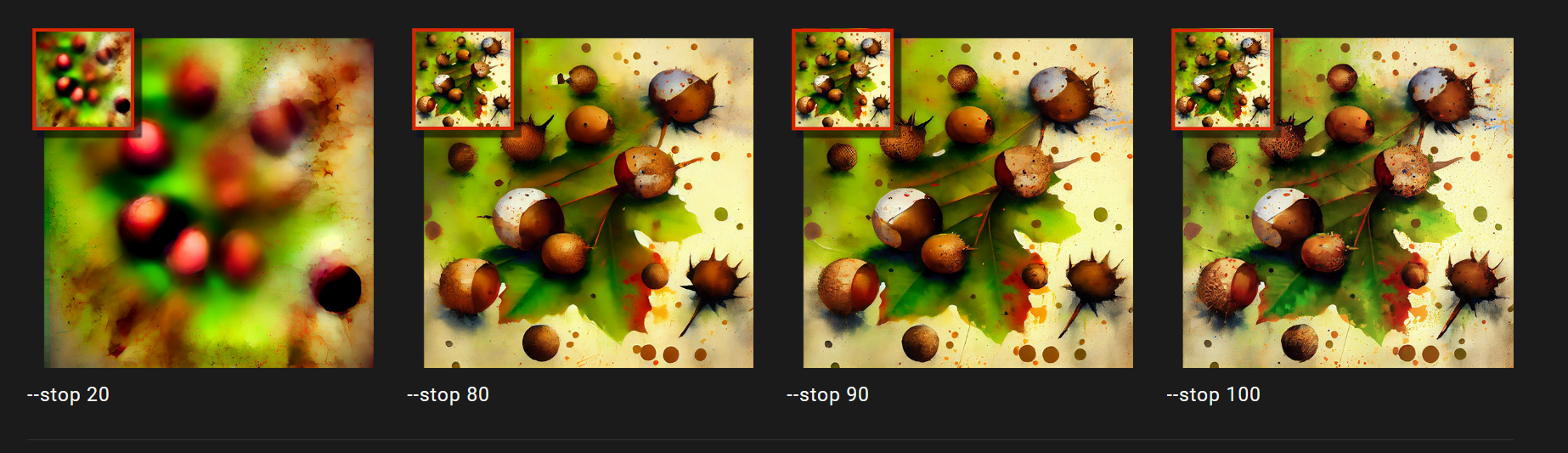
使用 --stop 参数
在提示符的末尾添加 --stop 。

这个Midjourney机器人已经训练出来了,可以生成更偏爱艺术色彩、构图和形式的图片。–stylize或–s参数会影响应用此训练的强度。低样式化值会产生与提示相匹配但不太艺术的图像。高样式化值则会创建非常艺术但与提示联系较少的图像。
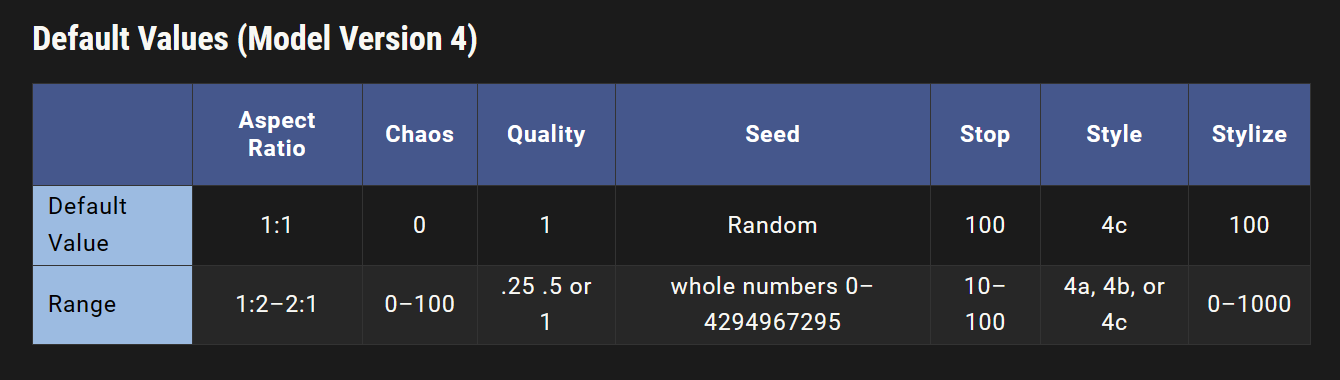
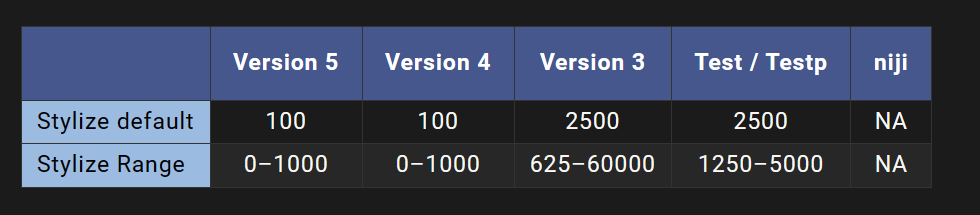
–stylize 的默认值为100,在使用默认[V4模型]时接受0-1000之间的整数值。
不同版本的Midjourney模型具有不同范围的样式化能力。
提示示例:/imagine prompt illustrated figs --s 100
V5模型
提示示例:/imagine prompt colorful risograph of a fig --s 100
在提示符的末尾添加–stylize 或–s 。

