摘要:通过本教程,我们可以学习客流统计应用的扩展——过线客流统计+口罩佩戴识别,可用于商超、写字楼入口安检。
本文分享自华为云社区《客流分析之未佩戴口罩识别》,作者: HiLens_feige 。
疫情虽然过去了,口罩佩戴防护依然十分重要,本文在 基于头肩部检测的过线客流统计 博文基础上增加口罩佩戴检测功能:采用头肩部检测人形并进行跟踪,当头肩部中心点跨过事先划定的线段时,增加客流计数,同时检查此人是否佩戴口罩;过线前后的人形将使用不同颜色的框表示,画面中会实时显示客流数量,若有未佩戴口罩的人也会产生告警。
本文将使用华为云ModelArts进行人形检测模型的训练,并使用ModelBox框架进行应用开发,使用前开发者需要完成如下准备工作:
这个应用对应的ModelBox版本已经做成模板放在华为云OBS中,可以用sdk中的solution.bat工具下载,接下来我们给出该应用在ModelBox中的完整开发过程:
执行.\solution.bat -l可看到当前公开的技能模板:
PS ███> .\solution.bat -l
...
Solutions name:
mask_det_yolo3
...
passenger_flow_mask_det_yolo7_LCNet结果中的passenger_flow_mask_det_yolo7_LCNet即为过线客流统计+口罩佩戴识别应用模板,可使用如下命令下载模板:
PS ███> .\solution.bat -s passenger_flow_mask_det_yolo7_LCNet
...solution.bat工具的参数中,-l 代表list,即列出当前已有的模板名称;-s 代表solution-name,即下载对应名称的模板。下载下来的模板资源,将存放在ModelBox核心库的solution目录下。
在ModelBox sdk目录下使用create.bat创建passenger_flow_mask_det工程
PS ███> .\create.bat -t server -n passenger_flow_mask_det -s passenger_flow_mask_det_yolo7_LCNet
sdk version is modelbox-xxx
success: create passenger_flow_mask_det in ███\modelbox\workspacecreate.bat工具的参数中,-t 表示创建事务的类别,包括工程(server)、Python功能单元(Python)、推理功能单元(infer)等;-n 代表name,即创建事务的名称;-s 代表solution-name,表示将使用后面参数值代表的模板创建工程,而不是创建空的工程。
workspace目录下将创建出passenger_flow_mask_det工程,工程内容如下所示:
passenger_flow_mask_det
|--bin
│ |--main.bat:应用执行入口
│ |--mock_task.toml:应用在本地执行时的输入输出配置,此应用默认使用本地视频文件为输入源,最终结果输出到另一本地视频文件,可根据需要修改
|--CMake:存放一些自定义CMake函数
|--data:存放应用运行所需要的图片、视频、文本、配置等数据
│ |--passenger_flow.mp4:客流统计测试用视频文件
│ |--simsun.ttc:中文字体库
|--dependence
│ |--modelbox_requirements.txt:应用运行依赖的外部库在此文件定义,本应用依赖pillow工具包
|--etc
│ |--flowunit:应用所需的功能单元存放在此目录
│ │ |--cpp:存放C++功能单元编译后的动态链接库,此应用没有C++功能单元
│ │ |--collapse_multi_face:合并功能单元,将同一张图的多个人脸的口罩佩戴数据进行合并输出
│ │ |--draw_passenger_bbox:客流画图功能单元
│ │ |--expand_face_images:展开功能单元,将同一张图的多个人脸检测框展开为多个输出
│ │ |--face_condition:条件功能单元,根据图中是否检测到人脸输出不同的分支
│ │ |--merge_track_face_info:将跟踪信息与口罩佩戴信息整合输出
│ │ |--object_tracker:目标跟踪功能单元
│ │ |--yolov7_post:头肩部检测使用的是YOLO7模型,此处即为后处理功能单元
|--flowunit_cpp:存放C++功能单元的源代码,此应用没有C++功能单元
|--graph:存放流程图
│ |--passenger_flow_mask_det.toml:默认流程图,使用本地视频文件作为输入源
│ |--modelbox.conf:modelbox相关配置
|--hilens_data_dir:存放应用输出的结果文件、日志、性能统计信息
|--model:推理功能单元目录
│ |--head_detection:头肩部检测推理功能单元
│ │ |--head_detection.toml:头肩部检测推理功能单元的配置文件
│ │ |--head_det_yolo7_lite_224x352.onnx:头肩部检测onnx模型
│ |--mask_cls:口罩佩戴分类推理功能单元
│ │ |--mask_cls.toml:口罩佩戴分类推理功能单元的配置文件
│ │ |--mask_cls.onnx:口罩佩戴分类onnx模型
|--build_project.sh:应用构建脚本
|--CMakeLists.txt
|--rpm:打包rpm时生成的目录,将存放rpm包所需数据
