
Elasticsearch在生产环境中有广泛的应用,本文介绍一种方法,基于网易数帆开源的Curve文件存储,实现Elasticsearch存储成本、性能、容量和运维方面的显著提升。
为了高可靠,ES如果使用本地盘的话一般会使用两副本,也就是说存储1PB数据需要2PB的物理空间。但是如果使用CurveFS,由于CurveFS的后端可以对接S3,所以可以利用对象存储提供的EC能力,既保证了可靠性,又可以减少副本数量,从而达到了降低成本的目的。
以网易对象存储这边当前主流的EC 20+4使用为例,该使用方式就相当于是1.2副本。所以如果以ES需要1PB使用空间为例,那么使用CurveFS+1.2副本对象存储只需要1.2PB空间,相比本地盘2副本可以节省800TB左右的容量,成本优化效果非常显著。
以下文将要介绍的使用场景为例,对比ES原来使用S3插件做snapshot转存储的方式,由于每次操作的时候索引需要进行restore操作,以100G的日志索引为例,另外会有传输时间,如果restore的恢复速度为100M,那么也要300多秒。实际情况是在一个大量写入的集群,这样的操作可能要几个小时。
而使用CurveFS后的新模式下基本上只要对freeze的索引进行unfreeze,让对应节点的ES将对应的meta数据载入内存就可以执行索引,大概耗时仅需30S左右,相比直接用S3存储冷数据有数量级的下降。
本地盘的容量是有限的,而CurveFS的空间容量可以在线无限扩展。同时减少了本地存储的维护代价。
ES使用本地盘以及使用S3插件方式,当需要扩容或者节点异常恢复时,需要增加人力运维成本。CurveFS实现之初的一个目标就是易运维,所以CurveFS可以实现数条命令的快速部署以及故障自愈能力。
另外如果ES使用CurveFS,就实现了存算分离,进一步释放了ES使用者的运维负担。
背景: 在生产环境有大量的场景会用到ES做文档、日志存储后端,因为ES优秀的全文检索能力在很多时候可以大大的简化相关系统设计的复杂度。比较常见的为日志存储,链路追踪,甚至是监控指标等场景都可以用ES来做。
为了符合国内的法律约束,线上系统需要按照要求存储6个月到1年不等的系统日志,主要是国内等保、金融合规等场景。按照内部管理的服务器数量,单纯syslog的日志存储空间每天就需要1T,按照当前手头有的5台12盘位4T硬盘的服务器,最多只能存储200多天的日子,无法满足日志存储1年的需求。