输入/settings并从菜单中选择您喜欢的样式值。

–tile参数生成可用作重复平铺的图像,以创建面料、壁纸和纹理的无缝图案。
–tile适用于模型版本1、2、3和5。
–tile仅生成单个平铺。使用类似这种无缝图案检查器的图案制作工具来查看平铺重复。


在您的提示符末尾添加–tile。

Midjourney定期发布新的模型版本以提高效率、连贯性和质量。最新的模型是默认的,但可以使用–version或–v参数或使用/settings命令并选择一个模型版本来使用其他模型。不同的模型在不同类型的图像上表现出色。
–version接受值1、2、3、4和5。
–version可以缩写为–v
Midjourney V5 模型是最新且最先进的模型,于2023年3月15日发布。
要使用此模型,请在提示后添加 --v 5 参数,或者使用 /settings 命令并选择 5️⃣ MJ Version 5。
该模型具有非常高的连贯性,在解释自然语言提示方面表现出色,分辨率更高,并支持诸如 --tile 等高级功能。

Midjourney V4 模型是由 Midjourney 设计的全新代码库和全新 AI 架构,它在新的 Midjourney AI 超级集群上进行了训练。最新的 Midjourney 模型对生物、地点、物体等有更多知识。它更擅长处理小细节,并且可以处理带有多个角色或对象的复杂提示。版本 4 模型支持高级功能,如图像提示和多重提示。
该模型具有非常高的连贯性,在图像提示方面表现出色。

Midjourney模型版本4有三种略微不同的“风味”,对模型的风格调整进行了轻微的调整。通过在V4提示末尾添加–style 4a、–style 4b或–style 4c来尝试这些版本。
–v 4 --style 4c是当前默认设置,无需添加到提示末尾。
关于Style 4a和4b的说明
- style 1a 和 - - style 1b 只支持1:1、2:3和3:2纵横比。
- style 1c 支持高达1:2或2:1的纵横比。
您可以使用 --version 或 --v 参数,或使用 /settings 命令并选择一个模型版本来访问早期中途模型。不同的模型在不同类型的图像上表现出色。
提示示例:/imagine prompt vibrant California poppies --v 1

Niji模型是Midjourney和Spellbrush之间的合作,旨在产生动漫和插画风格。–niji模型对动漫、动漫风格和动漫美学有着更丰富的知识。它擅长于具有活力和行动感的镜头以及一般性质的角色聚焦构图。
提示示例:/imagine prompt vibrant California poppies --niji
关于–niji模型的注释
Niji不支持–stylize参数。请使用/settings命令并选择Style
Med以重置所有–niji提示的默认样式设置。
Niji支持多个提示或图像提示。
偶尔会发布新的模型供社区测试和反馈。目前有两个可用的测试模型:–test和–testp,可以与–creative参数结合使用以获得更多样化的组合。
提示示例:/imagine prompt vibrant California poppies --testp --creative
关于当前测试模型的说明
–test 和 --testp 测试模型仅支持在 1250-5000 之间的 --stylize 值。
测试模型不支持多提示或图像提示。
测试模型最大宽高比为3:2或2:3。
当宽高比为1:1时,测试模型只生成两个初始网格图像。
当宽高比不是1:1时,测试模型只生成一个初始网格图像。
靠近提示前面的单词可能比靠近后面的单词更重要。
在提示符的末尾添加 --v 1、–v 2、–v 3、–v 4、–v 4 --style 4a、–v4 --style 4b --test,–testp,–test --creative,–testp --creative 或者 --niji。