|--rpm_copyothers.sh:rpm打包时的辅助脚本passenger_flow_mask_det工程graph目录下存放流程图,默认的流程图passenger_flow_mask_det.toml与工程同名,其内容为(以Windows版ModelBox为例):
[driver]
# 功能单元的扫描路径,包含在[]中,多个路径使用,分隔
# ${HILENS_APP_ROOT} 表示当前应用的实际路径
# ${HILENS_MB_SDK_PATH} 表示ModelBox核心库的实际路径
dir = [
"${HILENS_APP_ROOT}/etc/flowunit",
"${HILENS_APP_ROOT}/etc/flowunit/cpp",
"${HILENS_APP_ROOT}/model",
"${HILENS_MB_SDK_PATH}/flowunit",
]
skip-default = true
[profile]
# 通过配置profile和trace开关启用应用的性能统计
profile = false # 是否记录profile信息,每隔60s记录一次统计信息
trace = false # 是否记录trace信息,在任务执行过程中和结束时,输出统计信息
dir = "${HILENS_DATA_DIR}/mb_profile" # profile/trace信息的保存位置
[flow]
desc = "passenger flow count and mask detection example using yolo7 and LCNet for local video or rtsp video stream" # 应用的简单描述
[graph]
format = "graphviz" # 流程图的格式,当前仅支持graphviz
graphconf = """digraph passenger_flow_mask_det {
node [shape=Mrecord]
queue_size = 4
batch_size = 1
# 定义节点,即功能单元及其属性
input1[type=input, flowunit=input, device=cpu, deviceid=0]
data_source_parser[type=flowunit, flowunit=data_source_parser, device=cpu, deviceid=0]
video_demuxer[type=flowunit, flowunit=video_demuxer, device=cpu, deviceid=0]
video_decoder[type=flowunit, flowunit=video_decoder, device=cpu, deviceid=0, pix_fmt="rgb"]
resize[type=flowunit flowunit=resize device=cpu deviceid="0" image_width=352, image_height=224]
color_transpose[type=flowunit flowunit=packed_planar_transpose device=cpu deviceid="0"]
normalize[type=flowunit flowunit=normalize device=cpu deviceid="0" standard_deviation_inverse="0.0039215686,0.0039215686,0.0039215686"]
head_detection[type=flowunit flowunit=head_detection device=cpu deviceid="0"]
yolov7_post[type=flowunit flowunit=yolov7_post device=cpu deviceid="0"]
object_tracker[type=flowunit flowunit=object_tracker device=cpu deviceid="0"]
face_condition[type=flowunit flowunit=face_condition device=cpu deviceid="0"]
expand_face_images[type=flowunit, flowunit=expand_face_images, device=cpu, deviceid=0]
image_resize2[type=flowunit, flowunit=resize, device=cpu, deviceid=0, image_width=96, image_height=96]
color_transpose2[type=flowunit flowunit=packed_planar_transpose device=cpu deviceid="0"]
mean[type=flowunit flowunit=mean device=cpu deviceid="0" mean="123.675, 116.28, 103.53"]
normalize2[type=flowunit flowunit=normalize device=cpu deviceid="0" standard_deviation_inverse="0.01742919,0.0175070,0.01712475"]
mask_cls[type=flowunit, flowunit=mask_cls, device=cpu, deviceid=0]
collapse_multi_face[type=flowunit, flowunit=collapse_multi_face, device=cpu, deviceid=0]