针对ES使用本地盘无法满足存储容量需求这一情况,网易ES底层存储之前单独引入过基于S3的存储方案来降低存储空间的消耗。如下图,ES配合minio做数据存储空间的压缩。举例来说100G的日志,到了ES里面因为可靠性需求,需要双副本,会使用200G的空间。ES针对索引分片时间,定期性转存储到minio仓库。

这个方案从一定程度上缓解了存储空间的资源问题,但是实际使用的时候还会感觉非常不便利。
由于S3协议经过多年的演化,已经成了对象存储的工业标准。很多人都有想过用fuse的方式使用S3的存储能力。事实上基于S3的文件系统有很多款,例如开源的s3fs-fuse、ossfs、RioFS、CurveFS等。
在通过实际调研以及大量的测试后,基于Curve的性能(尤其是元数据方面,CurveFS是基于RAFT一致性协议自研的元数据引擎,与其他没有元数据引擎的S3文件系统(比如s3fs,ossfs)相比具备巨大的性能优势),易运维,稳定性,Curve可以同时提供块存储以及文件存储能力等能力以及Curve活跃的开源氛围,最终选用了CurveFS。
CurveFS是一个基于 Fuse实现的兼容POSIX 接口的分布式文件系统,架构如下图所示:
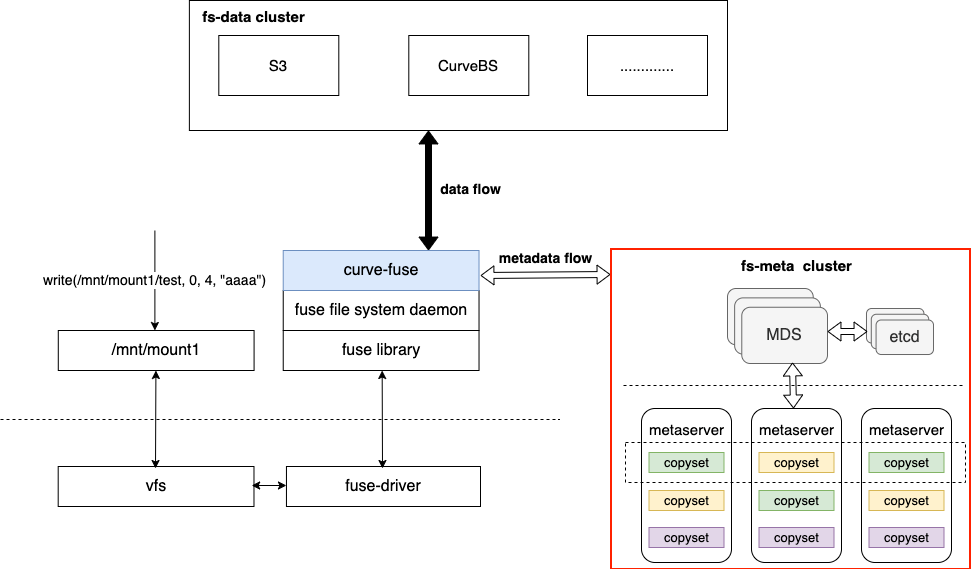
CurveFS由三个部分组成:
Curve除了既能支持文件存储,也能支持块存储之外,从上述架构图我们还能看出Curve的一个特点:就是CurveFS后端既可以支持S3,也可以支持Curve块存储。这样的特点可以使得用户可以选择性地把性能要求高的系统的数据存储在Curve块存储后端,而对成本要求较高的系统可以把数据存储在S3后端。
CurveFS定位于网易运维的云原生系统,所以其部署是简单快速的,通过CurveAdm工具,只需要几条命令便可以部署起CurveFS的环境,具体部署见[1][2];部署后效果如下图:

在日志存储场景,改造是完全基于历史的服务器做的在线改造。下图是线上日志的一个存储架构示例,node0到node5可以认为是热存储节点,机器为12*4T,128G的存储机型,每个节点跑3个ES实例,每个实例32G内存,4块独立盘。node6到node8为12*8T的存储机型,3台服务器跑一个Minio集群,每台机器上的ES实例不做数据本地写。