输入/settings并从菜单中选择您喜欢的版本。

使用–video参数创建一个短片,展示您的初始图像网格生成过程。完成任务后,请用信封✉️表情回应,让Midjourney Bot将视频链接发送到您的直接消息中。
--video仅适用于图像网格,不适用于放大。
--video与模型版本1、2、3、测试和测试p一起使用。


提示示例:/imagine prompt Vibrant California Poppies --video
在您的提示末尾添加–video。
任务完成后,单击“添加反应”。
选择 ✉️ 信封表情符号。
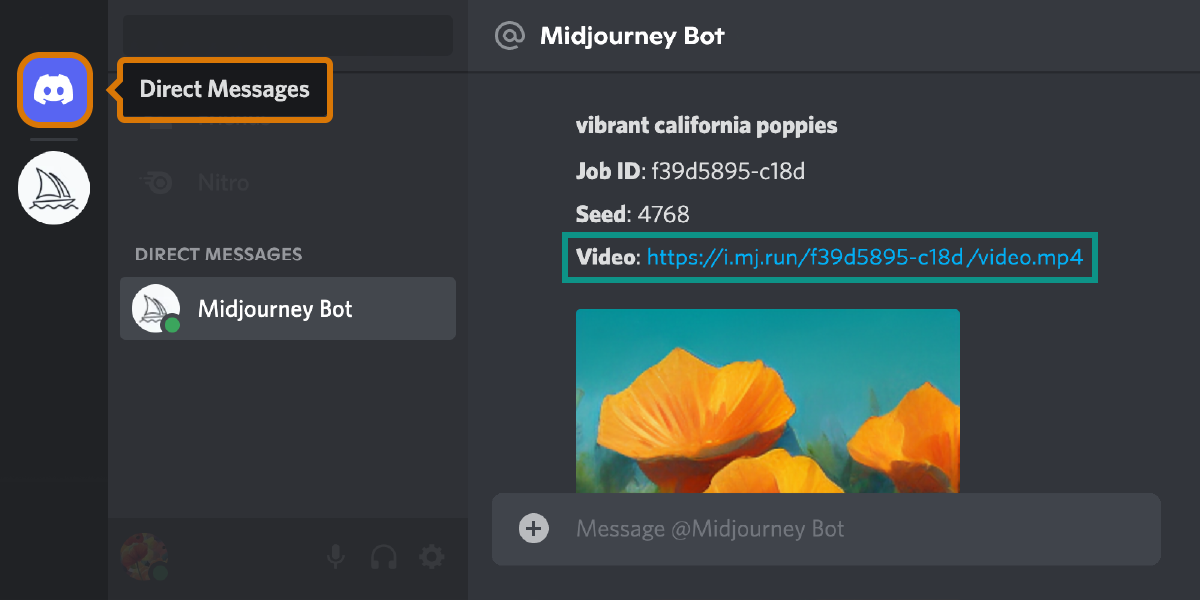
Midjourney机器人将向您的直接消息发送视频链接。
点击链接在浏览器中查看您的视频。右键单击或长按以下载视频。
在提示符的末尾添加 --video。

您可以使用图像作为提示的一部分,以影响工作的构成、风格和颜色。图像提示可以单独使用或与文本提示结合使用——尝试将不同风格的图像组合在一起,获得最令人兴奋的结果。
要添加图像到提示中,请键入或粘贴存储在线上的图片网址。该地址必须以扩展名结尾,如.png、.gif 或 .jpg。添加完图像地址后,再添加任何其他文本和参数来完成提示。

图像提示应放在提示的前面。
提示必须有两个图像或一个图像和其他文本才能工作。
图像URL必须是在线图像的直接链接。
在大多数浏览器中,右键单击或长按一张图片,然后选择复制图片地址以获取URL。
/blend命令是针对移动用户优化的简化图像提示过程。
要将个人图像用作提示的一部分,请将其上传到Discord。 要上传图像,请单击消息输入位置旁边的加号。 选择“上传文件”,选择一个图像,然后发送消息。 要将此图像添加到提示中,请按照通常的方式键入/imagine。 出现提示框后,将图像文件拖动到提示框中以添加图像的URL。 或者,右键单击该图像,选择“复制链接”,然后在提示框内粘贴链接即可。

隐私说明
使用Midjourney机器人在您的直接消息中上传图像,以防止其他服务器用户看到图像。
除非用户启用隐身模式,否则Midjourney网站上会显示图像提示。
雕像 + 花

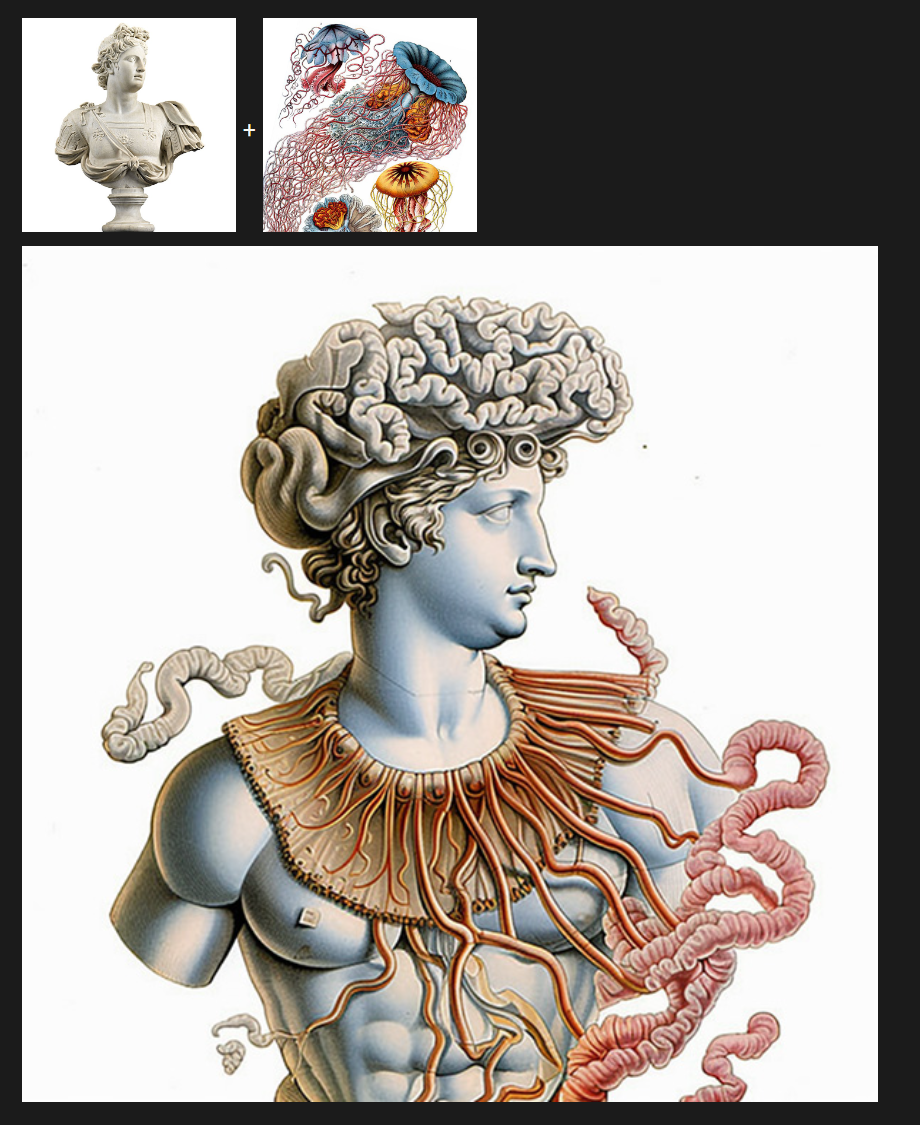
雕像 + 水母

雕像 + 地衣

雕塑+波浪

雕像+地衣+花朵

雕像+花朵

雕像 + 地衣

雕像 + 水母
雕塑+波浪

雕像+地衣+花朵

宽高比提示
为了获得最佳效果,
请将图像裁剪成与最终图像相同的宽高比。
在早期Midjourney模型版本中,图像提示比当前模型更具有抽象性。 图像提示不同于基于(或“初始化”自)起始输入图像构建。 图像提示用作视觉灵感,而不是起点。
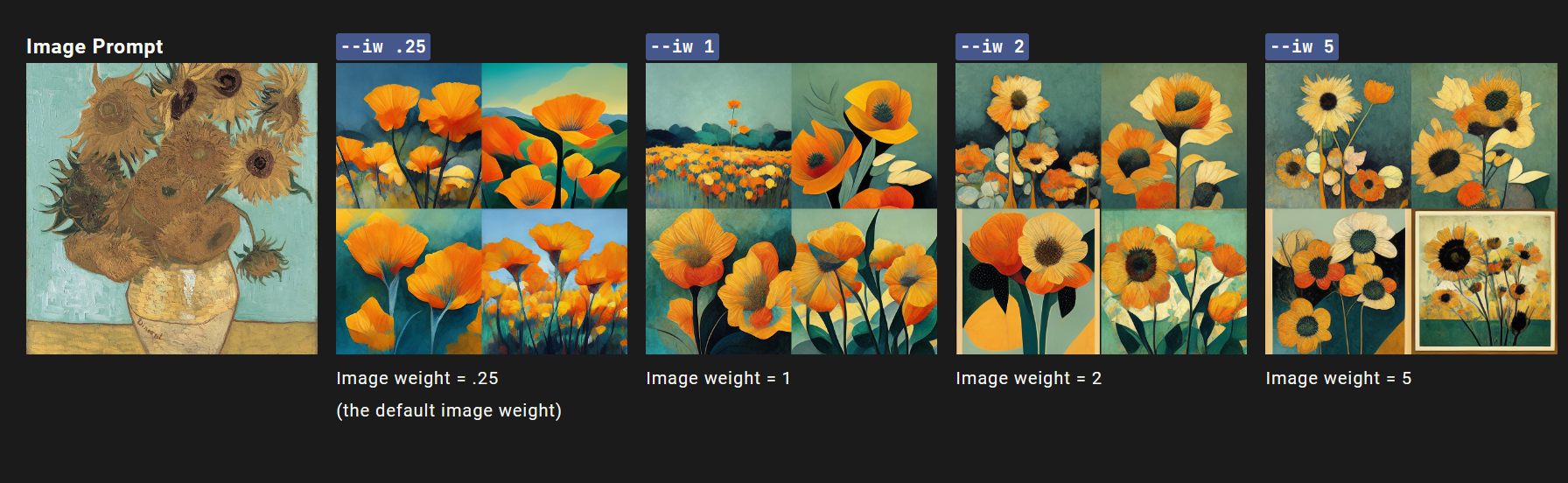
早期的Midjourney模型版本可以使用图像权重参数-iw来调整图片URL与文本之间的重要性。-iw 0.25是默认值,在未指定-iw时使用。 更高的-iw值意味着图像提示将对最终工作产生更大影响。
有关说明书各部分之间相对重要性的详细信息,请参见Multi Prompts页面。
–iw接受整数-10,000至10,000。
示例1:文本提示充满活力的加利福尼亚罂粟花与康定斯基画作为图像提示。
prompt: http://kandinsky.png vibrant California poppies --v 3 --iw

示例2:文本提示充满活力的加利福尼亚罂粟花,结合梵高向日葵的图像提示。
prompt: http://sunflowers.png vibrant California poppies --v 3 --iw
轻松使用混合模式在不同变体之间更改提示、参数、模型版本或宽高比。混合将以您的起始图像的一般组成部分作为新工作的一部分。混音可以帮助改变图像的设置或照明,发展主题,或实现棘手的构图。
Remix是一个实验性功能,可能随时更改或删除。
通过/prefer remix命令激活Remix模式,或者通过/settings命令并切换🎛️ Remix Mode按钮来激活它。当启用Remix时,它会更改图像网格下方变化按钮(V1、V2、V3、V4)的行为。启用Remix后,在每个变化中都允许您编辑提示内容。要对升级进行重新编排,请选择🪄 Make Variations。
启用Remix后,变量按钮在使用时会从蓝色转为绿色。
您可以在使用Remix时切换模型版本。
完成Remix操作后,请使用/settings 或 /prefer remix 命令关闭它。
如果想创建标准图片,则需要在弹出窗口中不修改提示内容,并保持Remix处于活动状态。
南瓜的线描堆叠
打开混合模式。
选择一个图像网格或放大的图像进行混合。
选择“创建变体”。
在弹出窗口中修改或输入新提示。
Midjourney Bot使用新提示生成图像,并受原始图像的影响。


您可以在使用Remix模式时添加或删除参数,但必须使用有效的参数组合。将“/imagine prompt illustrated stack of pumpkins --version 3 --stylize 10000”更改为“illustrated stack of pumpkins --version 4 --stylize 10000”会返回错误,因为Midjourney Model Version 4与Stylize参数不兼容。
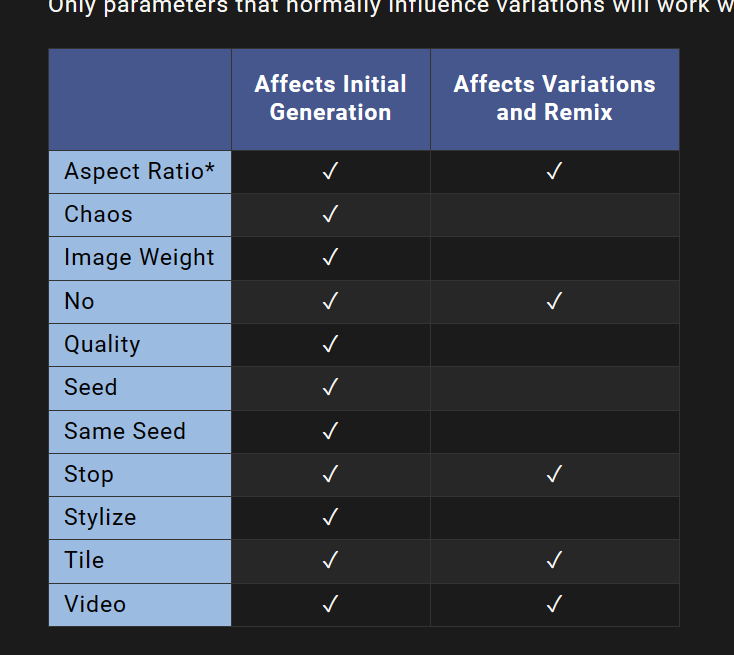
仅当使用Remix时通常影响变化的参数才能起作用:
使用Remix更改画面比例会拉伸图像。它不会扩展画布,添加缺失的细节或修复错误的裁剪。
输入/settings并从弹出窗口中选择Remix。
🎛️ Remix
输入/prefer remix以切换Remix模式的开启和关闭。
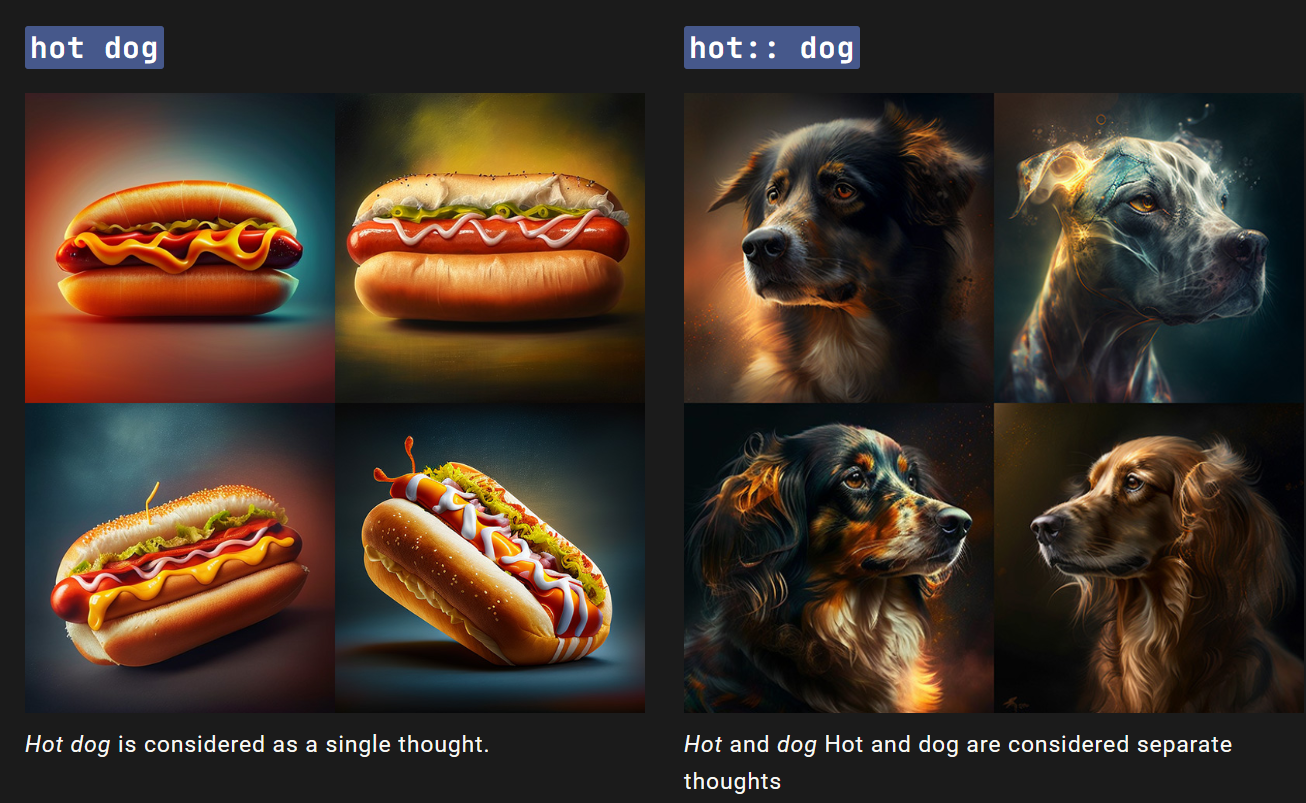
使用 :: 作为分隔符,可以让Midjourney Bot将两个或更多的独立概念单独考虑。分离提示可以使您对提示的部分进行相对重要性的指定。
在提示中添加双冒号::表示Midjourney Bot应该将每个部分的提示单独考虑。
在下面的示例中,对于hot dog这个提示,所有单词都被视为一个整体,Midjourney Bot会生成美味热狗的图像。如果将提示分成两部分hot :: dog,则会将两个概念分别考虑,创建一张温暖的狗的图片。
双冒号之间没有空格::
多重提示适用于模型版本1、2、3、4和niji
任何参数仍然添加到提示的最后。
杯子蛋糕插图被视为一起制作杯子蛋糕的插图图片。
杯子被单独考虑,与蛋糕插图分开制作在杯子里的蛋糕图片。
杯子、蛋糕和插图被分别考虑,产生了一个带有常见插图元素(如花朵和蝴蝶)的杯装蛋糕。
当双冒号::用于将提示分成不同的部分时,您可以在双冒号后立即添加数字,以为该提示的某个部分指定相对重要性。
在下面的示例中,提示hot :: dog生成了一只热狗。将提示更改为hot :: 2 dog使单词hot的重要性是单词dog的两倍,从而产生了一张非常热的狗!
[模型版本] 1、2、3仅接受整数作为权重
[模型版本] 4可以接受小数点作为权重
未指定权重默认为1。
权重已经标准化:
hot:: dog 等同于 hot::1 dog, hot:: dog::1,hot::2 dog::2, hot::100 dog::100 等。
cup::2 cake 等同于 cup::4 cake::2, cup::100 cake::50等。
cup ::cake :: illustration 等同于 cup :: 1 cake :: 1 illustration :: 1,cup :: 1 cake :illustration,cup ::2 cake ::2 illustration ::2等。
可以向提示添加负权重以删除不需要的元素。
所有权重之和必须为正数。
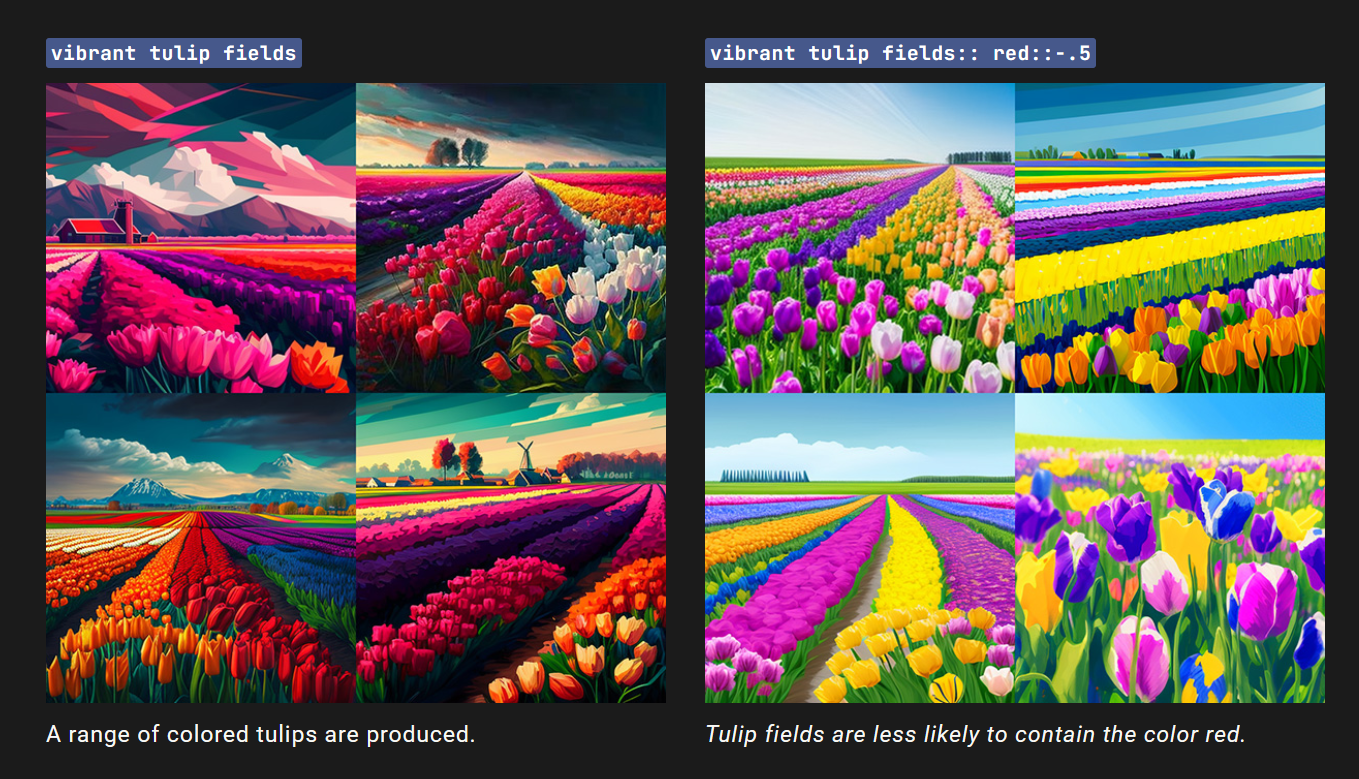
郁金香::红色::-0.5与郁金香::2红色::-1、郁金香::200红色::-100等效。
–no参数相当于将多个提示的一部分加权为“-0.5”,如:充满活力的郁金香田野::红色::-0.5与充满活力的郁金香田野 --no 红色 相同。
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我正在开发一个Rails应用程序,我需要在其中找到给定特定偏移量或时区的夏令时开始和结束日期。我基本上在我的数据库中保存了从用户浏览器接收到的时区偏移量(“+3”,“-5”),我想在它出现时修改它由于夏令时的变化。我知道Time实例变量有dst?和isdst方法,如果存储在它们中的日期在夏令时与否。>Time.new.isdst=>true但是使用它来查找夏令时的开始和结束日期会占用太多资源,而且我还必须为我拥有的每个时区偏移量执行此操作。我想知道更好的方法。 最佳答案 好的,基于你所说的和@dhouty'sanswer:您希望能够