merge_track_face_info[type=flowunit, flowunit=merge_track_face_info, device=cpu, deviceid=0]
draw_passenger_bbox[type=flowunit, flowunit=draw_passenger_bbox, device=cpu, deviceid=0]
video_out[type=flowunit, flowunit=video_out, device=cpu, deviceid=0]
# 定义边,即功能间的数据传递关系
input1:input -> data_source_parser:in_data
data_source_parser:out_video_url -> video_demuxer:in_video_url
video_demuxer:out_video_packet -> video_decoder:in_video_packet
video_decoder:out_video_frame -> resize:in_image
resize:out_image -> color_transpose:in_image
color_transpose:out_image -> normalize:in_data
normalize:out_data -> head_detection:input
head_detection:output -> yolov7_post:in_feat
yolov7_post:out_data -> object_tracker:in_bbox
video_decoder:out_video_frame -> face_condition:in_image
object_tracker:out_track -> face_condition:in_track
face_condition:no_face -> draw_passenger_bbox:in_image
face_condition:has_face -> expand_face_images:in_image
expand_face_images:roi_images -> image_resize2:in_image
image_resize2:out_image -> color_transpose2:in_image
color_transpose2:out_image -> mean:in_data
mean:out_data -> normalize2:in_data
normalize2:out_data -> mask_cls:input
mask_cls:output -> collapse_multi_face:in_feat
collapse_multi_face:out_data -> merge_track_face_info:in_face_info
face_condition:has_face -> merge_track_face_info:in_image
merge_track_face_info:out_image -> draw_passenger_bbox:in_image
draw_passenger_bbox:out_image -> video_out:in_video_frame
}"""整个应用逻辑较为复杂,视频解码后做图像预处理,接着是头肩部检测,模型后处理得到头肩框,送入跟踪算法进行实时跟踪与过线判断,此时根据是否有人过线并检测到人脸分成两个分支,一个分支直接输出跟踪信息,另一个分支将人脸检测框裁剪出来做口罩佩戴识别,最后将跟踪信息与口罩识别结果整合后画到图像输出到视频中。应用中使用到了条件功能单元、展开/合并功能单元。
本应用的核心逻辑有几处:
这一段逻辑体现在 object_tracker 功能单元 object_tracker.py 的 get_tracking_objects 函数中:
def get_tracking_objects(self, line_y):
'''从跟踪器中获取跟踪目标,保存到结构化数据中'''
def _is_pass_line(bbox, line_y):
'''根据检测框的中心点与线段的水平位置关系判断是否过线'''
center_y = (bbox[1] + bbox[3]) / 2
return center_y > line_y
track_bboxes = [track.det for track in self.tracker.tracks]
matches, _, _ = match(face_bboxes, track_bboxes, self.face_cover_ratio, True)
tracking_objects = [] # 所有跟踪目标
face_info = {} # 刚刚过线的人头目标对应的人脸框,track_id -> face_bbox
for ix, track in enumerate(self.tracker.tracks):
# 只记录CONFIRMED状态的跟踪目标
if track.state != EasyTracker.TrackingState.CONFIRMED:
continue
tracking_obj = {} # 使用字典保存跟踪目标
tracking_obj["id"] = track.track_id # 跟踪id
tracking_obj["bbox"] = track.det # 跟踪框
if not track.passline and _is_pass_line(track.det, line_y): # 刚好过线
track.passline = True
self.flow_count += 1
if ix in matches: # 找到了匹配的人脸框