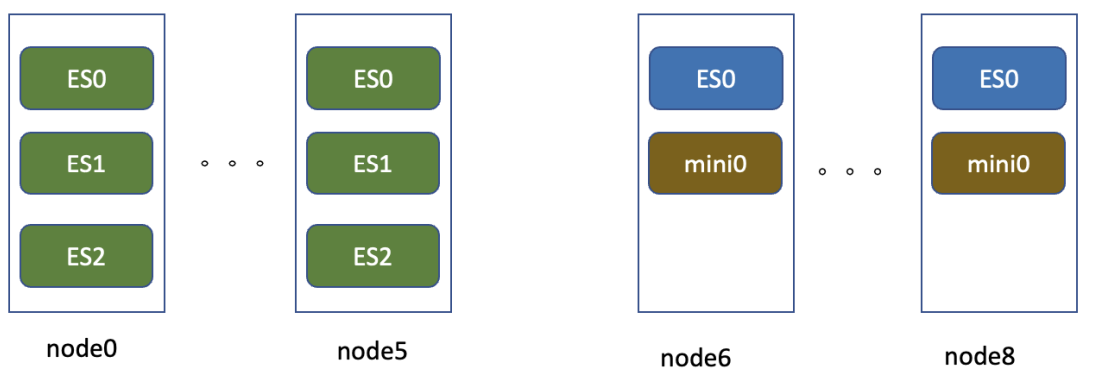
可以看到主要的改造重点是将node6到node8,3个节点进行ES的配置改造,其中以node6节点的配置为例:
cluster.name: ops-elk
node.name: ${HOSTNAME}
network.host: [_local_,_bond0_]
http.host: [_local_]
discovery.zen.minimum_master_nodes: 1
action.auto_create_index: true
transport.tcp.compress: true
indices.fielddata.cache.size: 20%
path.data: /home/nbs/elk/data1/data
path.logs: /home/nbs/elk/data1/logs
- /curvefs/mnt1
xpack.ml.enabled: false
xpack.monitoring.enabled: false
discovery.zen.ping.unicast.hosts: ["ops-elk1:9300","ops-elk7:9300","ops-elk
7:9300","ops-elk8.jdlt.163.org:9300"]
node.attr.box_type: cold如配置所示,主要的改造为调整ES的数据存储目录到CurveFS的fuse挂载目录,然后新增 node.attr.box_type 的设置。在node6到node8上分别配置为cold,node1到node5配置对应属性为hot,所有节点配置完成后进行一轮滚动重启。
除了底层配置外,很重要的一点就是调整index索引的设置。这块的设置难度不高,要点是:
其实在新节点开放数据存储后,如果没有亲和性设置,集群马上会启动relocating操作。因此建议对存量的索引新增routing.alloction.require的设置来避免热数据分配到CurveFS存储节点。针对每天新增索引,建议加入以下这样的index template配置。
{
"template": {
"settings": {
"index": {
"lifecycle": {
"name": "syslog",
"rollover_alias": "syslog"
},
"routing": {
"allocation": {
"require": {
"box_type": "hot"
}
}
},
"number_of_shards": "10",
"translog": {
"durability": "async"
}
}
},
"aliases": {
"syslog": {}
},
"mappings": {}
}
}这个index template设置的核心要点:
index部分的lifecycle是指索引的生命周期策略,需要注意rollover_alias里面的值要和下面的aliases定义对齐。
冷数据的切换,可以在kibana的index_lifecycle_management管理页面设置。针对上面的syslog场景,hot部分设置如下图,其余基本默认的就可以了。
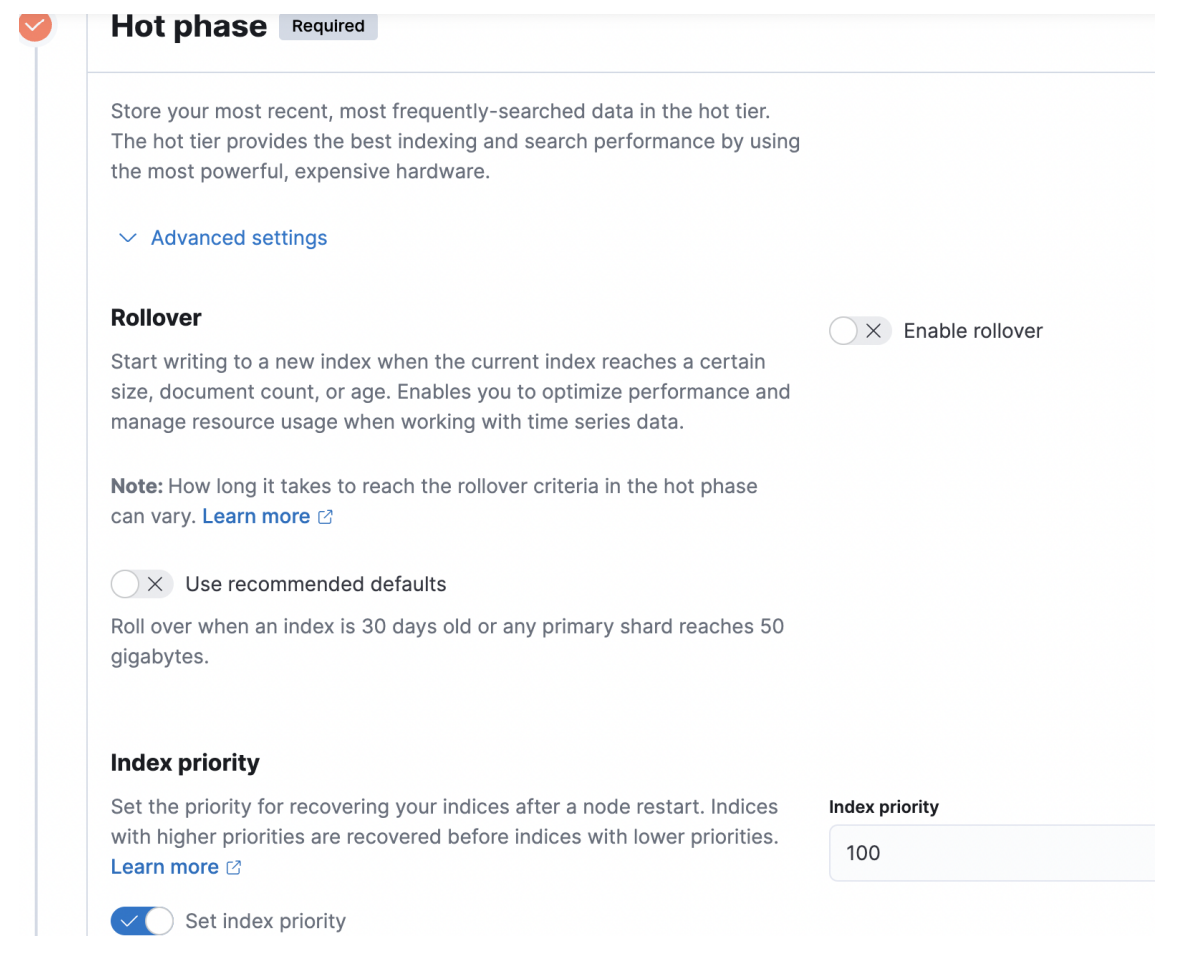
在索引周期管理配置页面中,除了设置hot phase,还可以设置warm phase,在warm phase可以做一些shrink,force merge等操作,日志存储场景我们直接做hot到cold的处理逻辑。
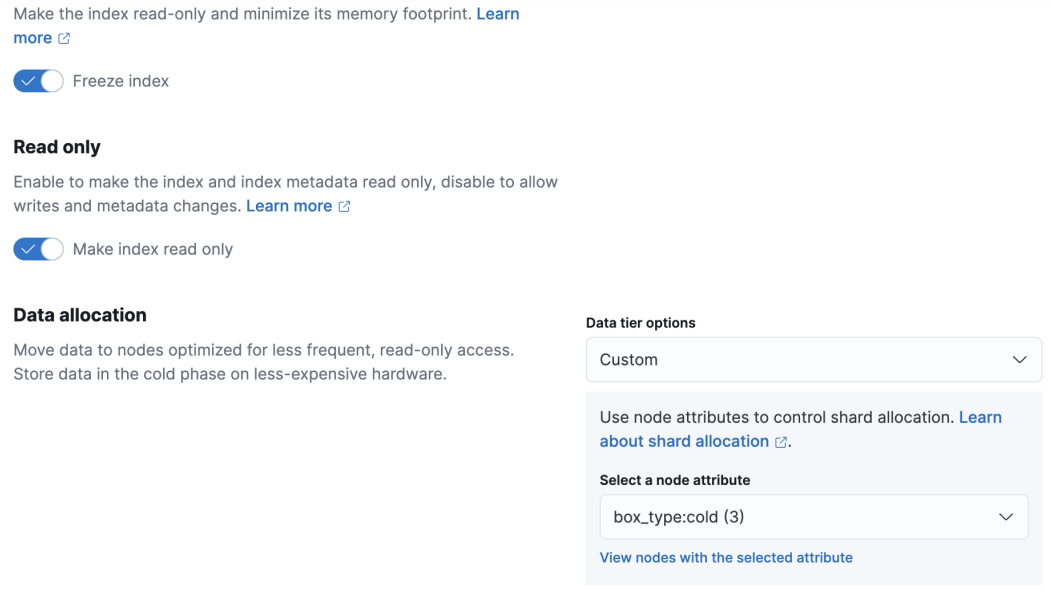
从技术上讲,日志存储类型的业务,底层索引一旦完成写后基本不做再次的数据更改,设置索引副本数量主要是为了应对分布式系统节点宕机等异常场景的数据恢复。如果存储层面有更可靠的方式,那么自然而然可以将es的副本数量调整为0。因此杭研云计算存储团队研发的一款基于S3后端的存储文件系统CurveFS,自然而然进入了冷数据选型的视野。从技术上讲内部S3存储基于EC纠删码的实现,通过降低ES的副本数量为0,可以明显的降低对存储空间的使用需求。
与 Curve 社区小伙伴沟通后,社区在 CurveFS 在存算分离方向的后续规划为:
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i