我有一台生产机器和一台开发机器,都运行ubuntu8.10并且都运行最新的phusionpassenger。当我在osx上的本地开发机器上使用ruby1.9.1时,我想知道外面的人是否已经在使用带有ruby1.9.1甚至1.9.2的phusionpassenger?如果是这样,请告诉我们您的设置!此外,有没有办法在apache上使用phusionpassenger同时运行ruby1.8.7(ree)和1.9.1?感谢您的指点,我在任何地方都找不到任何提示... 最佳答案 是的,从某些2.2.x版本开始就正式支持它,我不记
date_select方法只能设置:start_year,但我想设置开始日期(例如3个月前的日期)(但没有这样的选项)。那么,我可以将开始日期设置为date_select方法吗?或者,要制作这样的选择框,我应该使用select_tag和options_for_select吗?或者,有什么解决办法吗?谢谢, 最佳答案 有可能……例如:start_year–设置年份选择的开始年份。默认为Time.now.year-5参见thisresource. 关于ruby-Rails3-我可以将开始日期
我想从特定索引开始遍历数组。我该怎么做?myj.eachdo|temp|...end 最佳答案 执行以下操作:your_array[your_index..-1].eachdo|temp|###end 关于ruby-从特定索引开始迭代数组,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/44151758/
(本文是网络的宏观的概念铺垫)目录计算机网络背景网络发展认识"协议"网络协议初识协议分层OSI七层模型TCP/IP五层(或四层)模型报头以太网碰撞路由器IP地址和MAC地址IP地址与MAC地址总结IP地址MAC地址计算机网络背景网络发展 是最开始先有的计算机,计算机后来因为多项技术的水平升高,逐渐的计算机变的小型化、高效化。后来因为计算机其本身的计算能力比较的快速:独立模式:计算机之间相互独立。 如:有三个人,每个人做的不同的事物,但是是需要协作的完成。 而这三个人所做的事是需要进行协作的,然而刚开始因为每一台计算机之间都是互相独立的。所以前面的人处理完了就需要将数据