face_info[track.track_id] = face_bboxes[matches[ix]]
tracking_obj["passline"] = track.passline # 记录过线信息
tracking_objects.append(tracking_obj)
return tracking_objects, face_info可以看到,与过线客流统计 中的代码相比,此处还做了头肩部与人脸的匹配,当某头肩部过线时,若它匹配到了人脸(人脸框在头肩部框中),将它们进行关联(使用跟踪id关联)。后面的功能单元跟人脸框信息裁剪出人脸图片进行口罩佩戴分类。
这一段逻辑体现在 merge_track_face_info 功能单元 merge_track_face_info.py 的 process 函数中:
def process(self, data_context):
# 从DataContext中获取输入输出BufferList对象
in_image = data_context.input("in_image")
in_face_info = data_context.input("in_face_info")
out_image = data_context.output("out_image")
# 循环处理每一个输入Buffer数据
for buffer_img, buffer_mask in zip(in_image, in_face_info):
# 获取输入图像Buffer的宽、高、通道数等属性信息
width = buffer_img.get('width')
height = buffer_img.get('height')
channel = buffer_img.get('channel')
# 将输入图像Buffer转换为numpy对象
img_data = np.array(buffer_img.as_object(), dtype=np.uint8, copy=False)
img_data = img_data.reshape(height, width, channel)
# 提取口罩佩戴信息,转换为numpy对象
mask_info = np.array(buffer_mask.as_object(), copy=False)
# 提取图像Buffer中附带的json跟踪数据,转换为dict对象
track_info = json.loads(buffer_img.get("track_info"))
face_info = json.loads(track_info['face_info'])
for ix, id in enumerate(face_info): # 将口罩佩戴信息更新到人脸数据中
face_info[id] = int(mask_info[ix])
# 更新跟踪数据dict,转换为json对象
track_info["face_info"] = json.dumps(face_info)
buffer_img.set("track_info", json.dumps(track_info))
# 将输出Buffer放入输出BufferList中
out_image.push_back(buffer_img)
# 返回成功标志,ModelBox框架会将数据发送到后续的功能单元
return modelbox.Status.StatusCode.STATUS_SUCCESS可以看到,口罩佩戴数据整合到跟踪数据中,作为属性附在图片上往后传递。
本应用中的画图功能单元以来 pillow 工具包以实现中文输出,ModelBox应用不需要手动安装三方依赖库,只需要配置在 dependence\modelbox_requirements.txt 即可。另外,中文输出还需要对应的字体库,存放在 data 目录下,画图功能单元初始化时将从此目录加载资源。
查看任务配置文件bin/mock_task.toml,可以看到其中的任务输入和任务输出配置为如下内容::
[input]
type = "url"
url = "${HILENS_APP_ROOT}/data/passenger_flow.mp4" # 表示输入源为本地视频文件
[output]
type = "local"
url = "${HILENS_APP_ROOT}/hilens_data_dir/passenger_flow_result.mp4" # 表示输出为本地视频文件即,使用本地视频文件data/passenger_flow.mp4作为输入,统计过线客流后,画图输出到本地视频文件data/passenger_flow_result.mp4中。
启动应用前执行.\build_project.sh进行工程构建,该脚本将编译自定义的C++功能单元(本应用不涉及)、将应用运行时会用到的配置文件转码为Unix格式(防止执行过程中的格式错误):
PS ███> .\build_project.sh
...
PS ███>然后执行.\bin\main.bat运行应用:
PS ███> .\bin\main.bat
...运行结束后在hilens_data_dir目录下生成了passenger_flow_result.mp4文件,可以打开查看:
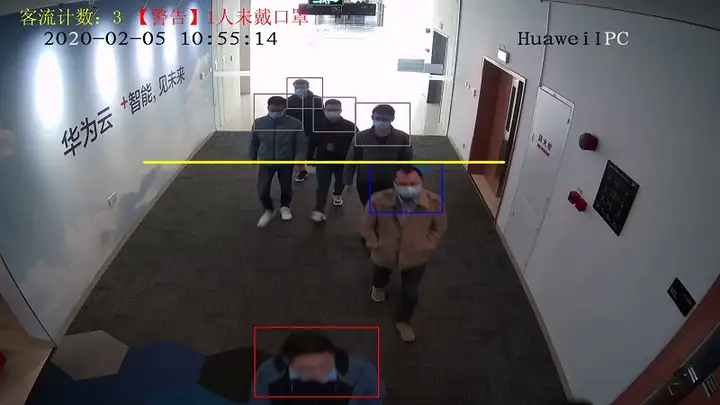
可以看到,黄色线段即为过线统计的水平线段,未过线的人使用灰色框标记其头肩部,已过线且未佩戴口罩的使用红色框,已过线且佩戴口罩的使用蓝色框,画面左上角实时显示总的过线客流数量,若画面中有未佩戴口罩的人会输出告警。
通过本教程,我们学习了客流统计应用的扩展——过线客流统计+口罩佩戴识别,可用于商超、写字楼入口安检。
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt